展开查看详情
1 .Lessons from database failures
Colin Charles, Chief Evangelist, Percona Inc.
colin.charles@percona.com / byte@bytebot.net
http://www.bytebot.net/blog/ | @bytebot on Twitter
Percona Webminar
18 January 2017
�
2 .whoami
• Chief Evangelist (in the CTO office), Percona Inc
• Focusing on the MySQL ecosystem (MySQL, Percona Server, MariaDB
Server), as well as the MongoDB ecosystem (Percona Server for
MongoDB) + 100% open source tools from Percona like Percona
Monitoring & Management, Percona xtrabackup, Percona Toolkit, etc.
• Founding team of MariaDB Server (2009-2016), previously at Monty
Program Ab, merged with SkySQL Ab, now MariaDB Corporation
• Formerly MySQL AB (exit: Sun Microsystems)
• Past lives include Fedora Project (FESCO), OpenOffice.org
• MySQL Community Contributor of the Year Award winner 2014
�
3 .Agenda
• Backups (and verification)
• Replication (and failover)
• Security (and encryption)
�
5 .ma.gnolia.com’s failure
• January 30 2009: complete outage
• February 17 2009: data corruption in the UDB, essentially dead
• What happened?
• Ruby on Rails on four self-hosted Mac Mini’s, a couple of
XServe’s, 500GB+ MySQL 5 DB
• Filesystem corruption, corrupted database backup
• No versioning, didn’t check if the backups worked, made use of
rsync to backup the database over Firewire network
�
6 .ma.gnolia.com today?
• EC2 for the app with EBS snapshots, RDS with snapshots, Multi-AZ
deployment
• Self-hosted?
• xtrabackup
• START TRANSACTION WITH CONSISTENT SNAPSHOT +
mysqldump —single-transaction —master-data
• Backup a replica
• Replication event checksums
�
8 .Couchsurfing problems
1. major, avoidable hard drive crash
2. incremental backups weren’t executed in the correct manner, and
twelve of our most important data files didn’t survive
�
9 .Time-delayed replication
• MySQL 5.6+ has time-delayed replication. Stop replication when you
know a mistake has happened before it propagates to all the slaves.
• Feature suggestion since 2001! Bug reported August 2006
(mysql#21639). Pushed June 2010 (WL#344). GA February 2013.
�
10 .Why replicate?
• Scale out
• [automatic] (master) failover
• Geographical redundancy across multiple data centres
• Online schema changes
�
11 .Replication
• Asynchronous (default)
• (Enhanced loss-less) Semi-synchronous (plugin)
• Synchronous (Galera, group replication, NDBCLUSTER)
• DRBD
�
12 .Frameworks
• MySQL-MMM • Percona Replication Manager
• Severalnines ClusterControl (https://github.com/percona/
percona-pacemaker-agents/)
• Orchestrator
• Replication Manager
• MySQL MHA (github.com/tanji/replication-
• Tungsten Replicator manager)
• 5.6+ utilities:
mysqlfailover,
mysqlrpladmin
�
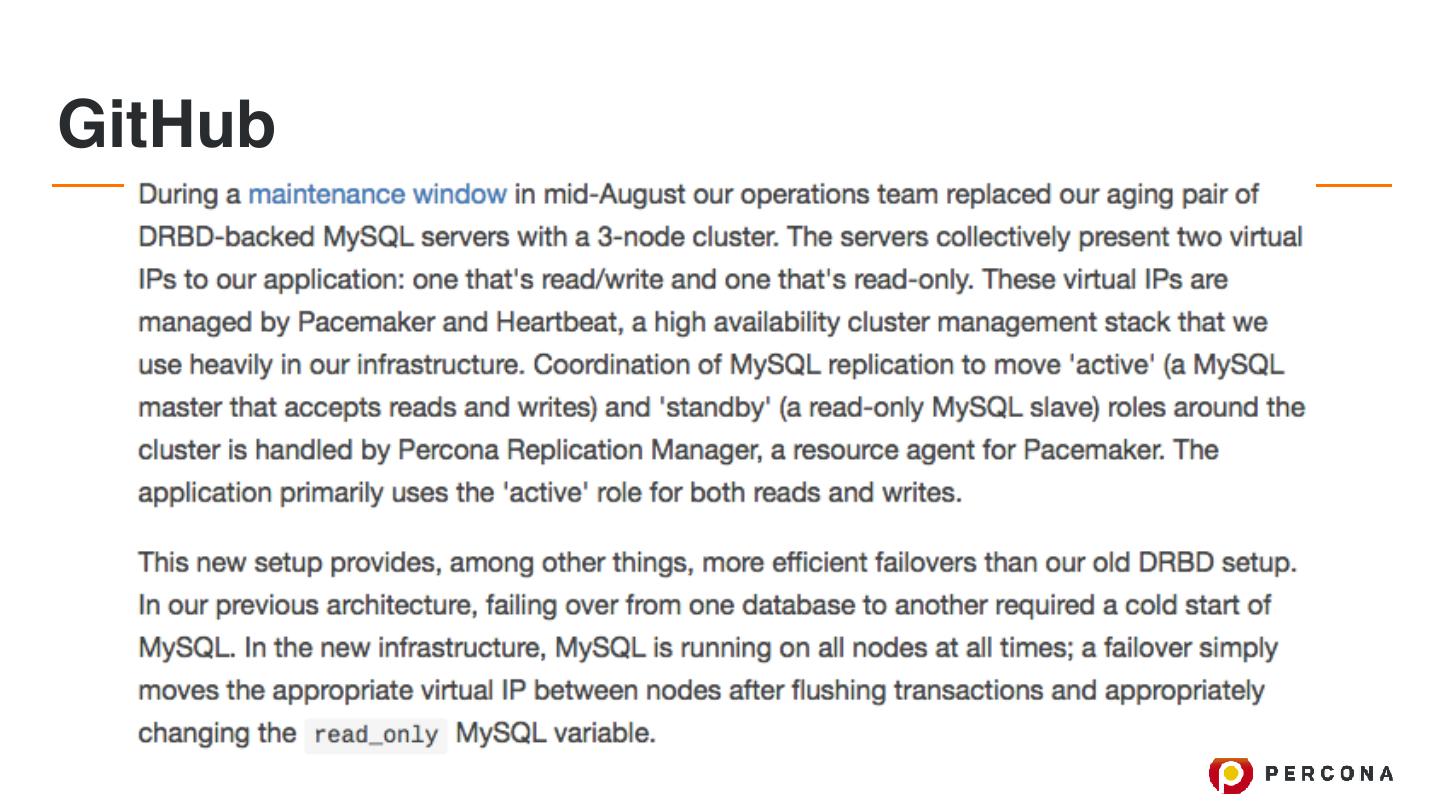
16 .GitHub
https://github.com/blog/1261-github-availability-this-week
�
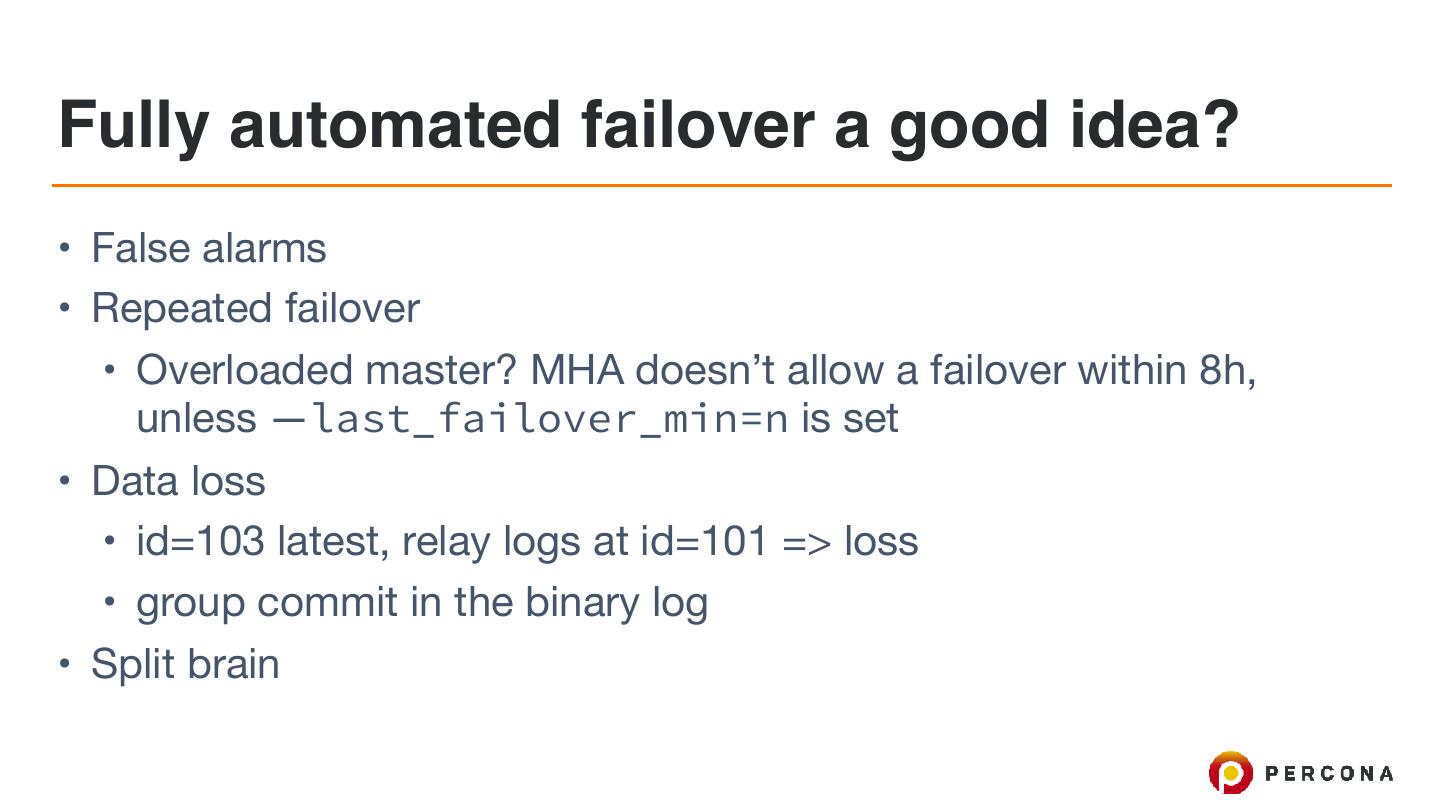
17 .Fully automated failover a good idea?
• False alarms
• Repeated failover
• Overloaded master? MHA doesn’t allow a failover within 8h,
unless —last_failover_min=n is set
• Data loss
• id=103 latest, relay logs at id=101 => loss
• group commit in the binary log
• Split brain
�
18 .Proxies
• MariaDB MaxScale
• Popular use: load balancing Galera clusters
• MySQL Router + MySQL Fabric
• ProxySQL
• Used alongside Galera clusters too
• Included with Percona XtraDB Cluster 5.7
�
20 .Sharding
• SPIDER
• Tungsten Replicator
• Tumblr JetPants
�
21 .Vitess
• Servers & tools to scale MySQL for web written in Go
• Has MariaDB support too (*)
• Python client interface
• DML annotation, connection pooling, shard management, workflow
management, zero downtime restarts
• Become super easy to use: http://vitess.io/ (with the help of
Kubernetes)
�
22 .Failwhales
• Twitter started on MySQL, and is still MySQL - you just need to
“evolve”
• Gizzard (sharding), Mesos + Apache Cotton
• Digg started on MySQL, migrated to Cassandra, and came back to
MySQL
�
23 .Security
• Philippines voter data leave 55m at risk: 338GB MySQL dump
• Ashley Madison: 6.9GB compressed dump, 36m email addresses
leaked, 9.6m credit card transactions
• Patreon: 13.7GB MySQL dump, 99 tables
�
24 .Mossack Fonseca: Panama Papers
�
25 .Prevent SQL injections
• MariaDB MaxScale database firewall filter
• Configurable filter actions on rule match (Allow the query, block
the query or ignore the match), Logging of matching and/or non-
matching queries
• MySQL Enterprise firewall
• ProxySQL
�
26 .Encryption at rest
• MariaDB Server 10.1: table or tablespace encryption
• design goal: Encrypt all user data that may touch the disk — InnoDB
data, InnoDB logs, binary logs, temporary tables, temporary files
• key management on the filesystem? [no key rotation] Amazon KMS?
• caveats: mysqlbinlog needs work with encrypted binlogs; Galera
Cluster gcache isn’t encrypted
• MySQL 5.7: only encrypts InnoDB tablespaces (innodb_file_per_table;
logs unencrypted)
�
27 .In conclusion…
• Use semi-sync replication with a failover solution that ensures you
don’t failover too often
• Make good backups. Test them. Save them.
• You’ll most definitely need to shard your data, use proven
frameworks and get a proxy involved. Complete backups with multi-
source replication when needed.
• Use mysqldump and xtrabackup together (and mydumper for
parallel backup/restore; mysqlpump)
• Security is key: prevent SQL injections, encrypt your data at rest
�
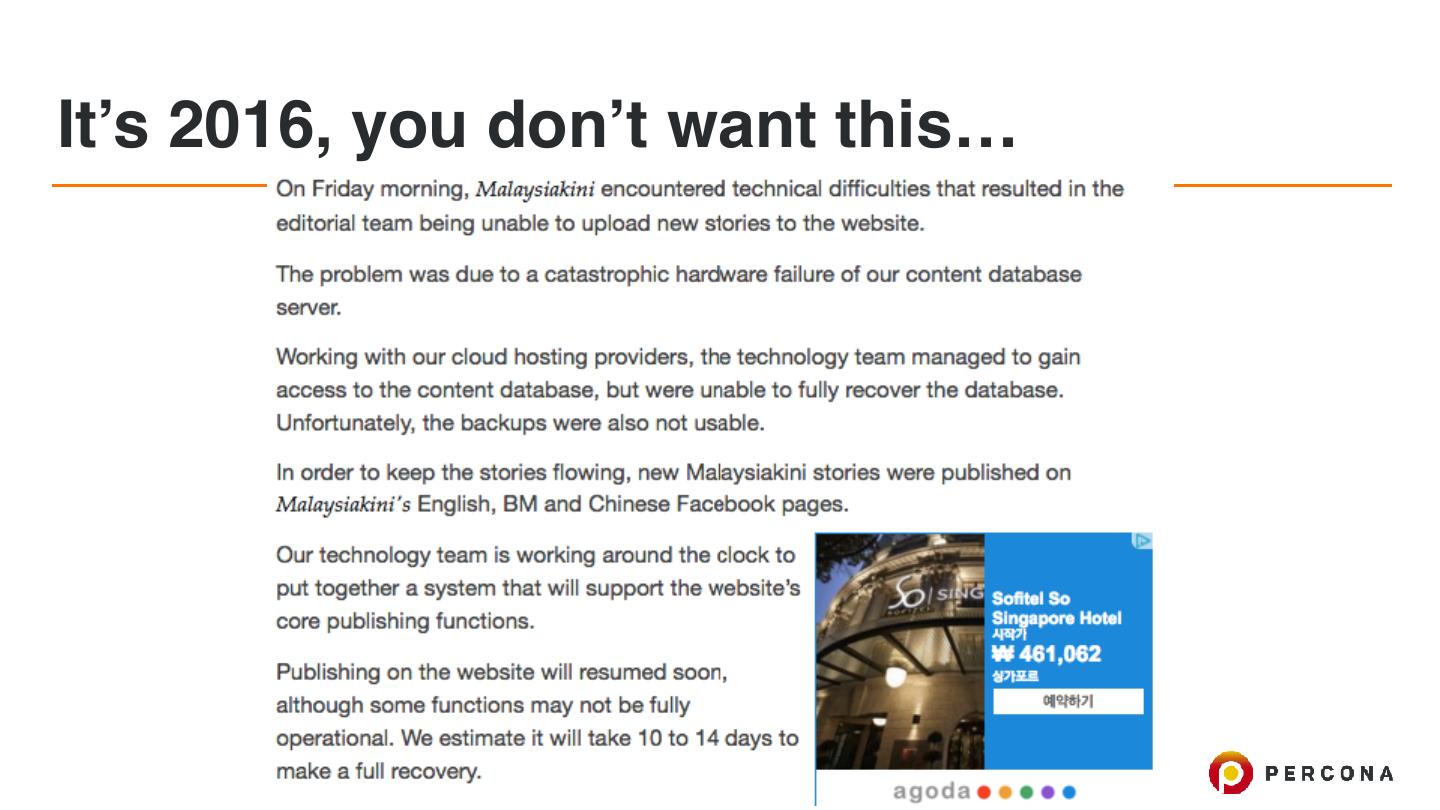
28 .It’s 2016, you don’t want this…
�
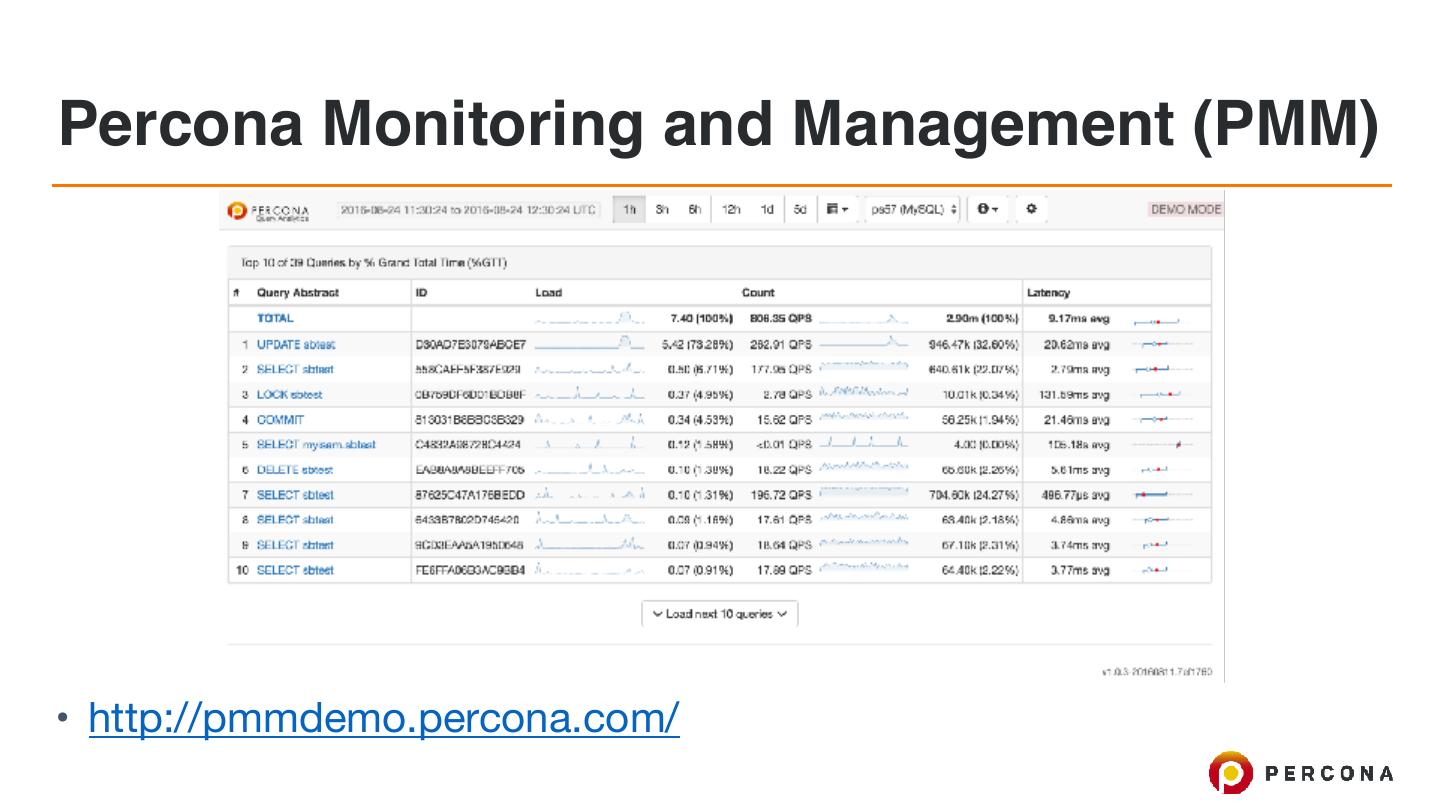
29 .Percona Monitoring and Management (PMM)
• http://pmmdemo.percona.com/
�