






- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
阿里云平台上深度优化分布式训练性能
基于阿里云弹性AI平台的推荐算法优化,涉及到大规模分布式GPU/FPGA等异构计算平台下的性能调优案例分享。
展开查看详情
1 . 阿里云弹性人工智能 阿里云平台上深度优化分布式训练性能 游亮(昀龙)
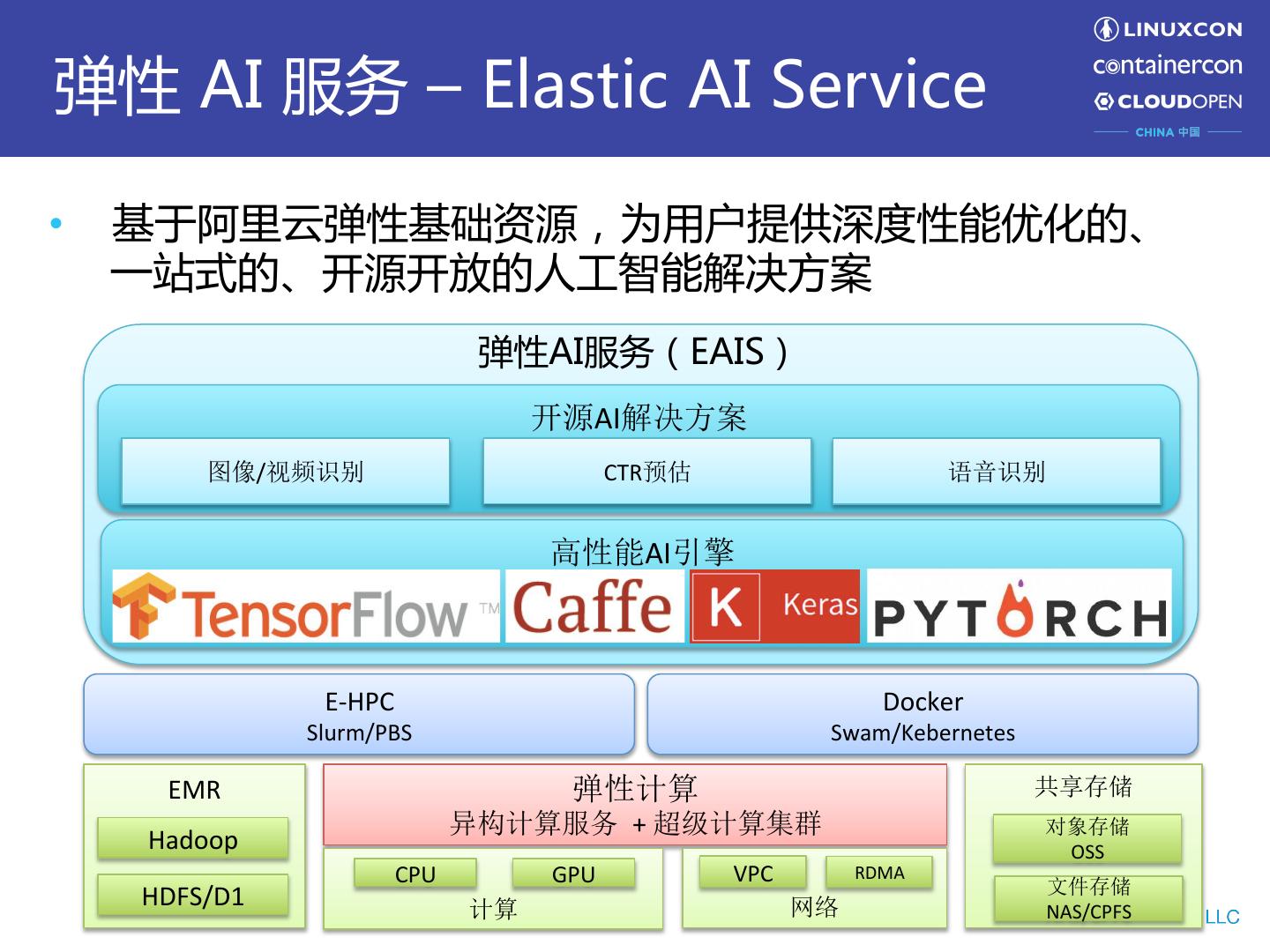
2 .弹性 AI 服务 – Elastic AI Service • 基于阿里云弹性基础资源,为用户提供深度性能优化的、 一站式的、开源开放的人工智能解决方案 弹性AI服务(EAIS) 开源AI解决方案 图像/视频识别 CTR预估 语音识别 高性能AI引擎 E-HPC Docker Slurm/PBS Swam/Kebernetes EMR 弹性计算 共享存储 异构计算服务 + 超级计算集群 对象存储 Hadoop OSS CPU GPU VPC RDMA 文件存储 HDFS/D1 计算 网络 NAS/CPFS
3 . 阿里云弹性异构计算服务 • EGS: Elastic GPU Service • FaaS: FPGA as a Service • 异构计算 – CPU + GPU/FPGA优势互补 • 云上大规模GPU/FPGA池 – 短时间能够获取大量GPU/FPGA资源 – 有效解决业务波峰、波谷的问题 – 大大降低训练时间,提高模型迭代速度 • 享受硬件升级的红利 • 和其他云产品深度整合
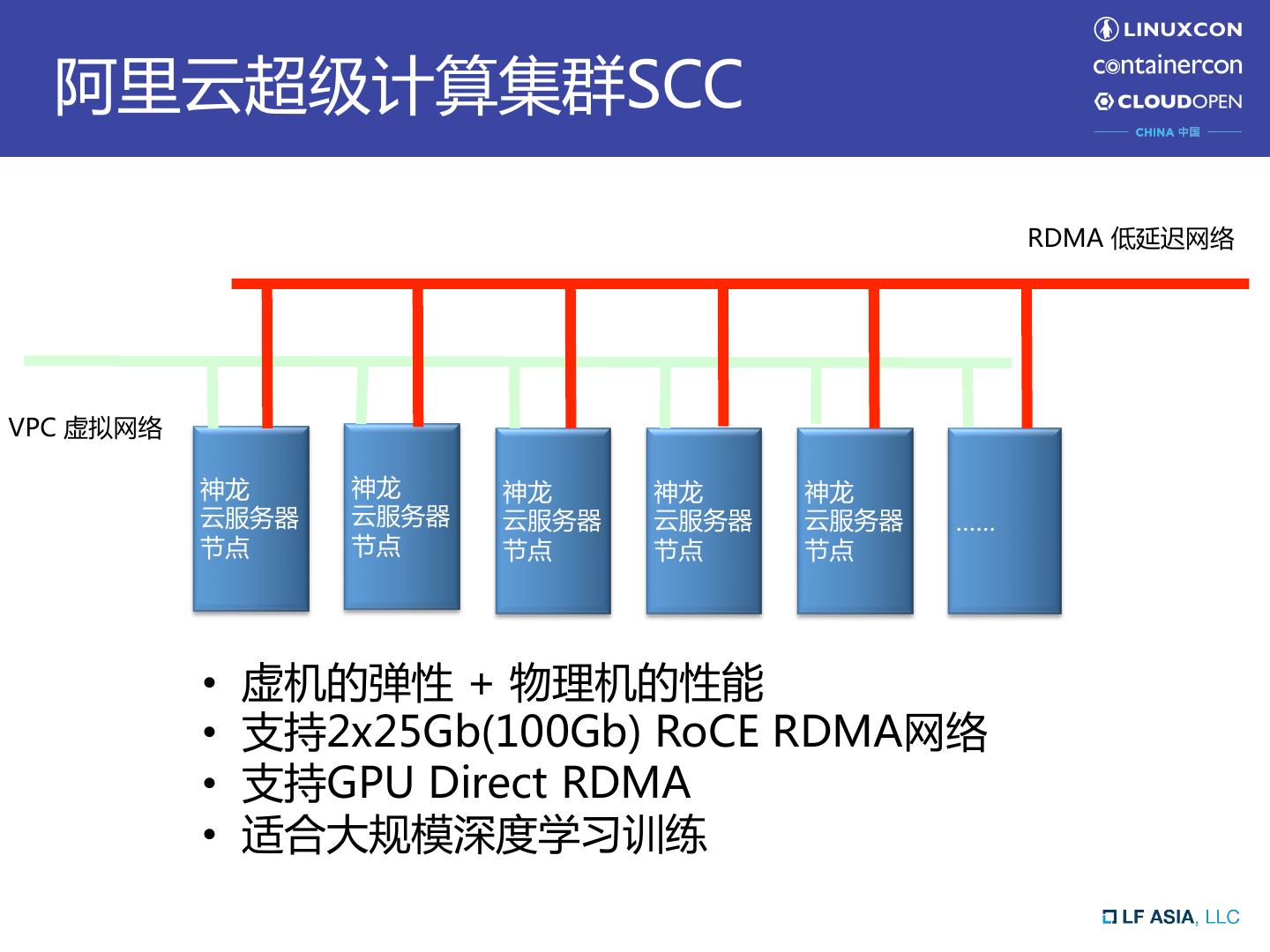
4 . 阿里云超级计算集群SCC 2x25Gb(100Gb) RDMA 低延迟网络 2x25G VPC 虚拟网络 云盘存储网络 神龙 神龙 神龙 神龙 神龙 云服务器 云服务器 云服务器 云服务器 云服务器 …… 节点 节点 节点 节点 节点 • 虚机的弹性 + 物理机的性能 • 支持2x25Gb(100Gb) RoCE RDMA网络 • 支持GPU Direct RDMA • 适合大规模深度学习训练
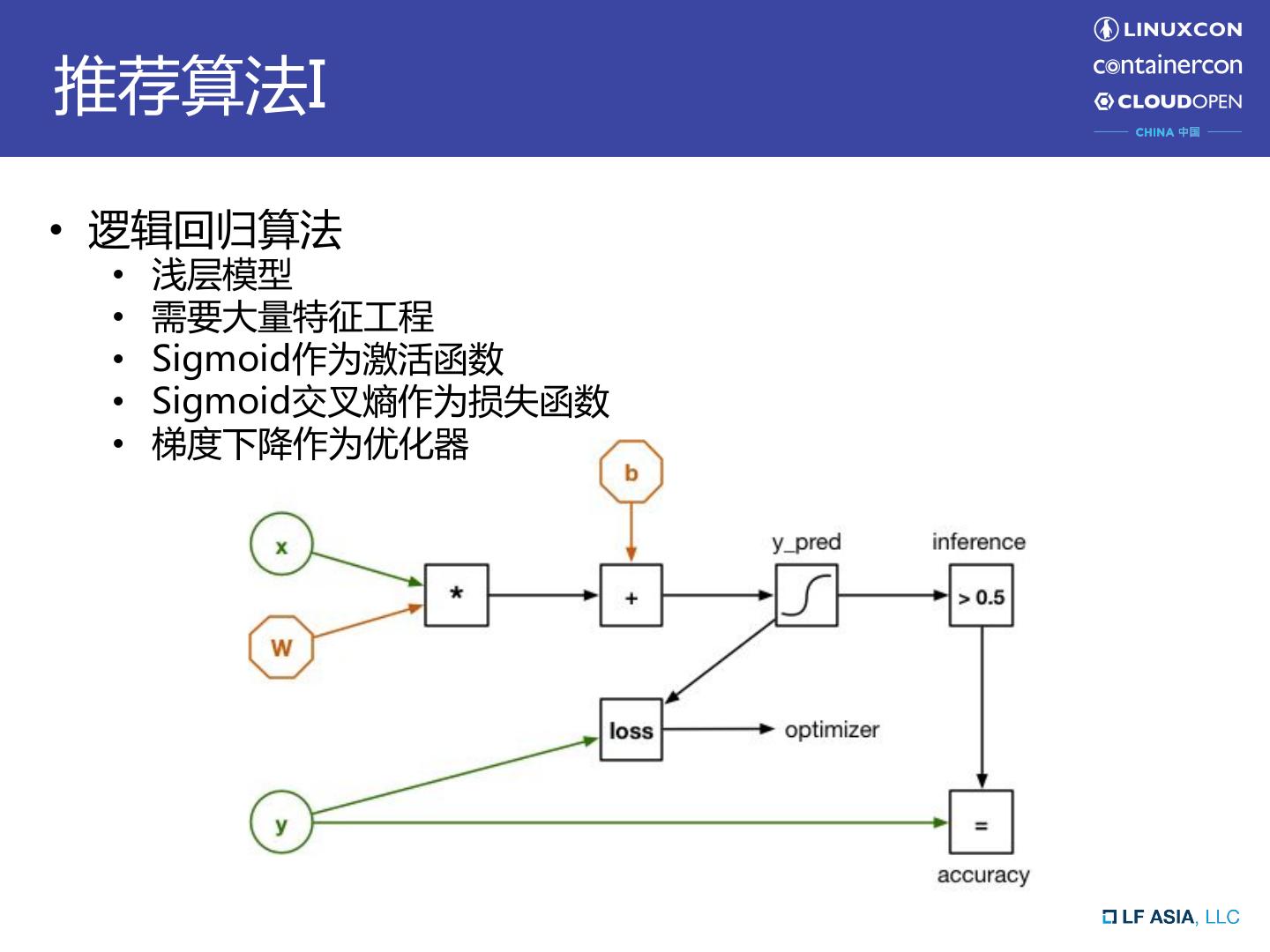
5 .推荐算法I • 逻辑回归算法 • 浅层模型 • 需要大量特征工程 • Sigmoid作为激活函数 • Sigmoid交叉熵作为损失函数 • 梯度下降作为优化器
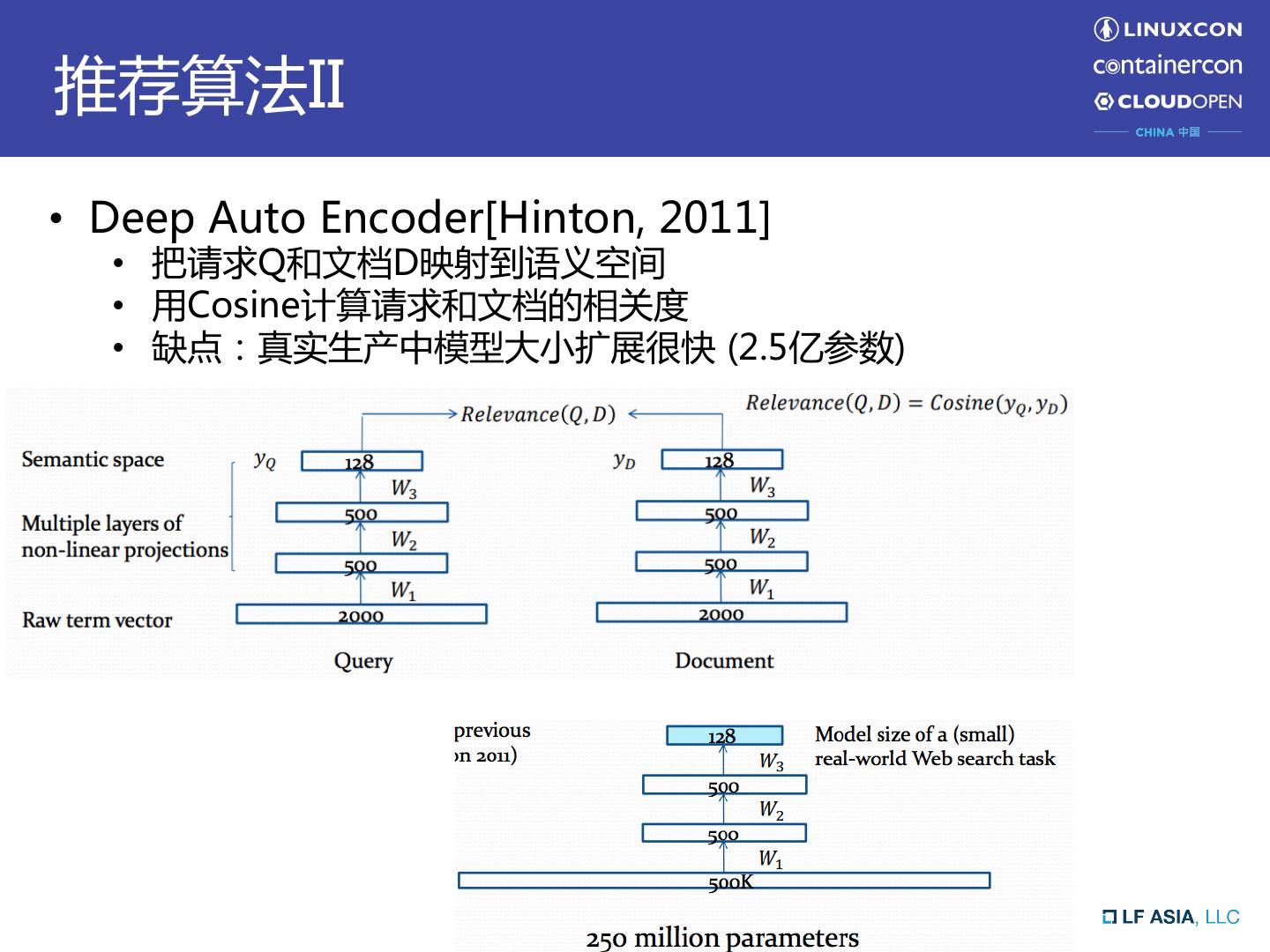
6 .推荐算法II • Deep Auto Encoder[Hinton, 2011] • 把请求Q和文档D映射到语义空间 • 用Cosine计算请求和文档的相关度 • 缺点:真实生产中模型大小扩展很快 (2.5亿参数)
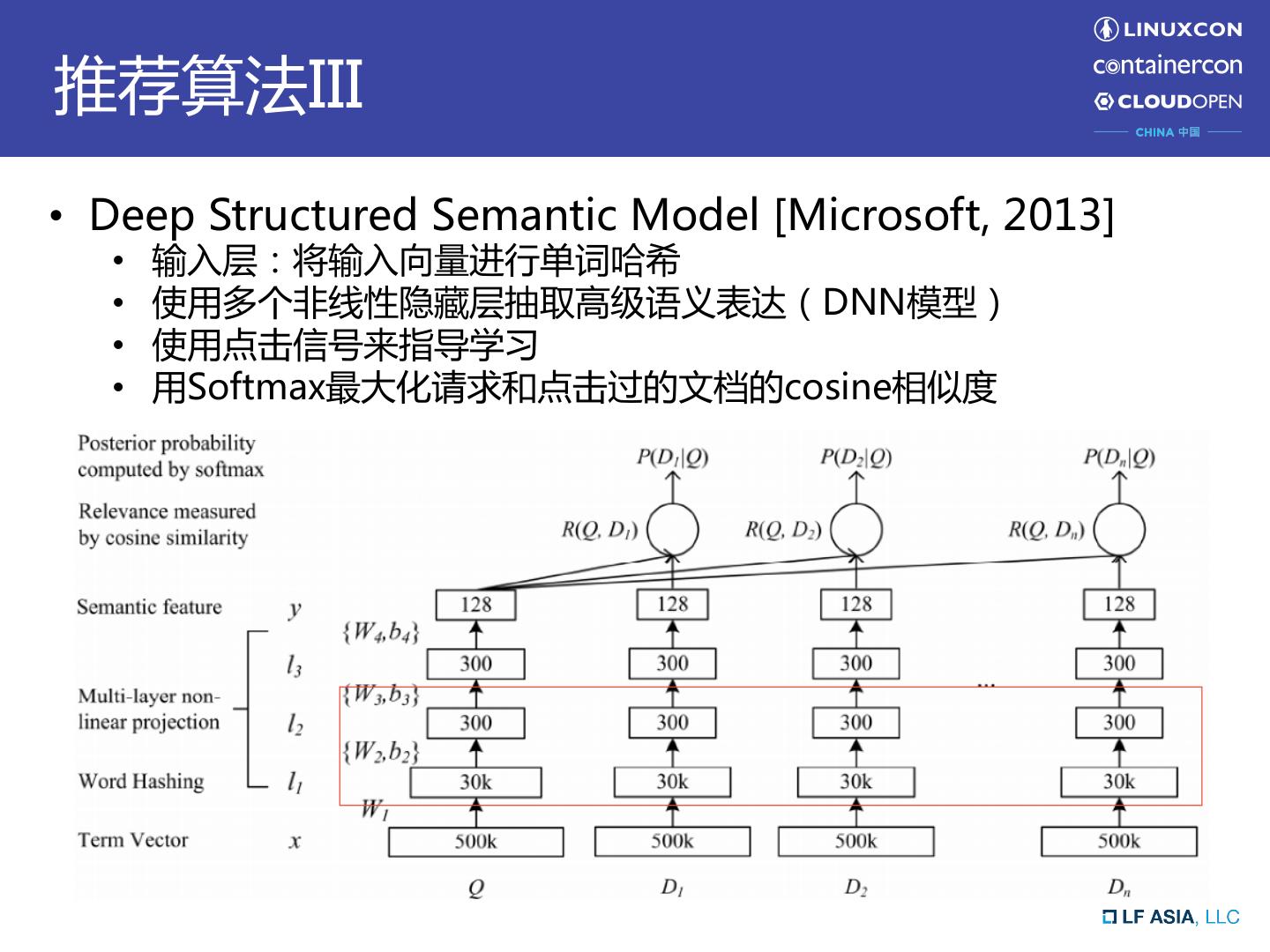
7 .推荐算法III • Deep Structured Semantic Model [Microsoft, 2013] • 输入层:将输入向量进行单词哈希 • 使用多个非线性隐藏层抽取高级语义表达(DNN模型) • 使用点击信号来指导学习 • 用Softmax最大化请求和点击过的文档的cosine相似度
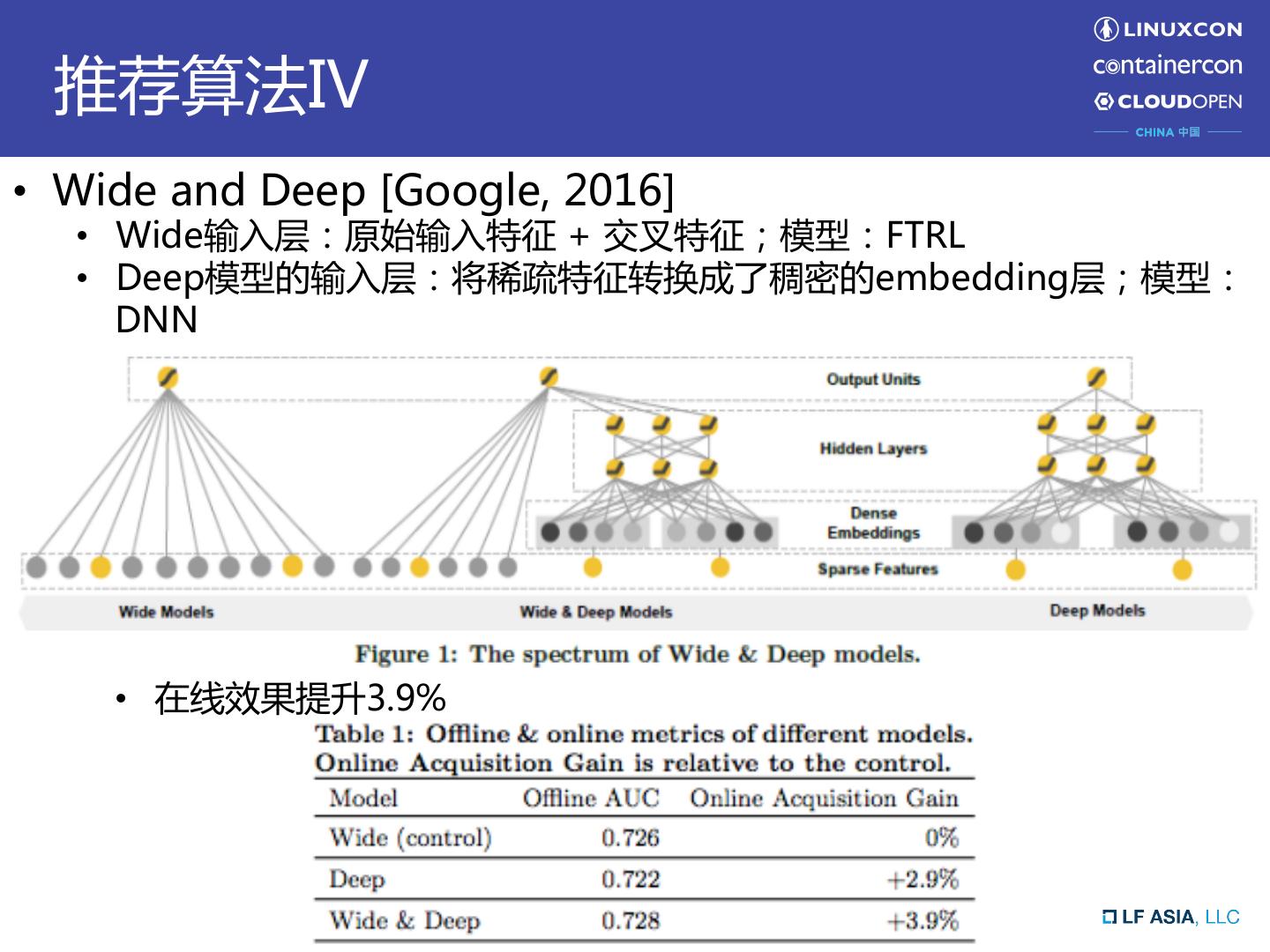
8 . 推荐算法IV • Wide and Deep [Google, 2016] • Wide输入层:原始输入特征 + 交叉特征;模型:FTRL • Deep模型的输入层:将稀疏特征转换成了稠密的embedding层;模型: DNN • 在线效果提升3.9%
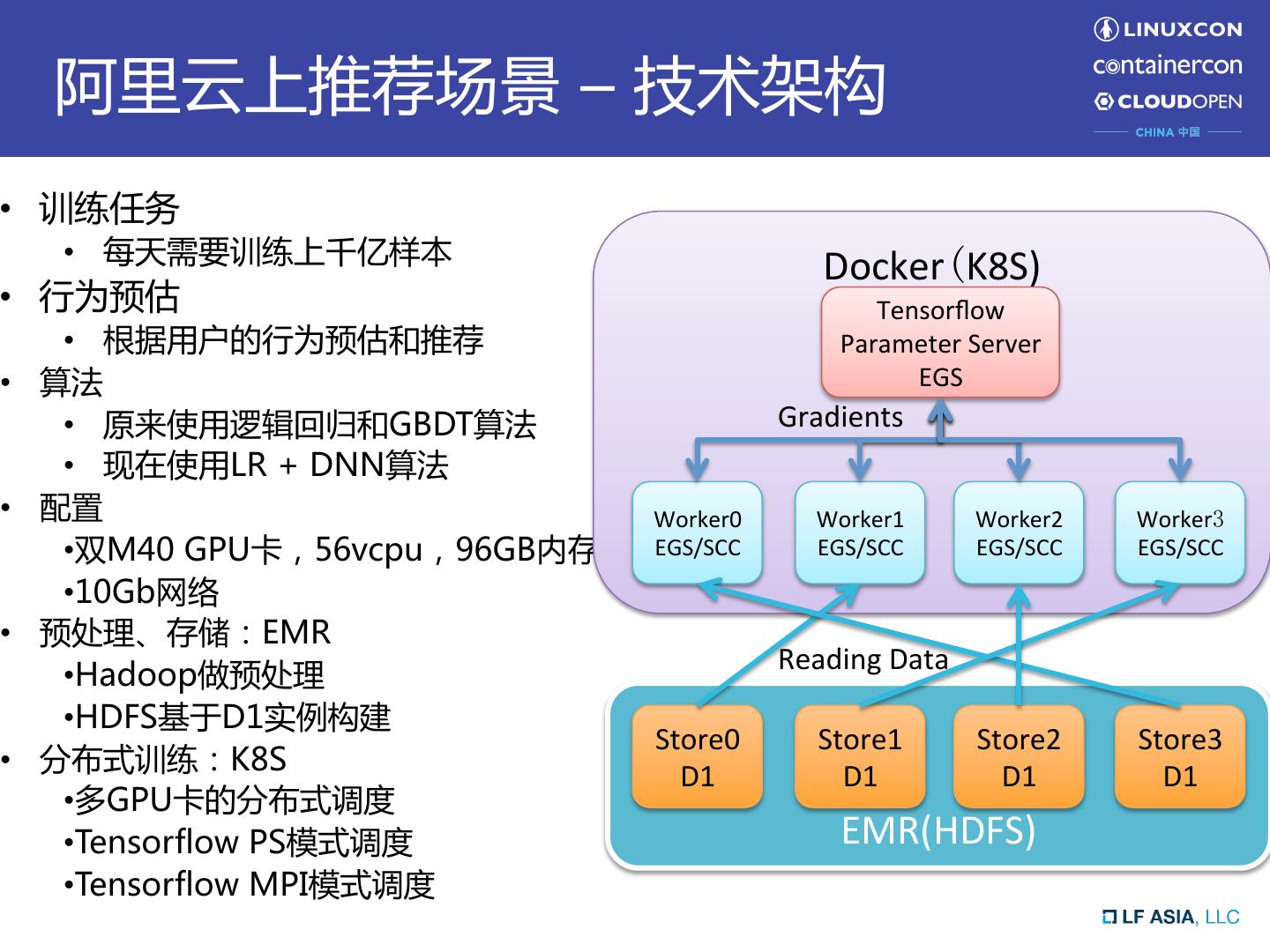
9 . 阿里云上推荐场景 – 技术架构 • 训练任务 • 每天需要训练上千亿样本 Docker(K8S) • 行为预估 Tensorflow • 根据用户的行为预估和推荐 Parameter Server • 算法 EGS • 原来使用逻辑回归和GBDT算法 Gradients • 现在使用LR + DNN算法 • 配置 Worker0 Worker1 Worker2 Worker3 • 双M40 GPU卡,56vcpu,96GB内存 EGS/SCC EGS/SCC EGS/SCC EGS/SCC • 10Gb网络 • 预处理、存储:EMR Reading Data • Hadoop做预处理 • HDFS基于D1实例构建 Store0 Store1 Store2 Store3 • 分布式训练:K8S D1 D1 D1 D1 • 多GPU卡的分布式调度 • Tensorflow PS模式调度 EMR(HDFS) • Tensorflow MPI模式调度
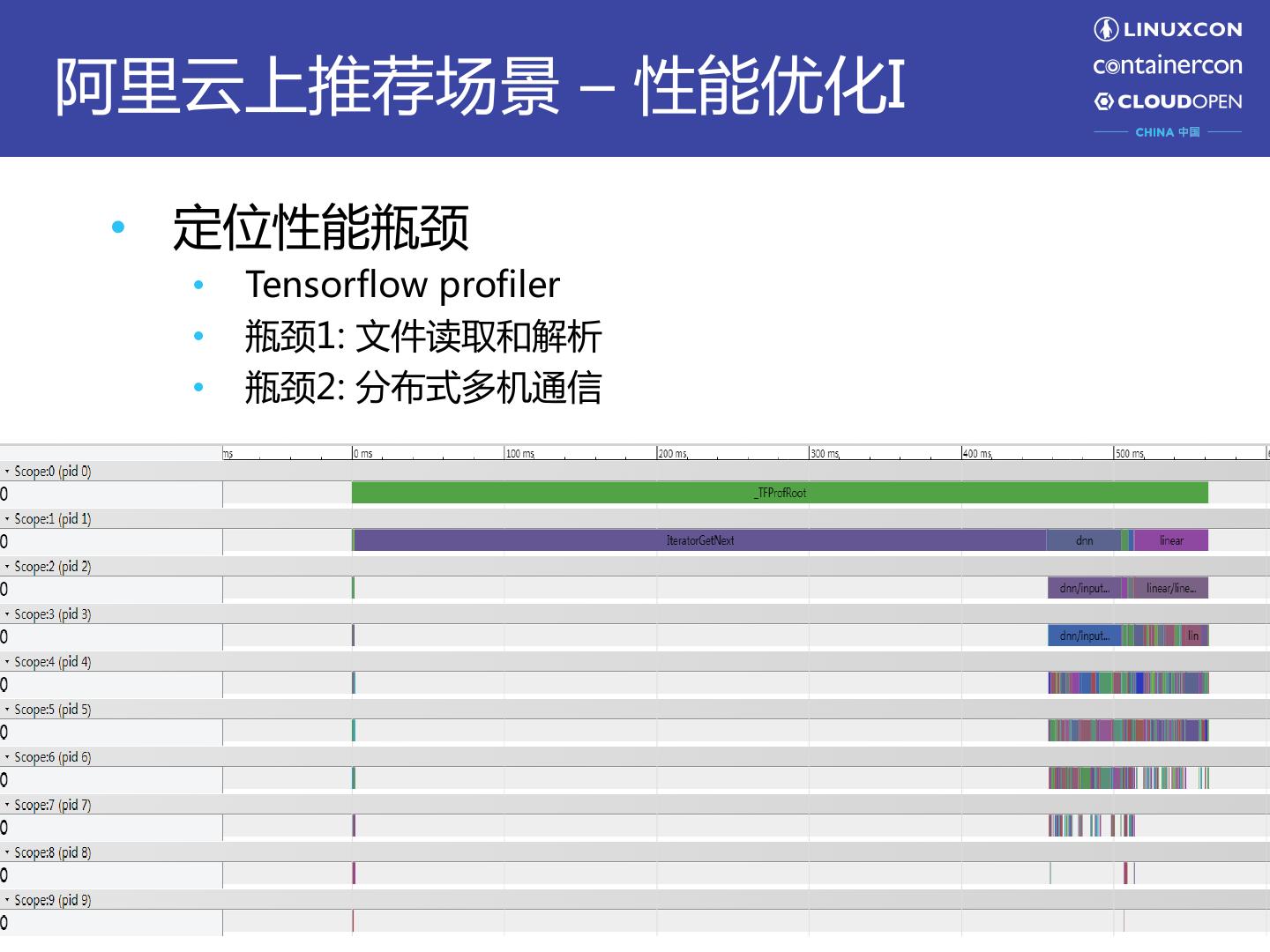
10 .阿里云上推荐场景 – 性能优化I • 定位性能瓶颈 • Tensorflow profiler • 瓶颈1: 文件读取和解析 • 瓶颈2: 分布式多机通信
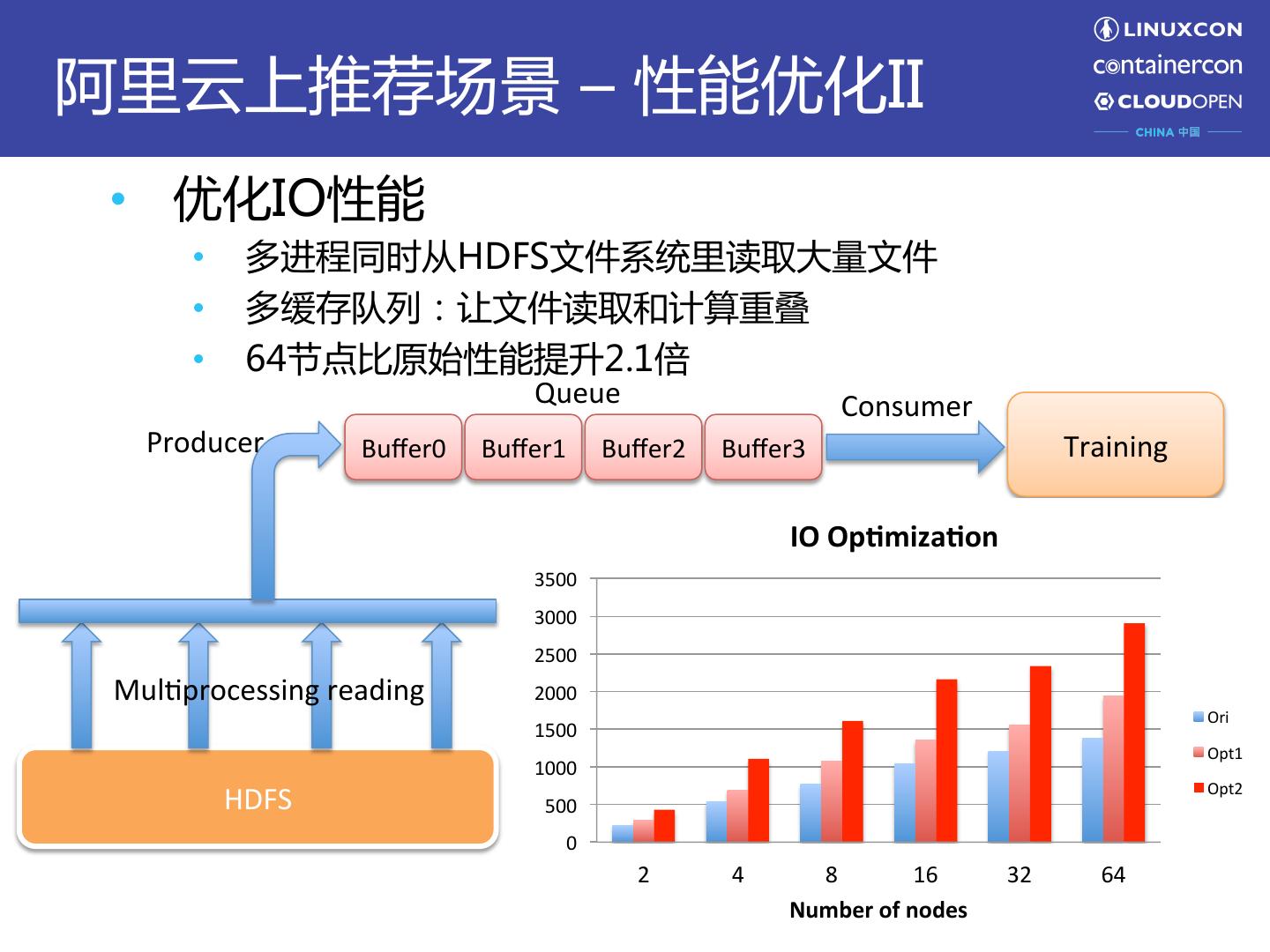
11 .阿里云上推荐场景 – 性能优化II • 优化IO性能 • 多进程同时从HDFS文件系统里读取大量文件 • 多缓存队列:让文件读取和计算重叠 • 64节点比原始性能提升2.1倍 Queue Consumer Producer Buffer0 Buffer1 Buffer2 Buffer3 Training IO Op0miza0on 3500 3000 2500 MulUprocessing reading 2000 Ori 1500 Opt1 1000 Opt2 HDFS 500 0 2 4 8 16 32 64 Number of nodes
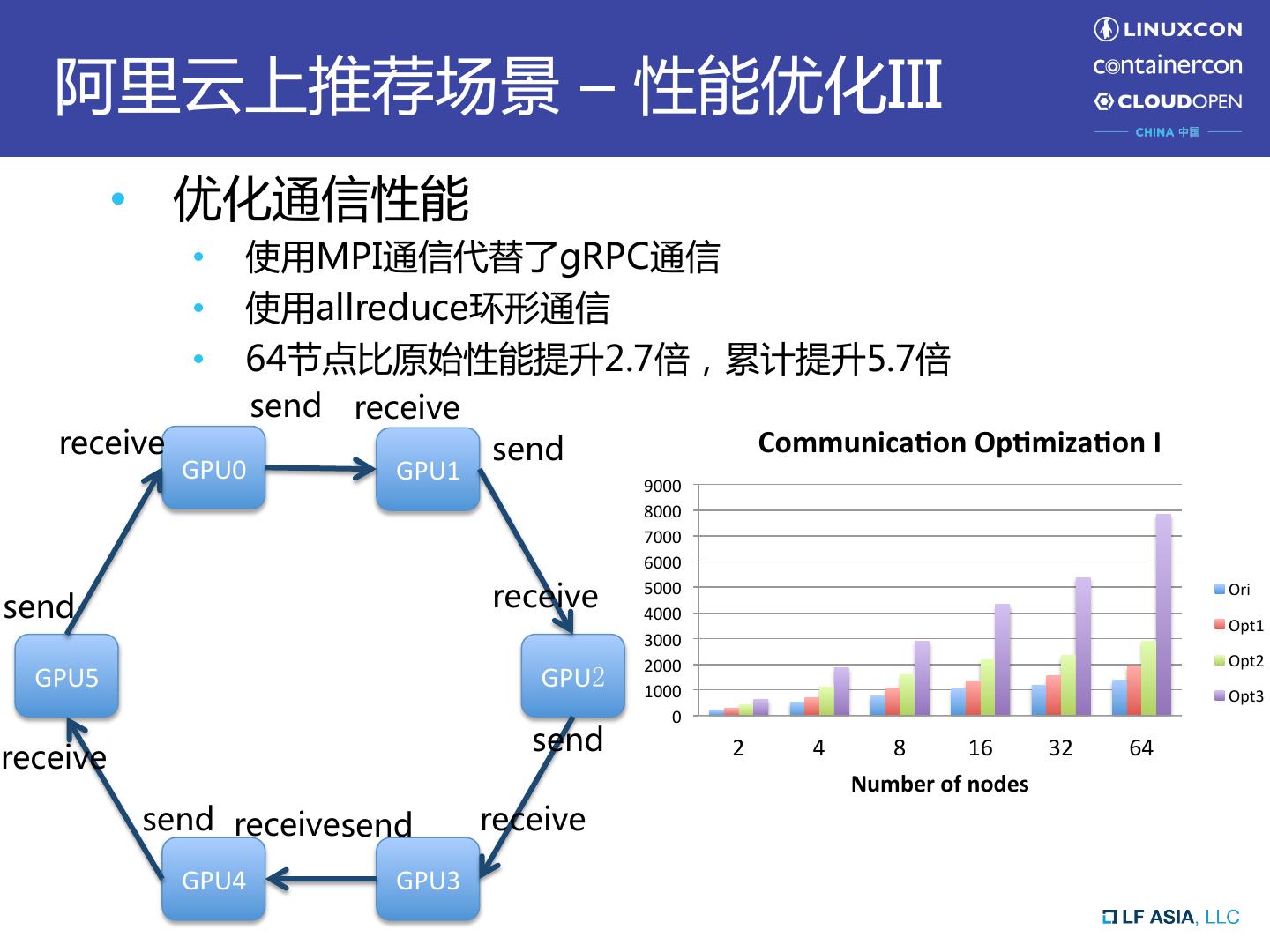
12 . 阿里云上推荐场景 – 性能优化III • 优化通信性能 • 使用MPI通信代替了gRPC通信 • 使用allreduce环形通信 • 64节点比原始性能提升2.7倍,累计提升5.7倍 send receive receive send Communica0on Op0miza0on I GPU0 GPU1 9000 8000 7000 6000 send receive 5000 4000 Ori Opt1 3000 2000 Opt2 GPU5 GPU2 1000 Opt3 0 send 2 4 8 16 32 64 receive Number of nodes send receivesend receive GPU4 GPU3
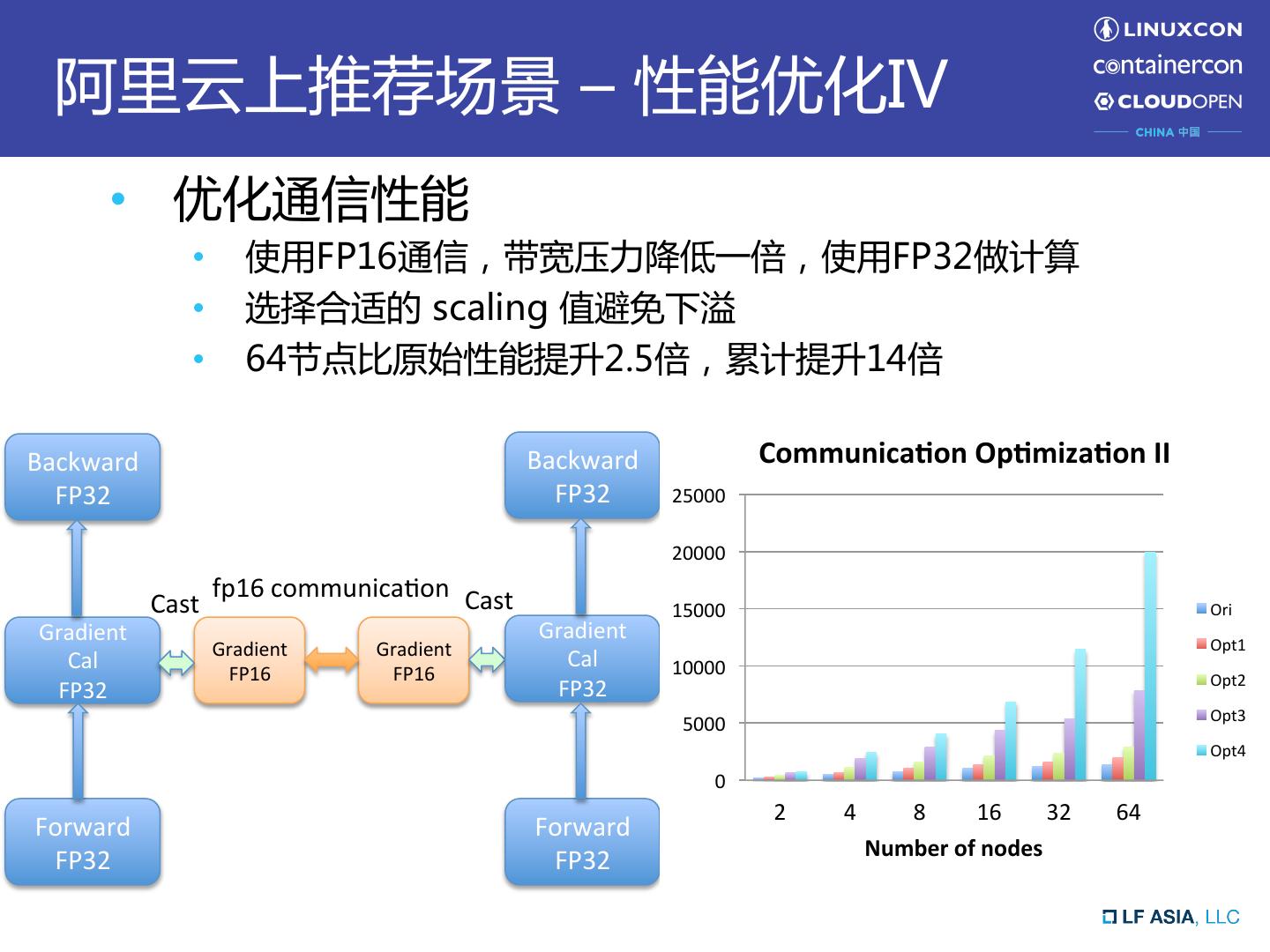
13 . 阿里云上推荐场景 – 性能优化IV • 优化通信性能 • 使用FP16通信,带宽压力降低一倍,使用FP32做计算 • 选择合适的 scaling 值避免下溢 • 64节点比原始性能提升2.5倍,累计提升14倍 Backward Backward Communica0on Op0miza0on II FP32 FP32 25000 20000 fp16 communicaUon Cast Cast 15000 Ori Gradient Gradient Opt1 Gradient Gradient Cal Cal 10000 FP16 FP16 Opt2 FP32 FP32 Opt3 5000 Opt4 0 2 4 8 16 32 64 Forward Forward Number of nodes FP32 FP32
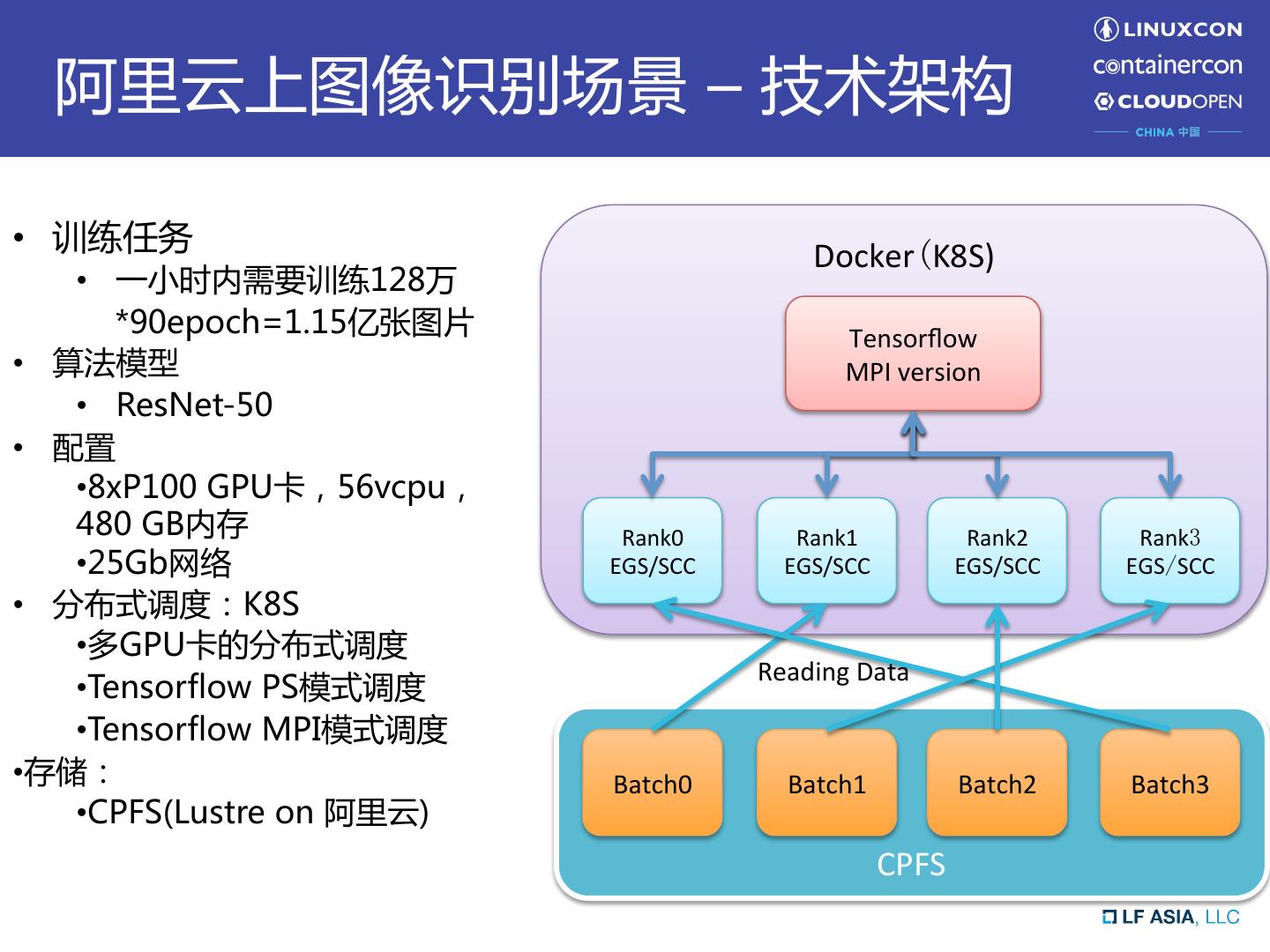
14 . 阿里云上图像识别场景 – 技术架构 • 训练任务 Docker(K8S) • 一小时内需要训练128万 *90epoch=1.15亿张图片 Tensorflow • 算法模型 MPI version • ResNet-50 • 配置 • 8xP100 GPU卡,56vcpu, 480 GB内存 Rank0 Rank1 Rank2 Rank3 • 25Gb网络 EGS/SCC EGS/SCC EGS/SCC EGS/SCC • 分布式调度:K8S • 多GPU卡的分布式调度 Reading Data • Tensorflow PS模式调度 • Tensorflow MPI模式调度 • 存储: Batch0 Batch1 Batch2 Batch3 • CPFS(Lustre on 阿里云) CPFS
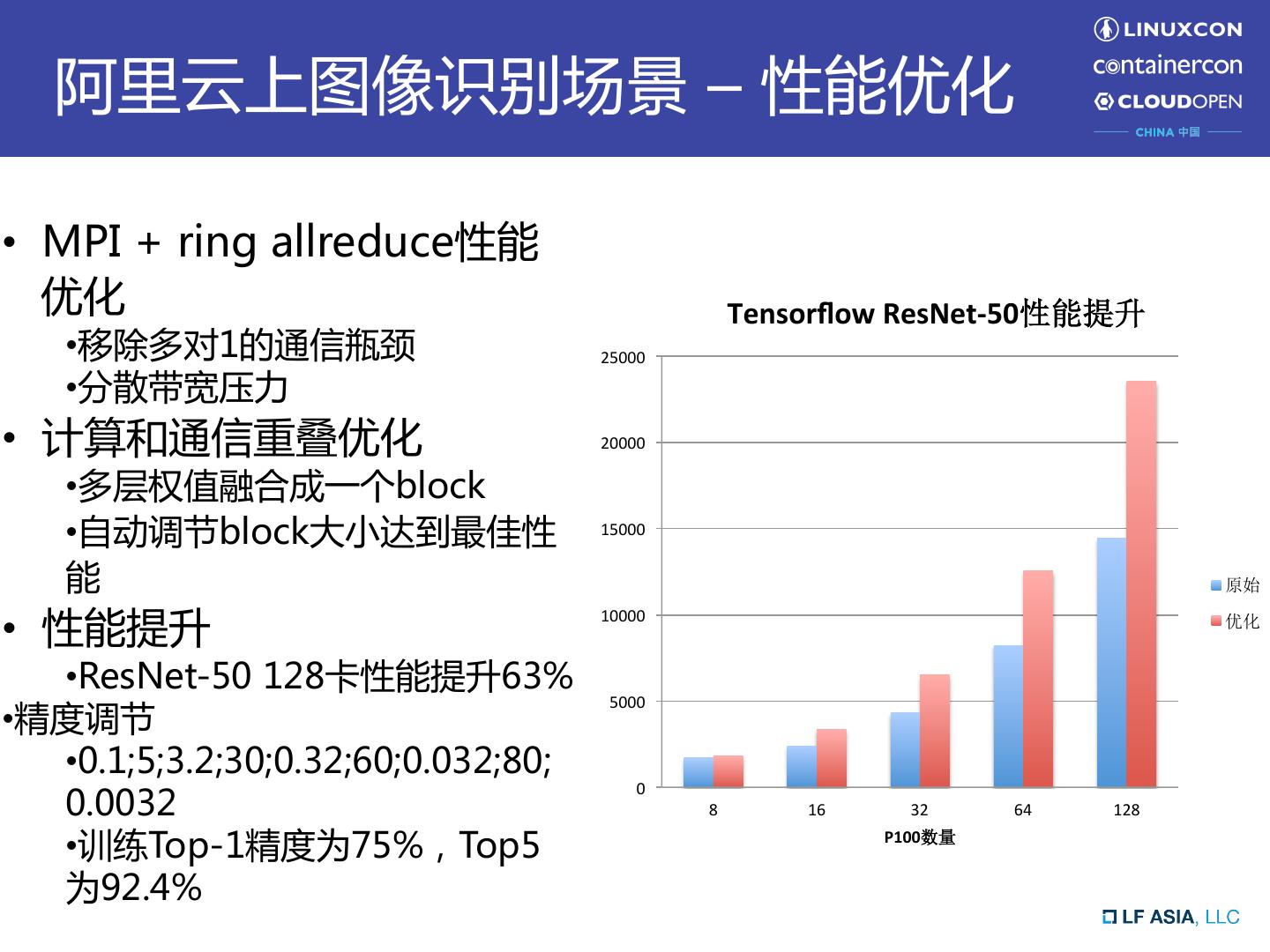
15 . 阿里云上图像识别场景 – 性能优化 • MPI + ring allreduce性能 优化 Tensorflow ResNet-50性能提升 • 移除多对1的通信瓶颈 25000 • 分散带宽压力 • 计算和通信重叠优化 20000 • 多层权值融合成一个block • 自动调节block大小达到最佳性 15000 能 原始 • 性能提升 10000 优化 • ResNet-50 128卡性能提升63% 5000 • 精度调节 • 0.1;5;3.2;30;0.32;60;0.032;80; 0 0.0032 8 16 32 64 128 • 训练Top-1精度为75%,Top5 P100数量 为92.4%
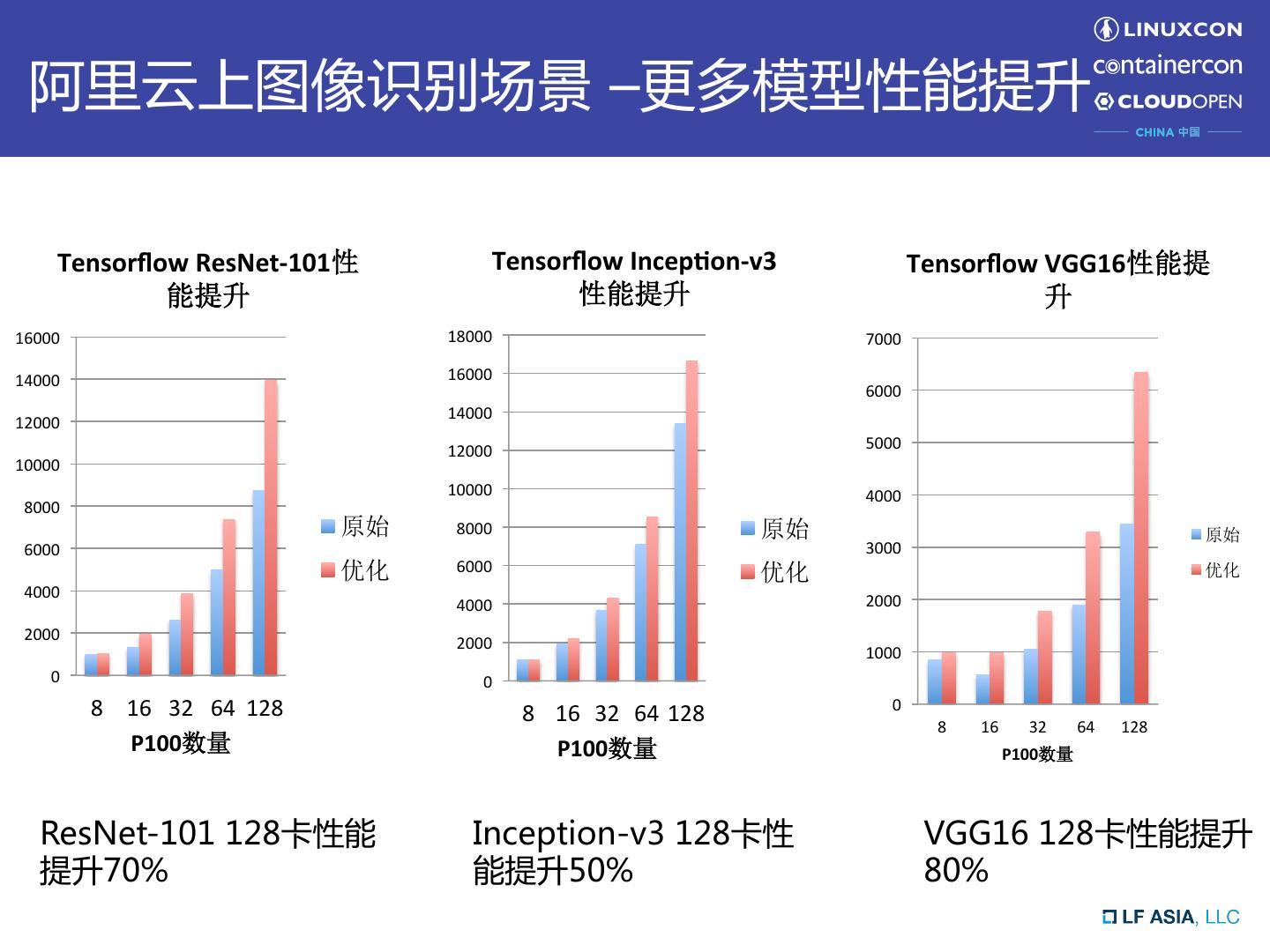
16 . 阿里云上图像识别场景 –更多模型性能提升 Tensorflow ResNet-101性 Tensorflow Incep0on-v3 Tensorflow VGG16性能提 能提升 性能提升 升 16000 18000 7000 14000 16000 6000 14000 12000 12000 5000 10000 10000 4000 8000 原始 8000 原始 原始 6000 3000 优化 6000 优化 优化 4000 2000 4000 2000 2000 1000 0 0 8 16 32 64 128 8 16 32 64 128 0 8 16 32 64 128 P100数量 P100数量 P100数量 ResNet-101 128卡性能 Inception-v3 128卡性 VGG16 128卡性能提升 提升70% 能提升50% 80%
17 .欢迎加入阿里云弹性人工智能团队 当人工智能遇上云计算,一切皆有可能 愿景: 加速阿里云上人工智能企业的发展
18 .
相关推荐
3秒后跳转登录页面
去登陆

