









































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Best Practices For BigData:Visualizing Billions of Rows with Rapid Response Times
MicroStrategy讲述他们的产品中如何提高大数据查询的性能。
Our Performance Scenario and Objective
• First Order Basic Practices
• A Note on Benchmarks
• Hadoop OLAP Type Tools
• Intelligent Cubes for Concurrency
• Last Things
• Summary
• Q&A
展开查看详情
1 . Best Practices for Big Data : Visualizing billions of rows with rapid response times “Big Data Analytics at the Speed of Thought” Anthony Maresco 1 Copyright © 2019 MicroStrategy Incorporated. All Rights Reserved .
2 .Safe Harbor Notice This presentation describes features that are under development by MicroStrategy. The objective of this presentation is to provide insight into MicroStrategy’s technology direction. The functionalities described herein may or may not be released as shown. This presentation contains statements that may constitute “forward-looking statements” for purposes of the safe harbor provisions under the Private Securities Litigation Reform Act of 1995, including descriptions of technology and product features that are under development and estimates of future business prospects. Forward-looking statements inherently involve risks and uncertainties that could cause actual results of MicroStrategy Incorporated and its subsidiaries (collectively, the “Company”) to differ materially from the forward-looking statements. Factors that could contribute to such differences include: the Company’s ability to meet product development goals while aligning costs with anticipated revenues; the Company’s ability to develop, market, and deliver on a timely and cost-effective basis new or enhanced offerings that respond to technological change or new customer requirements; the extent and timing of market acceptance of the Company’s new offerings; continued acceptance of the Company’s other products in the marketplace; the timing of significant orders; competitive factors; general economic conditions; and other risks detailed in the Company’s Form 10-Q for the three months ended September 30, 2018 and other periodic reports filed with the Securities and Exchange Commission. By making these forward-looking statements, the Company undertakes no obligation to update these statements for revisions or changes after the date of this presentation. Copyright © 2017 MicroStrategy Copyright Incorporated. © 2019 MicroStrategy Incorporated. AllAll Rights Rights Reserved. Reserved .
3 .Topics • Our Performance Scenario and Objective • First Order Basic Practices • A Note on Benchmarks • Hadoop OLAP Type Tools • Intelligent Cubes for Concurrency • Last Things • Summary • Q&A
4 . Special Thanks To…. HF Chadeisson Principal Solutions Architect 4 Copyright © 2019 MicroStrategy Incorporated. All Rights Reserved .
5 .Our Performance Scenario and Objectives Copyright © 2019 MicroStrategy Incorporated. All Rights Reserved .
6 .Objective • Compare performance impact of changes with a simple drill-down scenario using TPC-H SSB benchmark data • Progress from slow to fast using a combination of Hadoop features and MicroStrategy features • “Speed of Thought” Big Data Analytics with billions of rows • Get an introduction of new developments that improve the picture • Look at how some of these capabilities optimize Dossier interactive performance
7 .Minimize this….
8 .Johannes Kepler Johannes Kepler writing to Galileo Galilei in 1609 “Ships and sails proper for the heavenly air should be fashioned. Then there will also be people, who do not shrink from the dreary vastness of space.” Giordano Bruno was burned at the stake in 1600 for declaring the universe was infinite with countless suns and earths.
9 .Performance – Concurrency - Structure • “Initially, having any way to use SQL against the Hadoop data was the goal, now there is an increasing requirement to connect business users … and give them the performance they expect with high levels of concurrency.” • “Note that to meet this requirement, it is likely that users will need to have structured data stored in Hadoop (along with the original unstructured data), as good performance is more likely if a transformation is done once rather than per-query” https://dzone.com/articles/sql-and-hadoop
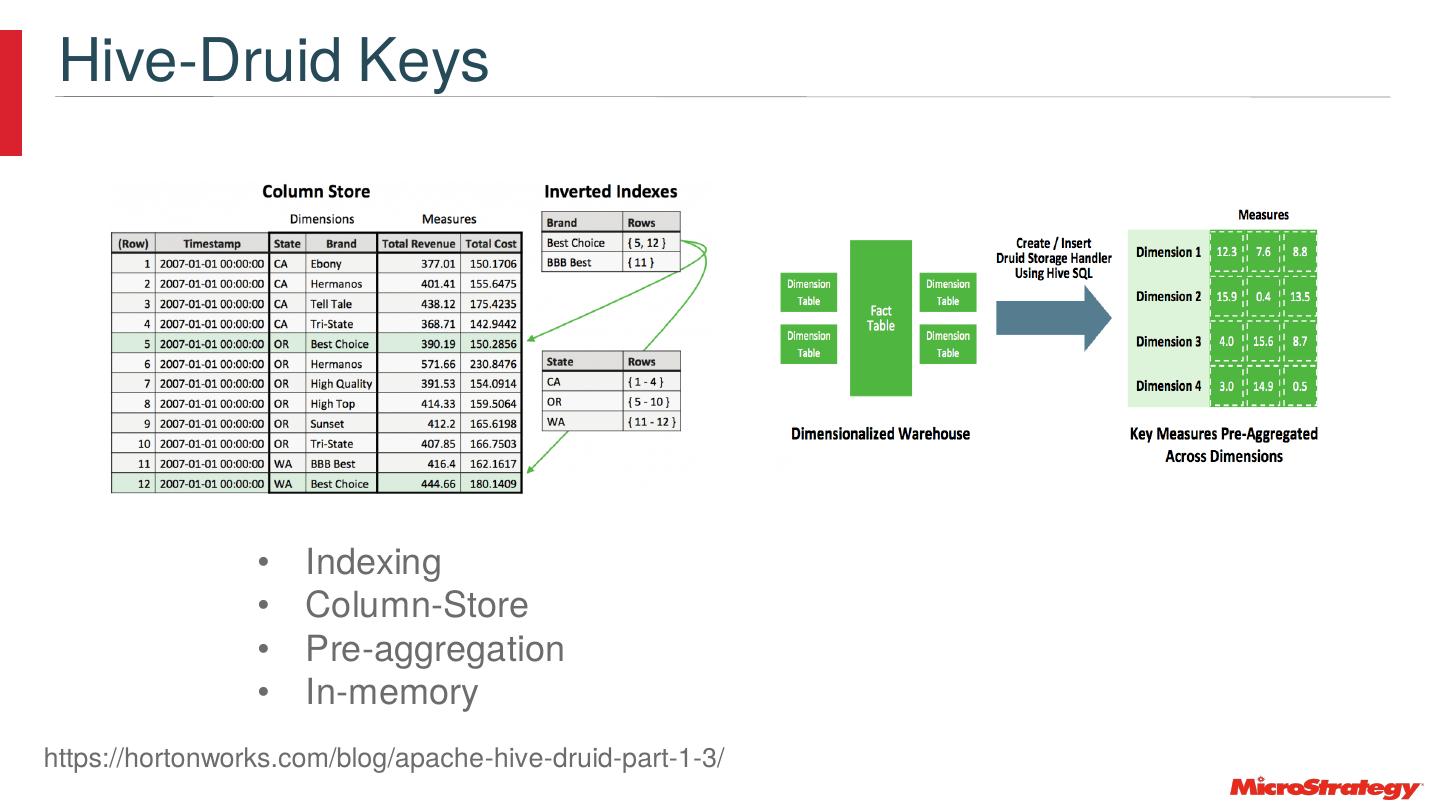
10 .déjà vu All Over Again • ROLAP vs. MOLAP • In-memory • Columnar • Indexing • Pre-Aggregation • MPP Features added to the data stores • And more… • All taken to the next level to deal with Big Data
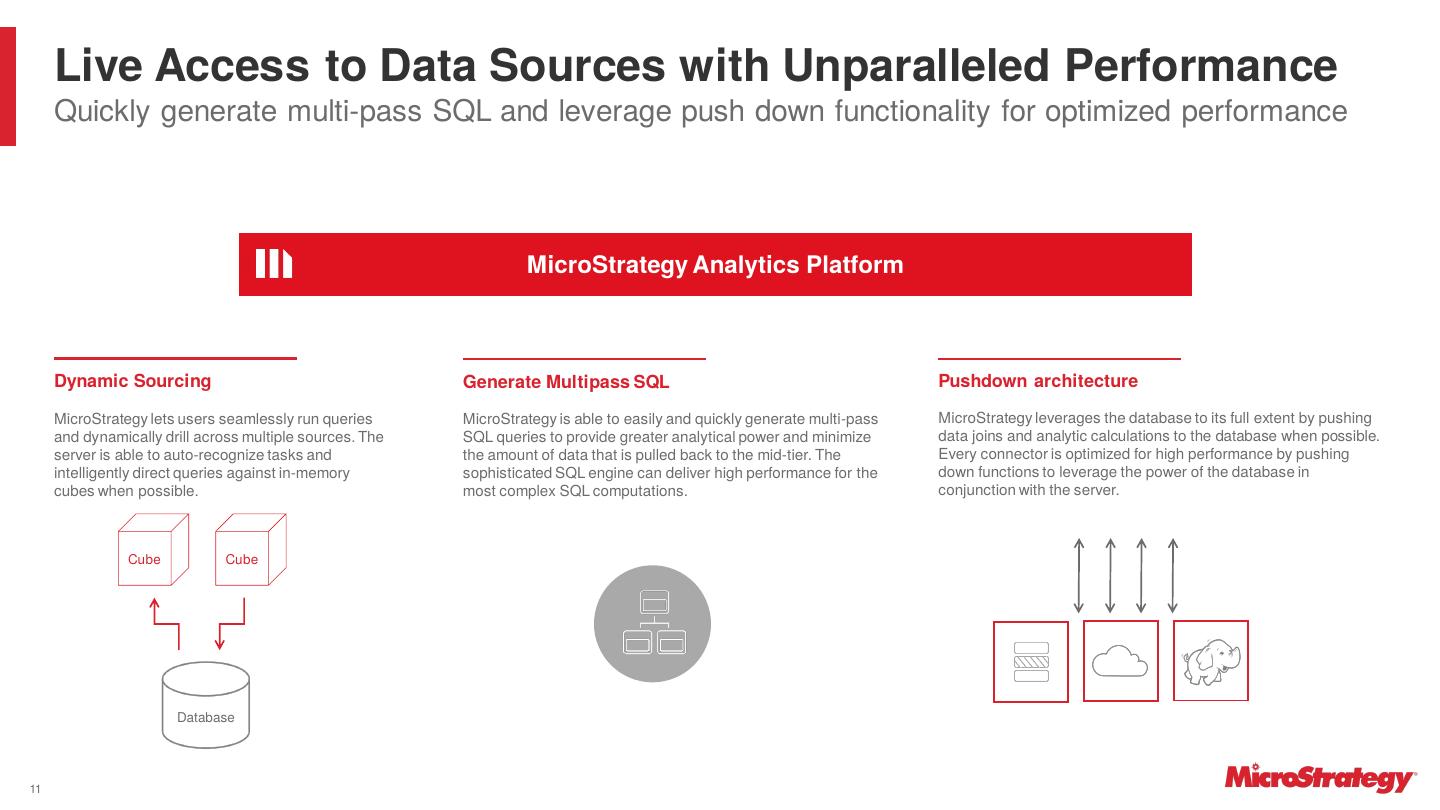
11 . Live Access to Data Sources with Unparalleled Performance Quickly generate multi-pass SQL and leverage push down functionality for optimized performance MicroStrategy Analytics Platform Dynamic Sourcing Generate Multipass SQL Pushdown architecture MicroStrategy lets users seamlessly run queries MicroStrategy is able to easily and quickly generate multi-pass MicroStrategy leverages the database to its full extent by pushing and dynamically drill across multiple sources. The SQL queries to provide greater analytical power and minimize data joins and analytic calculations to the database when possible. server is able to auto-recognize tasks and the amount of data that is pulled back to the mid-tier. The Every connector is optimized for high performance by pushing intelligently direct queries against in-memory sophisticated SQL engine can deliver high performance for the down functions to leverage the power of the database in cubes when possible. most complex SQL computations. conjunction with the server. Cube Cube Database 11
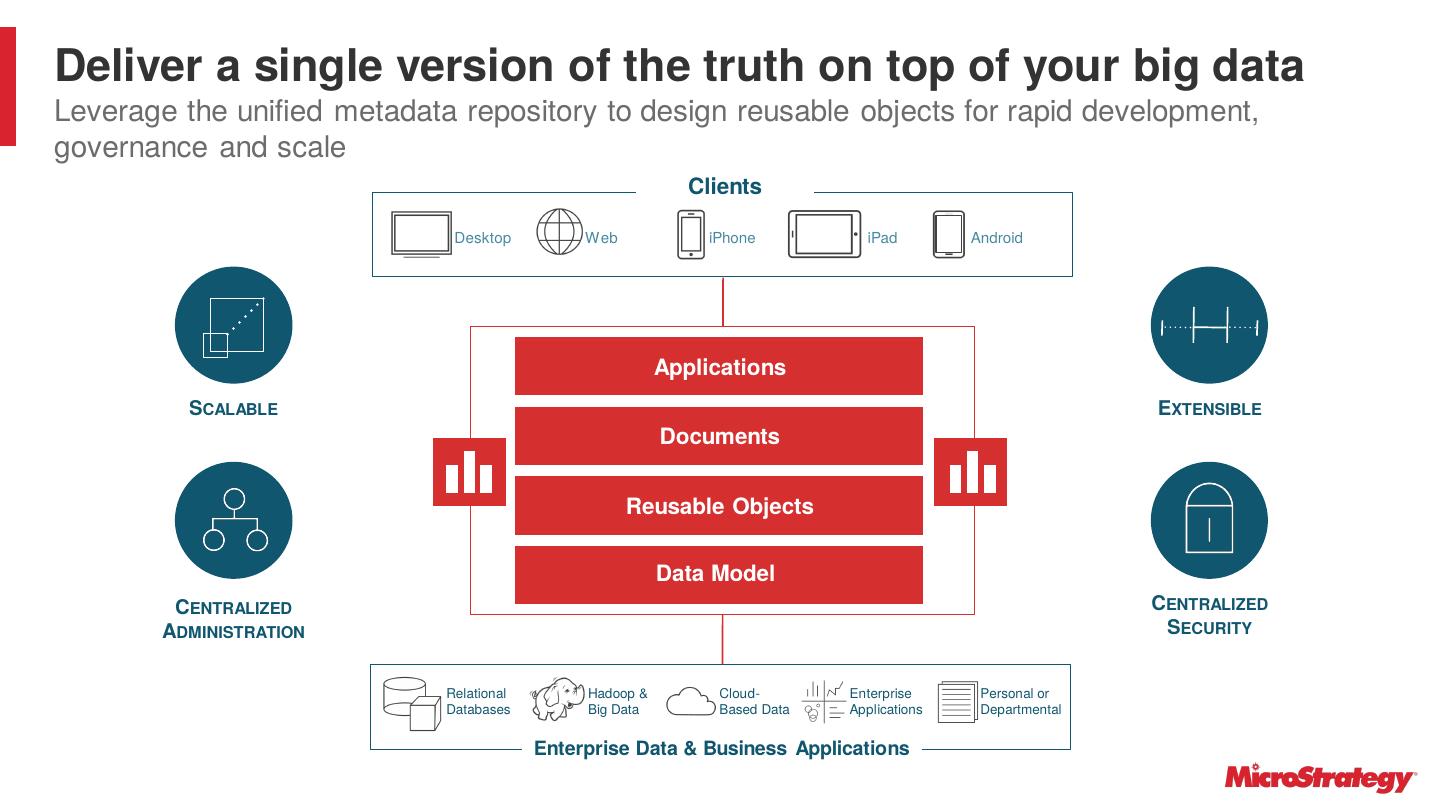
12 .Deliver a single version of the truth on top of your big data Leverage the unified metadata repository to design reusable objects for rapid development, governance and scale Clients Desktop Web iPhone iPad Android Applications SCALABLE EXTENSIBLE Documents Reusable Objects Data Model CENTRALIZED CENTRALIZED ADMINISTRATION SECURITY Relational Hadoop & Cloud- Enterprise Personal or Databases Big Data Based Data Applications Departmental Enterprise Data & Business Applications
13 .What is “Speed of Thought” Analytics ? • 3 seconds ? • 7 seconds ? • 10 seconds ? • 15 seconds ? • 30 seconds ? • More ??? • All have been quoted! Sometimes you have to wait….but you can set and manage SLA’s for X% of your workload…and evolve…
14 .Data – Hardware – Software - Facts • TPC-H SSB at various scales up to 1Terabyte • ~6 Billion rows in the largest fact table – also 1.2 and 3.3 billion tests • Add in semi-structured and data mining • 17 Billion Row Demo by Indexima • 30 B Row demo provided by Kyvos during the conference • 1.2 B Row Taxi used to show Dossier performance with several techniques and products referenced • 10 Node clusters with 8 data/worker nodes • Worker nodes have 8 vCPU and 61 GB • Use ORC file types • Hortonworks HDP 2.6.3 • 10 Node cluster with HDP 3.1.0 provided preliminary information
15 .Considerations • Plenty of new turf and it’s continually changing • SQL is still key as NoSQL or NewSQL • Add in semi-structured and data mining • SQL on Hadoop products are evolving quickly with rapid increases in functionality and performance. • Performance can double, triple or more in some cases in 6 month periods. • Ultimate decisions depend on testing with your data • Schema on read is key for iteration and flexibility in the back end • Schemas are still important to operationalize analytics to large number of users • Use of aggregation, agg-aware sql generation, caching, cubes, and dynamic sourcing are keys to performance and scalability • Memory Caching is a key infrastructure component • Agility means “Everything is finished…..Nothing is finished…”
16 .Prescription • Use the tools in the platform • Use MicroStrategy to make them better • Add additional tools & components where warranted • Use MicroStrategy to make them better • Use of aggregation, aggregation-aware sql generation, caching, cubes, and dynamic sourcing are tools for performance and scalability • Ensure you have the resources, knowledge, and time allocation for initial and ongoing tuning – sizing – monitoring - benchmarking • With MicroStrategy you get performance, scalability, governance, and concurrency to securely distribute insight with Big Data Analytics to 10’s of 1000’s of people • Additional Big Data Techniques and Tools are required when volume – velocity – variety get to a tipping point
17 .First-Order Best Practices Copyright © 2019 MicroStrategy Incorporated. All Rights Reserved .
18 .Preliminaries : Minimize Joins TPC-H Schema SSB Schema LINENUMB • SSB Version of TPC-H eliminates joins but is missing lookup tables • Snowflake is preferred with both dimension and lookup tables
19 .Preliminaries : Partitioning • Hive and Impala recommend partitioning to minimize scanned rows • This requires including a filter based on the partition in every query • It is important to pick partition columns so there are the right number of partitions • Partitioning can have other side effects • In an ad-hoc environment, you may not always be using the partitioning filter • In this study, partitioning was not used to see the relative impact of various actions • Bucketing can also be used in conjunction with Partitioning
20 .Preliminaries : Statistics • Always collect statistics on tables and columns in order to leverage cost based optimization • Example for Table ANALYZE TABLE table1 COMPUTE STATISTICS; • Example for Columns ANALYZE TABLE table1 COMPUTE STATISTICS FOR COLUMNS;
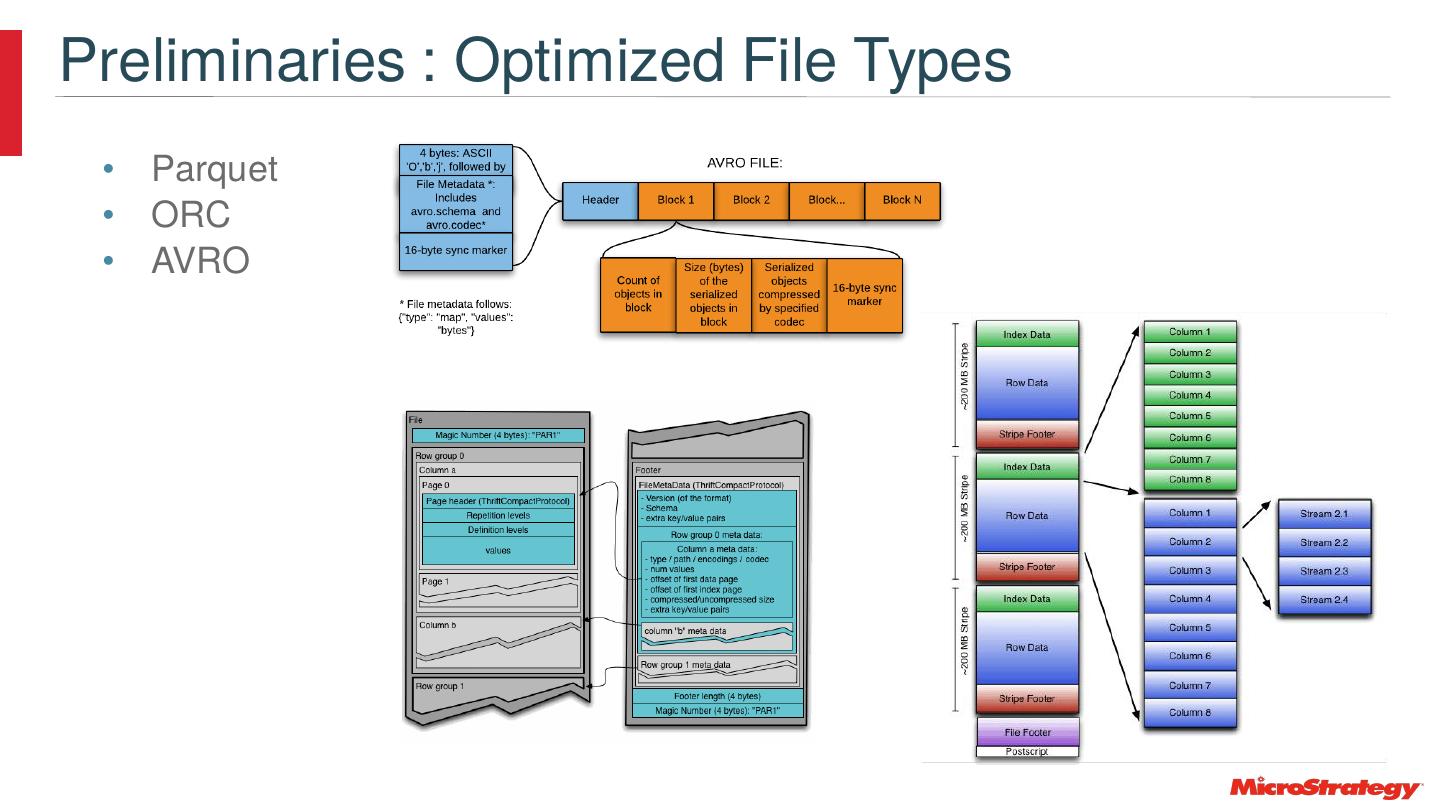
21 .Preliminaries : Optimized File Types • Parquet • ORC • AVRO
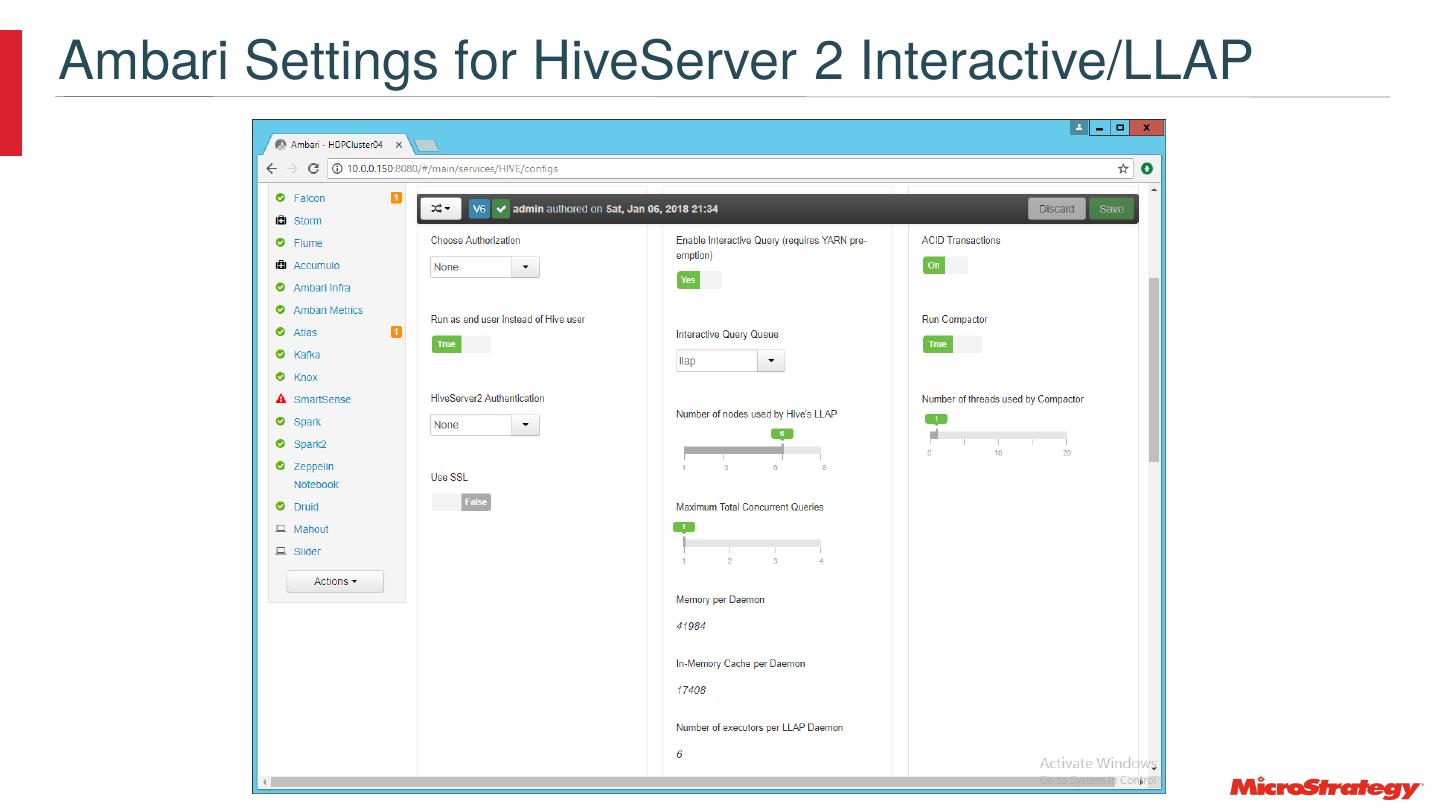
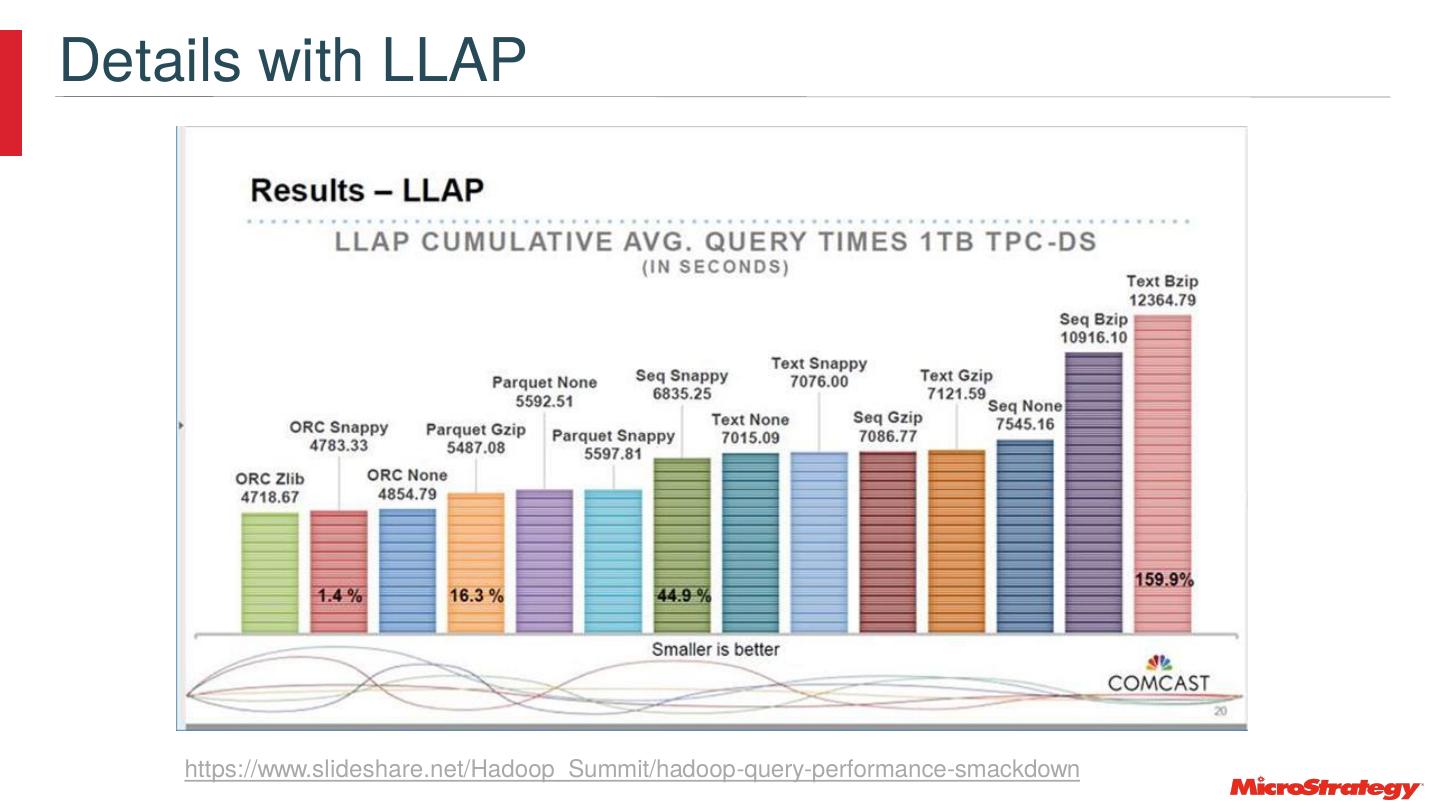
22 .Use the Latest Versions and Features • Example: move from HiveServer2 to HiveServer2 Interactive LLAP • At 550 Scale – 3.3 Billion Rows • Times are mm:ss Hive Server 2 Hive Server 2 Interactive LLAP 7:58 0:25 6:01 0:25 5:41 0:26
23 .SQL and Row Counts select a14.d_year d_year, Table Rows a13.c_region c_region, a12.p_category p_category, lineorders 5,999,989,709 a12.p_brand1 p_brand1, dates 2556 a12.p_mfgr p_mfgr, sum(a11.lo_revenue) WJXBFS1 customers 30,000,000 from lineorder join part a12 a11 parts 200,000,000 on (a11.lo_partkey = a12.p_partkey) Supplier 2,000,000 join customer a13 on (a11.lo_custkey = a13.c_custkey) join dates a14 on (a11.lo_orderdate = a14.d_datekey) where (a13.c_region = 'EUROPE' and a12.p_brand1 = 'MFGR#427') group by a14.d_year, a13.c_region, a12.p_category, a12.p_brand1, a12.p_mfgr
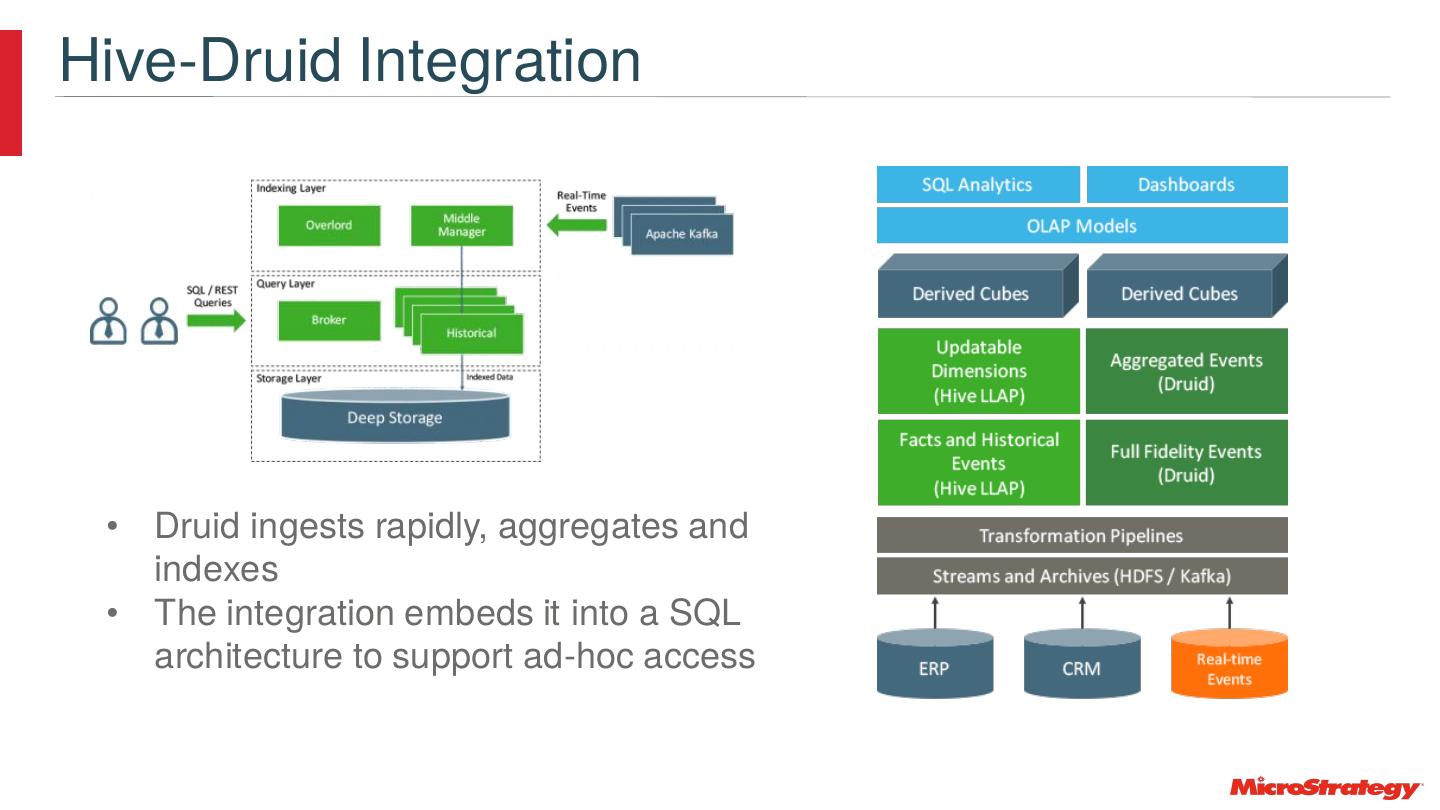
24 .Dynamic Runtime Filtering https://hortonworks.com/blog/top-5-performance-boosters-with-apache-hive-llap/
25 .Hive Server 2
26 .Hive Tez Query Processing
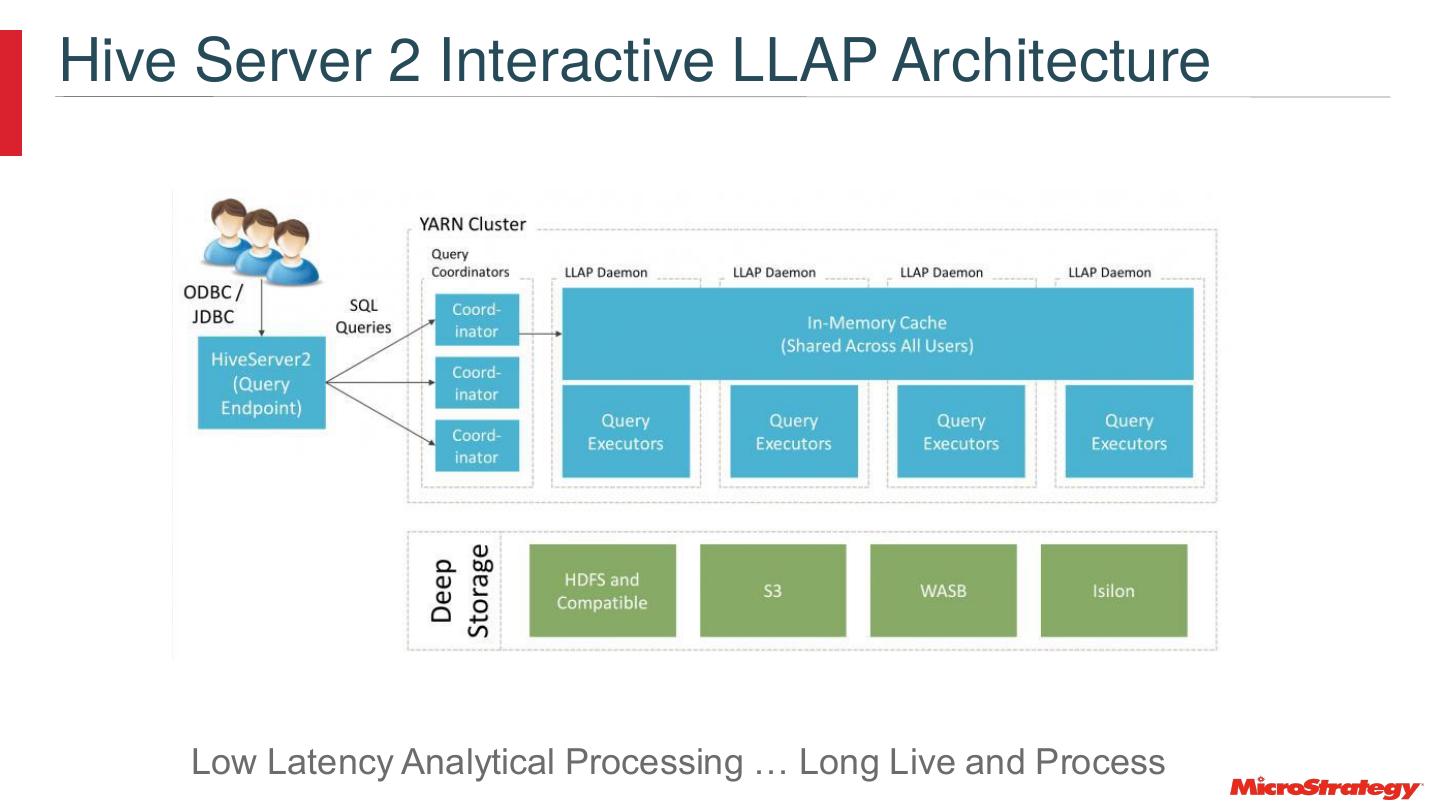
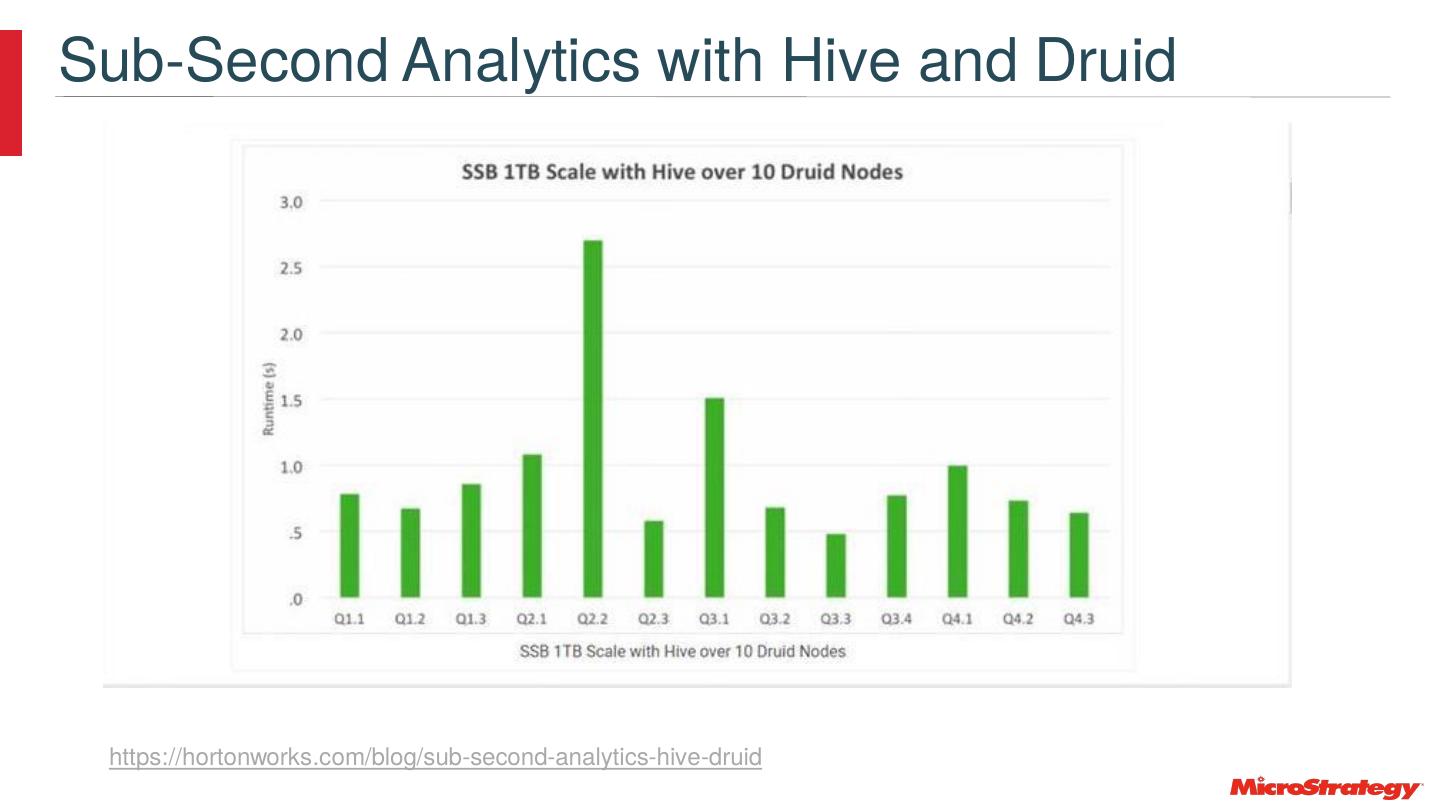
27 .Hive Server 2 Interactive LLAP Architecture Low Latency Analytical Processing … Long Live and Process
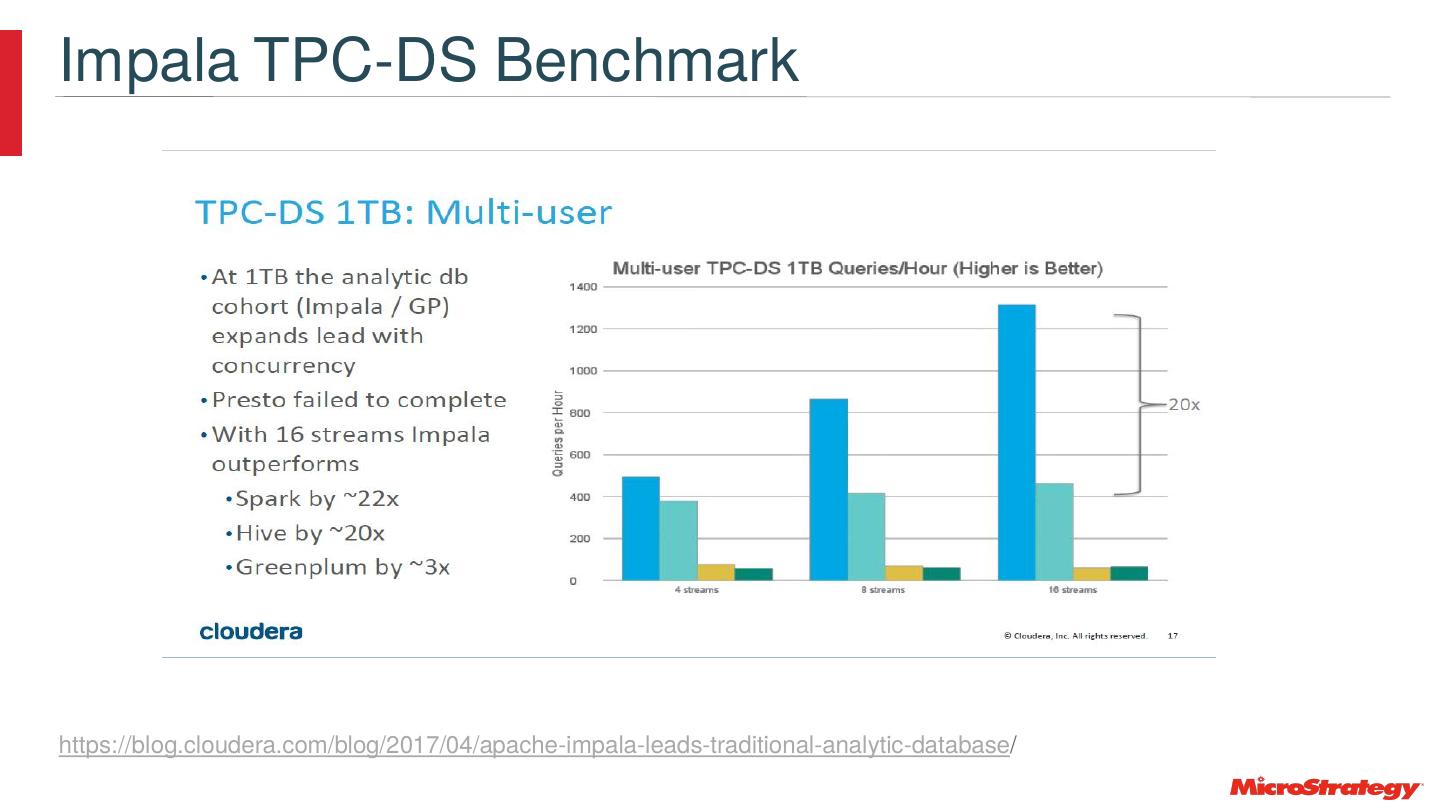
28 .Impala Architecture
29 .Presto Architecture “https://adtmag.com/articles/2015/06/08/teradata-presto.aspx
3秒后跳转登录页面
去登陆

