


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Tuning MongoDB Consistency
请加入Percona的高级技术操作架构师TimVaillancourt,他将展示“调优MongoDB一致性”。
欢迎来到Percona调音系列的第二部分。在我们之前的网络研讨会中,我们提到了一些MongoDB调优的最佳实践。如果在第一次网络研讨会上遵循调优建议之后仍然需要更好的性能呢?第二部分详细介绍了调优查询时要考虑的其他一些选项。
在本次网络研讨会中,我们将介绍:
MongoDB中的一致性、原子性和隔离性
副本集回滚以及数据风险
在开发期间要考虑的完整性与可伸缩性权衡
使用读关注点和写关注点来调整应用程序数据的一致性
何时使用读取首选项,以及这样做的权衡
调整MongoDB部署和服务器配置以实现数据完整性/一致性
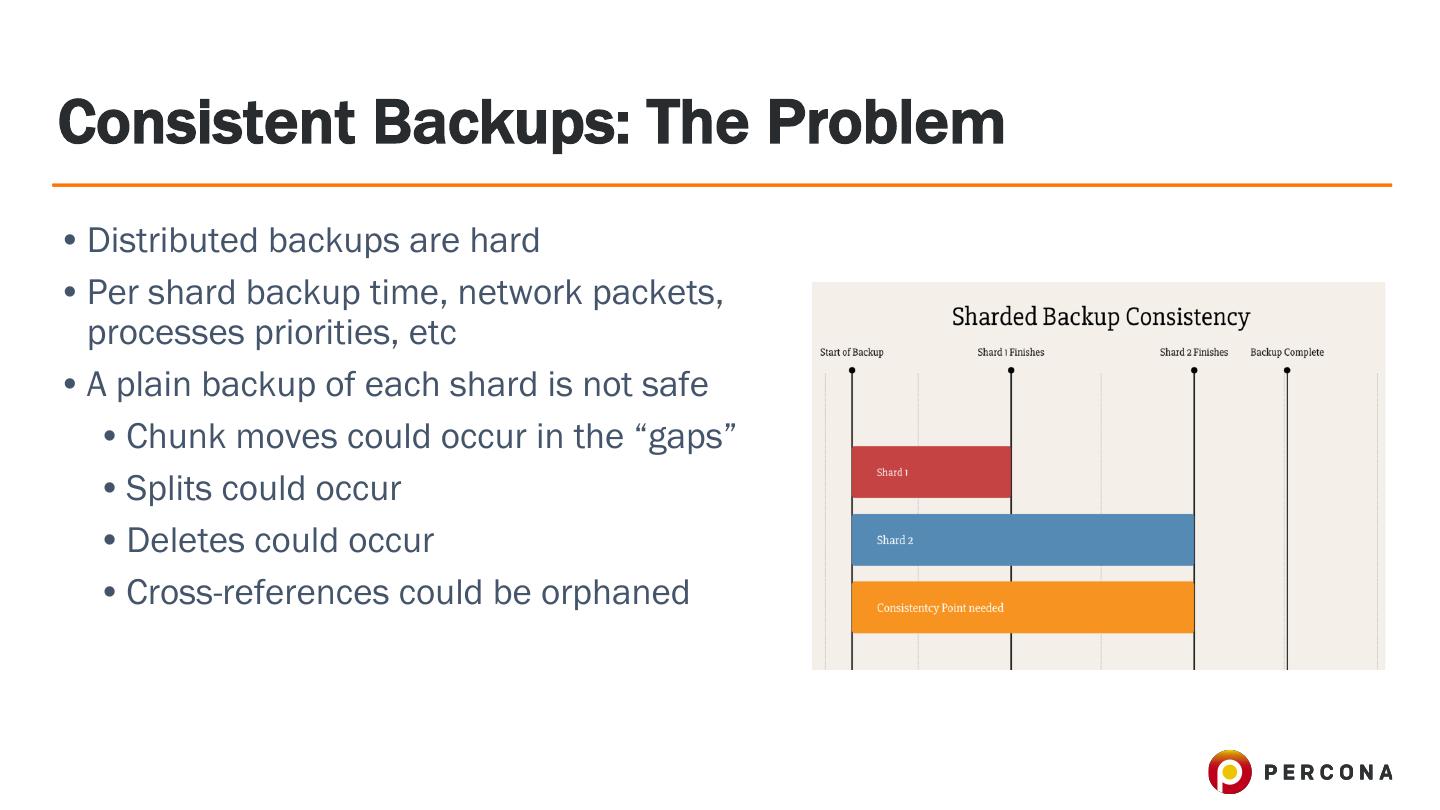
执行群集范围的一致备份
在网络研讨会结束时,您将更好地了解如何使用MongoDB的特性来实现一致性和可伸缩性的必要平衡。
展开查看详情
1 .Tuning MongoDB Consistency Exploring Consistency (and Durability) in MongoDB Tim Vaillancourt, Sr. Technical Operations Architect
2 .In This Webinar • Consistency • Isolation and Atomicity • Query-Level Consistency • Read Preference • Read Concern • Write Concern • Server Consistency • Backup Consistency
3 .About Me • Operations Architect for MongoDB team • Previous: • Gaming • Ecommerce • Marketing • Web Hosting • Main techs: MySQL, MongoDB, Cassandra, Solr, Redis, queues, etc • Paranoid about data integrity
4 .“MongoDB is Web Scale” 2013 2010
5 .Isolation and Atomicity • Isolation • Read Uncommitted • Any session can see a change, even before ack’d • Essentially no isolation compared to RDBMs • Atomicity • Single-document Update • A reader will never see a partially-changed document • Multi-document Update • Multi-operation not atomic, no rollback
6 .Consistency and Durability • Terms • Data Accuracy / “Lag” / Timeliness • Example: “If I change something and read from a replica, will it have the correct data?” • Data Durability / Consistency • Example: “If I pull the power cord on my server, will it have ALL of the data after crash recovery?
7 .Crash Recovery and Journaling • The Journal provides durability in the event of failure of the server • Changes are written ahead to the journal for each write operation • On crash recovery, the server: • Finds the last point of consistency to disk • Searches the journal file(s) for the record matching the checkpoint • Applies all changes in the journal since the last point of consistency • Journal data is stored in the ‘journal’ sub directory of the server data path (dbPath) • Dedicated disks for data (random I/O) and journal (sequential I/O) improve performance
8 .Storage Engines: MMAPv1 • MMAPv1 syncs data to disk once per 60 seconds (default) • Override with —syncDelay <seconds> flag • If a server with no journal crashes it can lose 1 min of data!!! • In memory buffering of Journal • Synced every 30ms ‘journal’ is on a different disk • Or every 100ms • Or 1/3rd of above if change uses Journaled write concern (explained later)
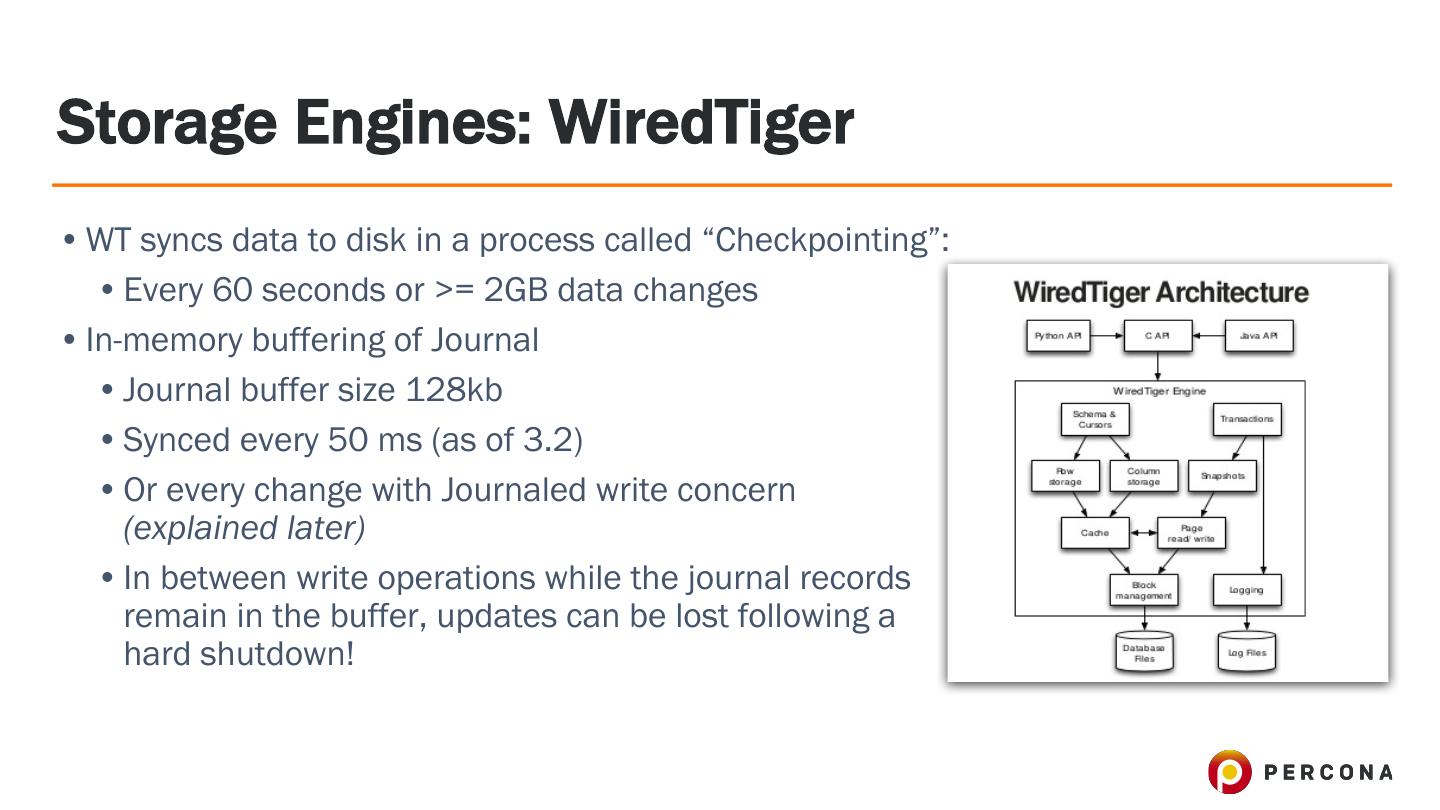
9 .Storage Engines: WiredTiger • WT syncs data to disk in a process called “Checkpointing”: • Every 60 seconds or >= 2GB data changes • In-memory buffering of Journal • Journal buffer size 128kb • Synced every 50 ms (as of 3.2) • Or every change with Journaled write concern (explained later) • In between write operations while the journal records remain in the buffer, updates can be lost following a hard shutdown!
10 .Storage Engines: RocksDB • RocksDB uses “compaction” to apply changes to data files • Tiered level compaction • Follows same logic as MMAPv1 for journal buffering
11 .Replication: Overview • Asynchronous • Changes are replicated and/or applied to replicas with eventual consistency • Examples: MongoDB, MySQL, … • Synchronous • Changes are replicated and/or applied to all replicas at the time of change • Examples: Percona XtraDB Cluster/Galera, Cassandra, MySQL w/Semisync (sometimes), … • MongoDB Write Concerns can “simulate” the idea of synchronous replication! Explained later
12 .Replication: MongoDB Replica Sets • Config: • Members: • Must have odd number of voting members • Elections consider Votes, Priority, Oplog time, etc • Tags: • Members can be tagged with arbitrary key/value pairs • Useful for pointing heavy queries, backups, etc at a certain node • Settings: • writeConcernMajorityJournalDefault = <true/false> • Added and default true in 3.4+ • Hidden: Nodes that replicate but should not take queries
13 .Failover • Voting • Set in replica set config ‘members’ documents (see rs.conf()) • 3.2 and Raft • Rewritten with Raft-like concepts • Faster elections = shorter failover • Priority • 1-1000 • 0 = never become Primary • Oplog Time
14 .Failover: Replica Set Rollbacks • Consider: • A PRIMARY has written 10 documents to the oplog and dies • 2 x SECONDARY nodes applied 5 and 7 of the changes • The SECONDARY with 7 changes wins PRIMARY • The PRIMARY that died comes back alive • The node becomes RECOVERING then SECONDARY • 3 documents are “rolledback” to disk • JSON file written to ‘rollback’ dir on-disk when PRIMARY crashes when ahead of SECONDARYs • Monitor for this file existing on disk!!
15 .Consistency: Write Concern • Levels: • “w: <num>” - Writes much acknowledge to defined number of nodes • “majority” - Writes much acknowledge on a majority of nodes • “<replica set tag>” - Writes much acknowledge to a member with the specified replica set tags • Durability: • By default write concerns are NOT durable • “j: true” - Optionally, wait for node(s) to acknowledge journaling of operation • In 3.4+ “writeConcernMajorityJournalDefault” allows enforcement of “j: true” via replica set configuration!
16 .Consistency: Read Concern • New feature in MongoDB and PSMDB 3.2+ • Like write concerns, the consistency of reads can be tuned • Levels: • “local” - Default, return the current node’s most-recent version of the data • “majority” - Reads return the most-version of the data that has been ack’d on a majority of nodes. Not supported on MMAPv1. • “linearizable” (3.4+) - Reads return data that reflects a “majority” read of all changes prior to the read
17 .Scalability, Etc: Read Preferences • Controls the node type (not consistency) for a session: • “primary” - Only read from Primary • “primaryPreferred” - Read from Primary unless there is none • “secondary” - Only read from Secondary • “secondaryPreferred” - Read from Secondary unless there are none • “nearest” - Connect to the first node you can
18 .Scalability, Etc: Read Preferences • Tag Sets: • Ensure reads go to specific, tagged nodes • Tags are set via replica set configuration • Use cases: • Backend / Business Analytics • Backups • Batch Jobs / Queries • Data Summary / Rollups • Geo Proximity, ie: {datacenter: “eu”}
19 .Read Preferences • Scalability with Secondary reads: • Benefit from all 3 (generally) nodes in your replica set! • Avoids single point of scale / offloads Primary • No “quality of service” for query types • Use Read Concern “majority” / “linearizable” for sensitive queries!!!
20 .Use Case: Stock Trading Application • Latency sensitive, ie: cannot handle “lag” in updates • Changes to data must survive failover • Possible data flow: • Update stock data: • w: N (if in-memory) • w: majority, j: true (if on-disk) • Read stock data: • Read Concern: “majority” • Read Preference: “secondaryPreferred” • Possible architecture: • Percona InMemory storage engine on *many* nodes • Or WiredTiger or RocksDB on SSD disks
21 .Use Case: Stock Trading Application • Possible architecture: • Percona InMemory storage engine on *many* nodes • Or WiredTiger or RocksDB on SSD disks
22 .Use Case: Social Network Application • Eventually consistent • Changes to data *should* survive failover • Possible data flow: • Adding a new user • w: majority • Reading a user • Read Concern: “majority” • Adding a status update • w: 1 (default) • Reading a status update • Read Concern: “local” (default) • Read Preference: “secondary” • Read timeline: • Read Concern: “local” (default) • Read Preference: “secondary”
23 .Use Case: Social Network Application • Possible Architecture: • WiredTiger or RocksDB • SSD or spinning disk • Sharding with 3 x member replica sets
24 .Use Case: Geo-distributed Application • Nodes in 3 x datacenters: “na1”, “eu1”, “apac1” • Eventually Consistent cross-datacenter, best-effort within datacenter • Possible Architecture: • Sharding: 1 x configsvr / datacenter • Shards: “na1”, “eu1”, “apac1” • Shard Zones, based on field “dc” • “na1” => “na” • “eu1” => “eu” • “apac1” => “apac” • Replica sets: 3 x nodes/shard in 1 x datacenter, 1 x hidden replica (with votes:0, priority:0) in another
25 .Use Case: Geo-distributed Application • Data workflow: • Adding data: • Insert data with field “dc” using write concern ‘majority’: db.users.insert({ name: ”tim”, dc: ”eu” }) • Query data: • Query data with (or without) “dc” set to …
26 .Tune Mongod for Durability • storage.journal.enabled = <true/false> • Default since 2.0 on 64-bit builds • Always enable unless data is transient • Always enable on cluster config servers • storage.journal.commitIntervalMs = <ms> • Max time between journal syncs • storage.syncPeriodSecs = <secs> • Max time between data file flushes
27 .System Data Durability • Balance: • Redundant Disks • Many redundant disks, NICs, power supplies, etc • Few replica set members • RAID • RAID10 - recommended for performance / redundancy balance • Redundant Members / Copies • Less per-system redundancy • Lots of replica set members • RAID • JBOD • InMemory (some or all) • RAID0
28 .System Data Durability • Datacenter Recommendations • Ensure VMs and systems are physically separate • Upload backups offsite • Many datacenters • 1 member per Cloud region, etc
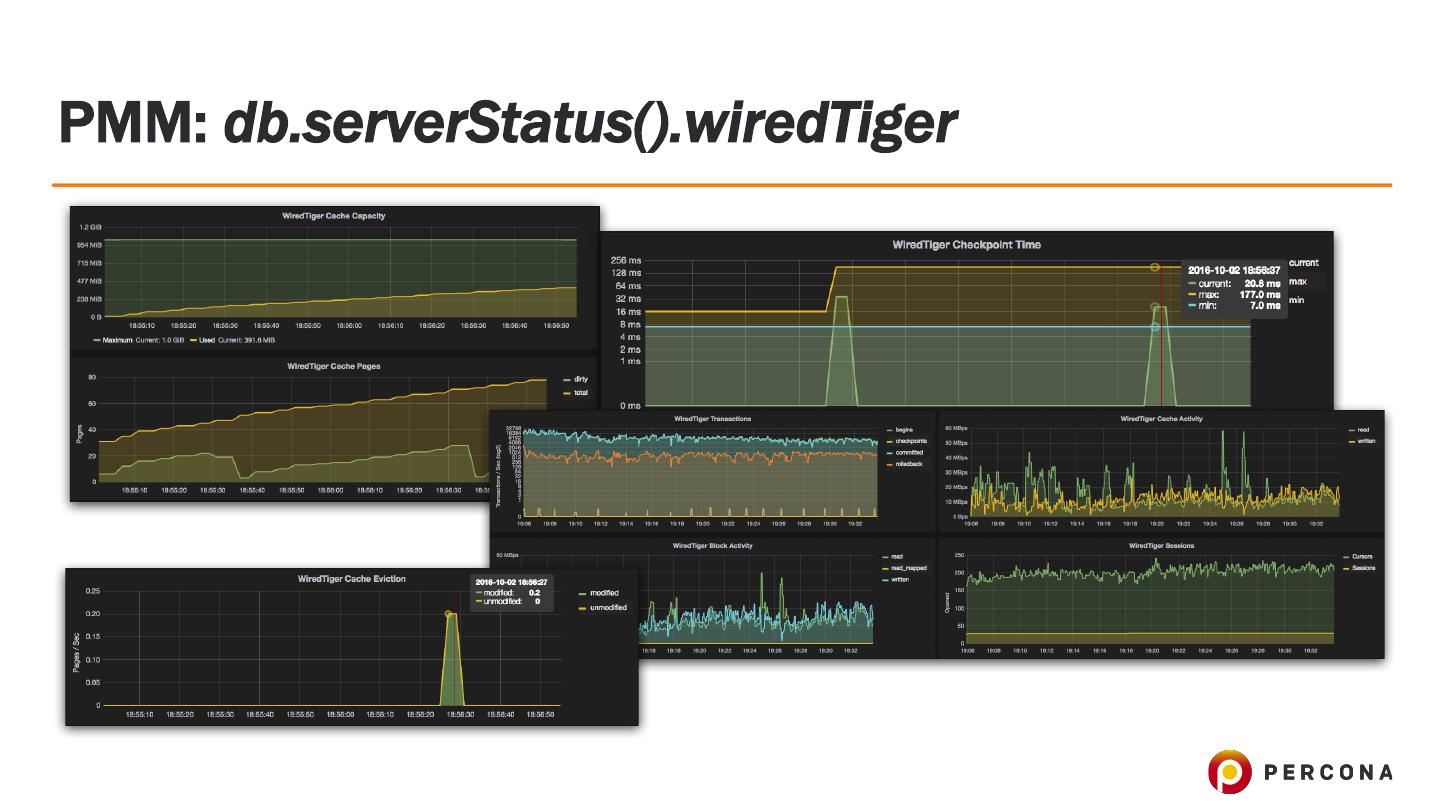
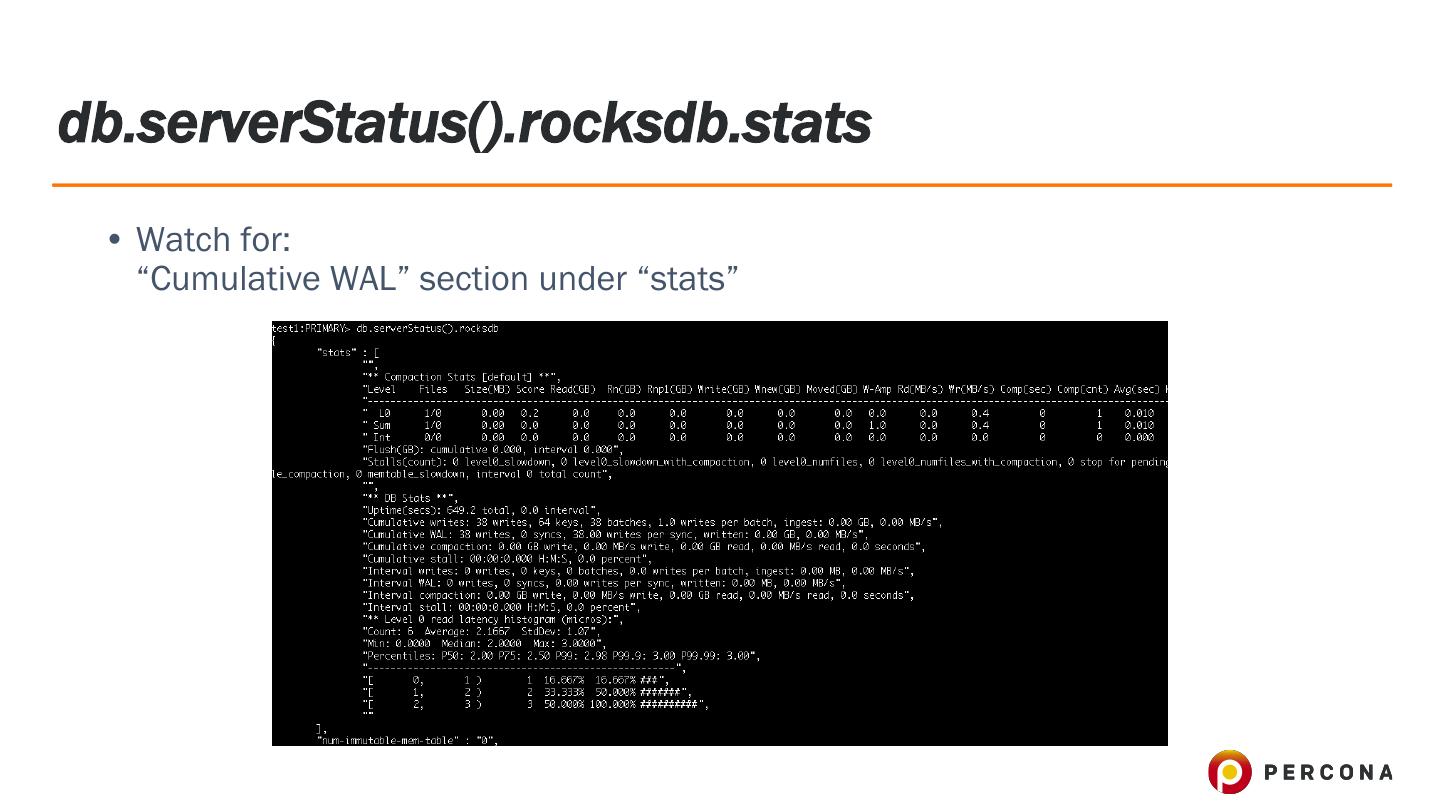
29 .db.serverStatus().wiredTiger.log • ‘log’ • Watch for the metrics: • “log sync operations” • “log sync time duration (usecs)” • and “block-manager” section of WiredTiger stats
3秒后跳转登录页面
去登陆

