






















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MariaDB 10.3 Optimizer and beyond
数据库优化器不断改进。在本课程中,我们将介绍优化器团队为Mariadb 10.3版本实施的新优化,以及为下一个10.4版本计划的项目。
重点是:
条件通过group by和partition by下推
派生表的拆分分组(适用于优化的保证加速)
改进了独立于引擎的表统计支持
新建优化器默认设置
展开查看详情
1 . MariaDB 10.3 Optimizer and Beyond Vicențiu Ciorbaru Software Engineer @ MariaDB Foundation vicentiu@mariadb.org * © 2018 MariaDB Foundation *
2 . Agenda ■ Histograms ○ Current state of Histograms in MariaDB ○ Plans for 10.4 ■ Optimizations for derived tables ○ Condition pushdown into non-mergeable derived tables and views ○ Condition pushdown into in subqueries (10.4) ■ Window Function optimisations ○ Condition pushdown through window functions' PARTITION BY © 2018 MariaDB Foundation
3 . Condition Selectivity ■ Query optimizer needs to decide on a plan to execute the query ■ Goal is to get the shortest running time ○ Chose access method ■ Index Access, Hash Join, BKA, etc. ○ Choose correct join order to minimize the cost of reading rows ■ Usually, minimizing rows read minimizes execution time ○ Sometimes reading more rows is advantageous, if table / index is all in memory ■ Use a cost model to estimate how long an execution plan would take © 2018 MariaDB Foundation
4 . Condition Selectivity ■ Query optimizer needs to decide on a plan to execute the query ■ Goal is to get the shortest running time ○ Chose access method ■ Index Access, Hash Join, BKA, etc. ○ Choose correct join order to minimize the cost of reading rows ■ Usually, minimizing rows read minimizes execution time ○ Sometimes reading more rows is advantageous, if table / index is all in memory ■ Use a cost model to estimate how long an execution plan would take ■ For each condition in the where clause (and having) we compute ○ Condition selectivity How many rows of the table is this condition going to accept? 10%, 20%, 90% ? © 2018 MariaDB Foundation
5 . Condition Selectivity ■ Query optimizer needs to decide on a plan to execute the query ■ Goal is to get the shortest running time ○ Chose access method ■ Index Access, Hash Join, BKA, etc. ○ Choose correct join order to minimize the cost of reading rows ■ Usually, minimizing rows read minimizes execution time ○ Sometimes reading more rows is advantageous, if table / index is all in memory ■ Use a cost model to estimate how long an execution plan would take Getting the estimates right is important! ■ For each condition in the where clause (and having) we compute ○ Condition selectivity How many rows of the table is this condition going to accept? 10%, 20%, 90% ? © 2018 MariaDB Foundation
6 . Condition Selectivity ■ Suppose we have query with 10 tables: T1, T2, T3, … T10 ■ Query optimizer will: ○ Estimate the number of rows that it will read from each table ○ Based on the conditions in the where (and having) clauses ■ Assume estimates have an average error coefficient e ○ Total number of estimated rows read is: (e * #T1) * (e * #T2) * (e * #T3) * … * (e * #T10) Where #T1..#T10 is the actual number of rows read for each table ■ The estimation error is amplified, the more tables there are in a join ○ If we under/over estimate by a factor of 2 final error factor is 1024! ○ If error is only 1.5 (off by 50%), final error factor is ~60 © 2018 MariaDB Foundation
7 . Condition Selectivity ■ How does optimizer produce estimates? ■ Condition analysis: ○ Is it possible to satisfy conditions? t1.a > 10 and t1.a < 5 ○ Equality condition on a distinct column? ■ Index dives to get number of rows in a range ■ Guesstimates (MySQL) ■ Histograms for non-indexed columns © 2018 MariaDB Foundation
8 . Histograms ■ Estimate a distribution © 2018 MariaDB Foundation
9 . Histograms ■ Estimate a distribution ○ Equal-width histogram ■ Not uniform information ■ Many values in one bucket (5), fewer in others. © 2018 MariaDB Foundation
10 . Histograms ■ Estimate a distribution ○ Equal-width histogram ■ Not uniform information ■ Many values in one bucket (5), fewer in others. © 2018 MariaDB Foundation
11 . Histograms ■ Estimate a distribution ○ Equal-height histogram ■ All bins have same # of values ■ More bins where there are more values. © 2018 MariaDB Foundation
12 . Histograms in MariaDB ■ MariaDB histograms are collected by doing a full table scan ○ Support for sampling is under development for 10.4 ■ 2018 GSOC project by Teodor Niculescu ■ Needs to be done manually using ANALYZE TABLE … PERSISTENT ■ Stored inside ○ mysql.table_stats, mysql.column_stats, mysql.index_stats ○ As a binary value (max 255 bytes), single / double precision ■ Special function to decode: decode_histogram() ■ Can be manually updated ○ One can run data collection on a slave, then propagate results ■ Not enabled by default, needs a few switches turned on to work ○ Will be enabled by default in 10.4 © 2018 MariaDB Foundation
13 . Histograms in MySQL (8.0) ■ MySQL histograms are collected by doing a full table scan ○ Needs to be done manually using ANALYZE TABLE … UPDATE HISTOGRAM ■ Can collect all data or perform sampling by skipping rows, based on max memory allocation ■ Comparable performance to full table scan. ■ Stored inside data dictionary ○ Can be viewed through INFORMATION_SCHEMA.column_statistics ■ Stored as Equi-Width (Singleton) or Equi-Height ○ Visible as JSON ■ Can not be manually updated ■ No obvious easy way to share statistics ■ Enabled by default, will be used when available © 2018 MariaDB Foundation
14 . Histograms in Postgres ■ PostgreSQL histograms are collected by doing a true random read ○ Can be collected manually with ANALYZE ○ Also collected automatically when VACUUM runs ■ Stores equal-height and most common values at the same time ○ Equal-height histogram doesn’t cover MCV ■ Can be manually updated ○ One could import histograms from slave instances ○ VACUUM auto-collection seems to cover the use case © 2018 MariaDB Foundation
15 . Histograms in Postgres ■ Histograms are useful for range conditions ○ Equi-width or equi-height: COLUMN > constant ■ Most Common Values (Singleton): ○ COLUMN = constant ■ Problematic when multiple columns are involved: ○ t1.COL1 > 100 AND t1.COL2 > 1000 ■ Most optimizers assume column values are independent ○ P(A ∩ B) = P(A) * P(B) vs P(A ∩ B) = P(A) * P(B | A) ■ PostgreSQL 10 has added support for multi-variable distributions. ○ MySQL assumes independent values. ■ MariaDB doesn’t handle multi-variable case well either. © 2018 MariaDB Foundation
16 . Histograms Performance Sample database world: select city.name from city where (city.population > 10 mil or city.population < 10 thousand) MariaDB MySQL PostgreSQL Estimated Rows Filtered 1.95% 1.09% 1.05% Actual Rows Filtered 1.05 % © 2018 MariaDB Foundation
17 . Histograms Performance ■ Table with 2 columns A and B ○ t1.a always equals t1.b ○ 10 distinct values, each value occurs with 10% probability select t1.A, t1.B from t1 where t1.A = t1.B and t1.A = 5 MariaDB MySQL PostgreSQL Estimated Rows Filtered 1% 1% 10% Actual Rows Filtered 10 % © 2018 MariaDB Foundation
18 . Histograms Performance ■ Both MySQL and MariaDB don't fare well with correlated column conditions ■ MySQL is a bit more precise than MariaDB ■ Harder to exchange histograms between MySQL instances ■ Performance is no better than full-table-scan for MariaDB/MySQL so far. © 2018 MariaDB Foundation
19 . Query Optimizations Query rewriting can lead to significantly better query plans! © 2018 MariaDB Foundation
20 . Background about optimizations ■ A derived table is a table in the FROM clause, defined as a subquery. SELECT * FROM (SELECT a from t1) der_t1; © 2018 MariaDB Foundation
21 . VIP Customers and their orders select * from vip_customers, (select * from orders where order_date between '2017-10-01' and '2017-10-31') as OCT_ORDERS where OCT_ORDERS.amount > 1000000 and OCT_ORDERS.customer_id = vip_customers.customer_id; © 2018 MariaDB Foundation
22 . Naive Execution select * from vip_customers, (select * from orders where order_date between '2017-10-01' and '2017-10-31') as OCT_ORDERS where OCT_ORDERS.amount > 1000000 and OCT_ORDERS.customer_id = vip_customers.customer_id; OCT_ORDERS orders DATE amount > 1000000 JOIN vip_customers FILTER RESULT © 2018 MariaDB Foundation
23 . Derived Table Merge select * select * from from vip_customers vc, vip_customers vc, (select * orders from orders where where OCT_ORDERS.amount > 1M and order_date between OCT_ORDERS.customer_id = '2017-10-01' and '2017-10-31' vc.customer_id and ) as OCT_ORDERS order_date between where '2017-10-01' and '2017-10-31'; OCT_ORDERS.amount > 1M and OCT_ORDERS.customer_id = vc.customer_id; © 2018 MariaDB Foundation
24 . Explain shows the table being merged select * from vip_customers, (select * from orders where order_date between '2017-10-01' and '2017-10-31') as OCT_ORDERS where OCT_ORDERS.amount > 1000000 and OCT_ORDERS.customer_id = vip_customers.customer_id; 16649 rows in set (7.64 sec) +----+-------------+---------------+------+..+---------+-------------+ |id | select_type | table | type |..| rows | Extra | +----+-------------+---------------+------+..+---------+-------------+ | 1 | SIMPLE | vip_customers | ALL |..| 101 | | | 1 | SIMPLE | orders | ALL |..| 1000000 | Using where;| +----+-------------+---------------+------+..+---------+-------------+ © 2018 MariaDB Foundation
25 . Execution after merge select * from vip_customers vc, orders where orders.amount > 1M and orders.customer_id = vc.customer_id and order_date between '2017-10-01' and '2017-10-31'; orders OCT_ORDERS amount > 1000000 JOIN vip_customers RESULT © 2018 MariaDB Foundation
26 . Execution after merge select * from vip_customers vc, orders where orders.amount > 1M and orders.customer_id = vc.customer_id and order_date between '2017-10-01' and '2017-10-31'; Merging is good! orders It simplifies the query. OCT_ORDERS amount > 1000000 JOIN vip_customers RESULT © 2018 MariaDB Foundation
27 . Execution after merge select * from vip_customers vc, orders where orders.amount > 1M and orders.customer_id = vc.customer_id and order_date between '2017-10-01' and '2017-10-31'; Works in all stable MySQL and MariaDB versions orders OCT_ORDERS amount > 1000000 JOIN vip_customers RESULT © 2018 MariaDB Foundation
28 . Execution after merge select * from vip_customers vc, orders where orders.amount > 1M and orders.customer_id = vc.customer_id and order_date between '2017-10-01' and '2017-10-31'; Can not be used when aggregation is present :( orders OCT_ORDERS amount > 1000000 JOIN vip_customers RESULT © 2018 MariaDB Foundation
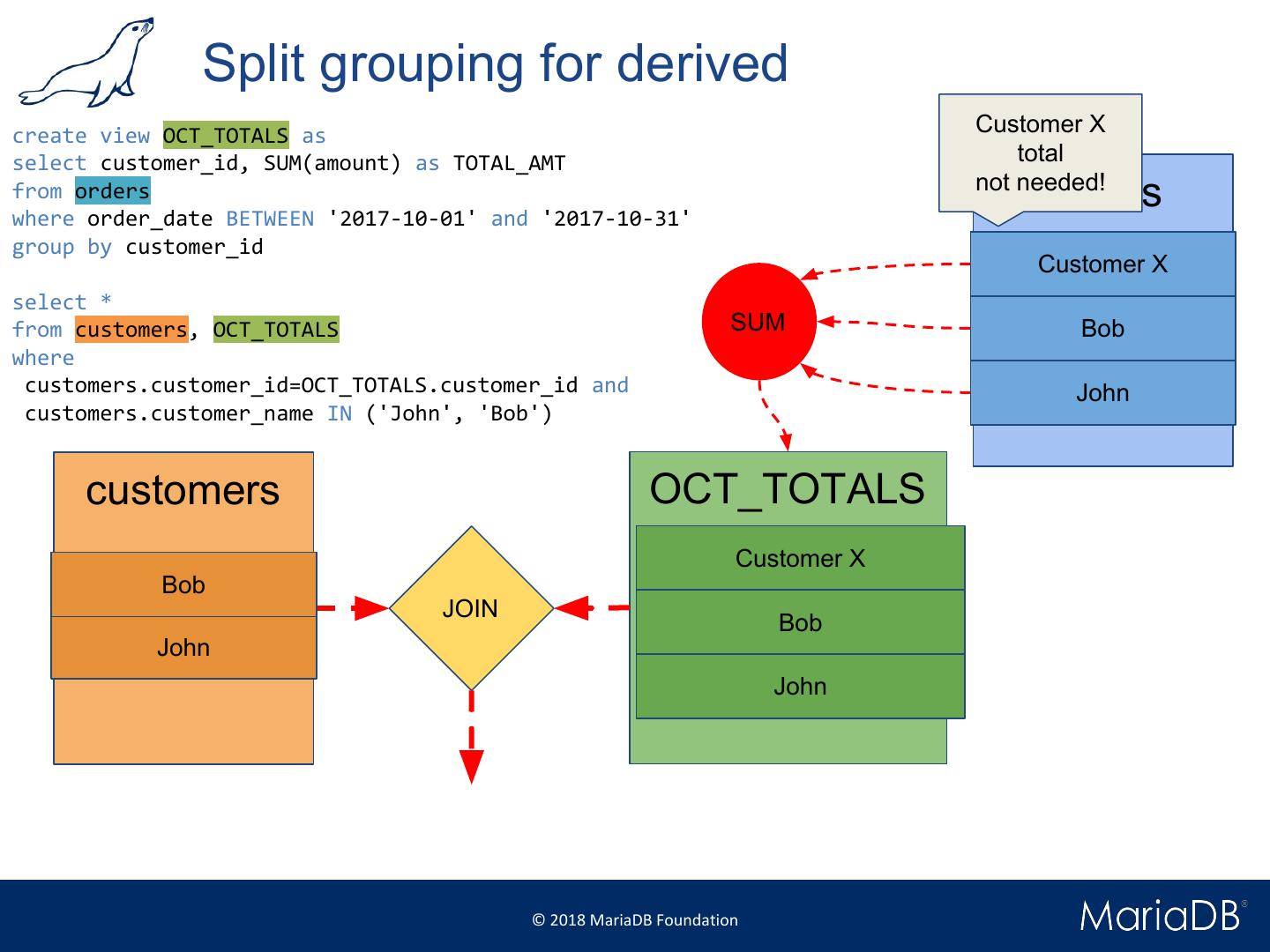
29 . Condition pushdown create view OCT_TOTALS as select customer_id, SUM(amount) as TOTAL_AMT from orders where order_date between '2017-10-01' and '2017-10-31' group by customer_id select * from OCT_TOTALS where customer_id=1 © 2018 MariaDB Foundation
3秒后跳转登录页面
去登陆

