


















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
并行数据文件系统与计算的高性能集成
在分布式数据存储和计算集成中,并行计算和并行数据访问是基本的优化方法,但是如何能让作业和任务高度并行,在实际应用场景中,由于分布式任务调度和数据本地性没有办法做到完美结合,性能会因此丢失。本文从分布式数据计算和存储架构角度,先分析了数据并行系统的特性,解释数据本地行对于性能的量化影响,并提出自己的对于作业和任务调度的优化策略,值得做分布式计算优化的小伙伴们参考。
展开查看详情
1 .High Performance Integration of Data Parallel File Systems and Computing Zhenhua Guo PhD Thesis Proposal
2 .Outline Introduction and Motivation Literature Survey Research Issues and Our Approaches Contributions
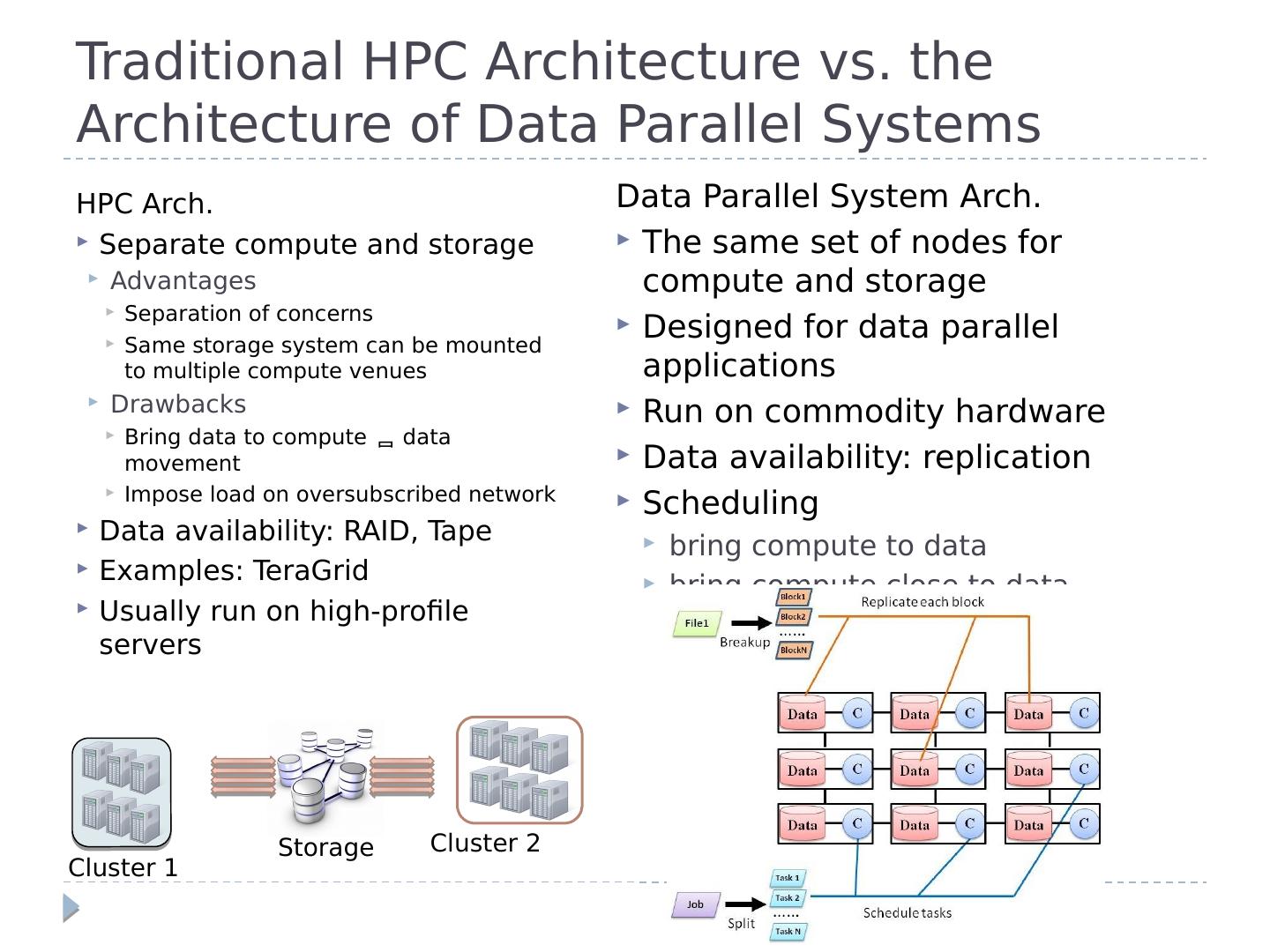
3 .Traditional HPC Architecture vs. the Architecture of Data Parallel Systems HPC Arch. Separate compute and storage Advantages Separation of concerns Same storage system can be mounted to multiple compute venues Drawbacks Bring data to compute data movement Impose load on oversubscribed network Data availability: RAID, Tape Examples: TeraGrid Usually run on high-profile servers Storage Cluster 1 Cluster 2 Data Parallel System Arch. The same set of nodes for compute and storage Designed for data parallel applications Run on commodity hardware Data availability: replication Scheduling bring compute to data bring compute close to data
4 .Data Parallel Systems Google File System/MapReduce, Twister, Cosmos/ Drayad , Sector/Sphere MapReduce has quickly gained popularity Google, Yahoo!, Facebook, Amazon EMR,… Academic usage: data mining, log processing, … Substantial research MapReduce online, Map-Reduce-Merge, Hierarchical MapReduce … Hadoop is an open source implementation of GFS and MapReduce Killing features Simplicity Fault tolerance Extensibility Scalability
5 .MapReduce Model Input & Output: a set of key/value pairs Two primitive operations map : (k 1 ,v 1 ) list(k 2 ,v 2 ) reduce : (k 2 ,list(v 2 )) list(k 3 ,v 3 ) Each map operation processes one input key/value pair and produces a set of key/value pairs Each reduce operation Merges all intermediate values (produced by map ops) for a particular key Produce final key/value pairs Operations are organized into tasks Map tasks: apply map operation to a set of key/value pairs Reduce tasks: apply reduce operation to intermediate key/value pairs Each MapReduce job comprises a set of map and reduce (optional) tasks. Use Google File System to store data Optimized for large files and write-once-read-many access patterns HDFS is an open source implementation Can be extended to non key/value pair models
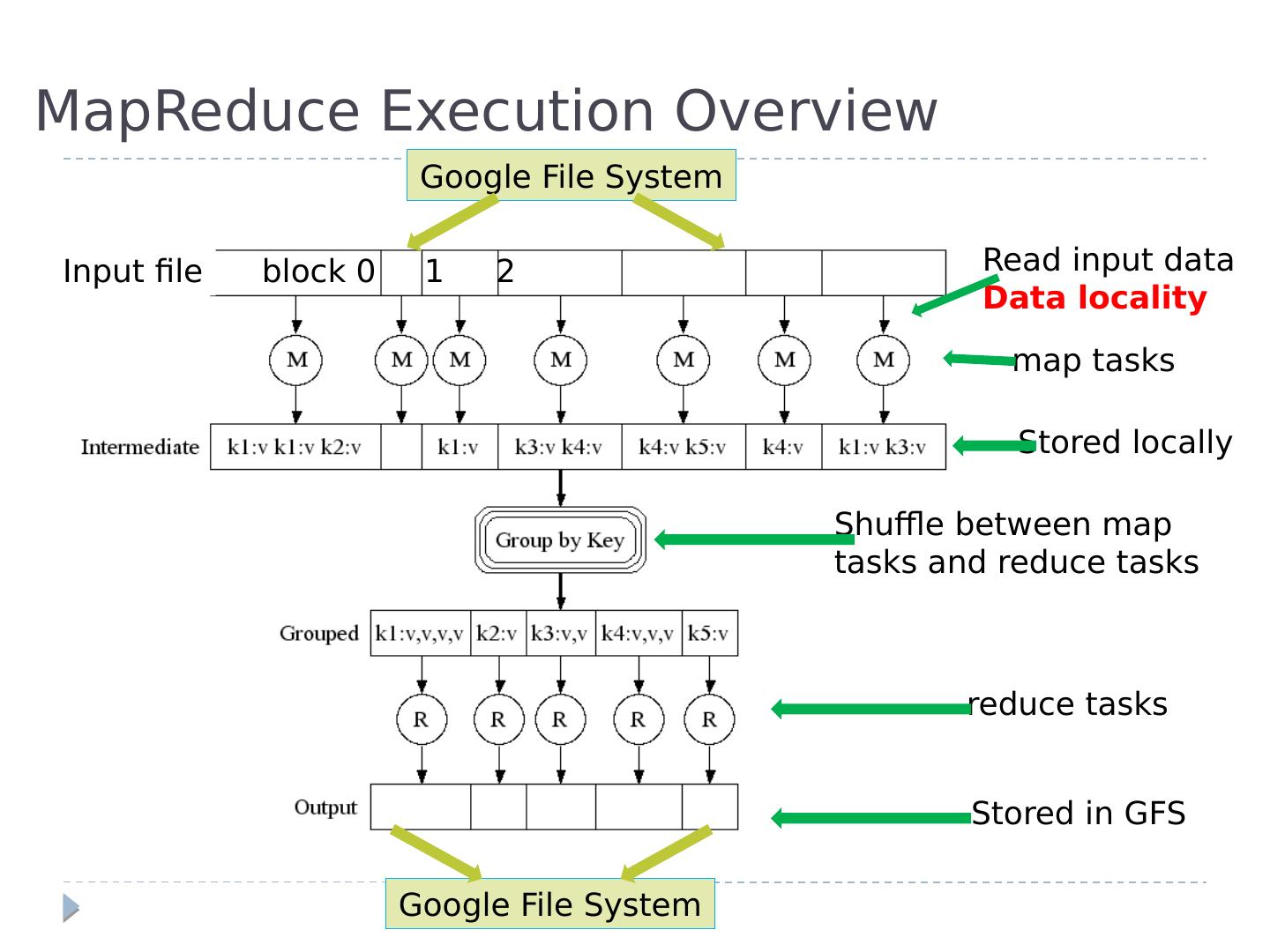
6 .MapReduce Execution Overview Google File System Read input data Data locality map tasks Stored locally Shuffle between map tasks and reduce tasks reduce tasks Stored in GFS block 0 1 2 Input file Google File System
7 .Hadoop Implementation Operating System Hadoop Operating System Hadoop HDFS Name node Metadata mgmt. Replication mgmt. Block placement MapReduce Job tracker Task scheduler Fault tolerance Storage : HDFS - Files are split into blocks. - Each block has replicas . - All blocks are managed by central name node. Compute : MapReduce - Each node has map and reduce slots - Tasks are scheduled to task slots # of tasks <= # of slots Worker node 1 Worker node N …… …… task slot data block
8 .Motivation GFS/MapReduce (Hadoop) is our research target Overall, MapReduce performs well for pleasantly parallel applications Want a deep understanding of its performance for different configurations and environments Observed inefficiency (thus degraded performance) that can be improved For state-of-the-art schedulers, data locality is not optimal Fixed task granularity ⇒ poor load balancing Simple algorithms to trigger speculative execution Low resource utilization when # of tasks is less than # of slots How to build MapReduce across multiple grid clusters
9 .Outline Motivation Literature Survey Research Issues and Our Approaches Contributions
10 .Storage Storage Distributed Parallel Storage System (DPSS): disk-based cache over WAN to isolate apps and tertiary archive storage systems Storage Resource Broker (SRB): unified APIs to heterogeneous data sources; catalog DataGrid : a set of sites are federated to store large data sets. Data staging and replication management GridFTP : High-performance data movement Reliable File Transfer, Replication Location Service, Data Replication Service Stork: treat data staging as jobs, support many storage systems and transport protocols. Parallel File System Network File System, Lustre (used by IU data capacitor), General Purpose File System (GPFS) (used by IU Bigred ), Parallel Virtual File System (PVFS) Google File System: non-POSIX Other storage systems Object store: Amazon S3, OpenStack Swift Key/Value store: Redis , Riak , Tokyo Cabinet Document-oriented store: Mongo DB, Couch DB Column family: Bigtable / Hbase , Cassandra
11 .Traditional Job Scheduling Use task graph to represent dependency: find a map from graph nodes to physical machines Bag-of-Tasks: Assume tasks of a job are independent. Heuristics: MinMin , MaxMin , Suffrage Batch scheduler Portable Batch System (PBS), Load Sharing Facility (LSF), LoadLeveler , and Simple Linux Utility for Resource Management (SLURM) Maintains job queue and allocates compute resources to jobs (no data affinity) Gang scheduling Synchronizes all processes of a job for simultaneous scheduling Co-scheduling Communication-driven, coordinated by passing messages Dynamic coscheduling, spin block, Periodic Boost, … HYBRID: combine gang scheduling and coscheduling Middleware Condor: harness idle workstations to do useful computation BOINC: volunteer computing Globus : grid computing
12 .MapReduce-related Improvement of vanilla MapReduce Delay scheduling: improve data locality Largest Approximate Time to End: a better metric to make decisions about when/where to run spec. tasks Purlieus: optimize VM provisioning in cloud for MapReduce apps Most of my work falls into this category Enhancements to MapReduce model Iterative MapReduce: Haloop , Twister @IU, Spark Map-Reduce-Merge: enable processing heterogeneous data sets MapReduce online: online aggregation, and continuous queries Alternative models Dryad: use Direct Acyclic Graph to represent job
13 .MapReduce-related Improvement of vanilla MapReduce Delay scheduling: improve data locality Largest Approximate Time to End: a better metric to make decisions about when/where to run spec. tasks Purlieus: optimize VM provisioning in cloud for MapReduce apps Most of my work falls into this category Enhancements to MapReduce model Iterative MapReduce: Haloop , Twister @IU, Spark Map-Reduce-Merge: enable processing heterogeneous data sets MapReduce online: online aggregation, and continuous queries Alternative models Dryad: use Direct Acyclic Graph to represent job
14 .Research Objectives Deploy data parallel system Hadoop to HPC clusters Many HPC clusters exist already (e.g. TeraGrid/XSEDE, FutureGrid ) Evaluate performance – Hadoop and storage systems Improve data locality Analyze relationship between system factors and data locality Analyze the optimality/non-optimality of existing schedulers Propose scheduling algorithm that gives optimal data locality Investigate task granularity Analyze the drawbacks of fixed task granularity Propose algorithms to dynamically adjust task granularity at runtime Investigate resource utilization and speculative execution Explore low resource utilization and inefficiency of running speculative tasks Propose algorithms to allow running tasks to harness idle resources Propose algorithms to make smarter decisions about the execution of speculative tasks Heterogeneity Aware MapReduce scheduling HMR: Build a unified MapReduce cluster across multiple grid clusters Minimize data IO time with real-time network information Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
15 .Performance Evaluation - Hadoop Investigate following factors # of nodes, # of map slots per node, the size of input data Measure job execution time and efficiency Observations Increase # of map slots more tasks run concurrently average task run time is increased job run time is decreased efficiency is decreased (overhead is increased) turning point: beyond it, job runtime is not improved much Vary # of nodes, the size of input data Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
16 .Performance Evaluation – Importance of data locality Measure how important data locality is to performance Developed random scheduler: schedule tasks based on user-specified randomness Conduct experiments for single-cluster, cross-cluster and HPC-style setup (a) Single-cluster (b) Cross-cluster and HPC-style Data locality matters Hadoop performs poorly with drastically heterogeneous network Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization HDFS MapReduce Cluster A HDFS MapReduce Cluster A Cluster B HDFS MapReduce Cluster A Cluster B Single cluster Cross cluster HPC-style (1) w/ high inter-cluster BW (2) w/ low inter-cluster BW Percent of slowdown (%) Number of slots per node
17 .Performance Evaluation - Storage Direct IO (buffer size is 512B) Regular IO with OS Caching operation size(GB) time io-rate size(GB) time io-rate seq-read 1 77.7sec 13.5MB/s 400 1059sec 386.8MB/s seq-write 1 103.2sec 10.2MB/s 400 1303sec 314MB/s Direct IO (buffer size is 512B) Regular IO with OS Caching operation size(GB) time io-rate size(GB) time io-rate seq-read 1 6.1mins 2.8MB/s 400 3556sec 115.2MB/s seq-write 1 44.81mins 390KB/s 400 3856sec 106.2MB/s operation data size(GB) time io-rate seq-read 400 3228sec 126.9MB/s seq-write 400 3456sec 118.6MB/s operation data size(GB) time io-rate seq -write 400 10723sec 38.2MB/s seq -read 400 11454sec 35.8MB/s Local Disk Network File System (NFS) Hadoop Distributed File System (HDFS) OpenStack Swift One worker node . All data accesses are local through HDFS API Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization HDFS and Swift are not efficiently implemented.
18 .Data Locality “distance” between compute and data Different levels: node-level, rack-level, etc. For data-intensive computing, data locality is critical to reduce network traffic Research questions Evaluate how system factors impact data locality and theoretically deduce their relationship Analyze state-of-the-art scheduling algorithms in MapReduce Propose scheduling algorithm giving optimal data locality Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
19 .Data Locality - Analysis Theoretical deduction of relationship between system factors and data locality (for Hadoop scheduling) For simplicity Replication factor is 1 # of slots on each node is 1 The ratio of data local tasks Assumptions Data are randomly placed across nodes Idle slots are randomly chosen from all slots Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
20 .Data Locality – Experiment 1 Measure the relationship between system factors and data locality and verify our simulation y-axis: percent of map tasks that achieve data locality. Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization better Number of slots per node Replication factor Ratio of idle slots Number of tasks (normal scale) Number of tasks (log scale) Number of nodes Num. of idle slots / num. of tasks (redraw a) Num. of idle slots / num. of tasks (redraw e)
21 .Data Locality - Optimality Problem: given a set of tasks and a set of idle slots, assign tasks to idle slots Hadoop schedules tasks one by one Consider one idle slot each time Given an idle slot, schedules the task that yields the “best” data(from task queue) Achieve local optimum; global optimum is not guaranteed Each task is scheduled without considering its impact on other tasks All idle slots need to be considered at once to achieve global optimum We propose an algorithm which gives optimal data locality Reformulate the problem: Construct a cost matrix Cell C( i . j) is the incurred cost if task T i is scheduled to idle slot s j 0: if compute and data are co-located 1: otherwise Reflects data locality Find an assignment to minimize the sum of cost Found a similar mathematical problem: Linear Sum Assignment Problem (LSAP) Convert the scheduling problem to LSAP (not directly mapped) Proved the optimality Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization s 1 s 2 … s m-1 s m T 1 1 1 0 0 0 T 2 0 1 0 0 1 … … … … … … T n-1 0 1 1 0 0 T n 1 0 1 0 1 C( i , j) =
22 .Data Locality – Experiment 2 Measure the performance superiority of our proposed algorithm y-axis: performance improvement (%) over native Hadoop Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
23 .Task Granularity Each task of a parallel job processes some amount of data Use input data size to represent task granularity To decide the optimal granularity is non-trivial Internal structure of input data Operations applied to data Hardware Each map task processes one block of data Block size is configurable (by default 64MB) The granularities of all tasks of a job are the same Drawbacks Limit the maximum degree of concurrency: num. # of blocks Load unbalancing An assumption made by Hadoop: Same input data size ⇒ Similar processing time May not always hold Example: easy and difficult puzzles Input is similar (9 x 9 grid) while solving them requires drastically different amounts of time Granularity Mgmt. overhead Concurrency Load Balancing Small High High Easy Large Low Low Hard Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization Tradeoffs
24 .Task Granularity – Auto. Re-organization Our approach: dynamically change task granularity at runtime Adapt to the real status of systems Non-application-specific Minimize overhead of task re-organization (best effort) Cope with single-job and multi-job scenarios Bag of Divisible Tasks (vs. Bag of Tasks) Proposed mechanisms Task consolidation consolidate tasks T 1 , T 2 , …, T n to T Task splitting split task T to spawn tasks T 1 , T 2 , …, and T m When there are idle slots and no waiting tasks, split running tasks For multi-job env , we prove Shortest-Job-First (SJF) strategy gives optimal job turnaround time*. (arbitrarily divisible work) (UI: unprocessed input data) Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
25 .Task Granularity – Task Re-organization Examples * May change data locality Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
26 .Task Granularity – Single-Job Experiment Synthesized workload: Task execution time follows Gaussian distribution. Fix mean and vary coefficient of variance (CV) Trace-based workload: Based on Google Cluster Data (75% short tasks, 20% long tasks, 5% medium tasks) better better Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization System: 64 nodes, 1 map slot per node (can run 64 tasks concurrently at most)
27 .Task Granularity – Multi-Job Experiment i ) Task execution time is the same for a job (balanced load) ii) Job serial execution time is different (75% short jobs, 20% long jobs, 5% others) i ) Task execution time is different. ii) Job serial execution time is the same (all jobs are equally long) The system is fully load until last “wave” of task execution Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization M/G/s model: inter-arrival time follows exponential dist (inter-arrival time << job execution time) 100 jobs are generated.
28 .Hierarchical MapReduce Motivation Single user may have access to multiple clusters (e.g. FutureGrid + TeraGrid + Campus clusters) They are under the control of different domains Need to unify them to build MapReduce cluster Extend MapReduce to Map-Reduce- GlobalReduce Components Global job scheduler Data transferer Workload reporter/ collector Job manager Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization Local cluster Local cluster Global controller
29 .Heterogeneity Aware Scheduling – Future Work Will focus on network heterogeneity Collect real-time network throughput information Scheduling of map tasks Minimize task completion time based on resource availability data IO/transfer time (depending on network performance) Scheduling of reduce tasks Goal: balance load so that they complete simultaneously data shuffling : impact IO time key distribution at reducer side : impact computation time Sum should be balanced: min{ max S – min S } (S is a scheduling) Both scheduling problems are NP hard. Will investigate heuristics that perform well Data Replication How to increase replication rate in heterogeneous env . Perf . evaluation Data locality Task granularity Heterogeneity Resource utilization
相关推荐
3秒后跳转登录页面
去登陆

