











































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Massively Parallel Data Storage System
大数据爆炸时代,大型分布式并行数据存储系统势在必行,谈到他们,不可避免要谈到分布式事务处理(比如:同步控制/数据复制和一致性),分布式文件系统,ACID和CAP理论,这些问题都是比较经典的问题,随着技术和方案的发展,顺带一起解释了这其中的先行者(比如F1,Spanner,MegaStore,Dynamo)解决这些难点问题的办法。虽然文章发布于2015年,但是对现在的系统设计和使用仍然具有借鉴意义。
展开查看详情
1 .Massively Parallel/Distributed Data Storage Systems S. Sudarshan IIT Bombay Oct 2015
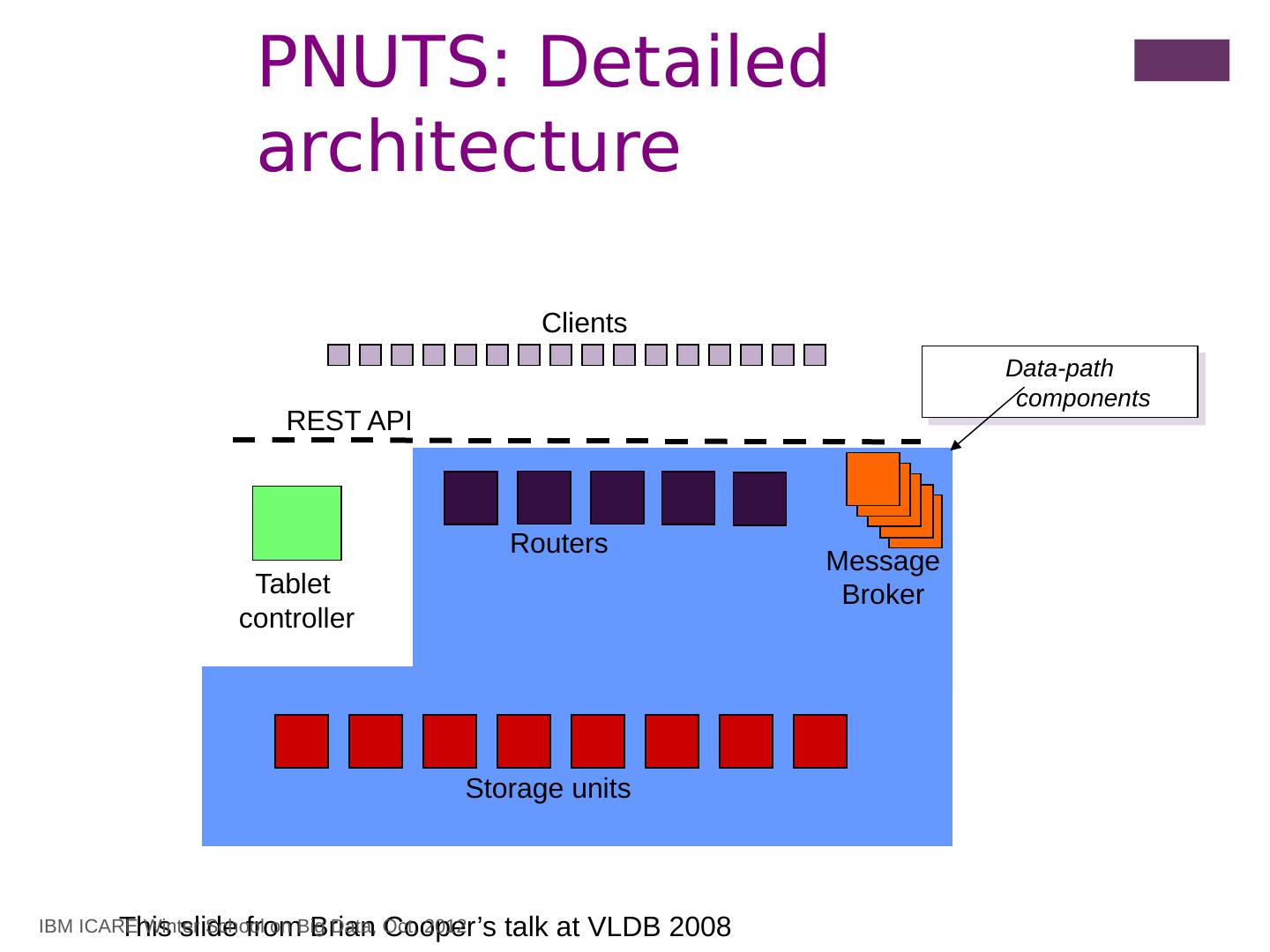
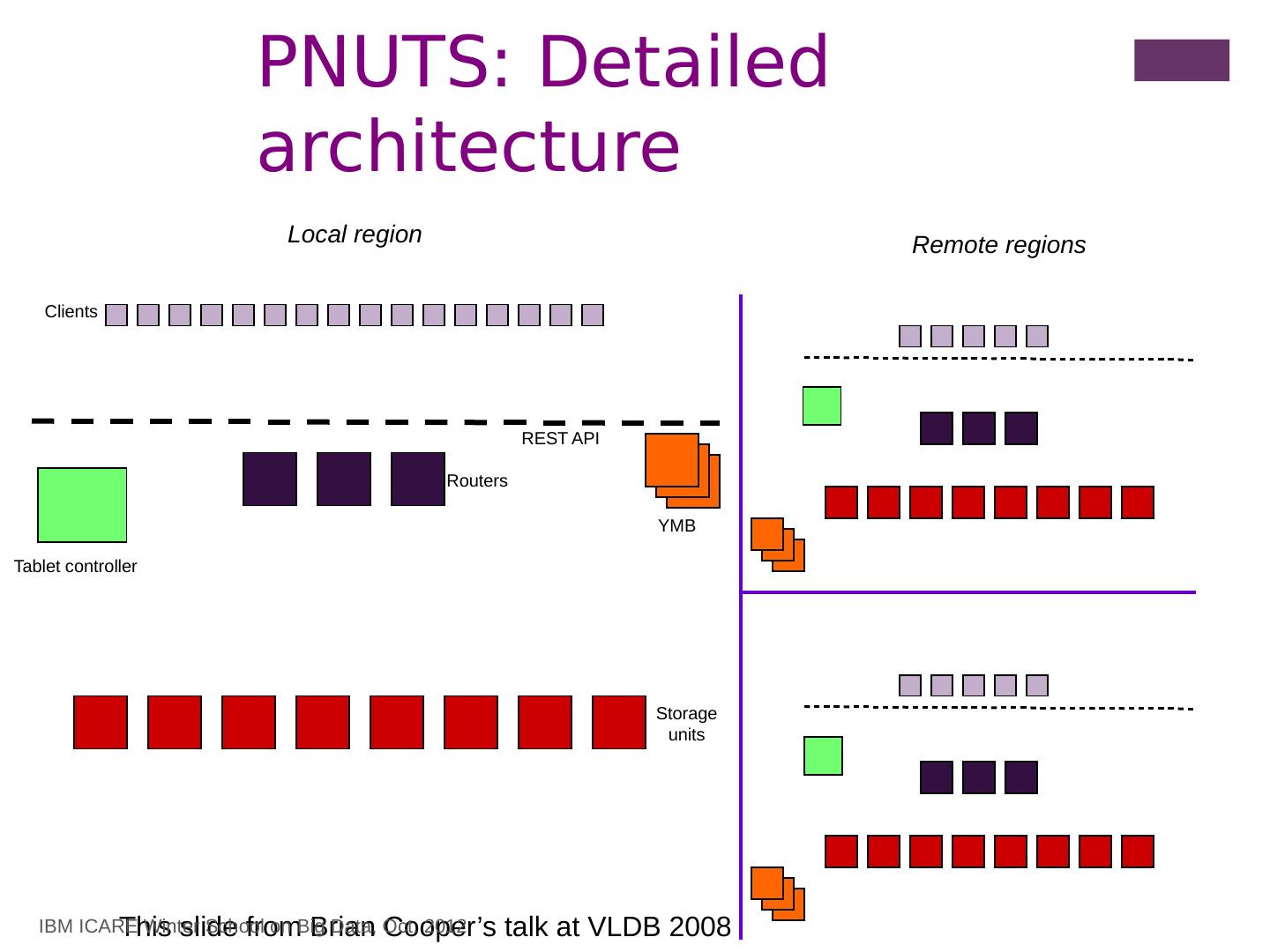
2 .Talk Outline Introduction Distributed Transactions Concurrency Control/Replication Consistency Schemes Distributed File Systems Parallel/Distributed Data Storage Systems Basics Architecture Bigtable (Google) PNUTS/Sherpa (Yahoo ) Back Towards ACID Megastore (Google ) Spanner (Google) F1 (Google) A vailability vs. consistency Basics, CAP Theorem Dynamo (Amazon ) Conclusions IBM ICARE Winter School on Big Data, Oct. 2012
3 .Why Distributed Data Storage a.k.a. Cloud Storage Explosion of social media sites (Facebook, Twitter) with large data needs Explosion of storage needs in large web sites such as Google, Yahoo 100’s of millions of users Many applications with petabytes of data Much of the data is not files Very high demands on Scalability Availability IBM ICARE Winter School on Big Data, Oct. 2012
4 .Why Distributed Data Storage a.k.a. Cloud Storage Step 0 (prehistory): Distributed database systems with tens of nodes Step 1: Distributed file systems with 1000s of nodes Millions of Large objects (100’s of megabytes) Step 2: Distributed data storage systems with 1000s of nodes 100s of billions of smaller (kilobyte to megabyte) objects Step 3 (recent and future work): Distributed database systems with 1000s of nodes IBM ICARE Winter School on Big Data, Oct. 2012
5 .Examples of Types of Big Data Large objects video, large images, web logs Typically write once, read many times, no updates Distributed file systems Transactional data from Web-based applications E.g. social network (Facebook/Twitter) updates, friend lists, likes, … email (at least metadata) Billions to trillions of objects, distributed data storage systems Indices E.g. Web search indices with inverted list per word In earlier days, no updates, rebuild periodically Today: frequent updates (e.g. Google Percolator) IBM ICARE Winter School on Big Data, Oct. 2012
6 .Why not use Parallel Databases? Parallel databases have been around since 1980s M ost parallel databases were designed for decision support not OLTP Were designed for scales of 10s to 100’s of processors Single machine failures are common and are handled But usually require jobs to be rerun in case of failure during exection Do not consider network partitions, and data distribution Demands on distributed data storage systems Scalability to thousands to tens of thousands of nodes Geographic distribution for lower latency, and higher availability IBM ICARE Winter School on Big Data, Oct. 2012
7 .Basics: Parallel/Distributed Data Storage Replication System maintains multiple copies of data, stored in different nodes/sites , for faster retrieval and fault tolerance. Data partitioning Relation is divided into several partitions stored in distinct nodes/sites Replication and partitioning are combined Relation is divided into multiple partition; system maintains several identical replicas of each such partition. IBM ICARE Winter School on Big Data, Oct. 2012
8 .Basics: Data Replication Advantages of Replication Availability : failure of site containing relation r does not result in unavailability of r is replicas exist. Parallelism : queries on r may be processed by several nodes in parallel. Reduced data transfer : relation r is available locally at each site containing a replica of r . Cost of Replication Increased cost of updates: each replica of relation r must be updated. S pecial concurrency control and atomic commit mechanisms to ensure replicas stay in sync IBM ICARE Winter School on Big Data, Oct. 2012
9 .Basics: Data Transparency Data transparency : Degree to which system user may remain unaware of the details of how and where the data items are stored in a distributed system Consider transparency issues in relation to: Fragmentation transparency Replication transparency Location transparency IBM ICARE Winter School on Big Data, Oct. 2012
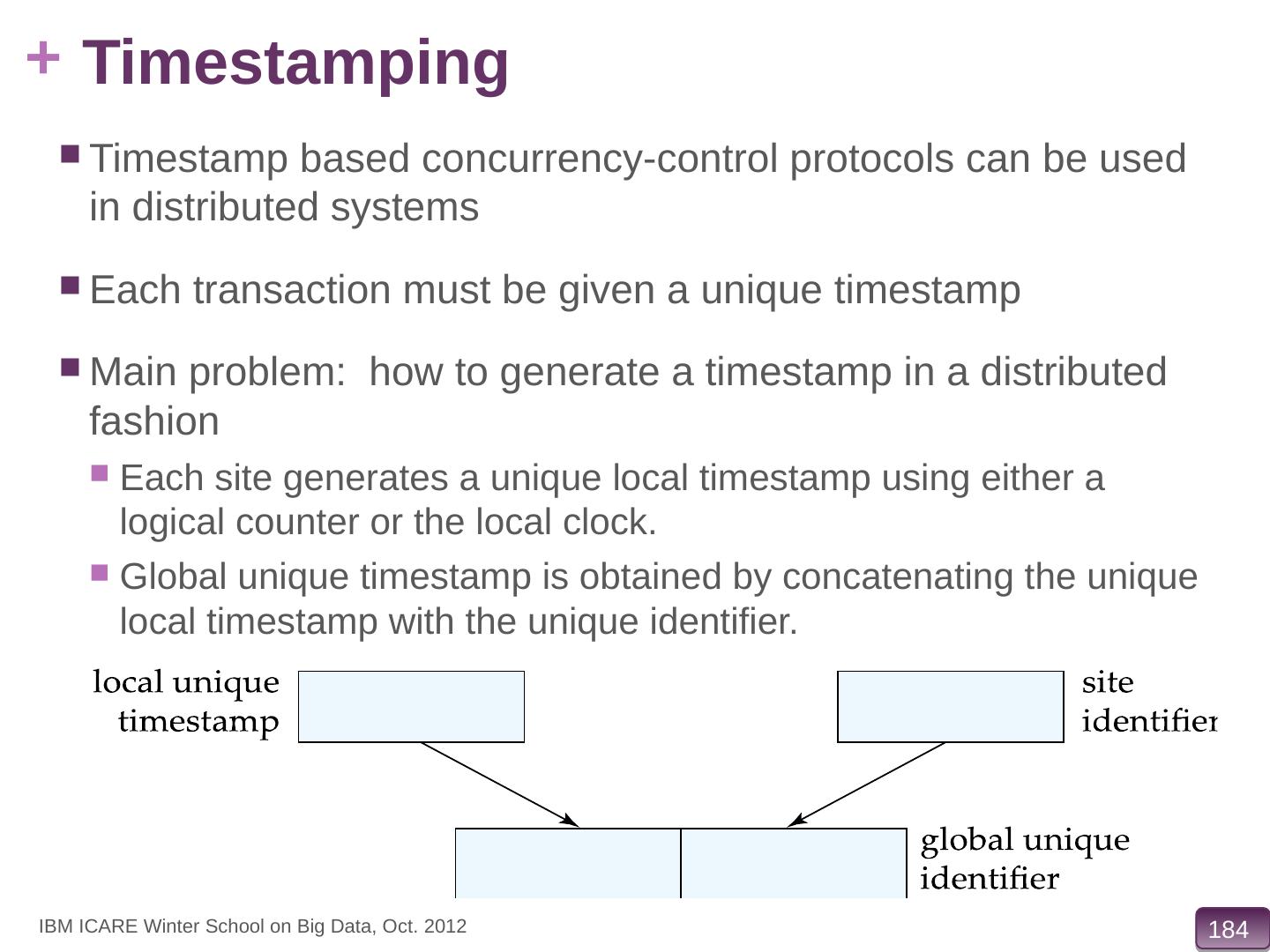
10 .Basics: Naming of Data Items Naming of items: desiderata Every data item must have a system-wide unique name. It should be possible to find the location of data items efficiently. It should be possible to change the location of data items transparently. Data item creation/naming should not be centralized Implementations: Global directory Used in file systems Partition name space Each partition under control of one node Used for data storage systems IBM ICARE Winter School on Big Data, Oct. 2012
11 .Build-it-Yourself Parallel Data Storage: a.k.a. Sharding “ Sharding ” Divide data amongst many cheap databases (MySQL/ PostgreSQL ) Manage parallel access in the application Partition tables map keys to nodes Application decides where to route storage or lookup requests Scales well for both reads and writes Limitations Not transparent application needs to be partition-aware AND application needs to deal with replication (Not a true parallel database, since parallel queries and transactions spanning nodes are not supported) IBM ICARE Winter School on Big Data, Oct. 2012
12 .Parallel/Distributed Key-Value Data Stores Distributed key-value data storage systems allow key-value pairs to be stored (and retrieved on key) in a massively parallel system E.g. Google BigTable , Apache Hbase , Yahoo ! Sherpa/PNUTS, Amazon Dynamo , Apache Cassandra, .. Partitioning, replication, high availability etc mostly transparent to application Are the responsibility of the data storage system These are NOT full-fledged database systems A.k.a. NO-SQL systems Focus of this talk IBM ICARE Winter School on Big Data, Oct. 2012
13 .Typical Data Storage Access API Basic API access: get(key) -- Extract the value given a key put(key, value) -- Create or update the value given its key delete(key) -- Remove the key and its associated value execute(key, operation, parameters) -- Invoke an operation to the value (given its key) which is a special data structure (e.g. List, Set, Map .... Etc ) Extensions to add version numbering, etc IBM ICARE Winter School on Big Data, Oct. 2012
14 .What is NoSQL? Stands for No-SQL or N ot O nly SQL?? Class of non-relational data storage systems E.g. BigTable , Dynamo, PNUTS/Sherpa, .. Synonymous with distributed data storage systems We don’t like the term NoSQL IBM ICARE Winter School on Big Data, Oct. 2012
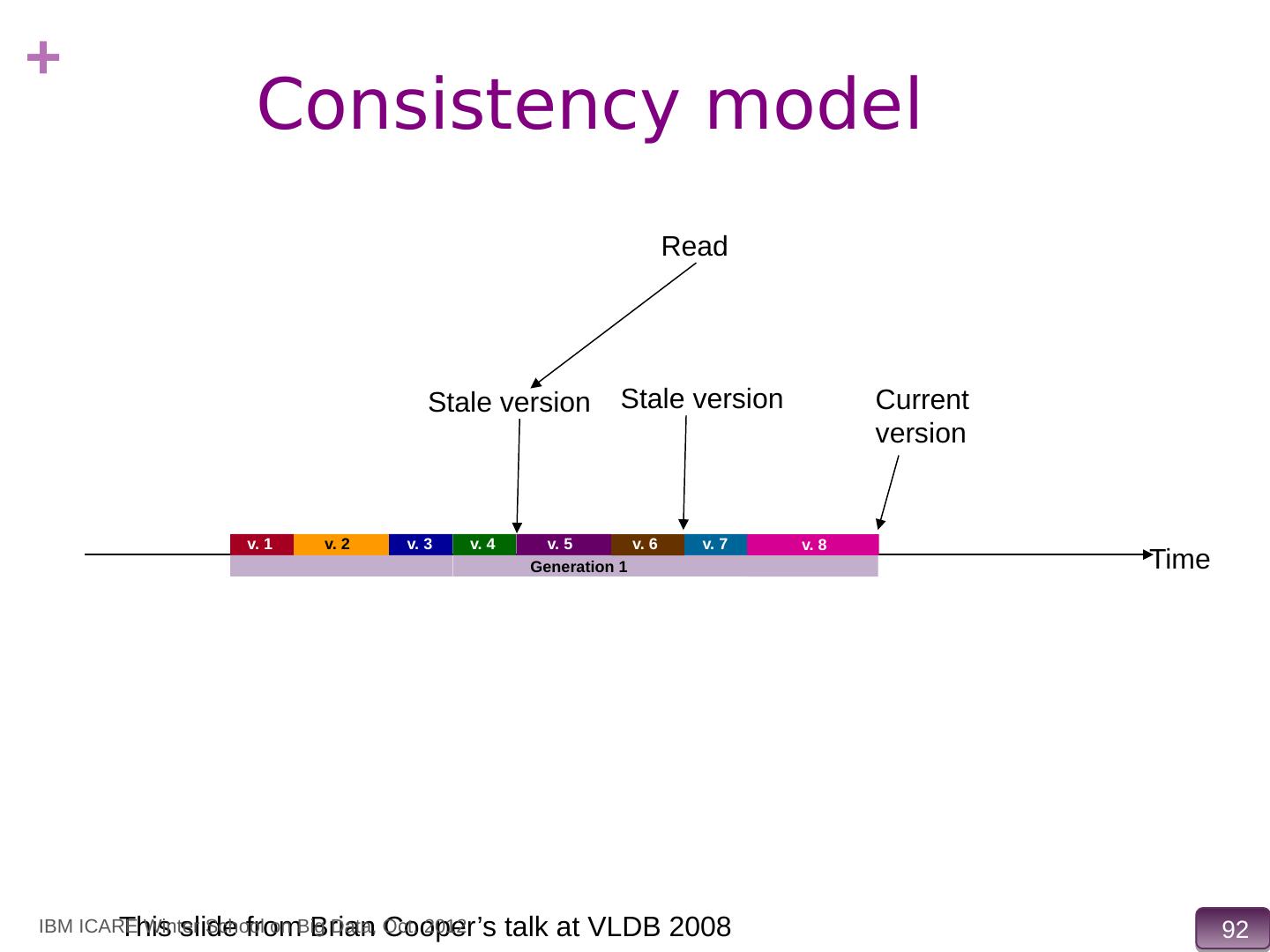
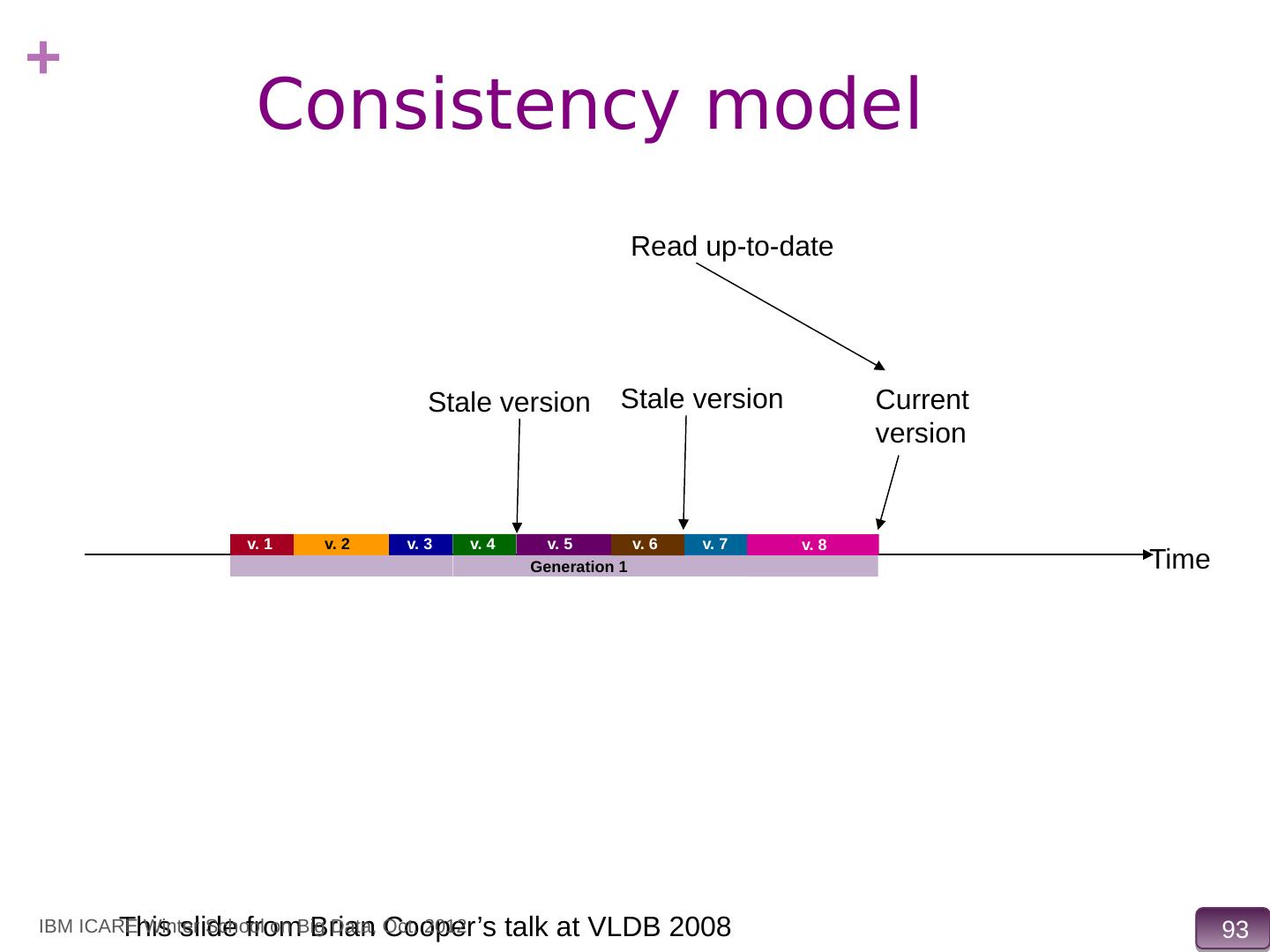
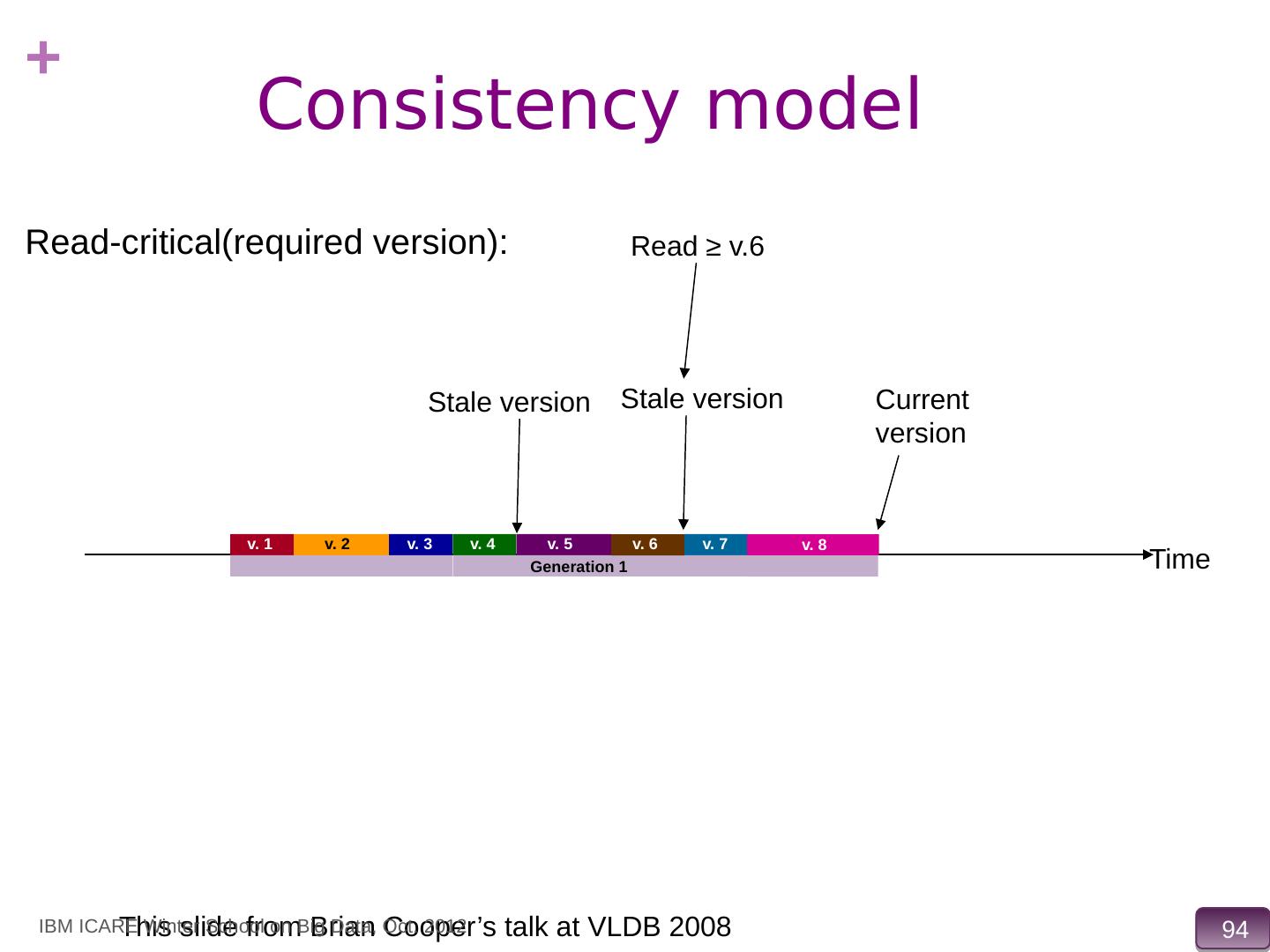
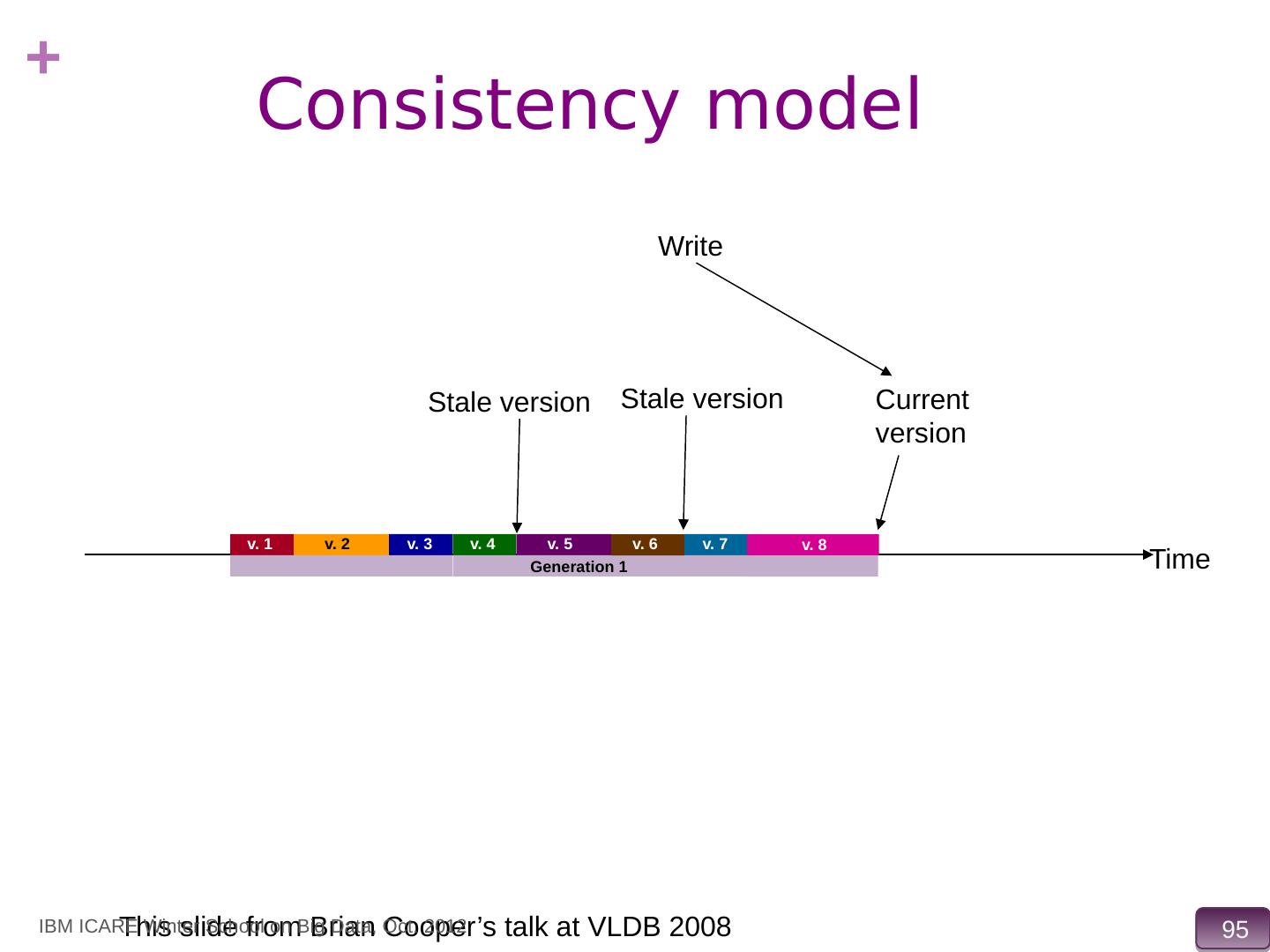
15 .Data Storage Systems vs. Databases Distributed data storage systems do not support many relational features No join operations (except within partition) No referential integrity constraints across partitions No ACID transactions (across nodes) No support for SQL or query optimization But usually do provide flexible schema and other features Structured objects e.g. using JSON M ultiple versions of data items, IBM ICARE Winter School on Big Data, Oct. 2012
16 .Querying Static Big Data Large data sets broken into multiple files Static append-only data E.g. new files added to dataset each day No updates to existing data Map-reduce framework for massively parallel querying Not the focus of this talk. We focus on: T ransactional data which is subject to updates Very large number of transactions Each of which reads/writes small amounts of data I.e. online transaction processing (OLTP) workloads IBM ICARE Winter School on Big Data, Oct. 2012
17 .Querying Static Big Data Large data sets broken into multiple files Static append-only data E.g. new files added to dataset each day No updates to existing data Map-reduce framework for massively parallel querying Not the focus of this talk. We focus on: T ransactional data which is subject to updates Very large number of transactions Each of which reads/writes small amounts of data I.e. online transaction processing (OLTP) workloads IBM ICARE Winter School on Big Data, Oct. 2012
18 .Background: Distributed Transactions Slides in this section are from Database System Concepts, 6 th Edition, by Silberschatz , Korth and Sudarshan, McGraw Hill, 2010 IBM ICARE Winter School on Big Data, Oct. 2012
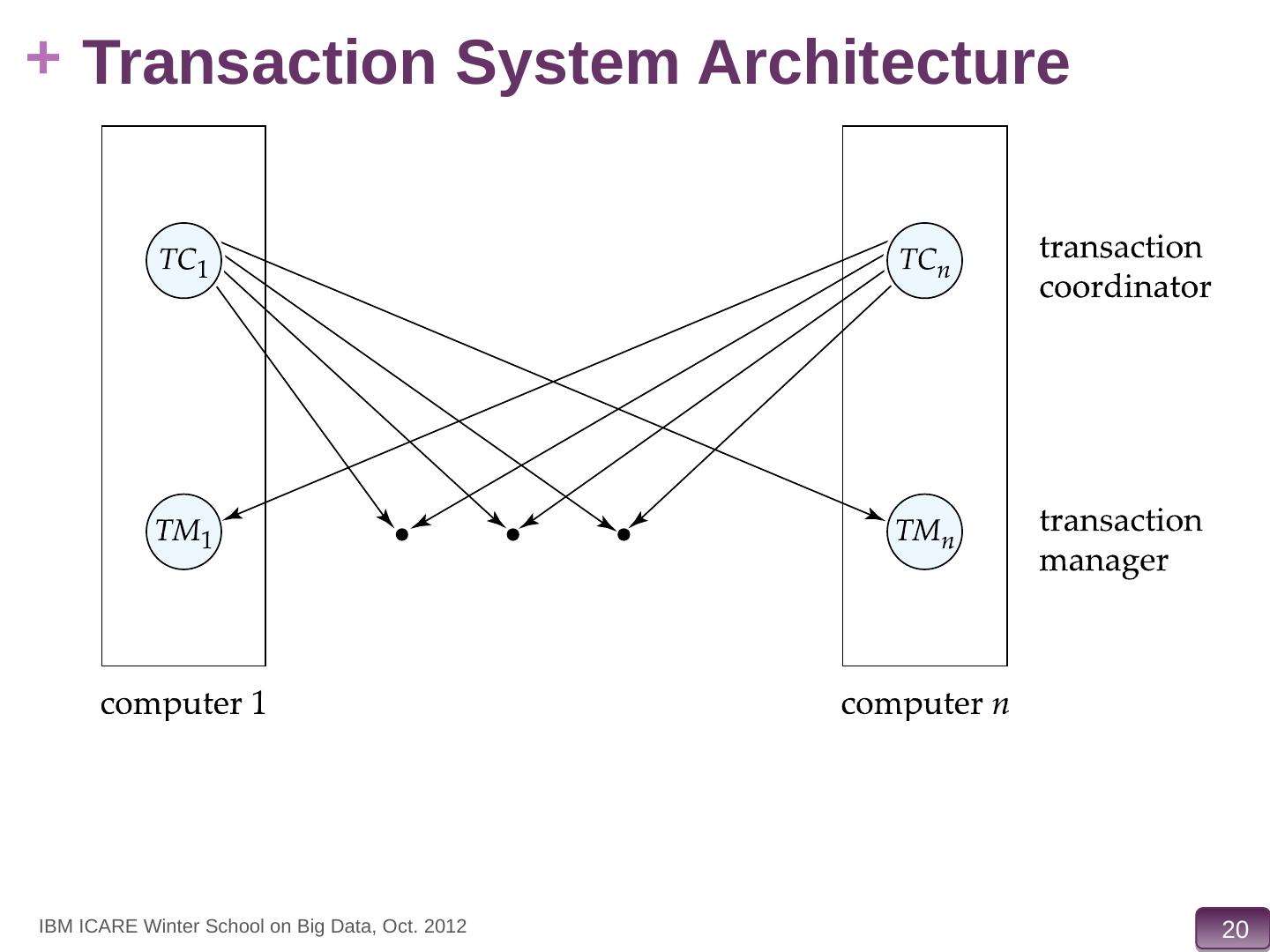
19 .Distributed Transactions Transaction may access data at several sites. Each site has a local transaction manager responsible for: Maintaining a log for recovery purposes Participating in coordinating the concurrent execution of the transactions executing at that site. Each site has a transaction coordinator , which is responsible for: Starting the execution of transactions that originate at the site. Distributing subtransactions at appropriate sites for execution. Coordinating the termination of each transaction that originates at the site, which may result in the transaction being committed at all sites or aborted at all sites. IBM ICARE Winter School on Big Data, Oct. 2012
20 .Transaction System Architecture IBM ICARE Winter School on Big Data, Oct. 2012
21 .System Failure Modes Failures unique to distributed systems: Failure of a site. Loss of massages Handled by network transmission control protocols such as TCP-IP Failure of a communication link Handled by network protocols, by routing messages via alternative links Network partition A network is said to be partitioned when it has been split into two or more subsystems that lack any connection between them Note: a subsystem may consist of a single node Network partitioning and site failures are generally indistinguishable. IBM ICARE Winter School on Big Data, Oct. 2012
22 .Commit Protocols Commit protocols are used to ensure atomicity across sites a transaction which executes at multiple sites must either be committed at all the sites, or aborted at all the sites. not acceptable to have a transaction committed at one site and aborted at another The two-phase commit (2PC) protocol is widely used The three-phase commit (3PC) protocol is more complicated and more expensive, but avoids some drawbacks of two-phase commit protocol . IBM ICARE Winter School on Big Data, Oct. 2012
23 .Two Phase Commit Protocol (2PC) Execution of the protocol is initiated by the coordinator after the last step of the transaction has been reached. The protocol involves all the local sites at which the transaction executed Let T be a transaction initiated at site S i , and let the transaction coordinator at S i be C i IBM ICARE Winter School on Big Data, Oct. 2012
24 .Phase 1: Obtaining a Decision Coordinator asks all participants to prepare to commit transaction T i . C i adds the records < prepare T > to the log and forces log to stable storage sends prepare T messages to all sites at which T executed Upon receiving message, transaction manager at site determines if it can commit the transaction if not, add a record < no T > to the log and send abort T message to C i if the transaction can be committed, then: add the record < ready T > to the log force all records for T to stable storage send ready T message to C i IBM ICARE Winter School on Big Data, Oct. 2012
25 .Phase 2: Recording the Decision T can be committed of C i received a ready T message from all the participating sites: otherwise T must be aborted. Coordinator adds a decision record, < commit T > or <a bort T >, to the log and forces record onto stable storage. Once the record stable storage it is irrevocable (even if failures occur) Coordinator sends a message to each participant informing it of the decision (commit or abort) Participants take appropriate action locally. IBM ICARE Winter School on Big Data, Oct. 2012
26 .Three Phase Commit (3PC) Blocking problem in 2PC: if coordinator is disconnected from participant, participant which had sent a ready message may be in a blocked state Cannot figure out whether to commit or abort Partial solution: Three phase commit Phase 1: Obtaining Preliminary Decision: Identical to 2PC Phase 1. Every site is ready to commit if instructed to do so Phase 2 of 2PC is split into 2 phases, Phase 2 and Phase 3 of 3PC In phase 2 coordinator makes a decision as in 2PC (called the pre-commit decision ) and records it in multiple (at least K) sites In phase 3, coordinator sends commit/abort message to all participating sites Under 3PC, knowledge of pre-commit decision can be used to commit despite coordinator failure Avoids blocking problem as long as < K sites fail Drawbacks: higher overhead, and assumptions may not be satisfied in practice IBM ICARE Winter School on Big Data, Oct. 2012
27 .Distributed Transactions via Persistent Messaging Notion of a single transaction spanning multiple sites is inappropriate for many applications E.g. transaction crossing an organizational boundary Latency of waiting for commit from remote site Alternative models carry out transactions by sending messages Code to handle messages must be carefully designed to ensure atomicity and durability properties for updates Isolation cannot be guaranteed, in that intermediate stages are visible, but code must ensure no inconsistent states result due to concurrency Persistent messaging systems are systems that provide transactional properties to messages Messages are guaranteed to be delivered exactly once Will discuss implementation techniques later IBM ICARE Winter School on Big Data, Oct. 2012
28 .Persistent Messaging E xample : funds transfer between two banks Two phase commit would have the potential to block updates on the accounts involved in funds transfer Alternative solution: Debit money from source account and send a message to other site Site receives message and credits destination account Messaging has long been used for distributed transactions (even before computers were invented!) Atomicity issue once transaction sending a message is committed, message must guaranteed to be delivered Guarantee as long as destination site is up and reachable, code to handle undeliverable messages must also be available e.g. credit money back to source account. If sending transaction aborts, message must not be sent IBM ICARE Winter School on Big Data, Oct. 2012
29 .Error Conditions with Persistent Messaging Code to handle messages has to take care of variety of failure situations (even assuming guaranteed message delivery) E.g. if destination account does not exist, failure message must be sent back to source site When failure message is received from destination site, or destination site itself does not exist, money must be deposited back in source account Problem if source account has been closed get humans to take care of problem User code executing transaction processing using 2PC does not have to deal with such failures There are many situations where extra effort of error handling is worth the benefit of absence of blocking E.g. pretty much all transactions across organizations IBM ICARE Winter School on Big Data, Oct. 2012
相关推荐
3秒后跳转登录页面
去登陆

