




















































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Billion Goods in Few Categories
我们存储数据的目的是使用它:搜索,检索,分组,排序…为了有效地执行这些操作,MySQL存储引擎在编译查询执行计划时索引数据并与优化器通信统计信息。这种方法非常有效,除非数据分布不均匀。
去年,我研究了几张门票,其中的数据遵循相同的模式:数以百万计的流行产品分为两类,其余的则使用其余的。我们很难找到快速取回货物的解决方案。提供了5.7版的解决方案。然而,我们了解到一个新的MySQL8.0特性——柱状图——会更好、更干净、更快地工作。因此,我们谈话的想法诞生了。
在本次网络研讨会中,我们将讨论:
-如何物理存储索引统计信息
-与优化器交换哪些数据
-为什么不足以做出正确的索引选择
最后,我将解释哪些问题是通过柱状图解决的,以及为什么使用索引统计数据不足以快速检索不均匀分布的数据。
展开查看详情
1 .Billion Goods in Few Categories how Histograms Save a Life? April, 11, 2019 Sveta Smirnova
2 .Table of Contents •Introduction •The Use Case The Cardinality: Two Levels Example •Even Worse Use Case ANALYZE TABLE Limitations Example •Why the Difference? •How Histograms Work? •Left Overs 2
3 .Optimizer Statistics aka Histograms The column statistics data dictionary table stores histogram statistics about column values, for use by the optimizer in constructing query execution plans MySQL User Reference Manual 3
4 .Introduction
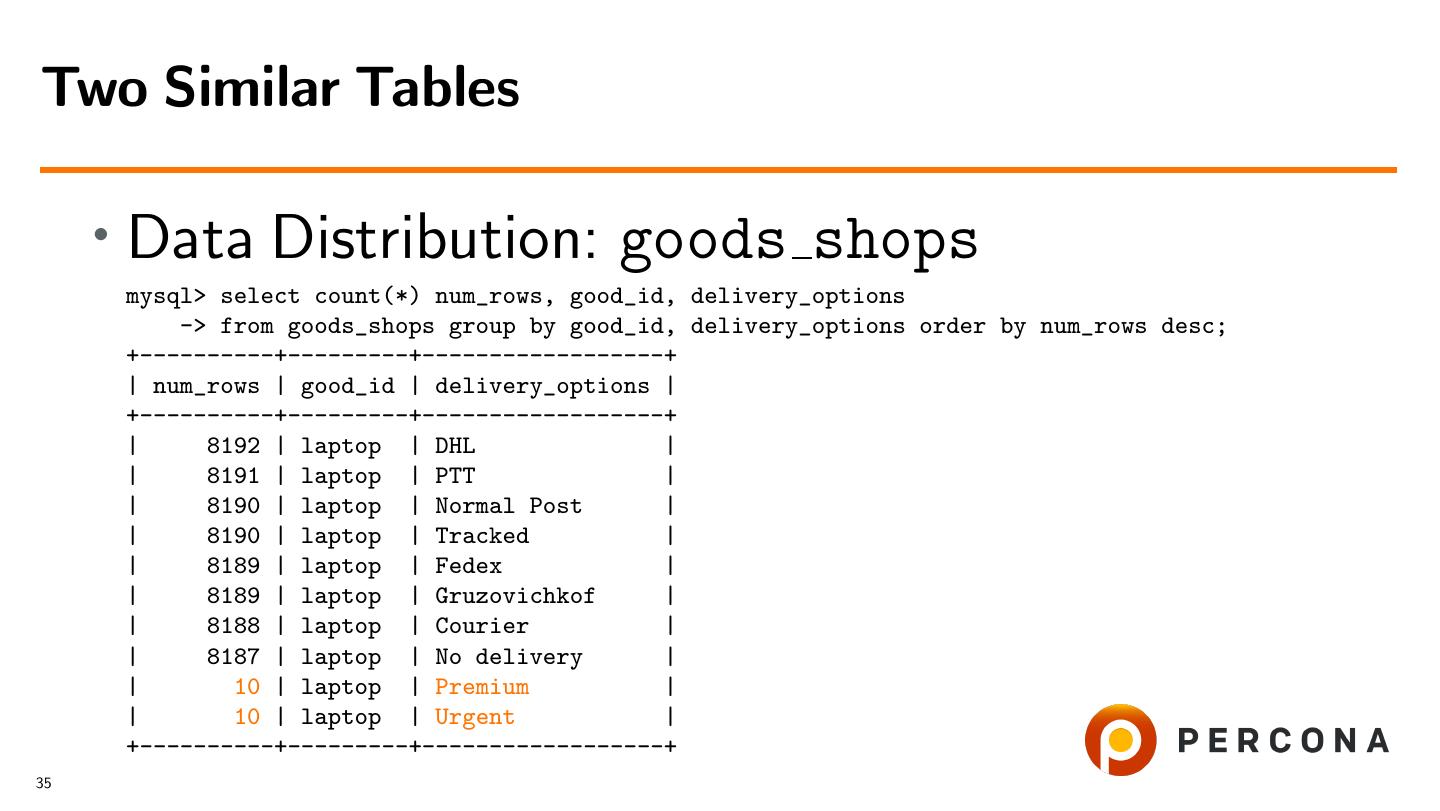
5 .Latest Support Tickets • Data distribution vary • Big difference between number of values • Costantly changing 5
6 .Latest Support Tickets • Data distribution vary • Cardinality is not correct • Was not updated in time • Updates too often • Calculated wrongly 5
7 .Latest Support Tickets • Data distribution vary • Cardinality is not correct • Index maintenance costs a lot • Hardware resources • Slow updates • Window to run CREATE INDEX 5
8 .Latest Support Tickets • Data distribution vary • Cardinality is not correct • Index maintenance costs a lot • Optimizer does not work as we wish to Examples in my talk @Percona Live 5
9 .Disclaimer • Topic based on real Support cases • Couple of them are still in progress 6
10 .Disclaimer • Topic based on real Support cases • All examples are 100% fake • They created such that • No customer can be identified • Everything generated Table names Column names Data • Use case itself is fictional 6
11 .Disclaimer • Topic based on real Support cases • All examples are 100% fake • All examples are simplified • Only columns, required to show the issue • Everything extra removed • Real tables usually store much more data 6
12 .Disclaimer • Topic based on real Support cases • All examples are 100% fake • All examples are simplified • All disasters happened with version 5.7 6
13 .The Use Case
14 .Two tables • categories • Less than 20 rows 8
15 .Two tables • categories • Less than 20 rows • goods • More than 1M rows • 20 unique cat id values • Many other fields Price Date: added, last updated, etc. Characteristics Store ... 8
16 .JOIN select * from goods join categories on (categories.id=goods.cat_id) where date_added between ’2018-07-01’ and ’2018-08-01’ and cat_id in (16,11) and price >= 1000 and <=10000 [ and ... ] [ GROUP BY ... [ORDER BY ... [ LIMIT ...]]] ; 9
17 .Option 1: Select from the Small Table First • Select from the Small Table 10
18 .Option 1: Select from the Small Table First • Select from the Small Table • For each cat id select from the large table 10
19 .Option 1: Select from the Small Table First • Select from the Small Table • For each cat id select from the large table • Filter result on date added[ and price[...]] 10
20 .Option 1: Select from the Small Table First • Select from the Small Table • For each cat id select from the large table • Filter result on date added[ and price[...]] • Slow with many items in the category 10
21 .Option 1: Illustration 11
22 .Option 1: Illustration 11
23 .Option 1: Illustration 11
24 .Option 1: Illustration 11
25 .Option 1: Illustration 11
26 .Option 1: Illustration 11
27 .Option 1: Illustration 11
28 .Option 1: Illustration 11
29 .Option 2: Select from the Large Table First • Filter rows by date added[ and price[...]] 12
3秒后跳转登录页面
去登陆

