















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cloud-Scale Information Retrieval
Facebook作为全球数一数二的社交网络互联网公司,照片和视频的存取是非常频繁的,如何高效的把照片和视频信息展现给普通用户,这个问题看似简单却又比较复杂。作者从问题的根源出发,先提出了用DHT(分布式哈希表)算法的核心,然后从数据的缓存策略,谈到Facebook的TAO系统,利用社交网络有图的关系,设计更好的缓存策略,又从CDN,谈到了更高效的文件存储框架Haystack,其中的每一个子系统都值得我们好好了解。
展开查看详情
1 .Cloud-Scale Information Retrieval Ken Birman, CS5412 Cloud Computing CS5412 Spring 2015
2 .Styles of cloud computing Think about Facebook… We normally see it in terms of pages that are image-heavy But the tags and comments and likes create “relationships” between objects within the system And FB itself tries to be very smart about what it shows you in terms of notifications, stuff on your wall, timeline, etc… How do they actually get data to users with such impressive real-time properties? (often << 100ms!) CS5412 Spring 2015
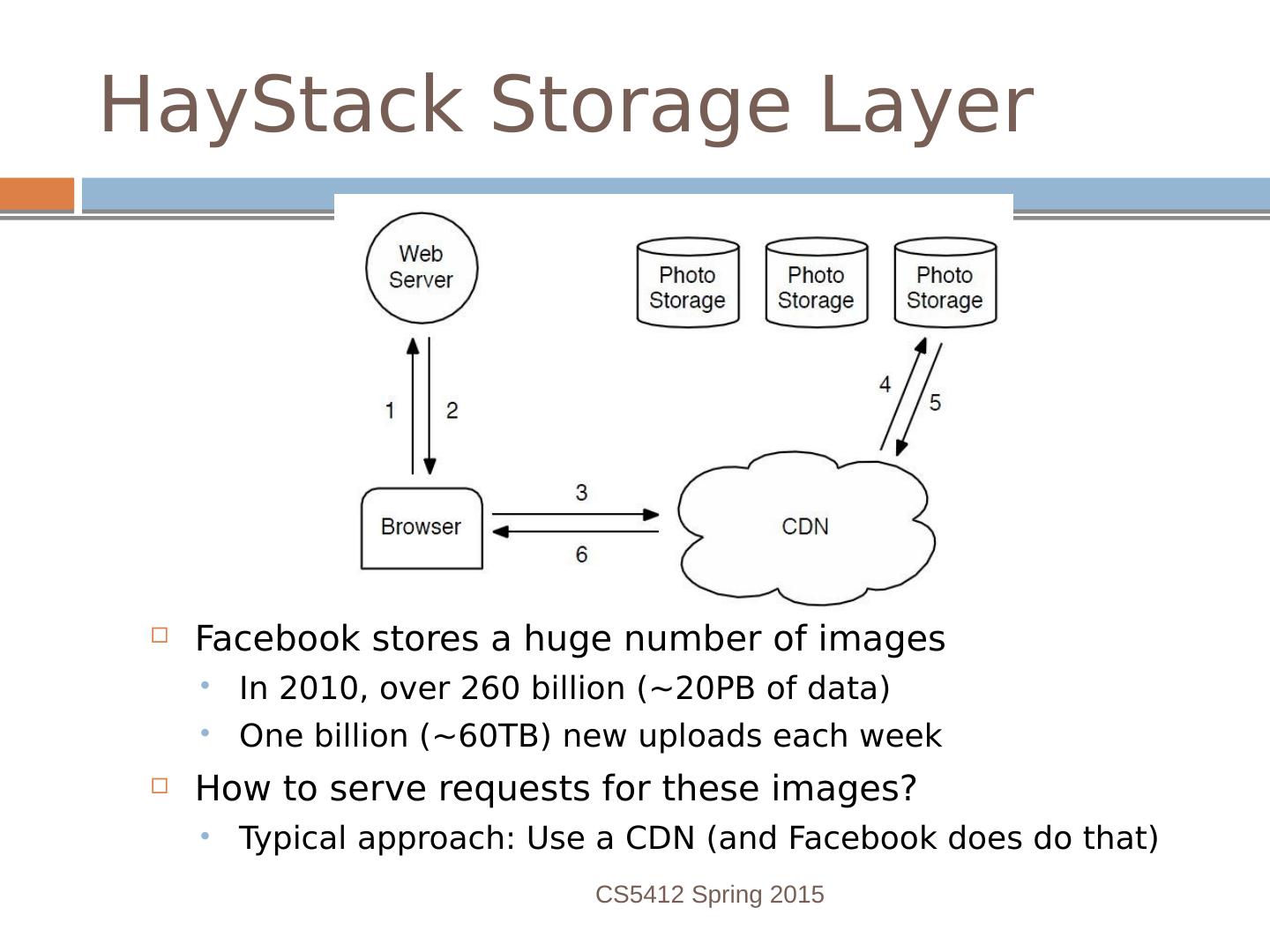
3 .Facebook image “stack” Role is to serve images (photos, videos) for FB’s hundreds of millions of active users About 80B large binary objects (“blob”) / day FB has a huge number of big and small data centers “Point of presense” or PoP: some FB owned equipment normally near the user Akamai: A company FB contracts with that caches images FB resizer service: caches but also resizes images Haystack: inside data centers, has the actual pictures (a massive file system) CS5412 Spring 2015
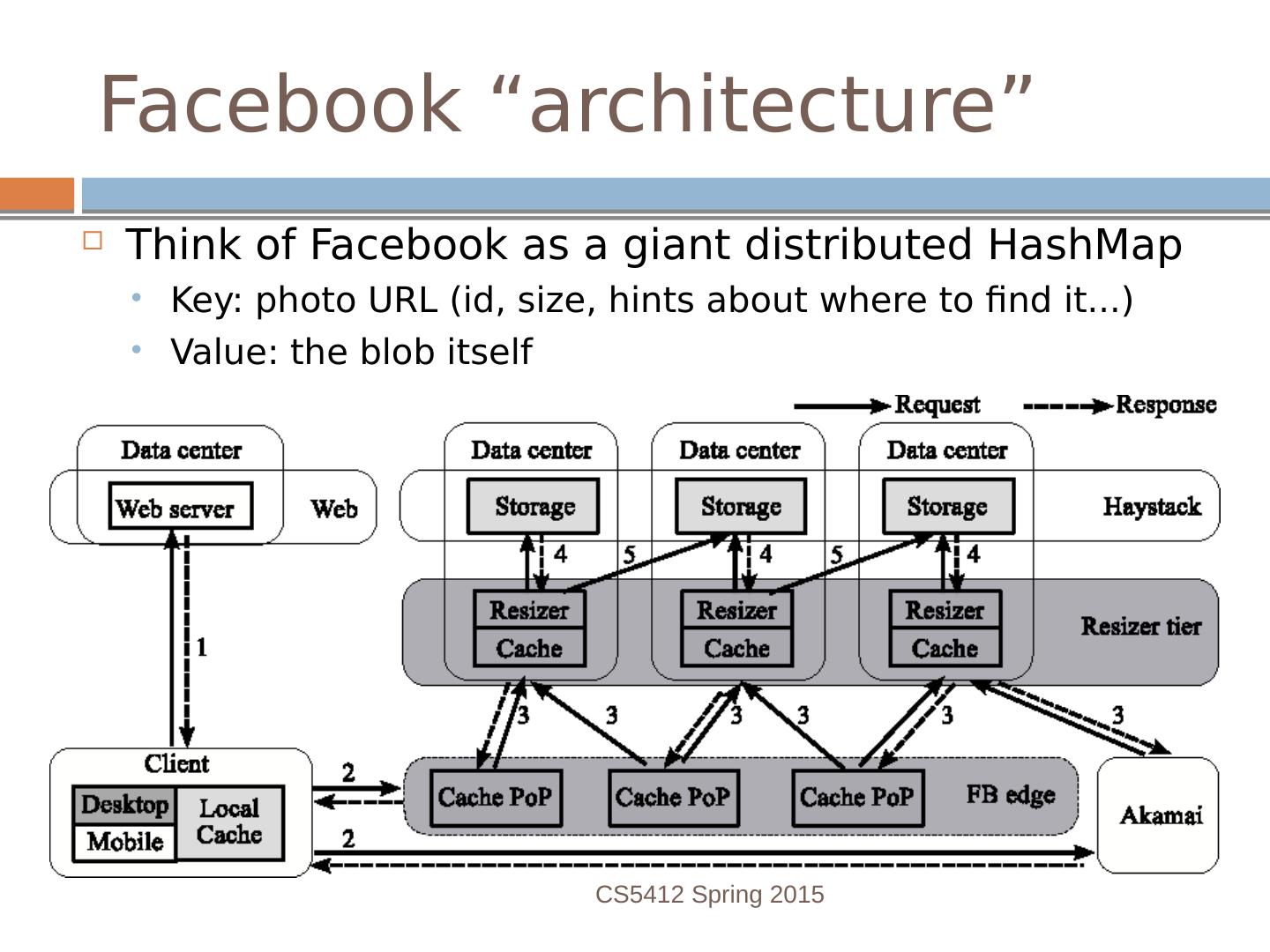
4 .Facebook “architecture” Think of Facebook as a giant distributed HashMap Key: photo URL (id, size, hints about where to find it...) Value: the blob itself CS5412 Spring 2015
5 .Facebook traffic for a week Client activity varies daily.... ... and different photos have very different popularity statistics CS5412 Spring 2015
6 .Observations There are huge daily, weekly, seasonal and regional variations in load, but on the other hand the peak loads turn out to be “similar” over reasonably long periods like a year or two Whew! FB only needs to reinvent itself every few years Can plan for the worst-case peak loads… And during any short period, some images are way more popular than others: Caching should help CS5412 Spring 2015
7 .Facebook’s goals? Get those photos to you rapidly Do it cheaply Build an easily scalable infrastructure With more users, just build more data centers ... they do this using ideas we’ve seen in cs5412! CS5412 Spring 2015
8 .Best ways to cache this data? Core idea: Build a distributed photo cache (like a HashMap, indexed by photo URL) Core issue: We could cache data at various places On the client computer itself, near the browser In the PoP In the Resizer layer In front of Haystack Where’s the best place to cache images? Answer depends on image popularity... CS5412 Spring 2015
9 .Distributed Hash Tables It is easy for a program on biscuit.cs.cornell.edu to send a message to a program on “jam.cs.cornell.edu” Each program sets up a “network socket Each machine has an IP address, you can look them up and programs can do that too via a simple Java utility Pick a “port number” (this part is a bit of a hack) Build the message (must be in binary format) Java utils has a request CS5412 Spring 2015
10 .Distributed Hash Tables It is easy for a program on biscuit.cs.cornell.edu to send a message to a program on “jam.cs.cornell.edu” ... so, given a key and a value Hash the key Find the server that “owns” the hashed value Store the key,value pair in a “local” HashMap there To get a value, ask the right server to look up key CS5412 Spring 2015
11 .Distributed Hash Tables dht.Put(“ken”,2110) (“ken”, 2110) dht.Get(“ken”) “ken”.hashcode()%N=77 IP.hashcode()%N=77 123.45.66.781 123.45.66.782 123.45.66.783 123.45.66.784 IP.hashcode()%N=98 IP.hashcode()%N=13 IP.hashcode()%N=175 hashmap kept by 123.45.66.782 “ken”.hashcode()%N=77 CS5412 Spring 2015
12 .How should we build this DHT? DHTs and related solutions seen so far in CS5412 Chord, Pastry, CAN, Kelips MemCached , BitTorrent They differ in terms of the underlying assumptions Can we safely assume we know which machines will run the DHT? For a P2P situation, applications come and go at will For FB, DHT would run “inside” FB owned data centers, so they can just keep a table listing the active machines… CS5412 Spring 2015
13 .FB DHT approach DHT is actually split into many DHT subsystems Each subsystem lives in some FB data center, and there are plenty of those (think of perhaps 50 in the USA) In fact these are really side by side clusters: when FB builds a data center they usually have several nearby buildings each with a data center in it, combined into a kind of regional data center They do this to give “containment” (floods, fires) and also so that they can do service and upgrades without shutting things down (e.g. they shut down 1 of 5…) CS5412 Spring 2015
14 .FB DHT approach DHT is actually split into many DHT subsystems Each subsystem lives in some FB data center, and there are plenty of those (think of perhaps 50 in the USA) In fact these are really side by side clusters: when FB builds a data center they usually have several nearby buildings each with a data center in it, combined into a kind of regional data center They do this to give “containment” (floods, fires) and also so that they can do service and upgrades without shutting things down (e.g. they shut down 1 of 5…) CS5412 Spring 2015
15 .Facebook cache effectiveness Existing caches are very effective... ... but different layers are more effective for images with different popularity ranks CS5412 Spring 2015
16 .Facebook cache effectiveness Each layer should “specialize” in different content. Photo age strongly predicts effectiveness of caching CS5412 Spring 2015
17 .Hypothetical changes to caching? We looked at the idea of having Facebook caches collaborate at national scale… … and also at how to vary caching based on the “busyness” of the client CS5412 Spring 2015
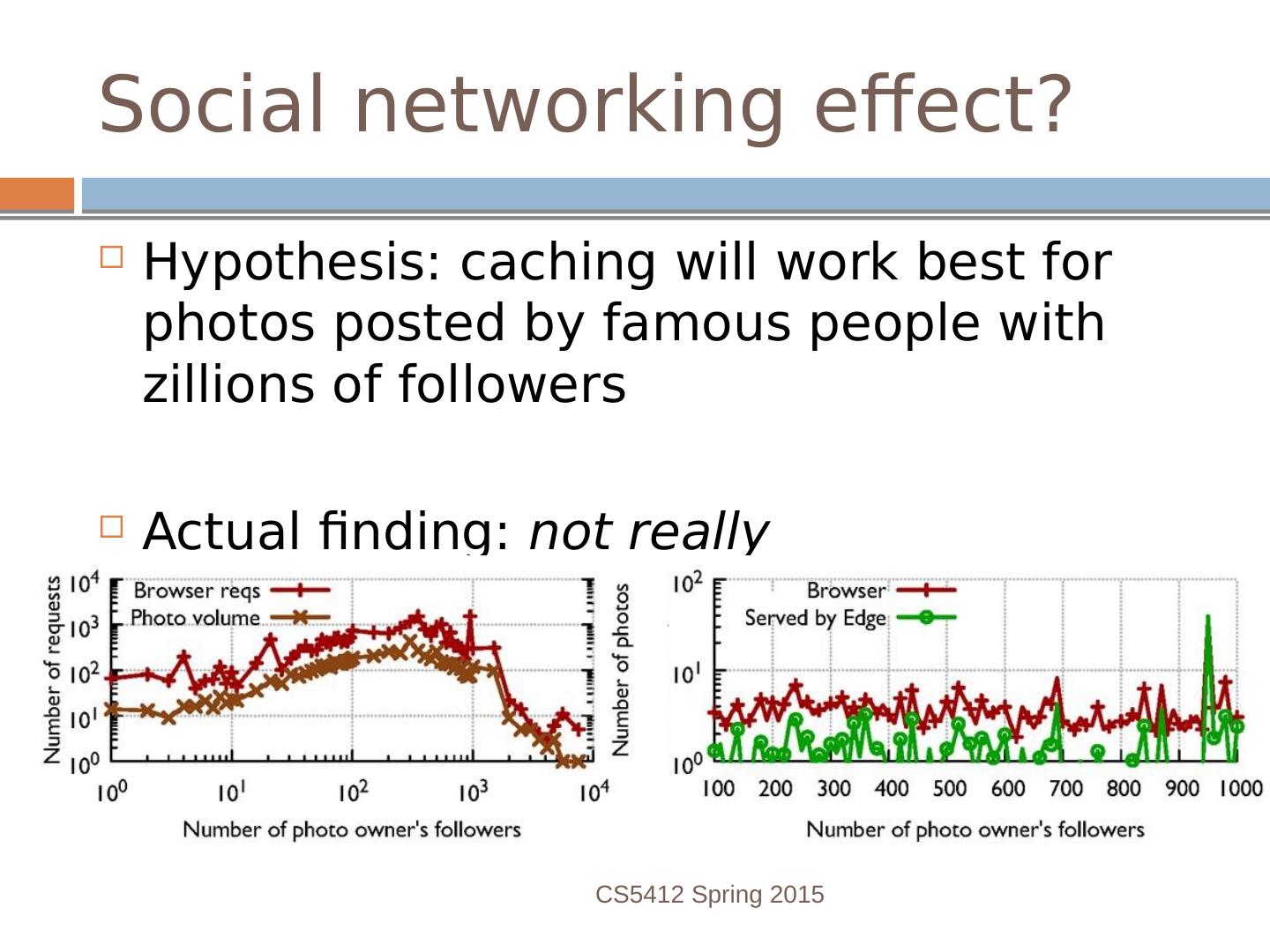
18 .Social networking effect? Hypothesis: caching will work best for photos posted by famous people with zillions of followers Actual finding: not really CS5412 Spring 2015
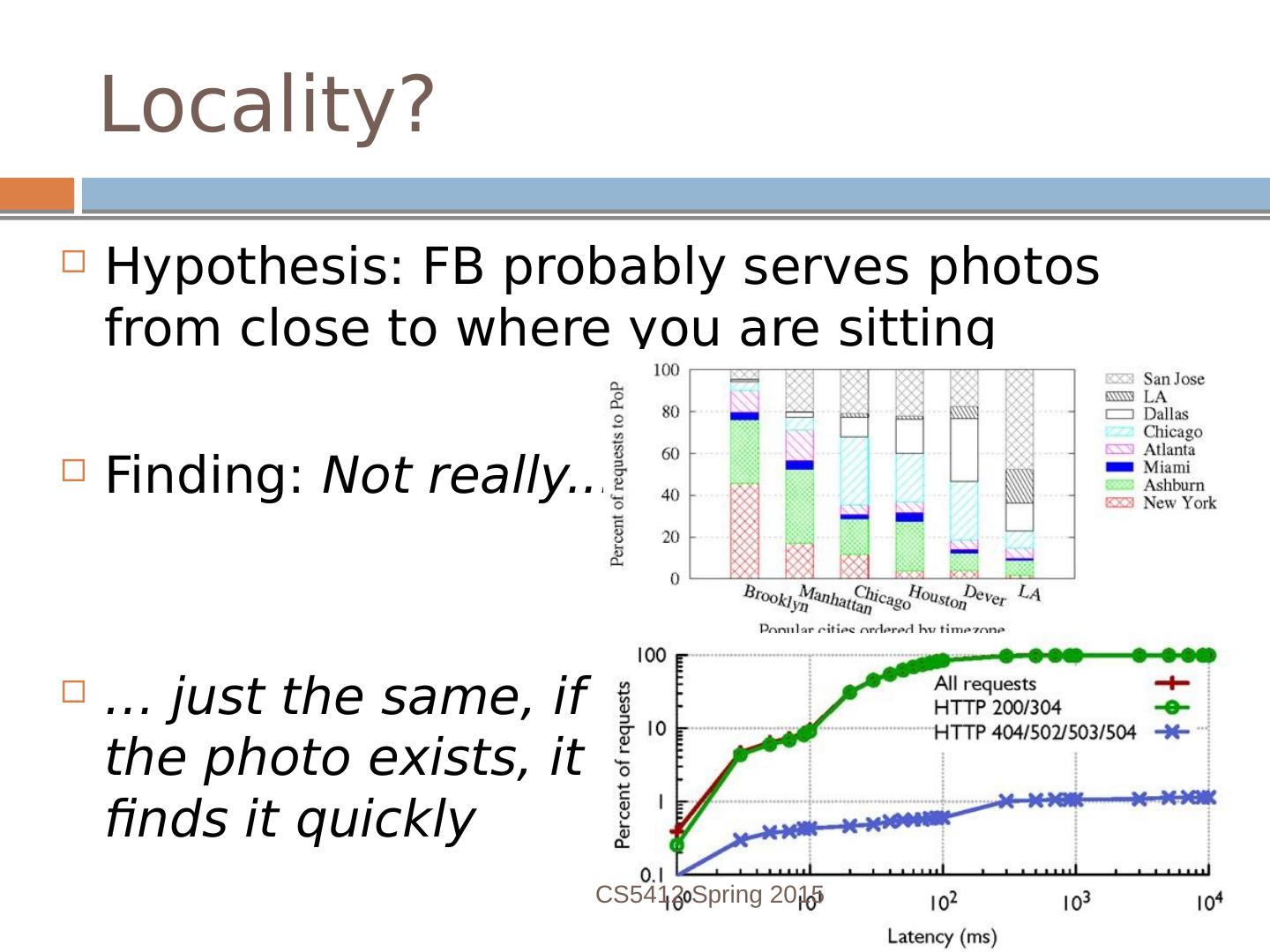
19 .Locality? Hypothesis: FB probably serves photos from close to where you are sitting Finding: Not really... … just the same, if the photo exists, it finds it quickly CS5412 Spring 2015
20 .Can one conclude anything? Learning what patterns of access arise, and how effective it is to cache given kinds of data at various layers, we can customize cache strategies Each layer can look at an image and ask “should I keep a cached copy of this, or not?” Smart decisions Facebook is more effective! CS5412 Spring 2015
21 .Strategy varies by layer Browser should cache less popular content but not bother to cache the very popular stuff Akamai/PoP layer should cache the most popular images, etc... We also discovered that some layers should “cooperatively” cache even over huge distances Our study discovered that if this were done in the resizer layer, cache hit rates could rise 35%! CS5412 Spring 2015
22 .Overall picture in cloud computing Facebook example illustrates a style of working Identify high-value problems that matter to the community because of the popularity of the service, the cost of operating it, the speed achieved, etc Ask how best to solve those problems, ideally using experiments to gain insight Then build better solutions Let’s look at another example of this pattern CS5412 Spring 2015
23 .Caching for TAO Facebook recently introduced a new kind of database that they use to track groups Your friends The photos in which a user is tagged People who like Sarah Palin People who like Selina Gomez People who like Justin Beiber People who think Selina and Justin were a great couple People who think Sarah Palin and Justin should be a couple CS5412 Spring 2015
24 .How is TAO used? All sorts of FB operations require the system to Pull up some form of data Then search TAO for a group of things somehow related to that data Then pull up fingernails from that group of things, etc So TAO works hard, and needs to deal with all sorts of heavy loads Can one cache TAO data? Actually an open question CS5412 Spring 2015
25 .How FB does it now They create a bank of maybe 1000 TAO servers in each data center Incoming queries always of the form “get group associated with this key ” They use consistent hashing to hash key to some server, and then the server looks it up and returns the data. For big groups they use indirection and return a pointer to the data plus a few items CS5412 Spring 2015
26 .Challenges TAO has very high update rates Millions of events per second They use it internally too, to track items you looked at, that you clicked on, sequences of clicks, whether you returned to the prior page or continued deeper… So TAO sees updates at a rate even higher than the total click rate for all of FBs users (billions, but only hundreds of millions are online at a time, and only some of them do rapid clicks… and of course people playing games and so forth don’t get tracked this way) CS5412 Spring 2015
27 .Goals for TAO Provide a data store with a graph abstraction (vertexes and edges), not keys+values Optimize heavily for reads More than 2 orders of magnitude more reads than writes! Explicitly favor efficiency and availability over consistency Slightly stale data is often okay (for Facebook) Communication between data centers in different regions is expensive CS5412 Spring 2015
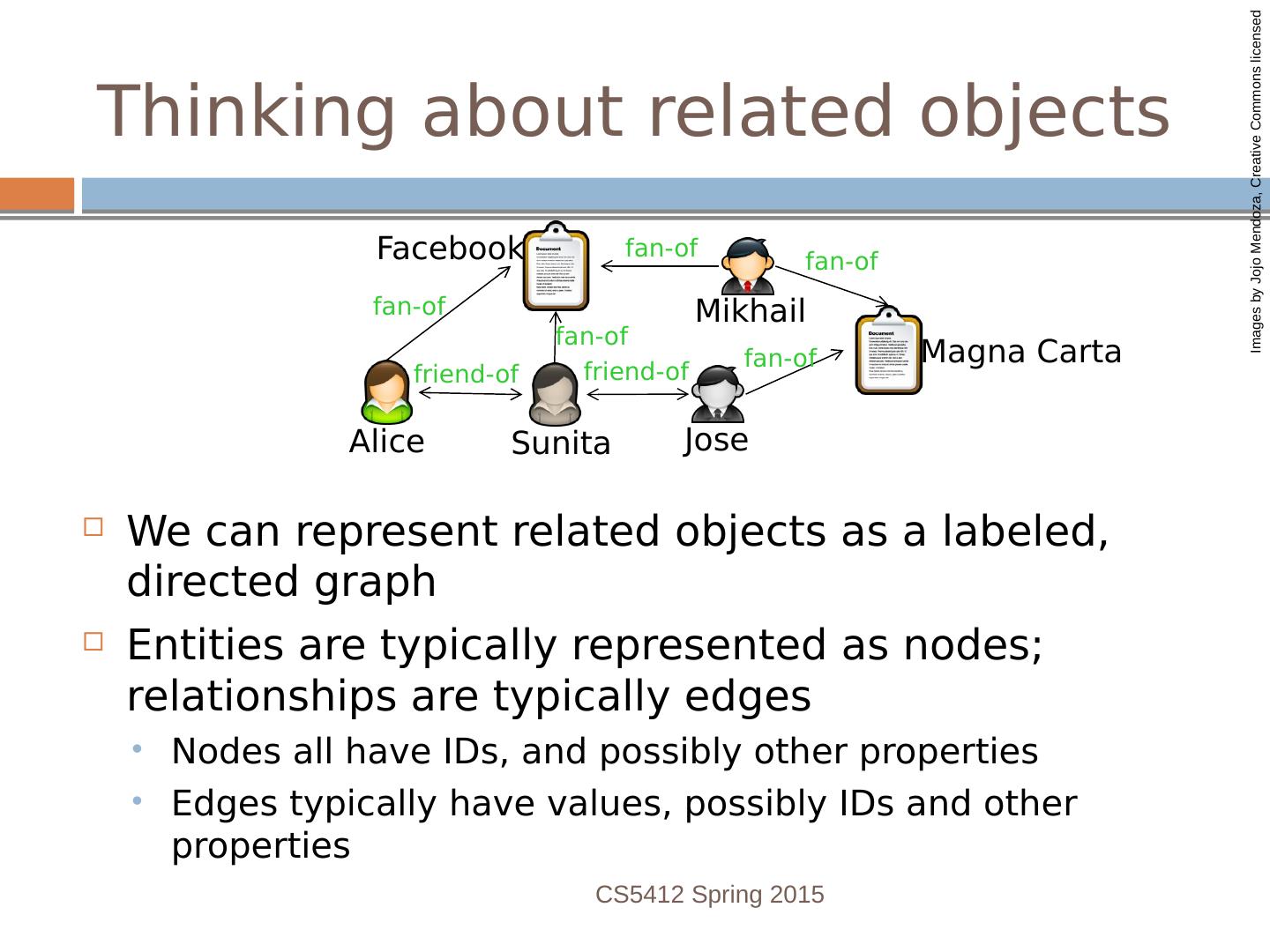
28 .Thinking about related objects We can represent related objects as a labeled, directed graph Entities are typically represented as nodes; relationships are typically edges Nodes all have IDs, and possibly other properties Edges typically have values, possibly IDs and other properties CS5412 Spring 2015 fan-of friend-of friend-of fan-of fan-of fan-of fan-of Alice Sunita Jose Mikhail Magna Carta Facebook Images by Jojo Mendoza, Creative Commons licensed
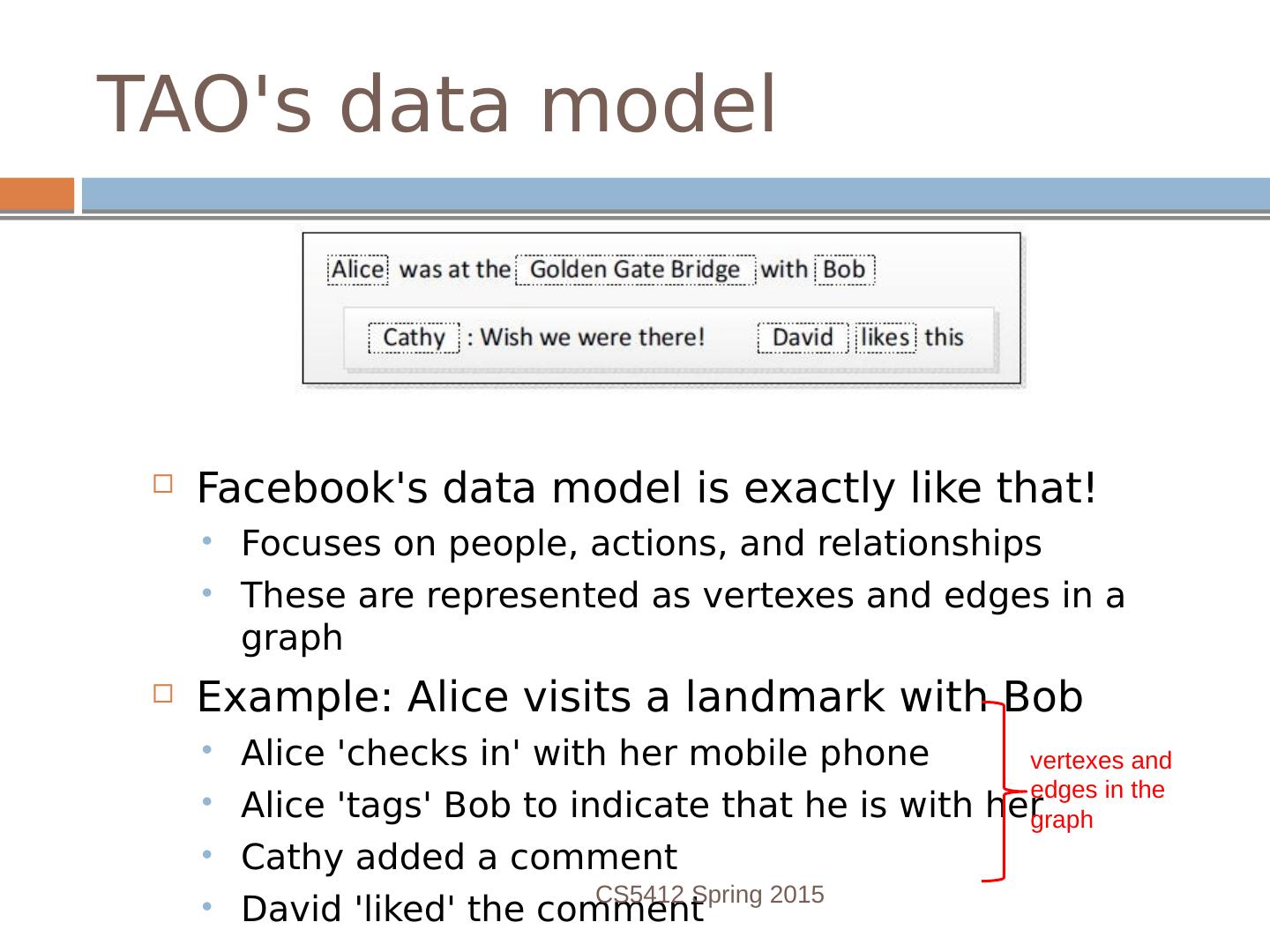
29 .TAOs data model Facebooks data model is exactly like that! Focuses on people, actions, and relationships These are represented as vertexes and edges in a graph Example: Alice visits a landmark with Bob Alice checks in with her mobile phone Alice tags Bob to indicate that he is with her Cathy added a comment David liked the comment CS5412 Spring 2015 vertexes and edges in the graph
相关推荐
3秒后跳转登录页面
去登陆

