






































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Supercharge Your Analytics with ClickHouse
Clickhouse是一个实时分析数据库系统。尽管他们仅仅庆祝作为开源软件的一年,但事实证明,它已经准备好应对严重的工作负载。
我们将讨论一下一般的Clickhouse,一些内部机制,以及它为什么这么快。Clickhouse与MySQL(传统上在分析工作负载上很弱)协同工作,本演示文稿演示了如何使两个系统协同工作。
展开查看详情
1 . Supercharge Your Analytics with ClickHouse Webinar September 14th, 2017 Vadim Tkachenko CTO, Percona Alexander Zaitsev CTO, Altinity 1 © 2017 Percona
2 .Analytic database landscape 2 © 2017 Percona
3 . Vertica RedShift Commercial solutions – fast and expensive Teradata • Etc The cost scales with your data 3 © 2017 Percona
4 . InfiniDB (now MariaDB ColumnStore) Open Source: InfoBright somewhat slow, sometime buggy. GreenPlum (started as commerical) But free Hadoop systems Apache Spark 4 © 2017 Percona
5 .ClickHouse – fast and free! OpenSourced in Jun 2016 5 © 2017 Percona
6 .ClickHouse story Yandex.ru - Russian search engine Yandex Metrika - Russian “Google Analytics” Interactive Ad Hoc reports at multiple petabytes • 30+ billions of events daily No commercial solution would be cost effective and no OpenSource solution to handle this scale. That’s how ClickHouse was born 6 © 2017 Percona
7 .ClickHouse is extremely fast and scalable. "We had no choice, but make it fast" by ClickHouse developers 7 © 2017 Percona
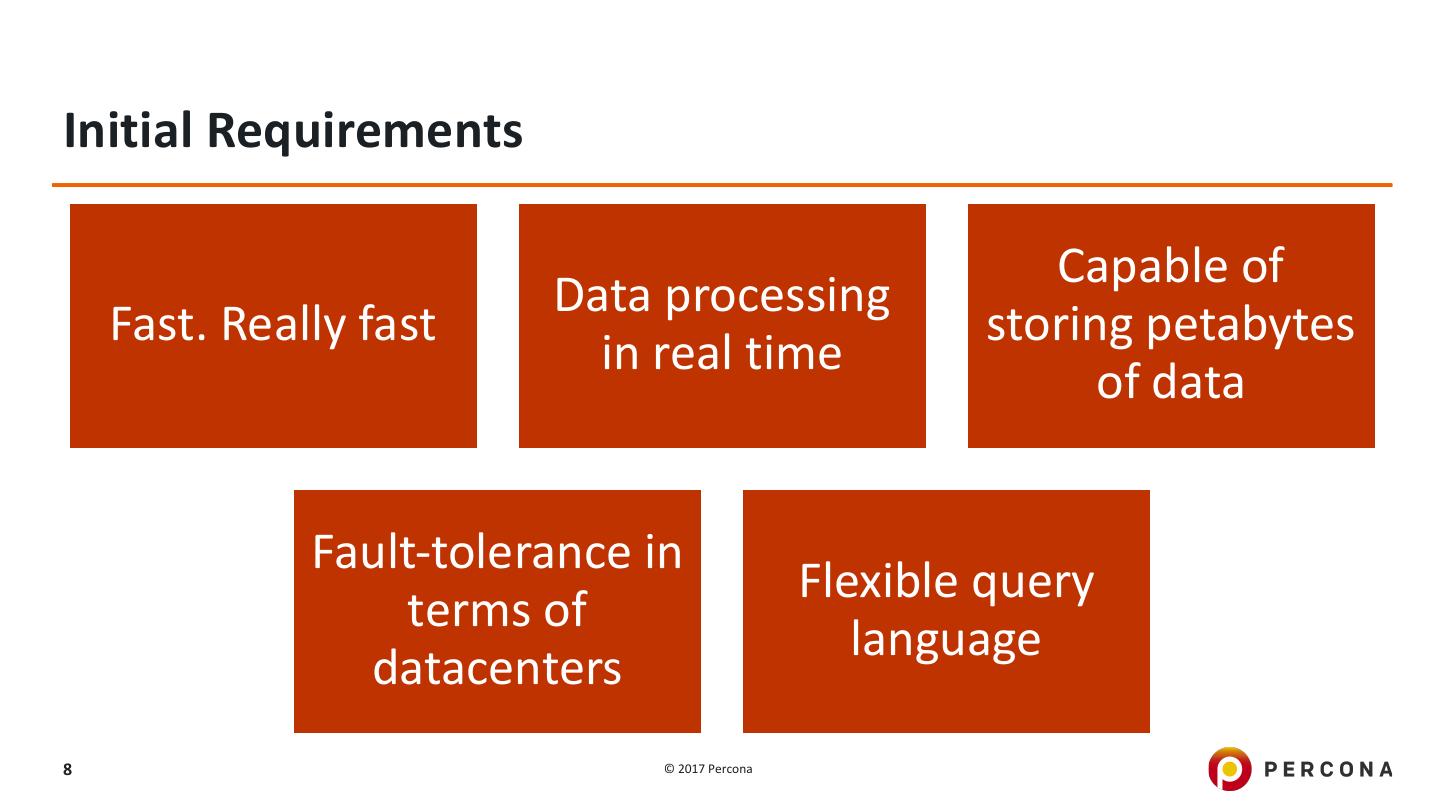
8 .Initial Requirements Capable of Data processing Fast. Really fast storing petabytes in real time of data Fault-tolerance in Flexible query terms of language datacenters 8 © 2017 Percona
9 .Technical details Vectorized processing Massively Parallel Processing Shared nothing Column store with late materialization (like C-Store and Vertica): • Data compression • Column locality • No random reads (more in details, in Russian, https://clickhouse.yandex/presentations/meetup7/internals.pdf) 9 © 2017 Percona
10 .Vectorized processing Data is represented as small single-dimensional arrays (vectors), easily accessible for CPUs. The percentage of instructions spent in interpretation logic is reduced by a factor equal to the vector- size The functions that perform work now typically process an array of values in a tight loop Tight loops can be optimized well by compilers, enable compilers to generate SIMD instructions automatically. Modern CPUs also do well on such loops, out-of-order execution in CPUs often takes multiple loop iterations into execution concurrently, exploiting the deeply pipelined resources of modern CPUs. It was shown that vectorized execution can improve data-intensive (OLAP) queries by a factor 50. 10 © 2017 Percona
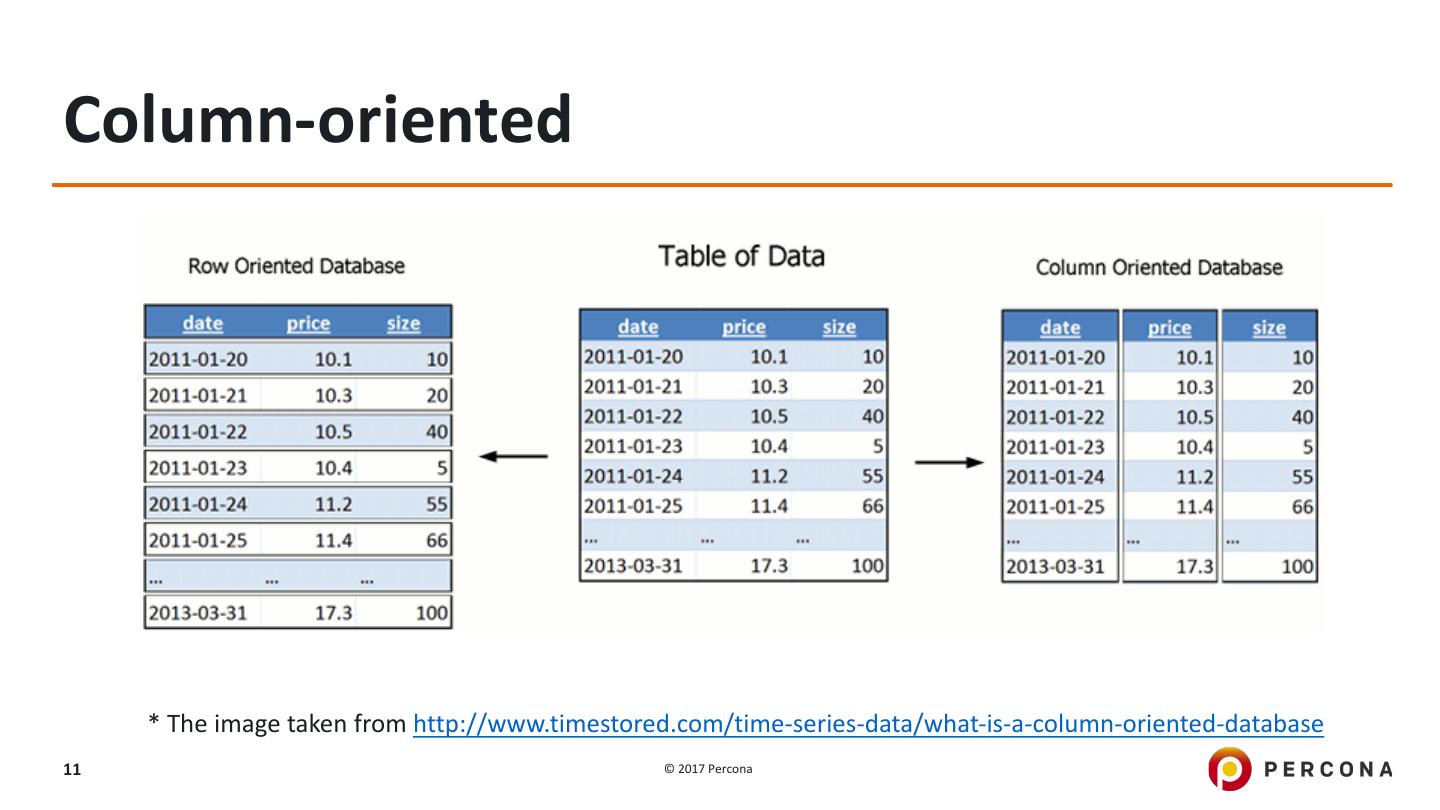
11 .Column-oriented * The image taken from http://www.timestored.com/time-series-data/what-is-a-column-oriented-database 11 © 2017 Percona
12 .Efficient execution SELECT Referer, count(*) AS count FROM hits WHERE CounterID = 1234 AND Date >= today() - 7 GROUP BY Referer ORDER BY count DESC LIMIT 10 (* example from https://clickhouse.yandex/presentations/meetup7/internals.pdf) Read only With index Vectorized needed columns: (CounterID, Date) Compression processing CounterID, - fast discard of Referer, Date unneeded blocks 12 © 2017 Percona
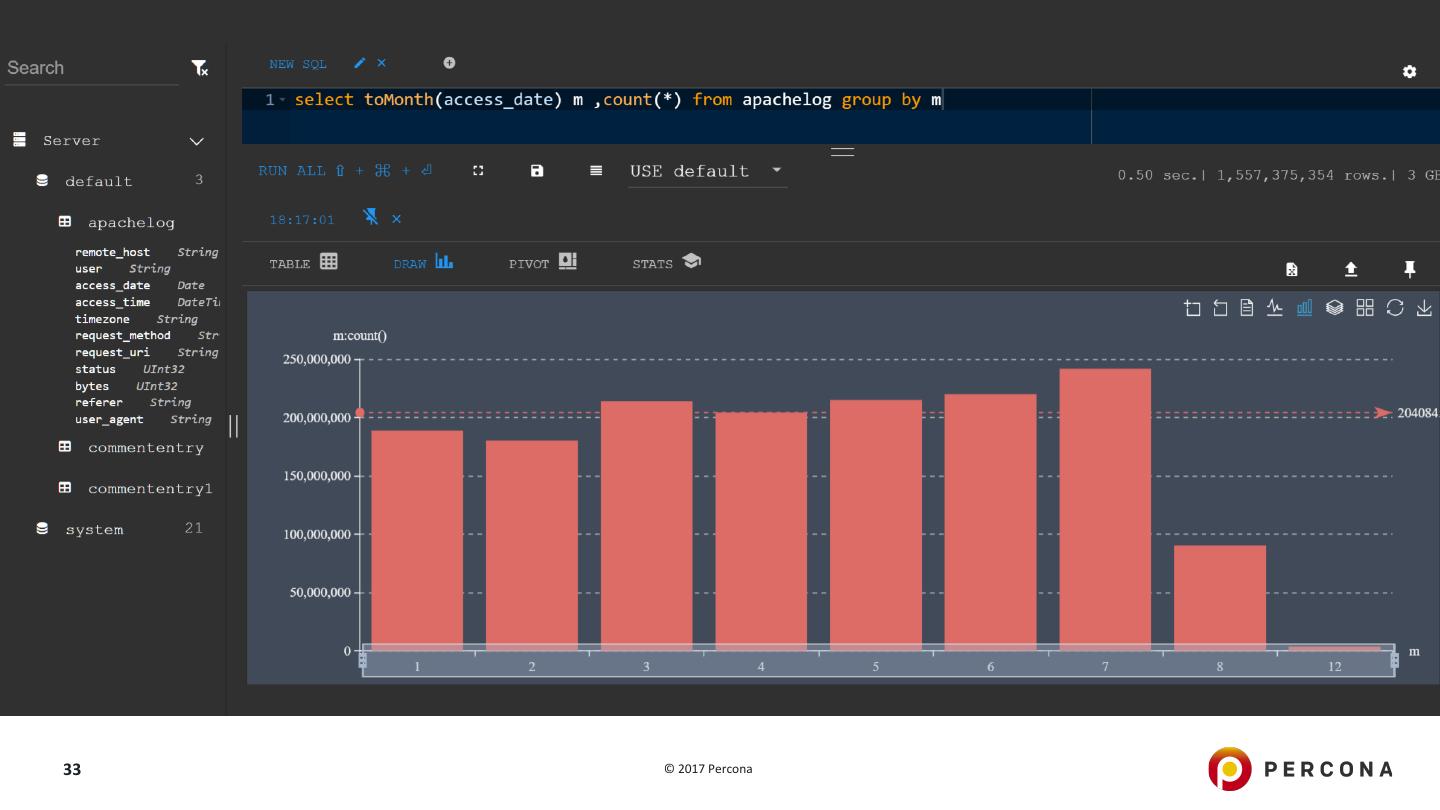
13 .Single Server - MPP Use multiple CPU cores on the single server Real case: Apache log from the real web site – 1.56 billion records Query: SELECT extract(request_uri,'(w+)$') p,sum(bytes) sm,count(*) c FROM apachelog GROUP BY p ORDER by c DESC limit 100 Query is suited for parallel execution – most time spent in extract function 13 © 2017 Percona
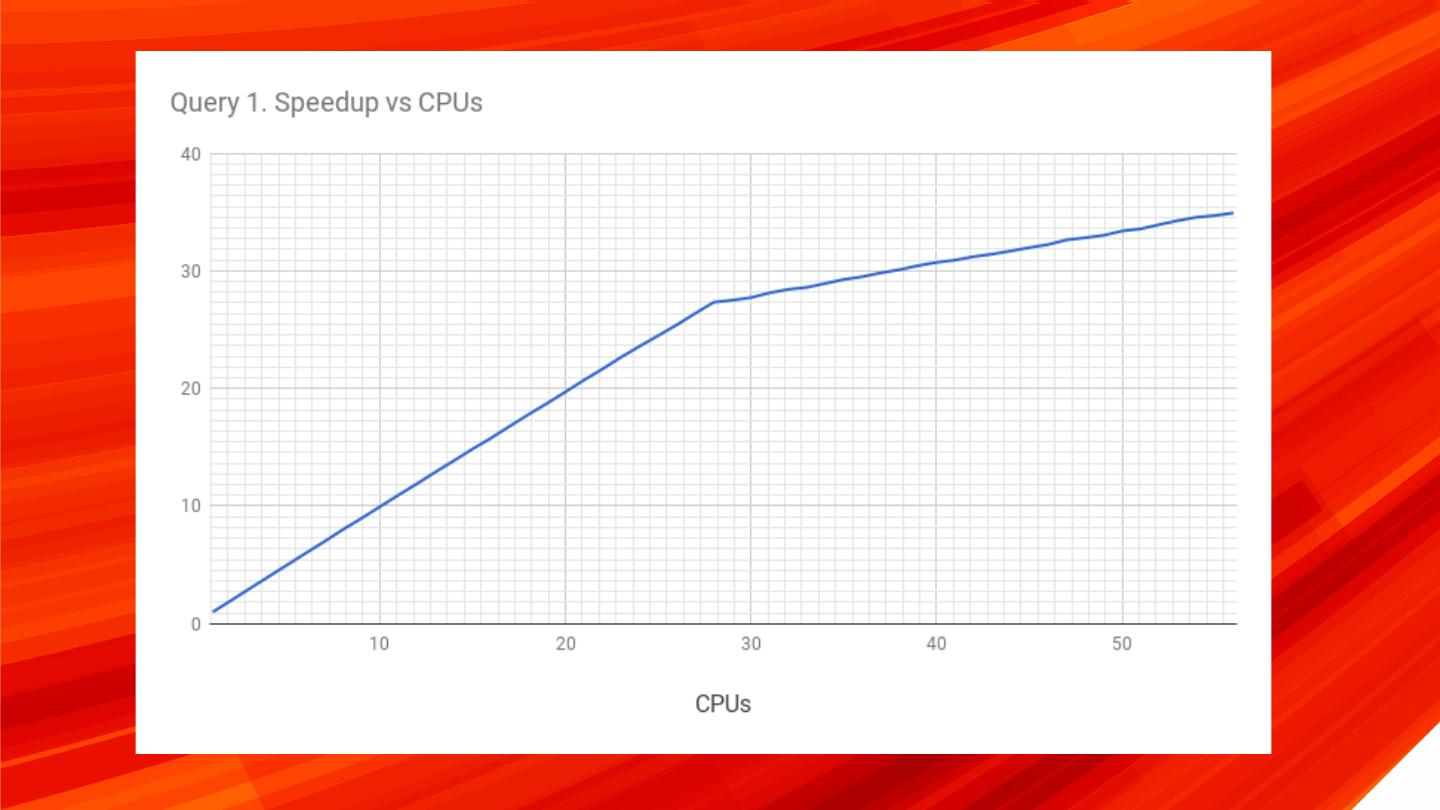
14 .Execution on single server 56 threads / 28 cores | Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz Query execution time With 1 thread allowed: 823.646 sec ~ 1.89 mln records/sec With 56 threads allowed: 23.587 sec ~ 66.14 mln records/sec Speedup: 34.9x times 14 © 2017 Percona
15 . DATABASE PERFORMANCE Database Performance Matters MATTERS
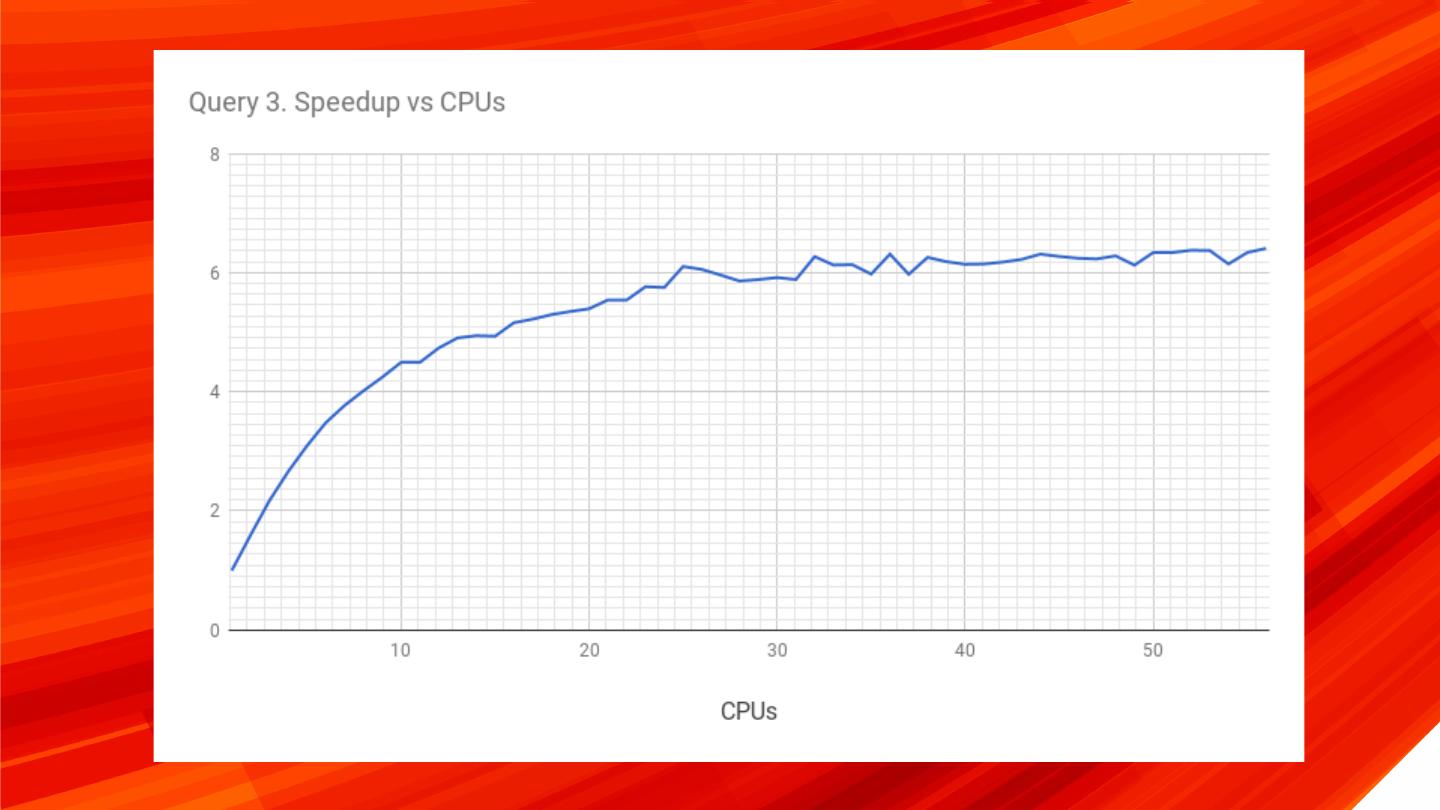
16 .Query 3 SELECT y, request_uri, cnt FROM ( SELECT access_date y, request_uri, count(*) AS cnt FROM apachelog GROUP BY y, request_uri ORDER BY y ASC ) ORDER BY y,cnt DESC LIMIT 1 BY y Less suitable for parallel execution – serialization to build a temporary table for internal subquery Speedup: 6.4x times 16 © 2017 Percona
17 . DATABASE PERFORMANCE Database Performance Matters MATTERS
18 .More details in the blog post: https://www.percona.com/blog/2017/09/13/massive-parallel-log- processing-clickhouse/ 18 © 2017 Percona
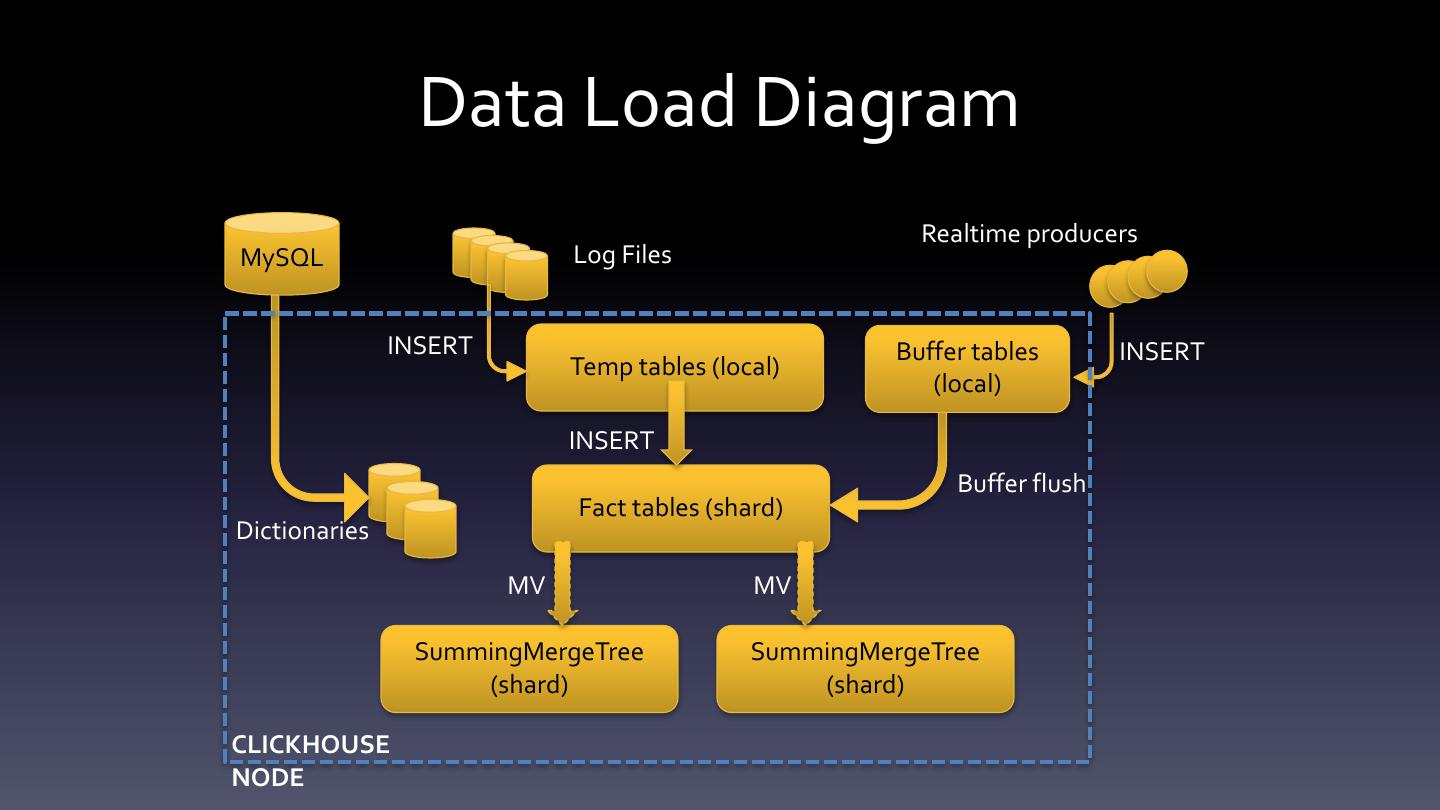
19 .Data distribution If a single server is not enough 19 © 2017 Percona
20 .Distributed query SELECT foo FROM distributed_table SELECT foo FROM local_table GROUP BY col1 • Server 1 SELECT foo FROM local_table GROUP BY col1 • Server 2 SELECT foo FROM local_table GROUP BY col1 • Server 3 20 © 2017 Percona
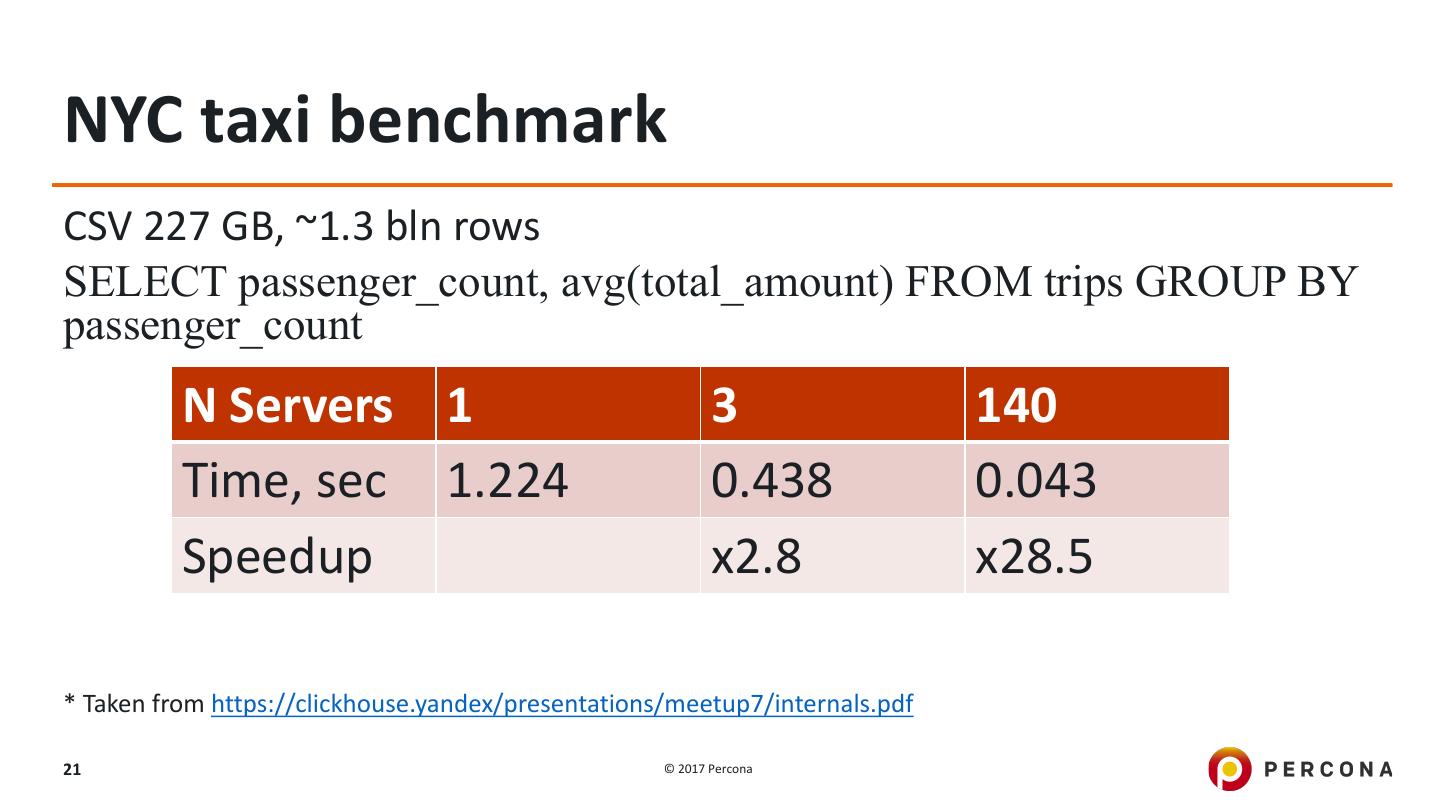
21 .NYC taxi benchmark CSV 227 GB, ~1.3 bln rows SELECT passenger_count, avg(total_amount) FROM trips GROUP BY passenger_count N Servers 1 3 140 Time, sec 1.224 0.438 0.043 Speedup x2.8 x28.5 * Taken from https://clickhouse.yandex/presentations/meetup7/internals.pdf 21 © 2017 Percona
22 .Reliability Any number of replicas Any replication topology Multi-master Cross-DC Asynchronous (for speed) • è Delayed replicas, possible stale data reads • More on data distribution and replication https://www.altinity.com/blog/2017/6/5/clickhouse-data- distribution 22 © 2017 Percona
23 .Benchmarks! 23 © 2017 Percona
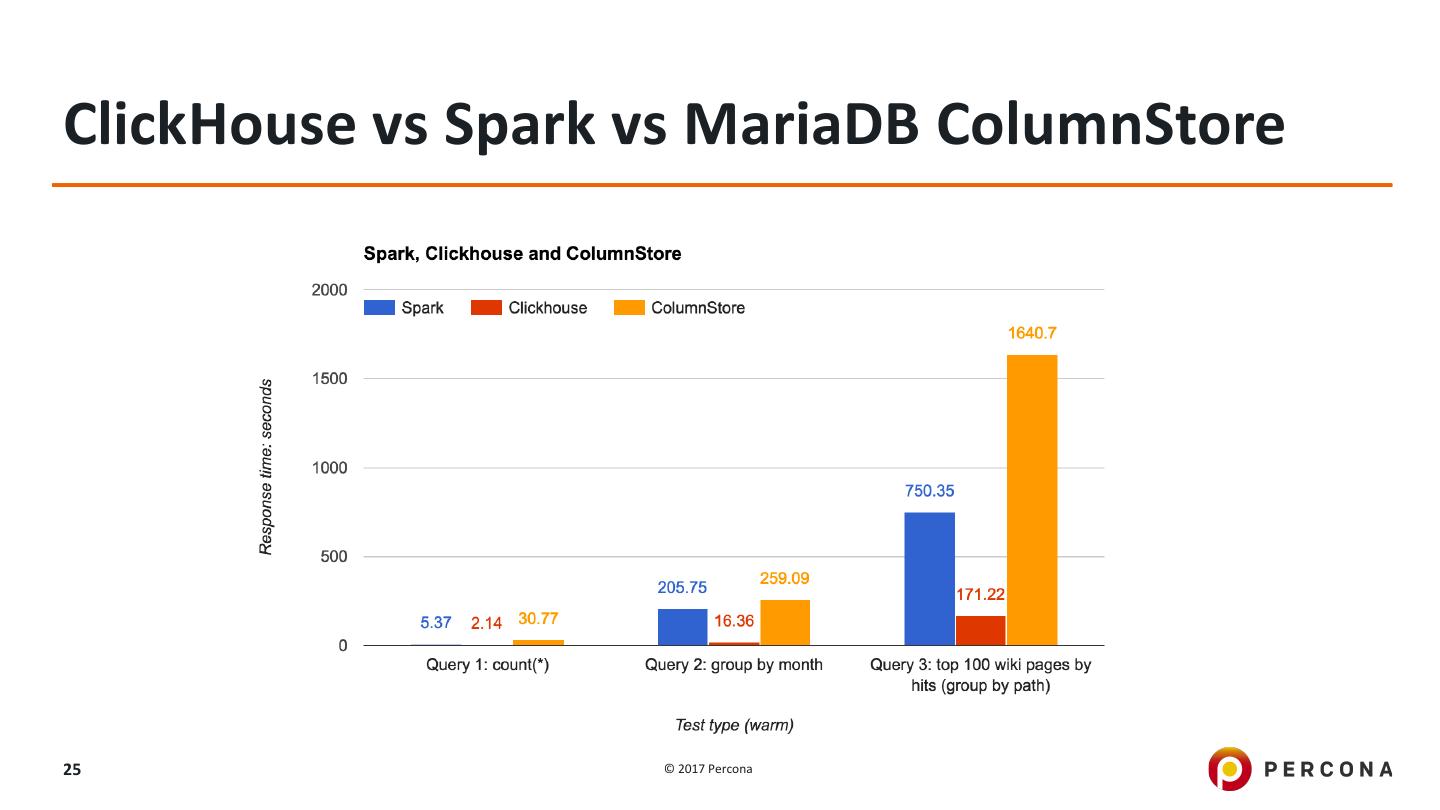
24 .ClickHouse vs Spark vs MariaDB ColumnStore Wikipedia page Counts, loaded full with the year 2008, ~26 billion rows https://www.percona.com/blog/2017/03/17/column-store-database-benchmarks- mariadb-columnstore-vs-clickhouse-vs-apache-spark/ 24 © 2017 Percona
25 .ClickHouse vs Spark vs MariaDB ColumnStore 25 © 2017 Percona
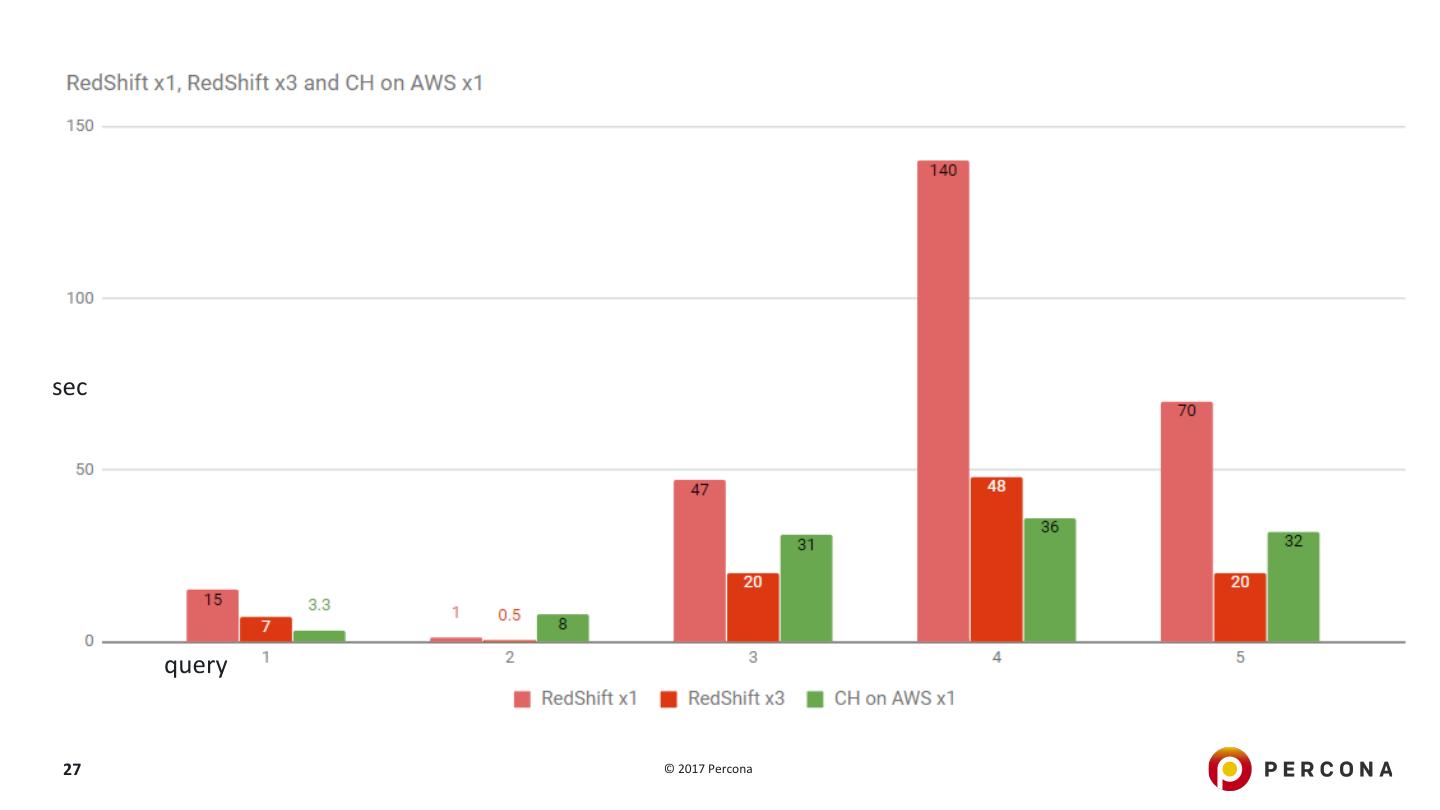
26 .Cloud: ClickHouse vs RedShift https://www.altinity.com/blog/2017/6/20/clickhouse-vs-redshift 5 queries based on NYC taxi dataset Query 1: SELECT dictGetString('taxi_zones', 'zone', toUInt64(pickup_location_id)) AS zone, count() AS c FROM yellow_tripdata_staging GROUP BY pickup_location_id ORDER BY c DESC LIMIT 10 RedShift 1 instance / 3 instances of ds2.xlarge (4 vCPU / 31 GiB memory) ClickHouse 1 instance r4.xlarge (4 vCPU / 30.5 GiB memory) 26 © 2017 Percona
27 .seconds sec query query 27 © 2017 Percona
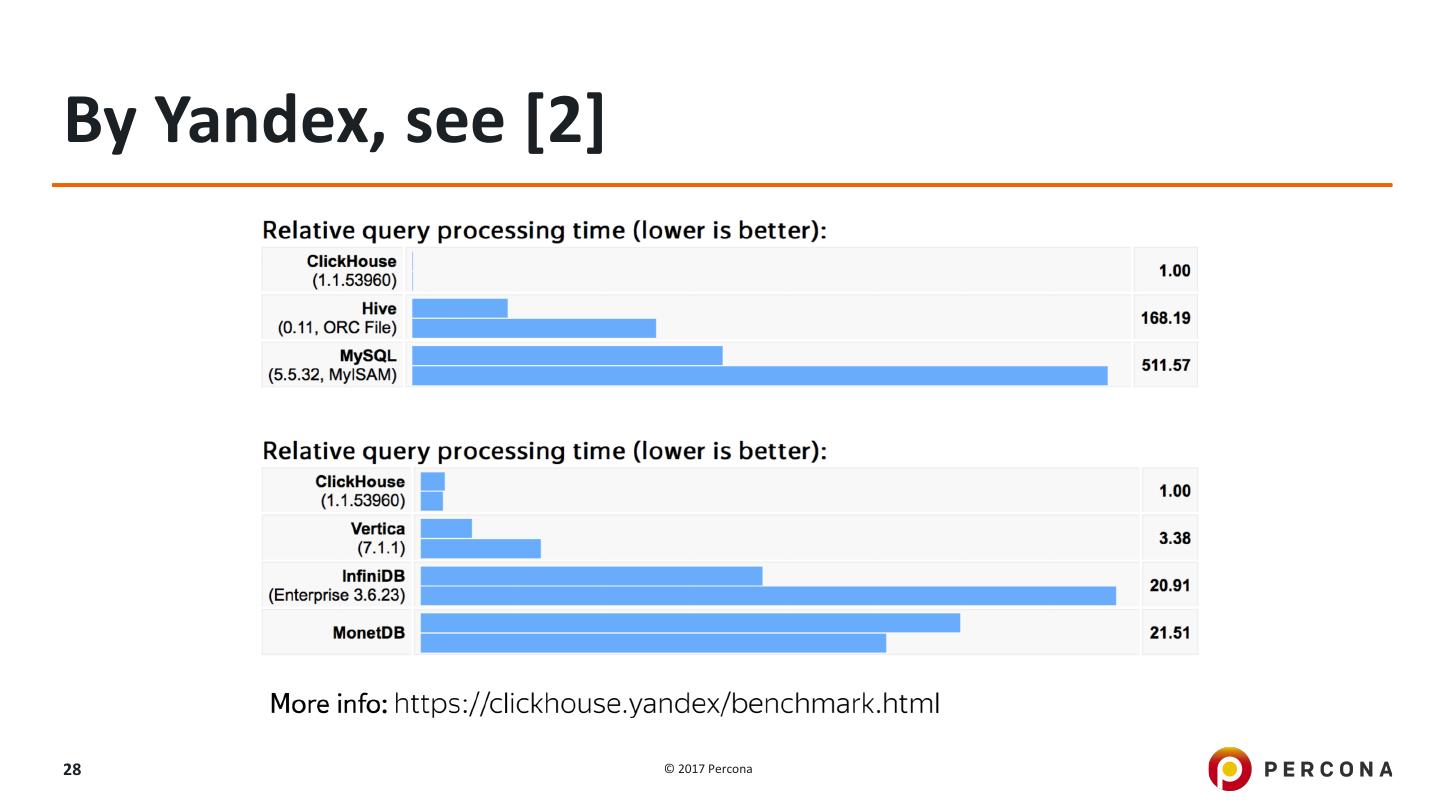
28 .By Yandex, see [2] 28 © 2017 Percona
29 .ClickHouse – use cases Adv networks data Web/App analytics Ecommerce/Telecom logs Online games Sensor data Monitoring 29 © 2017 Percona
3秒后跳转登录页面
去登陆

