









































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
pg_chameleon
pg_Chameleon是一个用python编写的轻量级复制系统。该工具可以连接到MySQL复制协议并复制PostgreSQL中的数据更改。
无论用户是需要在mysql和postgresql之间建立一个永久的副本,还是需要执行引擎迁移,pg_chameleon都是该作业的完美工具。
会谈将涵盖历史、当前实现和未来版本。
观众将通过几个简单的步骤学习如何建立从mysql到postgresql的副本。此外,还将介绍工具开发周期中的经验教训和一个小型演示。
展开查看详情
1 .pg_chameleon Federico Campoli Loxodata
2 .Few words about the speaker • Born in 1972 • Passionate about IT since 1982 • Joined the Oracle DBA secret society in 2004 • In love with PostgreSQL since 2006 • PostgreSQL tattoo on the right shoulder • Works at Loxodata as PostgreSQL Consultant 2
3 .Loxodata • A company built on 3 pillars 3
4 .Loxodata • A comprehensive service offer 4
5 .Agenda • History • The MySQL Replica • pg_chameleon v2.0 • The replica in action • Demo • Wrap up 5
6 . History How the project began
7 .The beginning • Years 2006/2012 neo_my2pg.py ⚫ I wrote the script because of a struggling phpbb on MySQL ⚫ The script is written in python 2.6 ⚫ It's a monolith script ⚫ And it's slow, very slow ⚫ It's a good checklist for things to avoid when coding ⚫ https://github.com/the4thdoctor/neo_my2pg 7
8 .I'm not scared of using the ORMs • Years 2013/2015 first attempt of pg_chameleon ⚫ Developed in Python 2.7 ⚫ Used SQLAlchemy for extracting the MySQL's metadata ⚫ Proof of concept only ⚫ It was a just a way to discharge frustration ⚫ Abandoned after a while ⚫ SQLAlchemy's limitations were frustrating as well ⚫ And pgloader did the same job much much better 8
9 .pg_chameleon reborn • Year 2016 ⚫ I needed to replicate the data from MySQL to PostgreSQL ⚫ http://tech.transferwise.com/scaling-our-analytics-database ⚫ The amazing library python-mysql-replication allowed me build a proof of concept ⚫ Which evolved later in pg_chameleon 1.x • Kudos to the python-mysql-replication team! • https://github.com/noplay/python-mysql-replication 9
10 .pg_chameleon v1.x ⚫ Developed on the London to Brighton commute ⚫ Released as stable the 7th May 2017 ⚫ Followed by 8 bugfix releases\pause ⚫ Compatible with CPython 2.7/3.3+ ⚫ No more SQLAlchemy ⚫ The MySQL driver changed from MySQLdb to PyMySQL ⚫ Command line helper ⚫ Supports type override on the fly (Danger!) ⚫ Installs in virtualenv and system wide via pypi ⚫ Can detach the replica for minimal downtime migrations 10
11 .pg_chameleon v1.x limitations ⚫ All the affected tables are locked in read only mode during the init_replica process ⚫ During the init_replica the data is not accessible ⚫ The tables for being replicated require primary keys ⚫ No daemon, the process always stays in foreground ⚫ Single schema replica ⚫ One process per each schema ⚫ Network inefficient ⚫ Read and replay not concurrent with risk of high lag ⚫ The optional threaded mode very inefficient and fragile ⚫ A single error in the replay process and the replica is broken ⚫ 11
12 .The MySQL replica Do I really need to do that?
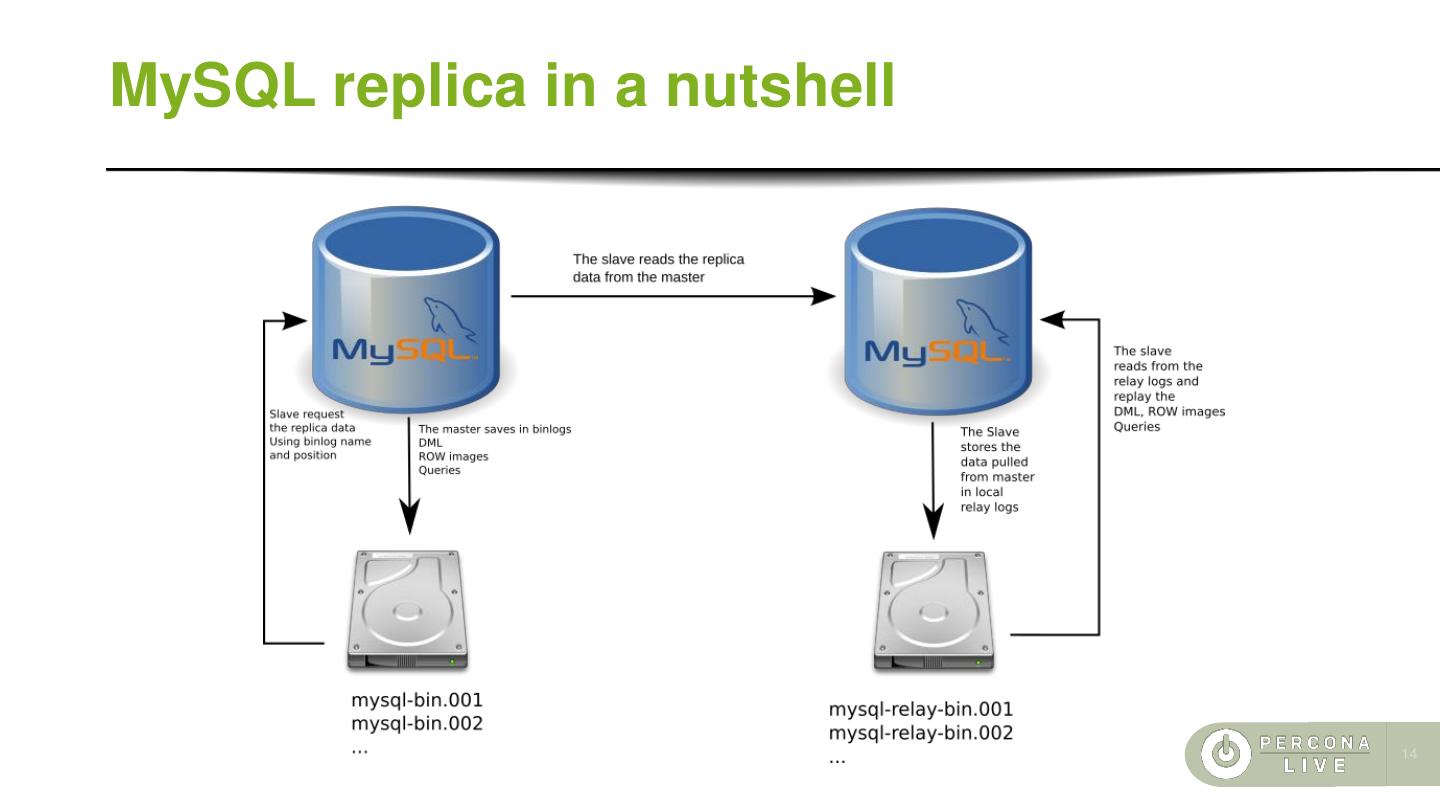
13 .MySQL replica in a nutshell ⚫ The MySQL replica is logical ⚫ When the replica is enabled the data changes are stored in the master's binary log files ⚫ The slave gets from the master's binary log files ⚫ The slave saves the stream of data into local relay logs ⚫ The relay logs are replayed against the slave ⚫ 13
14 .MySQL replica in a nutshell 14
15 .The log formats ⚫ MySQL can store the changes in the binary logs in three different formats ⚫ STATEMENT: It logs the statements which are replayed on the slave It's the best solution for the bandwidth. However, when replaying statements with not deterministic functions this format generates different values on the slave (e.g. using an insert with a column autogenerated by the uuid function). ⚫ ROW: It's deterministic. This format logs the row images. ⚫ MIXED takes the best of both worlds. The master logs the statements unless a not deterministic function is used. In that case it logs the row image. ⚫ All three formats always log the DDL query events. ⚫ The python-mysql-replication library used by pg_chameleon require the ROW format to work properly. 15
16 .pg_chameleon v2.0 Overview of the stable release
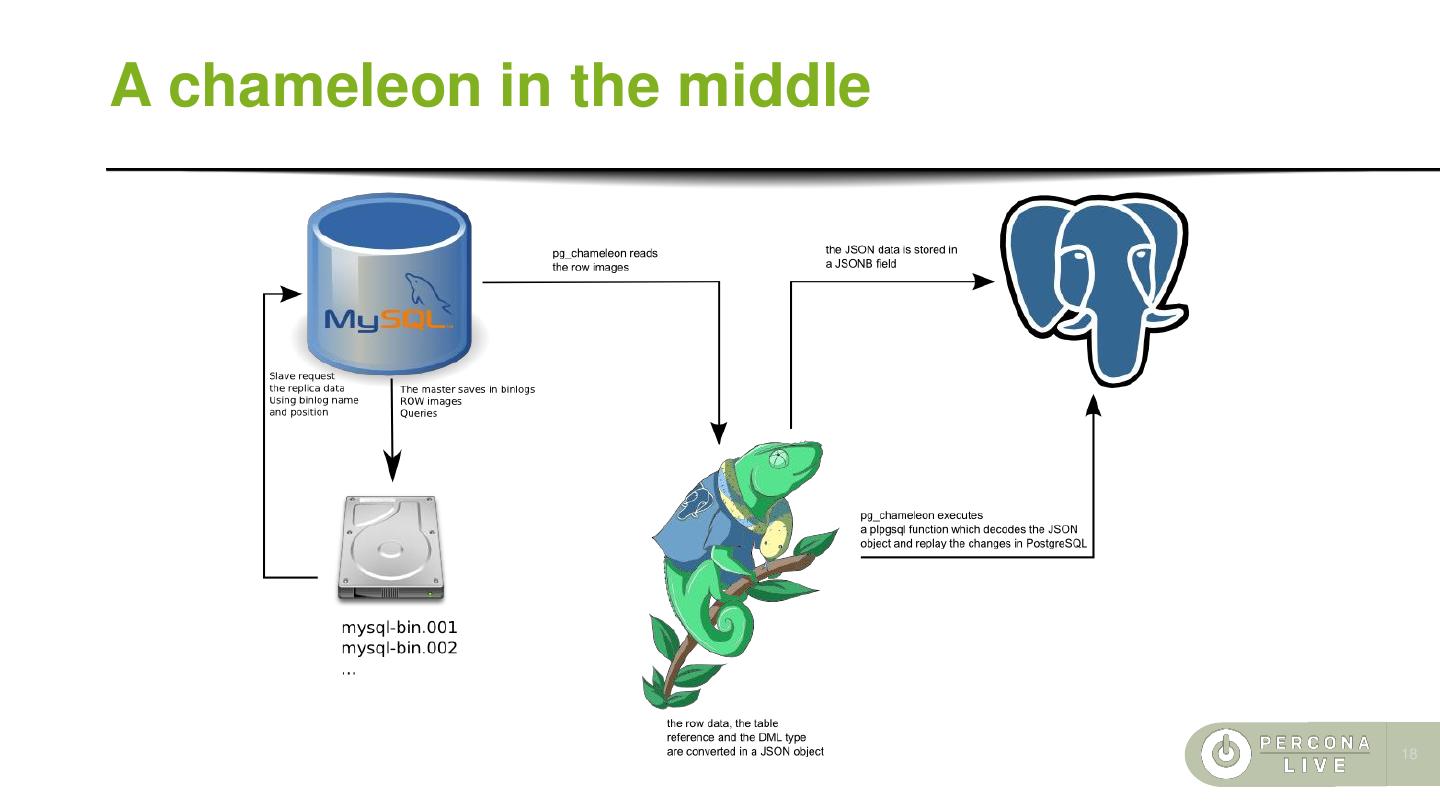
17 .A chameleon in the middle ⚫ pg_chameleon mimics a mysql slave's behaviour ⚫ It performs the initial load for the replicated tables ⚫ It connects to the MySQL replica protocol ⚫ It stores the row images into a PostgreSQL table ⚫ A plpgSQL function decodes the rows and replay the changes ⚫ It can detach the replica for minimal downtime migrations ⚫ PostgreSQL acts as relay log and replication slave 17
18 .A chameleon in the middle 18
19 .pg_chameleon v2.0 ⚫ Developed at the pgconf.eu 2017 and on the commute ⚫ Released as stable the 1st of January 2018 ⚫ Compatible with python 3.3+ ⚫ Installs in virtualenv and system wide via pypi ⚫ Replicates multiple schemas from a single MySQL into a target PostgreSQL database ⚫ Conservative approach to the replica. Tables which generate errors are automatically excluded from the replica ⚫ Daemonised replica process with two distinct subprocesses, for concurrent read and replay 19
20 .pg_chameleon v2.0 ⚫ Soft locking replica initialisation. The tables are locked only during the copy. ⚫ Rollbar integration for a simpler error detection and messaging ⚫ Experimental support for the PostgreSQL source type ⚫ The tables are loaded in a separate schema which is swapped with the existing. ⚫ This approach requires more space but it makes the init a replica virtually painless, leaving the old data accessible until the init_replica is complete. ⚫ The DDL are translated in the PostgreSQL dialect keeping the schema in sync with MySQL automatically ⚫ MySQL GTID support for switch across the replica cluster without need for init_replica 20
21 .pg_chameleon v2.0 limitations ⚫ The tables for being replicated require primary or unique keys ⚫ When detaching the replica the foreign keys are created always ON DELETE/UPDATE RESTRICT ⚫ The source type PostgreSQL supports only the init_replica process ⚫ Problems on Amazon RDS with the json data type ⚫ No support for MariaDB’s GTID 21
22 .The replica in action Lets configure the replica for our example
23 .Replica initialisation ⚫ The replica initialisation follows the same workflow as stated on the mysql online manual. ⚫ Flush the tables with read lock ⚫ Get the master's coordinates ⚫ Copy the data ⚫ Release the locks However...pg_chameleon flushes the tables with read lock one by one. The lock is held only during the copy. The log coordinates are stored in the replica catalogue along the table's name and used by the replica process to determine whether the table's binlog data should be used or not. 23
24 .Fallback on failure The data is pulled from mysql using the CSV format in slices. This approach prevents the memory overload. Once the file is saved then is pushed into PostgreSQL using the COPY command. However... ⚫ COPY is fast but is single transaction ⚫ One failure and the entire batch is rolled back ⚫ If this happens the procedure loads the same data using the INSERT statements ⚫ Which can be very slow ⚫ The process attempts to clean the NUL markers which are allowed by MySQL ⚫ If the row still fails on insert then it's discarded 24
25 .MySQL configuration The mysql configuration file on linux is usually stored in /etc/mysql/my.cnf To enable the binary logging find the section [mysqld] and check that the following parameters are set. binlog_format= ROW log-bin = mysql-bin server-id = 1 binlog-row-image = FULL 25
26 .MySQL database user Setup a MySQL database user for the replica CREATE USER usr_replica ; SET PASSWORD FOR usr_replica=PASSWORD('replica'); GRANT ALL ON sakila.* TO 'usr_replica'; GRANT RELOAD ON *.* to 'usr_replica'; GRANT REPLICATION CLIENT ON *.* to 'usr_replica'; GRANT REPLICATION SLAVE ON *.* to 'usr_replica'; FLUSH PRIVILEGES; 26
27 .PostgreSQL database user Setup a PostgreSQL database user and a database owned by the freshly created user CREATE USER usr_replica WITH PASSWORD 'replica'; CREATE DATABASE db_replica WITH OWNER usr_replica; 27
28 .Install pg_chameleon Install pg_chameleon and create the configuration files. Edit the file default.yml and set the correct values for connection and source. pip install pip --upgrade pip install pg_chameleon chameleon set_configuration_files cd ~/.pg_chameleon/configuration cp config-example.yml default.yml 28
29 .Global settings pg_conn: host: "localhost" port: "5432" user: "usr_replica" password: "replica" database: "db_replica" charset: "utf8" rollbar_key: '<rollbar_long_key>' rollbar_env: 'demo' type_override: "tinyint(1)": override_to: boolean override_tables: - "*" 29
3秒后跳转登录页面
去登陆

