
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Time Series Data in MongoDB on a Budget
您需要在MongoDB中存储和保留时间序列数据,而HDD不能跟上您的插入速度,但您不能负担得起将所有数据都保存在SSD上的费用?那么这个演示文稿就是给你的。您将学习如何使用切分和切分标记将插入内容和最新数据保存在快速SSD上,将存档数据保存在廉价HDD上,以及如何快速高效地将数据从SSD转换为HDD。您还将学习添加时序数据和以流的形式访问数据而不丢失任何数据点的最佳编程技术。
展开查看详情
1 . Time-Series Data in MongoDB on a Budget Peter Schwaller – Senior Director Server Engineering, Percona
2 .TIME SERIES DATA in MongoDB on a Budget Click to add text
3 .What is Time-Series Data? Characteristics: • Arriving data is stored as a new value as opposed to overwriting existing values • Usually arrives in time order • Accumulated data size grows over time • Time is the primary means of organizing/accessing the data 3
4 .Time Series Data in MONGODB on a Budget Click to add text
5 .Why MongoDB? • General purpose database • Specialized Time-Series DBs do exist • Do not use mmap storage engine 5
6 .Data Retention Options • Purge old entries • Set up MongoDB index with TTL option (be careful if this index is your shard key) • Aggregate data and store summaries • Create summary document, delete original raw data • Huge compression possible (seconds->minutes->hours->days->months->years) • Measurement buckets • Store all entries for a time window in a single document • Avoids storing duplicate metadata • Individual Documents for Each Measurement • Useful when data is sparse or intermittent (e.g., events rather than sensors) 6
7 .Potential Problems with Data Collection • Duplicate entries • Utilize unique index in MongoDB to reject duplicate entries • Delayed • Out of order 7
8 .Problems with Delayed and Out-of-Order Entries • Alert/Event generation • Incremental Backup 8
9 .Enable Streaming of Data • Add recordedTime field (in addition to existing field with timestamp) • Utilize $currentDate feature of db.collection.update() $currentDate: { recordedTime: true } • You cannot use this field as a shard key! • Requires use of update instead of insert • Which in turn requires specification of _id field • Consider constructing your _id to solve the duplicate entries issue at the same time Allows applications to reliably process each document once and only once. 9
10 .Accessing Your Data It’s only *mostly* write-only.
11 .Create Appropriate Indexes • Avoid collection scans! • Consider using: db.adminCommand( { setParameter: 1, notablescan: 1 } ) • Avoid queries that might as well be collection scans • Create the indexes you need (but no more) • Don’t depend on index intersection • Don’t over index • Each index can take up a lot of disk/memory • Consider using partial indexes { partialFilterExpression: { speed: { $gt: 75.0 } } } 11
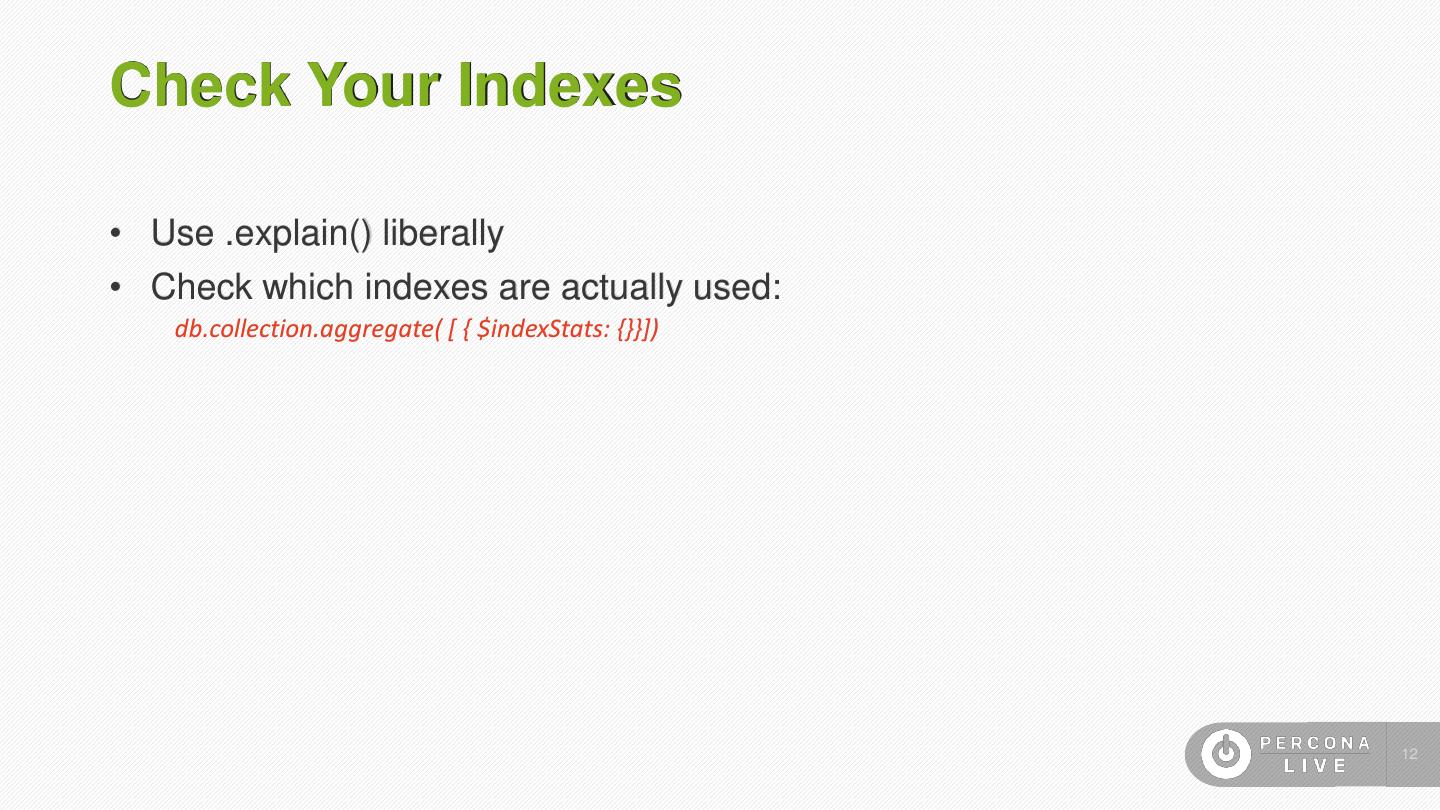
12 .Check Your Indexes • Use .explain() liberally • Check which indexes are actually used: db.collection.aggregate( [ { $indexStats: {}}]) 12
13 .Adding Data Getting the Speed You Need
14 .API Methods • Insert array database[collection].insert(doc_array) • Insert unordered bulk bulk = database[collection].initialize_unordered_bulk_op() bulk.insert(doc) # loop here bulk.execute() • Upsert unordered bulk bulk = database[collection].initialize_unordered_bulk_op() bulk.find({"_id": doc["_id"]}).upsert().update_one({"$set": doc}) # loop here bulk.execute() • Insert single database[collection].insert(doc) • Upsert single database[collection].update_one({"_id": doc["_id"]}, {"$set": doc}, upsert=True) 14
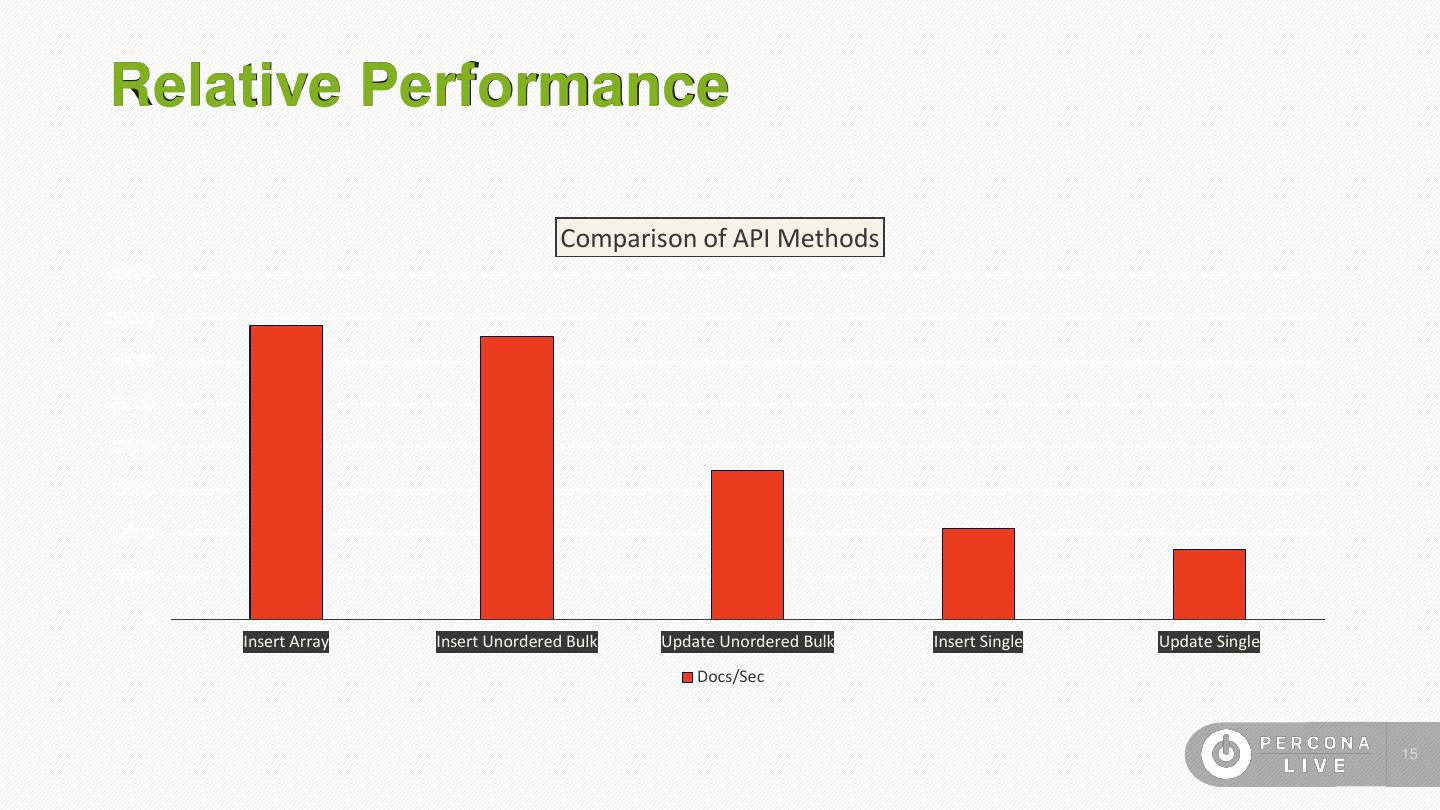
15 .Relative Performance Comparison of API Methods 40000 35000 30000 25000 20000 15000 10000 5000 0 Insert Array Insert Unordered Bulk Update Unordered Bulk Insert Single Update Single Docs/Sec 15
16 .Benchmarks… and other lies. Answering, “Why can’t I just use a gigantic HDD RAID array?”
17 .Benchmark Environment • VMs • 4 core Intel(R) Xeon(R) CPU E3-1246 v3 @ 3.50GHz • 8 GB RAM • Sandisk Ultra II 960GB SSD • WD 5TB 7200rpm HDD • MongoDB • 3.4.13 • WiredTiger • 4GB Cache • Snappy collection compression • Standalone server (no replica set, no mongos) • Data • 178 bytes per document in 6 fields • 3 indexes (2 compound) • Disk usage: 40% storage, 60% indexes • Using update unordered bulk method, 1000 docs per bulk.execute() 17
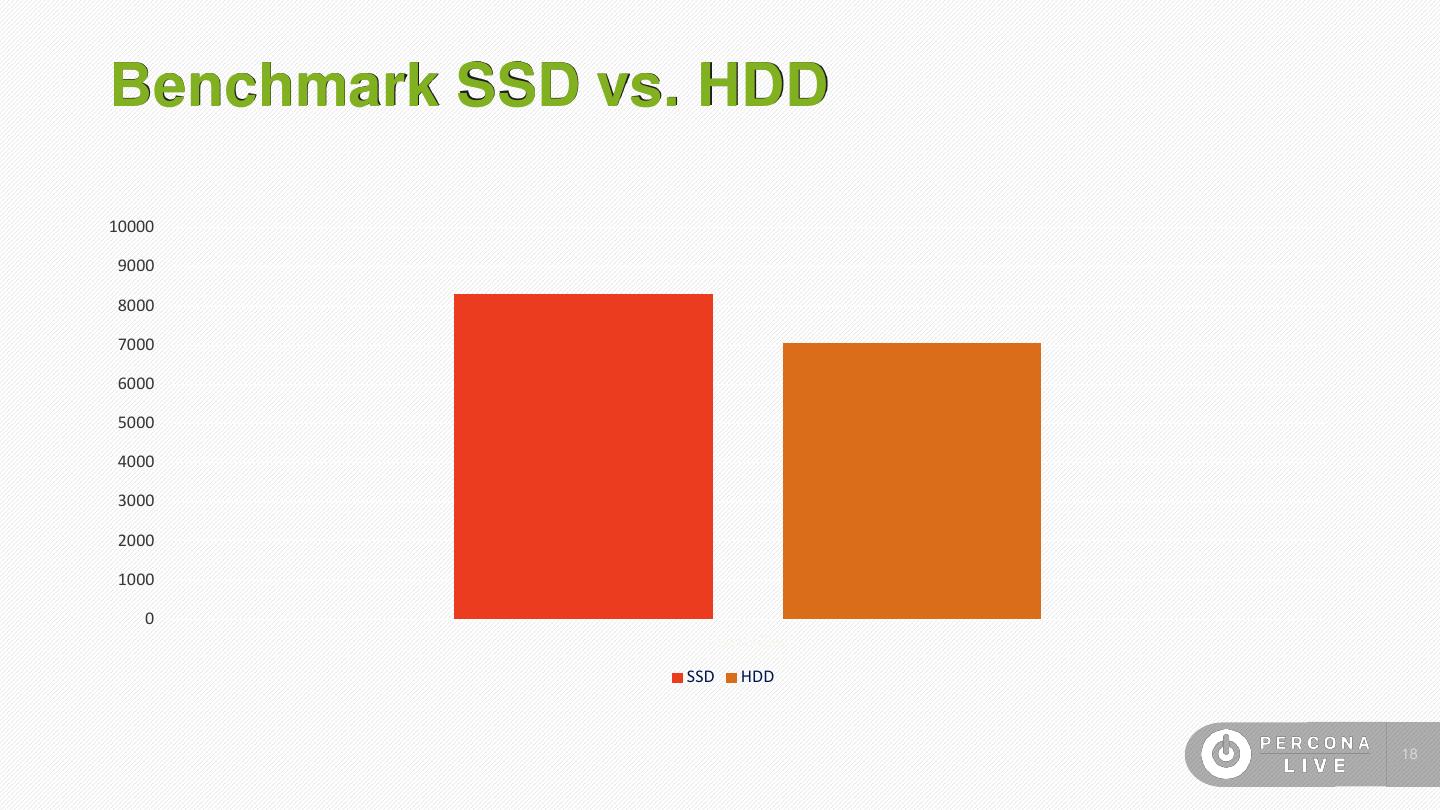
18 .Benchmark SSD vs. HDD 10000 9000 8000 7000 6000 5000 4000 3000 2000 1000 0 Inserts/Sec SSD HDD 18
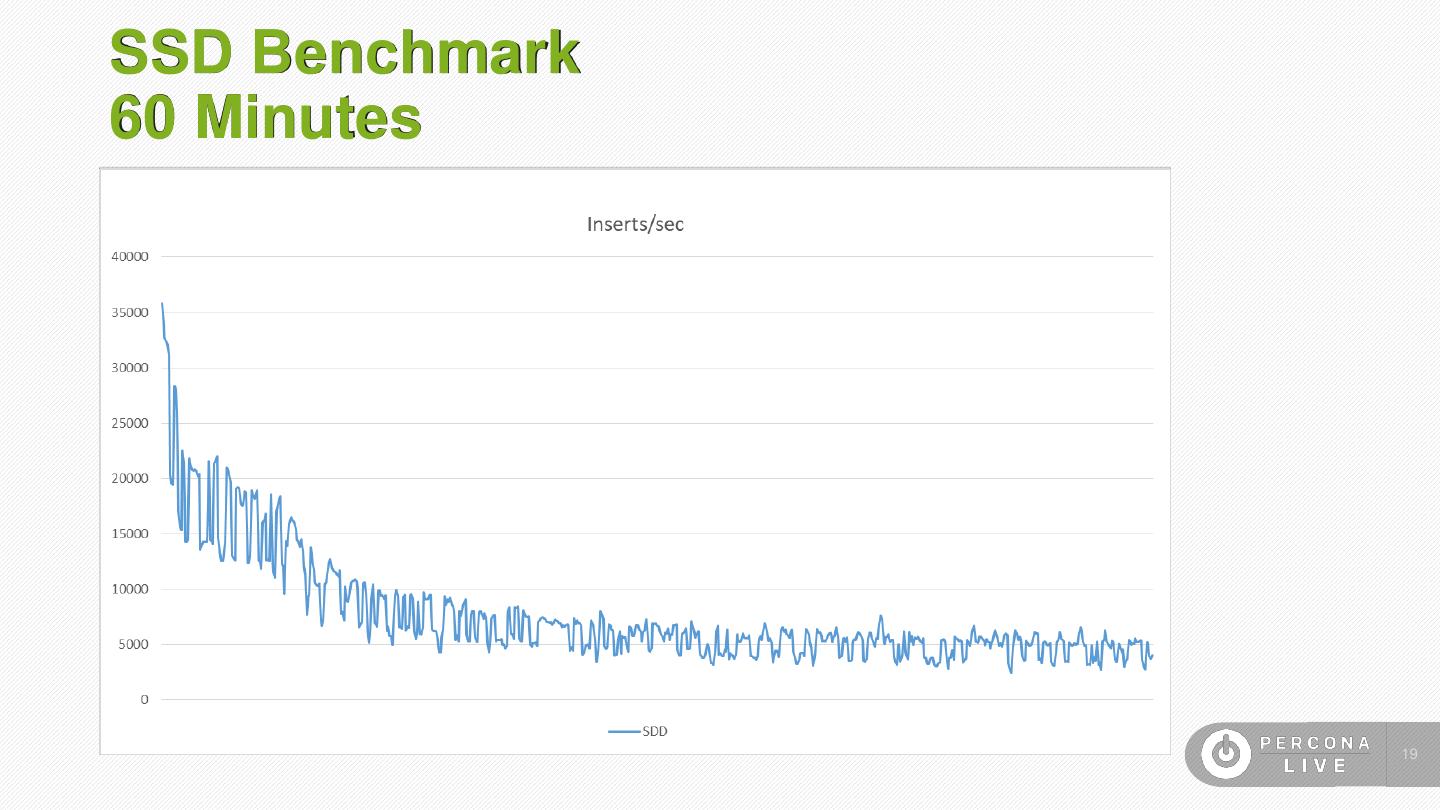
19 .SSD Benchmark 60 Minutes 19
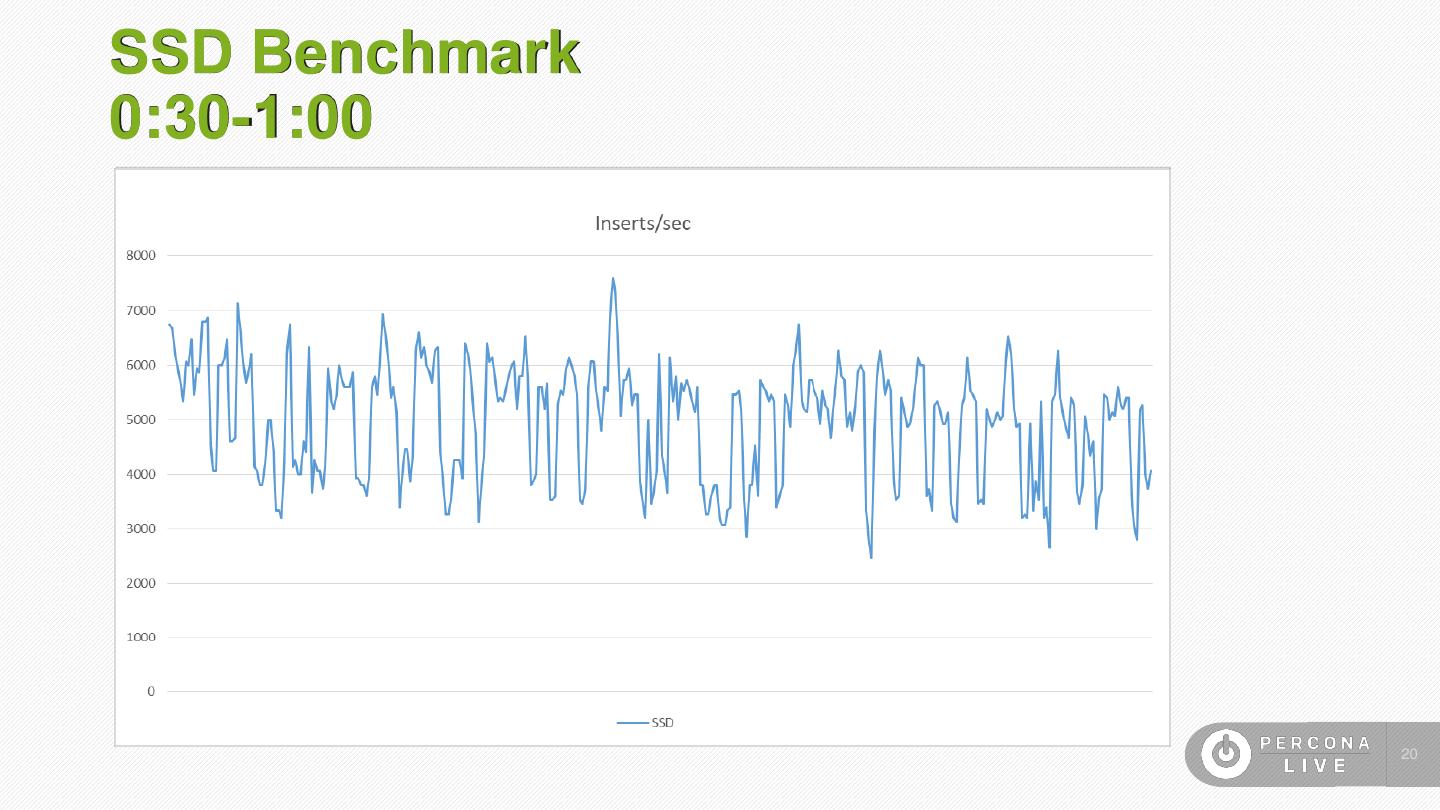
20 .SSD Benchmark 0:30-1:00 20
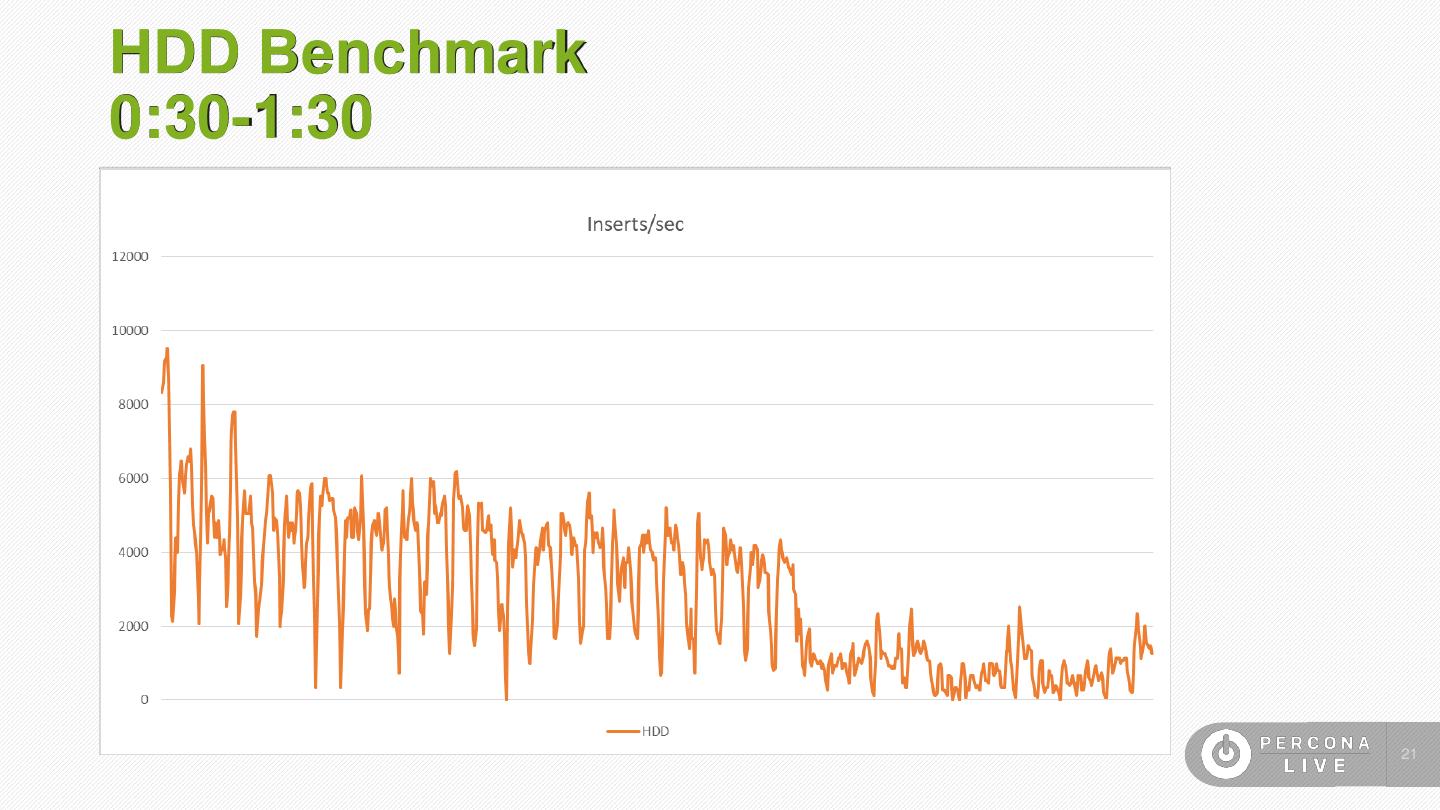
21 .HDD Benchmark 0:30-1:30 21
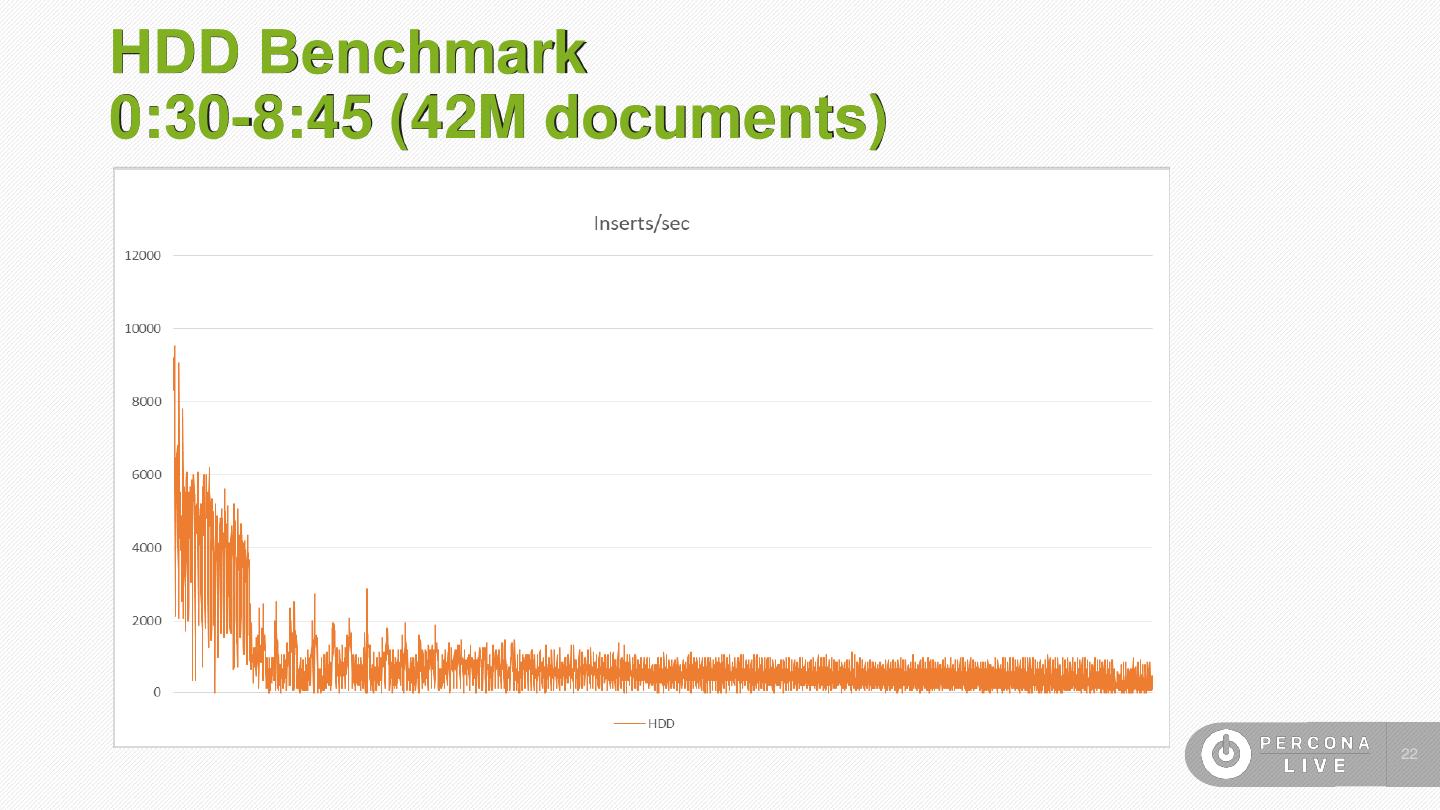
22 .HDD Benchmark 0:30-8:45 (42M documents) 22
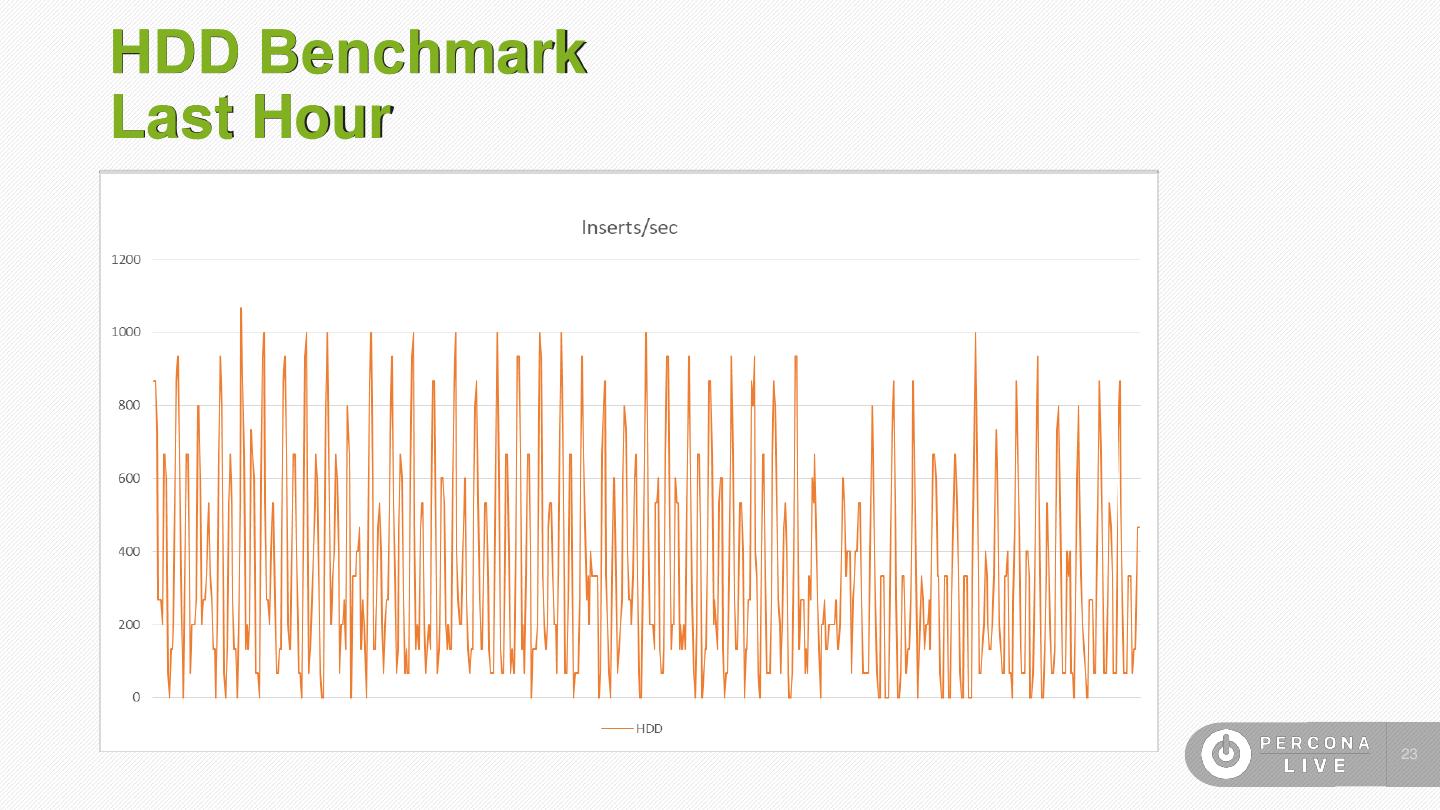
23 .HDD Benchmark Last Hour 23
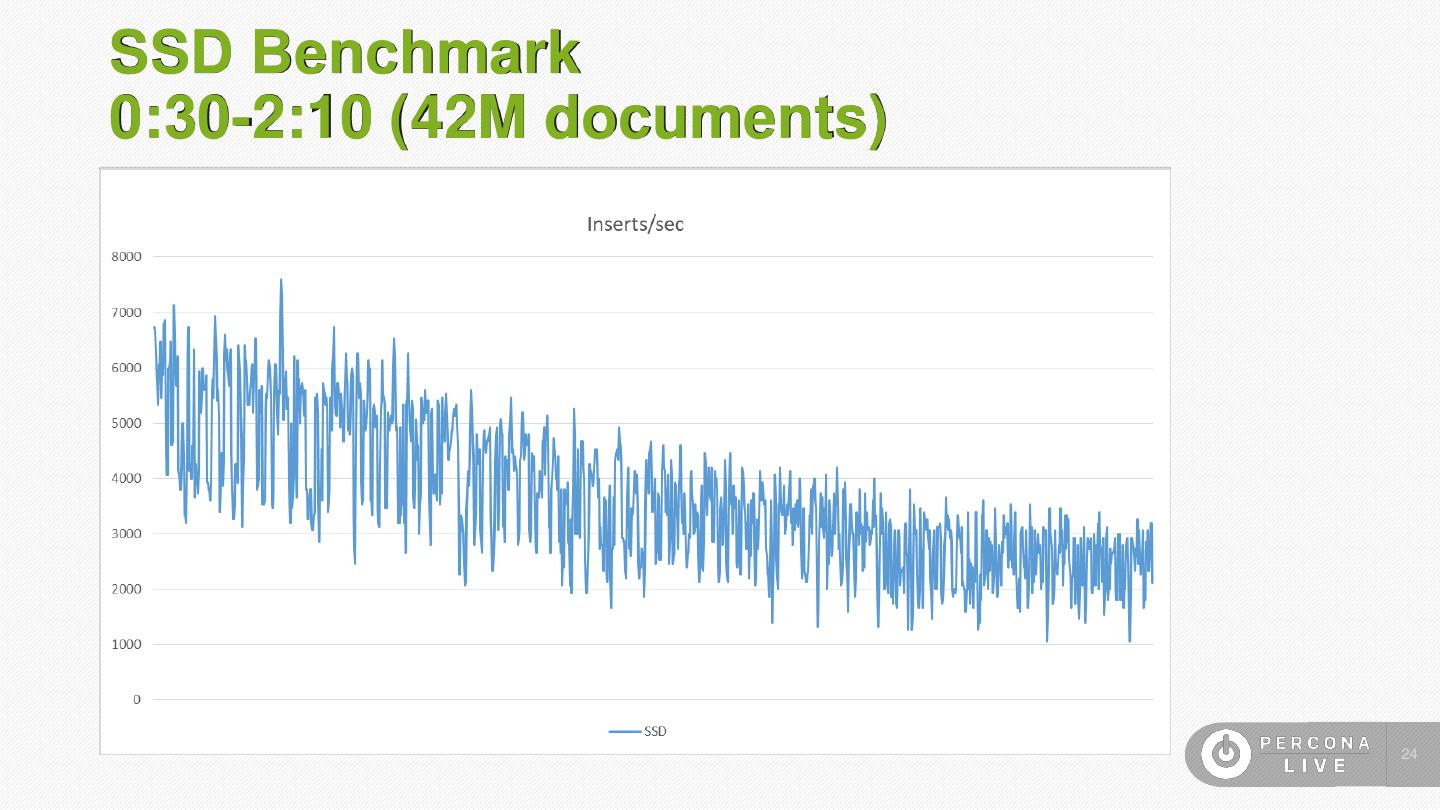
24 .SSD Benchmark 0:30-2:10 (42M documents) 24
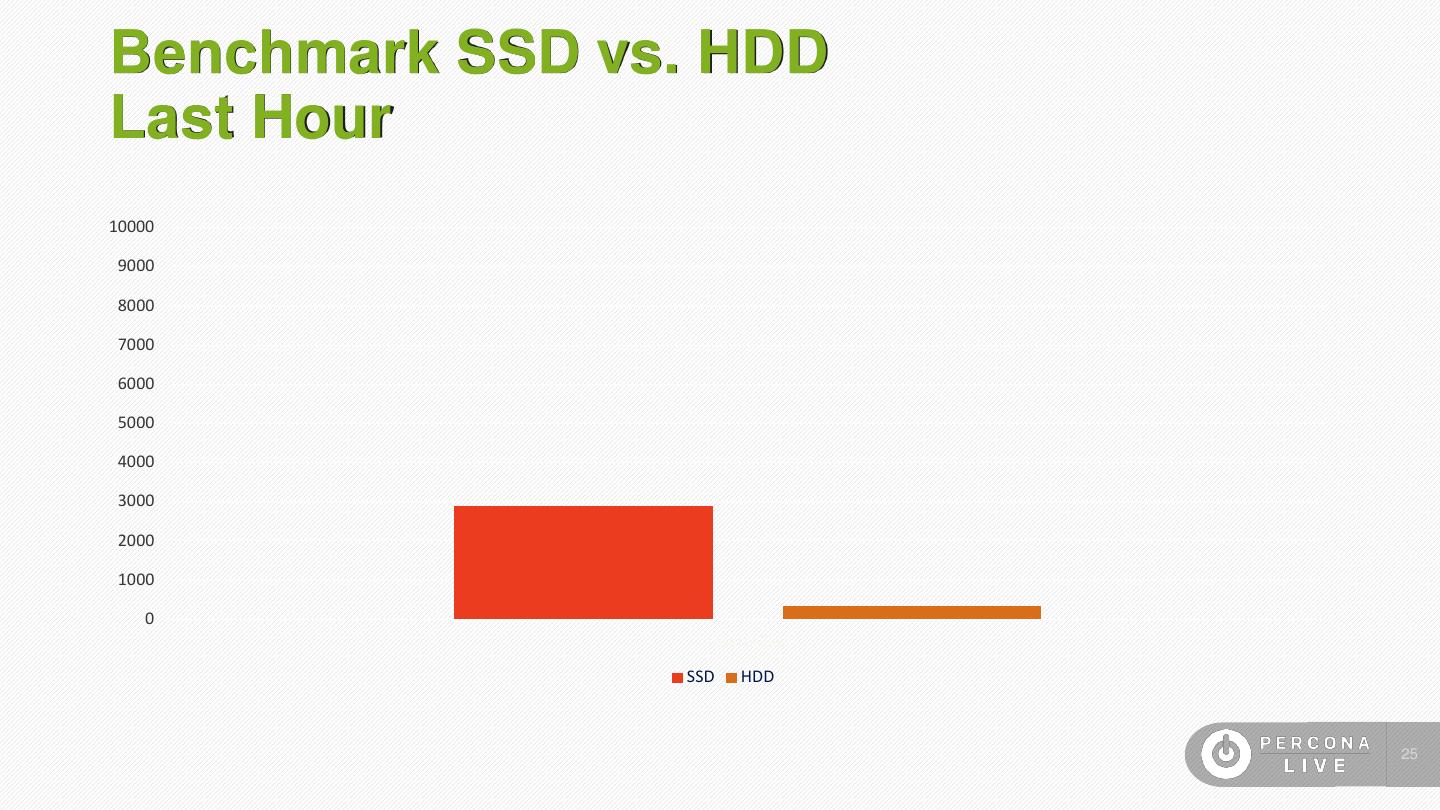
25 .Benchmark SSD vs. HDD Last Hour 10000 9000 8000 7000 6000 5000 4000 3000 2000 1000 0 Inserts/Sec SSD HDD 25
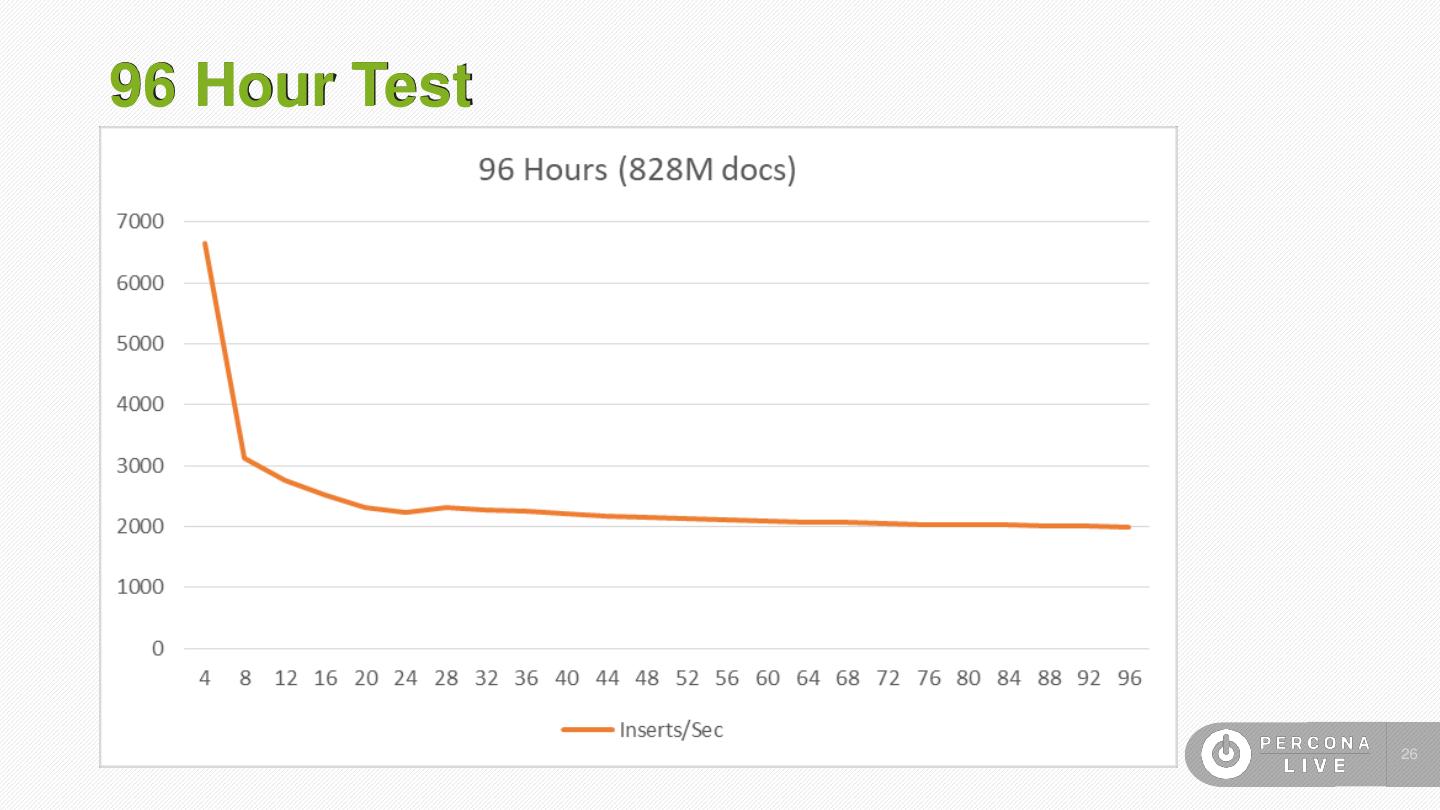
26 .96 Hour Test 26
27 .TL;DR • Don’t trust someone else’s benchmarks (especially mine!) • Benchmark using your own “schema” and indexes • Artificially accelerate index size exceeding available memory 27
28 .Time Series Data in MongoDB on a BUDGET
29 .Replica Set Rollout Options • Follow standard advice • 3 server replica sets (Primary, Secondary, Secondary) • Every replica set server on its own hardware • Disk mirroring • Cost cutting options • Primary, Secondary, Arbiter • Locate multiple replica set servers on the same hardware (but NOT from the SAME replica set) • No disk mirroring (how many copies do you really need?) • “I love downtime and don’t care about my data” • Single instance servers instead of replica sets • RAID0 (“no wasted disk space!”) • No backups 29
3秒后跳转登录页面
去登陆

