

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Faster MySQL replication using dependencies
异步复制的延迟与主从之间的吞吐量差距成正比。虽然在多核机器上已经做了大量的工作来提高主人的速度,但是奴隶却被抛在了后面。今天,主从吞吐量缺口实质上是一个并行性缺口。并行应用事务的串行日志并不容易。
在这项工作中,我们的目标是将从系统的吞吐量与主系统的吞吐量相匹配,而不仅仅是使其快X倍。我们使用已经存在于基于行的二进制日志中的信息来提取行突变之间的细粒度依赖关系,这使得从系统能够像主系统一样将事务调度到多个线程。我们还探讨了如何在从属服务器上放松事务执行模型,使它们更轻,并提高单线程性能。
展开查看详情
1 .Faster MySQL replication using dependencies Abhinav Sharma Facebook Inc.
2 .Motivation Replication lag is bad news • Stale reads on slaves • Potential data-loss 2
3 .Motivation Can we eliminate replication lag? No! • There will always be a finite replication lag • Network delay (bounded by speed of light) • Transaction processing on the slave • Minimum lag = Network lag + Transaction time 3
4 .Motivation Can we have bounds on replication lag? Yes! • Increasing lag is a function of difference in throughput between master and slave • Given master and the slave run on similar hardware and the slave is able to utilize it at least as much as the master we should never see unbounded lag 4
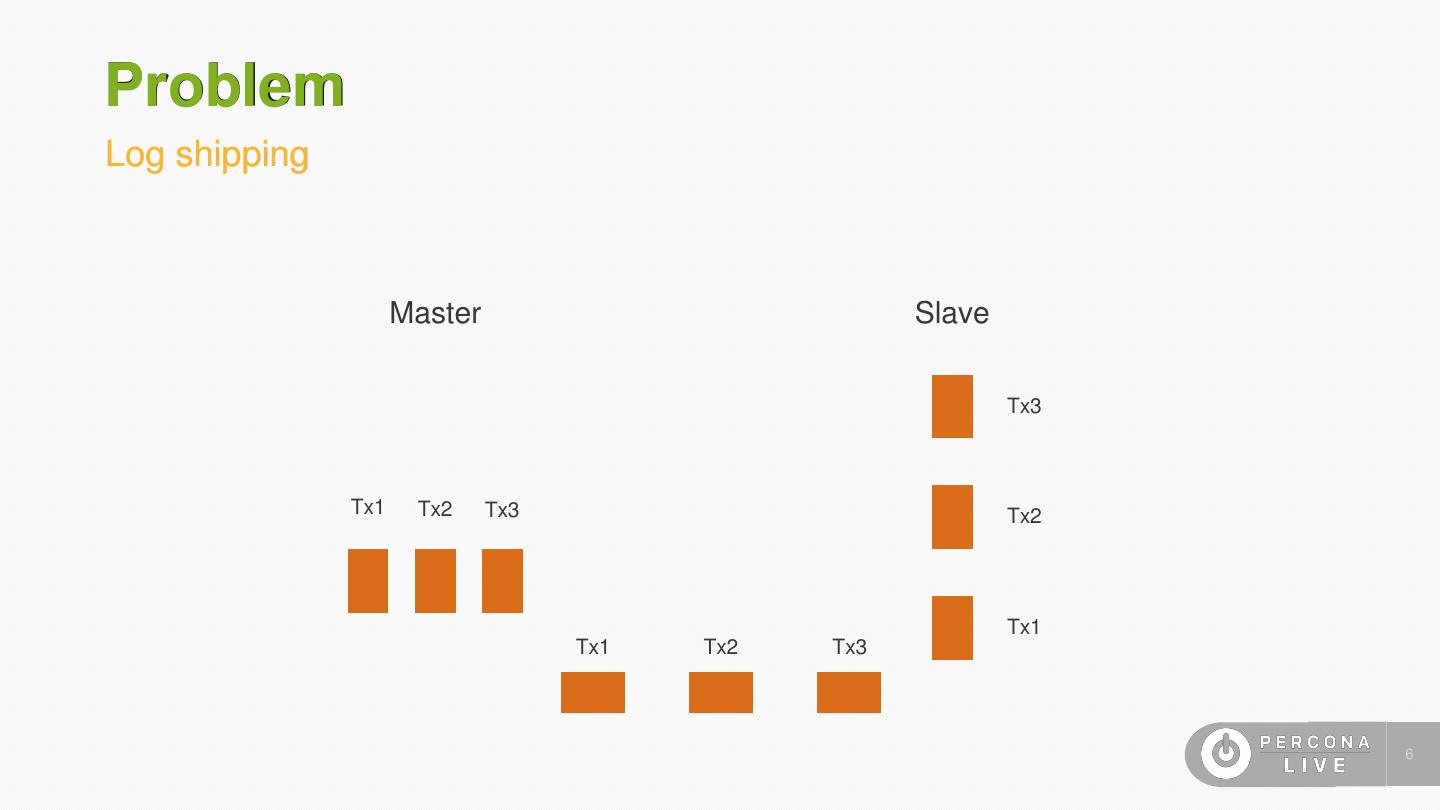
5 .Problem Log shipping • Parallel transactions on the master are serialized in a log • Slave sees a linear stream of transactions that it can apply one-by- one to obtain a serializable schedule • Master is multithreaded, slave is single threaded • Throughput differential causes unbounded lag 5
6 .Problem Log shipping Master Slave Tx3 Tx1 Tx2 Tx3 Tx2 Tx1 Tx1 Tx2 Tx3 6
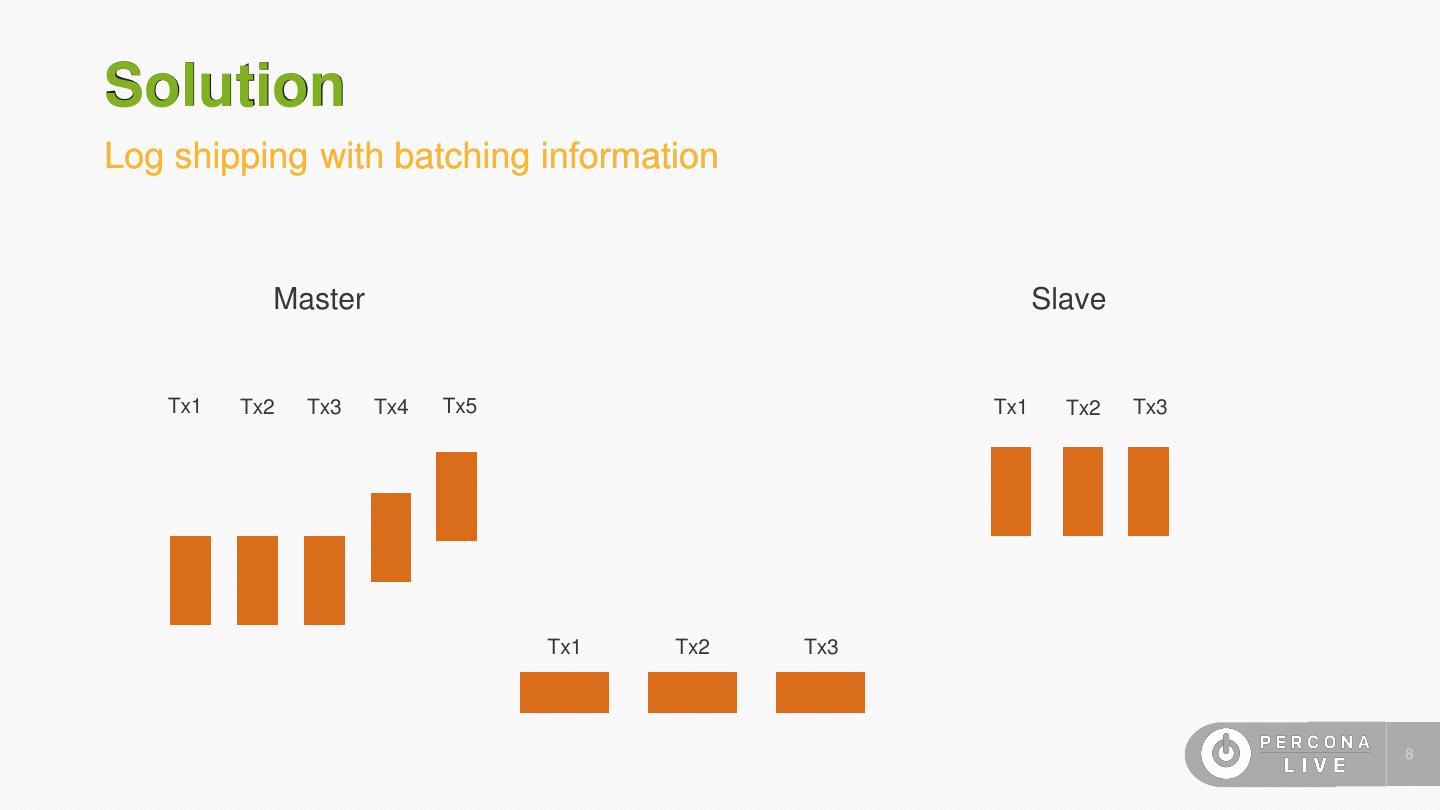
7 .Solution Log shipping with batching information • Record information about batching at the master in the log • Trivially, all transactions that commit together at the master can be executed in parallel on the slave (group commit) 7
8 .Solution Log shipping with batching information Master Slave Tx1 Tx2 Tx3 Tx4 Tx5 Tx1 Tx2 Tx3 Tx1 Tx2 Tx3 8
9 .Problem Log shipping with batching information • This still misses some independent transactions because we’re checking transactions that “committed” together not “executing” together • Batch size gets smaller with each hop in chain replication 9
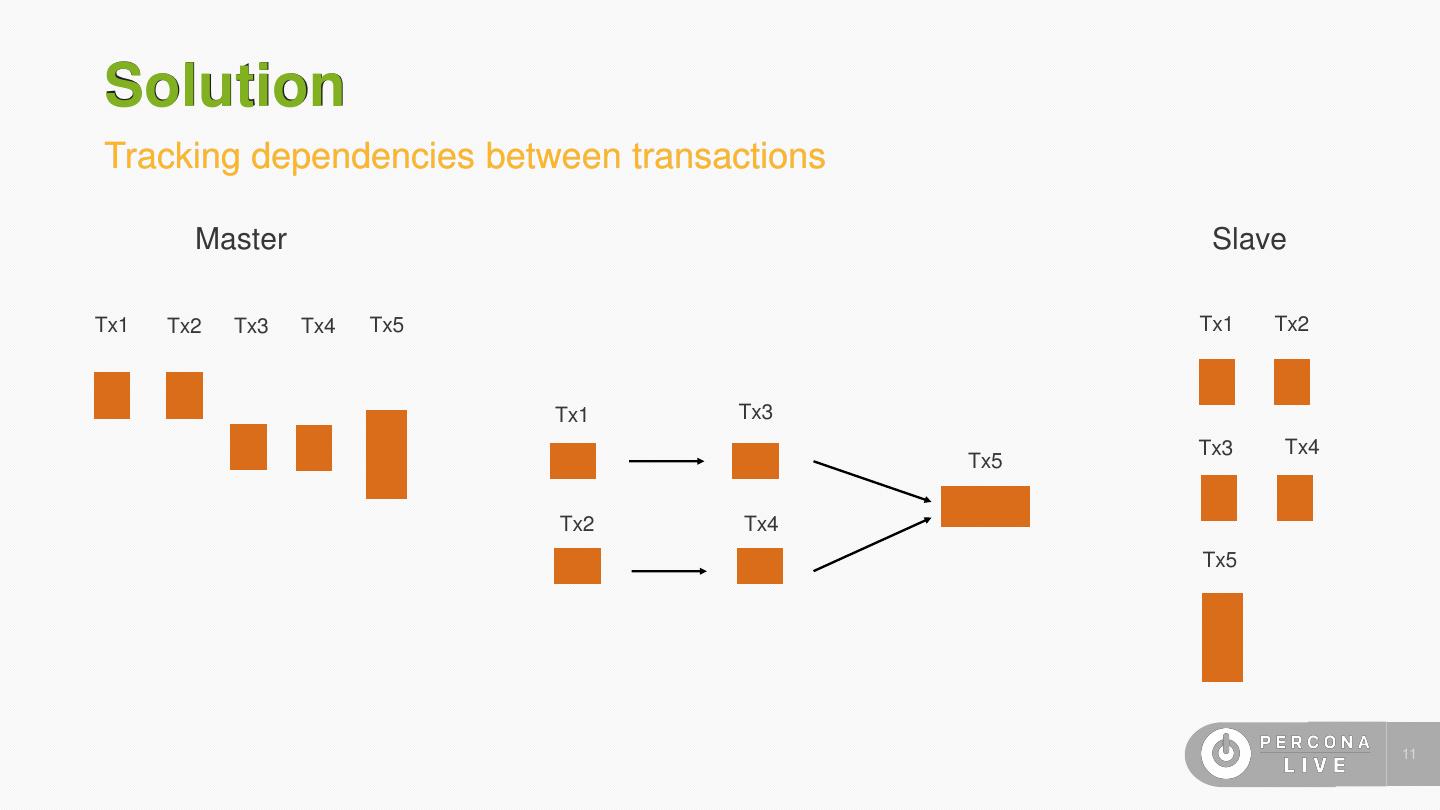
10 .Solution Tracking dependencies between transactions • By definition we just need to satisfy RW and WW conflicts • Logs are awesome for shipping but they’re one dimensional • Row based format of MySQL already has all the data required to find RW and WW conflicts! • Convert the log into a DAG of conflicts 10
11 .Solution Tracking dependencies between transactions Master Slave Tx1 Tx2 Tx3 Tx4 Tx5 Tx1 Tx2 Tx1 Tx3 Tx3 Tx4 Tx5 Tx2 Tx4 Tx5 11
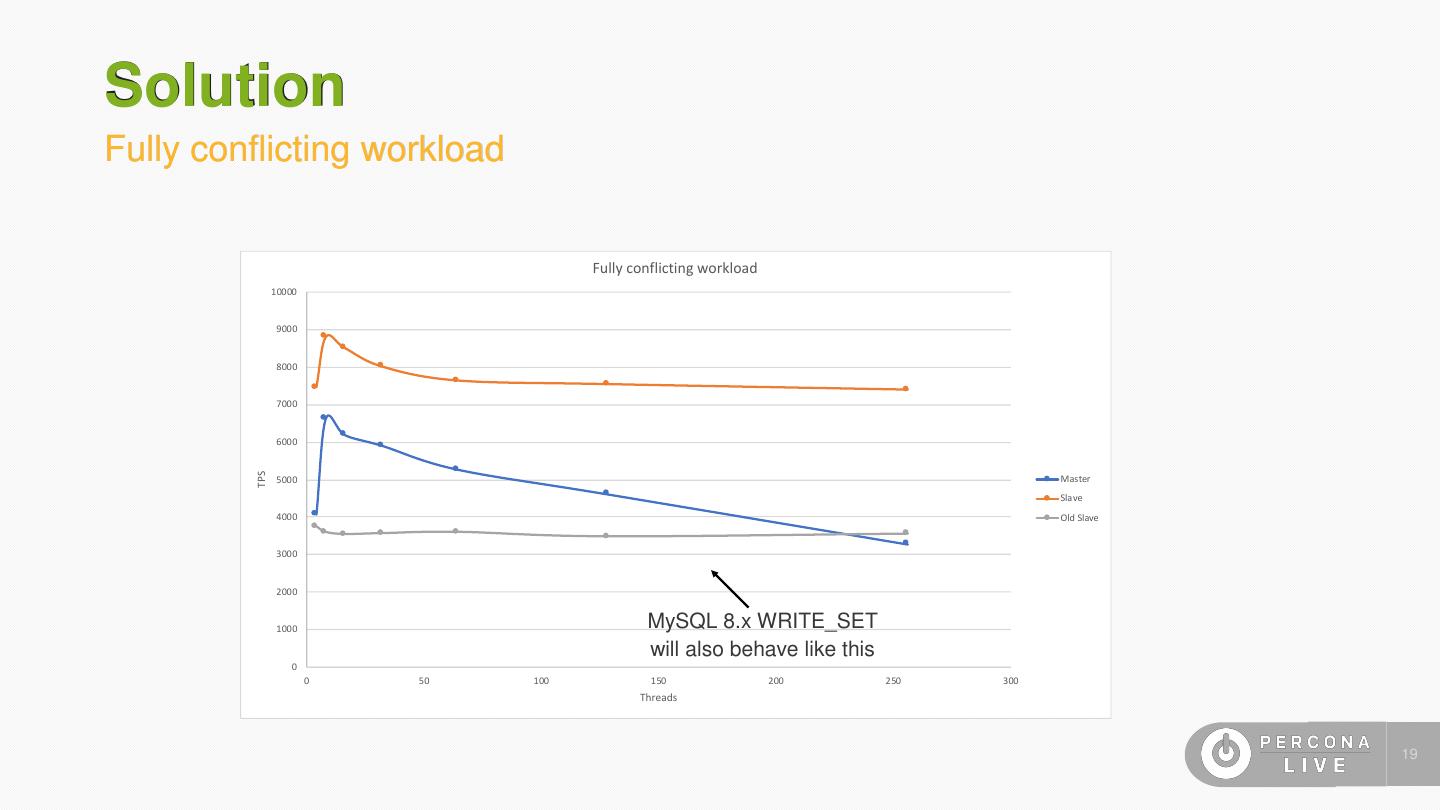
12 .Problem Tracking dependencies between transactions • Are we done? Not yet… • We’re serializing transactions even if a single row is common between them • On the master two conflicting transactions can run partially in parallel, on the slave we’re serializing them completely • Extreme example: A workload where all transactions conflict will be serialized on a single thread on the slave 12
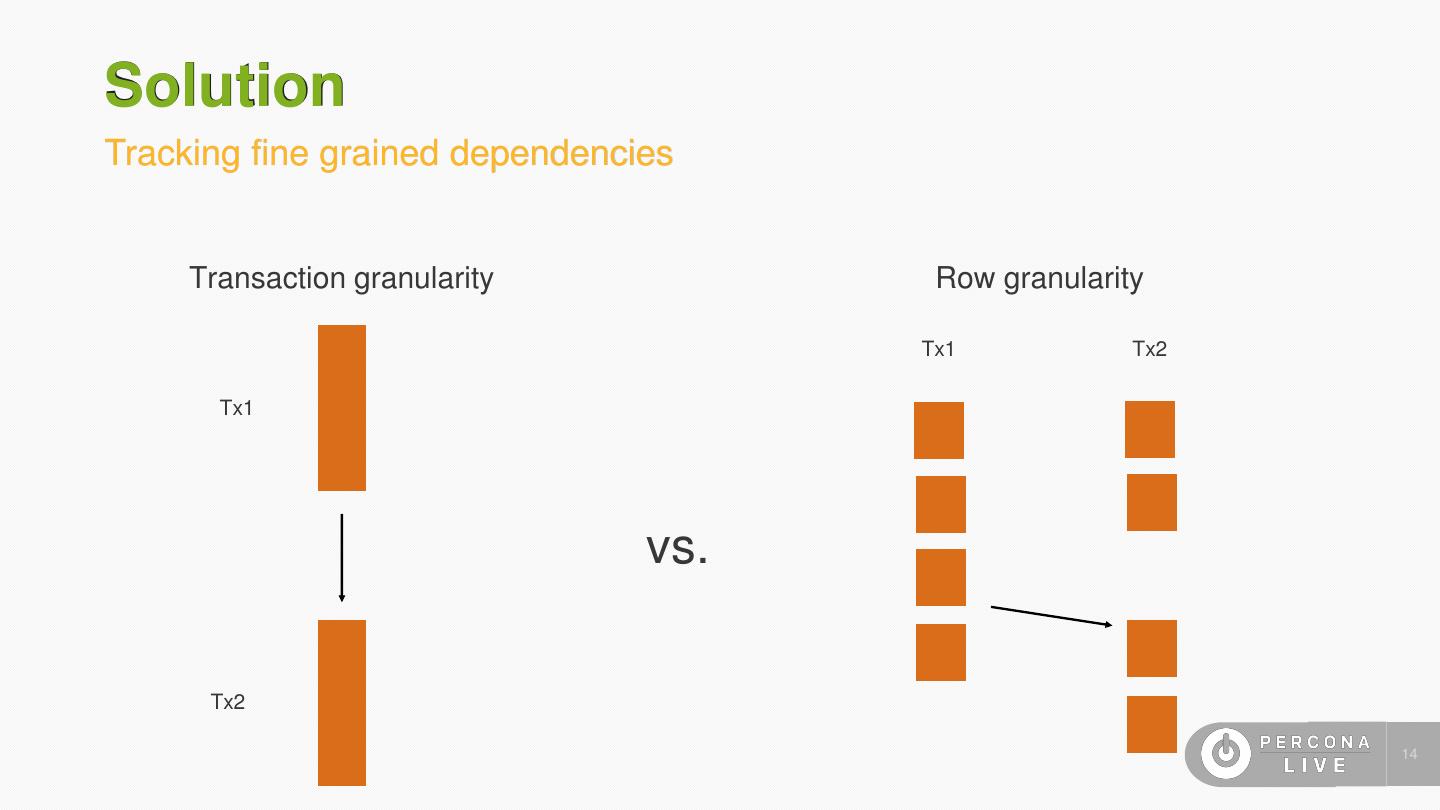
13 .Solution Tracking fine grained dependencies • Track conflicts between individual row events • Dispatch events to workers immediately and pause execution on the workers for conflicting events • It can be proved that this is a necessary and sufficient condition to achieve bounded lag 13
14 .Solution Tracking fine grained dependencies Transaction granularity Row granularity Tx1 Tx2 Tx1 vs. Tx2 14
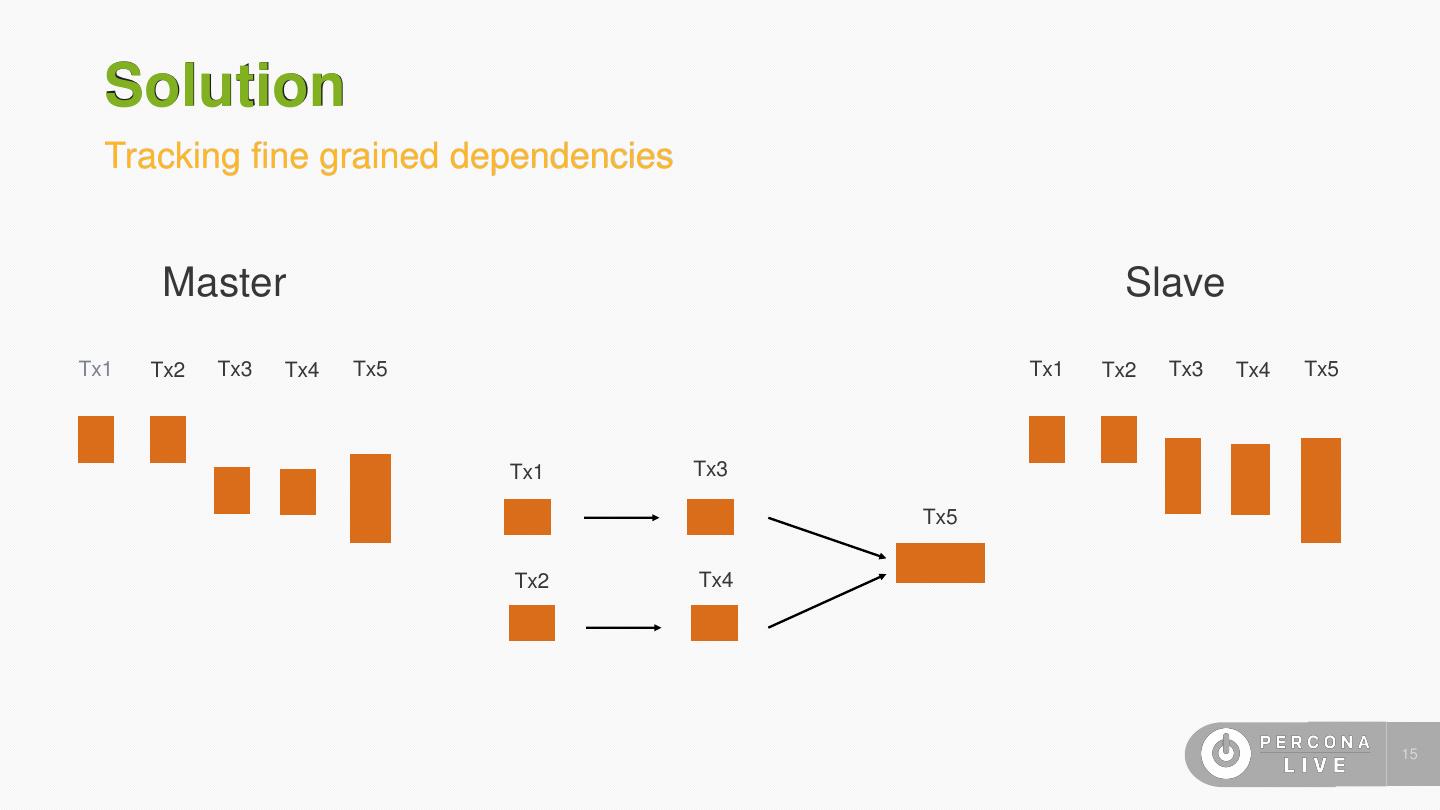
15 . Solution Tracking fine grained dependencies Master Slave Tx1 Tx2 Tx3 Tx4 Tx5 Tx1 Tx2 Tx3 Tx4 Tx5 Tx1 Tx3 Tx5 Tx2 Tx4 15
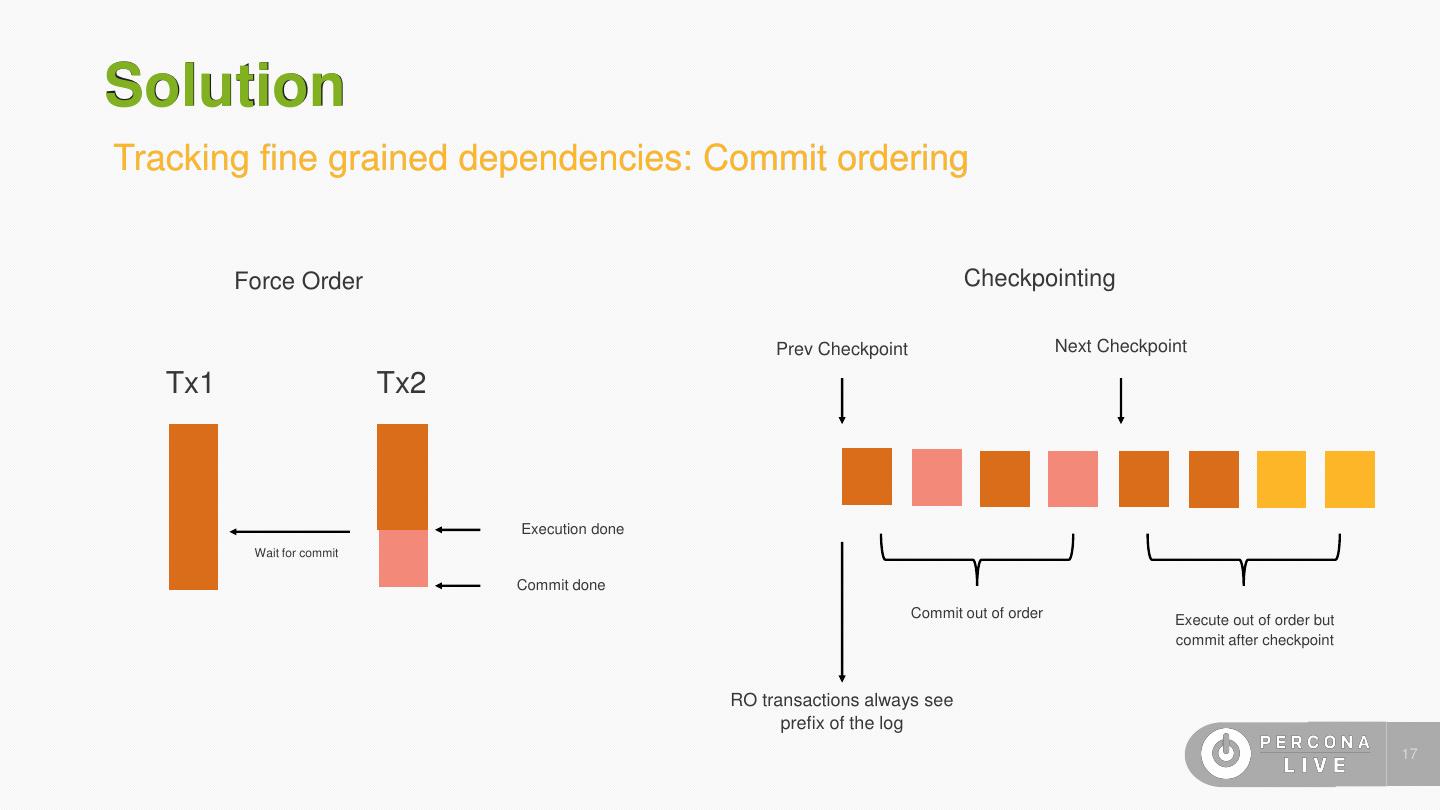
16 .Solution Tracking fine grained dependencies • What about ordering of commits? • Commit ordering is sometimes important for reads on the slave • Two ways to solve this: • Never commit a transaction before it’s preceding transaction is committed. Trivial, easy to implement but can increase commit latency • Commit out of order and take periodic checkpoints at a prefix of the log. All clients read from the checkpoint. Caveat: This will still produce slave logs that are out of order • If we treat commit order as a kind of conflict, the 1 st solution is analogous to conflict serializable and the 2nd to view serializable 16
17 .Solution Tracking fine grained dependencies: Commit ordering Force Order Checkpointing Prev Checkpoint Next Checkpoint Tx1 Tx2 Execution done Wait for commit Commit done Commit out of order Execute out of order but commit after checkpoint RO transactions always see prefix of the log 17
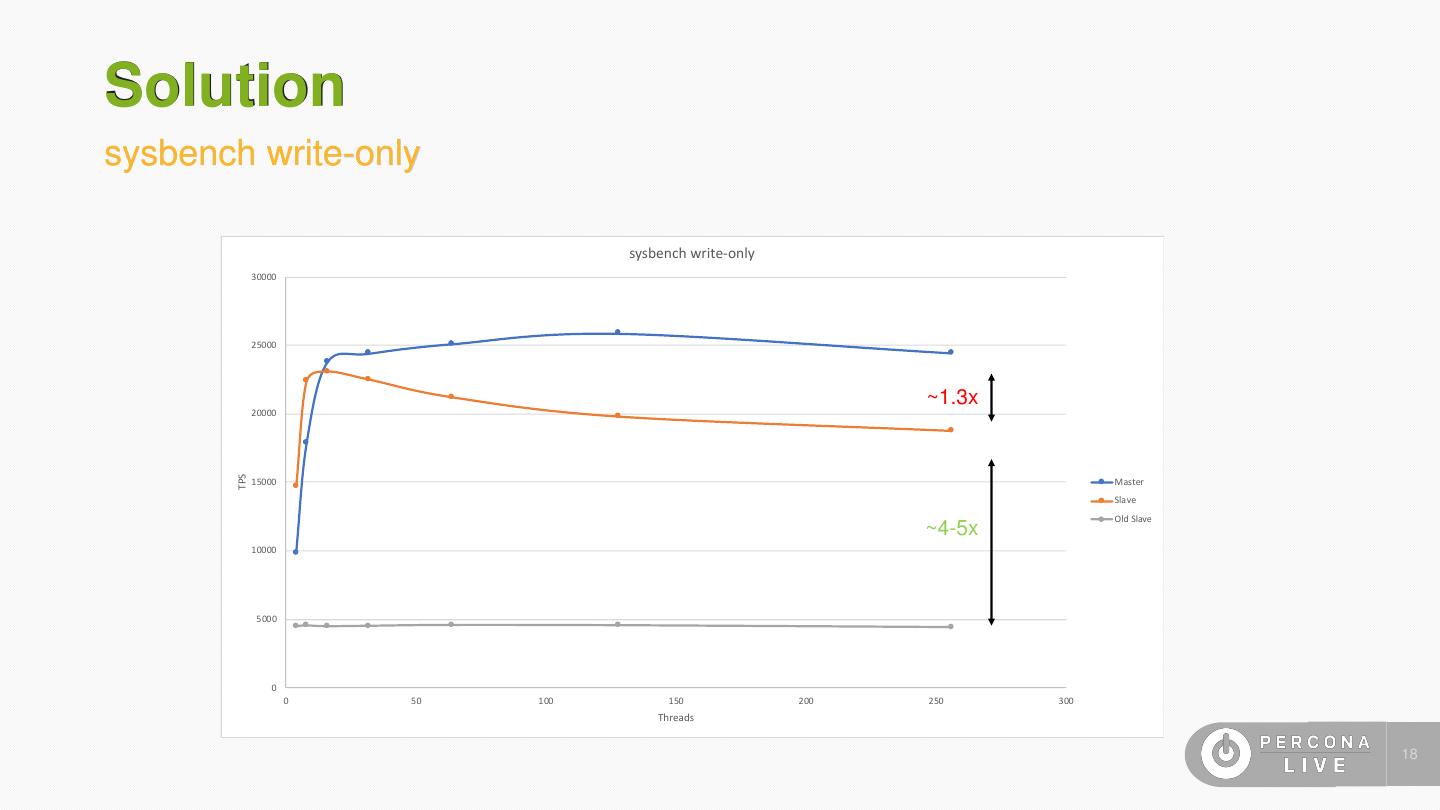
18 .Solution sysbench write-only sysbench write-only 30000 25000 ~1.3x 20000 TPS 15000 Master Slave Old Slave ~4-5x 10000 5000 0 0 50 100 150 200 250 300 Threads 18
19 .Solution Fully conflicting workload Fully conflicting workload 10000 9000 8000 7000 6000 TPS 5000 Master Slave 4000 Old Slave 3000 2000 1000 MySQL 8.x WRITE_SET will also behave like this 0 0 50 100 150 200 250 300 Threads 19
20 .Solution Tracking fine grained dependencies Can we do any better? Yes! • Eliminate 2PL • If replication workers are the only ones writing we can disable row locking altogether because we take care of conflicts explicitly • Replication threads will need to run in READ UNCOMMITTED isolation level • Rely on MVCC for consistent client reads • Transaction rewriting • Tx1: update tb1 set a = 2 where a = 1 • Tx2: update tb1 set a = 3 where a = 2 • Rewrite as Tx1 + Tx2: update tb1 set a = 3 where a = 1 20
21 .Problems Tracking fine grained dependencies Some implementation problems • Coordinator/scheduler is the bottleneck. Anything more we do to make transaction processing faster is useless right now • Unpacking row events to find keys is expensive • Interaction between IO and SQL thread make things worse 21
22 .MySQL 8.x WRITE_SET • MySQL 8.x supports WRITE_SET replication which uses transaction level dependencies extracted at the master • Workers are simple in WRITE_SET, both conflict detection and resolution happens in the coordinator • We use finer granularity than WRITE_SET and don’t sacrifice anything on the master • We also separate conflict detection (in the coordinator) and conflict resolution (in the workers) which allows better parallelization 22
23 .Future Plans • Getting the best of both worlds • Use WRITE_SET to give hints about dependencies • All independent transactions go straight to the workers • Parse out finer row dependencies only for conflicting transactions 23
24 .Resources Code: https://github.com/facebook/mysql-5.6 Relevant variables: • mts_dependency_replication = {NONE|TBL|STMT} • mts_dependency_order_commits = {0|1} • slave_tx_isolation = {keep it at READ-COMMITTED or lower} 24
25 .Rate My Session 25
3秒后跳转登录页面
去登陆

