























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Explaining the Postgres Query Optimizer
优化器是数据库的“大脑”,它解释SQL查询并确定最快的执行方法。本文使用explain命令来演示优化器如何解释查询并确定最佳执行。该演讲将帮助开发人员和管理员理解Postgres如何优化地执行其查询,以及他们可以采取哪些步骤来理解和改进其行为。
展开查看详情
1 . Explaining the Postgres Query Optimizer BRUCE MOMJIAN The optimizer is the "brain" of the database, interpreting SQL queries and determining the fastest method of execution. This talk uses the EXPLAIN command to show how the optimizer interprets queries and determines optimal execution. Creative Commons Attribution License http://momjian.us/presentations Last updated: September, 2018 1 / 56
2 . Postgres Query Execution User Terminal PostgreSQL Application Database Code Server Libpq Queries Results 2 / 56
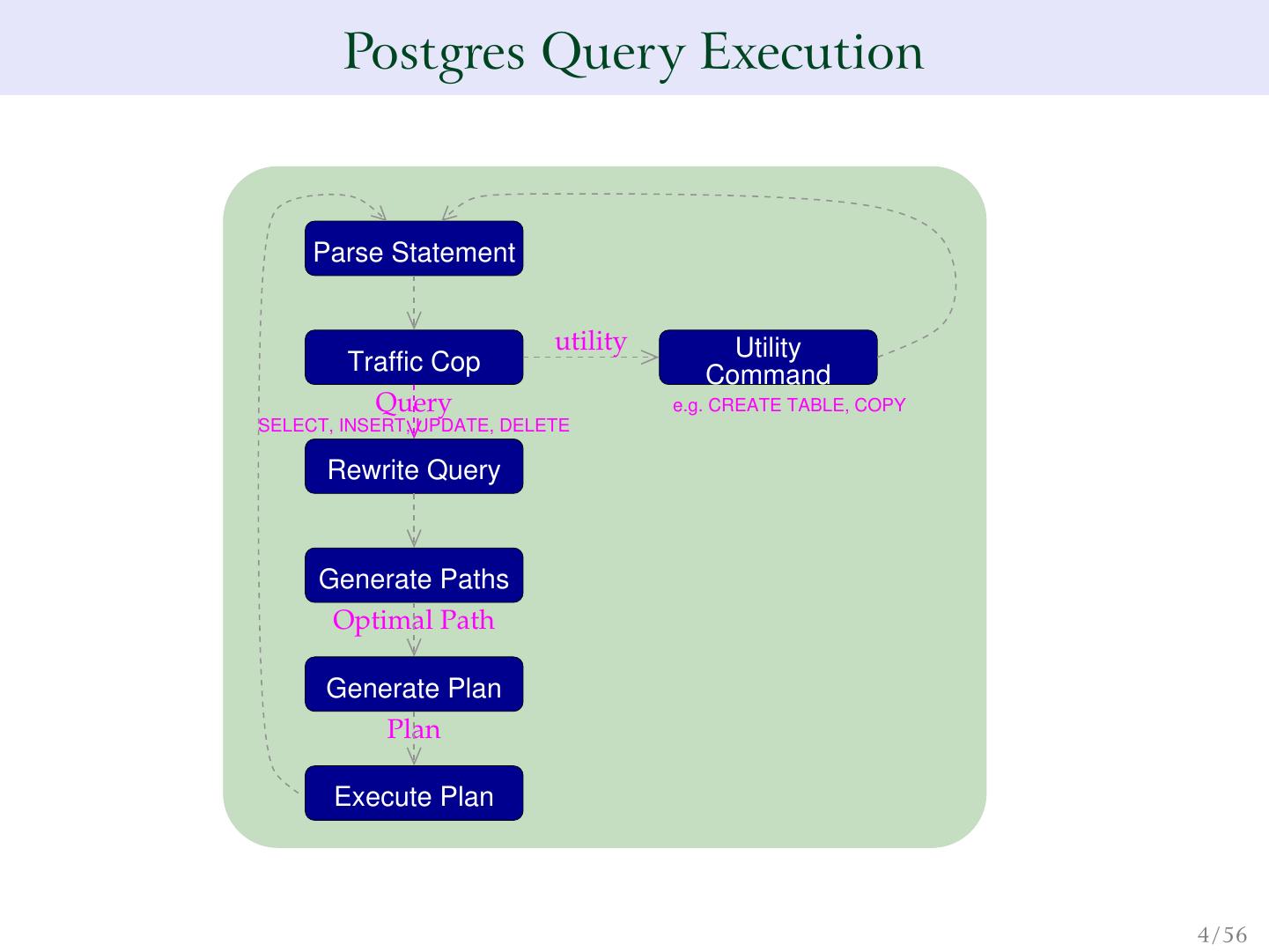
3 .Postgres Query Execution Main Libpq Postmaster Postgres Postgres Parse Statement utility Utility Traffic Cop Command Query e.g. CREATE TABLE, COPY SELECT, INSERT, UPDATE, DELETE Rewrite Query Generate Paths Optimal Path Generate Plan Plan Execute Plan Utilities Catalog Storage Managers Access Methods Nodes / Lists 3 / 56
4 . Postgres Query Execution Parse Statement utility Utility Traffic Cop Command Query e.g. CREATE TABLE, COPY SELECT, INSERT, UPDATE, DELETE Rewrite Query Generate Paths Optimal Path Generate Plan Plan Execute Plan 4 / 56
5 .The Optimizer Is the Brain https://www.flickr.com/photos/dierkschaefer/ 5 / 56
6 .What Decisions Does the Optimizer Have to Make? ◮ Scan Method ◮ Join Method ◮ Join Order 6 / 56
7 . Which Scan Method? ◮ Sequential Scan ◮ Bitmap Index Scan ◮ Index Scan 7 / 56
8 . A Simple Example Using pg_class.relname SELECT relname FROM pg_class ORDER BY 1 LIMIT 8; relname ----------------------------------- _pg_foreign_data_wrappers _pg_foreign_servers _pg_user_mappings administrable_role_authorizations applicable_roles attributes check_constraint_routine_usage check_constraints 8 / 56
9 .Let’s Use Just the First Letter of pg_class.relname SELECT substring(relname, 1, 1) FROM pg_class ORDER BY 1 LIMIT 8; substring ----------- _ _ _ a a a c c 9 / 56
10 . Create a Temporary Table with an Index CREATE TEMPORARY TABLE sample (letter, junk) AS SELECT substring(relname, 1, 1), repeat(’x’, 250) FROM pg_class ORDER BY random(); -- add rows in random order CREATE INDEX i_sample on sample (letter); All queries used in this presentation are available at http://momjian. us/main/writings/pgsql/optimizer.sql. 10 / 56
11 . Create an EXPLAIN Function CREATE OR REPLACE FUNCTION lookup_letter(text) RETURNS SETOF text AS $$ BEGIN RETURN QUERY EXECUTE ’ EXPLAIN SELECT letter FROM sample WHERE letter = ’’’ || $1 || ’’’’; END $$ LANGUAGE plpgsql; 11 / 56
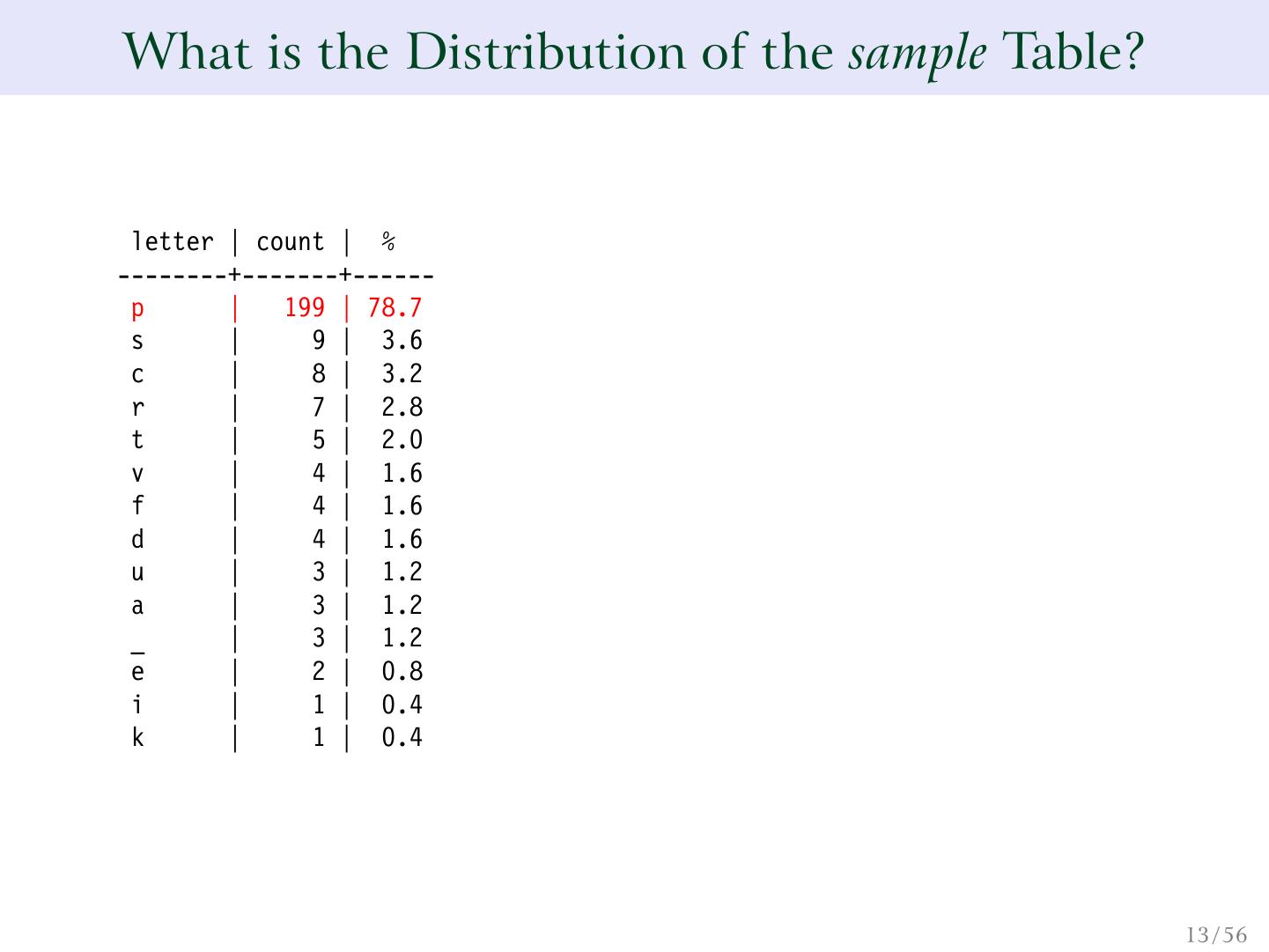
12 .What is the Distribution of the sample Table? WITH letters (letter, count) AS ( SELECT letter, COUNT(*) FROM sample GROUP BY 1 ) SELECT letter, count, (count * 100.0 / (SUM(count) OVER ()))::numeric(4,1) AS "%" FROM letters ORDER BY 2 DESC; 12 / 56
13 .What is the Distribution of the sample Table? letter | count | % --------+-------+------ p | 199 | 78.7 s | 9 | 3.6 c | 8 | 3.2 r | 7 | 2.8 t | 5 | 2.0 v | 4 | 1.6 f | 4 | 1.6 d | 4 | 1.6 u | 3 | 1.2 a | 3 | 1.2 _ | 3 | 1.2 e | 2 | 0.8 i | 1 | 0.4 k | 1 | 0.4 13 / 56
14 . Is the Distribution Important? EXPLAIN SELECT letter FROM sample WHERE letter = ’p’; QUERY PLAN ------------------------------------------------------------------------ Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=32) Index Cond: (letter = ’p’::text) 14 / 56
15 . Is the Distribution Important? EXPLAIN SELECT letter FROM sample WHERE letter = ’d’; QUERY PLAN ------------------------------------------------------------------------ Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=32) Index Cond: (letter = ’d’::text) 15 / 56
16 . Is the Distribution Important? EXPLAIN SELECT letter FROM sample WHERE letter = ’k’; QUERY PLAN ------------------------------------------------------------------------ Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=32) Index Cond: (letter = ’k’::text) 16 / 56
17 . Running ANALYZE Causes a Sequential Scan for a Common Value ANALYZE sample; EXPLAIN SELECT letter FROM sample WHERE letter = ’p’; QUERY PLAN --------------------------------------------------------- Seq Scan on sample (cost=0.00..13.16 rows=199 width=2) Filter: (letter = ’p’::text) Autovacuum cannot ANALYZE (or VACUUM) temporary tables because these tables are only visible to the creating session. 17 / 56
18 . Sequential Scan Heap D D D D D D D D D D D D A A A A A A A A A A A A T T T T T T T T T T T T A A A A A A A A A A A A 8K 18 / 56
19 .A Less Common Value Causes a Bitmap Index Scan EXPLAIN SELECT letter FROM sample WHERE letter = ’d’; QUERY PLAN ----------------------------------------------------------------------- Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) Recheck Cond: (letter = ’d’::text) -> Bitmap Index Scan on i_sample (cost=0.00..4.28 rows=4 width=0) Index Cond: (letter = ’d’::text) 19 / 56
20 . Bitmap Index Scan Index 1 Index 2 Combined Table col1 = ’A’ col2 = ’NS’ Index 0 0 0 ’A’ AND ’NS’ 1 1 1 & = 0 1 0 1 0 0 20 / 56
21 . An Even Rarer Value Causes an Index Scan EXPLAIN SELECT letter FROM sample WHERE letter = ’k’; QUERY PLAN ----------------------------------------------------------------------- Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) Index Cond: (letter = ’k’::text) 21 / 56
22 . Index Scan Index < Key = > < Key = > < Key = > Heap D D D D D D D D D D D D A A A A A A A A A A A A T T T T T T T T T T T T A A A A A A A A A A A A 22 / 56
23 . Let’s Look at All Values and their Effects WITH letter (letter, count) AS ( SELECT letter, COUNT(*) FROM sample GROUP BY 1 ) SELECT letter AS l, count, lookup_letter(letter) FROM letter ORDER BY 2 DESC; l | count | lookup_letter ---+-------+----------------------------------------------------------------------- p | 199 | Seq Scan on sample (cost=0.00..13.16 rows=199 width=2) p | 199 | Filter: (letter = ’p’::text) s | 9 | Seq Scan on sample (cost=0.00..13.16 rows=9 width=2) s | 9 | Filter: (letter = ’s’::text) c | 8 | Seq Scan on sample (cost=0.00..13.16 rows=8 width=2) c | 8 | Filter: (letter = ’c’::text) r | 7 | Seq Scan on sample (cost=0.00..13.16 rows=7 width=2) r | 7 | Filter: (letter = ’r’::text) … 23 / 56
24 . OK, Just the First Lines WITH letter (letter, count) AS ( SELECT letter, COUNT(*) FROM sample GROUP BY 1 ) SELECT letter AS l, count, (SELECT * FROM lookup_letter(letter) AS l2 LIMIT 1) AS lookup_letter FROM letter ORDER BY 2 DESC; 24 / 56
25 . Just the First EXPLAIN Lines l | count | lookup_letter ---+-------+----------------------------------------------------------------------- p | 199 | Seq Scan on sample (cost=0.00..13.16 rows=199 width=2) s | 9 | Seq Scan on sample (cost=0.00..13.16 rows=9 width=2) c | 8 | Seq Scan on sample (cost=0.00..13.16 rows=8 width=2) r | 7 | Seq Scan on sample (cost=0.00..13.16 rows=7 width=2) t | 5 | Bitmap Heap Scan on sample (cost=4.29..12.76 rows=5 width=2) f | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) v | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) d | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) a | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) _ | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) u | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) e | 2 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) i | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) k | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) 25 / 56
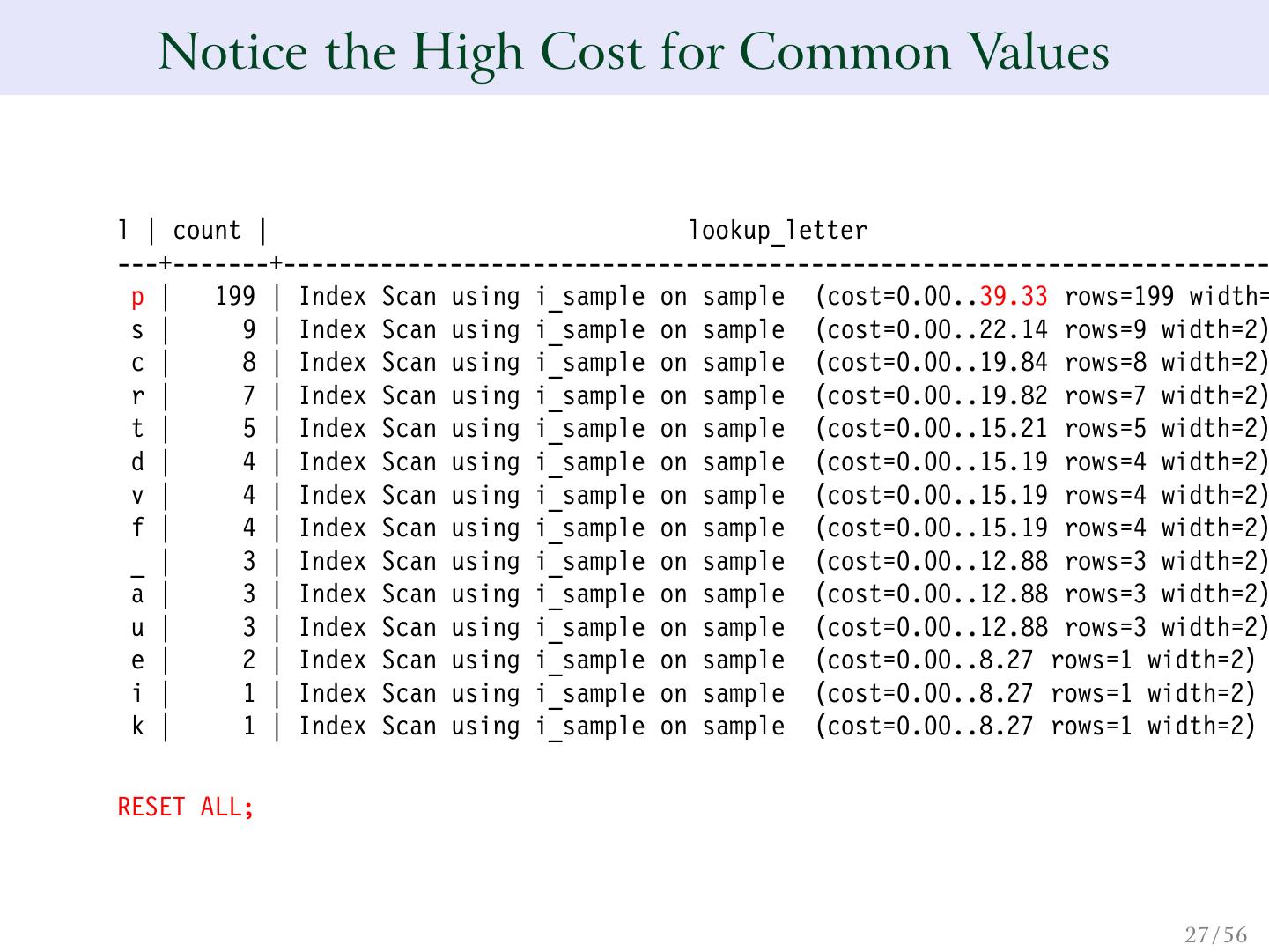
26 . We Can Force an Index Scan SET enable_seqscan = false; SET enable_bitmapscan = false; WITH letter (letter, count) AS ( SELECT letter, COUNT(*) FROM sample GROUP BY 1 ) SELECT letter AS l, count, (SELECT * FROM lookup_letter(letter) AS l2 LIMIT 1) AS lookup_letter FROM letter ORDER BY 2 DESC; 26 / 56
27 . Notice the High Cost for Common Values l | count | lookup_letter ---+-------+----------------------------------------------------------------------- p | 199 | Index Scan using i_sample on sample (cost=0.00..39.33 rows=199 width= s | 9 | Index Scan using i_sample on sample (cost=0.00..22.14 rows=9 width=2) c | 8 | Index Scan using i_sample on sample (cost=0.00..19.84 rows=8 width=2) r | 7 | Index Scan using i_sample on sample (cost=0.00..19.82 rows=7 width=2) t | 5 | Index Scan using i_sample on sample (cost=0.00..15.21 rows=5 width=2) d | 4 | Index Scan using i_sample on sample (cost=0.00..15.19 rows=4 width=2) v | 4 | Index Scan using i_sample on sample (cost=0.00..15.19 rows=4 width=2) f | 4 | Index Scan using i_sample on sample (cost=0.00..15.19 rows=4 width=2) _ | 3 | Index Scan using i_sample on sample (cost=0.00..12.88 rows=3 width=2) a | 3 | Index Scan using i_sample on sample (cost=0.00..12.88 rows=3 width=2) u | 3 | Index Scan using i_sample on sample (cost=0.00..12.88 rows=3 width=2) e | 2 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) i | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) k | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) RESET ALL; 27 / 56
28 . This Was the Optimizer’s Preference l | count | lookup_letter ---+-------+----------------------------------------------------------------------- p | 199 | Seq Scan on sample (cost=0.00..13.16 rows=199 width=2) s | 9 | Seq Scan on sample (cost=0.00..13.16 rows=9 width=2) c | 8 | Seq Scan on sample (cost=0.00..13.16 rows=8 width=2) r | 7 | Seq Scan on sample (cost=0.00..13.16 rows=7 width=2) t | 5 | Bitmap Heap Scan on sample (cost=4.29..12.76 rows=5 width=2) f | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) v | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) d | 4 | Bitmap Heap Scan on sample (cost=4.28..12.74 rows=4 width=2) a | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) _ | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) u | 3 | Bitmap Heap Scan on sample (cost=4.27..11.38 rows=3 width=2) e | 2 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) i | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) k | 1 | Index Scan using i_sample on sample (cost=0.00..8.27 rows=1 width=2) 28 / 56
29 . Which Join Method? ◮ Nested Loop ◮ With Inner Sequential Scan ◮ With Inner Index Scan ◮ Hash Join ◮ Merge Join 29 / 56
3秒后跳转登录页面
去登陆

