展开查看详情
1 .HashKV : Enabling Efficient Updates in KV Storage via Hashing Helen H . W . Chan † , Yongkun Li ‡ , Patrick P. C. Lee † , Yinlong Xu ‡ † The Chinese University of Hong Kong ‡ University of Science and Technology of China USENIX ATC 2018 1
2 .Background Update-intensive workloads are common in key-value (KV) stores Online transaction processing (OLTP) Enterprise servers Yahoo’s workloads are shifting from reads to writes [*] Log-structured merge (LSM) tree Transform random writes into sequential writes Support efficient range scans Limitation : high read and write amplifications during compaction 2 [*] Sears et al., “ bLSM : A General P urpose L og S tructured M erge T ree ”, SIGMOD 2012
3 .LSM-tree in LevelDB 3 Read SSTables Merge and sort by keys Split into new SSTables High I/O amplifications! Immutable MemTable MemTable flush Memory Disk … … … KV pairs (Sorted) Metadata SSTable L 0 L 1 L k – 1 … Compaction KV pairs
4 .KV Separation [*] Store values separately to reduce LSM-tree size LSM-tree : keys and metadata for indexing vLog : circular log for KV pairs 4 [*] Lu et al., “ WiscKey : Separating Keys from Values in SSD-Conscious Storage”, FAST 2016 KV pairs Key, value Key, value Key, value Log tail Log head vLog
5 .KV Separation Does KV separation solve all problems? High garbage collection (GC) overhead in vLog management More severe if reserved space is limited Update-intensive workloads aggravate GC overhead GC needs to query the LSM-tree to check if KV pairs are valid 5 High write amplification of vLog if reserved space is filled Reserved space not filled up yet Filled reserved space
6 .Our Contributions HashKV , an efficient KV store for update-intensive workloads Extend KV separation with hash-based data grouping for value storage Mitigate GC overhead with smaller I/O amplifications and without LSM-tree queries Three extensions that adapt to workload characteristics E1: Dynamic reserved space allocation E2: Hotness awareness E3: Selective KV separation Extensive prototype experiments 4.6x throughput and 53.4% less write traffic over circular log 6
7 .Hash-based Data Grouping Hash values into fixed-size partitions by keys Partition isolation : all value updates of the same key must go to the same partition in a log-structured manner Deterministic grouping : instantly locate the partition of a given key Allow flexible and lightweight GC Localize all updates of a key in the same partition 7 What if a partition is full? … LSM-tree (for indexing) KV pairs … value store
8 .E1: Dynamic Reserved Space Allocation Layout: Logical address space: main segments (e.g., 64 MiB ) Reserved space: log segments (e.g., 1 MiB ) Segment group : 1 main segment + multiple log segments In-memory segment table tracks all segment groups Checkpointed for fault tolerance 8 Reserved space Segment group Log segment … Main segment … Segment group … LSM-tree
9 .Group-Based Garbage Collection Select a segment group for GC e.g., the one with largest amount of writes Likely to have many invalid KV pairs to reclaim free space Identify all valid KV pairs in selected group Since each group stores updates in a log-structured manner, the latest version of each key must reside at the end of the group No LSM-tree queries required Write all valid KV pairs to new segments Update LSM-tree 9
10 .E2: Hotness Awareness Problem: mix of hot and cold KV pairs Unnecessary rewrites for cold KV pairs Tagging : Add a tag in metadata to indicate presence of cold values Cold values are separately stored Hot-cold value separation GC rewrites small tags instead of values 10
11 .E3: Selective KV Separation KV separation for small values incurs extra costs to access both LSM-tree and value store Selective approach: Large values: KV separation Small values: stored entirely in LSM-tree Open issue: how to distinguish between small and large values? 11
12 .Other Issues Range scans: Leverage read-ahead (via posix_fadvise ) for speedup Metadata journaling: Crash consistency for both write and GC operations Implementation: Multi-threading for writes and GC Batched writes for KV pairs in the same segment group Built on SSDs 12
13 .Putting It All Together: HashKV Architecture 13 … Memory Persistent Storage Write cache (meta, key, value) KV separation (meta, key) LSM-tree MemTable … Value store Reserved space Cold data log Segment group Log segment … Main segment … Segment group Write journal GC journal Segment table Group 1 Group 2 (end pos , segments) (end pos , segments)
14 .Experiments Testbed backed with an SSD RAID array KV stores LevelDB , RocksDB , HyperLevelDB , PebblesDB (default parameters) vLog (circular log) and HashKV : built on LevelDB for KV separation Workloads 40 GiB for main segments + 12 GiB (30%) reserved space for log segments Load : 40 GiB of 1-KiB KV pairs (Phase P0) Update : 40 GiB of updates for three phases (Phases P1, P2, P3 ) P1 : reserved space gradually filled up P2 & P3: reserved space fully filled (stabilized performance) 14
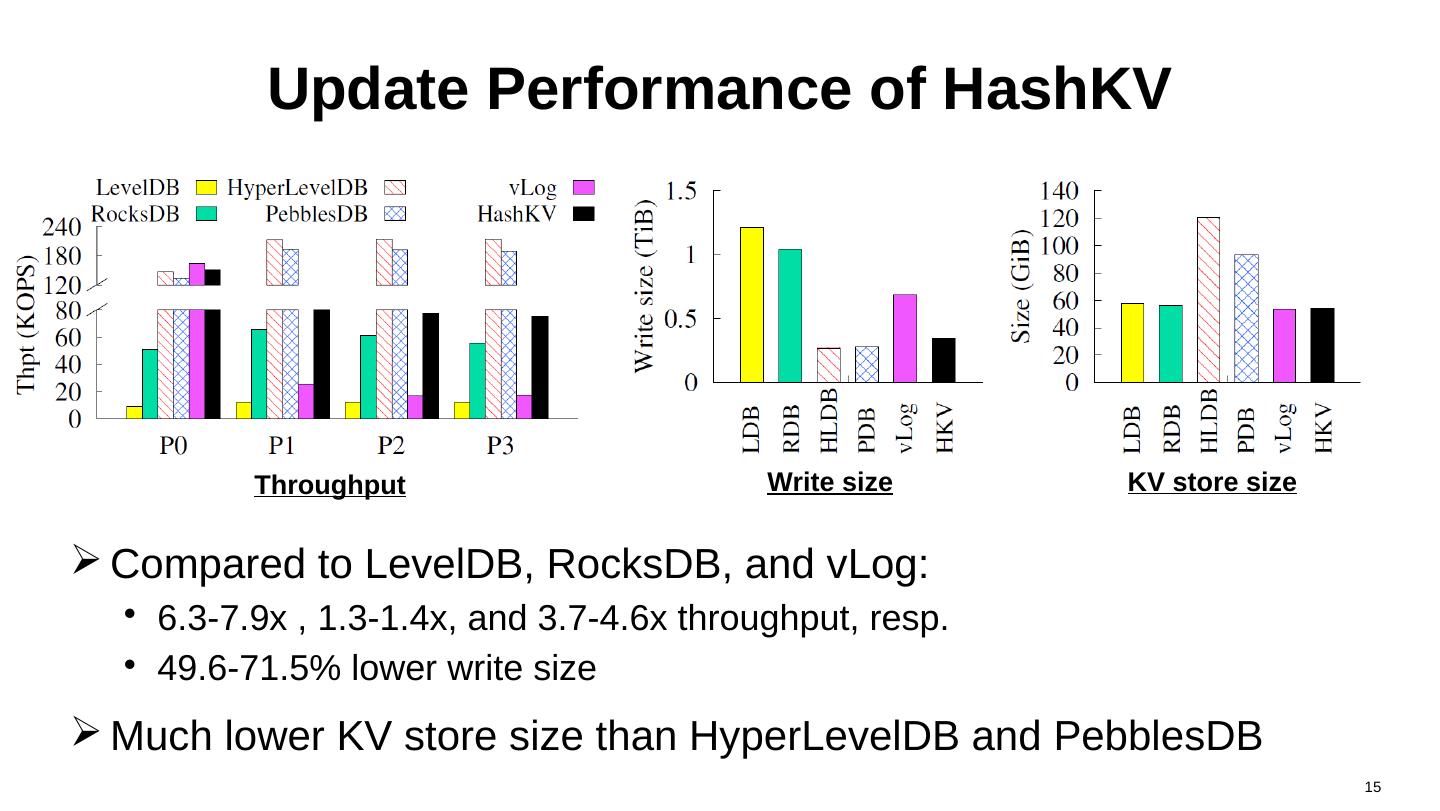
15 .Update Performance of HashKV Compared to LevelDB , RocksDB , and vLog : 6.3-7.9x , 1.3-1.4x, and 3.7-4.6x throughput, resp. 49.6-71.5 % lower write size Much lower KV store size than HyperLevelDB and PebblesDB 15 Throughput Write size KV store size
16 .Impact of Reserved Space HashKV’s throughput increases with reserved space size vLog has high LSM-tree query overhead (80% of latency) 16 Throughput Latency breakdown (V = vLog ; H = HashKV )
17 .Range Scans HashKV maintains high range scan performance 17
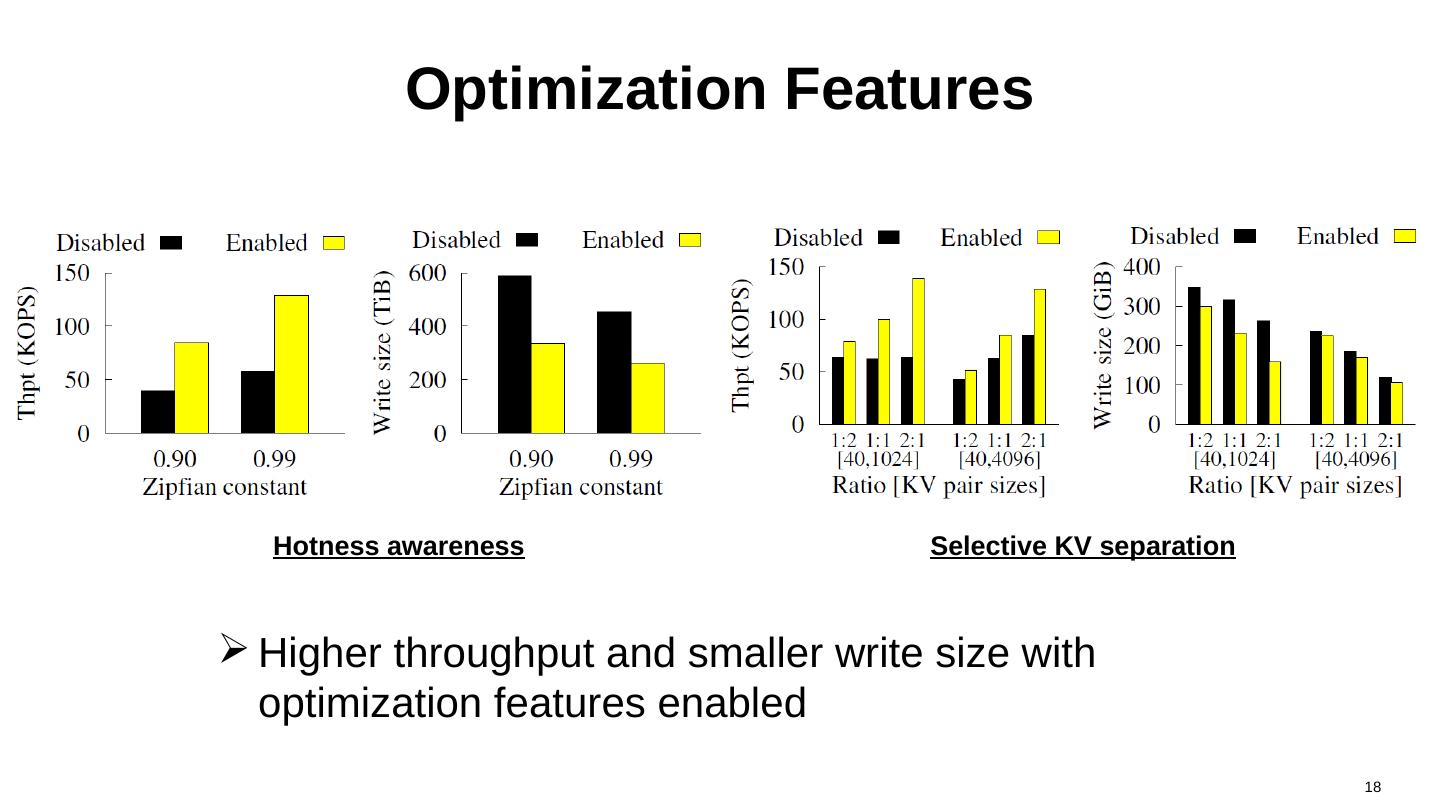
18 .Optimization Features Higher throughput and smaller write size with optimization features enabled 18 Hotness awareness Selective KV separation
19 .Conclusions HashKV : hash-based data grouping for efficient updates Dynamic reserved space allocation Hotness awareness via tagging Selective KV separation More evaluation results and analysis in paper and technical report Source code: http://adslab.cse.cuhk.edu.hk/software/hashkv 19