



































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
IntelAIDC18 Workshop
2018年Intel AI DevCon的资料分享。
展开查看详情
1 .
2 .Inference with Intel: hands on workshop + fireside chat Yi Ge Monique Jones Technical Consulting Engineer Technical Consulting Engineer
3 .3
4 .Emergency Response Financial services Machine Vision Cities/transportation Autonomous Vehicles Responsive Retail Manufacturing Public sector 4
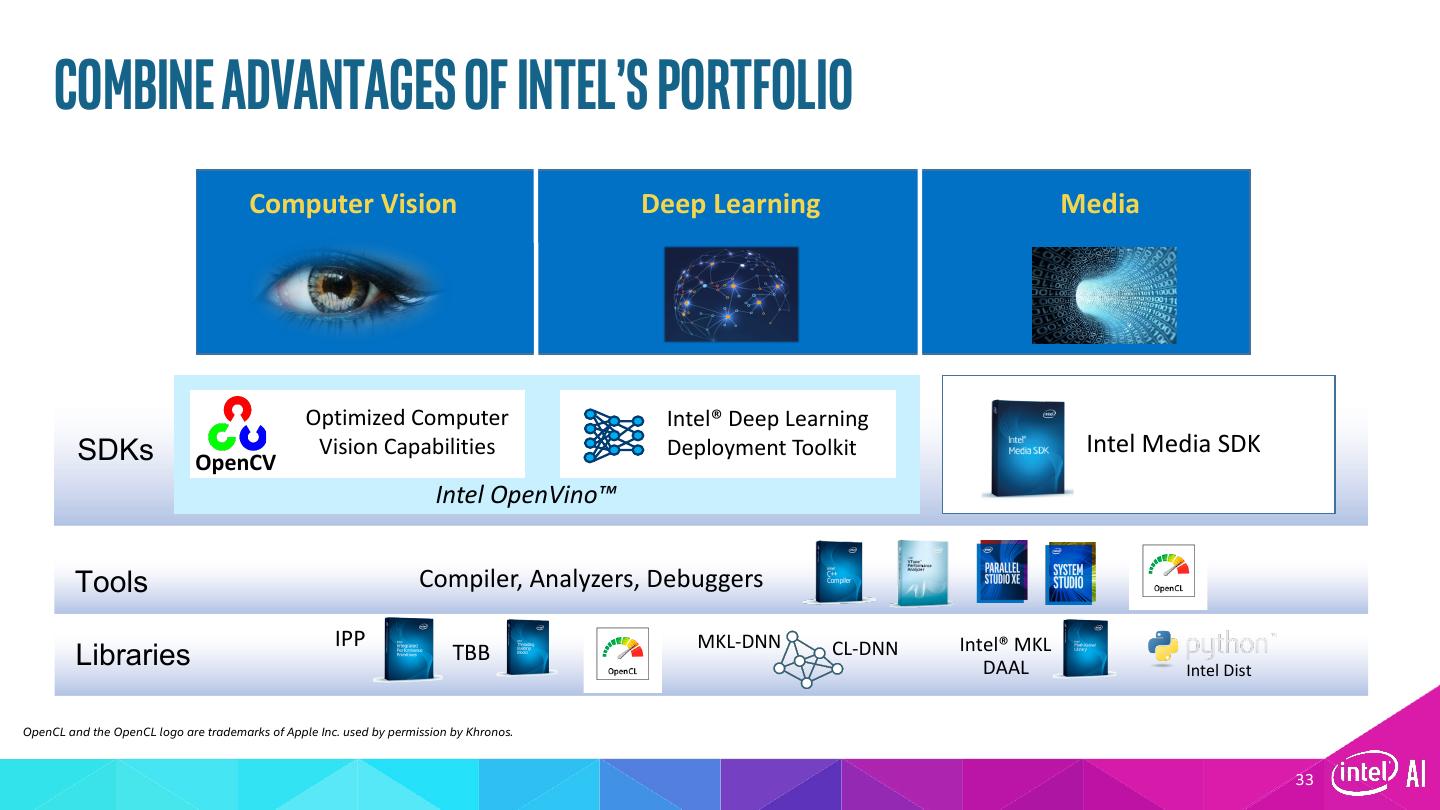
5 .Intel® IoT Video Portfolio Smart Cameras Video Gateways / NVRs Data center / Cloud FPGA solutions from intel CV Intel® Media SDK, Intel OpenvinoTM TOOLKIT Industry’s Broadest Media, Computer Vision, and Deep Learning Portfolio 5
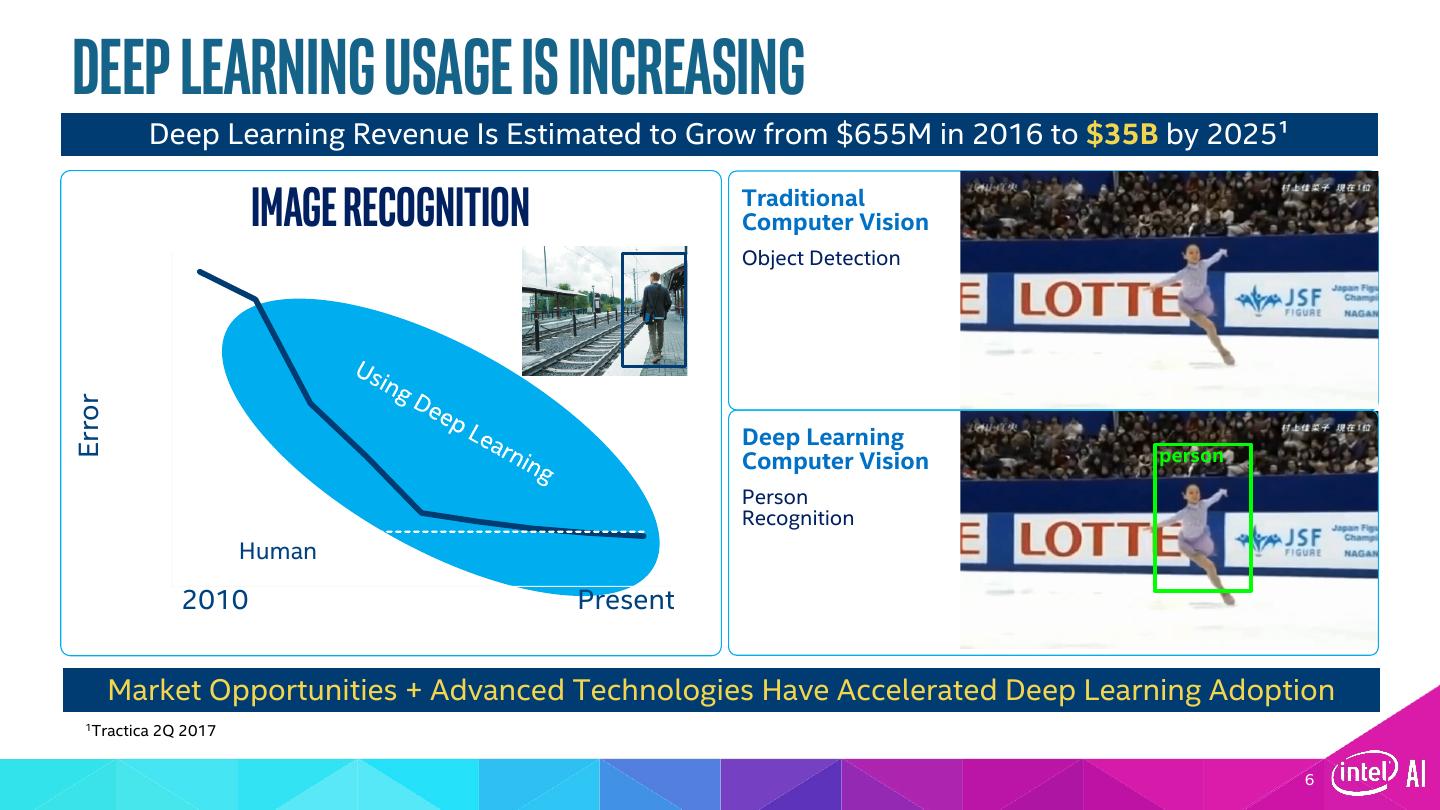
6 .Deep Learning Usage is Increasing Deep Learning Revenue Is Estimated to Grow from $655M in 2016 to $35B by 2025¹ Image Recognition Traditional Computer Vision 30% Object Detection 23% Error 15% Deep Learning Computer Vision person 8% Person Recognition Human 0% 2010 Present Market Opportunities + Advanced Technologies Have Accelerated Deep Learning Adoption 1Tractica 2Q 2017 6
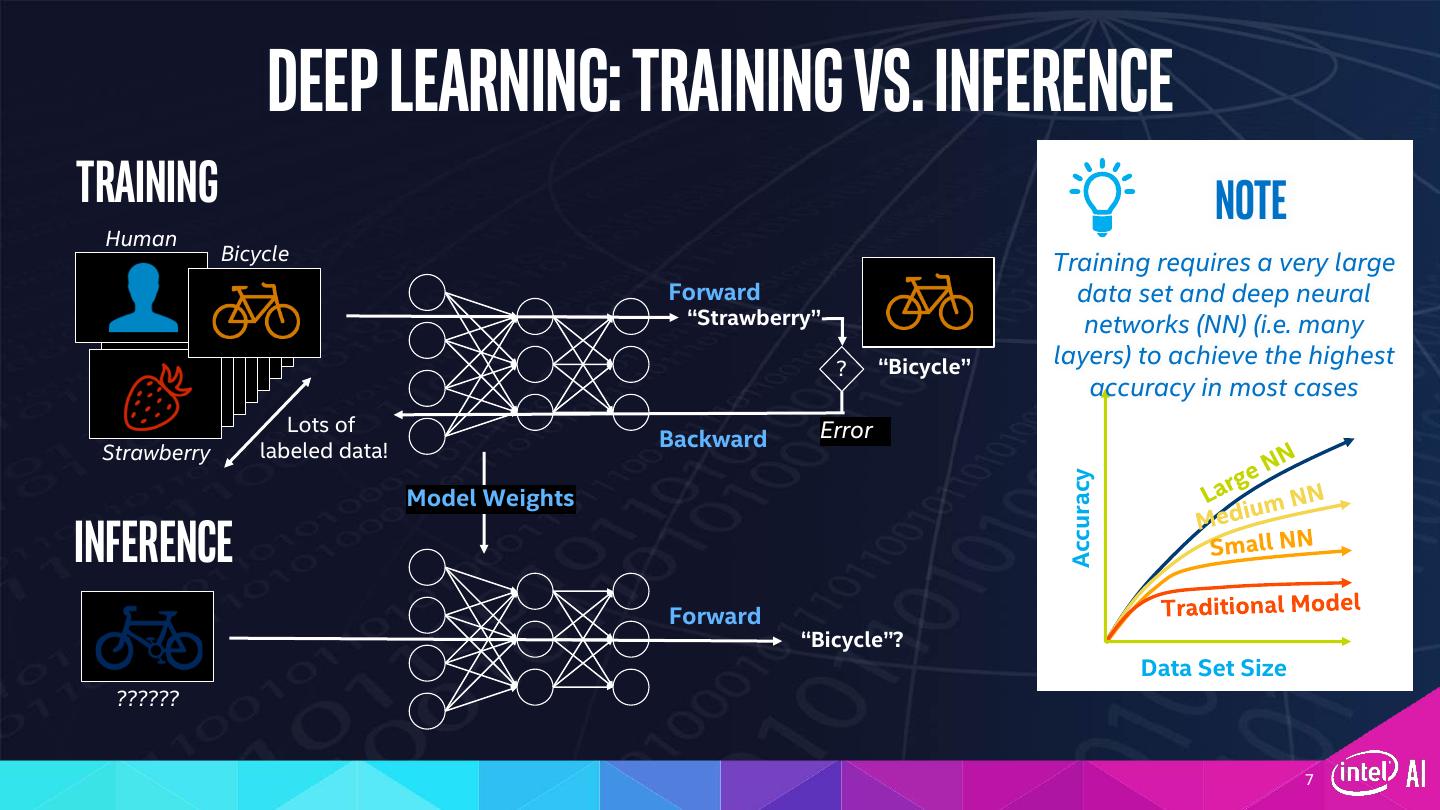
7 . Deep learning: Training vs. inference Training Note Human Bicycle Training requires a very large Forward data set and deep neural “Strawberry” networks (NN) (i.e. many ? “Bicycle” layers) to achieve the highest accuracy in most cases Lots of Error labeled data! Backward Strawberry Accuracy Model Weights Inference Forward “Bicycle”? Data Set Size ?????? 7
8 .Artificial Intelligence Development Cycle Dataset Aquisition and Create Models Organization Today’s focus: Integrate Trained Adjust Models to Meet Models with Performance and Accuracy Application Code Objectives Intel® Deep Learning Deployment Toolkit: Deploy Optimized Inference from Edge to Cloud 8
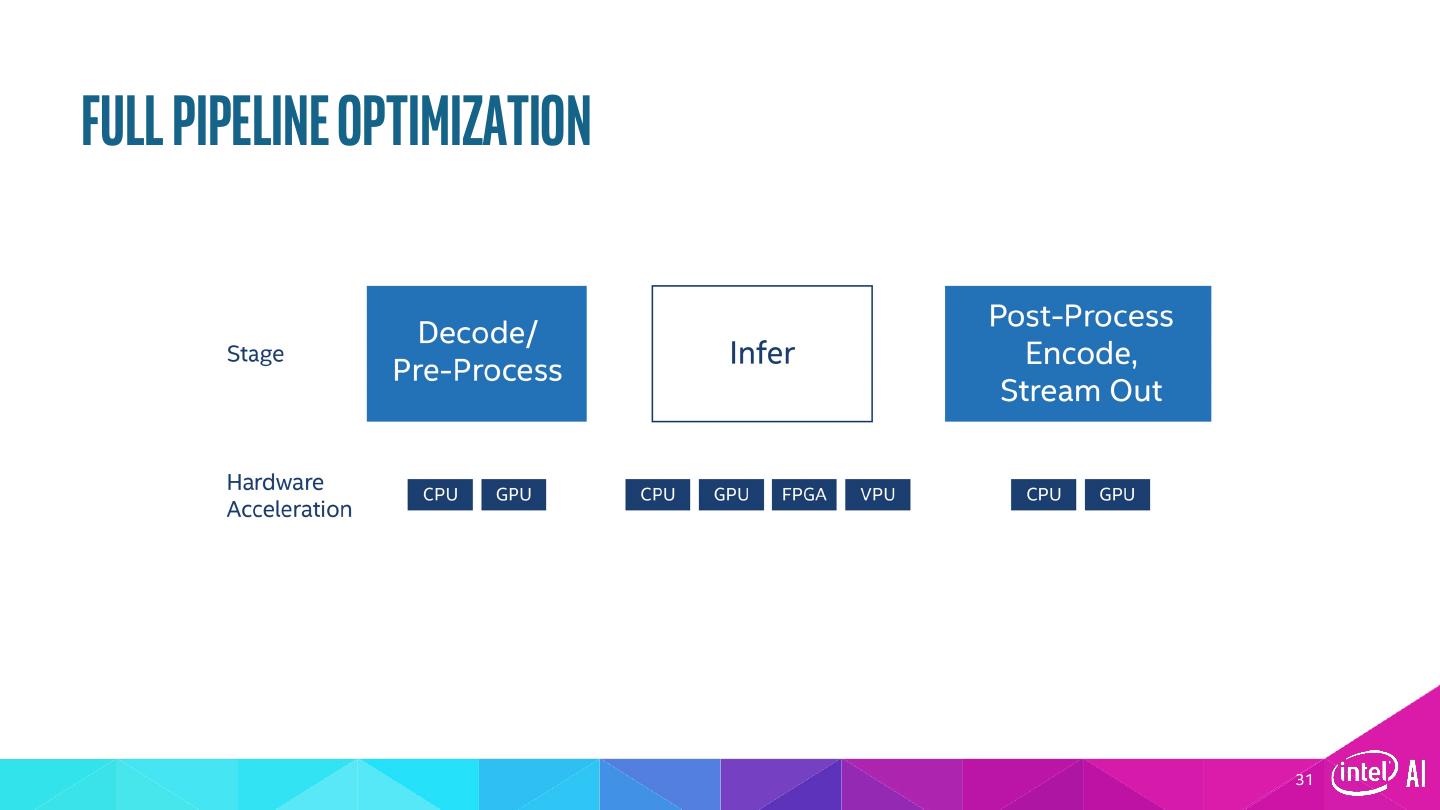
9 .What’s inside Intel® Deep Learning Deployment Toolkit Component tools Traditional Computer Vision – All SDK versions Optimized Computer Vision Libraries Model Optimizer OpenCV* OpenVX* Convert & Optimize Increase Processor Graphics Performance – Linux* Only Trained Intel® Media SDK OpenCL™ Models IR (Open-Source Intel® Integrated Graphics Version) Drivers & Runtimes Inference Engine Linux for FPGA only Optimized Inference FPGA RunTime Environment (RTE) Bitstreams (from Intel FPGA SDK for OpenCL™) GPU = CPU with Intel® Integrated Graphics Processing Unit CPU GPU FPGA VPU VPU = Movidius™ Vision Processing Unit OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos 9
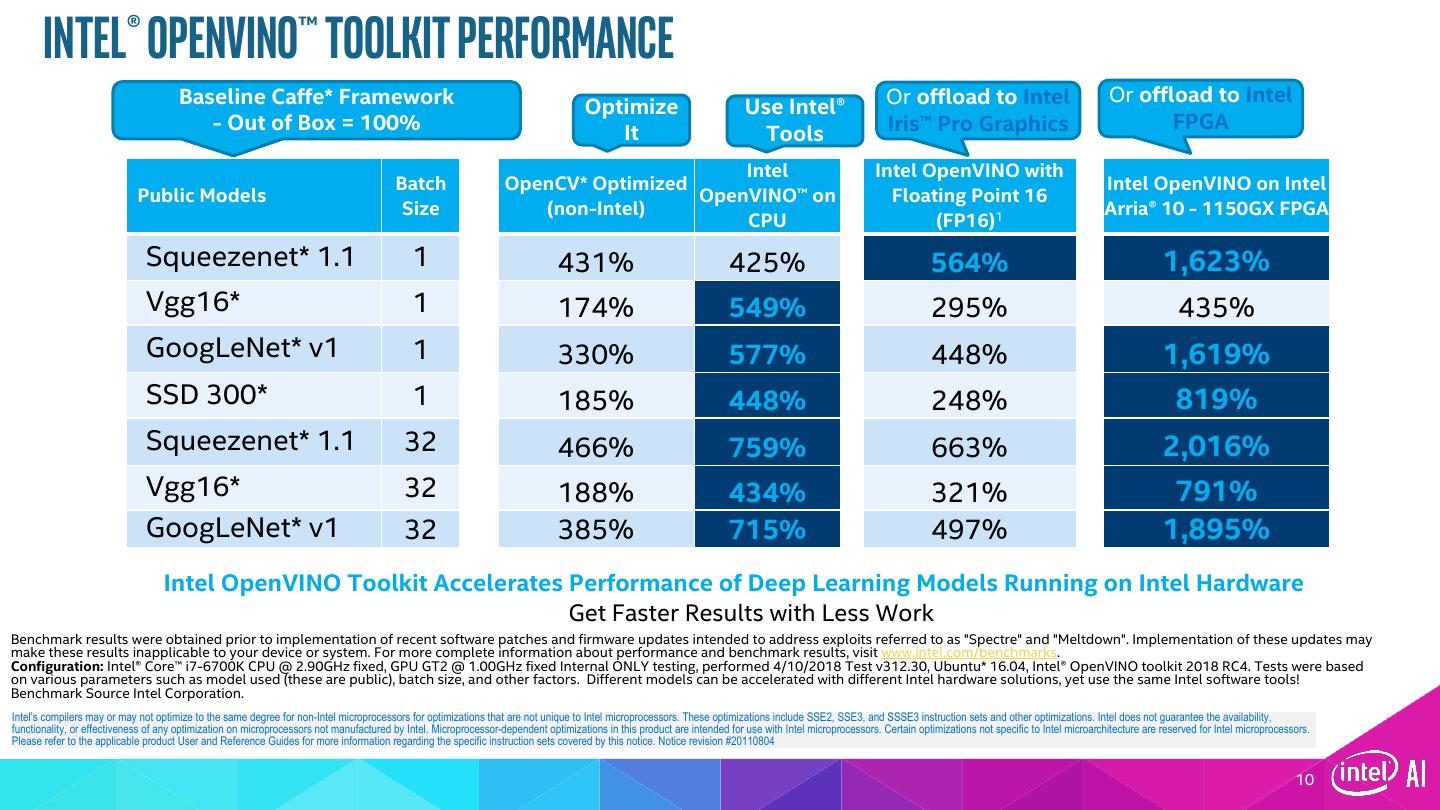
10 . Intel® openvino™ toolkit Performance Baseline Caffe* Framework Or offload to Intel Or offload to Intel Optimize Use Intel® - Out of Box = 100% Iris™ Pro Graphics FPGA It Tools Intel Intel OpenVINO with Batch OpenCV* Optimized Intel OpenVINO on Intel Public Models OpenVINO™ on Floating Point 16 Size (non-Intel) Arria® 10 - 1150GX FPGA CPU (FP16)1 Squeezenet* 1.1 1 431% 425% 564% 1,623% Vgg16* 1 174% 549% 295% 435% GoogLeNet* v1 1 330% 577% 448% 1,619% SSD 300* 1 185% 448% 248% 819% Squeezenet* 1.1 32 466% 759% 663% 2,016% Vgg16* 32 188% 434% 321% 791% GoogLeNet* v1 32 385% 715% 497% 1,895% Intel OpenVINO Toolkit Accelerates Performance of Deep Learning Models Running on Intel Hardware 1Accuracy changes can occur w/ FP16 à Get Faster Results with Less Work Benchmark results were obtained prior to implementation of recent software patches and firmware updates intended to address exploits referred to as "Spectre" and "Meltdown". Implementation of these updates may make these results inapplicable to your device or system. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Configuration: Intel® Core™ i7-6700K CPU @ 2.90GHz fixed, GPU GT2 @ 1.00GHz fixed Internal ONLY testing, performed 4/10/2018 Test v312.30, Ubuntu* 16.04, Intel® OpenVINO toolkit 2018 RC4. Tests were based on various parameters such as model used (these are public), batch size, and other factors. Different models can be accelerated with different Intel hardware solutions, yet use the same Intel software tools! Benchmark Source Intel Corporation. Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #20110804 10
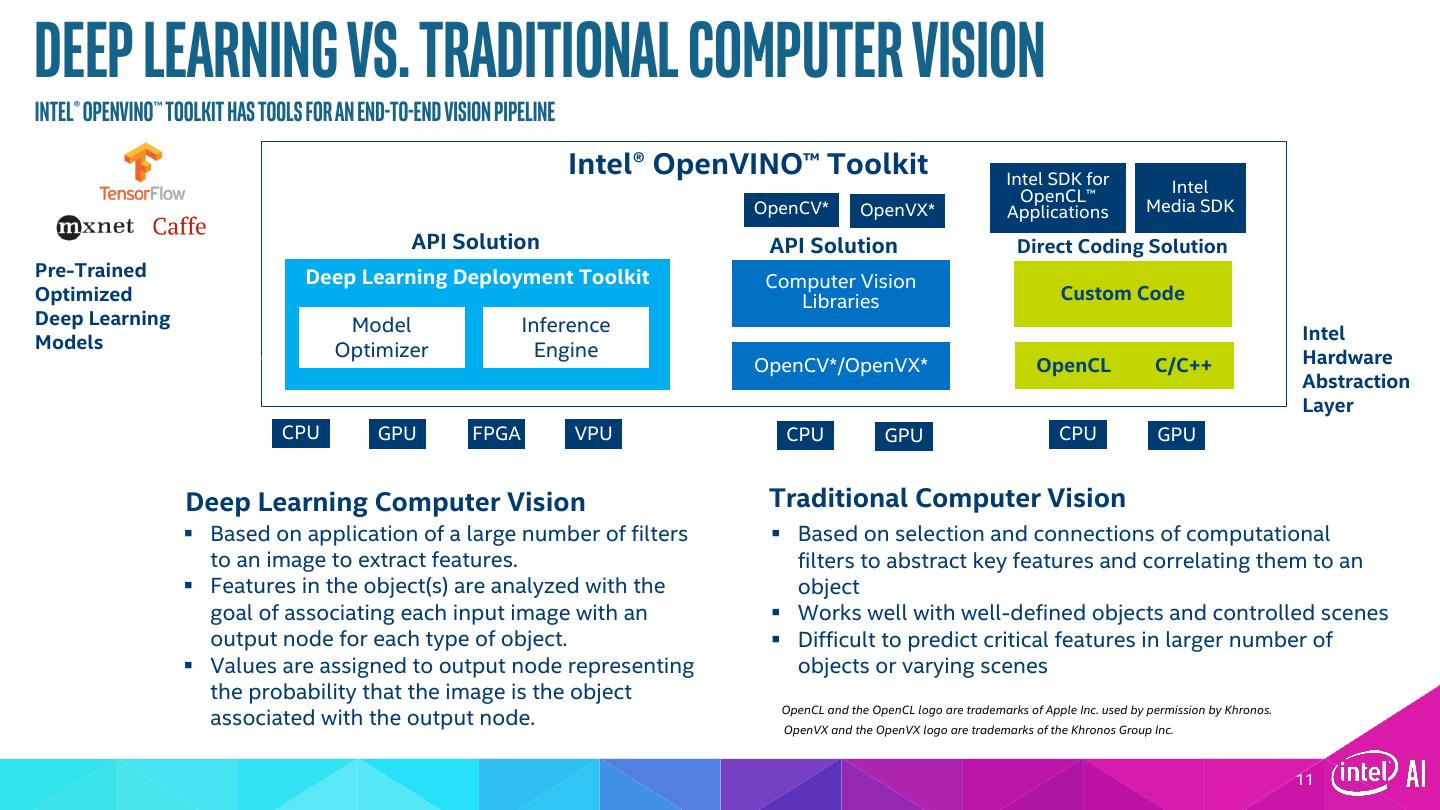
11 .Deep Learning vs. Traditional Computer Vision Intel® Openvino™ toolkit has tools for an end-to-end vision pipeline Intel® OpenVINO™ Toolkit Intel SDK for Intel OpenCL™ OpenCV* OpenVX* Applications Media SDK API Solution API Solution Direct Coding Solution Pre-Trained Deep Learning Deployment Toolkit Computer Vision Optimized Libraries Custom Code Deep Learning Model Inference Models Intel Optimizer Engine Hardware OpenCV*/OpenVX* OpenCL C/C++ Abstraction Layer CPU GPU FPGA VPU CPU GPU CPU GPU Deep Learning Computer Vision Traditional Computer Vision § Based on application of a large number of filters § Based on selection and connections of computational to an image to extract features. filters to abstract key features and correlating them to an § Features in the object(s) are analyzed with the object goal of associating each input image with an § Works well with well-defined objects and controlled scenes output node for each type of object. § Difficult to predict critical features in larger number of § Values are assigned to output node representing objects or varying scenes the probability that the image is the object OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. associated with the output node. OpenVX and the OpenVX logo are trademarks of the Khronos Group Inc. 11
12 .12
13 . Train Prepare Inference Optimize/ Extend Optimizer Hetero Train a deep learning Model Optimizer Inference-Engine Inference-Engine Inference-Engine model (out of our • Converting a lightweight Supports multiple devices Supports scope) • Optimizing application for heterogeneous flows extensibility and • Preparing to programming allows custom Currently supporting: inference interface (API) Device-level optimization kernels for various • Caffe* to use in your devices • MXNet* (device agnostic, application for • TensorFlow* generic optimization) inference OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. 13
14 .Model Optimizer • Convert models from various frameworks (i.e. Caffe*, TensorFlow*, MXNet*) • Converts to a unified model (i.e. intermediate representation (IR), later n- graph) • Optimizes topologies (i.e. node merging, batch normalization elimination, performing horizontal fusion) • Folds constants paths in graph 14
15 .Improve Performance with Model Optimizer Intel® Deep Learning Deployment Toolkit supports a wide range of deep learning topologies: •Classification models: • AlexNet; • VGG-16, VGG-19; § Easy to use, Python*-based workflow does not require rebuilding • SqueezeNet v1.0/v1.1; frameworks. • ResNet-50/101/152; • Inception v1/v2/v3/v4; § Import Models from various frameworks (Caffe*, TensorFlow*, MXNet*, • CaffeNet; more are planned…) • MobileNet; § More than 100 models for Caffe, TensorFlow, and MXNet validated. •Object detection models: • SSD300/500-VGG16; § IR files for models using standard layers or user-provided custom layers do • Faster-RCNN; not require Caffe • SSD-MobileNet v1, SSD-Inception v2 § Fallback to original framework is possible in cases of unsupported layers, • Yolo Full v1/Tiny v1 but requires original framework • ResidiualNet-50/101/152, v1/v2 Support model formats • DenseNet 121/161/169/201 •Face detection models: • VGG Face; •Semantic segmentation models: • FCN8; 15
16 .Lab: Optimize a deep-learning model using the Model Optimizer (MO) 16
17 .17
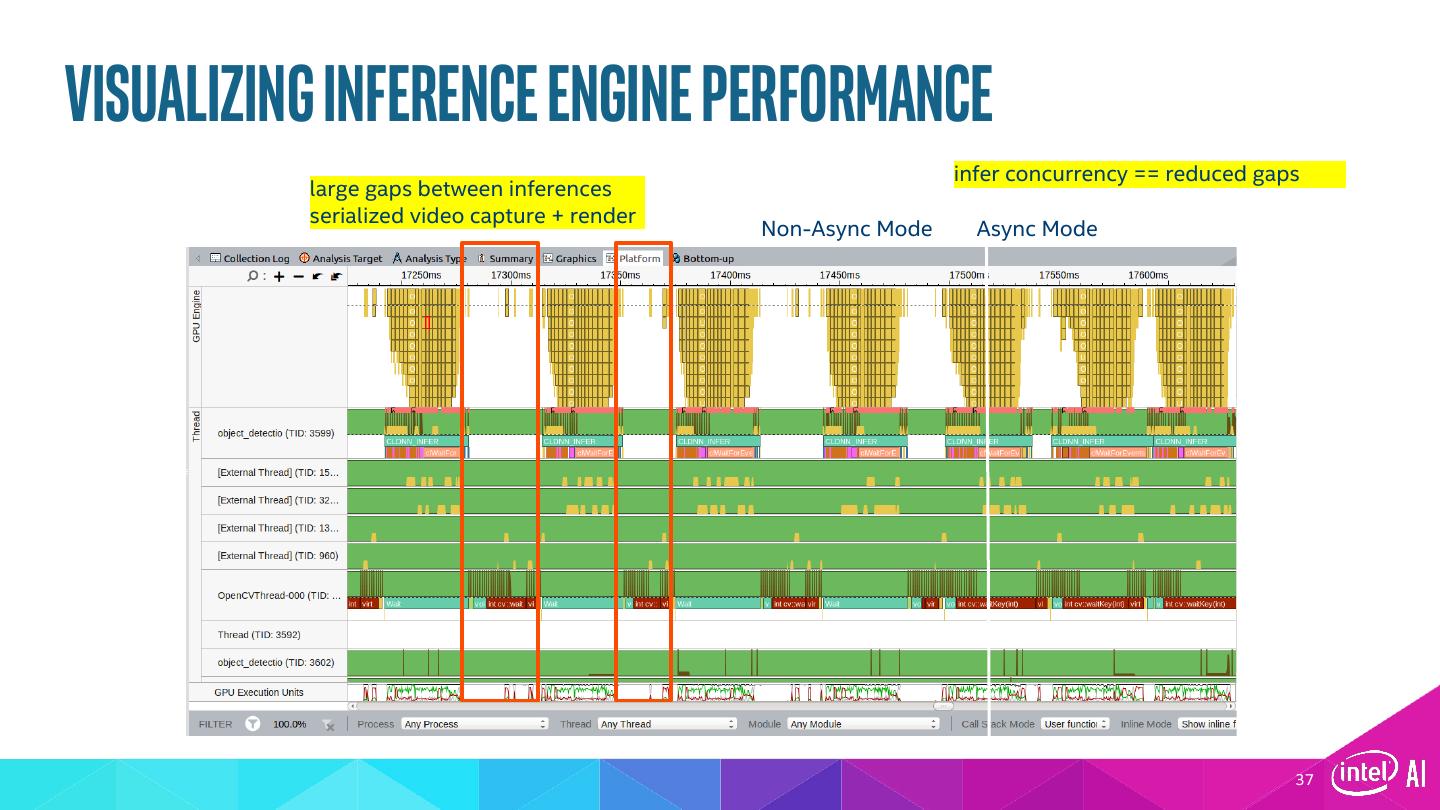
18 .Inference Engine § Simple and unified API for Inference across all Intel® architecture § Optimized inference on large Intel architecture hardware targets (CPU/GEN/FPGA) § Heterogeneity support allows execution of layers across hardware types § Asynchronous execution improves performance § Futureproof/scale your development for future Intel processors OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. 18
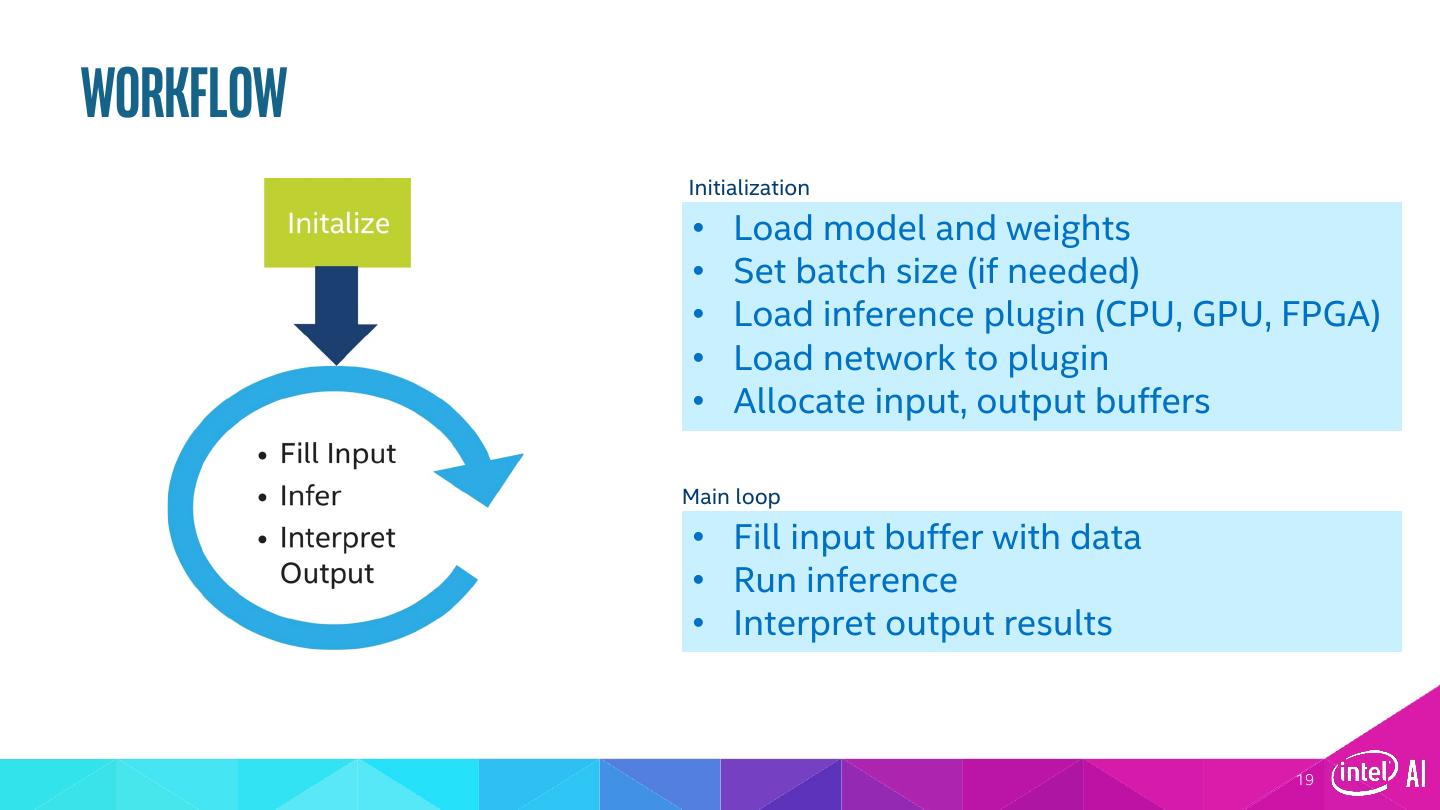
19 .Workflow Initialization • Load model and weights • Set batch size (if needed) • Load inference plugin (CPU, GPU, FPGA) • Load network to plugin • Allocate input, output buffers Main loop • Fill input buffer with data • Run inference • Interpret output results 19
20 .Load model 20
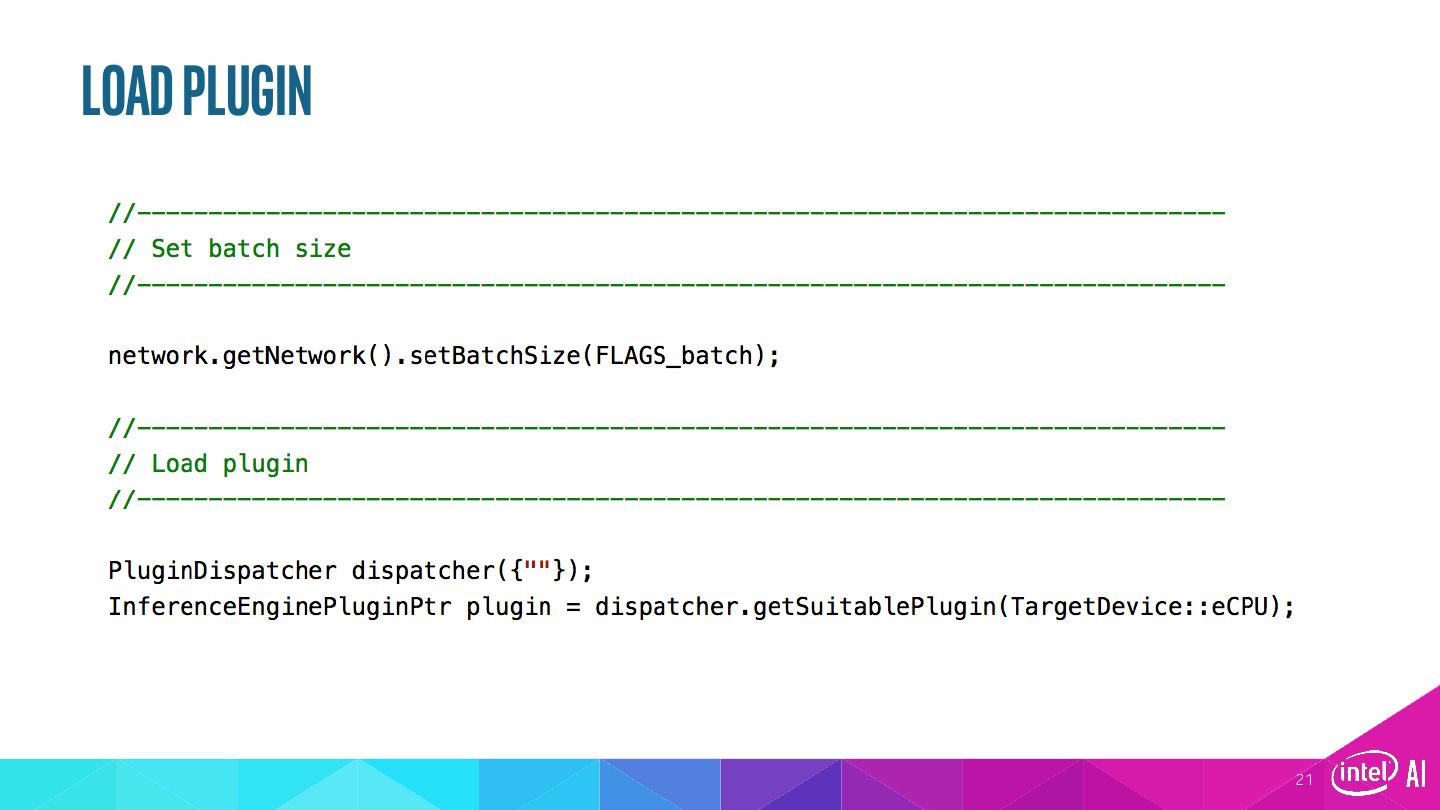
21 .Load plugin 21
22 .set up Input blobs 22
23 .set up Output blobs 23
24 .Pre-processing • Most image formats are interleaved (RGB, BGR, BGRA, etc.) • Models usually expect RGB planar format: • R-plane • G-plane • B-plane Intervealed Planar 24
25 .Prepare input data 25
26 .Infer 26
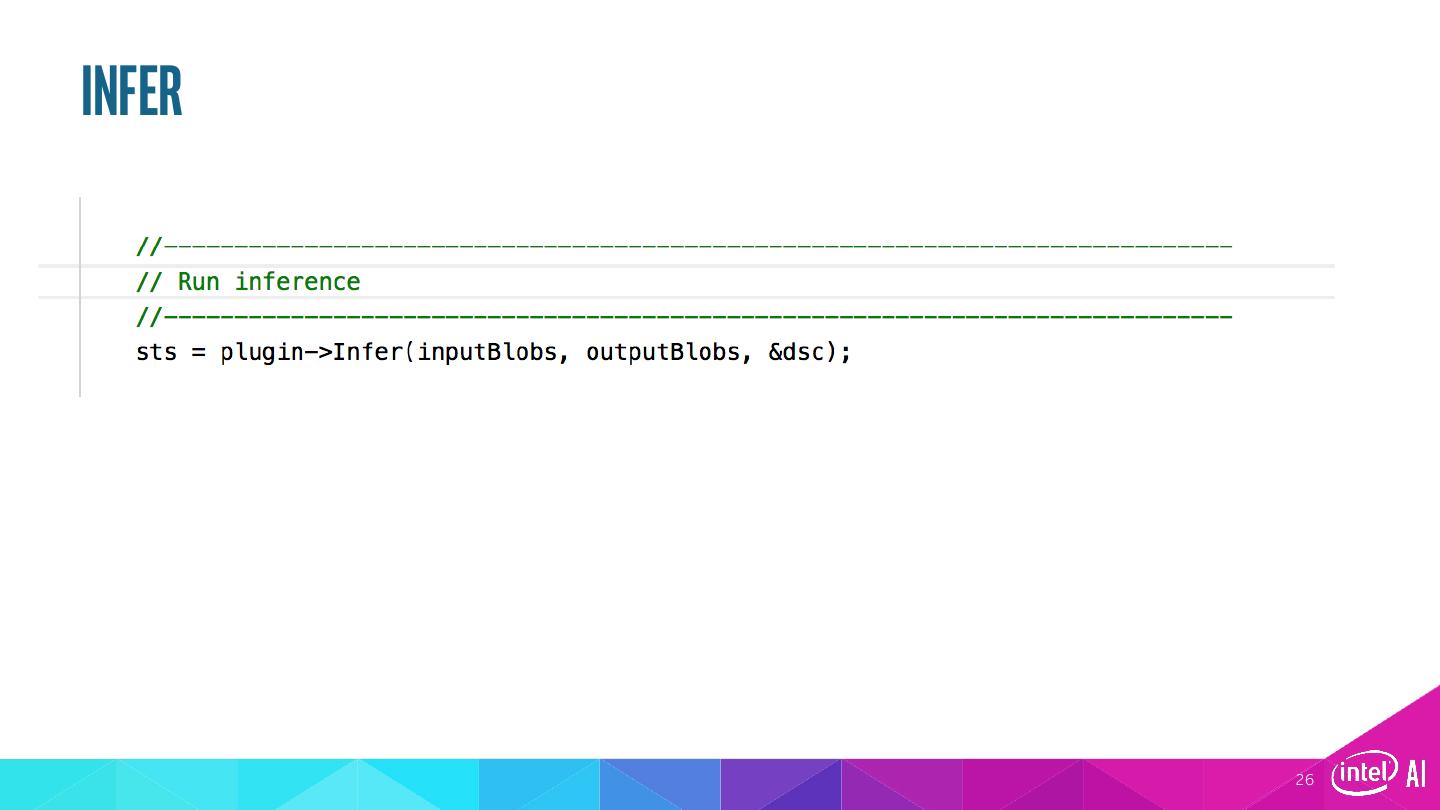
27 .Post-processing Developer responsible to parse inference output. Many output formats. Some examples: • Simple classification (alexnet): an array of float confidence scores, # of elements=# of classes in the model • SSD: many “boxes” with a confidence score, label #, xmin,ymin, xmax,ymax 27
28 .Automatic Fallback with hetero plugin $ object_detection_sample_ssd -d HETERO:GPU,CPU -l lib/libicv_extension.so -m ssd.xml -i snake.bmp • The “priorities” define search order – Keeps all layers that can be executed on the device (FPGA) – Carefully respecting the topological and other limitations – Then follows priorities when searching (e.g. CPU) 28
29 .Lab: Build and run an object detection application 29
相关推荐
3秒后跳转登录页面
去登陆

