












































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Hadoop Hbase Operations Practice
2013年出品的大数据Hadoop和HBase最佳实践文章,讲述了为什么大数据用HBase进行存储,一般大数据平台的基本架构,其中设计基本的软硬件配置对2018年的今天仍然有一定参考意义,但是软硬件进展非常快,理解其中对问题的调研方法很重要。
展开查看详情
1 .HBase Operations & Best Practices Venu Anuganti July 2013 http://scalein.com/ Blog: http://venublog.com / Twitter: @vanuganti
2 .Who am I Data Architect, Technology Advisor Founder of ScaleIN , Data Consulting Company, 5+ years 100+ companies, 20+ from Fortune 200 http://scalein.com/ Architect, Implement & Support SQL, NoSQL and BigData Solutions Industry : Databases, Games, Social, Video, SaaS , Analytics, Warehouse, Web, Financial, Mobile, Advertising & SEM Marketing
3 .Agenda BigData - Hadoop & HBase Overview BigData Architecture HBase Cluster Setup Walkthrough High Availability Backup and Restore Operational Best Practices
4 .BigData Overview
5 .BigData Trends BigData is the latest industry buzz, many companies adopting or migrating Not a replacement for OLTP or RDBMS systems Gartner – 28B in 2012 & 34B in 2013 spend 2013 top-10 technology trends – 6 th place Solves large data problems that existed for years Social, User, Mobile growth demanded such a solution Google “ BigTable ” is the key, followed by Amazon “ Dynamo ”; new papers like Dremel drives it further Hadoop & ecosystem is becoming synonym for BigData Combines vast structured/un-structured data Overcomes from legacy warehouse model Brings data analytics & data science Real-time, mining, insights, discovery & complex reporting
6 .BigData Key factors - Pros Can handle any size Commodity hardware Scalable, Distributed, Highly Available Ecosystem & growing community Key factors – Cons Latency Hardware evolution, even though designed for commodity Does not fit for all
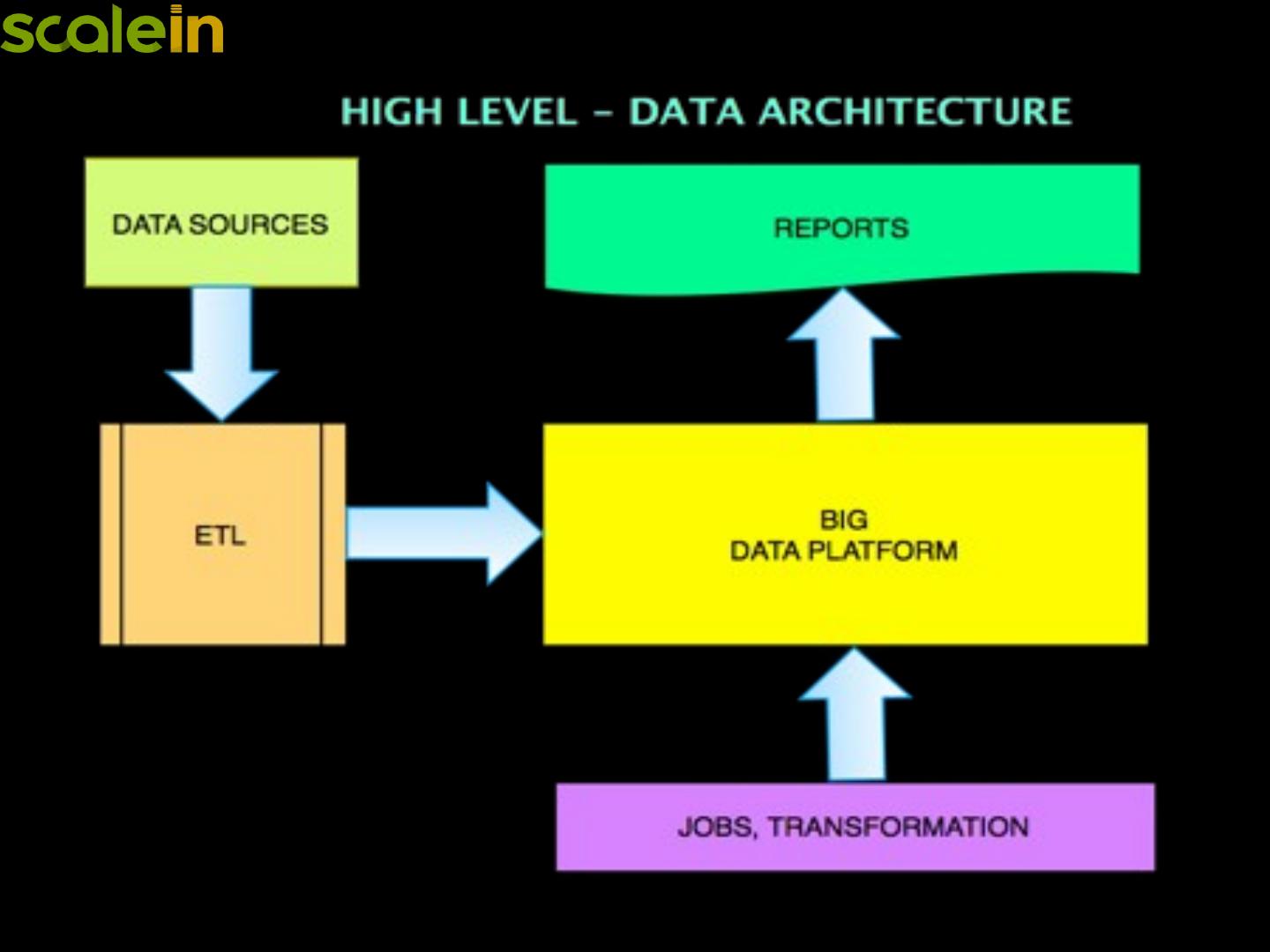
7 .BigData Architecture
8 .
9 .Low Level Architecture
10 .Why HBase
11 .Why HBase HBase is proven, widely adopted Tightly coupled with hadoop ecosystem Almost all major data driven companies using it Scales linearly Read performance is its core; random, sequential reads Can store tera/peta bytes of data Large scale scans, millions of records Highly distributed CAP Theorem – HBase is CP driven Competition: Cassandra (AP)
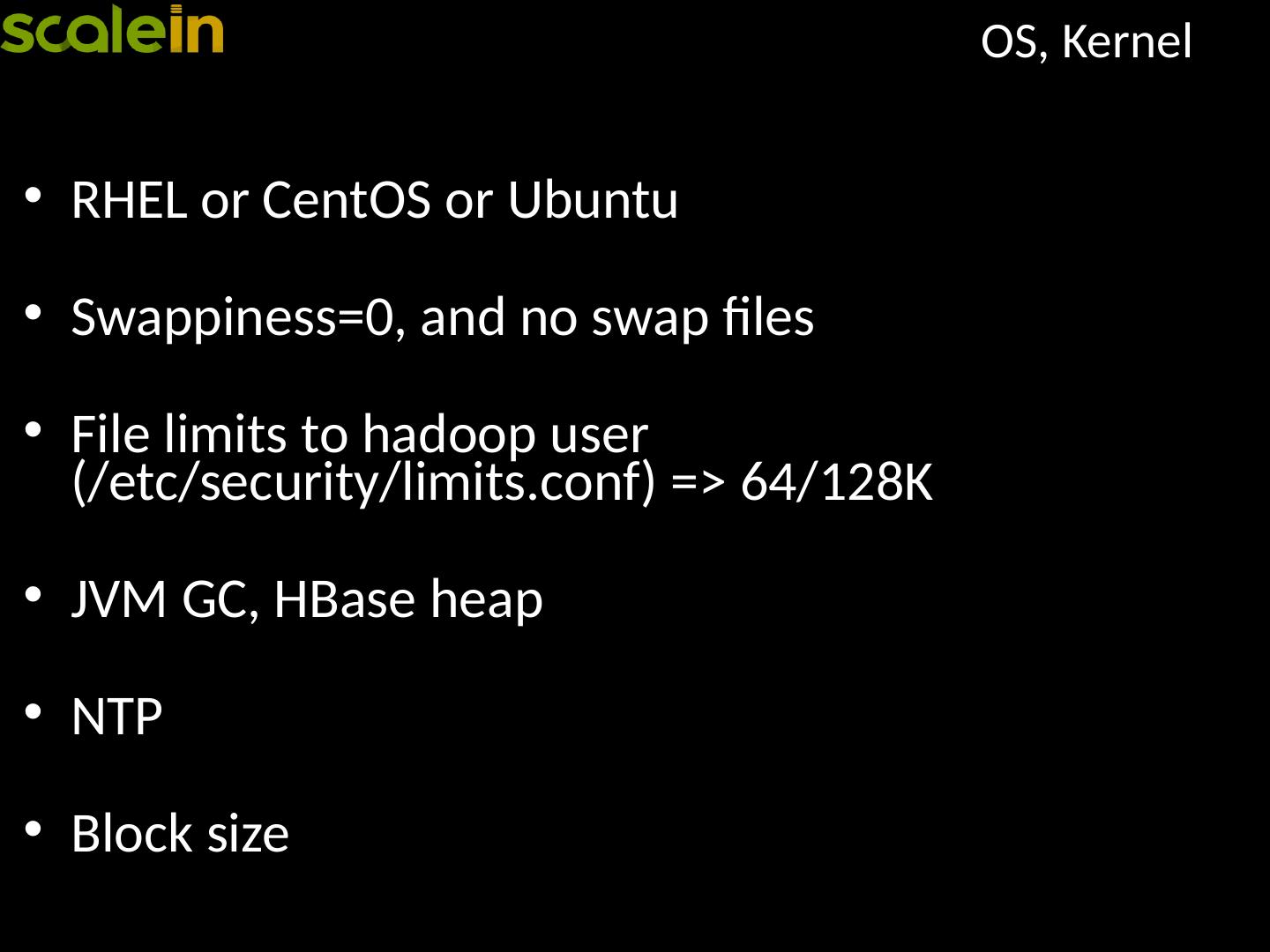
12 .Hadoop/ HBase Cluster Setup
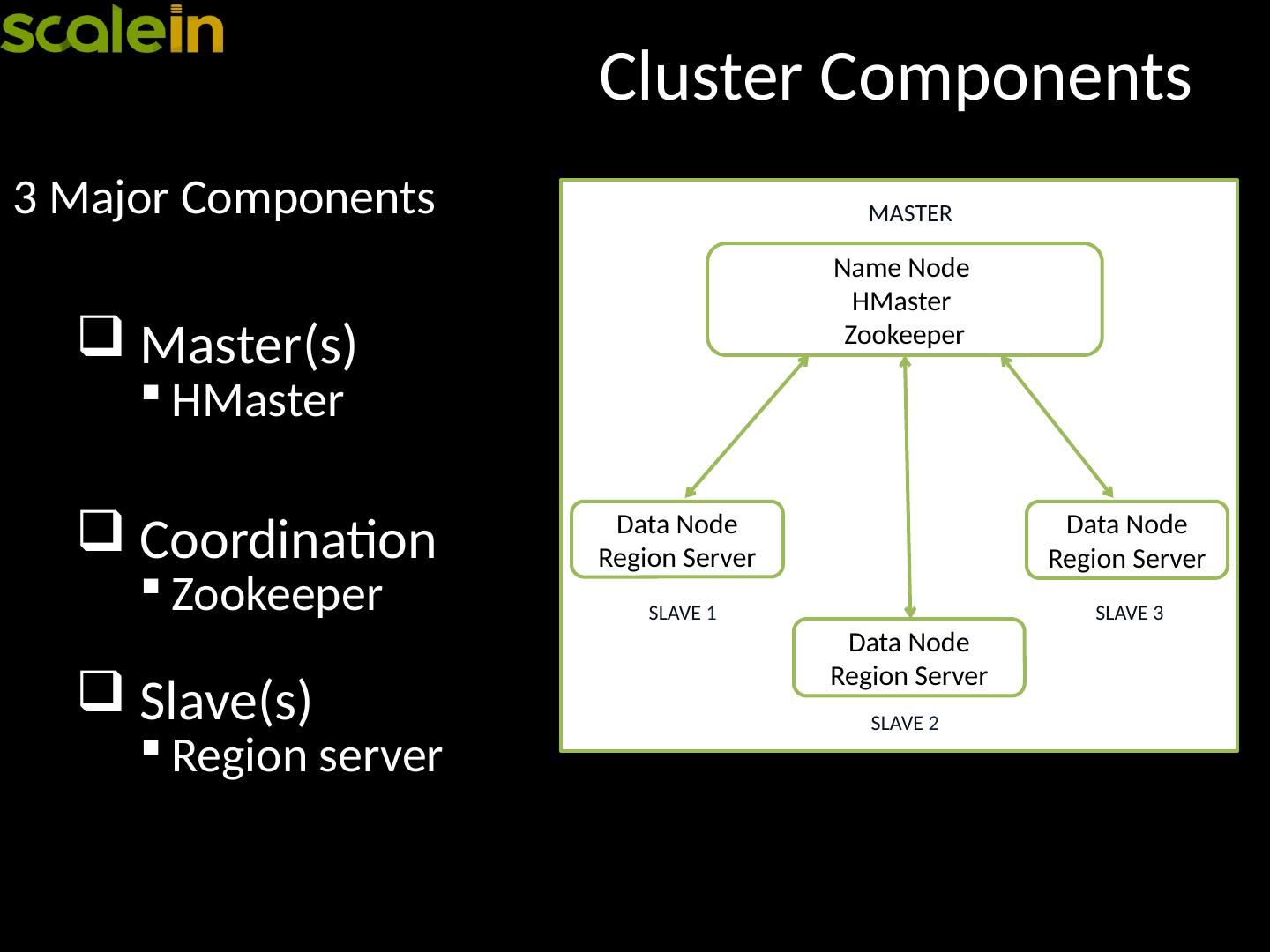
13 .Cluster Components 3 Major Components Master(s) HMaster Coordination Zookeeper Slave(s) Region server Name Node HMaster Zookeeper MASTER Data Node Region Server SLAVE 1 Data Node Region Server SLAVE 3 Data Node Region Server SLAVE 2
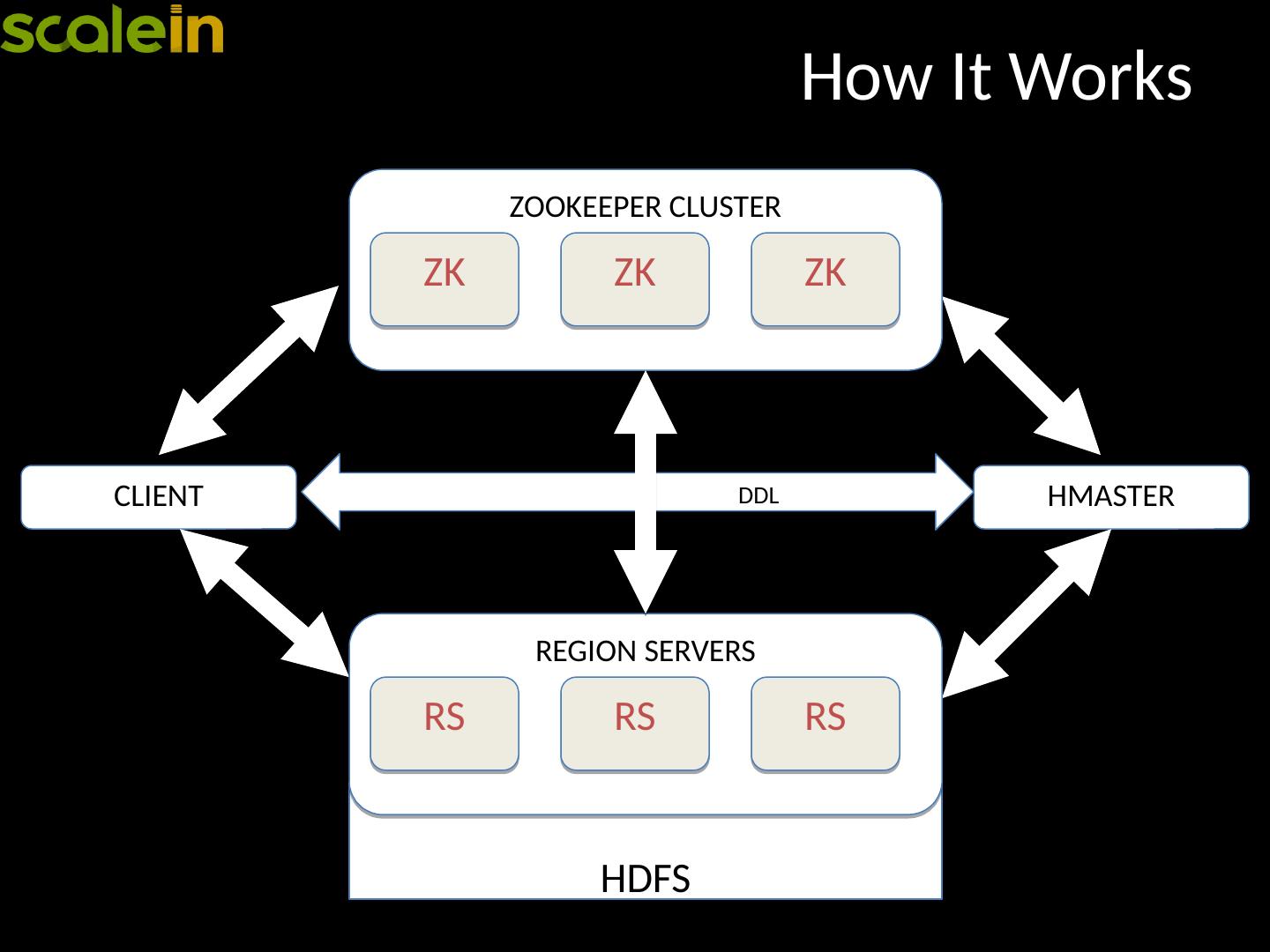
14 .How It Works HMASTER DDL CLIENT HDFS REGION SERVERS RS RS RS ZOOKEEPER CLUSTER ZK ZK ZK
15 .Zookeeper Zookeeper Coordination for entire cluster Master selection Root region server lookup Node registration Client always communicates with Zookeper for lookups (cached for sub-sequent calls) hbase (main):001:0> zk " ls /hbase" [safe-mode, root-region-server, rs , master, shutdown, replication]
16 .Zookeeper Setup Zookeeper Dedicated nodes in the cluster Always in odd number Disk, memory, cpu usage is low Availability is a key
17 .Master Node HMaster Typically runs with Name Node Monitors all region servers, handles RS failover Handles all meta data changes Assigns regions Interface for all meta data changes L oad balancing on idle times
18 .Master Setup Dedicated Master Node Light on use, but should be on reliable hardware Good amount of memory and CPU can help Disk space is pretty nominal Must Have Redundancy Avoid single point of failure (SPOF) RAID preferred for redundancy or even JBOD DRBD or NFS is also preferred
19 .Region Server Region Server Handles all I/O requests Flush MemStore to HDFS Splitting Compaction Basic element of table storage Table => Regions => Store per Column Family => CF => MemStore / CF/Region && StoreFile /Store/Region => Block Maintains WAL (Write Ahead Log) for all changes
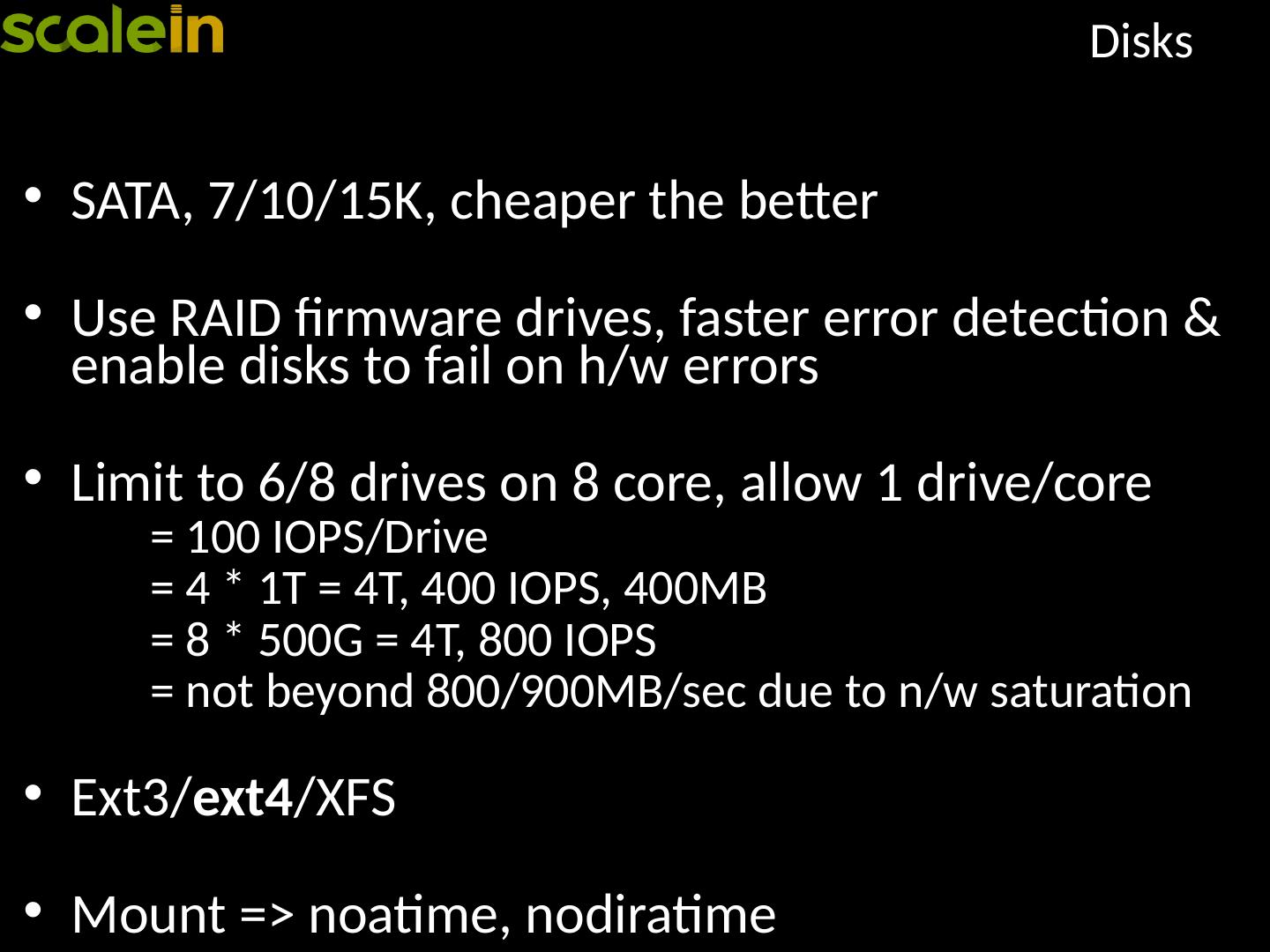
20 .Region Server - Setup S hould be stand-alone and dedicated JBOD disks In-expensive Data node and region server should be co-located Network Dual 1G, 10G or InfiniBand, DNS lookup free Replication - at least 3, locality Region size for splits; too many or too small regions are not good.
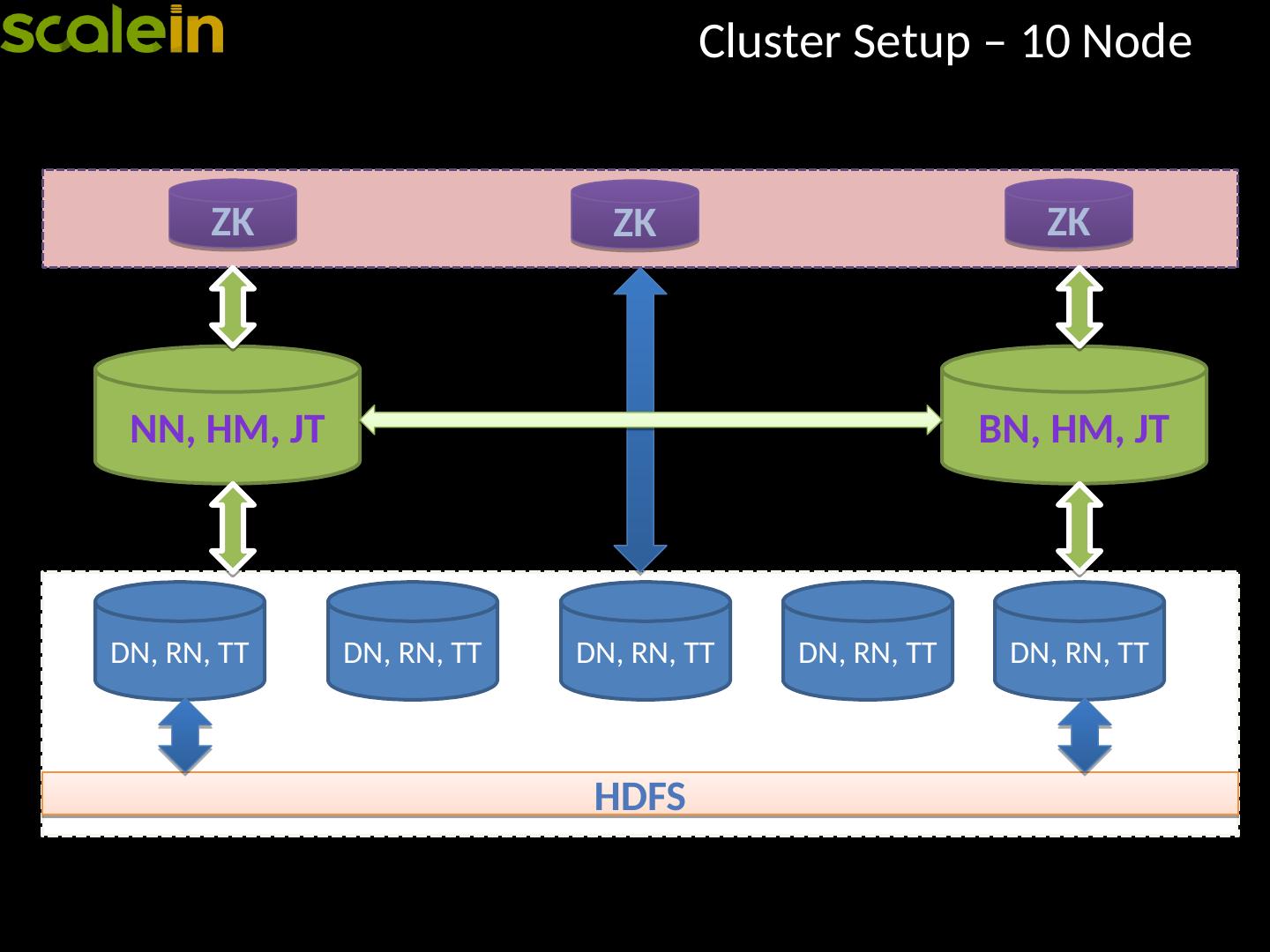
21 .Cluster Setup – 10 Node HDFS NN, HM, JT BN, HM, JT ZK ZK ZK DN, RN, TT DN, RN, TT DN, RN, TT DN, RN, TT DN, RN, TT
22 .High Availability
23 .High Availability HBase Cluster - Failure Candidates Data Center Cluster Rack Network Switch Power Strip Region or Data Node Zookeeper Node HBase Master Name Node
24 .HA - Data Center Cross data center, geo distributed Replication is the only solution Up2date data Active-active Active-passive Costly (can be sized) Need dedicated network On-demand offline cluster Only for disaster recovery No up2date copy Can be sized appropriately Need to reprocess for latest data
25 .HA – Redundant Cluster Redundant cluster within a data center using replication Mainly to have backup cluster for disasters Up2date data Restore a state back using TTL based Restore deleted data by keeping deleted cells Run backups Read/write distributed with load balancer Support development or provide on-demand data Support low important activities Best practice: Avoid redundant cluster, rather have one big cluster with high redundancy
26 .HA – Rack, Network, Power Cluster nodes should be rack and switch aware Loosing a rack or a network switch should not bring cluster down Hadoop has built-in rack awareness Assign nodes based on rack diagram Redundant nodes are within rack, across switch and rack Manual or automatic setup to detect location Redundant power and network within each node (master)
27 .HA – Region Servers Loosing a region server or data node is very common, in many cases it could be very frequent They are distributed and replicated Can be added/removed dynamically, taken out for regular maintenance Replication factor of 3 Can loose ⅔ rd of the cluster nodes Replication factor of 4 Can loose ¾th of the cluster nodes
28 .HA – Zookeeper Zookeeper nodes are distributed Can be added/removed dynamically Should be implemented in odd number, due to quorum (majority voting wins the active state) If 4, can loose 1 node (3 major voting) If 5, can loose 2 nodes (3 major voting) If 6, can loose 2 nodes (4 major voting) If 7, can loose 3 nodes (4 major voting) Best Practice: 5 or 7 with dedicated hardware.
29 .HA – HMaster HMaster - single point of failure HA - Multiple HMaster nodes within a cluster Zookeeper co-ordinates master failure Only one active at any given point of time Best practice : 2-3 HMasters , 1 per rack
相关推荐
3秒后跳转登录页面
去登陆

