













































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Next Generation Grid -HPC Cloud
下一代计算网格概念,集成并行计算和分布式计算的框架到HPC组件构建成的云/雾平台,用以IoT(物联网)大数据和仿真计算。文章提出其动机和趋势,让FaaS(Function as a Service)成为主流,底层框架(计算/调度/管理)可以针对HPC组件进行优化,为用户透明提供多种计算模型的能力支持。
展开查看详情
1 .Next Generation Grid: Integrating Parallel and Distributed Computing Runtimes for an HPC Enhanced Cloud and Fog Spanning IoT Big Data and Big Simulations ` Geoffrey Fox, Supun Kamburugamuve , Judy Qiu , Shantenu Jha June 28, 2017 IEEE Cloud 2017 Honolulu Hawaii gcf@indiana.edu http://www.dsc.soic.indiana.edu/ , http://spidal.org / Department of Intelligent Systems Engineering School of Informatics and Computing, Digital Science Center Indiana University Bloomington 1
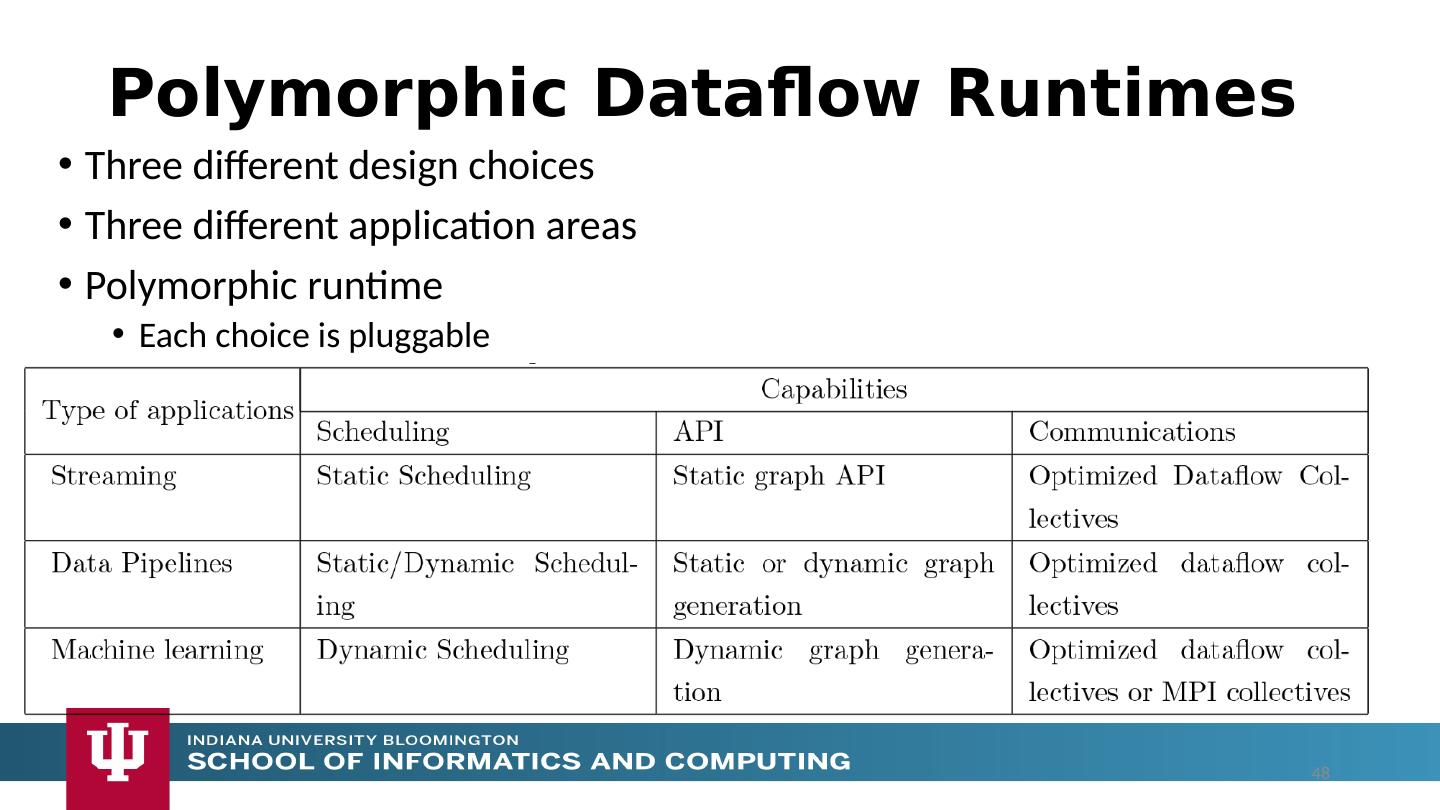
2 .“Next Generation Grid – HPC Cloud” Problem Statement Design a dataflow event-driven FaaS (microservice) framework running across application and geographic domains. Build on Cloud best practice but use HPC wherever possible and useful to get high performance Smoothly support current paradigms Hadoop, Spark, Flink, Heron, MPI, DARMA … Use interoperable common abstractions but multiple polymorphic implementations. i.e. do not require a single runtime Focus on Runtime but this implicitly suggests programming and execution model This next generation Grid based on data and edge devices – not computing as in old Grid 2
3 .Data gaining in importance compared to simulations Data analysis techniques changing with old and new applications All forms of IT increasing in importance; both data and simulations increasing Internet of Things and Edge Computing growing in importance Exascale initiative driving large supercomputers Use of public clouds increasing rapidly Clouds becoming diverse with subsystems containing GPU’s, FPGA’s, high performance networks, storage, memory … They have economies of scale; hard to compete with Serverless computing attractive to user: “No server is easier to manage than no server” Important Trends I 3
4 .Rich software stacks: HPC for Parallel Computing Apache for Big Data including some edge computing (streaming data) On general principles parallel and distributed computing has different requirements even if sometimes similar functionalities Apache stack typically uses distributed computing concepts For example, Reduce operation is different in MPI (Harp) and Spark Important to put grain size into analysis Its easier to make dataflow efficient if grain size large Streaming Data ubiquitous including data from edge Edge computing has some time-sensitive applications Choosing a good restaurant can wait seconds Avoiding collisions must be finished in milliseconds Important Trends II 4
5 .HPC needed for some Big Data processing Deep Learning needs small HPC systems Big Data requirements are not clear but current workloads have substantial pleasingly parallel or modestly synchronized applications that are well suited to current clouds Maybe will change as users get more sophisticated Such as change happened in simulation as increased computer power led to ability to do much larger and different problems (2D in 1980 became fully realistic 3D) Data should not be moved unless essential Supported by Fog computing Fog is a well establish idea but no agreement on architecture Need Security and Fault Tolerance!! Important Trends III 5
6 .Applications ought to drive new-generation big data software stacks but (at many universities) academic applications lag commercial use in big data area and needs are quite modest This will change and we can expect big data software stacks to become more important and broadly used in academia Note importance of plethora of small (pleasingly parallel) jobs Note University compute systems historically offer HPC and not Big Data Expertise. We could anticipate users moving to public clouds (away from university systems) but Users will still want support Need a Requirements Analysis that builds in application changes that might occur as users get more sophisticated Need to help ( train ) users to explore big data opportunities Academic (Research) Big Data Applications 6
7 .Motivation Summary Explosion of Internet of Things and Cloud Computing Clouds will continue to grow and will include more use cases Edge Computing is adding an additional dimension to Cloud Computing Device --- Fog ---Cloud Event driven computing is becoming dominant Signal generated by a Sensor is an edge event Accessing a HPC linear algebra function could be event driven and replace traditional libraries by FaaS (as NetSolve GridSolve Neos did in old Grid) Services will be packaged as a powerful Function as a Service FaaS Serverless must be important: users not interested in low level details of IaaS or even PaaS? Applications will span from Edge to Multiple Clouds 7
8 .Supercomputers will c ontinu e for large simulations and may run other applications but these codes will be developed on HPC Clouds or Next-Generation Commodity Systems which are dominant force Merge Cloud HPC and Edge computing Clouds running in multiple giant datacenters offering all types of computing Distributed data sources associated with device and Fog processing resources Server-hidden computing for user pleasure Support a distributed event driven dataflow computing model covering batch and streaming data Needing parallel and distributed (Grid) computing ideas Predictions/Assumptions 8
9 .Implementing these ideas at a high level 9
10 .Integrate systems that offer full capabilities Scheduling Storage “Database” Programming Model (dataflow and/or “in-place” control-flow) and corresponding runtime Analytics Workflow Function as a Service and Event-based Programming With a broad scope For both Batch and Streaming Distributed and Centralized ( Grid versus Cluster ) Pleasingly parallel ( Local machine learning ) and Global machine learning (large scale parallel codes) How do we do this? What is the challenge? 10
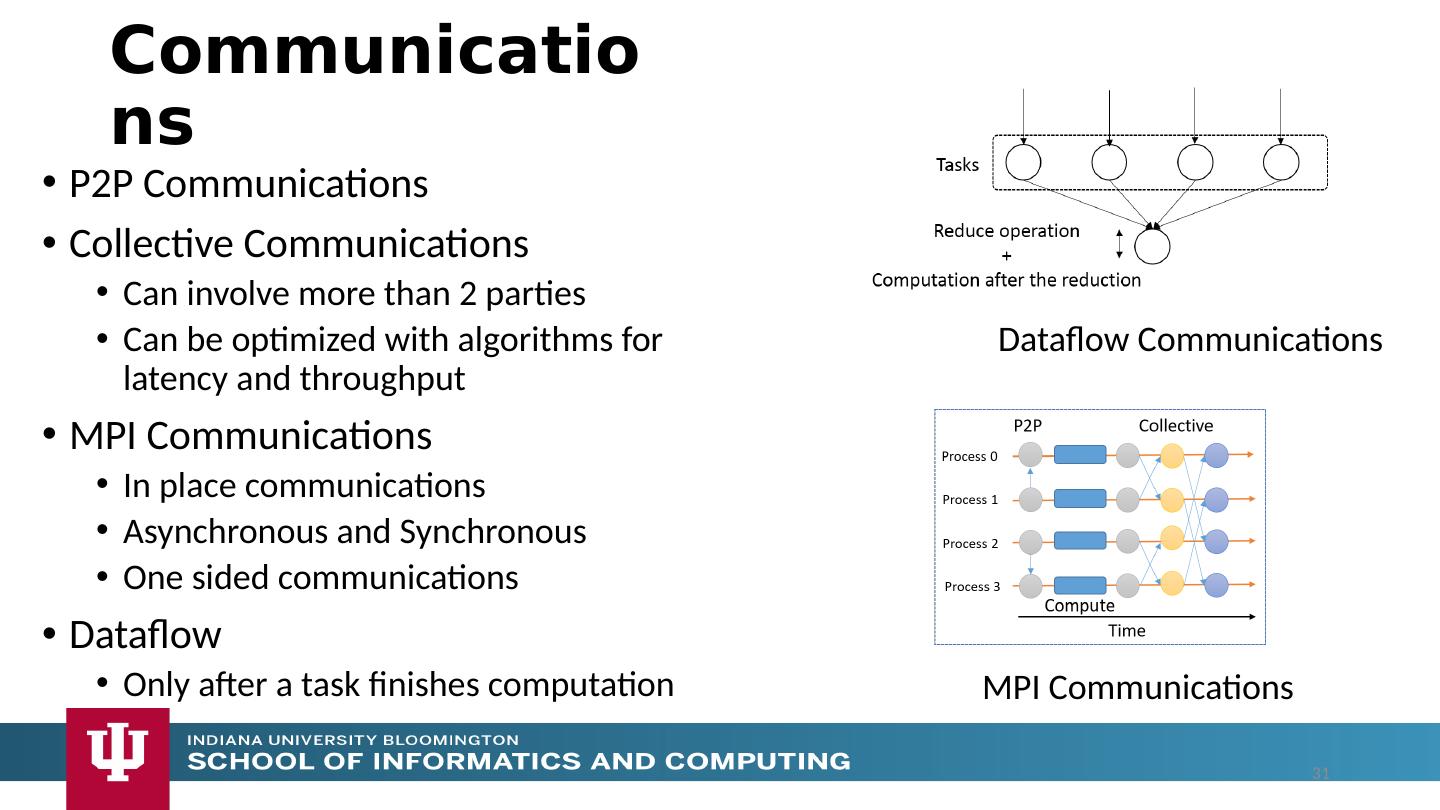
11 .Unit of Processing is an Event driven Function (a service) Can have state that may need to be preserved in place (Iterative MapReduce) Can be hierarchical as in invoking a parallel job Functions can be single or 1 of 100,000 maps in large parallel code Processing units run in clouds, fogs or devices but these all have similar architecture Fog (e.g. car) looks like a cloud to a device (radar sensor) while public cloud looks like a cloud to the fog (car) Use polymorphic runtime that uses different implementations depending on environment e.g. on fault-tolerance – latency (performance) tradeoffs Data locality (minimize explicit dataflow) properly supported as in HPF alignment commands (specify which data and computing needs to be kept together) Support the federation of the heterogeneous (in function – not just interface that characterized old Grid) resources that form the new Grid Proposed Approach I 11
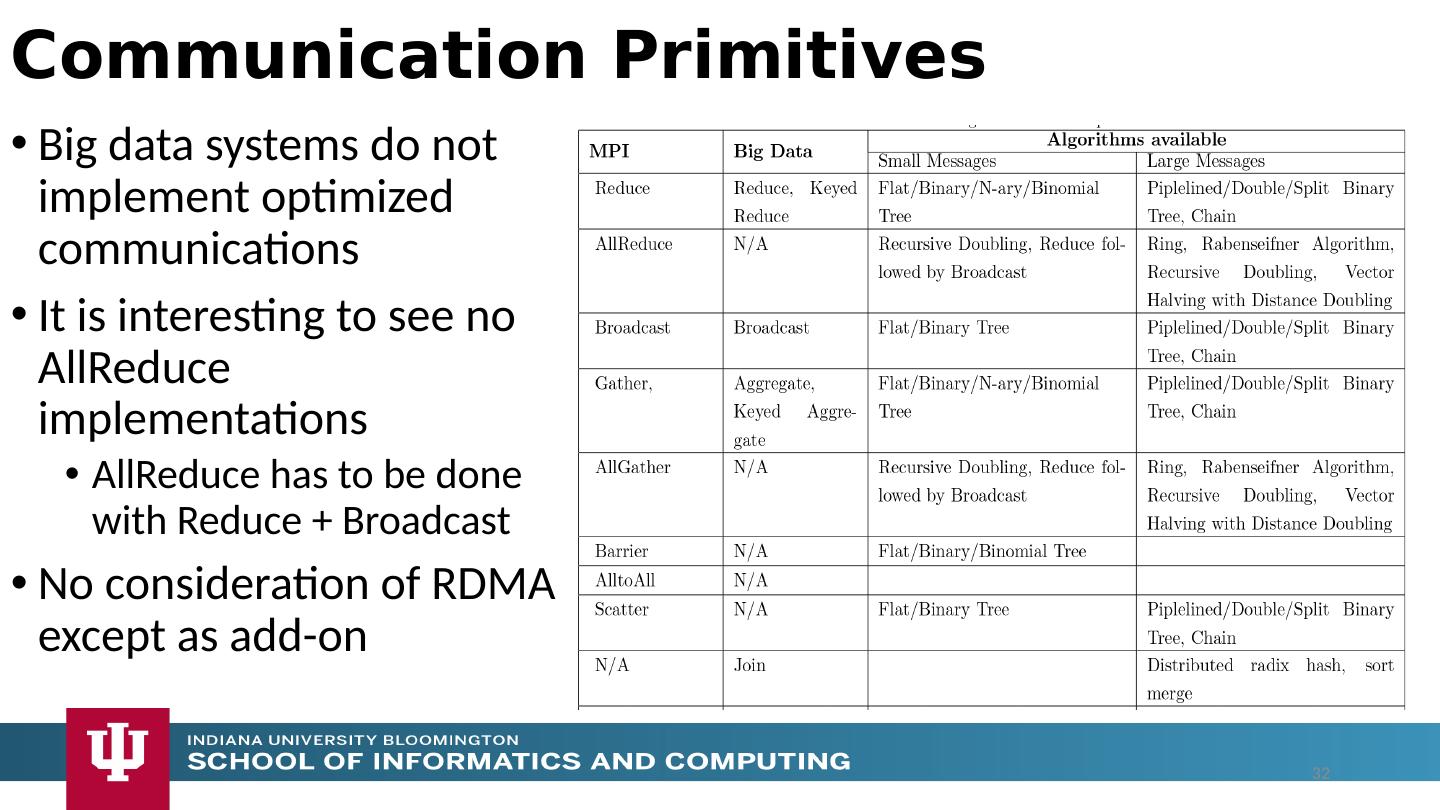
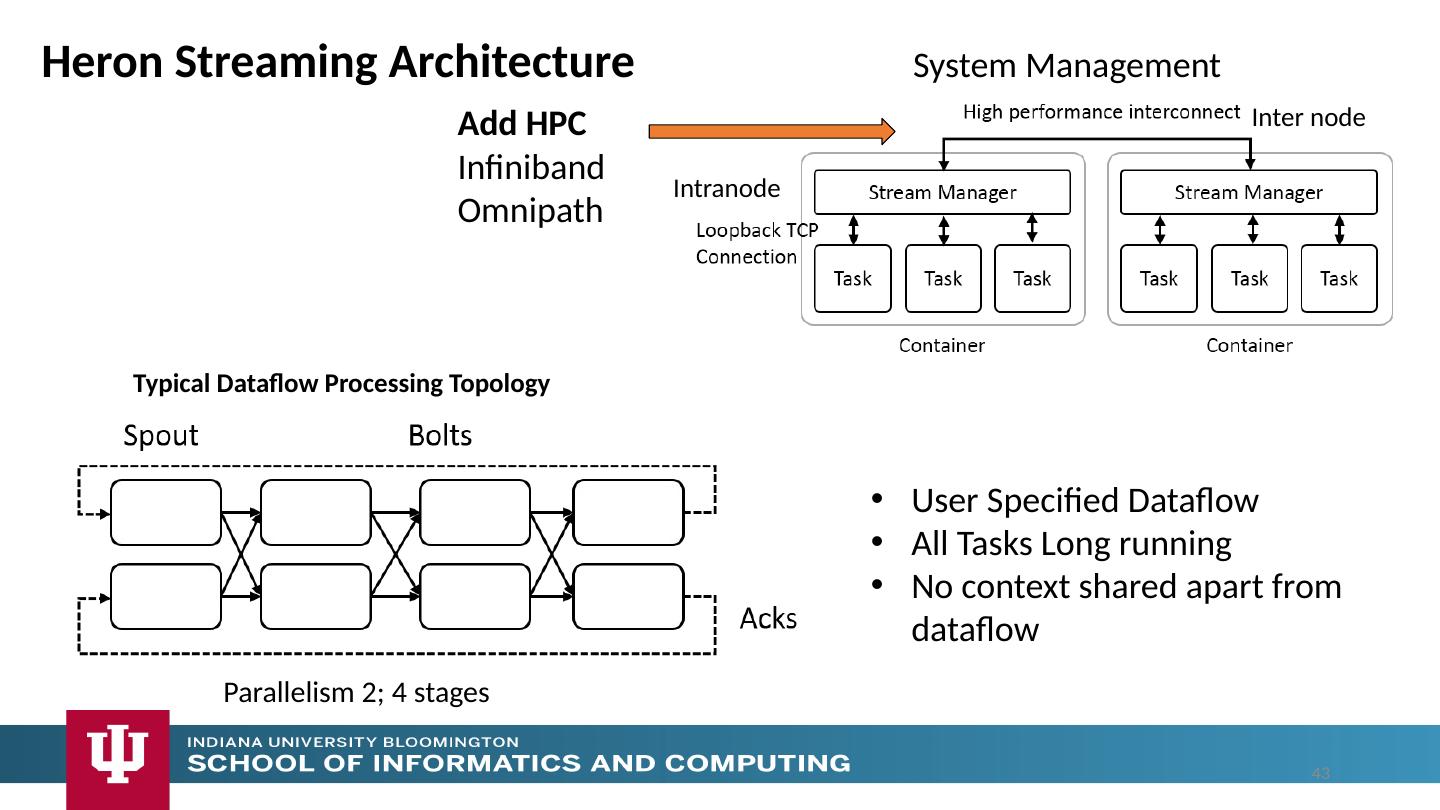
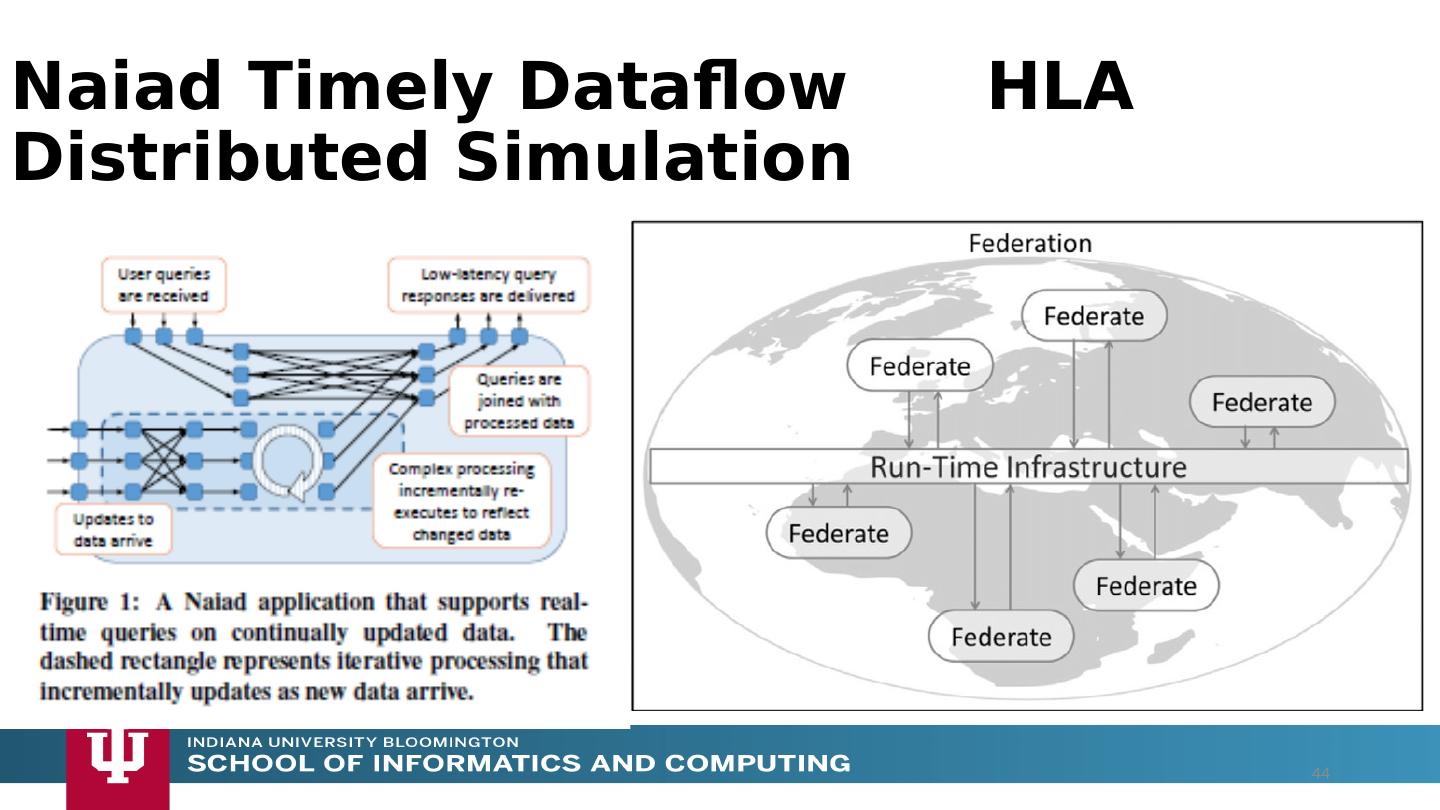
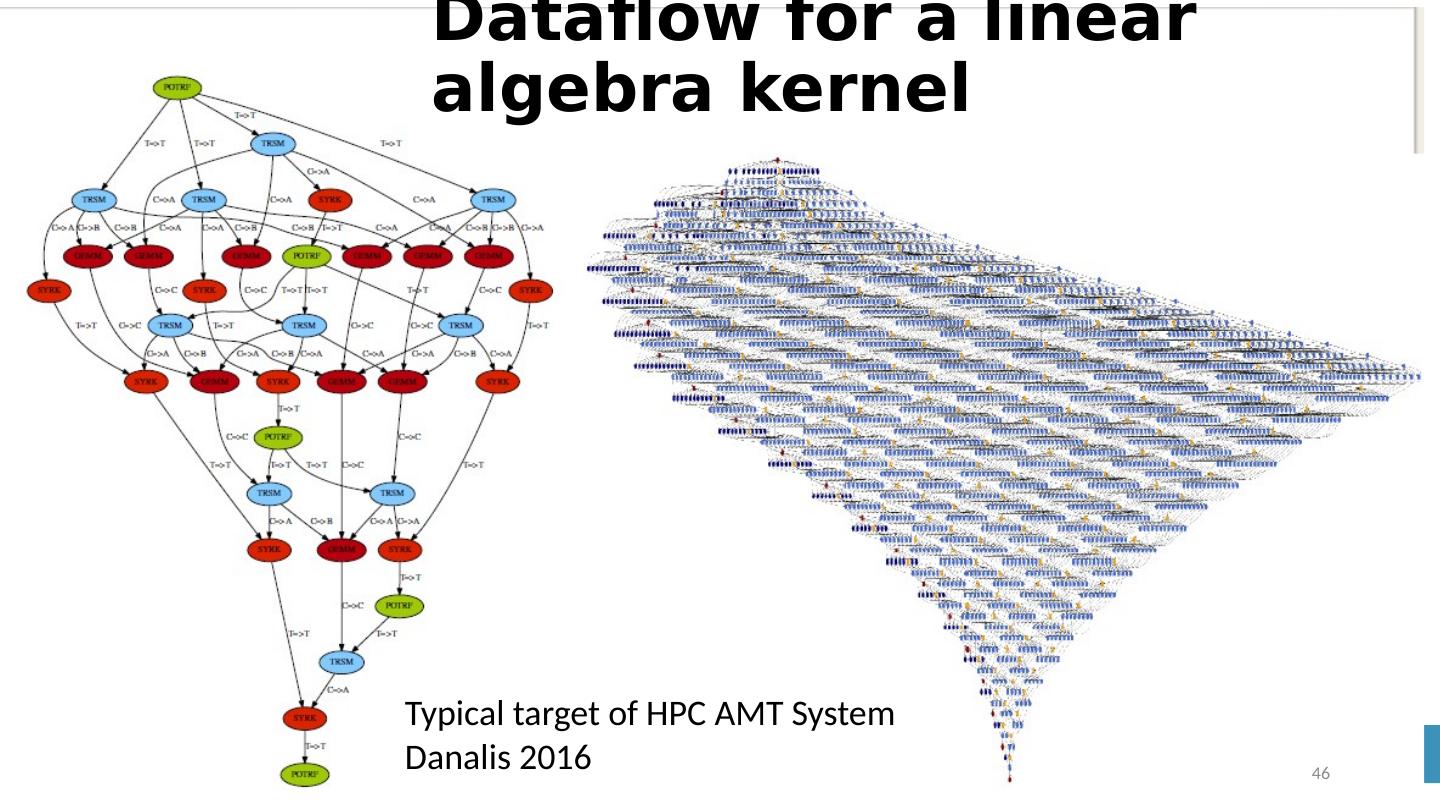
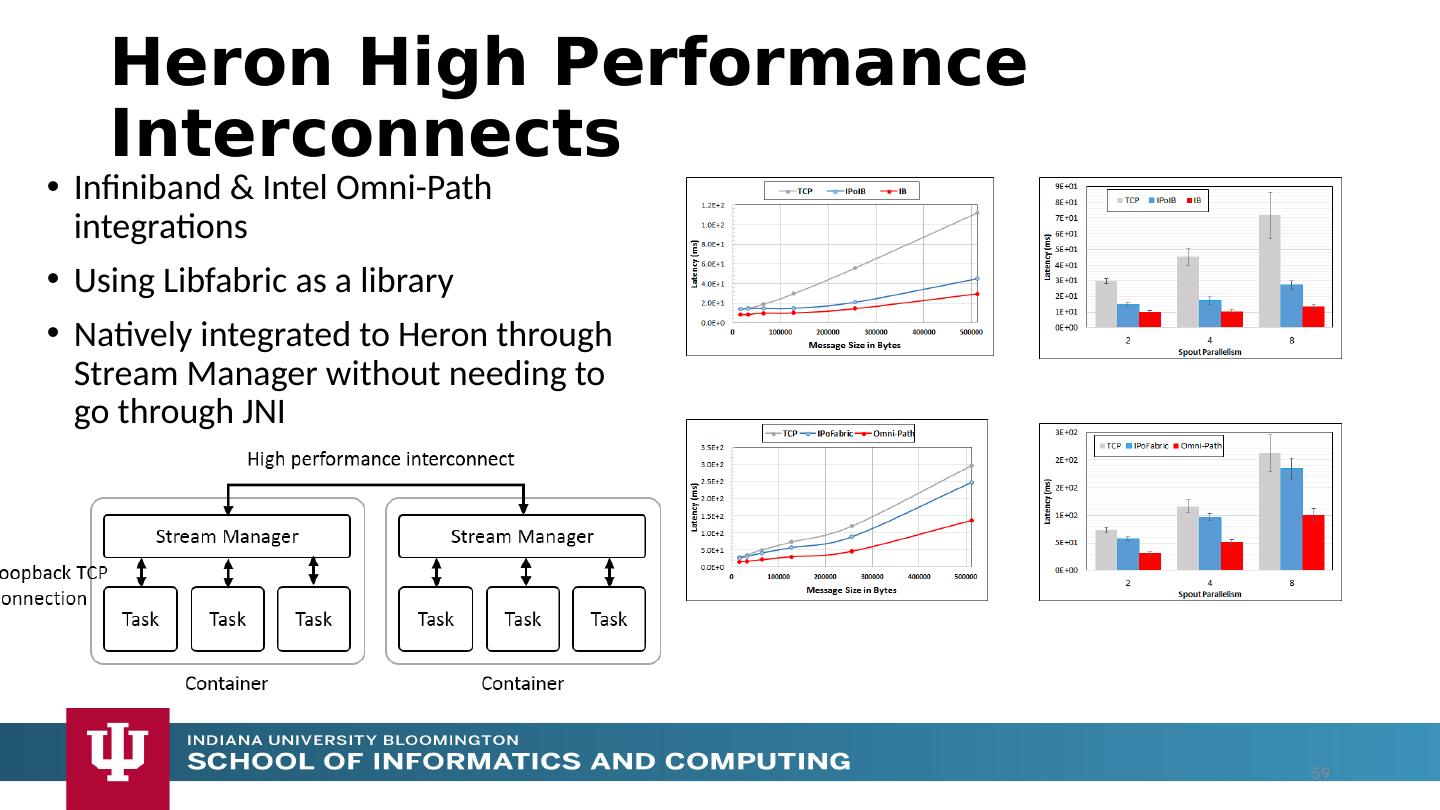
12 .Analyze the runtime of existing systems Hadoop, Spark, Flink, Naiad Big Data Processing Storm, Heron Streaming Dataflow Kepler, Pegasus, NiFi workflow systems Harp Map-Collective, MPI and HPC AMT runtime like DARMA And approaches such as GridFTP and CORBA/HLA (!) for wide area data links Propose polymorphic unification (given function can have different implementations) Choose powerful scheduler ( Mesos ?) Support processing locality/alignment including MPI’s never move model with grain size consideration This should integrate HPC and Clouds Proposed Approach II 12
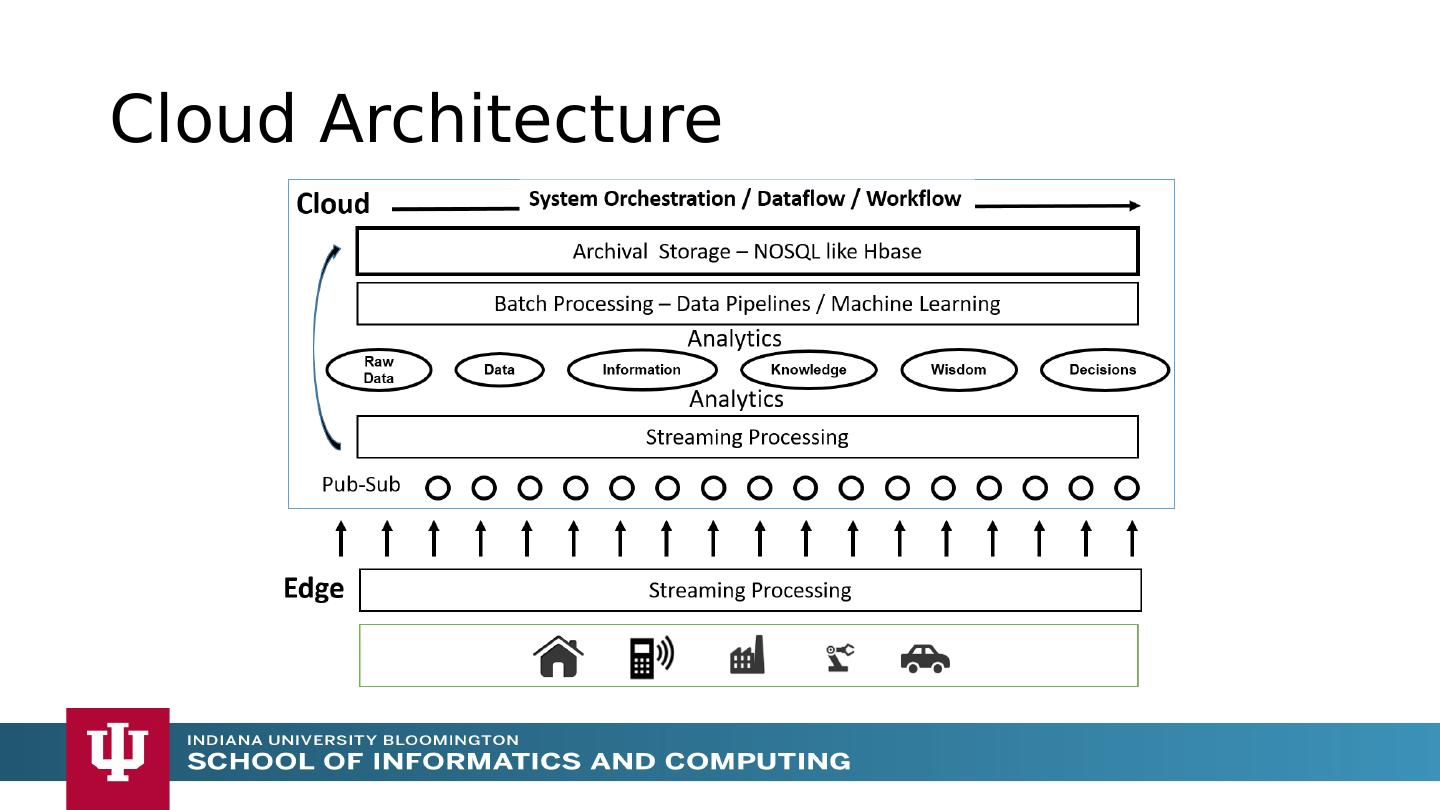
13 .Cloud Architecture
14 .Implementing these ideas in detail 14
15 .Google likes to show a timeline; we can build on (Apache version of) this 2002 Google File System GFS ~HDFS 2004 MapReduce Apache Hadoop 2006 Big Table Apache Hbase 2008 Dremel Apache Drill 2009 Pregel Apache Giraph 2010 FlumeJava Apache Crunch 2010 Colossus better GFS 2012 Spanner horizontally scalable NewSQL database ~ CockroachDB 2013 F1 horizontally scalable SQL database 2013 MillWheel ~Apache Storm, Twitter Heron (Google not first!) 2015 Cloud Dataflow Apache Beam with Spark or Flink (dataflow) engine Functionalities not identified: Security, Data Transfer, Scheduling, DevOps, serverless computing (assume OpenWhisk will improve to handle robustly lots of large functions) Components of Big Data Stack 15
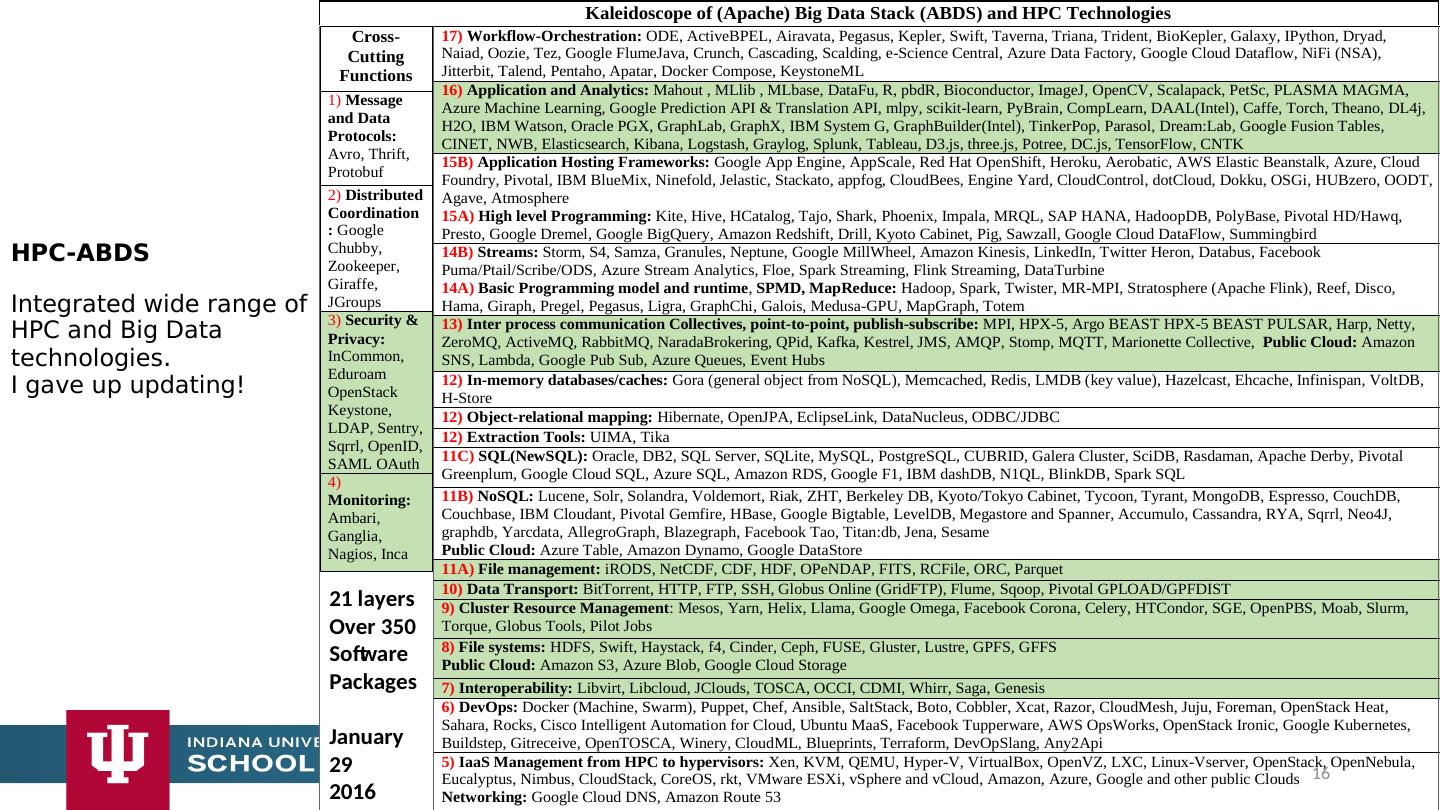
16 .HPC-ABDS Integrated wide range of HPC and Big Data technologies . I gave up updating! 16
17 .HPC-ABDS Integrated wide range of HPC and Big Data technologies . I gave up updating! 16
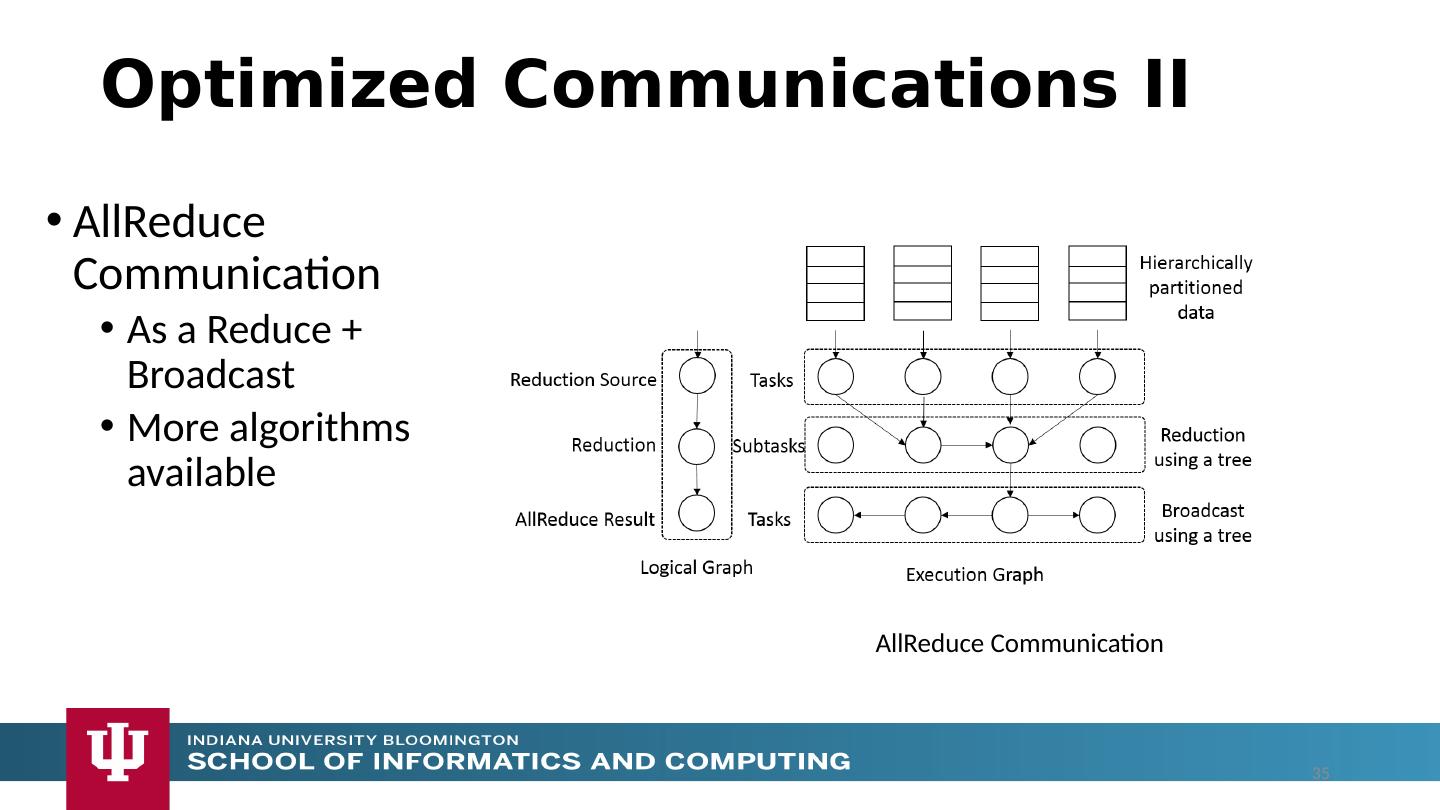
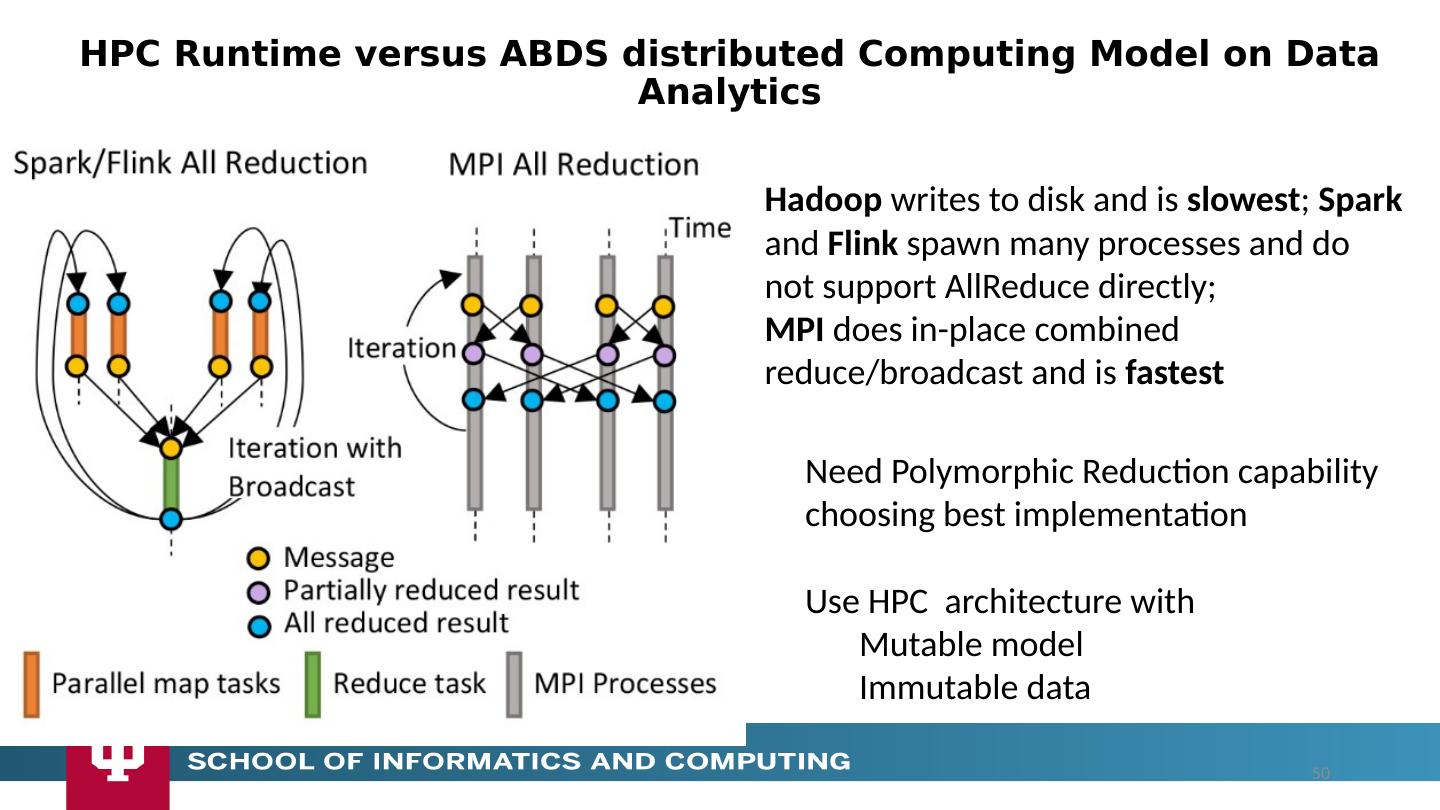
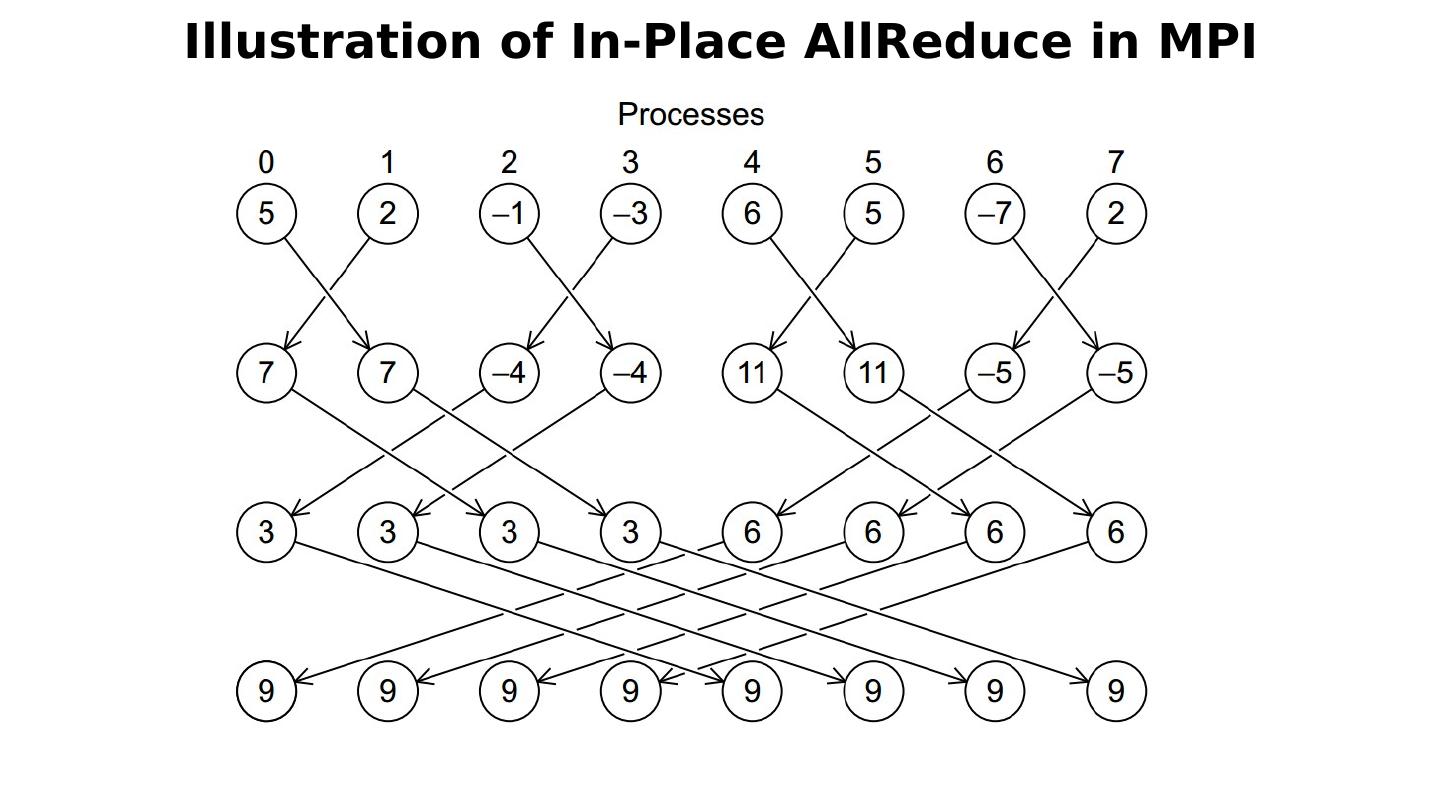
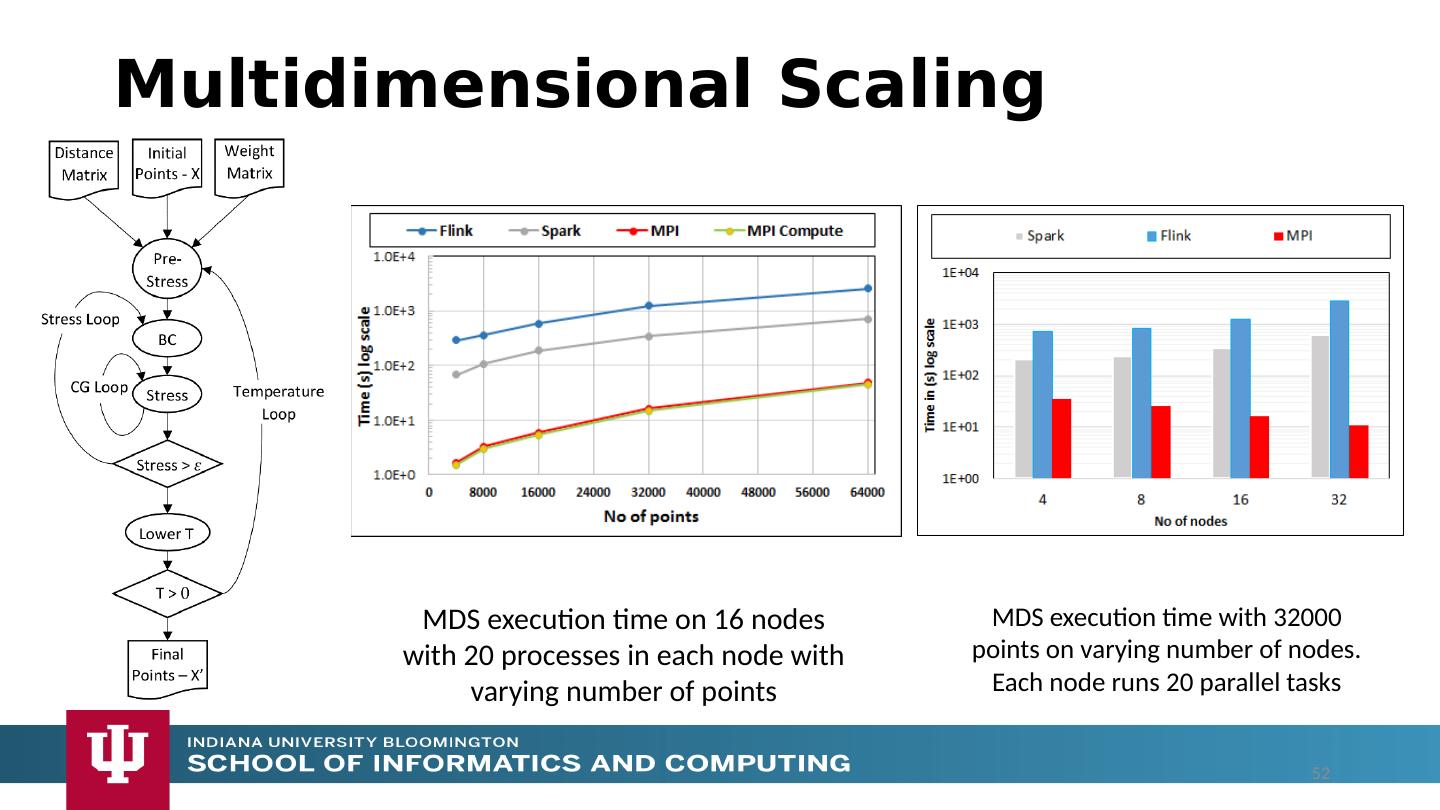
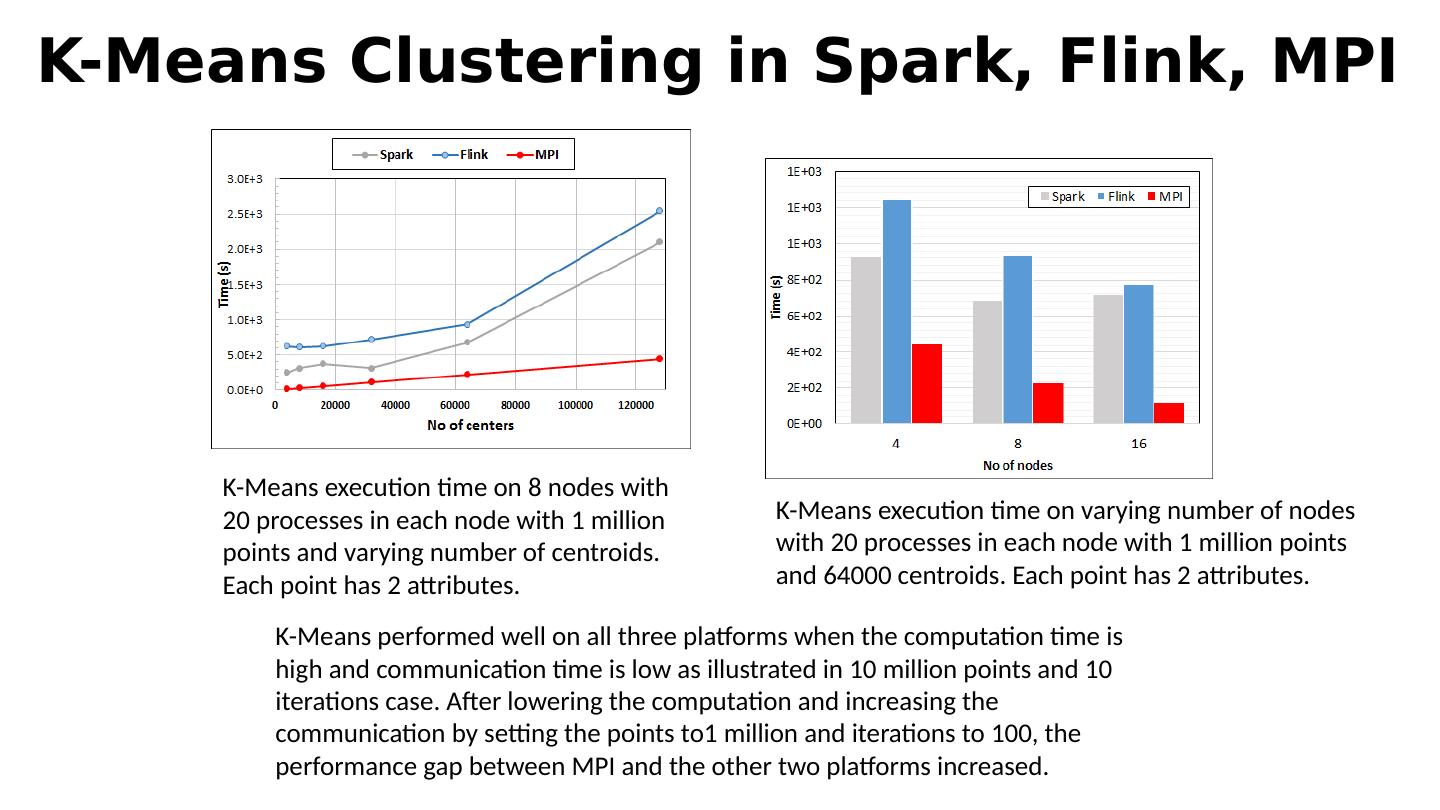
18 .The performance of Spark, Flink, Hadoop on classic parallel data analytics is poor/dreadful whereas HPC (MPI) is good One way to understand this is to note most Apache systems deliberately support a dataflow programming model e.g. for Reduce, Apache will launch a bunch of tasks and eventually bring results back MPI runs a clever AllReduce interleaved “in-place” tree Maybe can preserve Spark, Flink programming model but change implementation “under the hood” where optimization important. Note explicit dataflow is efficient and preferred at coarse scale as used in workflow systems Need to change implementations for different problems Why use HPC and not Spark, Flink, Hadoop? 18
19 .Big Data Applications I Big Data Large data Heterogeneous sources Unstructured data in raw storage Semi-structured data in NoSQL databases Raw streaming data Important characteristics affecting processing requirements Data can be too big to load into even a large cluster Data may not be load balanced Streaming data needs to be analyzed before storing to disk 19
20 .Big Data Applications II Streaming applications High rate of data Low latency processing requirements Simple queries to complex online analytics Data pipelines Raw data or semi structured data in in NoSQL databases Extract, transform and load (ETL) operations Machine learning Mostly deal with curated data Complex algebraic operations Iterative computations with tight synchronizations 20
21 .What do we need in runtime for distributed HPC FaaS Finish examination of all the current tools Handle Events Handle State Handle Scheduling and Invocation of Function Define data-flow graph that needs to be analyzed Handle data flow execution graph with internal event-driven model Handle geographic distribution of Functions and Events Design dataflow collective and P2P communication model Decide which streaming approach to adopt and integrate Design in-memory dataset model for backup and exchange of data in data flow (fault tolerance) Support DevOps and server-hidden cloud models Support elasticity for FaaS (connected to server-hidden) 21
22 .MPI Applications HPC application with components written in MPI and orchestrated by a workflow engine Tightly synchronized applications Efficient communications (µs latency) Use of advanced hardware In place communications and computations Process scope state HPC applications are orchestrated by workflow engines Can expect curated, balanced data User is required to manage threads, caches, NUMA boundaries 22
23 .Load Imbalance & Velocity Data in raw form are not load balanced HDFS, NoSQL , Streaming data MPI style tightly synchronized operations need sophisticated load balancing? Asynchronous Many Task Runtime such as DARMA suitable? 23
24 .Data Partitioning Cannot process the complete data set in memory Data partitioned across the tasks Each task partitions the data further Need to program specifically to handle such partitioning Sometimes need to align partitions of different datasets Supported in past by HPF but not now? 24
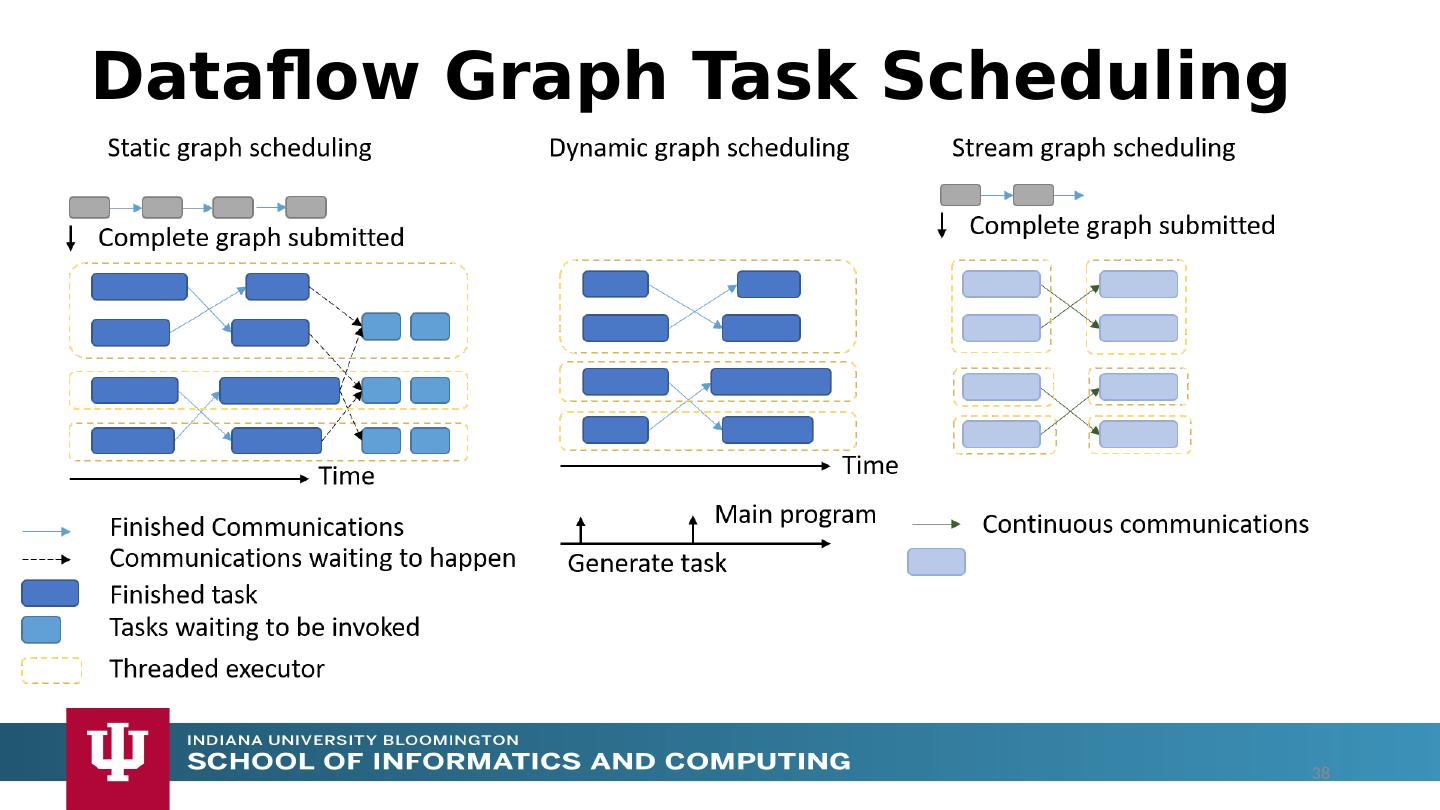
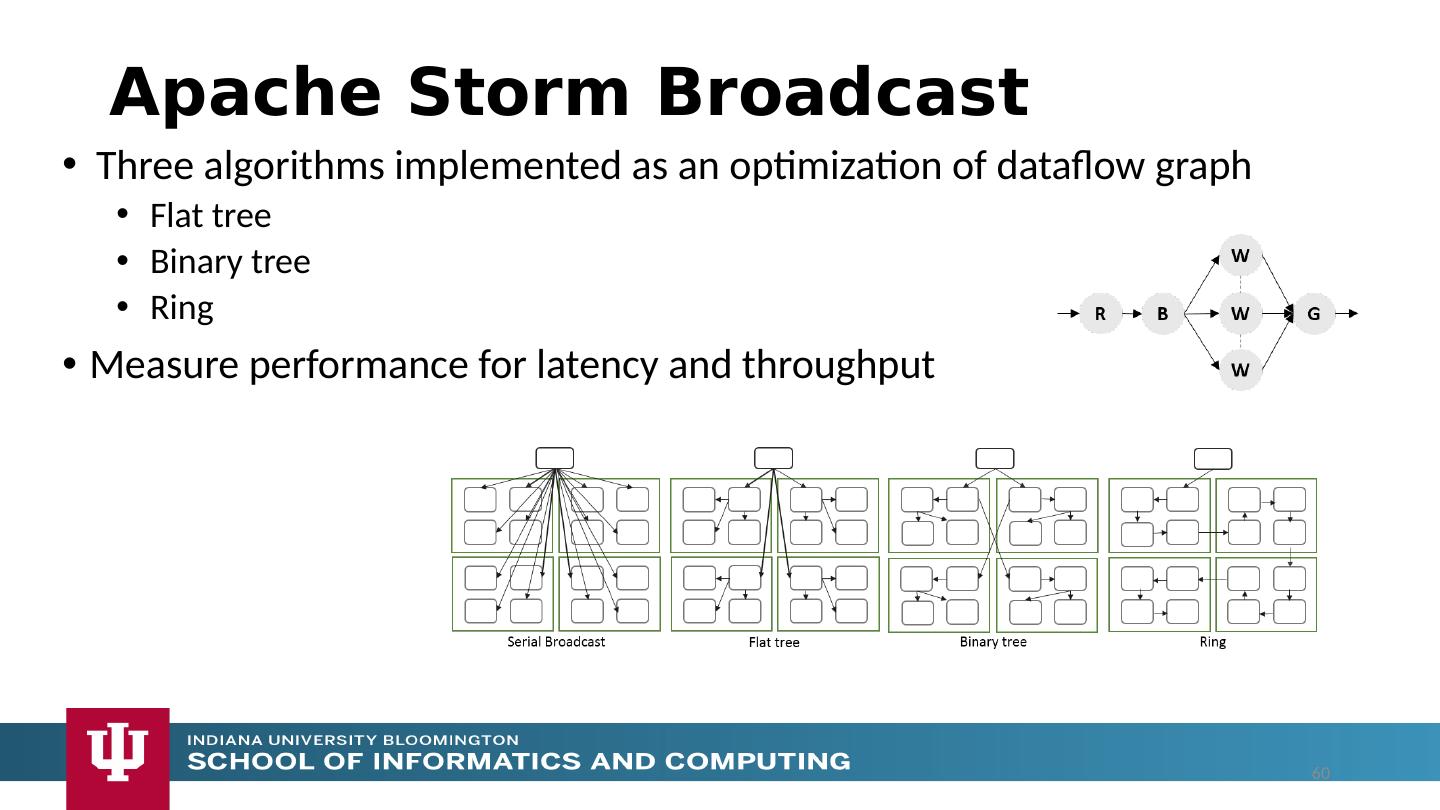
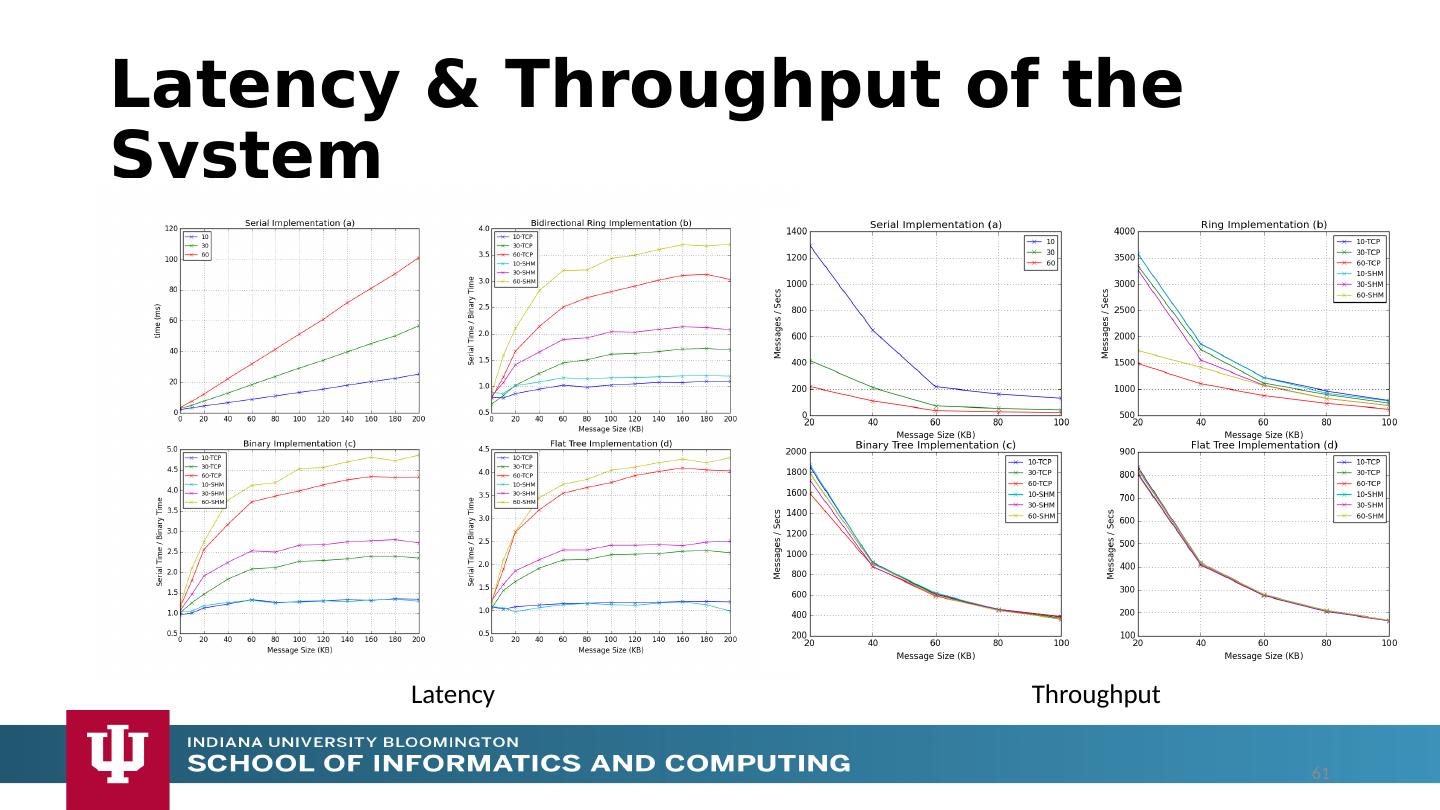
25 .Dataflow Applications Model a computation as a graph Nodes does computations - Task Edges communications A computation is activated when its input data dependencies are satisfied Data driven Asynchronous execution of tasks Tasks can only communicate through their input and output edges To preserve asynchronous nature of computation Otherwise becomes MPI S W G S W G S W W 25
26 .Streaming - Dataflow Applications Streaming is a natural fit for dataflow Partitions of the data are called Streams Streams are unbounded, ordered data tuples Order of events important Group data into windows Count based Time based Types of windows Sliding Windows Tumbling Windows Continuously Executing Graph 26
27 .Data Pipelines – Dataflow Applications Similar to streaming applications Finite amount of data Partitioned hierarchically similar to streaming Mostly pleasingly parallel, but some form of communications can be required Reduce, Join 27
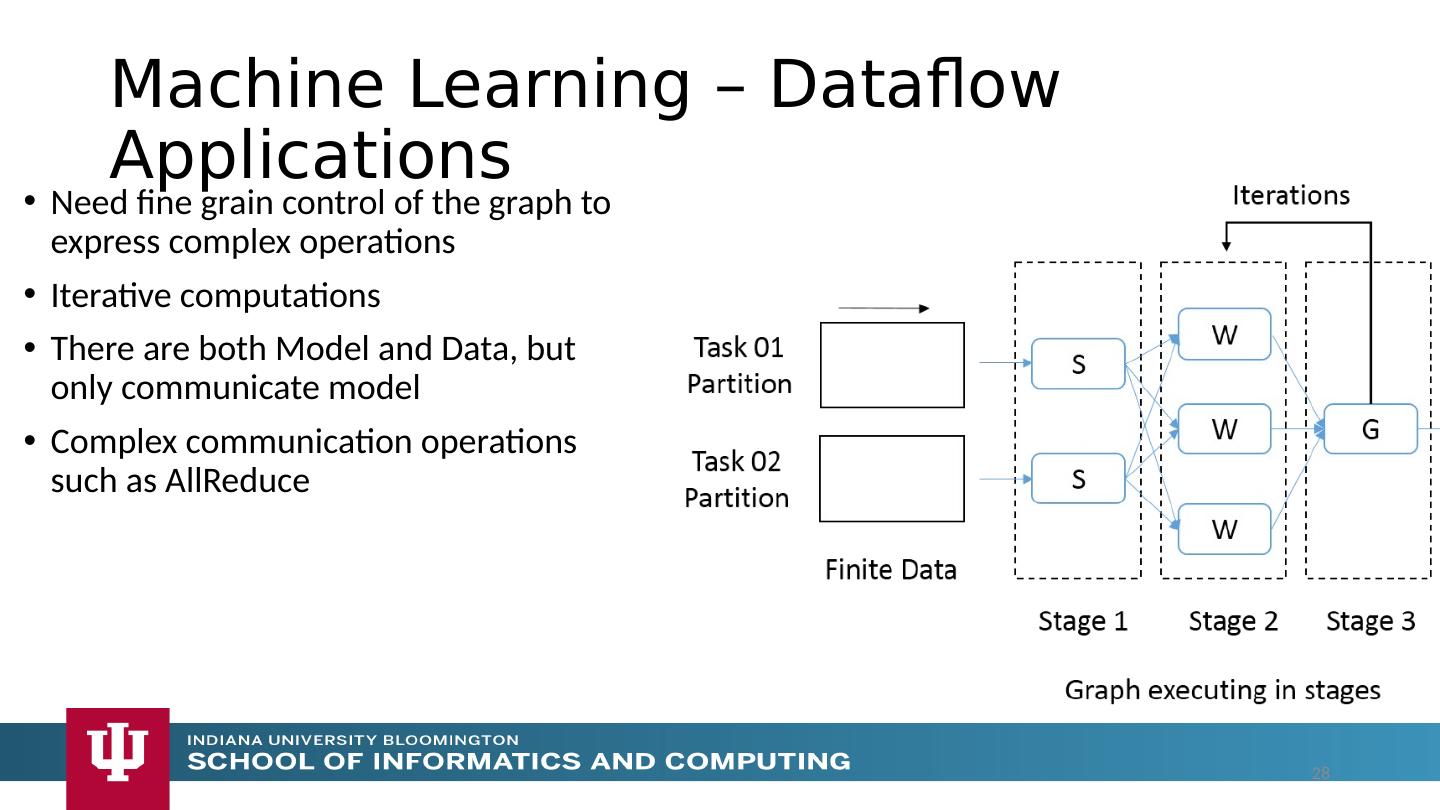
28 .Machine Learning – Dataflow Applications Need fine grain control of the graph to express complex operations Iterative computations There are both Model and Data, but only communicate model Complex communication operations such as AllReduce 28
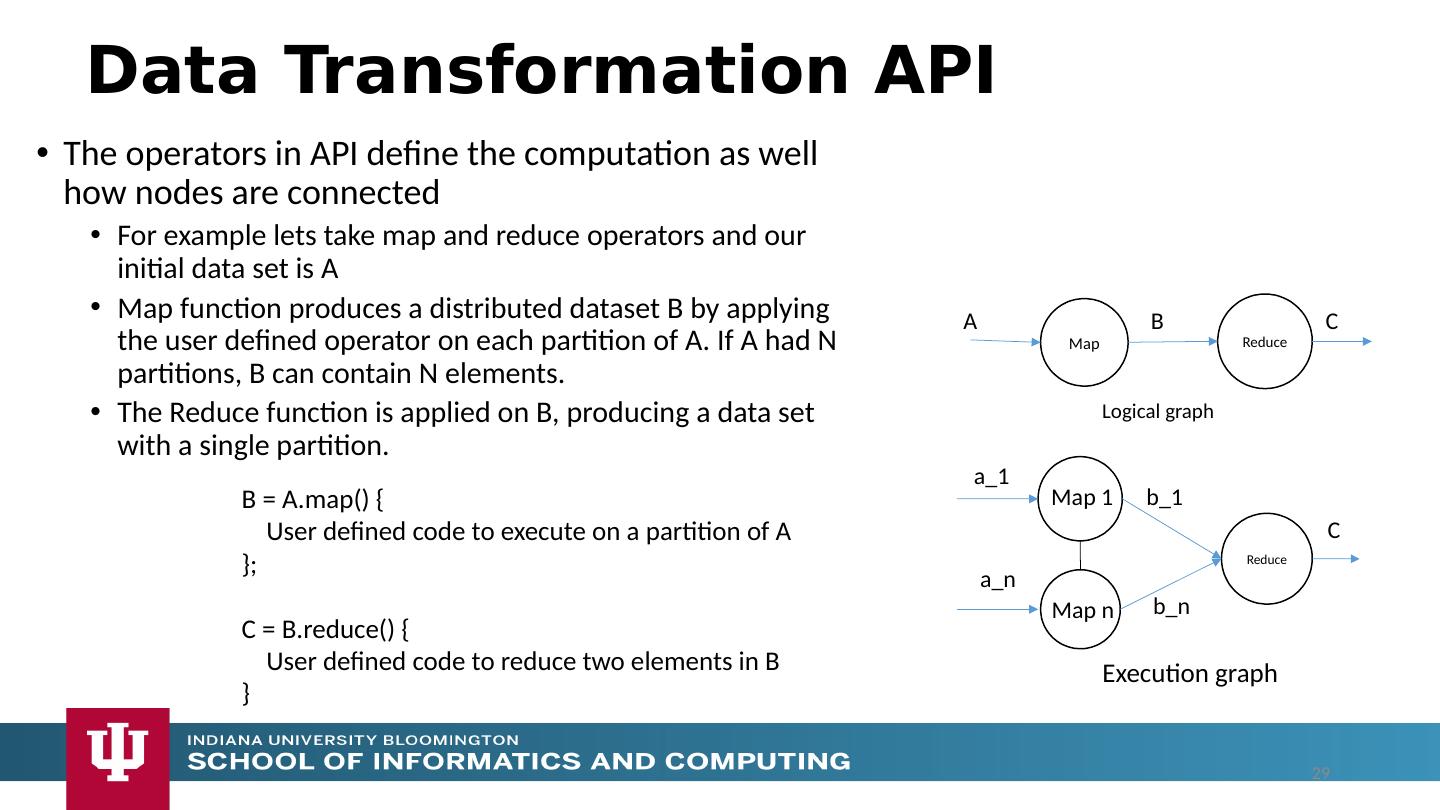
29 .Data Transformation API The operators in API define the computation as well how nodes are connected For example lets take map and reduce operators and our initial data set is A Map function produces a distributed dataset B by applying the user defined operator on each partition of A. If A had N partitions, B can contain N elements. The Reduce function is applied on B, producing a data set with a single partition. B = A.map () { User defined code to execute on a partition of A }; C = B.reduce () { User defined code to reduce two elements in B } Map A Reduce B Logical graph C a_1 Reduce b_1 Execution graph C a_n b_n Map 1 Map n 29
相关推荐
3秒后跳转登录页面
去登陆

