
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Intelligent System for AI
在云端搭建一个人工智能系统碰到的问题和挑战分析,及相关的解决方案。
展开查看详情
1 .Intelligent System for AI 清大資工 周志遠 2018/5/19 @ AII Workshop
2 .• 周志遠 (Jerry Chou) – Email: jchou@cs.nthu.edu.tw – Large-scaled System Architecture (LSA) Lab • 經歷 – 清華大學資工系 副教授 2016~現今 – 清華大學資工系 助理教授 2011~2016 – 美國勞倫斯國家實驗室 工程師 2010~2011 – 美國加州大學聖帝亞哥分校(UCSD) 博士學位 2009 • 研究領域 – 雲端計算、分散式系統、高效能計算、巨量資料處理 2
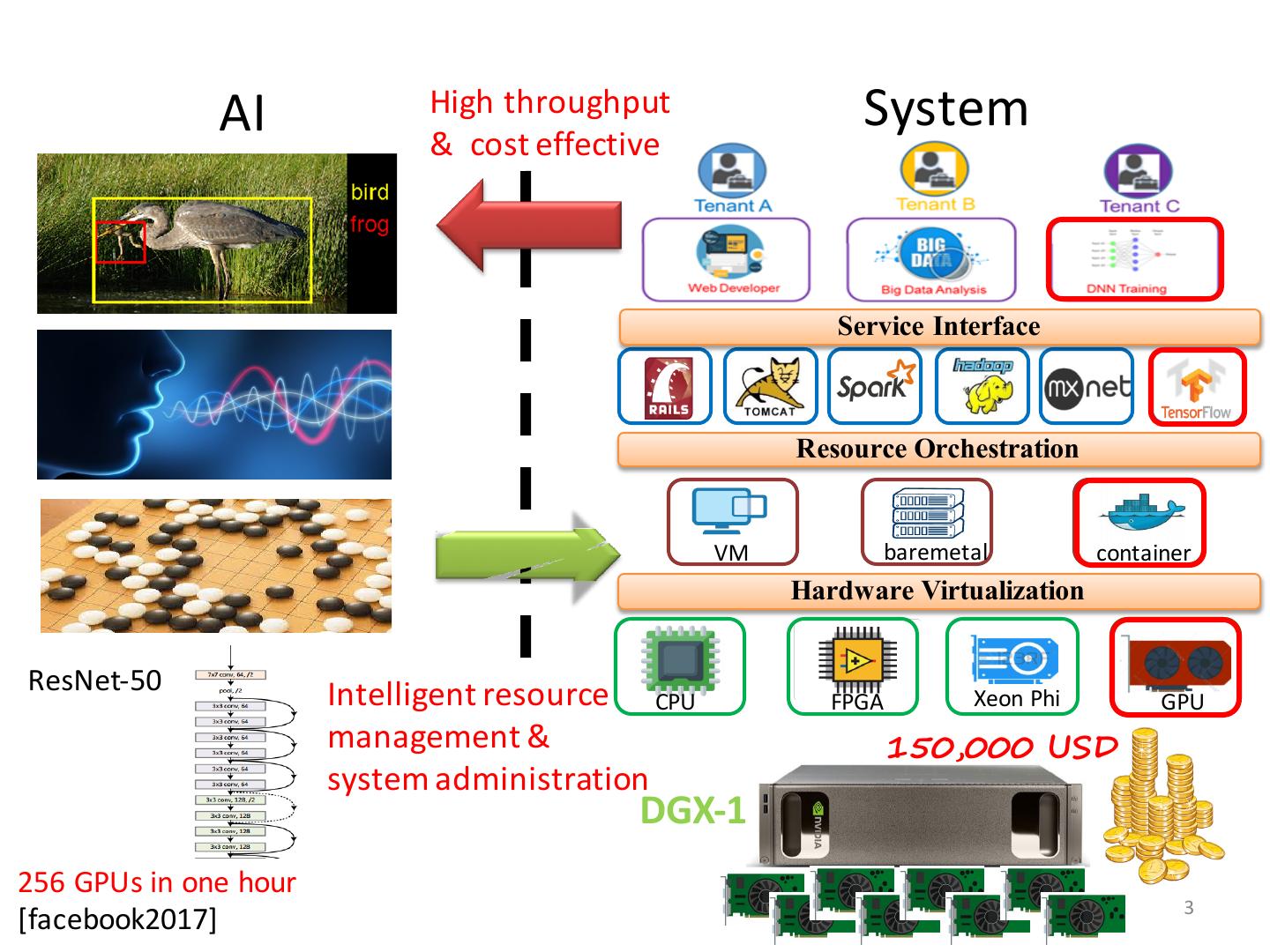
3 . AI High throughput System & cost effective Service Interface Resource Orchestration VM baremetal container Hardware Virtualization ResNet-50 Intelligent resource CPU Xeon Phi FPGA GPU management & 150,000 USD system administration DGX-1 256 GPUs in one hour 3 [facebook2017]
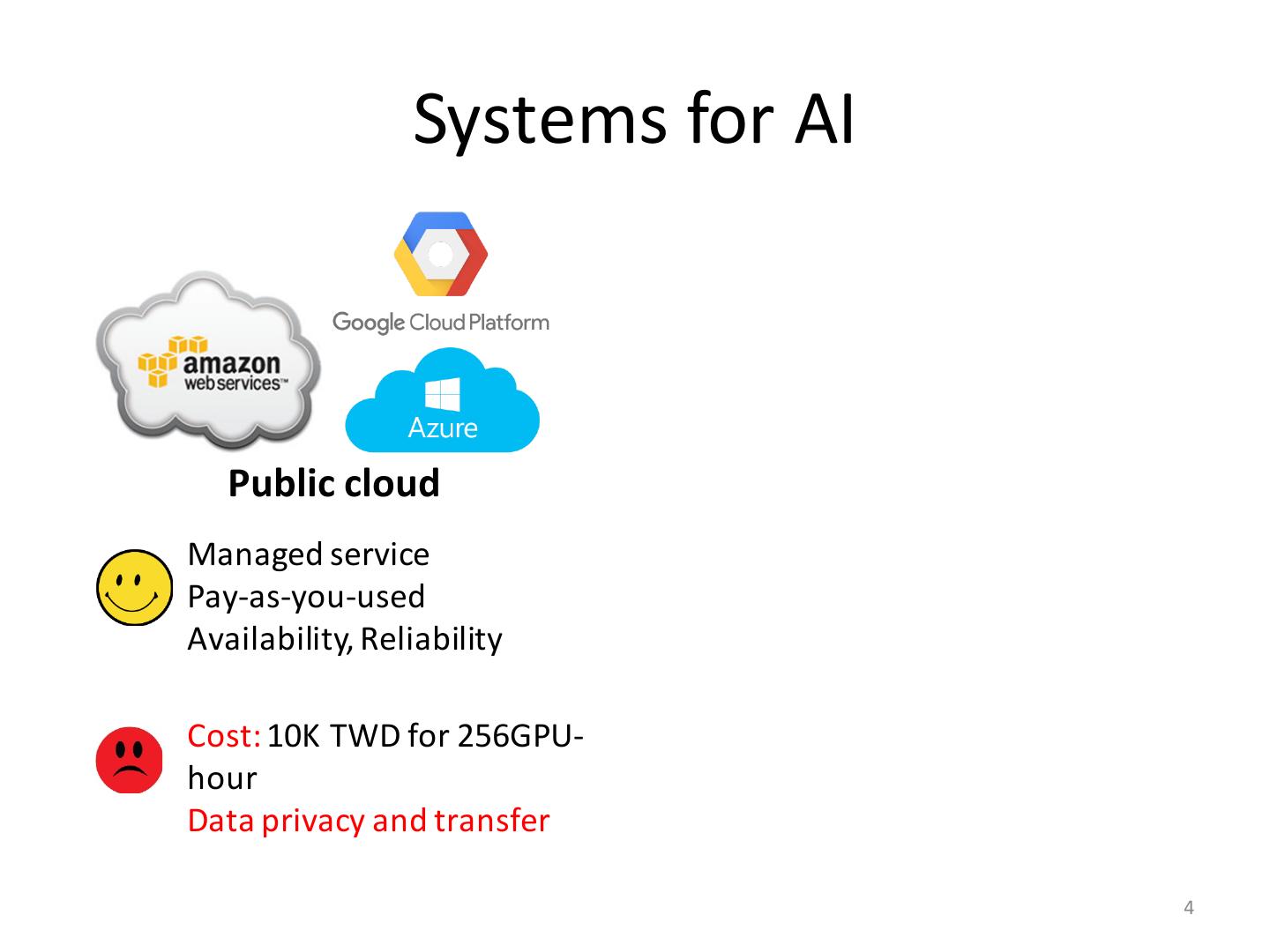
4 . Systems for AI Public cloud Managed service Pay-as-you-used Availability, Reliability Cost: 10K TWD for 256GPU- hour Data privacy and transfer 4
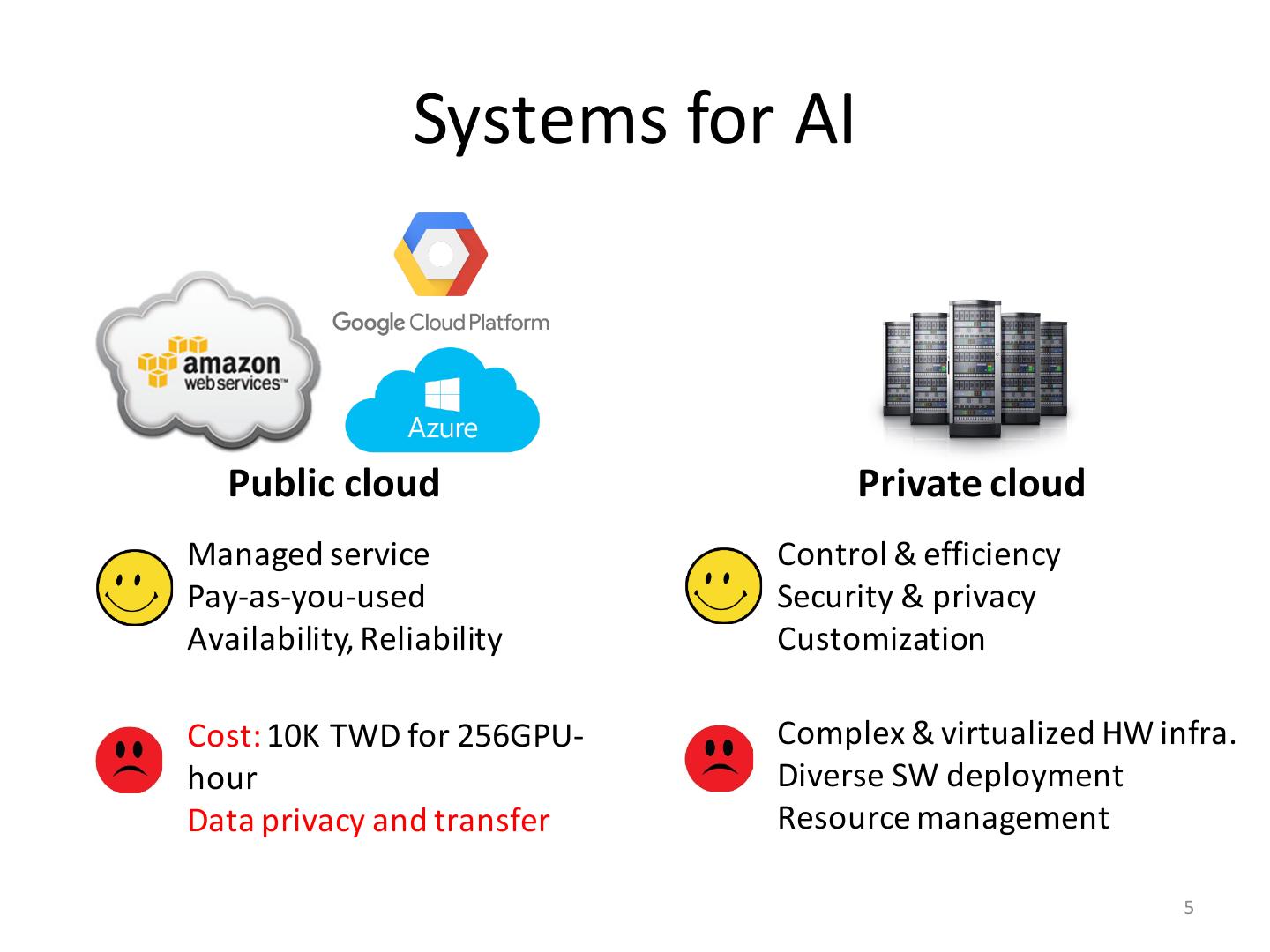
5 . Systems for AI Public cloud Private cloud Managed service Control & efficiency Pay-as-you-used Security & privacy Availability, Reliability Customization Cost: 10K TWD for 256GPU- Complex & virtualized HW infra. hour Diverse SW deployment Data privacy and transfer Resource management 5
6 . Systems for AI Public cloud Private cloud Managed service Control & efficiency Pay-as-you-used Security & privacy Availability, Reliability Customization Cost: 10K TWD for 256GPU- Complex & virtualized HW infra. hour Diverse SW deployment Data privacy and transfer Resource management 6
7 . Key Challenges of AI Systems • System Infrastructure: – VM + CPU è Container + GPU • Training job execution: – Static Single instance execution è Elastic distributed execution 7
8 . Container-based GPU Cloud • Why Container? – Lightweight, low performance overhead – High deployment density – Execution environment isolation Benchmark TensorFlow on varied resource orchestration (baremetal, container, VM) and execution environment (single, distributed, multi-tenant) 8
9 . Container-based GPU Cloud • Why Container? – Lightweight, low performance overhead – High deployment density – Execution environment isolation Container can deliver close to the bare-metal performance in dedicated resource environment Single instance Distributed 9
10 . Container-based GPU Cloud • Why Container? – Lightweight, low performance overhead – High deployment density – Execution environment isolation • Continer lacks of QoS control for PCIE and GPU • GPU may not be fully utilized by a single job large batch size arge batch size Multi-tenant 10
11 . Container-based GPU Cloud • Why Kubernetes (container orchestrator)? – Automating deployment, scaling, and (lifecycle & resource) management of containerized applications • Current solutions & limitations – NVidia-Docker: expose GPU devices to containers • Dedicate GPU allocation to container – K8S resource limit: control memory and CPU usage • GPU is not manageable resource yet – KubeFlow: A TF-operator to deploy containerized TF job as a set of K8S applications • Naïve round-robin scheduling without scaling and management 11
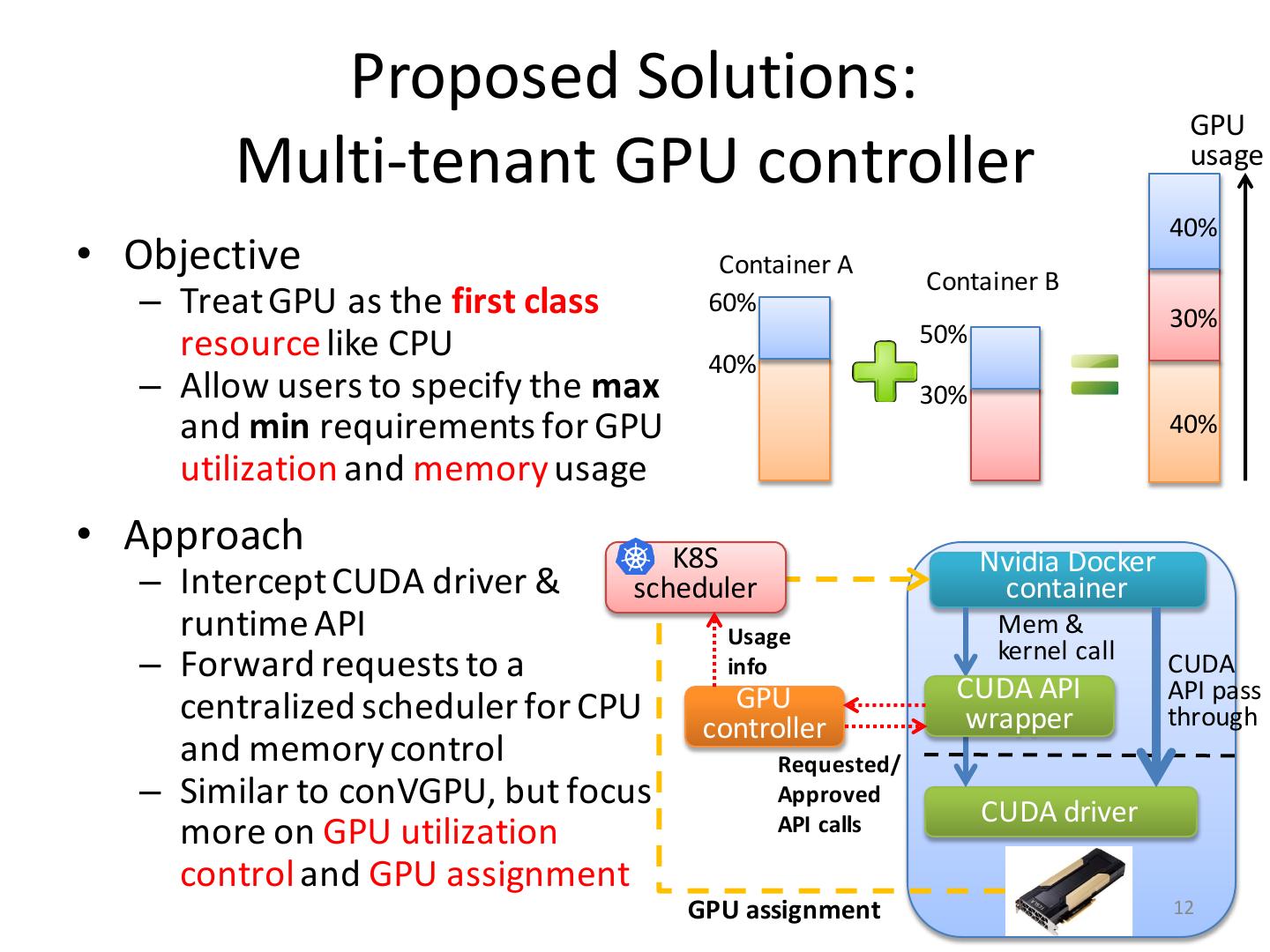
12 . Proposed Solutions: GPU Multi-tenant GPU controller usage 40% • Objective Container A Container B – Treat GPU as the first class 60% 30% resource like CPU 50% 40% – Allow users to specify the max 30% and min requirements for GPU 40% utilization and memory usage • Approach K8S Nvidia Docker – Intercept CUDA driver & scheduler container runtime API Usage Mem & kernel call – Forward requests to a info CUDA GPU CUDA API API pass centralized scheduler for CPU controller wrapper through and memory control Requested/ – Similar to conVGPU, but focus Approved CUDA driver more on GPU utilization API calls control and GPU assignment GPU assignment 12
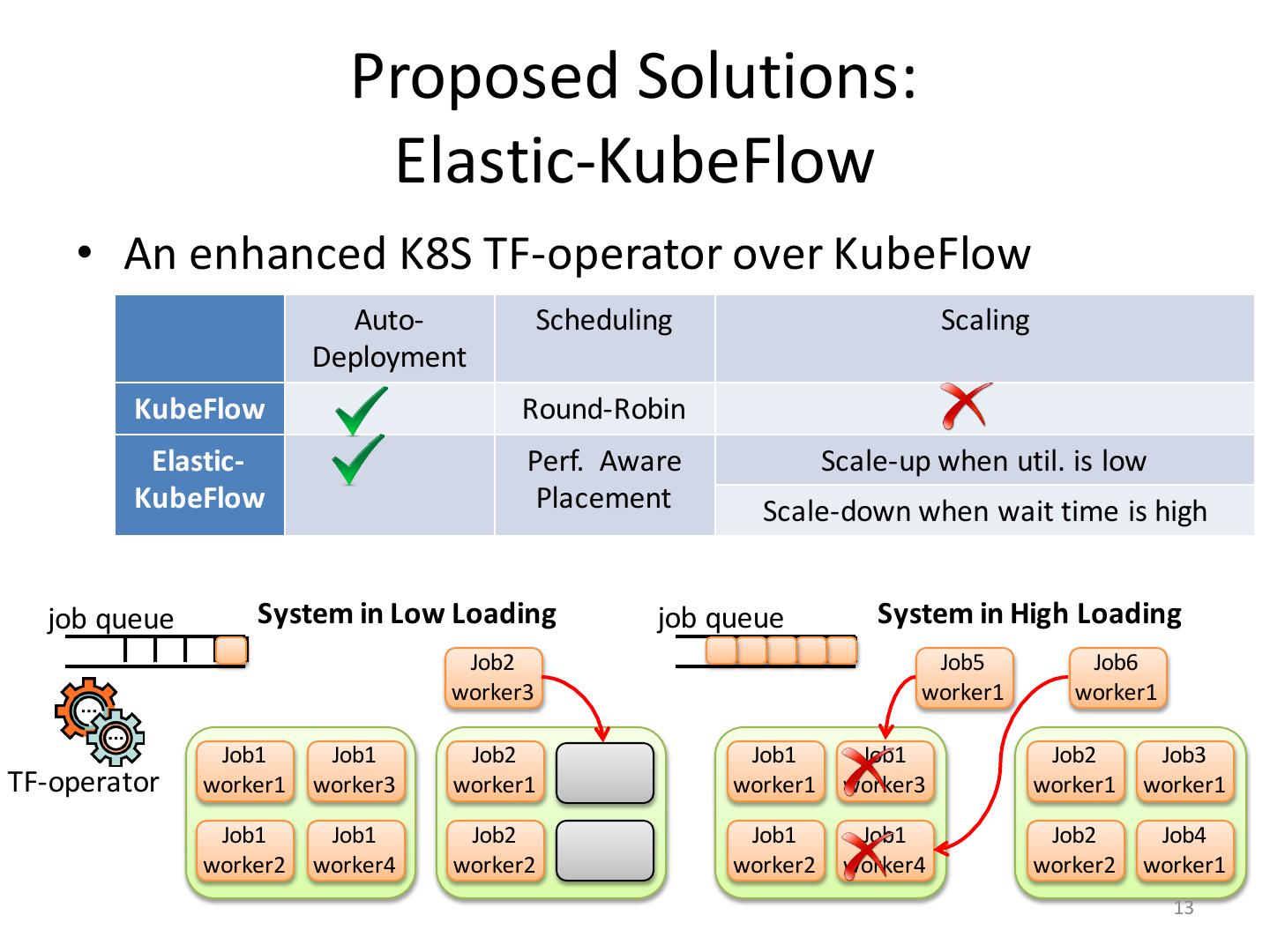
13 . Proposed Solutions: Elastic-KubeFlow • An enhanced K8S TF-operator over KubeFlow Auto- Scheduling Scaling Deployment KubeFlow Round-Robin Elastic- Perf. Aware Scale-up when util. is low KubeFlow Placement Scale-down when wait time is high job queue System in Low Loading job queue System in High Loading Job2 Job5 Job6 worker3 worker1 worker1 Job1 Job1 Job2 Job1 Job1 Job2 Job3 TF-operator worker1 worker3 worker1 worker1 worker3 worker1 worker1 Job1 Job1 Job2 Job1 Job1 Job2 Job4 worker2 worker4 worker2 worker2 worker4 worker2 worker1 13
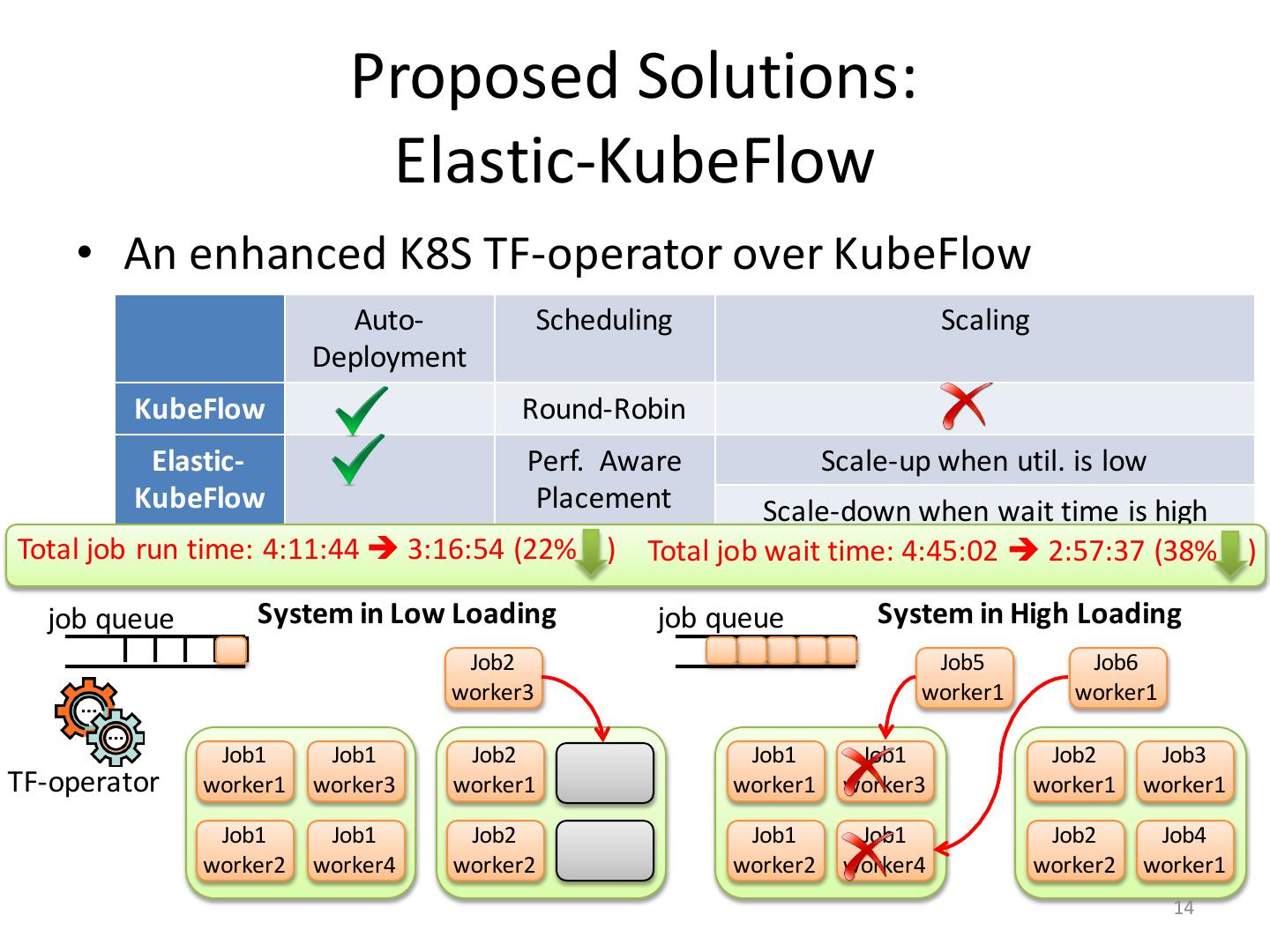
14 . Proposed Solutions: Elastic-KubeFlow • An enhanced K8S TF-operator over KubeFlow Auto- Scheduling Scaling Deployment KubeFlow Round-Robin Elastic- Perf. Aware Scale-up when util. is low KubeFlow Placement Scale-down when wait time is high Total job run time: 4:11:44 è 3:16:54 (22% ) Total job wait time: 4:45:02 è 2:57:37 (38% ) job queue System in Low Loading job queue System in High Loading Job2 Job5 Job6 worker3 worker1 worker1 Job1 Job1 Job2 Job1 Job1 Job2 Job3 TF-operator worker1 worker3 worker1 worker1 worker3 worker1 worker1 Job1 Job1 Job2 Job1 Job1 Job2 Job4 worker2 worker4 worker2 worker2 worker4 worker2 worker1 14
15 . Distributed Deep Learning • Model Parallelism – Within a node: shared memory, auto- managed by framework – Across nodes: message passing, model Model parallelism rewritten by developers • Data Parallelism – Parameter server: • Asynchronous centralized comm. èFaster converge time, but higher network BW requirement Data parallelism (PS) • Main strategy in TF – All reduce: • Synchronous P2P comm. èHigher latency delay, but more balanced network traffic (avoid hotspot) • Recent optimized imp. by Horovod Data parallelism (P2P) 15
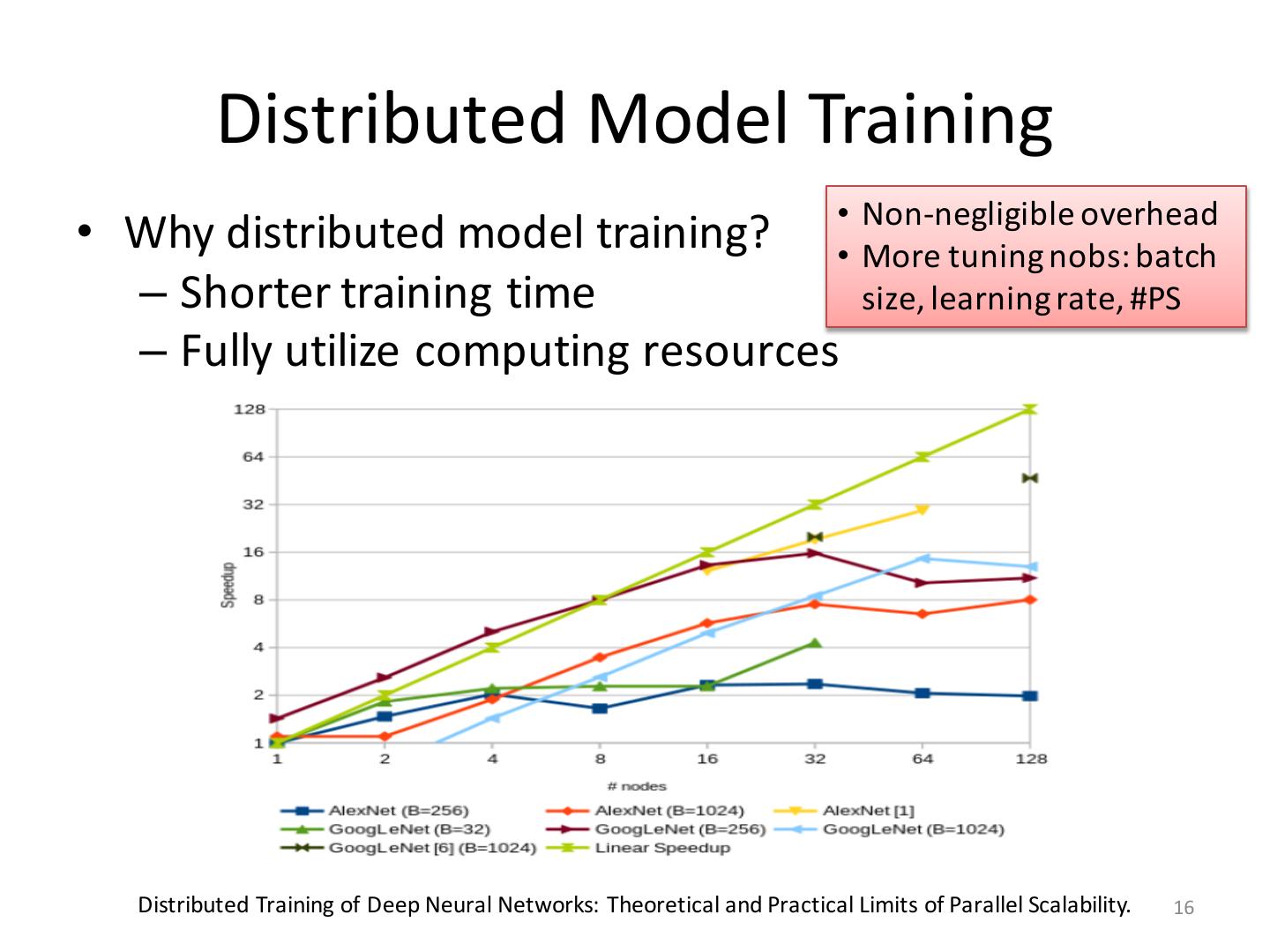
16 . Distributed Model Training • Non-negligible overhead • Why distributed model training? • More tuning nobs: batch – Shorter training time size, learning rate, #PS – Fully utilize computing resources Distributed Training of Deep Neural Networks: Theoretical and Practical Limits of Parallel Scalability. 16
17 . Proposed Solutions: Elastic-TensorFlow • Why we want to dynamically add/remove workers from a training job without checkpoint-restart? – Auto-tuning PS/Worker ratio at runtime – Reach desired performance with minimum cost – Maximize system utilization & throughput (Combine with our elastic-kubeflow controller) http://blog.kubernetes.io/2017/12/paddle-paddle-fluid- Distributed training strategies for a computer vision 17 elastic-learning.html deep learning algorithm on GPU cluster
18 . AI for Systems • Time prediction for optimizing job execution – Apply FCN、RNN for complex parallel DAG • Anomaly & failure prediction for minimizing cost – DNN along might not be enough… • Using SVM for rare class classification • Using bayesian network or decision tree for root cause diagnosis • Using probability distribution for system metrics prediction • Auto-scaling & Scheduling for maximizing system performance – Apply reinforcement learning: A3S, Deep Q-learning 18
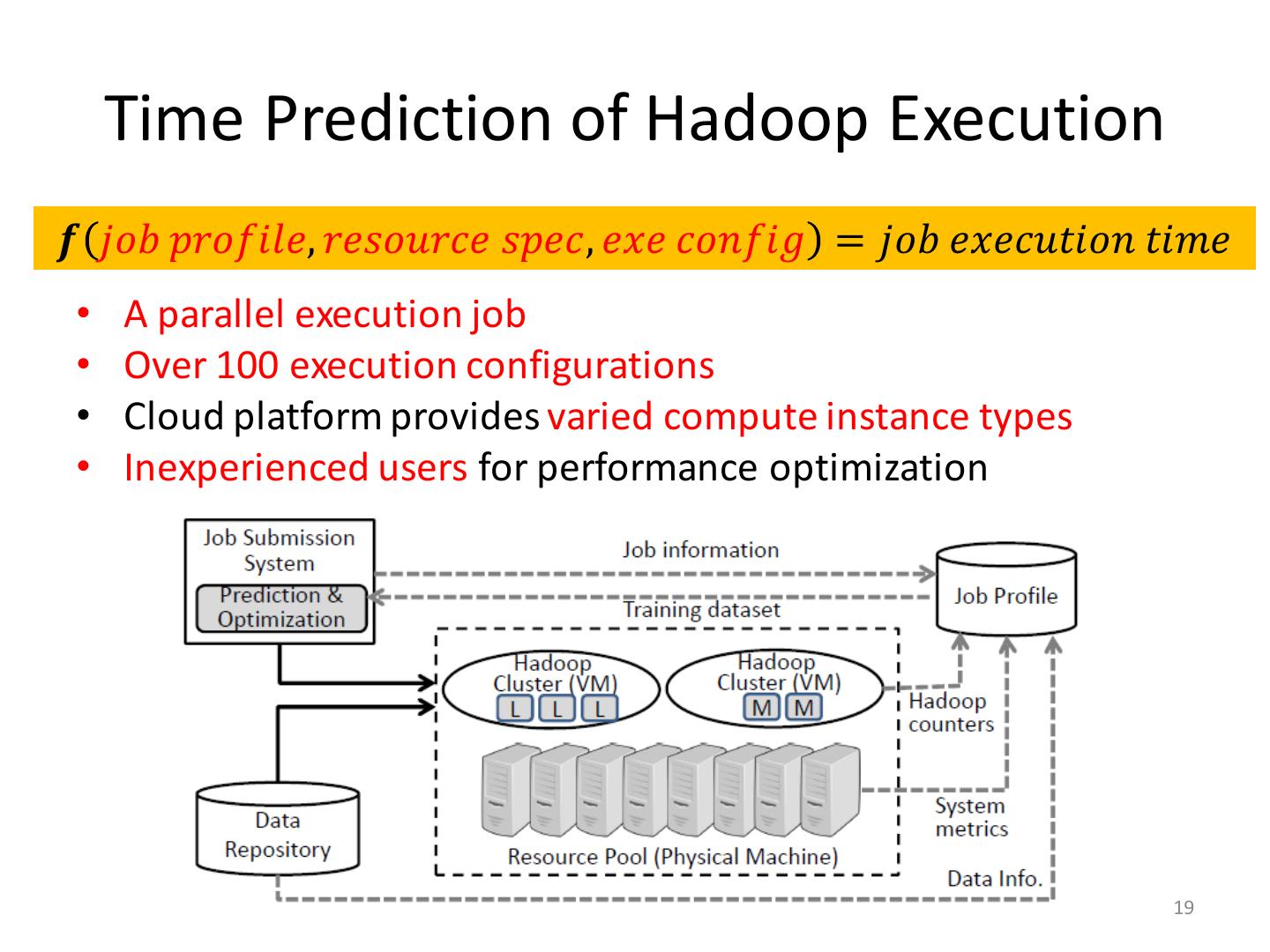
19 . Time Prediction of Hadoop Execution 𝒇 𝑗𝑜𝑏 𝑝𝑟𝑜𝑓𝑖𝑙𝑒, 𝑟𝑒𝑠𝑜𝑢𝑟𝑐𝑒 𝑠𝑝𝑒𝑐, 𝑒𝑥𝑒 𝑐𝑜𝑛𝑓𝑖𝑔 = 𝑗𝑜𝑏 𝑒𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 • A parallel execution job • Over 100 execution configurations • Cloud platform provides varied compute instance types • Inexperienced users for performance optimization 19
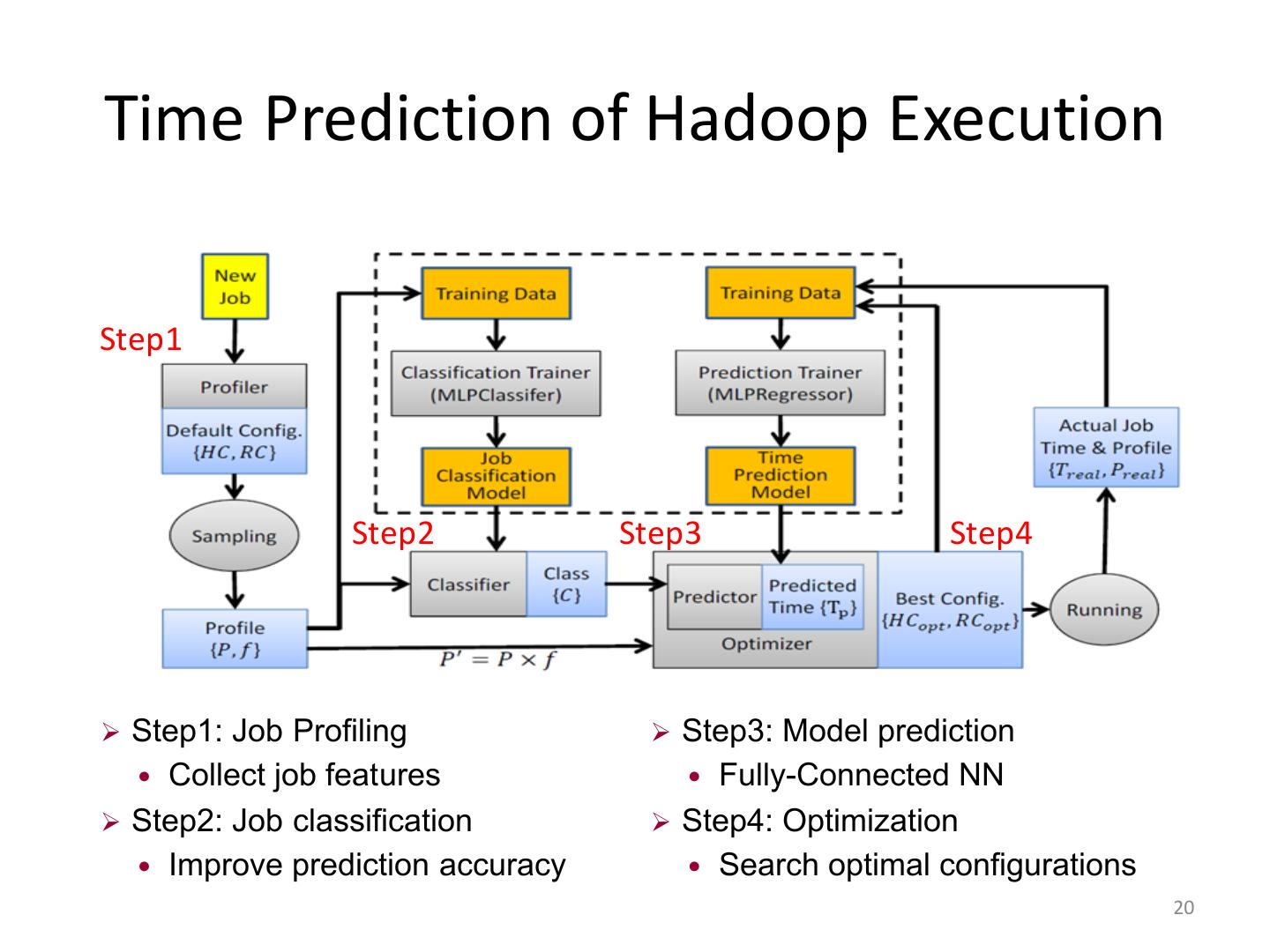
20 .Time Prediction of Hadoop Execution Step1 Step2 Step3 Step4 Ø Step1: Job Profiling Ø Step3: Model prediction Collect job features Fully-Connected NN Ø Step2: Job classification Ø Step4: Optimization Improve prediction accuracy Search optimal configurations 20
21 . Evaluation Results • Workload from HiBench, a Hadoop benchmark suite Prediction Accuracy Performance Improvement DecisionTree: 16% SVM: 12% NN: 8% 10~50% performance More accurate time prediction improvement by choosing the than traditional ML methods proper execution configurations 21
22 . Time Prediction of Hive Query • Hive: A query engine on Hadoop – Complex workflow represented by DAG Different DAG execution plans OR Translation Execution Query Statement Job dependency 22
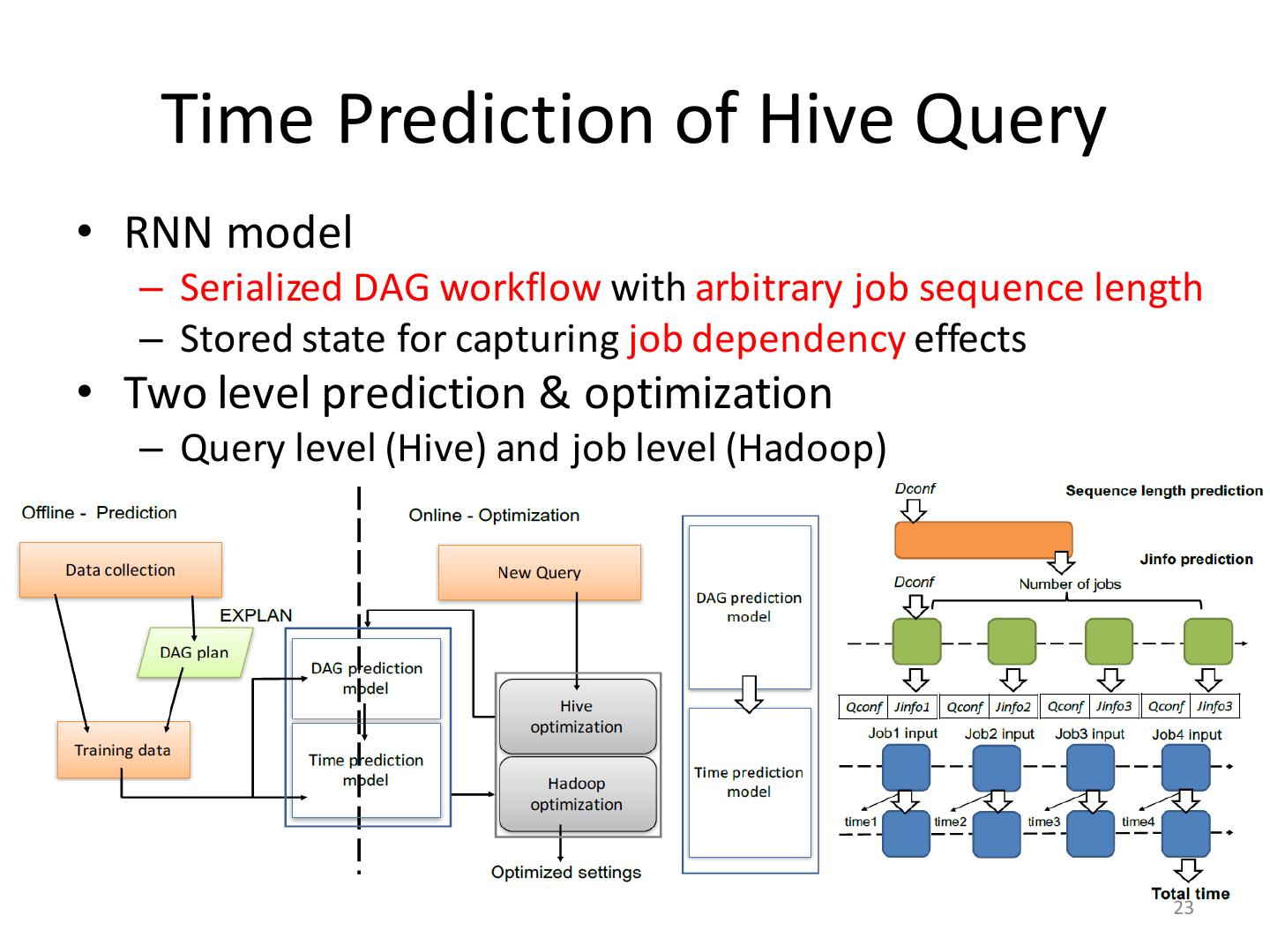
23 . Time Prediction of Hive Query • RNN model – Serialized DAG workflow with arbitrary job sequence length – Stored state for capturing job dependency effects • Two level prediction & optimization – Query level (Hive) and job level (Hadoop) 23
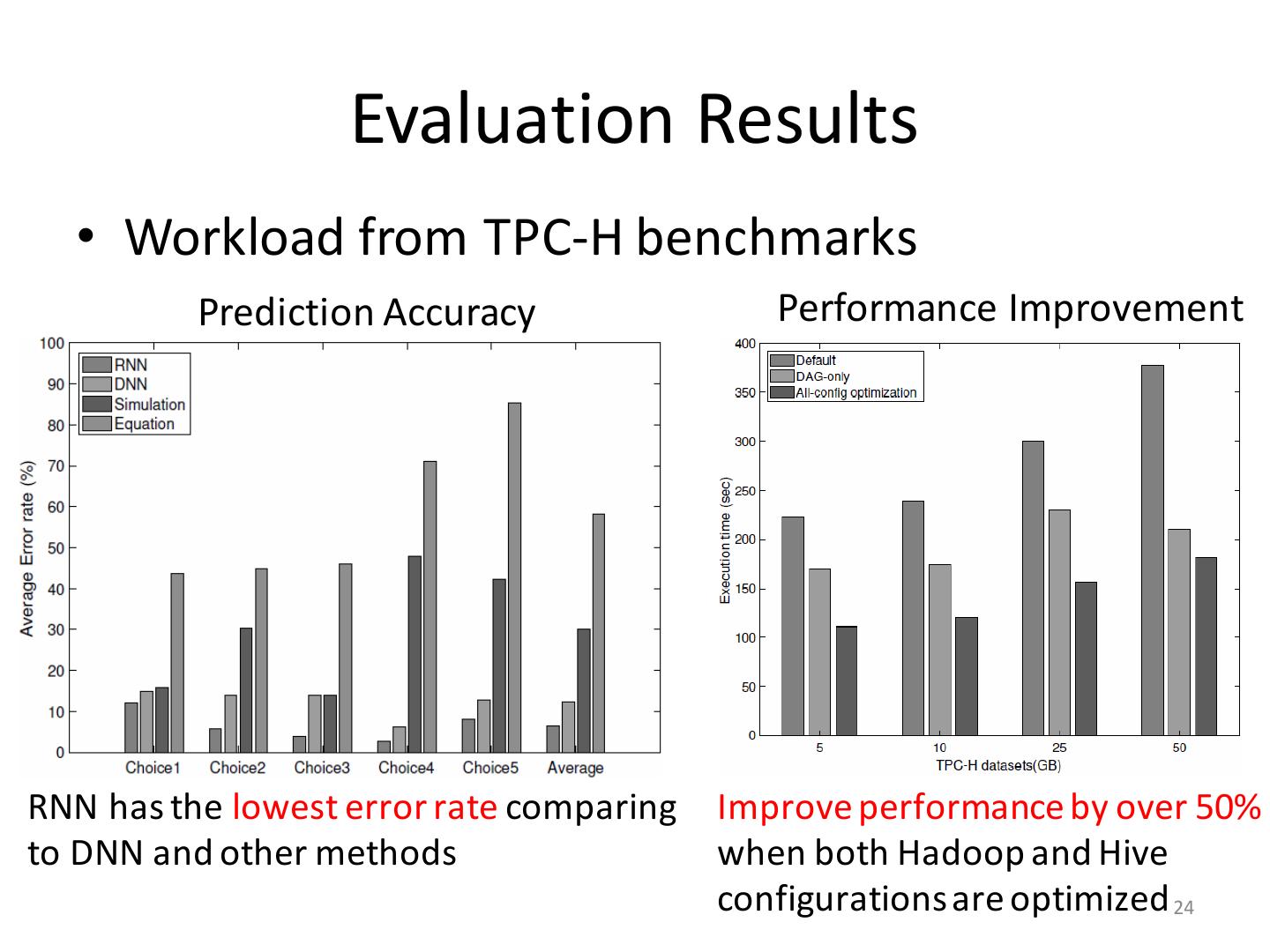
24 . Evaluation Results • Workload from TPC-H benchmarks Prediction Accuracy Performance Improvement RNN has the lowest error rate comparing Improve performance by over 50% to DNN and other methods when both Hadoop and Hive configurations are optimized 24
25 .25
相关推荐
3秒后跳转登录页面
去登陆

