




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cloud-Native Database
在我们在Percona Live 2019上的演讲中,Intel及其软件合作伙伴将向观众介绍我们为实现开源框架所做的工作,我们称之为云原生数据库(CNDB)。这是Intel、Rockset、Planetscale、Mariadb和Percona之间的合作。英特尔为什么要做这个演讲?我们相信这样的开源CNDB是对Intel Optane DC持久内存、基于QLC NAND的NVME和Cascade Lake CPU产品的完美补充。
在过去的几年中,我们已经与许多公司和行业的数据库从业人员进行了交谈。从这些讨论中得出的结论是,对开源的需求相当于一个云原生数据库,比如亚马逊的Aurora、Facebook的MySQL和Azure的CosmosSDB。在本文中,您将了解我们为使这样一个开放源码的云本地数据库对社区可用所做的努力。
通过演示,将向观众介绍一组原则和架构元素,这些原则和架构元素定义了云本机数据库的含义。我们将讨论Rockset的RockSDB云库以及它如何与Facebook的MyLocks存储引擎一起工作。我们还将介绍Planetscale的vitess项目及其在部署数据库即服务(dbaas)机制时使用kubernetes的情况。最后,我们共享有关我们开发的体系结构和组件的性能和规模特征的数据。
展开查看详情
1 .Cloud-Native Database Yekesa Kosuru - Managing Director/Database Engineering, State Street Jitendra Vaidya - CEO, PlanetScale Steve Shaw, Database Engineer, Intel David Cohen – Storage Solutions CTO & Sr. PE., Intel
2 .Agenda • Principles of a Cloud-Native Database • Key Components of the Implementation • Basic Mechanics • Intel’s Data Management Platform (DMP) • Future Work • Q&A 2
3 . Principles of a Cloud Native Database This section presents the principles and design of an open-source, Cloud-Native Database
4 .Principles of a Cloud Native Database Postulate 1 – Separate Performance (“A,” “C”, & “I” in ACID) from Durability (“D” in ACID) Performance is concerned with placing computation and data near the CPU. Durability is concerned with persisting data (and software) in a crash consistent manner through some form of logging and secondly, maintaining snapshot images to optimize recovery. Postulate 2 – Leverage Vertical Tiering These separate concerns are addressed as tiers in a vertical tiering scheme. For simplicity let’s call the top tier memory and the bottom tier storage. All external access to the database is serviced by/routed through the Memory tier. Postulate 3 - Use of Shared Storage rather than Shared-Nothing Storage A workload’s durable state is refactored to reside on network-accessible, Shared- Storage. Only processes in the Memory tier of the Database have access to the Storage tier. Postulate 4 – Workload Scheduling to manage both Supply & Demand Exploit scheduling to prioritize work during peak load periods and scavenge cycles to fill in demand valleys with idle supply. Postulate 5 - Improve Price-Performance compared to pre-Cloud-Native Database The goal of adhering to these principles is to maintain a price/performance balance. [Arpaci-Dusseau/HotCloud '18] Arpaci-Dusseau et al, "Cloud-native file systems," 2018 [Sreekanti/VLDB ‘19] Sreekanti, "Autoscaling Tiered Cloud Storage in Anna," 2019 https://dl.acm.org/citation.cfm?id=3277195 https://rise.cs.berkeley.edu/blog/publication/autoscaling-tiered-cloud-storage-in-anna/
5 . Data Caching Systems – Exploiting Slow Memory MyRocks CosmosDB low cost acceptable cost high cost poor performance ‘good-enough’ performance high performance ✗ ✗ perf alignment Somewhere cost alignment Disk-based -in- Memory-based shifting right shifting left Between Data Caching System (Traditional) Data Caching System (Next-Gen) Data Memory Store • Database resides on secondary storage • Database spans memory and storage • Database fits in main memory • Data read into main memory only when • latch-free access to data structures • Accesses are much faster. operated on. • dramatically shrink write I/O via the use of • latch-free access to data structures • Low performance log-structuring techniques. • High Cost. [Lomet/DAMON '18] Lomet, "Cost/performance in modern data stores: how data caching systems succeed," 2018 https://dl.acm.org/citation.cfm?id=32119272
6 .Initial Focus MariaDB, Percona Server, and their Respective MyRocks Distributions 1. Berkeley/RiseLabs’ Anna project 2. Cloud-Native Database (CNDB) kubernetes Prometheus/EFK Vitess Vitess Vitess … Memory Tier MariaDB/Percona MariaDB/Percona MariaDB/Percona … MyRocks MyRocks MyRocks Storage Tier s3-like Store s3-like Store s3-like Store … s3 Bucket s3 Bucket s3 Bucket Wu et al, "Autoscaling tiered cloud storage in Anna,” 2019 Verbitski et al, "Amazon Aurora: Design Considerations for High https://dl.acm.org/citation.cfm?id=3322438 Throughput Cloud-Native Relational Databases,” 2017 https://dl.acm.org/citation.cfm?id=3056101
7 .Overview of Key Features • Vertical Tiering • multiple storage tiers, each with a different cost-performance tradeoff. • Memory tier (close to the CPU) • exploit Persistent Memory, initially for disabling page-oriented caches and enabling nvram semantics. • Storage-over-App-Direct so memtables, wal, sstable files, and one or more snapshots are all on the memory bus. • Storage tier (far from the CPU) • exploit Object Storage with synchronously distributed erasure codes to maintain consistent images of the database at a point-in-time • exploit an event stream that serves as the transaction log for cross-cluster replication and point-in-time recovery • Transparent Vertical Sharding w/Request Routing & Read-Scaling • In the Memory tier each database instance is composed of a stateless database (eg SQL) engine with a storage engine that handles the vertical tiering (see above). • Transparent Vertical Sharding • Request Routing • Read-Scaling • k8s-managed Elastic Scaling/Database Mobility • each shard guarantees 1 or more point-in-time snapshots are available on the cloud storage tier. • snapshots represent a subset of sstable files needed to restore the database to a point-in-time. • a restored database is then brought to a consistent state by replaying the log from the time the snapshot was created.
8 . Key Components of the Implementation This section presents an overview of Rockset’s RocksDB-Cloud library and PlanetScale’s Vitess project.
9 .Cloud-Native Database (CNDB) Rockset’s RocksDB-Cloud Library • Transformation to Cloud-Native • Transform a Database into a Cloud-Native Database by replacing RocksDB with RocksDB-Cloud in the Database’s Storage Engine • Consistent Image on Shared Storage (“Vertical Tiering”) • The new Storage Engine maintains a Consistent Image of the database/shard’s LSM-tree on the Network • SSTable Files in an s3-like bucket • Redo/Write-Ahead Log in a Kafka-like Event Stream • SQL Engine as a stateless Micro-Service • The Cloud Native Database engine that uses this Storage Engine is ‘Stateless;’ managing a local cache for performance and a network-resident image for durability. • Full Mobility across the Cluster • This enables Kubernetes-managed Fast Restore/Clone from the Network-resident Image • Initial focus is on OLTP (TPC-C/HammerDB) Cohen, "Rockset's RocksDB-Cloud Library - Enabling the Next Generation of Cloud Native Databases,” 2018 https://rockset.com/blog/rocksdb-cloud-enabling-the-next-generation-of-cloud-native-databases/
10 .RocksDB-Cloud extends RocksDB to Support Tiering RocksDB Updates RocksDB-Cloud* SQL Cloud Log Storage, WAL (Percona, MariaDB) writes reads Kafka* Topic Queries MyRocks memtable block cache cache RocksDB b RocksDB-cloud local-attached Persistent Flush sst file to Copy sst file to storage read cache local SSD cloud storage bin on SSD SST WAL Cloud Storage Bucket Cloud Storage
11 .Vertical Tiering RocksDB-Cloud-managed LSM-tree image WAL sstable files MemTable Cache Append-Only File Cache Cloud Storage Storage Class: DRAM Optane DCPMM Append-Only File (remote, QLC-NAND NVMe) Cloud Storage (remote, QLC-NAND NVMe) MariaDB Server [MDEV-17084] - Optimize append only files for NVDIMM https://jira.mariadb.org/browse/MDEV-17084 Roy et al, "Cyclone: High Availability for Persistent Key Value Stores,” 2017 (see specifically section 3 - Storage) https://arxiv.org/abs/1711.06964 Arulraj et al, "Multi-Tier Buffer Management and Storage System Design for Non-Volatile Memory," 2019 https://arxiv.org/abs/1901.10938
12 .Database-as-a-Service (DBaaS) Virtualizing the Database via PlanetScale’s Vitess project • Database-as-a-Service (DBaaS) Operator • Leverages Kubernetes for Scheduling/Orchestration • Multi-Tenant Database Hosting • Host multiple databases over a shared infrastructure, similar to AWS Aurora • Virtualizes a Database • presents a single database over the network • Internally, this virtual database is horizontally sharded with rows of the same table partitioned over multiple database nodes • Initial focus is on OLTP • good TPC-C/HammerDB characterization results Pavlo et al, "What's Really New with NewSQL?,” 2016 (see sections 3.2 Transparent Sharding Middleware and 3.3 Database-as-a-Service) https://dl.acm.org/citation.cfm?id=3003674
13 . Vitess Architecture App Vitess 13 PlanetScale Data Platform - Deploy, Manage, Monitor
14 . PlanetScale Architecture PlanetScale Monitoring Control Signals Watched Resource Type PlanetScale Vitess + Kubernetes Cluster Specs MySQL Web UI + Load HTTPS API Server Balancers Proxy 14
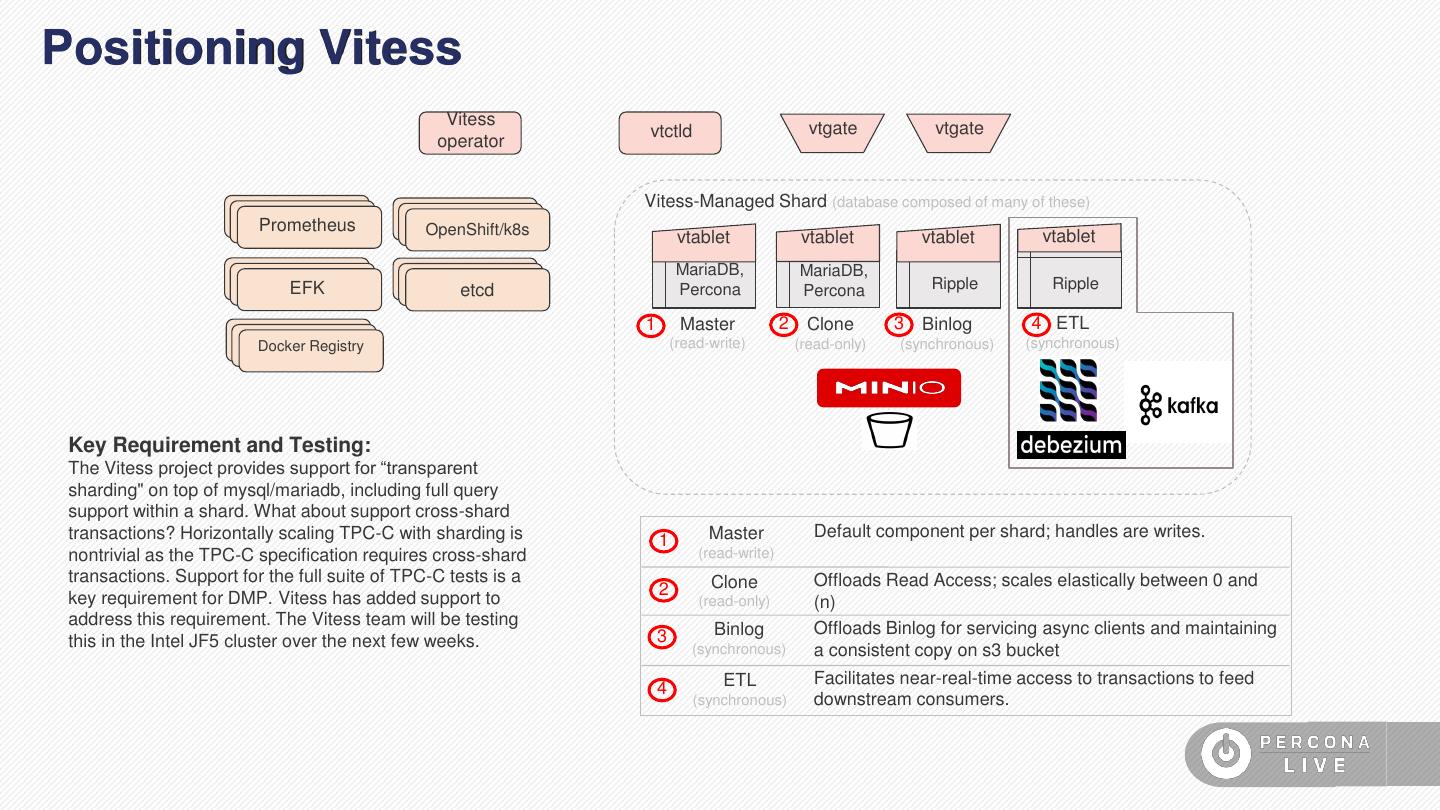
15 .Positioning Vitess Vitess vtgate vtgate vtctld operator Vitess-Managed Shard (database composed of many of these) Prometheus OpenShift/k8s vtablet vtablet vtablet vtablet MariaDB, MariaDB, EFK etcd Percona Percona Ripple Ripple 1 Master 2 Clone 3 Binlog 4 ETL Docker Registry (read-write) (read-only) (synchronous) (synchronous) Key Requirement and Testing: The Vitess project provides support for “transparent sharding" on top of mysql/mariadb, including full query support within a shard. What about support cross-shard transactions? Horizontally scaling TPC-C with sharding is 1 Master Default component per shard; handles are writes. nontrivial as the TPC-C specification requires cross-shard (read-write) transactions. Support for the full suite of TPC-C tests is a Clone Offloads Read Access; scales elastically between 0 and 2 key requirement for DMP. Vitess has added support to (read-only) (n) address this requirement. The Vitess team will be testing 3 Binlog Offloads Binlog for servicing async clients and maintaining this in the Intel JF5 cluster over the next few weeks. (synchronous) a consistent copy on s3 bucket ETL Facilitates near-real-time access to transactions to feed 4 (synchronous) downstream consumers.
16 . Basic Mechanics This section provides a review of the basic mechanics of a database deployment.
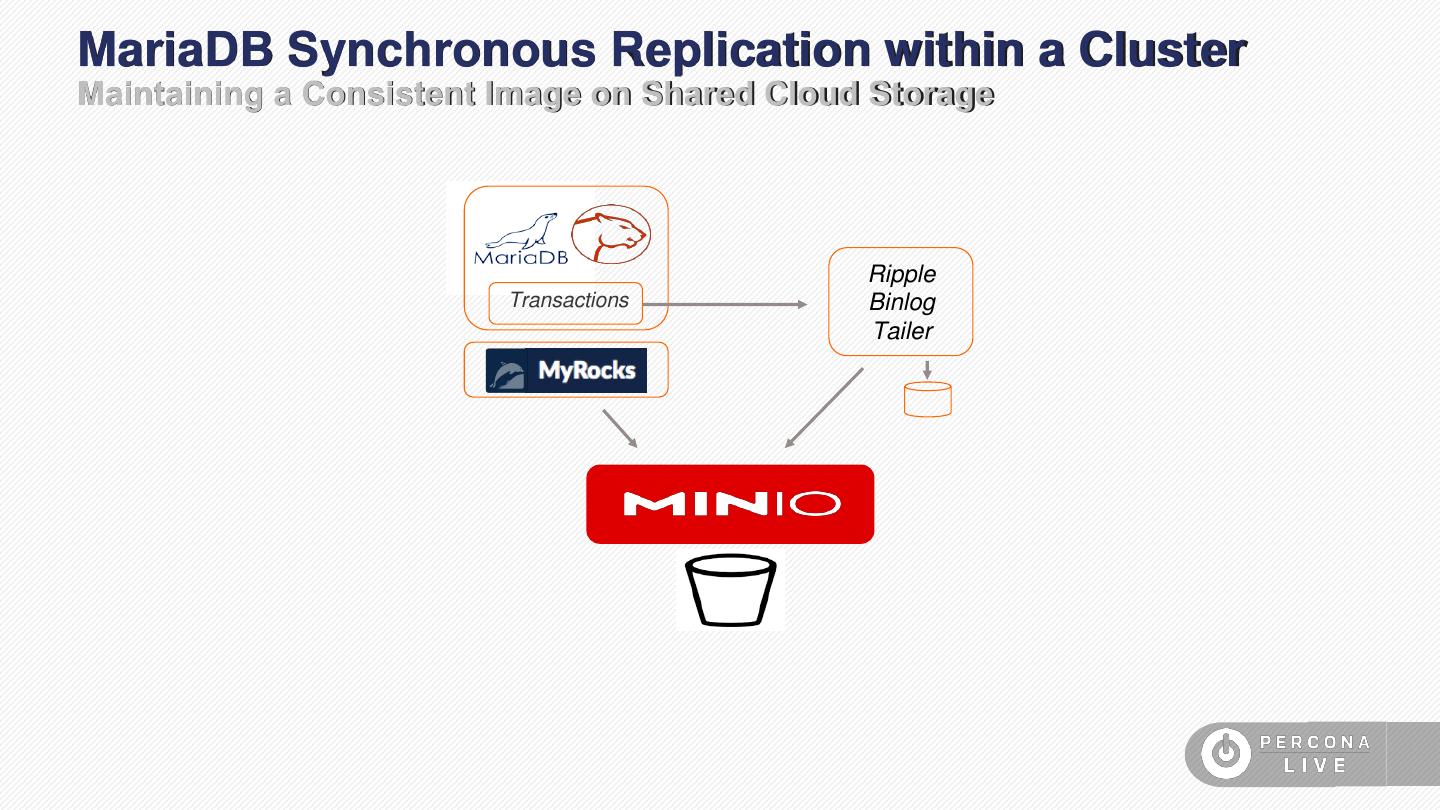
17 .MariaDB Synchronous Replication within a Cluster Maintaining a Consistent Image on Shared Cloud Storage Ripple Transactions Binlog Tailer
18 .MariaDB Asynchronous Replication across Clusters Maintaining a Consistent Image across Sites Ripple Ripple Transactions Binlog Transactions Binlog Tailer Tailer
19 .Transforming the ETL Process from Batch to Interactive (within a Cluster) Ripple Transactions Binlog Tailer Interactive Ad-Hoc Queries
20 .Intel’s Next Gen Platform Intel Data Management Platform
21 .End User “Pain Points” 1 The Downside of Becoming a Data Company Companies that have pivoted to AI and analytics in order to monetize their data are experiencing accelerating data growth rates 2 Disaggregating Storage This data growth challenge makes disaggregating storage from compute attractive because the company can scale their storage capacity to match their data growth, independent of compute. Cloud-Like, Open-Source, Database and AI/Analytics-Ready 3 Many of these companies are using Hadoop* and HDFS*, but still find it difficult to share data. They expressed a desire to move to something more cloud-like that readily supports their AI/analytics investments. These same customers expressed a similar desire for their portfolio of proprietary databases. 21
22 . Scale compute and storage independently HCI Optimal System design network Low latency access to storage Compute NVMessd Compute Nvmessd Compute Nvmessd compute Compute Compute Nvmessd Nvmessd Hot data random Compute Nvmessd accesses Compute Nvmessd Compute Nvmessd Warm data Compute Nvmessd sequential accesses Solution stack engineering required for independent scaling of storage & compute 22
23 . The Network is No Longer in my Way! 1. Disruption of the Data Center Network Model 2. Networking enables NVM Memory Innovations Back in 2010, James Hamilton famously observed that the Data Two years later, Andy Bechtolsheim predicts that data center Center network was in the way. network innovations will be a key part of addressing gaps in the Memory Hierarchy. Velocity 2010: James Hamilton, "Datacenter Infrastructure Innovation" Bechtolsheim, “NANOG 55 Keynote; Moore's Law and Networking," 2012 https://www.youtube.com/watch?v=kHW-ayt_Urk https://www.youtube.com/watch?v=j9M1i8YP3bE&feature=youtu.be
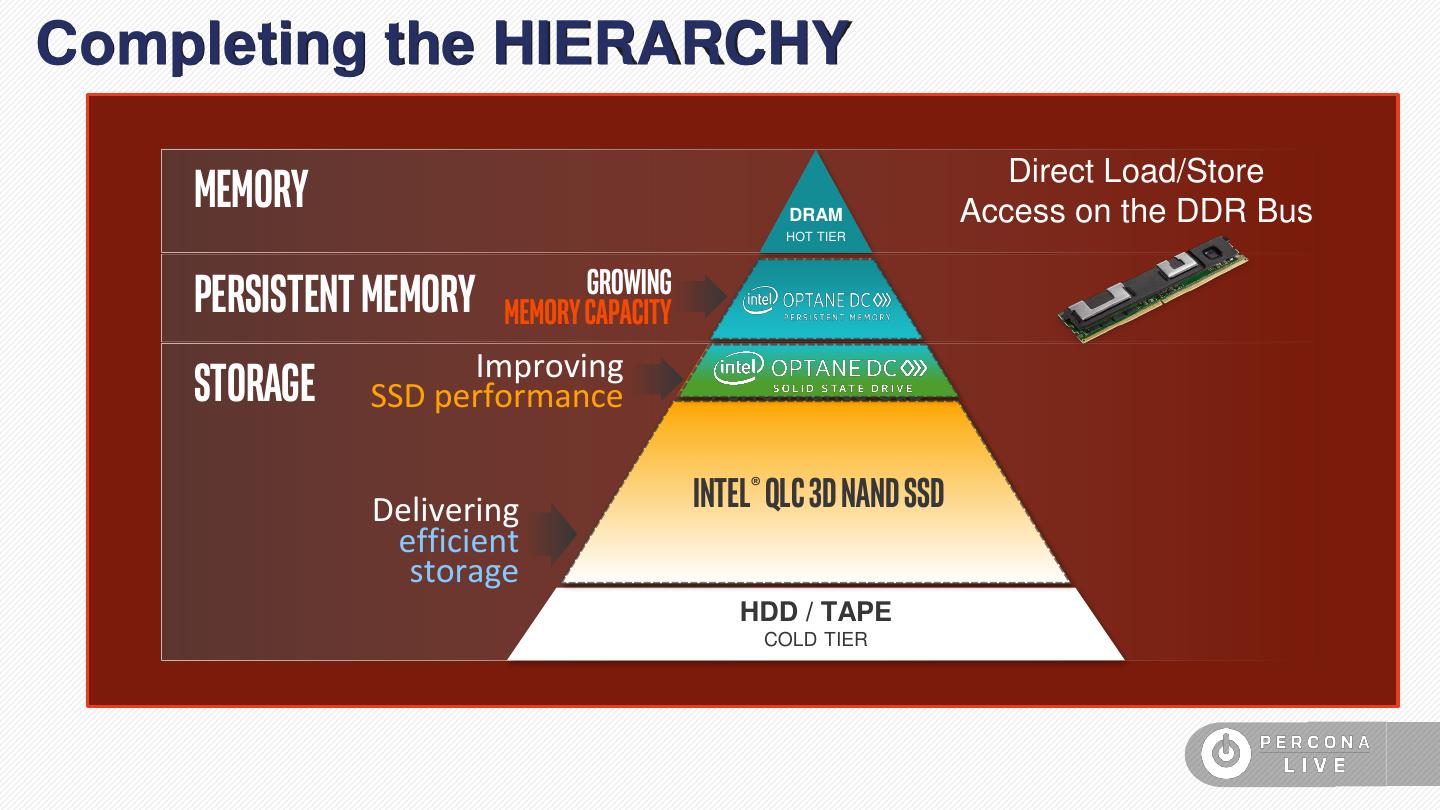
24 .Completing the HIERARCHY Memory DRAM Direct Load/Store Access on the DDR Bus HOT TIER Growing Persistent Memory memory capacity Capacity Gap Storage Storage Improving SSD performance Performance Gap 3D NAND SSD WARM TIER Delivering Intel® QLC 3D Nand SSD efficient Cost performance GAp storage HDD / TAPE COLD TIER
25 . Rack Centric Physical Cluster Rack Rack2 Rack3 …….Rack16 BALANCED STORAGE & NETWORK 1 Compute nodes (16): WARM STORAGE OVER Server: Dell R640 (1U) NVMe-oF CPU: 2x6254* CLX CPU Network: 1x50GB MLNX CX5 (x16) Memory: 24x32GB DIMMs ORCHESTRATION THROUGH Hot caching tier: 2x750GB Optane SSD OR AEP DIMM K8s Option 1: 24x32 DRAM DIMM + 2x750GB Optane SSD (1) Option 2: 12x32 DRAM DIMM + 12x256GB Optane DCPM OS: Use BOSS card (2x240GB M2 SATA in RAID-1 config) MANAGEMENT PLANE Dedicated drives for Docker overlay: 1TB P4510 NVMe Switches: Mgmt. aggregator Switch (10GbE): Dell S4128F-ON Storage nodes (4): ToR & Spine (100GbE): Dell Z9100 Server: Dell R740XD (2U) Mgmt. switch (1GbE): Dell DS3048 CPU: 2x6254* CLX CPU Network: 2x100GB MLNX CX5 (x16) Memory: 12x16GB DIMMs** Storage: 8x16TB P4xxx QLC NVMe OS: Use BOSS card (2x240GB M2 SATA in RAID-1 config) Dedicated drives for Docker overlay: 1TB P4510 NVMe (16) Infra nodes (2): Server: Dell R640 (1U) CPU: 2x6242 CLX CPU Network: 1x25GB MLNX CX5 (x16) Cable: 4:1 100GbE splitter cable with 1 each going each infra nodes Memory: 12x16GB DIMMs (20) Storage: 3x1.6TB P4510 NVMe SSDs configured in RAID-5 (FF: U2) OS: Use BOSS card (2x240GB M2 SATA in RAID-1 config) (22) Value: Scalable storage at best performance/cost - QLC 3DNAND &Optane/AEP caching
26 .Engineered Solution Stack for Cloud-Native Workloads Illustrative Apache Spark, MariaDB Apache Spark Starburst Data’s Applications TensorFlow w/Debezium Streaming, distribution of Apache Kafka PrestoDB Workload Database Real-Time Categories w/Change-Data- Ingestion & Distributed AI/Analytics (Memory Intensive, Capture Indexing Query Partitioned Datasets) Cloud-Native Event Stream Cloud-Native Object Store Managed Local Scratch Resource Scheduling K8s SDN SDS (BGP/rfc7938) & Orchestration “Core” Hardware (includes Core resource SW, CPU Network Optane Storage eg Satellite/Foreman) Value: Open-source S/W-H/W integration, leading to rapid adoption of innovations
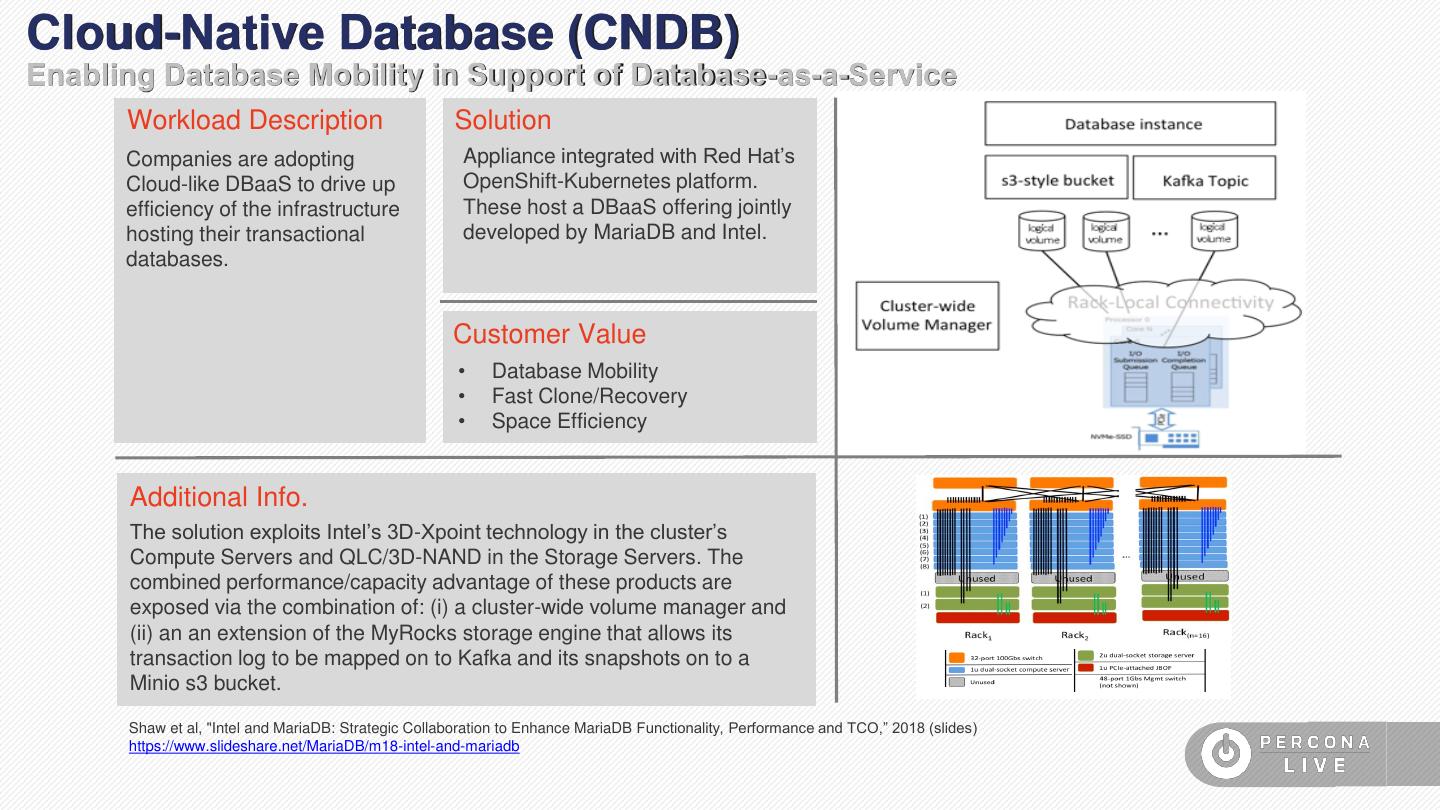
27 .Cloud-Native Database (CNDB) Enabling Database Mobility in Support of Database-as-a-Service Workload Description Solution Companies are adopting Appliance integrated with Red Hat’s Cloud-like DBaaS to drive up OpenShift-Kubernetes platform. efficiency of the infrastructure These host a DBaaS offering jointly hosting their transactional developed by MariaDB and Intel. databases. Customer Value • Database Mobility • Fast Clone/Recovery • Space Efficiency Additional Info. The solution exploits Intel’s 3D-Xpoint technology in the cluster’s Compute Servers and QLC/3D-NAND in the Storage Servers. The combined performance/capacity advantage of these products are exposed via the combination of: (i) a cluster-wide volume manager and (ii) an an extension of the MyRocks storage engine that allows its transaction log to be mapped on to Kafka and its snapshots on to a Minio s3 bucket. Shaw et al, "Intel and MariaDB: Strategic Collaboration to Enhance MariaDB Functionality, Performance and TCO,” 2018 (slides) https://www.slideshare.net/MariaDB/m18-intel-and-mariadb
28 .Future Work
29 .Future Work • BINLOG • Implement Tail-of-Log • Optimize Group Commit using Write-Behind Logging (WBL) • Point-in-Time Recovery (PiTR) • MyRocks • Enable Atomic Writes when Persistent Memory is detected • Move Immutable MemTables off DRAM to Persistent Memory for Row Granularity Caching 29
3秒后跳转登录页面
去登陆

