


















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Efficient CRUD Queries in MongoDB
MongoDB有自己的命令和函数结构,要求数据库工作。在本文中,我们将讨论查询、更新、删除和插入是如何工作的。然而,我们将超越这些操作,并回顾您应该和不应该使用哪些操作符,以及它们实际上如何驱动您的模式选择。然后,我们将讨论在您想要限制对生产的影响时批量删除和插入的操作上合理的方法(如果其他工具可能过于激进的话)。
展开查看详情
1 .Efficient CRUD Queries in MongoDB Tim Vaillancourt Sr. Technical Operations Architect Percona
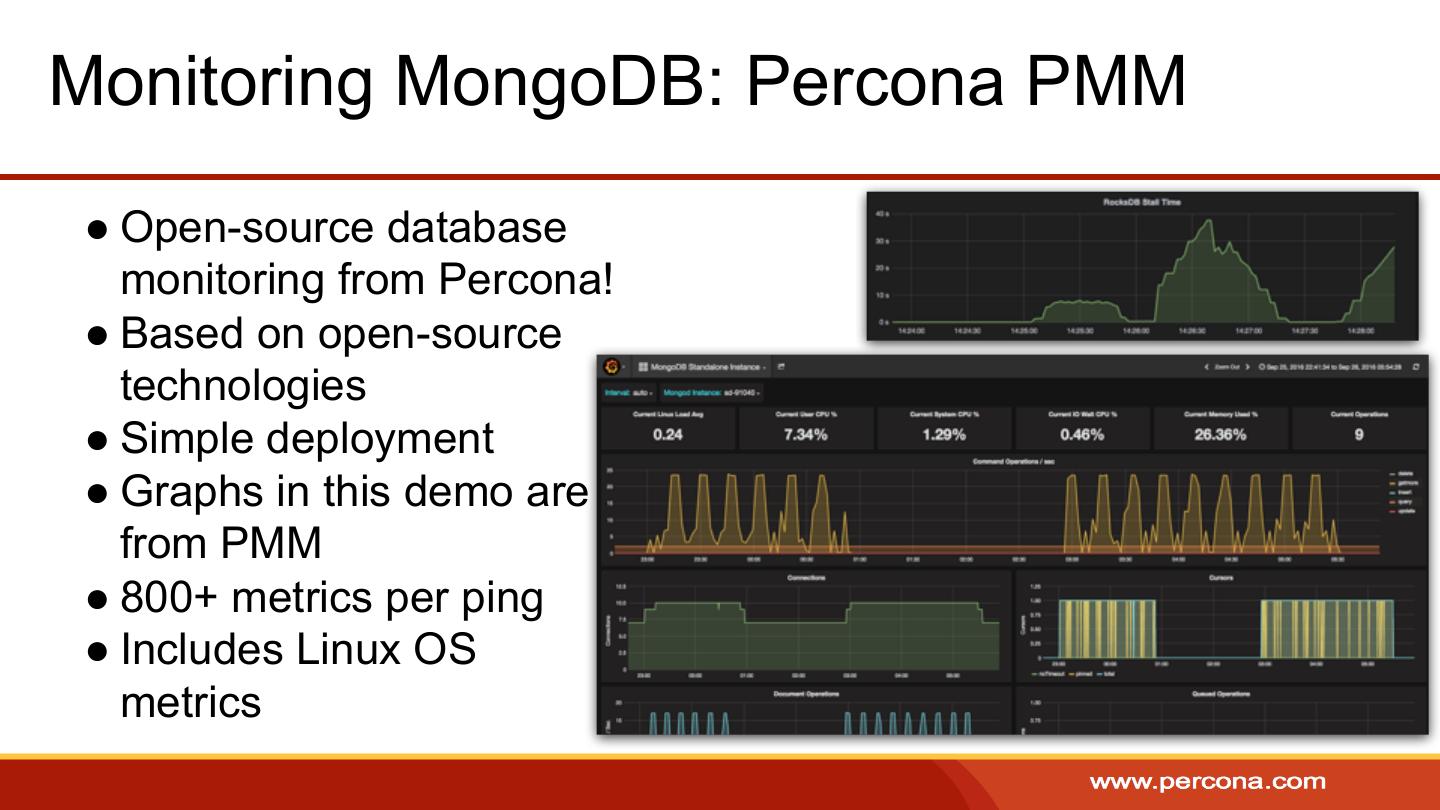
2 .Agenda ●What is CRUD? ●CRUD-related MongoDB Features ●Troubleshooting ○ Explain ○ Database Profiler ○ Log File ●Read Preference ●Read and Write Concerns ●Deletion/Retention Strategies ●Monitoring
3 .About Me ●Started at Percona in January 2016 ●Experience ○ Web Publishing ■ Big-scale LAMP-based web infrastructures ○ Ecommerce ■ Large Inventory SaaS at Amazon / AbeBooks ○ Gaming ■ DevOps / NoSQL DBA at EA SPORTS ■ DBA at EA DICE
4 .About Me ○ Technologies ■ MongoDB, Cassandra and Couchbase ■ MySQL ■ Redis and Memcached ■ RabbitMQ, Kafka and ActiveMQ ■ Solr and Elasticsearch ■ Mesos ■ (Non-tech) Distributed Systems and Infrastructure Architecture
5 .Terminology ● What is CRUD? ○ Create ■ Operations that create entire documents, eg: .insert() ■ Relatively light operation with low cache/disk IO impact ○ Read ■ Operations that read documents, eg: .find(), .aggregate(), … ■ Generally the main source of slowness
6 .Terminology ● What is CRUD? ○ Update ■ Operations that find and replace data, eg: .update() ■ Expensive, operates similar to a .find() and updates data after ○ Delete ■ Operations that remove documents, eg: .remove()
7 .Terminology ● Document - a single MongoDB document (JSON/BSON) ● Collection - a collection of documents, similar to “table” ● Database - a grouping of MongoDB collections ● Index - a BTree Index applied to a MongoDB collection ● CRUD? ○ Create: operations that create documents, eg: .insert() ○ Read: operations that read documents, eg: .find(), .aggregate(), … ○ Update: operations that find and replace data, eg: .update() ○ Delete: operations that deletes documents, eg: .delete()
8 .Terminology ● What is efficient CRUD? ○ Use the minimal server resources possible ○ Scalable ● Metrics ○ keysExamined - # of Index items examined ○ docsExamined - # of Documents (cache or disk) examined ○ Nreturned - # of Documents returned to client ● Lag ○ The delay seen in reading data from a replication replica
9 .Storage Engines ● MMAPv1: Default in 1.x and 2.x ○ Good read performance, poor write performance ○ No compression ○ Collection-level Locking(!) ● WiredTiger: Default in 3.2+, available since 3.x ○ Good read performance, good write performance ○ Compression supported ● RocksDB: Available in Percona Server for MongoDB (or patch) ○ Good 95%~ read performance, very good write performance ○ Compression supported
10 .Isolation and Atomicity ● Isolation ○ Read Uncommitted ■ Any session can see a change, even before ack’d ■ Essentially no isolation compared to RDBMs ○ Atomicity ■ Single-document Update ● A reader will never see a partially-changed document ■ Multi-document Update ● Multi-operation not atomic, no rollback
11 .Replication ● Async changelog replication ● Primary ○ Single Primary via election ○ Serves Read and Write operations ● Secondary ○ One or more, three required for reliable elections ○ Serves Read queries only ○ May take-over Primary in election ● Consistency ○ Driver-level tunables for Read and Write consistency(!)
12 .Insert Operations ● A Single-document Insert triggers: ○ 1 x append to the journal ○ 1 x document to be added to the data file(s) ○ MMAPv1 Considerations ■ MMAP will scan for a free slot for the insert ■ Shown as the “nmoved” metric ● Multi-document Insert Operations ○ Can be used to batch inserts ○ Improves insert performance in many cases ○ Can be ordered <true/false> in options document
13 .Insert Operations ● Write Concern accepted ● RocksDB or WiredTiger recommended for high write volumes
14 .Insert Operations Example: db.users.insert([ { “username”: “tim”, “password”: 123456, “createDate”: new Date(), }, { ... } ], { “writeConcern”: { w: ”majority” }, ordered: true })
15 .Read Operations ● .find() ○ Returns cursor of document(s) matching a set of conditions ○ Option to specify which fields to return, default: full doc! ● .aggregate() ○ Powerful framework for data aggregations, summaries, etc ○ No .explain() support ○ Scans entire collection unless using a $match as first stage ■ db.<coll>.find(<$match conditions>).explain() to explain! ● .mapReduce() ○ Runs in JavaScript and offers little insight
16 .Read Operations ● Read Concern ○ Important for strict data integrity (often combined with WCs) ■ Replica Set failovers can cause some data “rollback” ● “Rolledback” data is written to a json file in your dbPath ○ Tunable read consistency ■ “local” = default, local node read only ■ “majority” = read from a majority of members ■ “linearizable” = read and ack’d from a majority of members ○ RC can be changed per query
17 .Read Operations ● Example: test1:PRIMARY> db.getMongo().setReadPref('primary') test1:PRIMARY> db.pages.find({title : "Geography of Guinea-Bissau"}, {_id: 1, title: 1}).pretty() { "_id" : "0c25a313481757720f5e9e46b4cffddd08a13fef", "title" : "Geography of Guinea-Bissau" }
18 .Update Operations ● Operates much like a .find() with special re-insertion ● Cannot run .explain() on .update() ○ Convert the .update() match to a .find(<conds).explain() ● Can change one or more documents ○ { multi: true } option required for multi-document updates ○ Avoid Multi-document updates if possible ● MMAPv1 Considerations ○ In many cases MMAP can do in-place updates (no replace) ● Provides many update operators to change the data ○ Examples: $set, $inc, $mul, $min, $max
19 .Update Operations ● Efficient Updates ○ Use indexes on the match condition (very crucial) ○ Avoid multi-document updates in your design
20 .Update Operations ● Example: test1:PRIMARY> db.pages.update( {title : "Geography of Guinea-Bissau"}, {$set: {title: "Geography of Guinea-Bisso"} }) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
21 .Delete Operations ● Similar in execution impact to an .update() ● Accepts array of delete conditions (batching) ● Using TTL Index to Delete ○ Deletes documents based on MongoDB ISODate() objects ○ Batches deletes by minute (by default) ○ Doubles as an index for the date field ● Batch delete by field ○ Mark a field as {deleted:true} ○ Run controlled batch job to .remove({deleted:true}) ○ Requires some scripting / cronjob
22 .Delete Operations ● RocksDB Considerations ○ Compaction may struggle with very high delete volume ○ “Toombstones” are written in place of the document ■ Considered by read operations until compaction
23 .Delete Operations ● Example: test1:PRIMARY> db.pages.remove({title : "Geography of Guinea-Bisso"}) WriteResult({ "nRemoved" : 1 })
24 .Indexing ● MongoDB supports BTree, text and geo indexes ● Default behaviour ● Collection lock until indexing completes ● {background:true} ○ Runs indexing in the background avoiding pauses ○ Hard to monitor and troubleshoot progress ○ Unpredictable performance impact ● Avoid drivers that auto-create indexes. Use real performance data ● Too many indexes hurts performance ● Indexes have a forward or backward direction
25 .Indexing ● Compound Indexes ○ Several fields supported ○ Fields can be in forward or backward direction ■ Consider any .sort() query options and match sort direction! ○ Read Left -> Right ■ Index can be partially-read ■ Left-most fields do not need to be duplicated, example: You have an index with fields: {status:1, date:1} and a 2nd with: {status:1}. {status:1} is duplicated!
26 .Indexing ● Get Indexes Example: test1:PRIMARY> db.pages.getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "wikipedia.pages" } ]
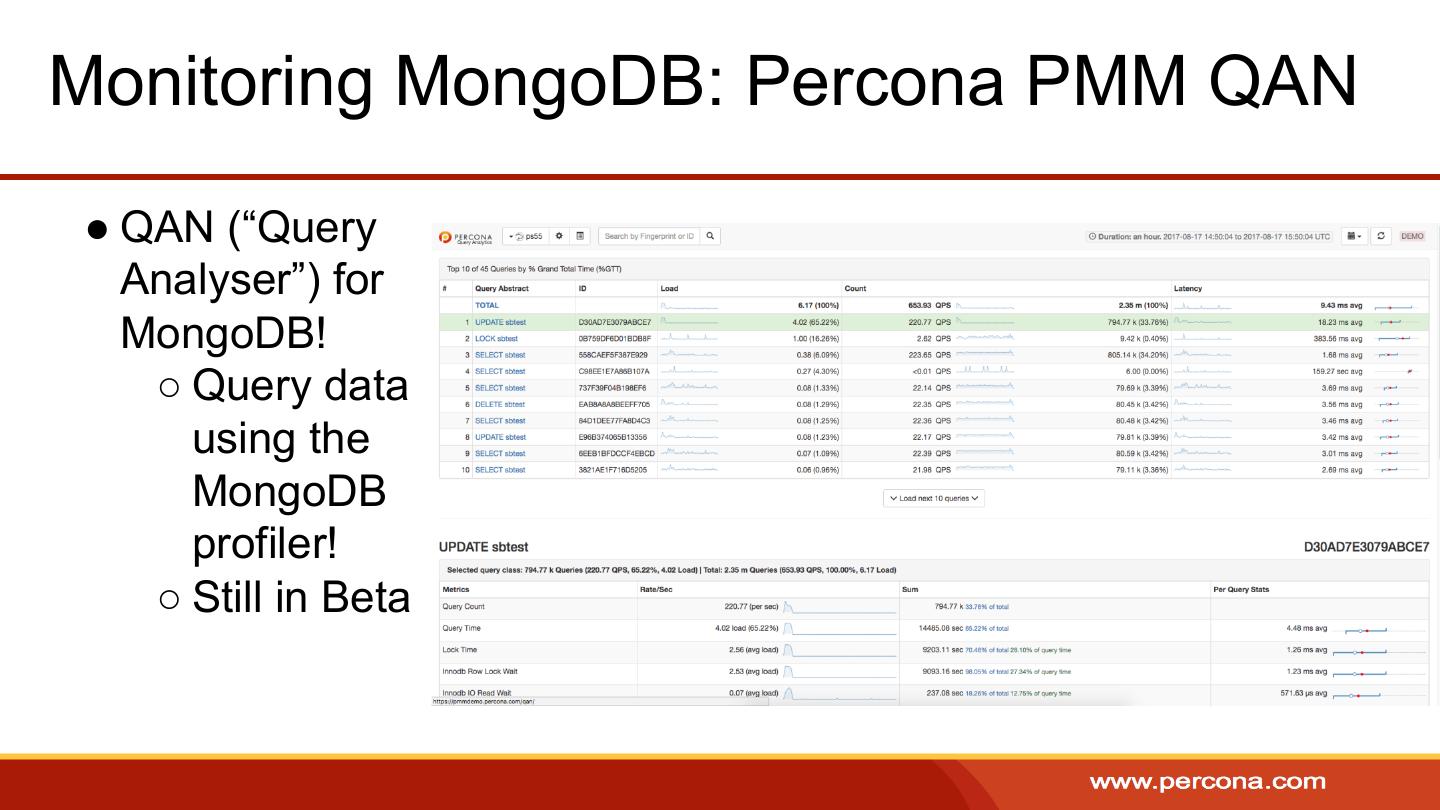
27 .Operation Profiling ● Writes slow database operations to a new MongoDB collection for analysis ○ Capped Collection: “system.profile” in each database, default 1mb ○ The collection is capped, ie: profile data doesn’t last forever ○ Enable operationProfiling in “slowOp” mode ■ Start with a very high threshold and decrease it in steps Usually 50-100ms is a good threshold Enable in mongod.conf operationProfiling: slowOpThresholdMs: 100 mode: slowOp
28 .Operation Profiling ● op/ns/query: type, namespace and query of a profile ● keysExamined: # of index keys examined ● docsExamined: # of docs examined to achieve result ● writeConflicts: # of WCE encountered during update ● numYields: # of times operation yielded for others ● locks: detailed lock statistics
29 ..explain() and Profiler ● .explain() Example: Profiler:
3秒后跳转登录页面
去登陆

