展开查看详情
1 .NUMA( yey ) By jacob Kugler
2 .MOtivation Next generation of EMC VPLEX hardware is NUMA based What is the expected performance benefit? How to best adjust the code to NUMA? Gain experience with NUMA tools
3 .VPLEX OVERVIEW A unique virtual storage technology that enables: Data mobility and high availability within and between data centers. Mission critical continuous availability between two synchronous sites. Distributed RAID1 between 2 sites.
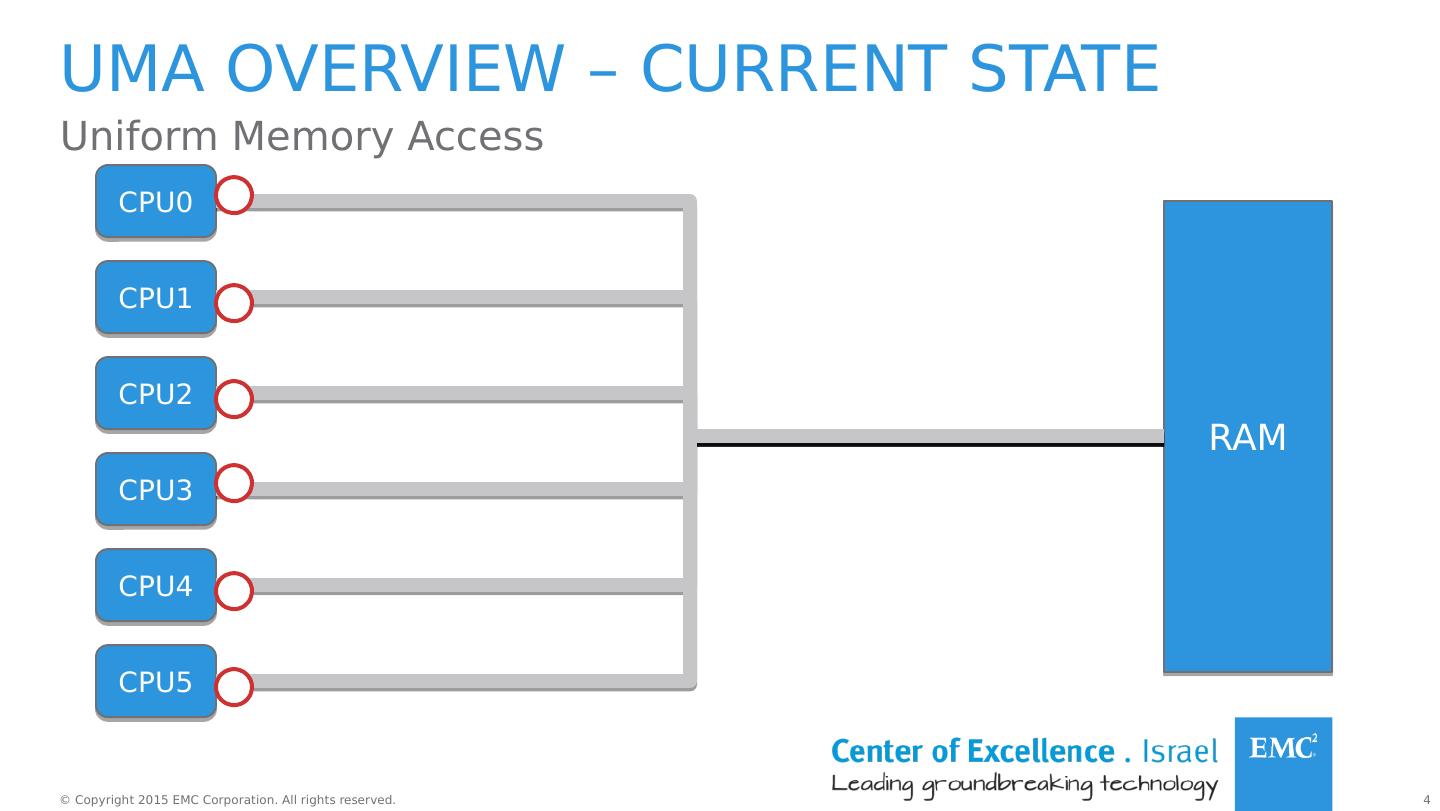
4 .uma overview – current state Uniform Memory Access RAM CPU0 CPU1 CPU2 CPU3 CPU4 CPU5
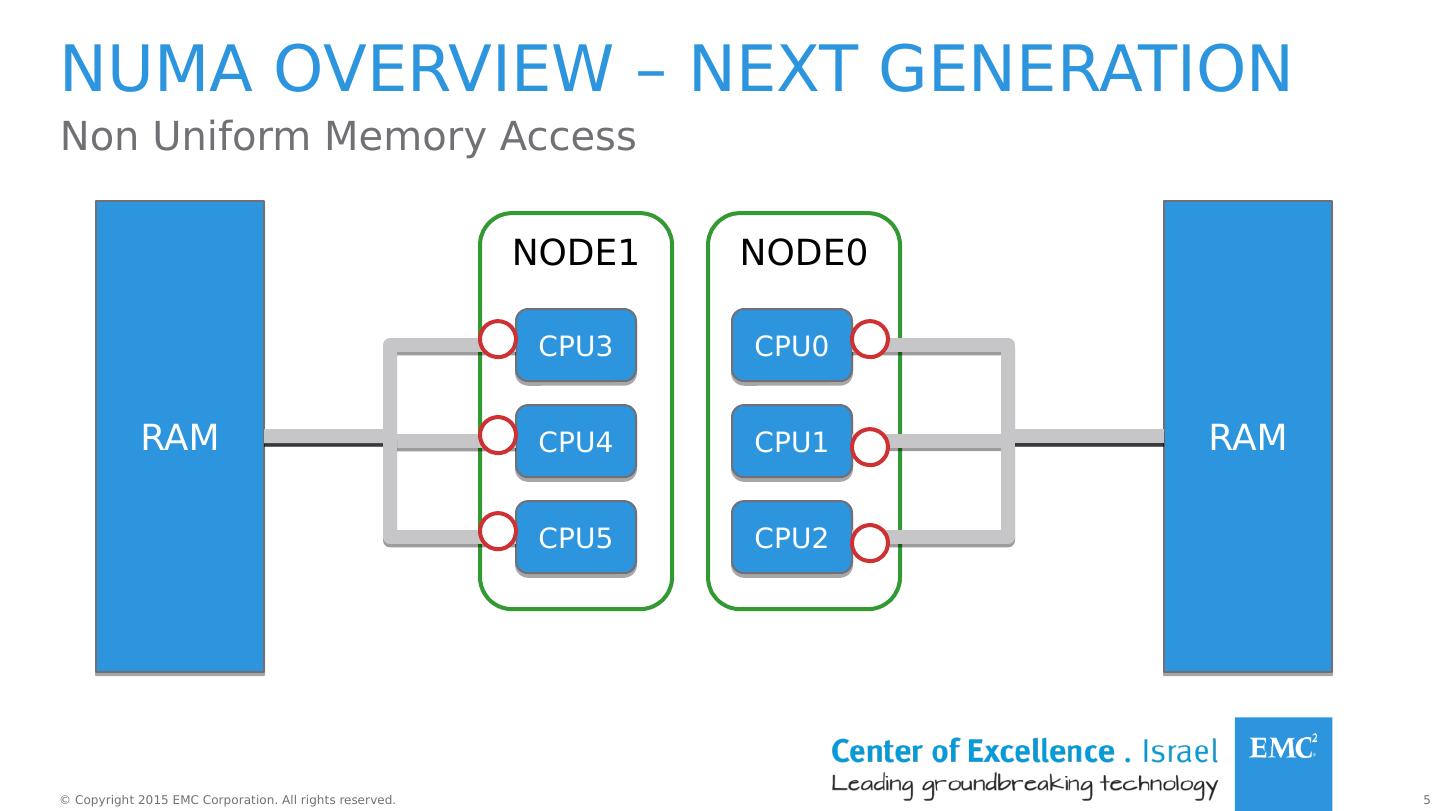
5 .NODE0 NODE1 Numa overview – next generation Non Uniform Memory Access RAM CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 RAM
6 .Policies Allocation of memory on specific nodes Binding threads to specific nodes/CPUs Can be applied to: Process Memory area
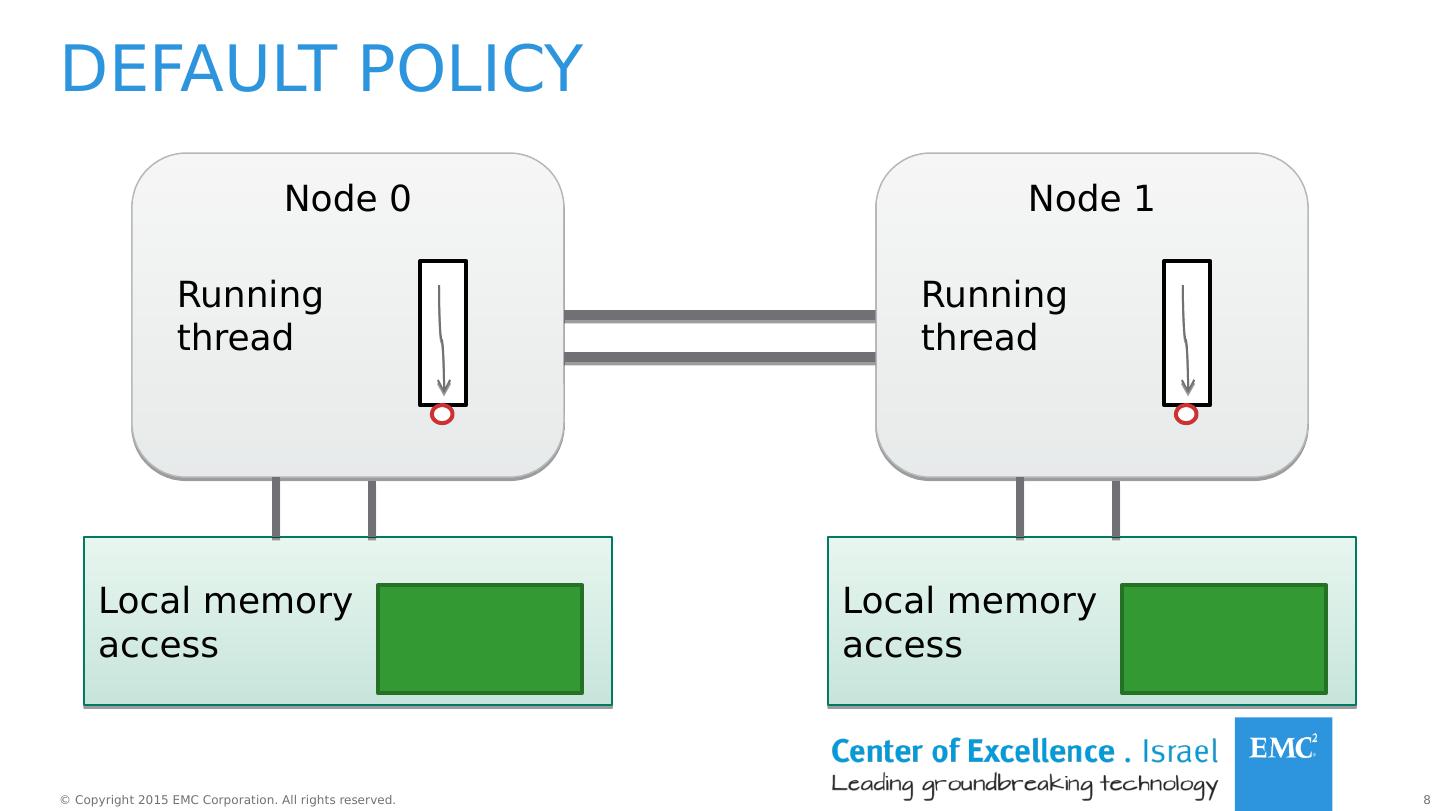
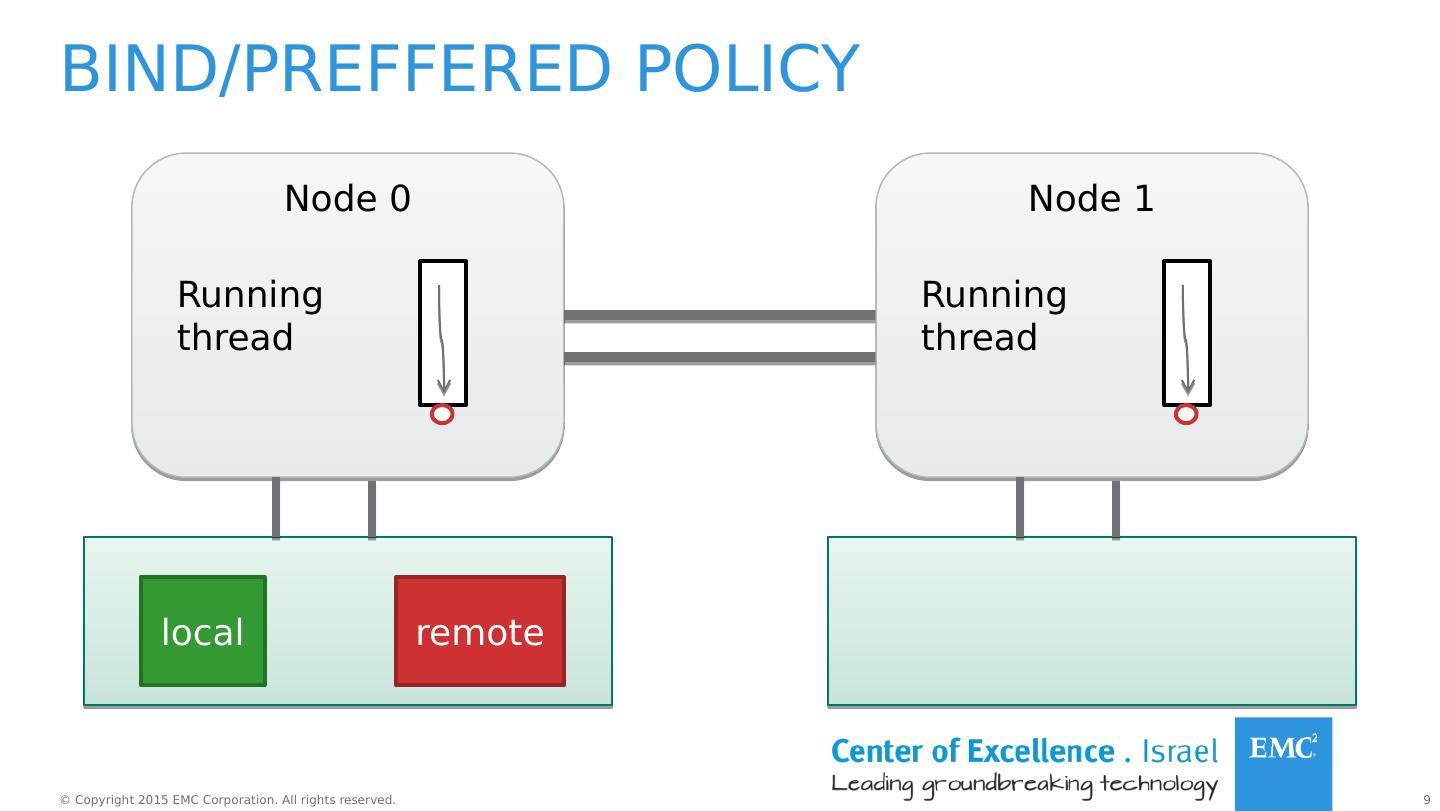
7 .Policies Cont. Name Description default Allocate on the local node (the node the thread is running on) bind Allocate on a specific set of nodes interleave Interleave memory allocations on a set of nodes preferred Try to allocate on a node first * Policies can also be applied to shared memory regions.
8 .Default policy Node 0 Local memory access Running thread Node 1 Local memory access Running thread
9 .Bind/ preffered policy Node 0 Running thread local Node 1 Running thread remote
10 .Interleave policy Node 0 Local memory access Running thread Node 1 Remote memory access
11 .NUMActl Command line tool for running a specific NUMA Policy. Useful for programs that cannot be modified or recompiled.
12 .NUMActl examples numactl – cpubind =0 – membind =0,1 <program> run the program on node 0 and allocate memory from nodes 0,1 numactl –interleave=all <program> run the program with memory interleave on all available nodes.
13 .libnuma A library that offers an API for NUMA policy. Fine grained tuning of NUMA policies. Changing policy in one thread does not affect other threads.
14 .Libnuma examples numa_available () – checks if NUMA is supported on the system. numa_run_on_node ( int node ) – binds the current thread on a specific node. n uma_max_node () – the number of the highest node in the system. numa_alloc_interleave ( size_t size ) – allocates size bytes of memory page interleaved on all available nodes. numa_alloc_onnode ( size_t size , int node ) – allocate memory on a specific node.
15 .Hardware overview Node 0 cpu0 L2 L1 cpu1 L2 L1 cpu2 L2 L1 cpu3 L2 L1 cpu4 L2 L1 cpu5 L2 L1 L3 cache Node 1 cpu0 L2 L1 cpu1 L2 L1 cpu2 L2 L1 cpu3 L2 L1 cpu4 L2 L1 cpu5 L2 L1 L3 cache RAM RAM QPI 2 hyper threads Quick Path Interconnect
16 .Hardware overview Processor Intel Xeon Processor E5-2620 # Cores 6 # Threads 12 QPI speed 8.0 GT/s = 64 GB/s L1 data cache 32 KB L1 instruction cache 32 KB L2 cache 256 KB L3 cache 15 MB RAM 62.5 GB Gigatransfers per second GB/s = GT/s * BUS bandwidth (8B)
17 .Linux perf tool Command line profiler Based on perf_events Hardware events – counted by the CPU Software events – counted by the kernel perf list – a list of pre-defined events (to be used in –e) . instructions [ Hardware event ] context-switches OR cs [Software event ] L1-dcache-loads [ Hardware cache event ] rNNN [ Raw hardware event descriptor]
18 .Perf stat Keeps a running count of selected events during process execution. p erf stat [options] –e [list of events] <program> < args > Examples: perf stat –e page-faults my_exec . #page-faults that occurred during execution of my_exec . perf stat –a –e instructions,r81d0 sleep 5 System wide count on all CPUs . Counts # intructions and l1 dcache loads.
19 .Characterizing our system Linux perf tool CPU Performance counters L1-dcache-loads L1-dcache-stores Test: ran IO for 120 seconds Result: RD/WR = 2:1
20 .The simulator Measuring performance for different memory allocation policies on a 2 node system. Throughput is measured as the time it takes to complete N iterations. Threads randomly access a shared memory .
21 .The simulator cont. #Threads RD/WR ratio – ratio between the number of read and write operations a thread performs Policy – local / interleave / remote. Size – the size of memory to allocate. #Iterations Node0/Node1 – ratio between threads bound to Node 0 and threads bound Node 1 RW_SIZE - size of read or write operation in each iteration. Config file:
22 .Experiment # 1 Compare performance of 3 policies: Local – threads access memory on node they run on. Remote – threads access memory on a different node from which they run on. Interleave – memory is interleaves across nodes (threads access both local and remote memory)
23 .Experiment #1 3 policies – local, interleave, remote. #Threads varies from 1- 24 (the maximal number of concurrent threads in the system) 2 setups – balanced/unbalanced workload balanced unbalanced
24 .EXPERIment #1 #Iterations = 100,000,000 Data size = 2 * 150 MB RD/WR ratio = 2:1 RW_SIZE = 128 Bytes Configurations:
25 .results - balanced workload -37% +69% -46% +83% Time it took until the last thread finished working.
26 .results - unbalanced workload - 35 % + 73 % - 45 % + 87 %
27 .results - compared local remote interleave balanced unbalanced
28 .conclusions The more concurrent threads in the system, the more impact memory locality has on performance. In applications with #concurrent threads up to #cores in 1 node, the best solution is to bind the process and allocate memory on the same node. In applications with #concurrent threads up to #cores in a 2 node system, disabling NUMA (interleaving memory) will have similar performance to binding the process and allocating memory on the same node.
29 .Experiment # 2 Local access is significantly faster than remote. Our system uses RW locks to synchronize memory access. Is maintaining read locality by mirroring the data on both nodes have better performance than the current interleave policy?