




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spanner & Aurora
Google走过了从Big Table(2006)-分布式KV存储系统,MegaStore(2011)-分布式的事务处理系统和Spanner(2012)分布式关系数据库系统。这些系统设计和论文深远的影响了很多当代非常流行的数据库系统架构,本文介绍了其中的基本概念,算是对Spanner系统论文导读。此外还介绍了亚马逊的Aurora系统,一个诞生于云端,几乎线性水平扩展但是又兼容MySQL的关系数据库系统。当然这些系统并不完美,不能解决我们在大数据时代的所有问题,了解并掌握它们的适用场景很重要,文末对这两个系统的探讨和提问,也值得大家去揣摩比较。
展开查看详情
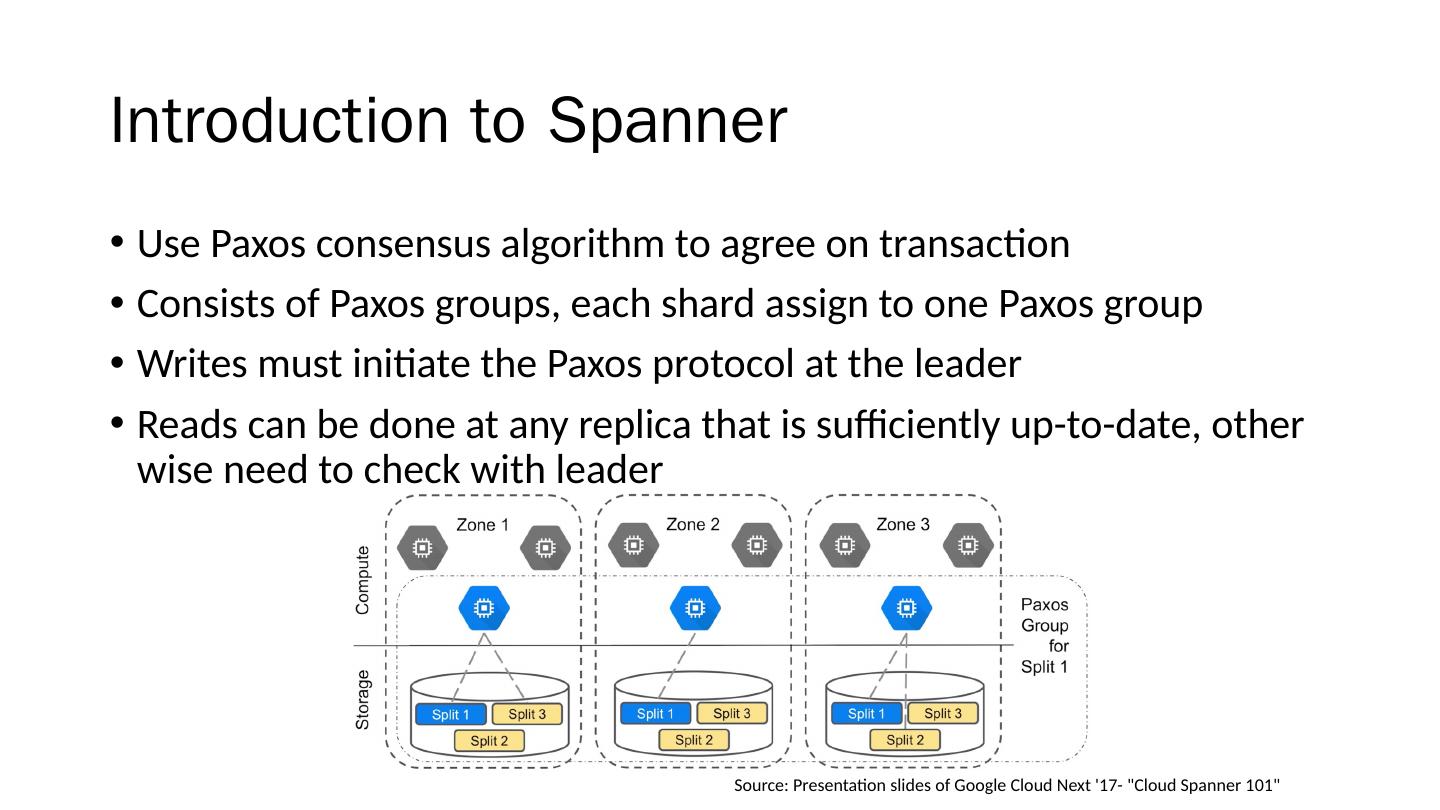
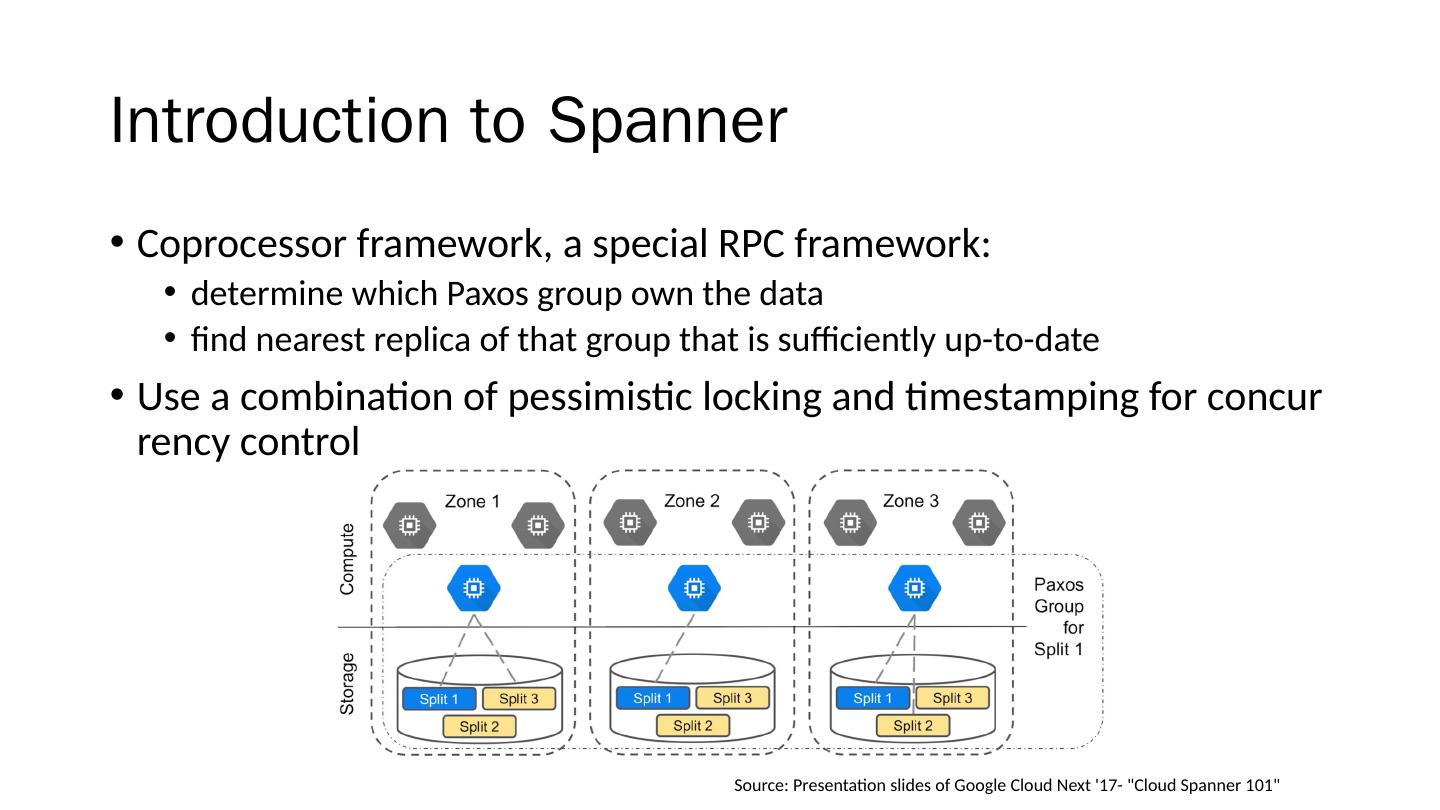
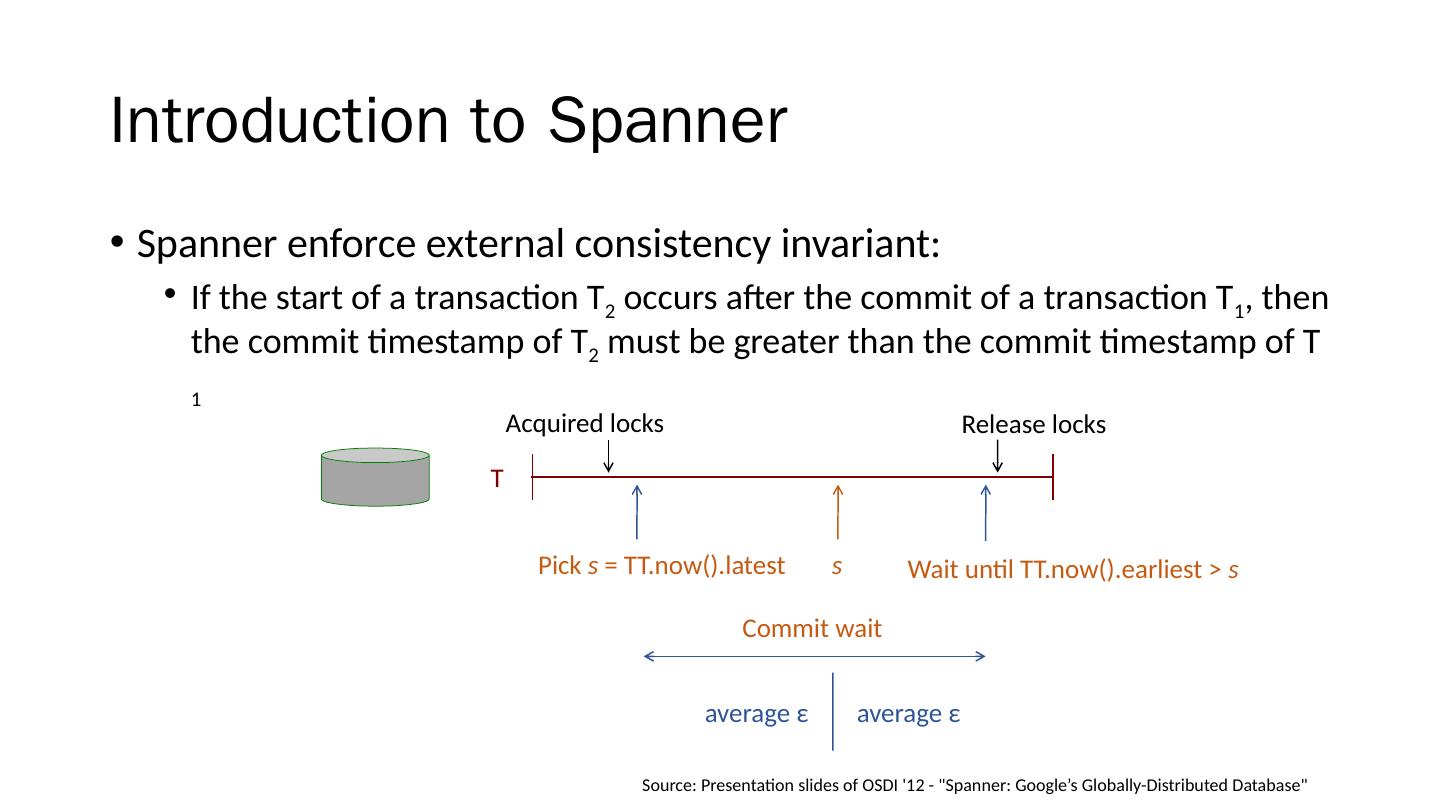
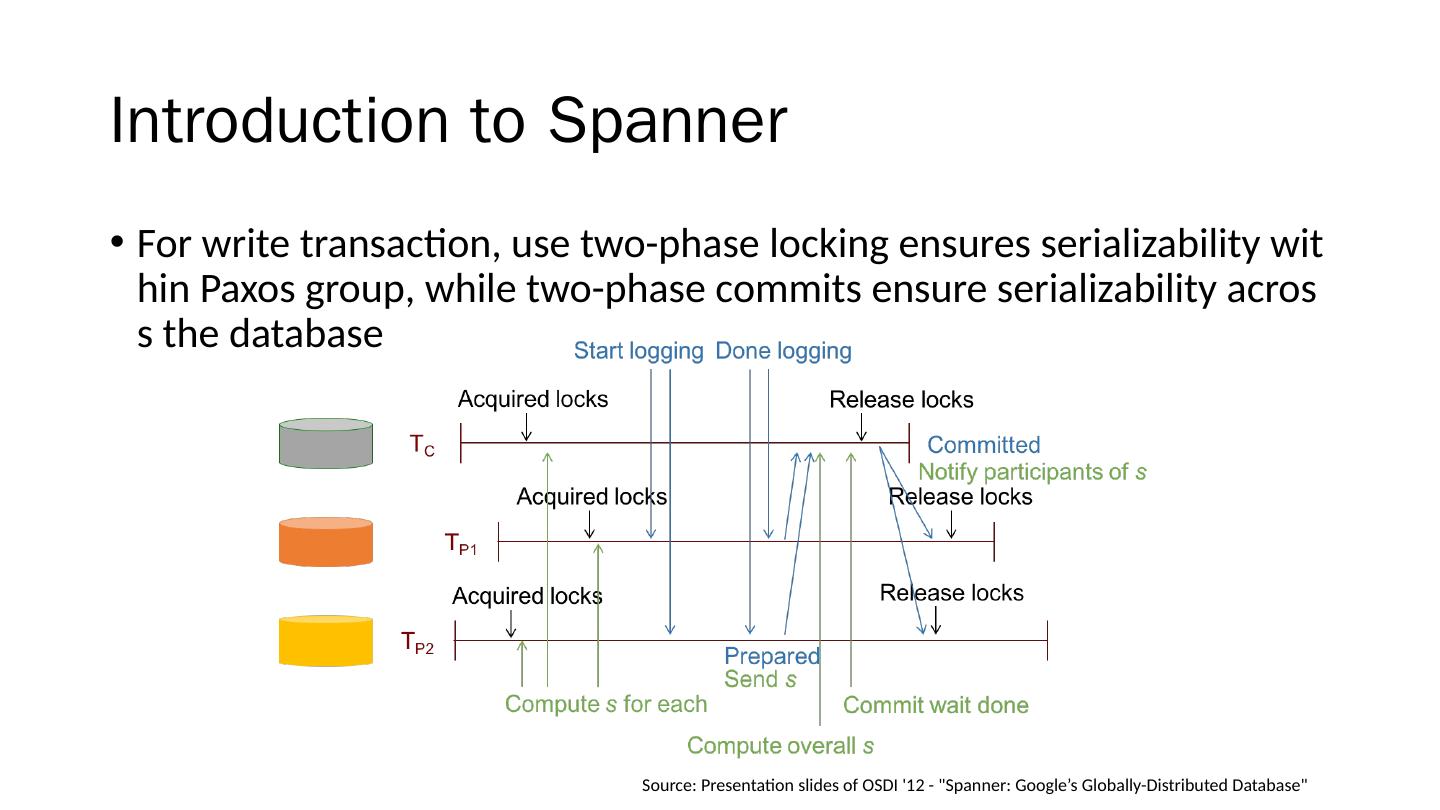
1 .Spanner : Becoming a SQL System David F. Bacon et al. Google, Inc. Presenter: Che-Lin Huang
2 .Overview Motivation Introduction to Spanner Distributed Query Query Range Extraction Query Restart Common SQL Dialect Thoughts Takeaway
3 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
4 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
5 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
6 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
7 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
8 .Motivation Bigtable (2006) Key-value storage system Difficult to build online transaction processing application without strong schema, cross-row transaction, consistent replication and a powerful query language Megastore (2011) Transaction processing system build on top of Bigtable Lack many relational database features such as a robust query language Spanner (2012) D istributed data storage not yet support SQL query interface until 2017
9 .Introduction to Spanner Parent-child relationship between tables: Child table can be co-located and interleave with parent table Source : https:// cloud.google.com /spanner/docs/schema-and-data-model Schema example defines Albums as a child of Singers Physical layout of rows of Singers and its child table Albums
10 .Distributed Query - Compilation Query compiler uses traditional approach of building relational algebra operator tree and optimizing it using equivalent rewrite Distributed union: ship subquery to shards and concatenate results Partitionability for a relational operation requires: For the aggregate expression Join between same prefix of primary key are pushed below Distributed Union
11 .Distributed Query - Query Plan Source: Spanner: Becoming a SQL System, David F. Bacon et al, SIGMOD 2017 Distributed query plan for the following SQL query
12 .Distributed Query - Execution Runtime analysis to extract a set of shard key range Send subquery to minimal relevant shards If key range cover whole table, send subquery to servers that hosting multiple shards of target table Dispatch subqueries in parallel to reduce latency Parallelized between subshard for large shards Detect if target shards are host locally to avoid making remote call
13 .Distributed Query - Join Naïve implementation of apply-style joins is expensive: Cross-machine call per row Use batched apply join to minimize cross-machine call Distributed Apply performs shard pruning using following steps: Extract sharding key range using column values from each row Merge sharding key range for all rows Compute minimal set of shards to send the batch Construct minimal batch for each shard Name NetID John clhuang1 Jerry clhuang2 Jack clhuang3 Joey clhuang4 NetID Course clhuang1 CS 525 clhuang2 CS 425 NetID Course clhuang3 CS 325 clhuang4 CS 225 Student table Enroll table Example SQL join query involves student and enroll table: SELECT * FROM Student s JOIN Enroll e on s.NetID = e.NetID NetID Course clhuang5 CS 125
14 .Query Range Extraction Distributed range extraction What table shards are referenced by query Seek range extraction What fragments of relevant shard to read Lock range extraction What fragment of table to be locked Checked for potential pending modification Source: Spanner: Becoming a SQL System, David F. Bacon et al, SIGMOD 2017 Ranges given param1 = P001 param2 = 2017-01-01: (P001) (P001, /proposals/doc1, 2017-01-01), (P001, /proposals/doc2, 2017-01-01) (P001, /proposals)
15 .Query Restart Transient failures: network disconnects, machine reboots, process crashes, distributed wait and data movement Spanner transparently resumes execution of query if transient failures Redo minimum work after restarting from transient failure Benefit: Improved tail latency for online request Zero downtime for schema change and Spanner upgrade
16 .Common SQL Dialect A common data model, type system, syntax, semantics, and function library shared within systems in Google Google SQL library: Shared compiler front-end Shared library of scalar functions Shared testing framework: compliance tests and coverage tests Compliance tests: developer written tests Coverage tests: random query generation tool and a reference engine
17 .Thoughts Although Spanner is relational database system, some design consideration is different from traditional relational database system Choice of primary key and it’s value Interleave a table or not No experimental data? Here are some: A year after Spanner switch to a common Google-wide SQL dialect, the SQL query volume increased by a factor of five O ver 5,000 databases run in production instances T ens of millions of query per second across all Spanner databases M anaging hundreds of petabytes of data Any possible drawback of Spanner?
18 .Takeaway Spanner combine OLTP, OLAP, and full-text search capabilities in a single system Shard boundaries change dynamically for load balancing and reconfiguration, thus require a communication layer to route queries Trade offs for seek and lock range extraction, need judicious algorithm Query restart upon transient failures, which simply the client’s work on dealing with failures
19 .Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases Presenter: Wen-Chen Lo Alexandre Verbitski et al . Amazon Web Services
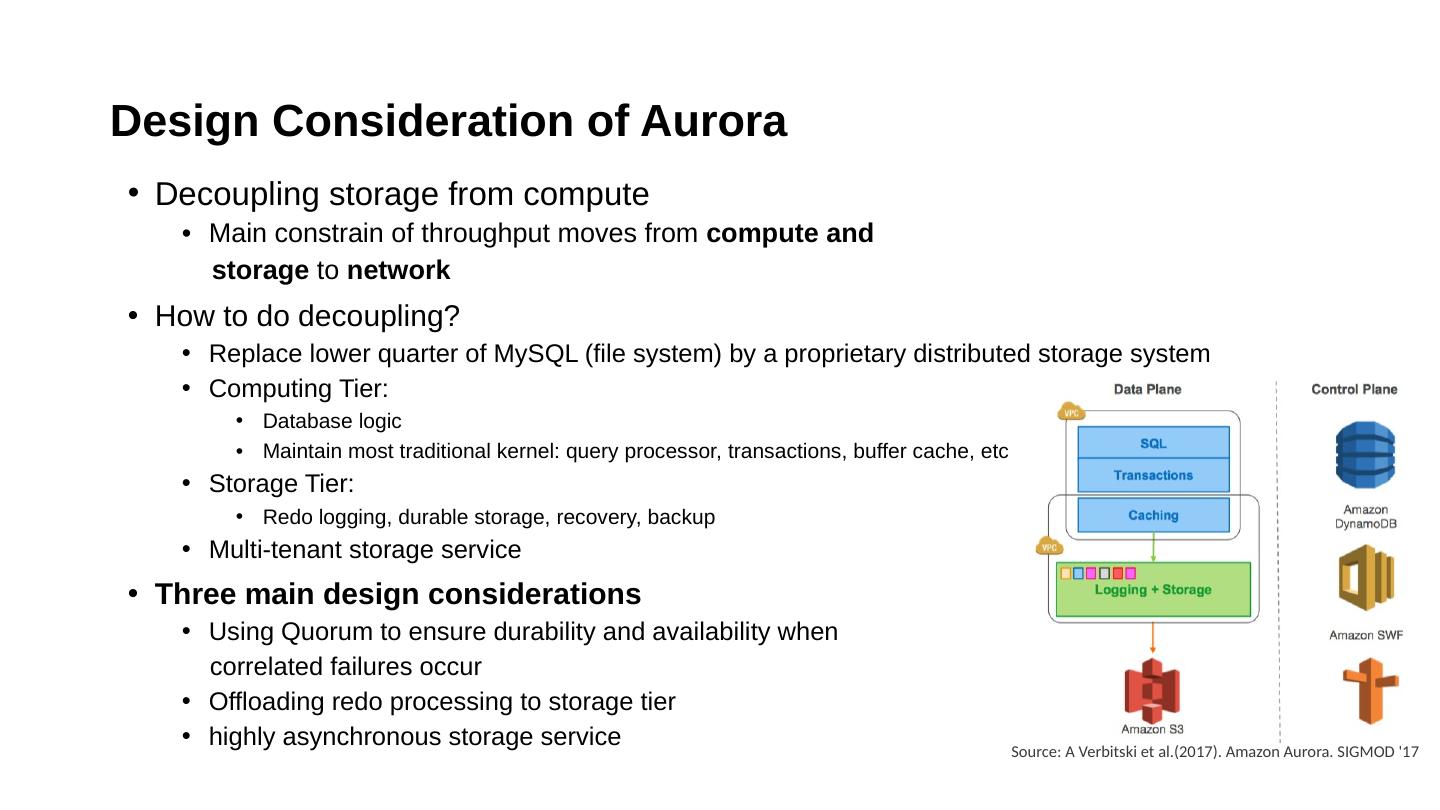
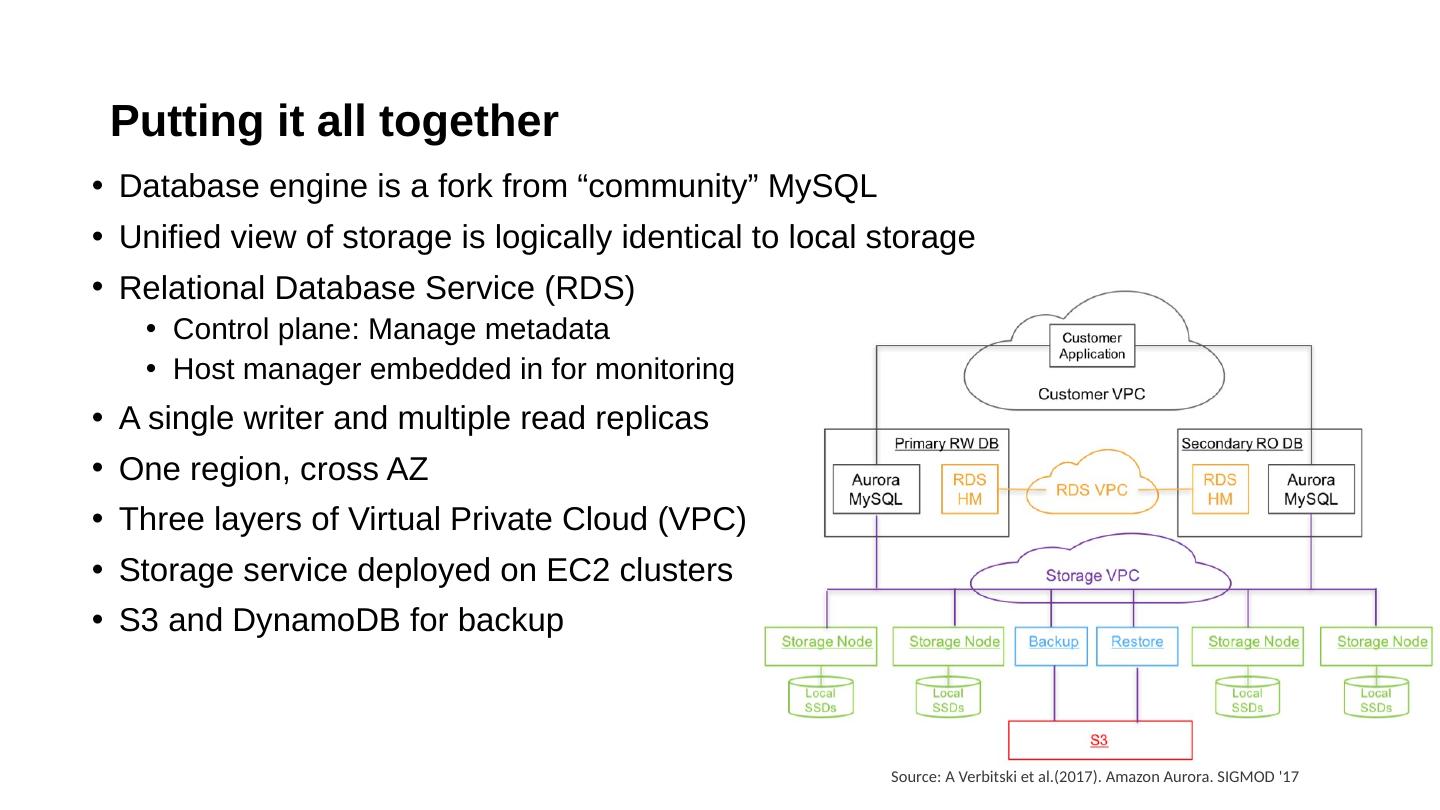
20 .What is Aurora and Why Amazon built Aurora? Aurora is a relational database as part of Amazon Web Services especially designed for high throughput workloads It is built based upon InnoDB (database engine for MySQL) with new design consideration Easy for migration: marketing policy
21 .What is Aurora and Why Amazon built Aurora? Aurora is a relational database as part of Amazon Web Services especially designed for high throughput workloads It is built based upon InnoDB (database engine for MySQL) with new design consideration Easy for migration: marketing policy
22 .What is Aurora and Why Amazon built Aurora? Aurora is a relational database as part of Amazon Web Services especially designed for high throughput workloads It is built based upon InnoDB (database engine for MySQL) with new design consideration Easy for migration: marketing policy
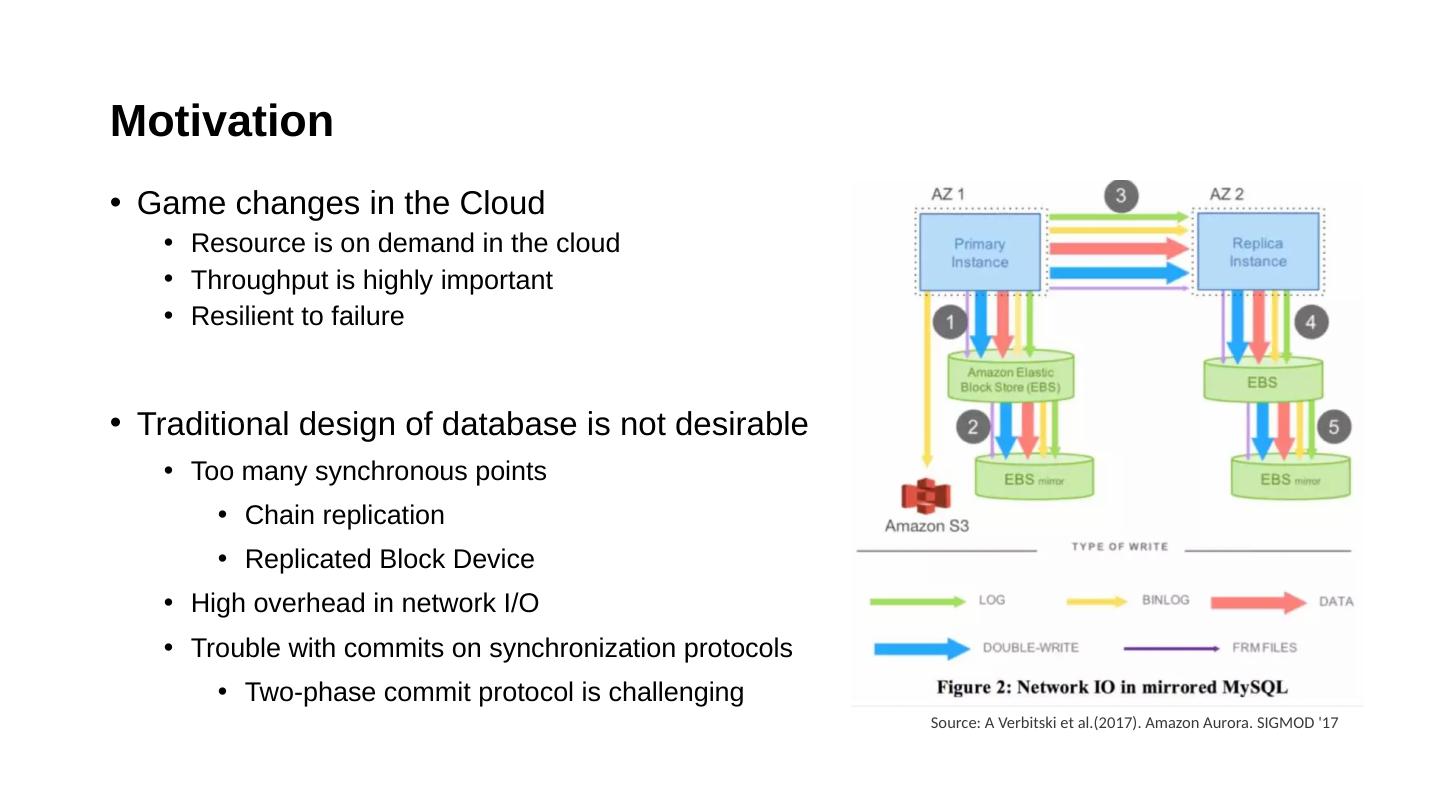
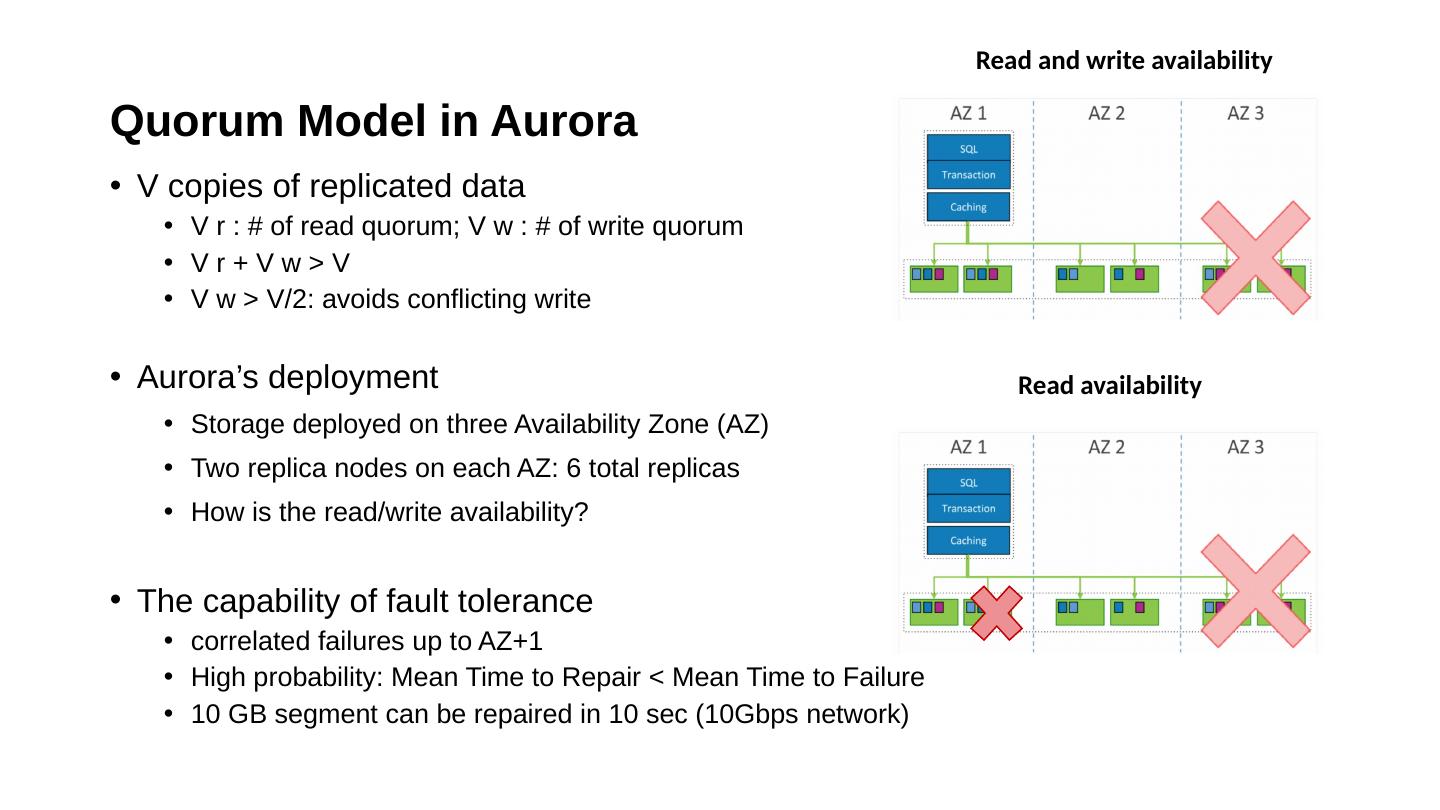
23 .Quorum Model in Aurora V copies of replicated data V r : # of read quorum; V w : # of write quorum V r + V w > V V w > V/2: avoids conflicting write Aurora’s deployment Storage deployed o n three Availability Zone (AZ) Two replica nodes on each AZ: 6 total replicas How is the read/write availability? The capability of fault tolerance correlated failures up to AZ+1 High probability: Mean Time to Repair < Mean Time to Failure 10 GB segment can be repaired in 10 sec (10Gbps network) Read and write availability Read availability
24 .Quorum Model in Aurora V copies of replicated data V r : # of read quorum; V w : # of write quorum V r + V w > V V w > V/2: avoids conflicting write Aurora’s deployment Storage deployed o n three Availability Zone (AZ) Two replica nodes on each AZ: 6 total replicas How is the read/write availability? The capability of fault tolerance correlated failures up to AZ+1 High probability: Mean Time to Repair < Mean Time to Failure 10 GB segment can be repaired in 10 sec (10Gbps network) Read and write availability Read availability
25 .Quorum Model in Aurora V copies of replicated data V r : # of read quorum; V w : # of write quorum V r + V w > V V w > V/2: avoids conflicting write Aurora’s deployment Storage deployed o n three Availability Zone (AZ) Two replica nodes on each AZ: 6 total replicas How is the read/write availability? The capability of fault tolerance correlated failures up to AZ+1 High probability: Mean Time to Repair < Mean Time to Failure 10 GB segment can be repaired in 10 sec (10Gbps network) Read and write availability Read availability
26 .Quorum Model in Aurora V copies of replicated data V r : # of read quorum; V w : # of write quorum V r + V w > V V w > V/2: avoids conflicting write Aurora’s deployment Storage deployed o n three Availability Zone (AZ) Two replica nodes on each AZ: 6 total replicas How is the read/write availability? The capability of fault tolerance correlated failures up to AZ+1 High probability: Mean Time to Repair < Mean Time to Failure 10 GB segment can be repaired in 10 sec (10Gbps network) Read and write availability Read availability
27 .Quorum Model in Aurora V copies of replicated data V r : # of read quorum; V w : # of write quorum V r + V w > V V w > V/2: avoids conflicting write Aurora’s deployment Storage deployed o n three Availability Zone (AZ) Two replica nodes on each AZ: 6 total replicas How is the read/write availability? The capability of fault tolerance correlated failures up to AZ+1 High probability: Mean Time to Repair < Mean Time to Failure 10 GB segment can be repaired in 10 sec (10Gbps network) Read and write availability Read availability
28 .Evaluation (Standard Benchmarks) MySQL 5.6 & MySQL 5.7 r3.8xlarge EC2 instances with 32 vCPUs and 244GB of memory if not specify A ttached EBS volume with 30K provisioned IOPS Buffer cache set to 170GB Benchmarks: SysBench & TPC-C Setups
29 .Write-only & Read-only workload (Aurora vs MySQL) Aurora can scale linearly while MySQL cannot > 5x of MySQL
相关推荐
3秒后跳转登录页面
去登陆

