展开查看详情
1 .高性能计算与天文学 应用优化 陈俊 博士 浪潮 应用支持团队
2 .Contents 如何进行高性能计算应用优化? 浪潮对天文学 HPC 应用的相关积累 典型案例分享: SKA 平方公里阵列 射电望远镜 发展中的天文学:数据挖掘、机器学习和人工智能
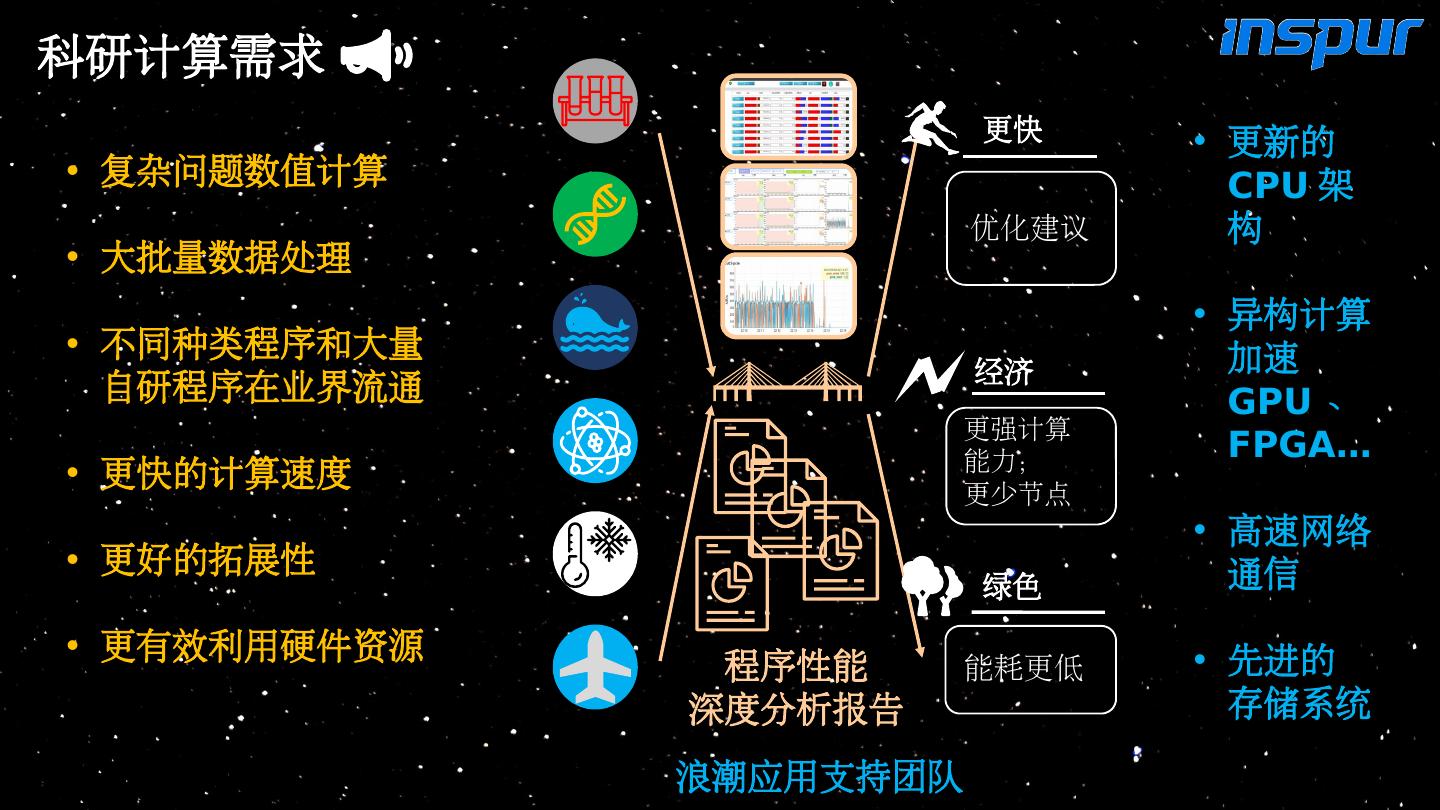
4 .科研计算需求 浪潮应用支持团队 程序性能 深度分析报告 更快 优化建议 经济 更 强计算 能力; 更 少节点 绿色 能耗更低 复杂问题数值计算 大批量数据处理 不同种类程序和大量自研程序在业界流通 更快的计算速度 更好的拓展性 更有效利用硬件资源 更新的 CPU 架构 异构计算加速 GPU 、 FPGA… 高速网络通信 先进 的 存储系统
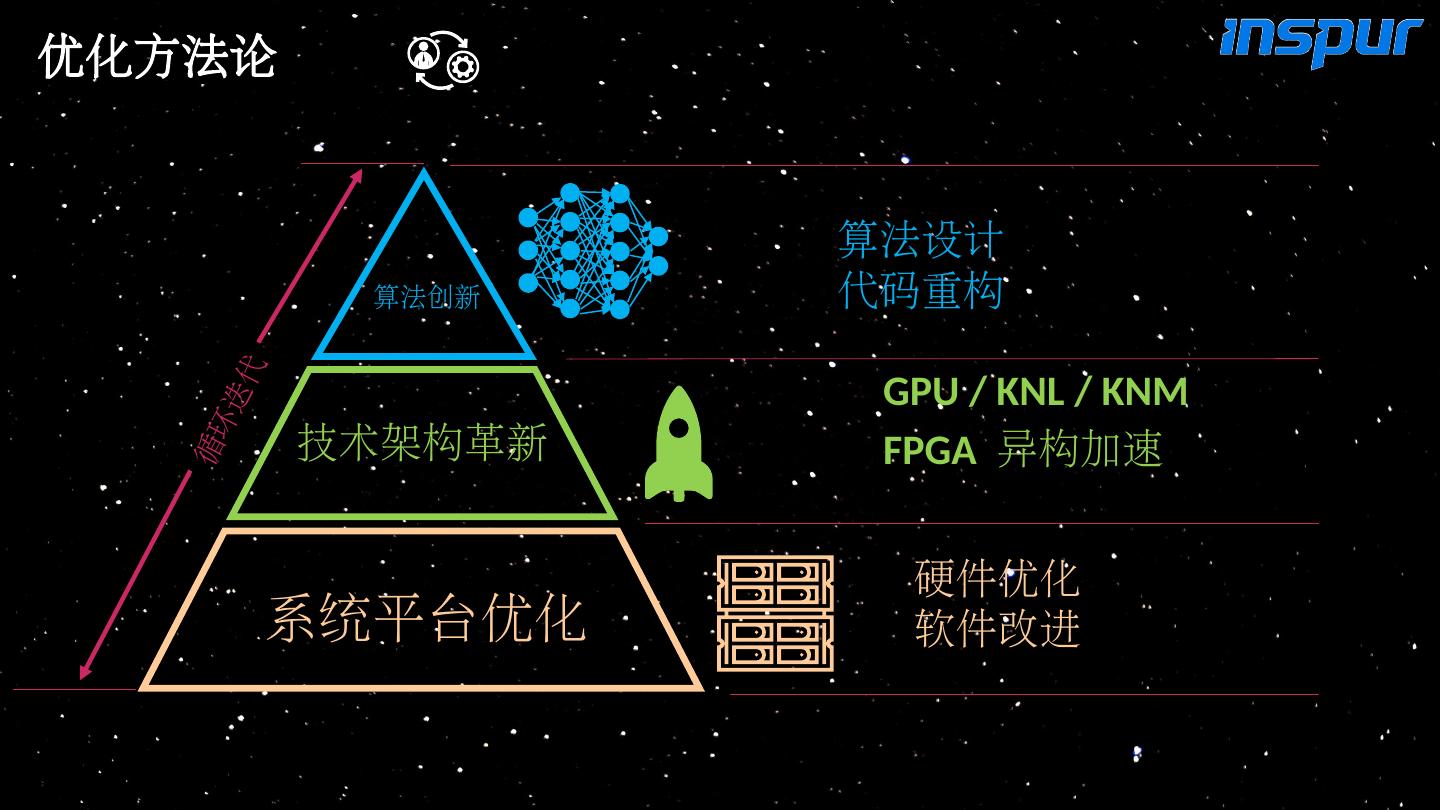
5 .优化方法论 硬件优化 软件改进 GPU / KNL / KNM FPGA 异构加速 算法设计 代码重构 算法创新 技术架构革新 系统 平台优化 循环迭代
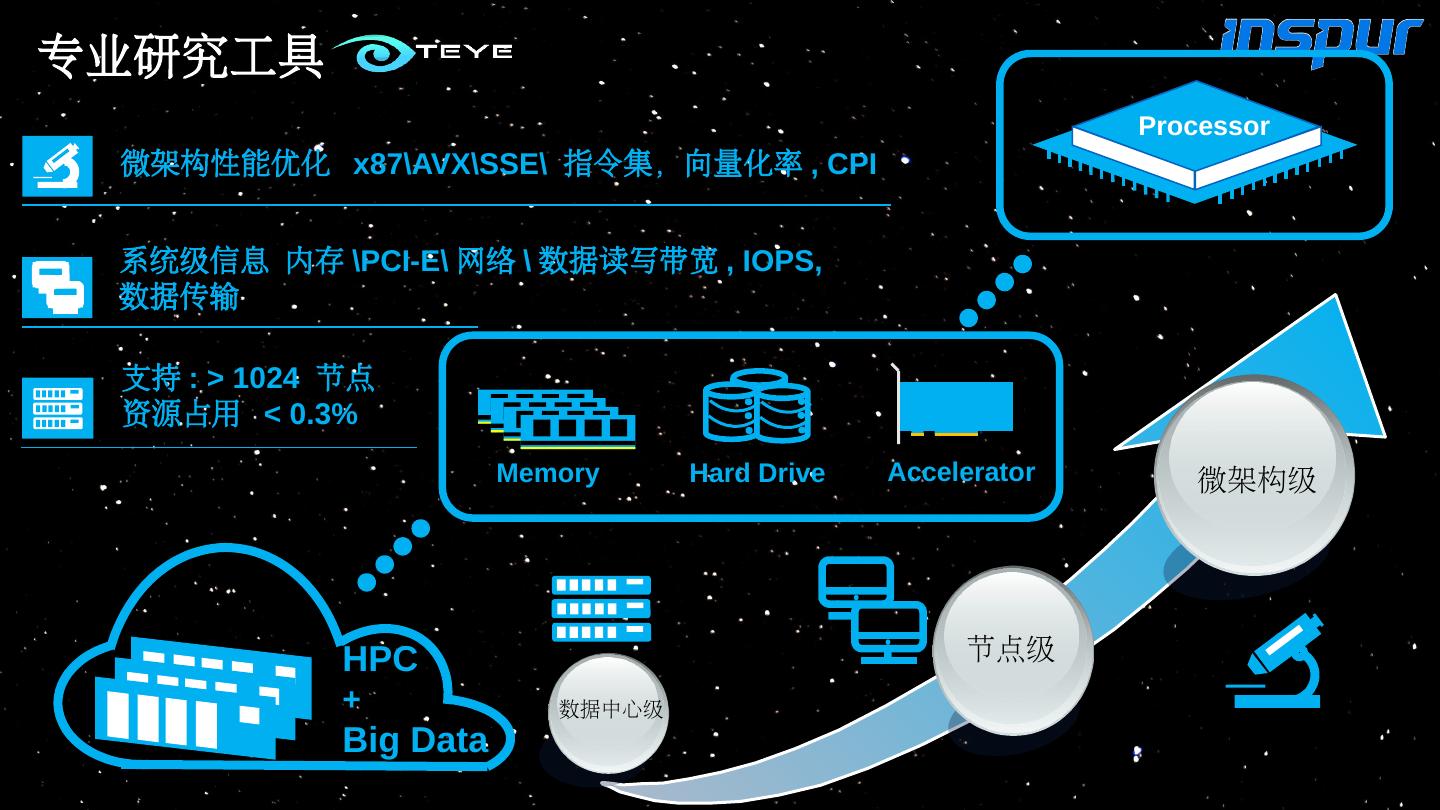
6 .HPC + Big Data Memory Hard Drive Accelerator 数据中心级 节点级 微架构级 支持 : > 1024 节点 资源占用 < 0.3% 系统级信息 内存 \PCI-E\ 网络 \ 数据读写带宽 , IOPS, 数据传输 微架构性能优化 x87\AVX\SSE \ 指令集,向量化率 , CPI Processor 专业研究工具
7 .~10 行业白皮书 ~20 应用性能 分析白皮书 >100 基准测试报告 Sandybridge Ivybridge Haswell Broadwell Skylake GPU FPGA MIC KNL KNM Infiniband OmniPath Ethernet Lustre BeeGFS GPFS NFS Processor Accelerator Network Storage 经验积累
8 .经验积累 ~20 研究领域 ~300 应用种类 ~900 应用程序 ~100 深度分析报告
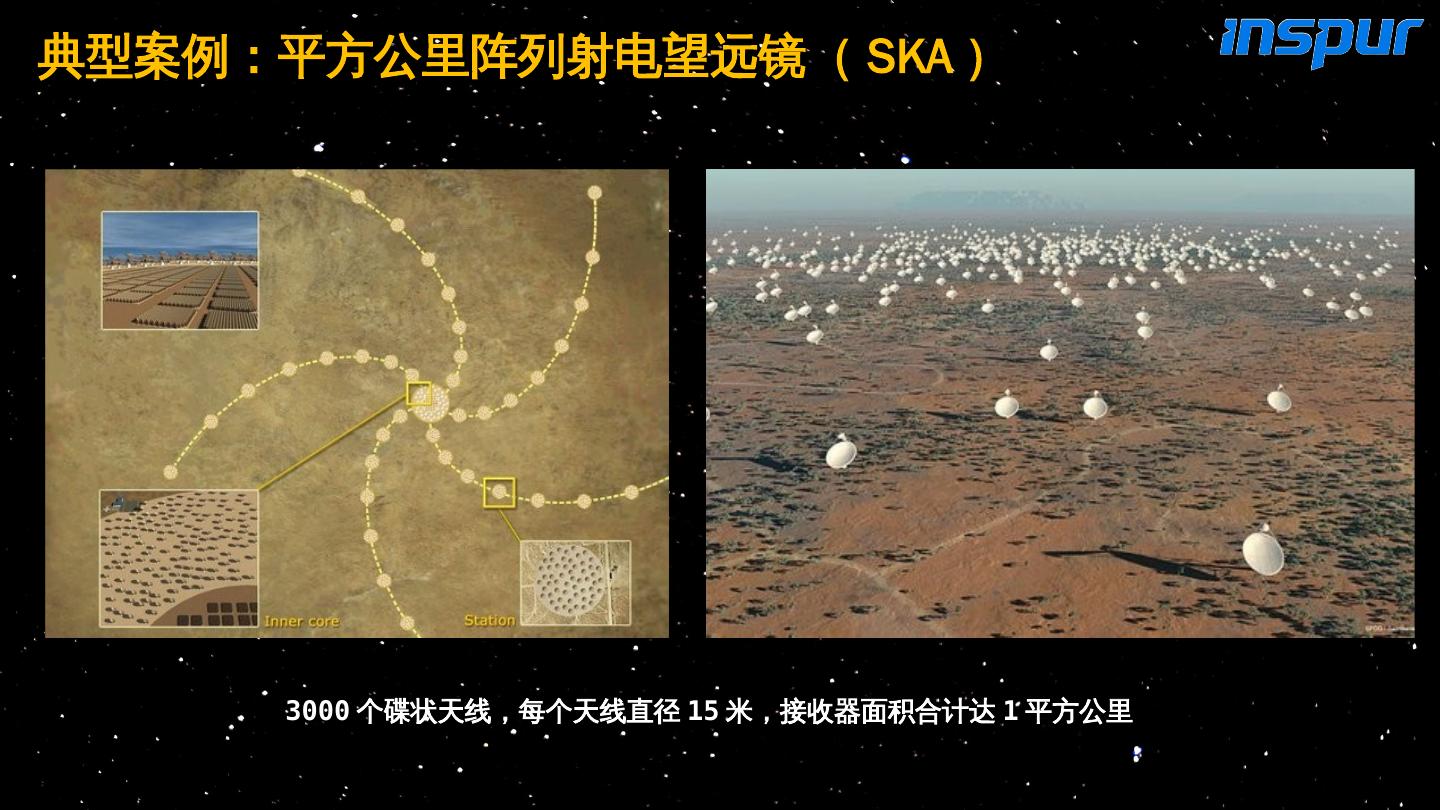
9 .3000 个碟状天线,每个天线直径 15 米,接收器面积合计达 1 平方公里 典型案例:平方公里 阵列 射电望远镜( SKA )
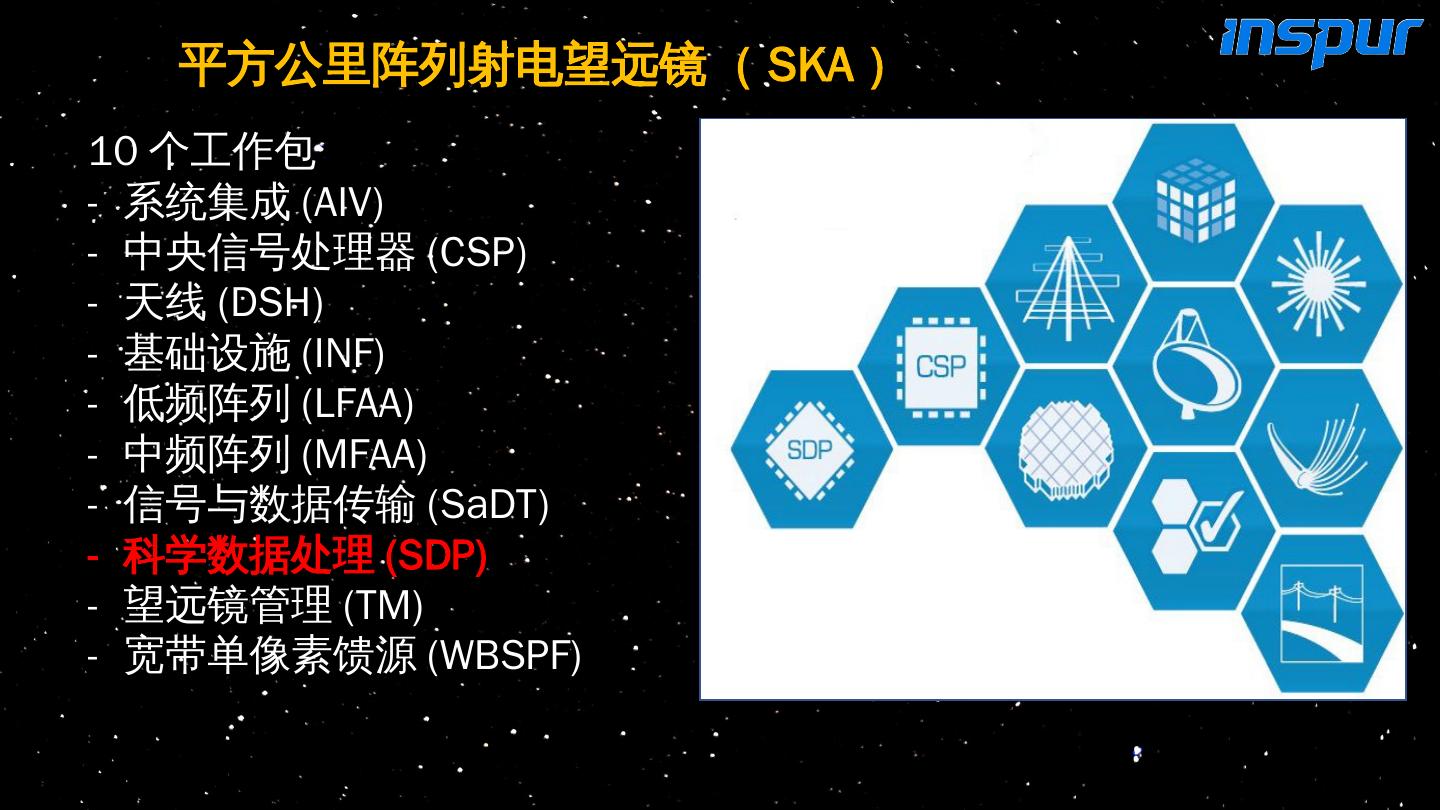
10 .平方公里阵列 射电望远镜( SKA ) 10 个工作包 - 系统集成 (AIV) - 中央信号处理器 (CSP) - 天线 (DSH) - 基础设施 (INF) - 低频阵列 (LFAA) - 中频阵列 (MFAA) - 信号与数据传输 ( SaDT ) - 科学数据处理 (SDP) - 望远镜管理 (TM) - 宽带单像素馈源 ( WBSPF )
11 .浪潮参与 SDP 情况 SDP 国际联盟 参与计算平台任务 计算部件、存储等 每两周一次网络视频会议 50 次 承担关键软件优化任务 SDP 中方联盟 牵头计算平台任务 SKA Telescope Science Data Procesor (SDP) Project Inspur
12 .SKA 高性能应用特点 数据量庞大 覆盖频率 70~10000MHz 3000 个天线碟型阵列 高频每秒 1600 亿比特数据 中、低频大量数据 计算能力需求 >1000P Top1 太湖之光约 125P Top2 天河二号约 55P
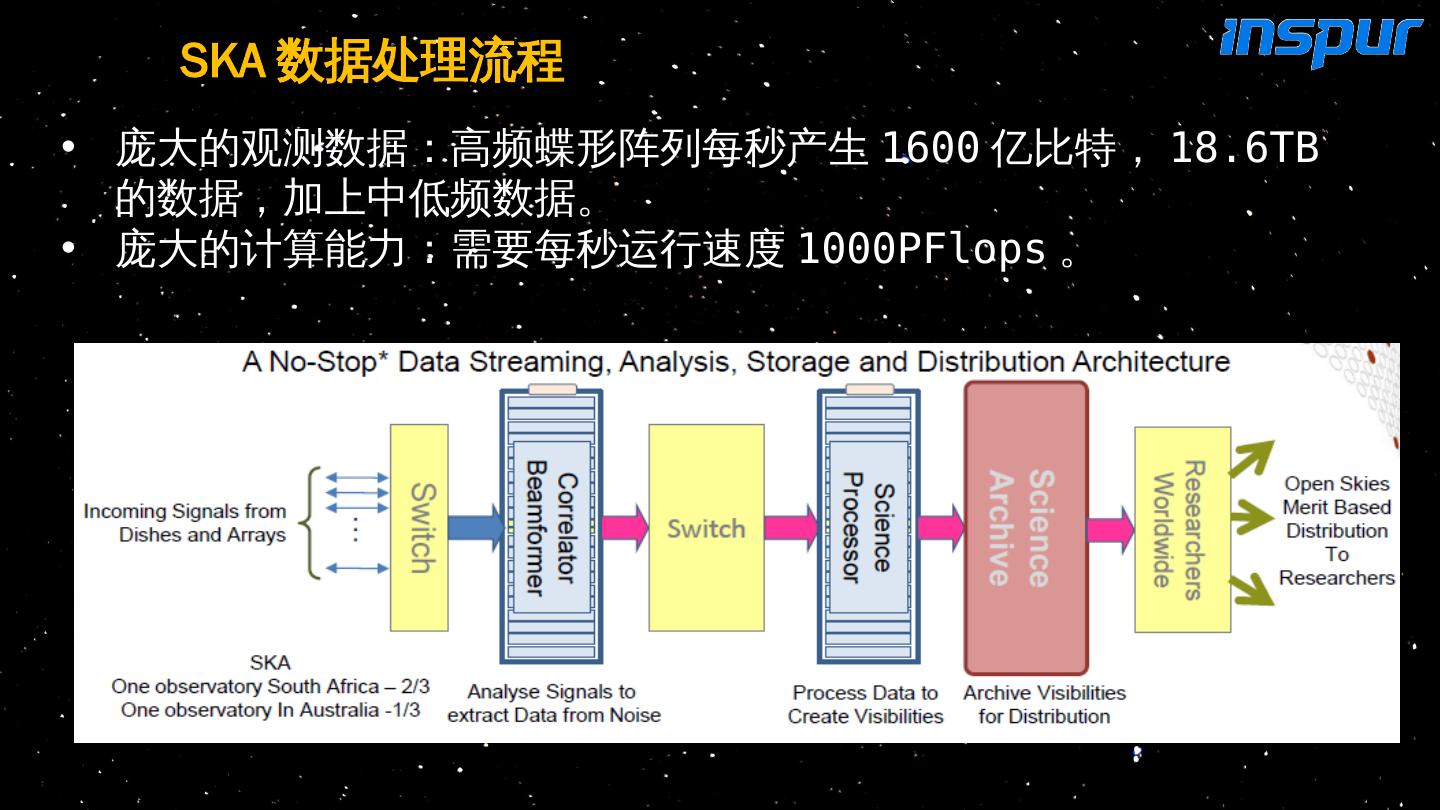
13 .SKA 数据处理流程 庞大的观测 数据: 高频 蝶形阵列每秒产生 1600 亿比特, 18.6TB 的 数据 , 加 上 中 低频 数据 。 庞大的计算能力: 需要每秒运行速度 1000PFlops 。
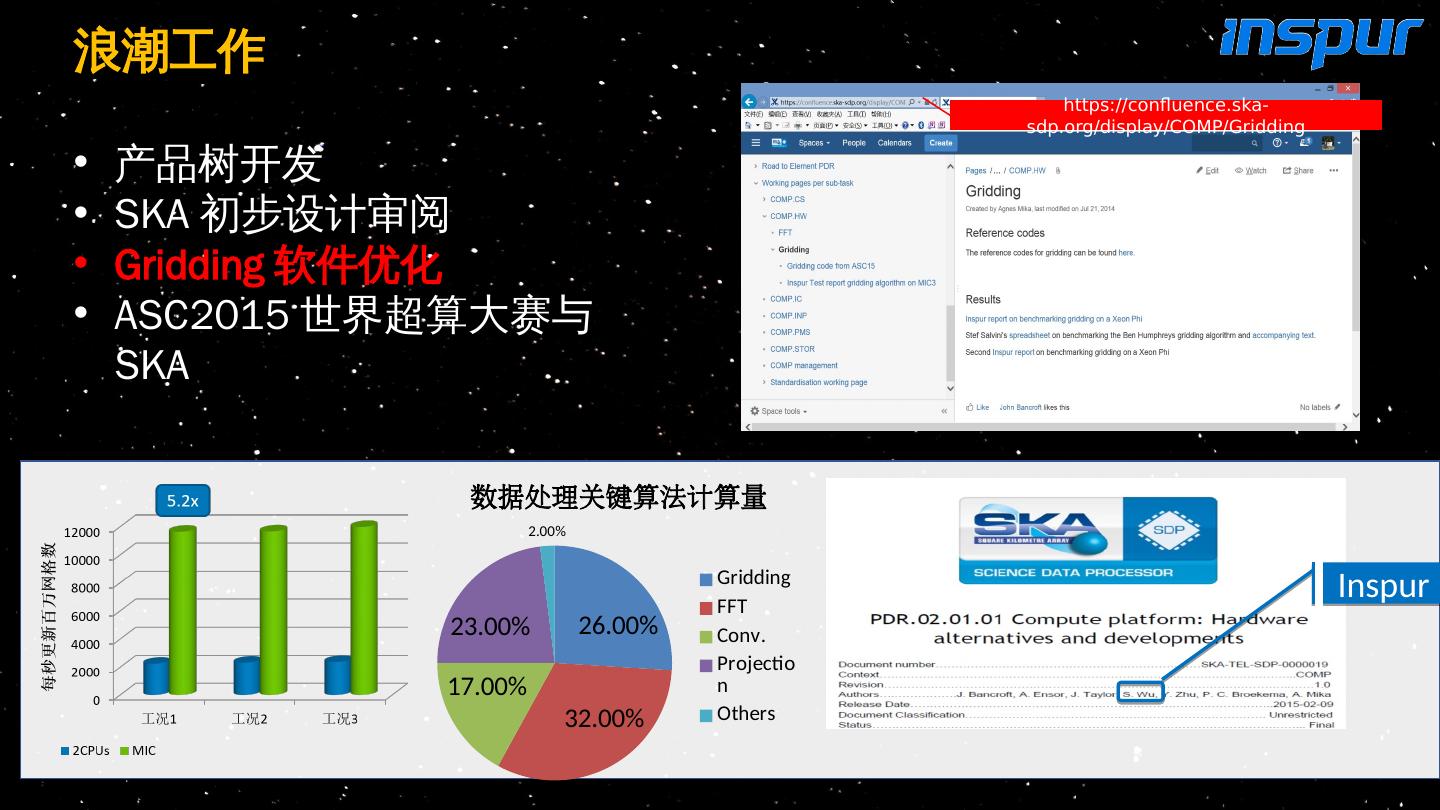
14 .浪潮工作 产品树开发 SKA 初步设计审阅 Gridding 软件优化 ASC2015 世界超算大赛与 SKA https://confluence.ska-sdp.org/display/COMP/Gridding Inspur
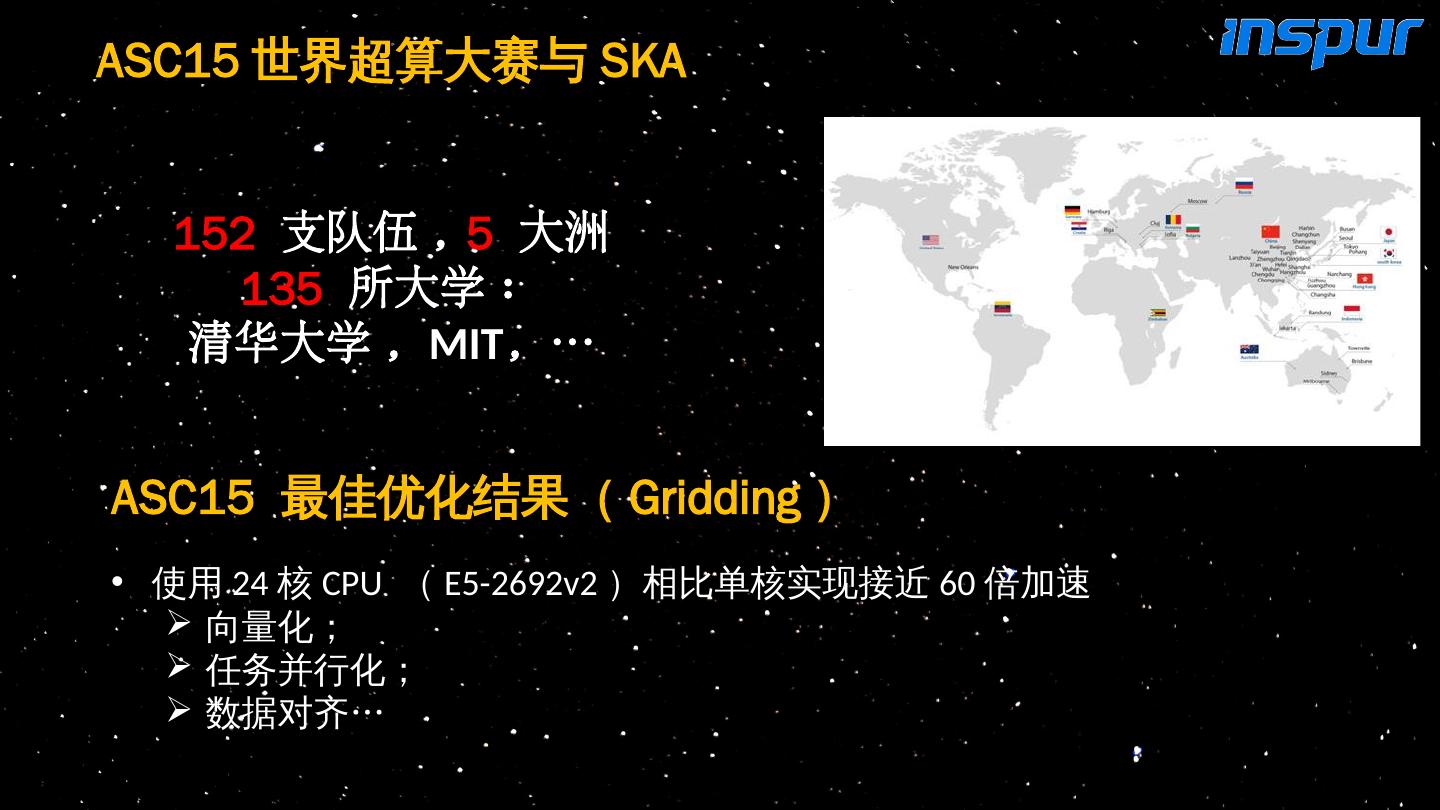
15 .152 支队伍 , 5 大洲 135 所大学 : 清华大学 , MIT , … ASC15 世界超算大赛与 SKA ASC15 最佳优化结果( Gridding ) 使用 24 核 CPU ( E5-2692v2 )相比单核实现接近 60 倍加速 向量化; 任务并行化; 数据对齐 …
16 .应用优化和特征分析的经验 Solutions
17 .Gridding 需求及解决方案 科研业务需求: 数据量巨大 内存需求大 计算量大 SKA 针对化高性能解决方案: 专业 级的直连存储 + 并行文件系统 大 内存服务器或胖节点 单节点最高可达 6TB 内存 综合性能最优的 Intel CPU 系统的高稳定性 内存密集型; 存储密集型;
18 .浪潮高性能 — 面向百亿亿次 (E 级 ) 计算的整体能力 平方公里阵列射电望远镜( SKA ) 世界 最大 的天文望远镜合作项目 浪潮为项目全球唯一超算厂商 面向 E 级超算架构研究 联合先进厂商 浪潮 INTEL 并行计算 联合实验室 浪潮 NVIDIA 云超算应用创新中心 面向 E 级超算应用优化 发展和分析调优理论与工具 理论 / 算法革新 技术架构创新 MIC/GPU/FPGA 系统平台优化 CPU/Mem/IO/Net/OS/ Mgt / Schd 面向 E 级超算应用开发 参加国际合作
19 .中国高性能计算机 Top 100 冠军 浪潮 46 套高性能集群上榜 世界 Top 500 list Top 3 浪潮 56 套集群上榜 2017 年 11 月最新数据
20 .天文学的发展 从一个组独立研究的领域,发展为一个 大数据、大组织 的领域 从关注某一类特殊天体进行研究,发展为高精度 大范围巡天 等研究任务; 使用 GPU 进行 Nbody 模拟 与 人工智能 AI 的相结合 对庞大观测数据进行数据挖掘、模式识别和机器学习 利用有标签数据训练 AI 对 行星分类
21 .浪潮高性能服务人工智能计算 领先的硬件平台 强大的应用能力 完善的生态环境 浪潮人工智能计算平台 2/4/8 卡 GPU 平台 /KNL 平台 /FPGA 平台 互联网人工智能应用合作 百度无人驾驶汽车 阿里智能 ” 店小二 ” 科大讯飞智能语音识别 打造人工智能生态环境 人工智能并行深度学习框架 Caffe-MPI KEEP 平台,深度 学习 KNL 训练营 AI Station ,人工智能管理调度软件
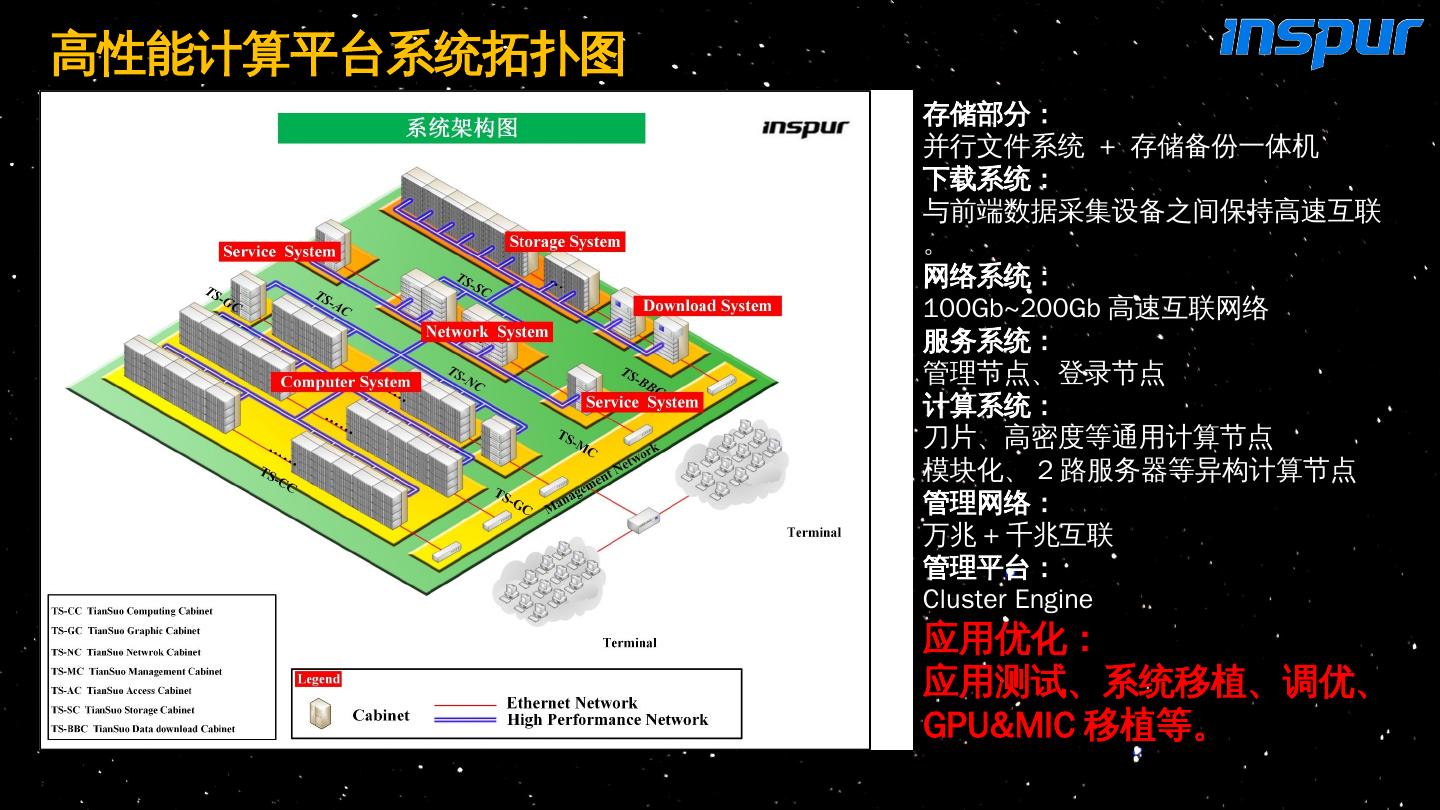
22 .高性能计算平台系统拓扑图 存储部分: 并行 文件系统 + 存储备份一体机 下载系统: 与前端数据采集设备之间保持高速互联。 网络 系统: 100Gb~200Gb 高速互联网络 服务系统: 管理节点、登录节点 计算系统: 刀片、高密度等通用计算节点 模块化、 2 路服务器等异构计算节点 管理 网络: 万兆 + 千兆互联 管理平台: Cluster Engine 应用优化: 应用测试、系统移植、调优、 GPU&MIC 移植等。
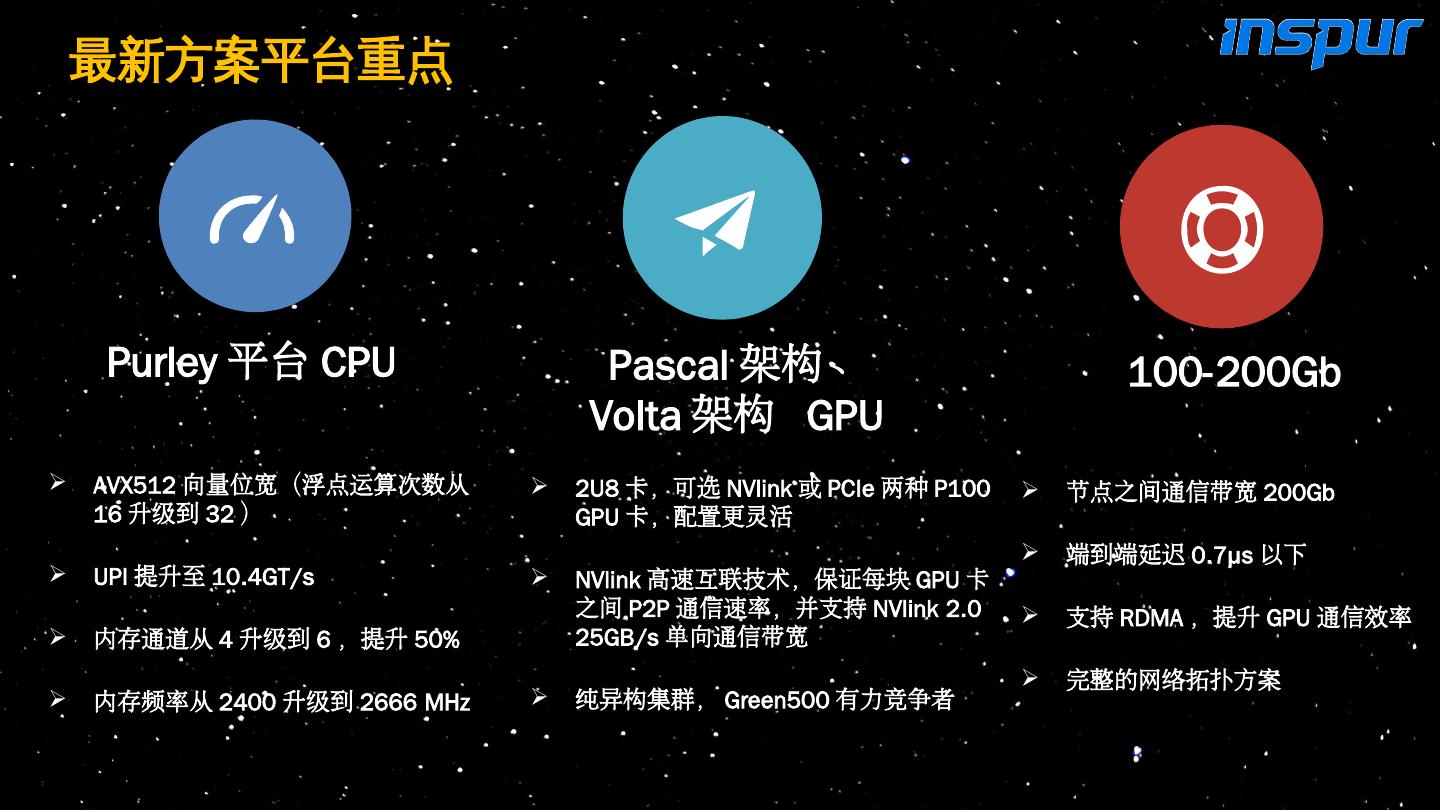
23 .Purley 平台 CPU Pascal 架构 、 Volta 架构 GPU 100-200G b 最新方案平台重点 AVX512 向量位宽(浮点运算次数从 16 升级到 32 ) U PI 提升至 10.4GT/s 内存 通道 从 4 升级到 6 ,提升 50 % 内存频率从 2400 升级到 2666 MHz 节点之间通信带宽 200Gb 端到 端延迟 0.7μs 以下 支持 RDMA ,提升 GPU 通信效率 完整的网络拓扑方案 2U8 卡,可选 NVlink 或 PCIe 两种 P100 GPU 卡,配置更灵活 NVlink 高速互联技术,保证每块 GPU 卡之间 P2P 通信速率,并支持 NVlink 2.0 25GB/s 单向通信带宽 纯异构集群, Green500 有力竞争者
24 .Thanks for your attention Furthur Information: chen_jun@inspur.ccom 18611768812