






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HDFS on Kubernetes Tech deep dive
Kubernetes作为容器编排工具,提供了很好的横向扩展能力和资源隔离手段,作为大数据技术栈非常重要的一环,如何让HDFS也运行在Kubernetes之上,并且提供用户粒度的安全隔离,并且,作为大数据处理引擎,Apache Spark很多优化都是基于数据本地行(Node Locality和Rack Locality)假设的,在保证数据隔离安全性的基础上,还能减小性能损失,Spark on Kubernetes也做了不少工作,本篇Slides对Big Data on Kuberntes做了很好的阐述。
展开查看详情
1 .HDFS on Kubernetes -- Deep Dive on Security and Locality Kimoon Kim, Pepperdata Ilan Filonenko, Bloomberg LP
2 .Agenda Kubernetes intro Big Data on Kubernetes Demo: Spark on K8s accessing secure HDFS Secure HDFS deep dive HDFS running on K8s Data locality deep dive Demo: Namenode HA
3 .Kubernetes New open-source cluster manager. github.com/kubernetes/kubernetes libs app kernel libs app libs app libs app Runs programs in Linux containers. 1600+ contributors and 60,000+ commits.
4 .“My app was running fine until someone installed their software” DON’T TOUCH MY STUFF
5 .More isolation is good Kubernetes provides each program with: a lightweight virtual file system -- Docker image an independent set of S/W packages a virtual network interface a unique virtual IP address an entire range of ports
6 .Other isolation layers Separate process ID space Max memory limit CPU share throttling Mountable volumes Config files -- ConfigMaps Credentials -- Secrets Local storages -- EmptyDir, HostPath Network storages -- PersistentVolumes
7 .Kubernetes architecture node A node B Pod 1 Pod 2 Pod 3 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Pod , a unit of scheduling and isolation. runs a user program in a primary container holds isolation layers like a virtual IP in an infra container
8 .Big Data on Kubernetes github.com/apache-spark-on-k8s Bloomberg, Google, Haiwen, Hyperpilot, Intel, Palantir, Pepperdata, Red Hat, and growing Patching up Spark Driver and Executor code to work on Kubernetes. Upstreaming. Part of Spark 2.3 -- “Spark release 2.3.0. … Major features: Spark on Kubernetes : [ SPARK-18278 ] A new kubernetes scheduler backend that supports native submission of spark jobs to a cluster managed by kubernetes. ...” Related talk: spark-summit.org/2017/events/apache-spark-on-kubernetes/
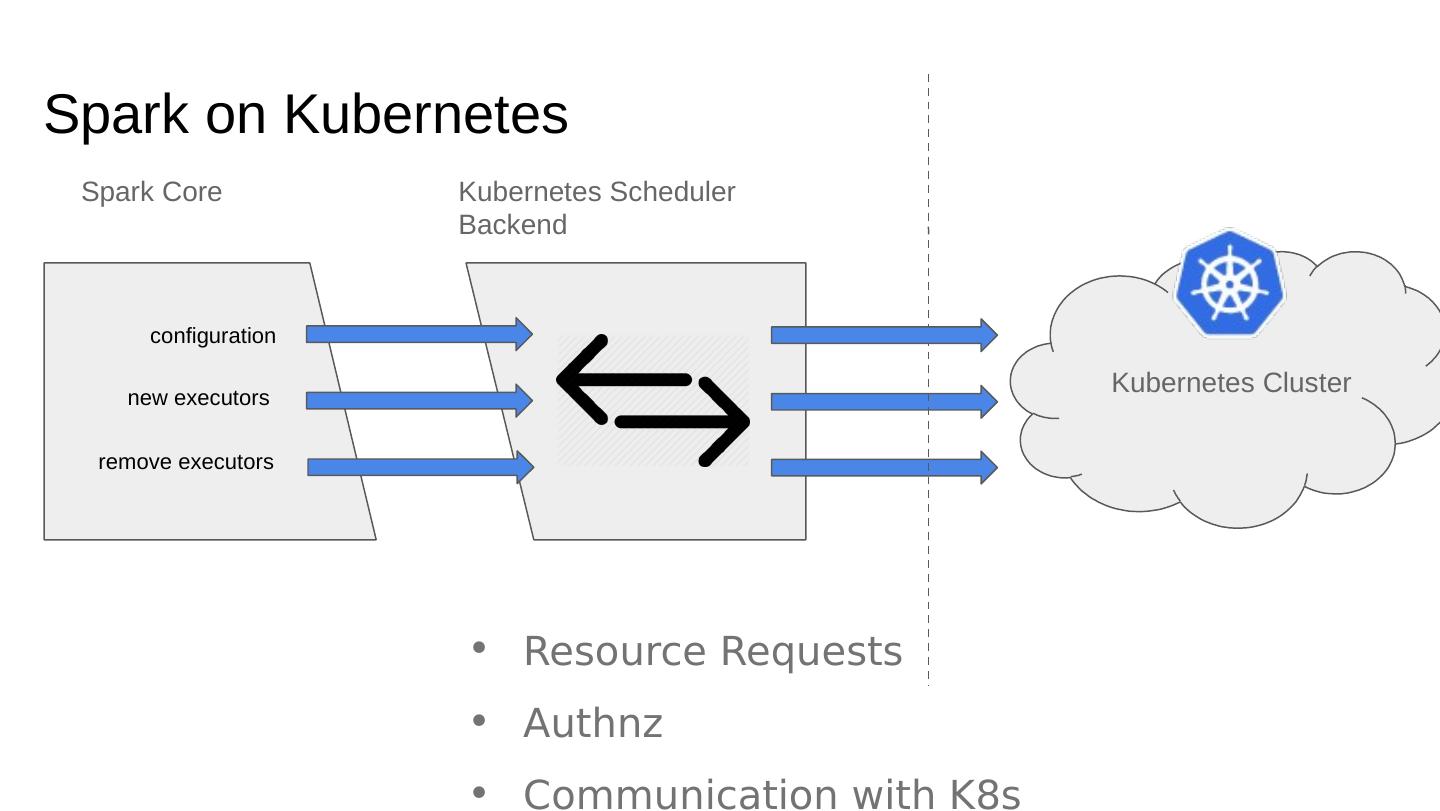
9 .Spark on Kubernetes Spark Core Kubernetes Scheduler Backend Kubernetes Cluster new executors remove executors configuration Resource Requests Authnz Communication with K8s
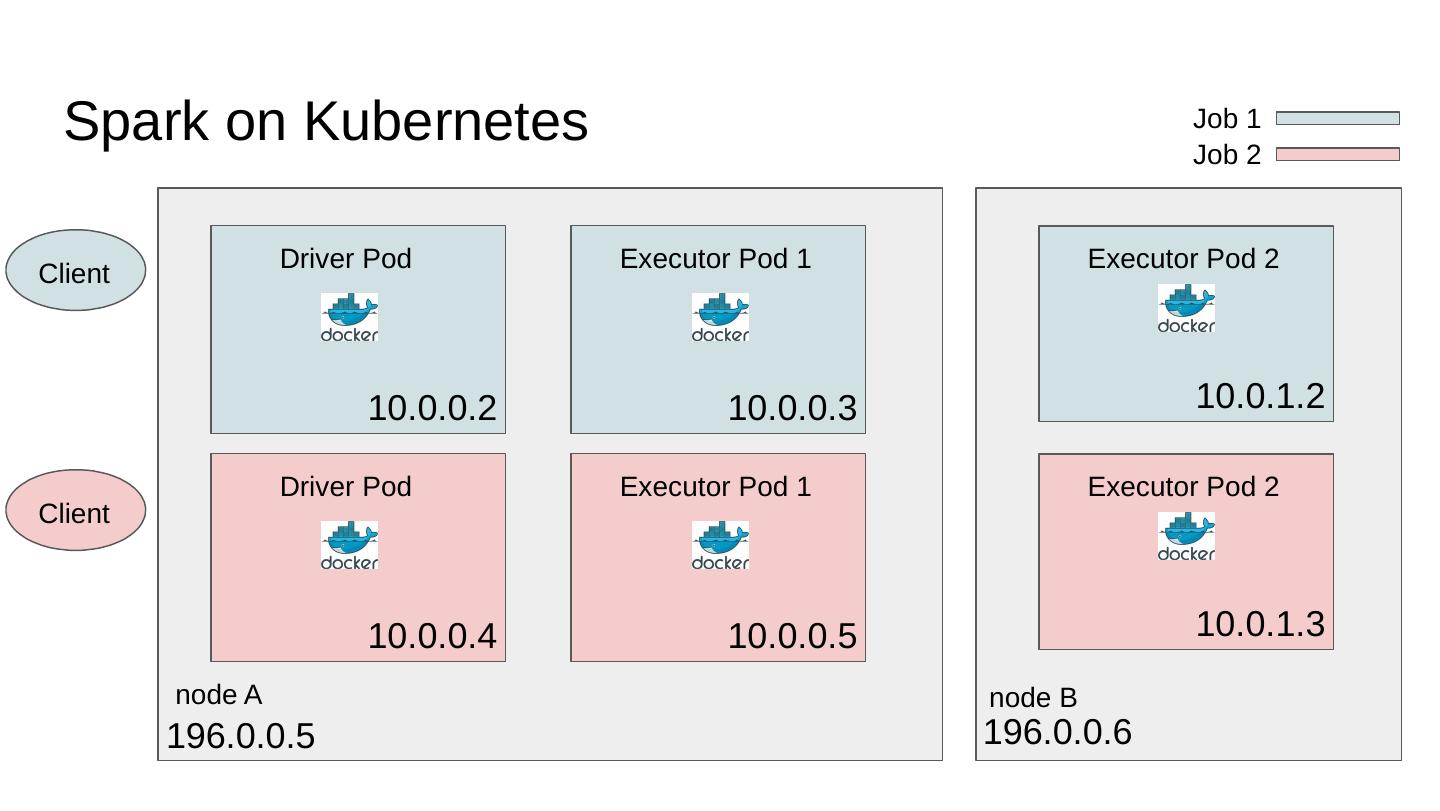
10 .Spark on Kubernetes node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Client Client Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.4 10.0.0.5 10.0.1.3 Job 1 Job 2
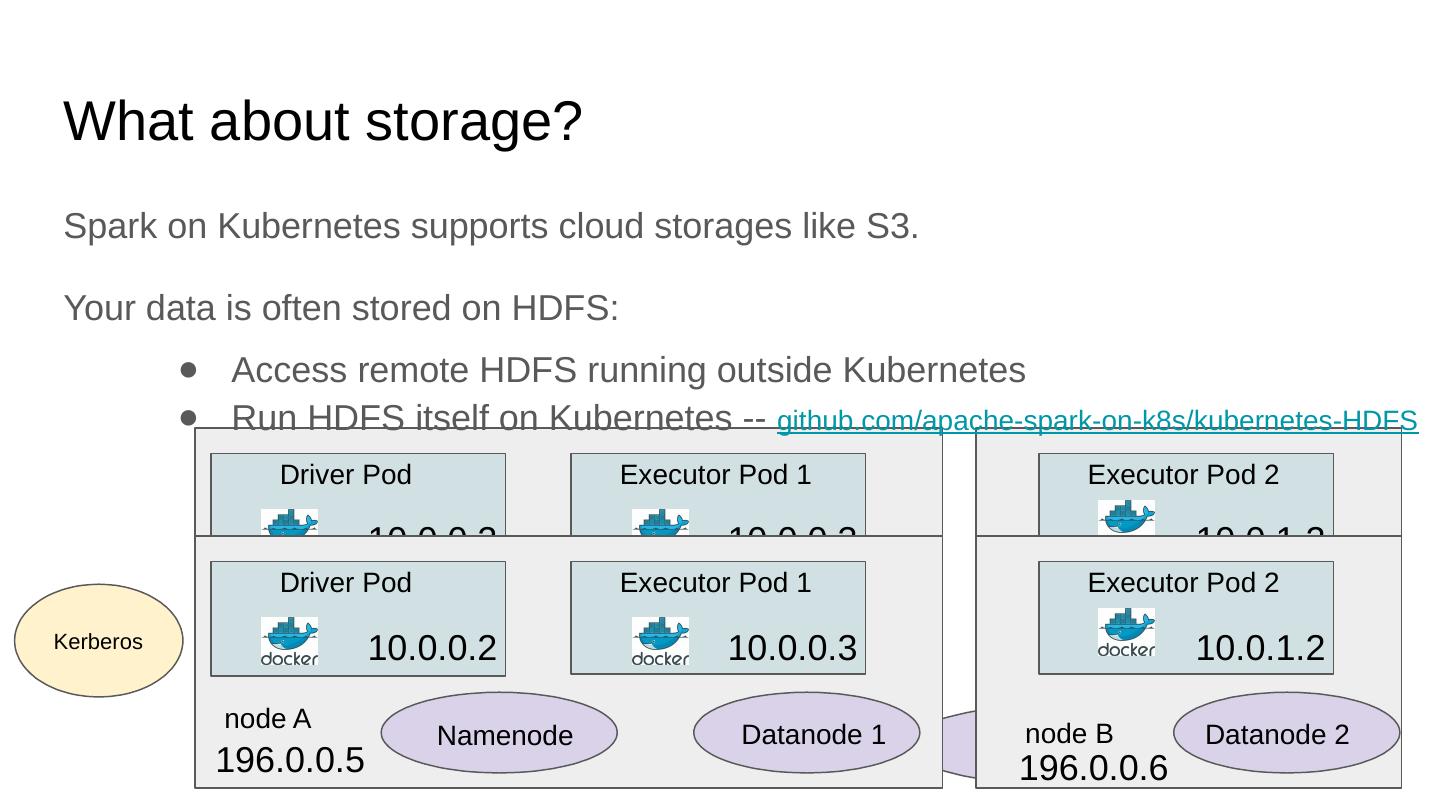
11 .What about storage? Spark on Kubernetes supports cloud storages like S3. Your data is often stored on HDFS: node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Namenode Datanode 1 Datanode 2 Access remote HDFS running outside Kubernetes Run HDFS itself on Kubernetes -- github.com/apache-spark-on-k8s/kubernetes-HDFS node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Namenode Datanode 1 Datanode 2 Kerberos
12 .What about storage? Spark on Kubernetes supports cloud storages like S3. Your data is often stored on HDFS: node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Namenode Datanode 1 Datanode 2 Access remote HDFS running outside Kubernetes Run HDFS itself on Kubernetes -- github.com/apache-spark-on-k8s/kubernetes-HDFS node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Namenode Datanode 1 Datanode 2 Kerberos
13 .Demo: Spark k8s Accessing Secure HDFS Running a Spark Job on Kubernetes accessing Secure HDFS https://github.com/ifilonenko/secure-hdfs-test
14 .Security deep dive Kerberos tickets HDFS tokens Long running jobs Access Control of Secrets
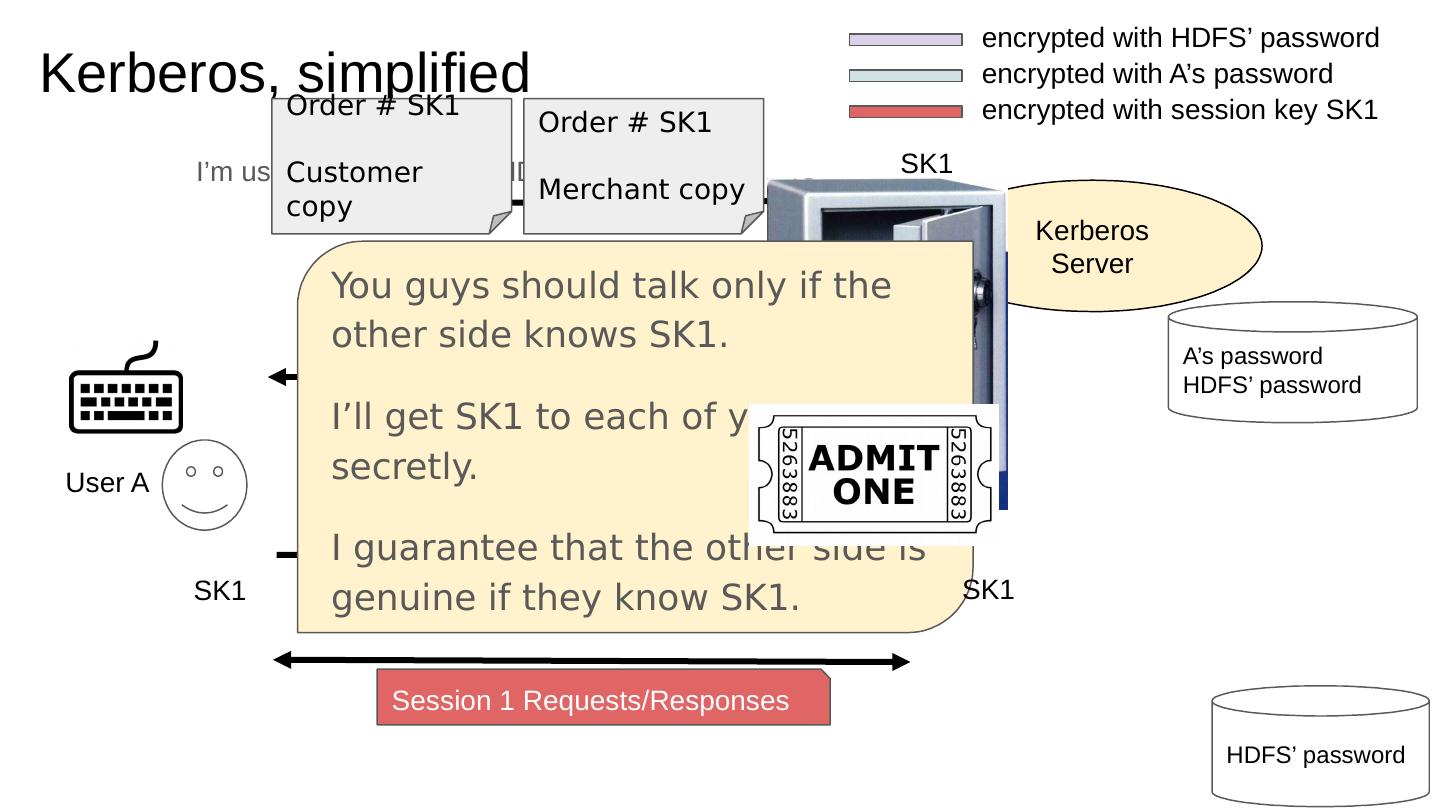
15 .HDFS namenode User A encrypted with session key SK1 encrypted with HDFS’ password encrypted with A’s password Session 1 Requests/Responses Kerberos Server A’s password HDFS’ password HDFS’ password I’m user A. May I talk to HDFS? SK1 copy for HDFS SK1 copy for User A SK1 copy for HDFS Ticket to HDFS Kerberos, simplified SK1 You guys should talk only if the other side knows SK1. I’ll get SK1 to each of you secretly. I guarantee that the other side is genuine if they know SK1. Order # SK1 Customer copy Order # SK1 Merchant copy SK1 SK1
16 .HDFS Delegation Token Kerberos ticket, no good for executors on cluster nodes. Stamped with the client IP. Give tokens to driver and executors instead. Issued by namenode only if the client has a valid Kerberos ticket. No client IP stamped. Permit for driver and executors to use HDFS on your behalf across all cluster nodes.
17 .Solved: Share tokens via K8s Secret node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Client Namenode Datanode 1 Datanode 2 Secret 1 Kerberos Problem: Driver & executors need token ADMIT USER
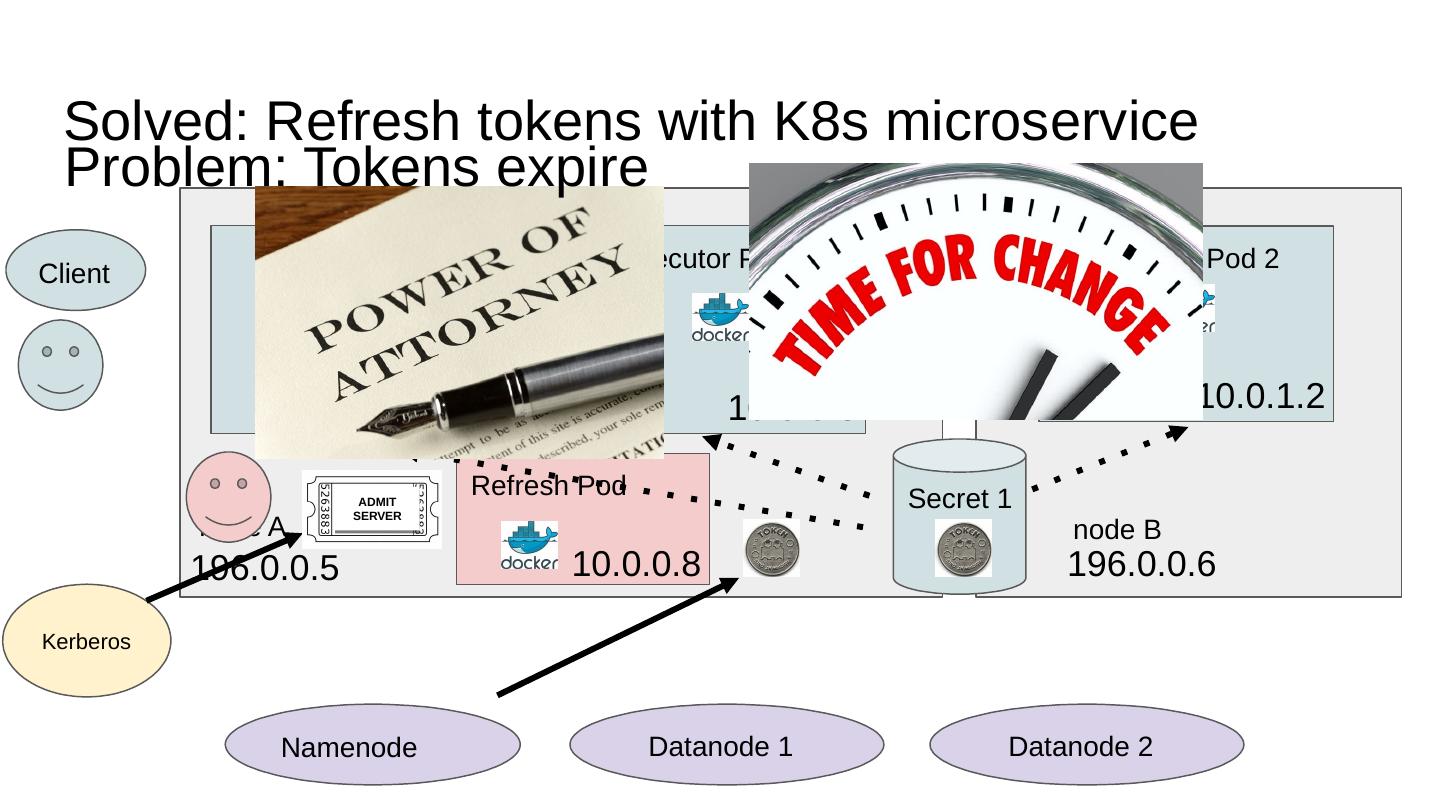
18 .Solved: Refresh tokens with K8s microservice node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Client Namenode Datanode 1 Datanode 2 Refresh Pod 10.0.0.8 Secret 1 Kerberos Problem: Tokens expire ADMIT SERVER
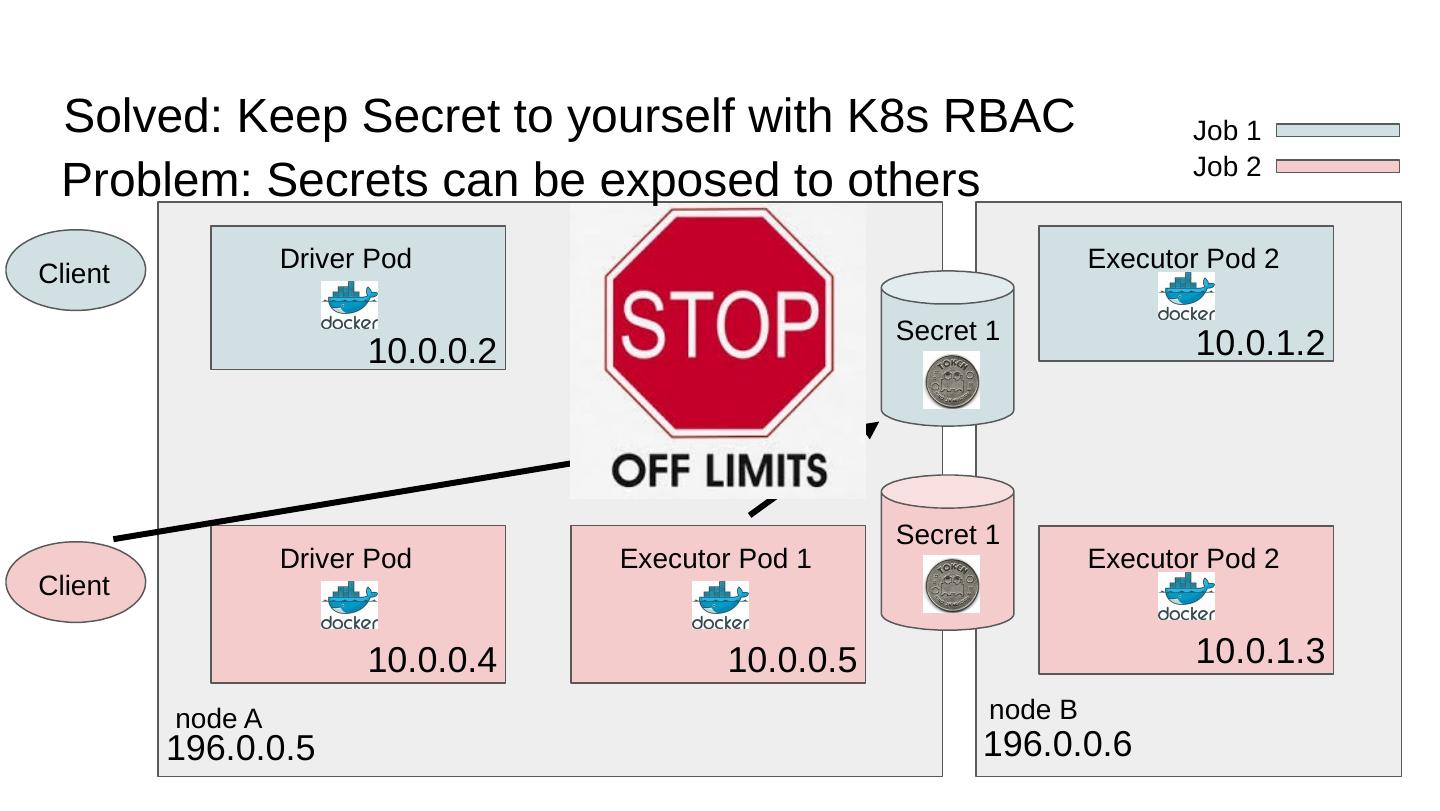
19 .Solved: Keep Secret to yourself with K8s RBAC node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Client Client Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.4 10.0.0.5 10.0.1.3 Secret 1 Secret 1 Job 1 Job 2 Problem: Secrets can be exposed to others
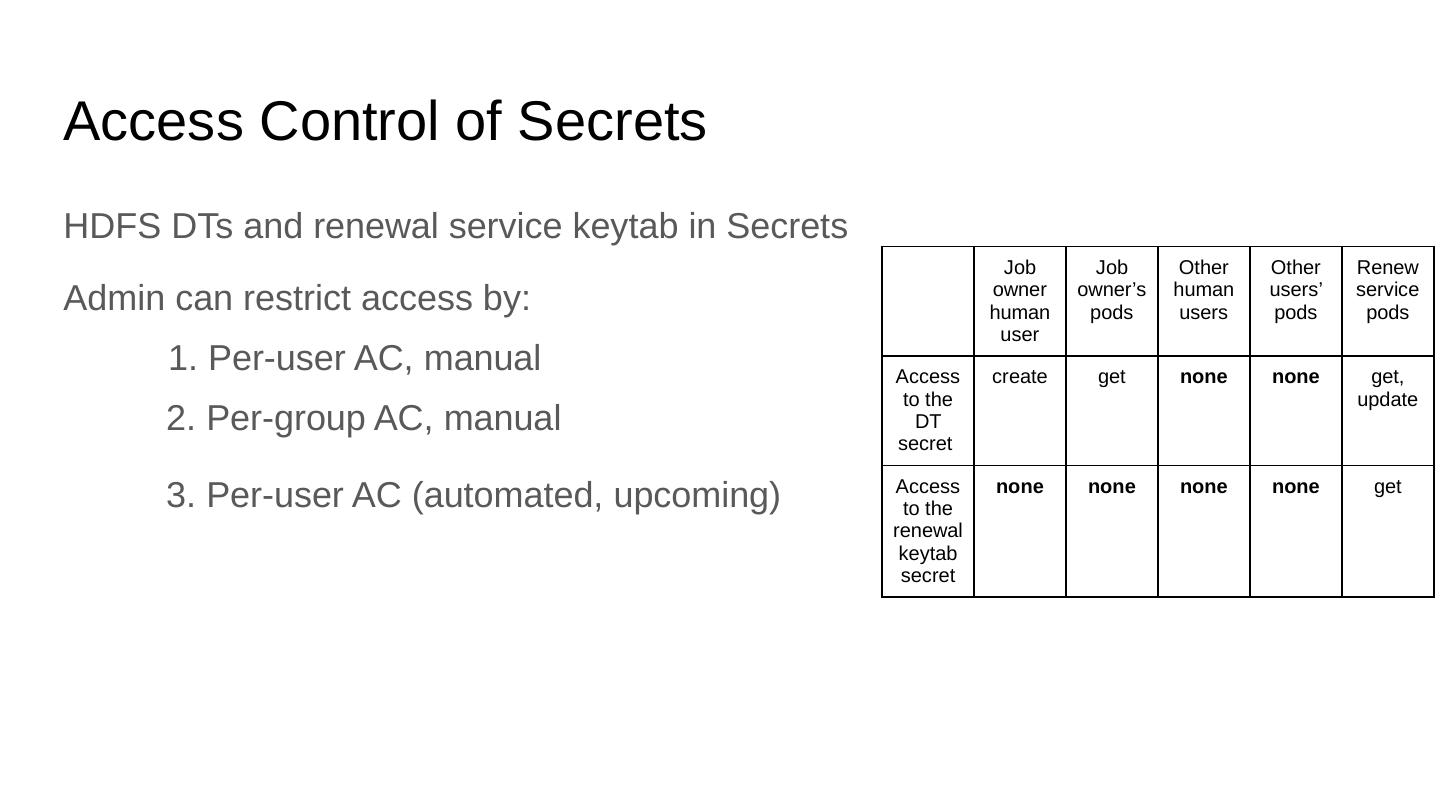
20 .Access Control of Secrets HDFS DTs and renewal service keytab in Secrets Job owner human user Job owner’s pods Other human users Other users’ pods Renew service pods Access to the DT secret create get none none get, update Access to the renewal keytab secret none none none none get Admin can restrict access by: 1. Per-user AC, manual 2. Per-group AC, manual 3. Per-user AC (automated, upcoming)
21 .Access Control of Secrets HDFS DTs and renewal service keytab in Secrets Job owner human user Job owner’s pods Other human users Other users’ pods Renew service pods Access to the DT secret create get none none get, update Access to the renewal keytab secret none none none none get Admin can restrict access by: 1. Per-user AC, manual 2. Per-group AC, manual 3. Per-user AC (automated, upcoming)
22 .Agenda Kubernetes intro Big Data on Kubernetes Demo: Spark on K8s accessing secure HDFS Secure HDFS deep dive HDFS running on K8s Data locality deep dive Demo: Namenode HA node A node B 196.0.0.5 196.0.0.6 Namenode Datanode 1 node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Namenode Datanode 1 Datanode 2
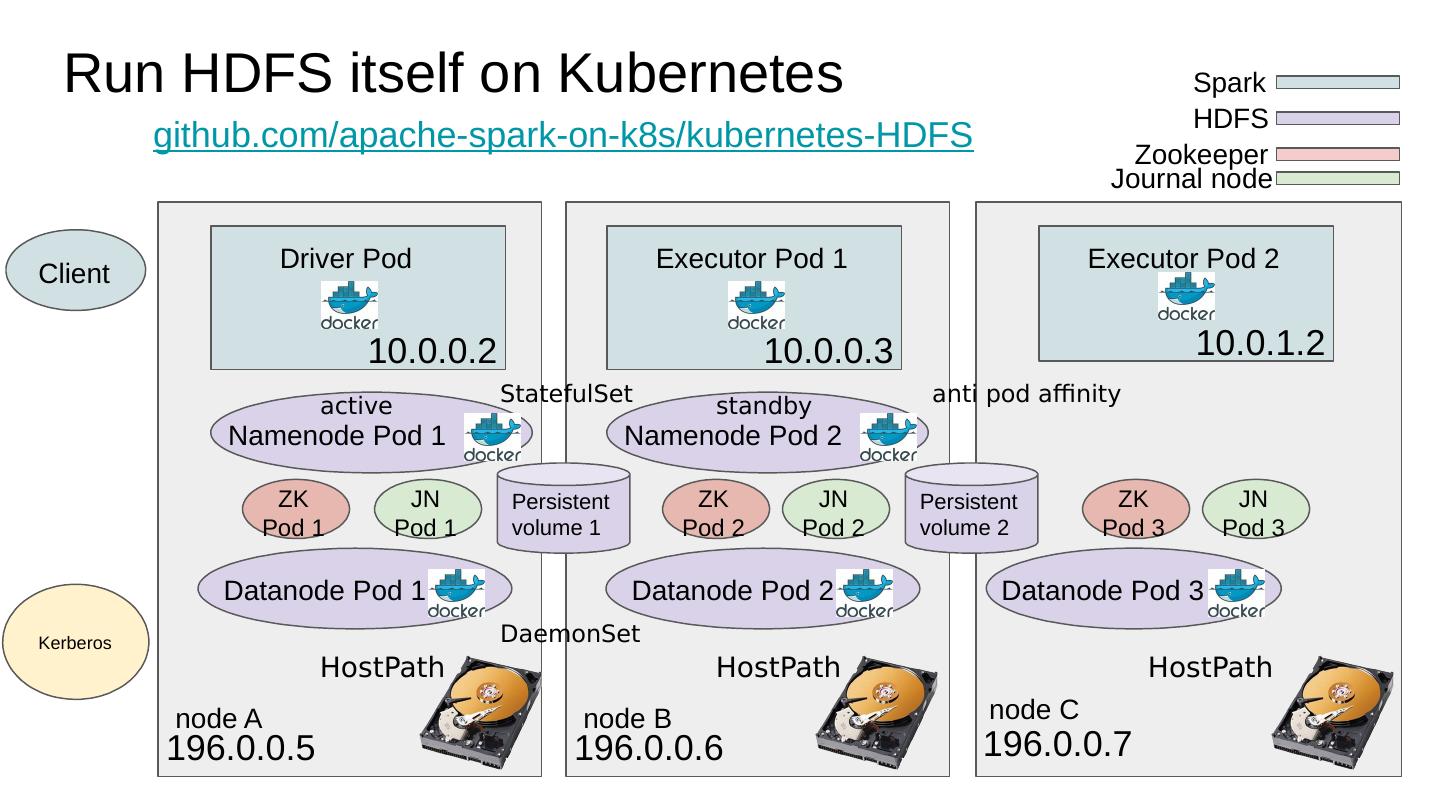
23 .Run HDFS itself on Kubernetes node A node C Driver Pod Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.7 10.0.1.2 Client Spark Namenode Pod 1 Datanode Pod 1 Datanode Pod 3 HDFS HostPath HostPath github.com/apache-spark-on-k8s/kubernetes-HDFS 196.0.0.6 Executor Pod 1 10.0.0.3 Datanode Pod 2 HostPath Namenode Pod 2 node B Persistent volume 1 Persistent volume 2 ZK Pod 1 ZK Pod 2 JN Pod 1 ZK Pod 3 JN Pod 2 JN Pod 3 Zookeeper Journal node Kerberos StatefulSet DaemonSet active standby anti pod affinity
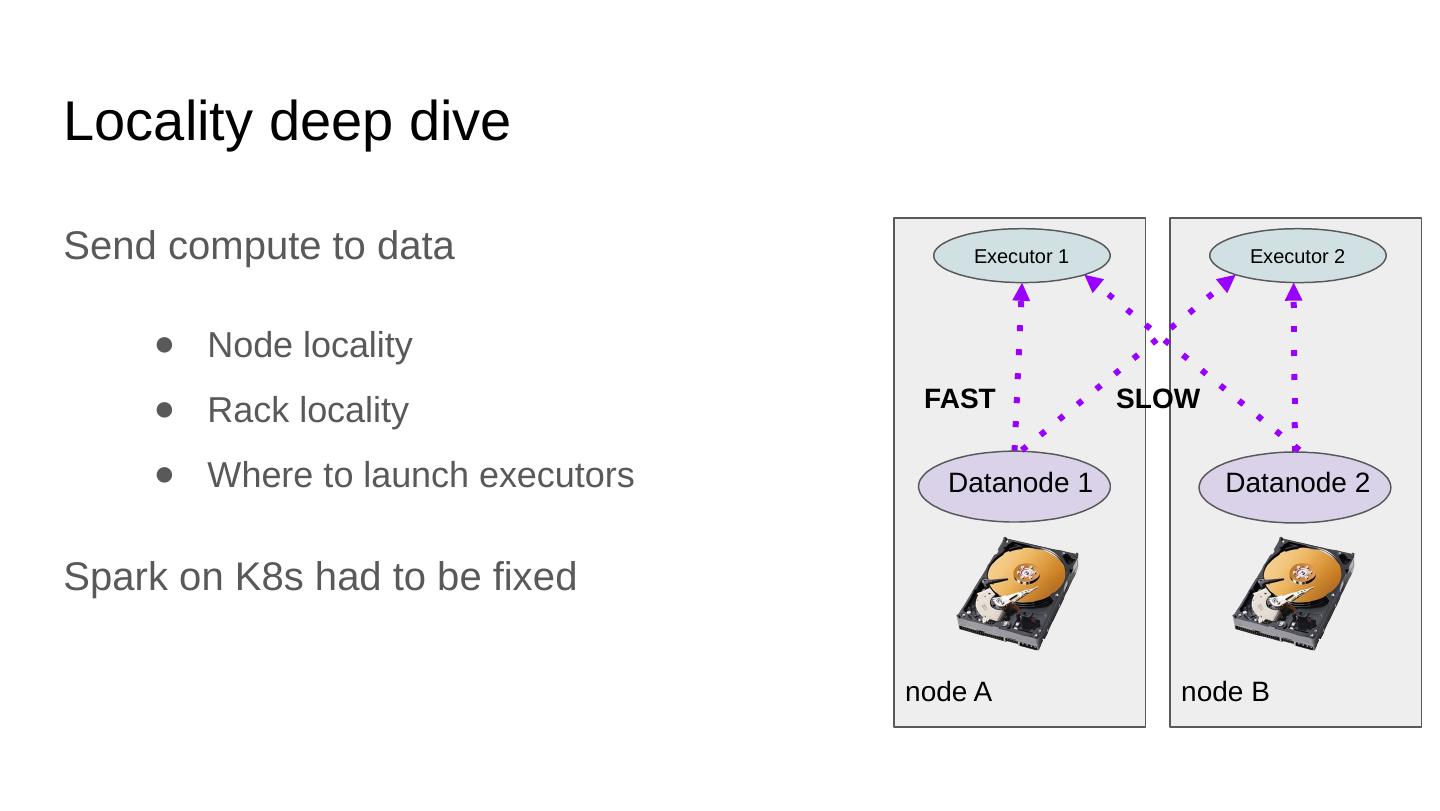
24 .Locality deep dive Send compute to data Node locality Rack locality Where to launch executors Spark on K8s had to be fixed Executor 2 node B Executor 1 node A Datanode 1 Datanode 2 SLOW FAST
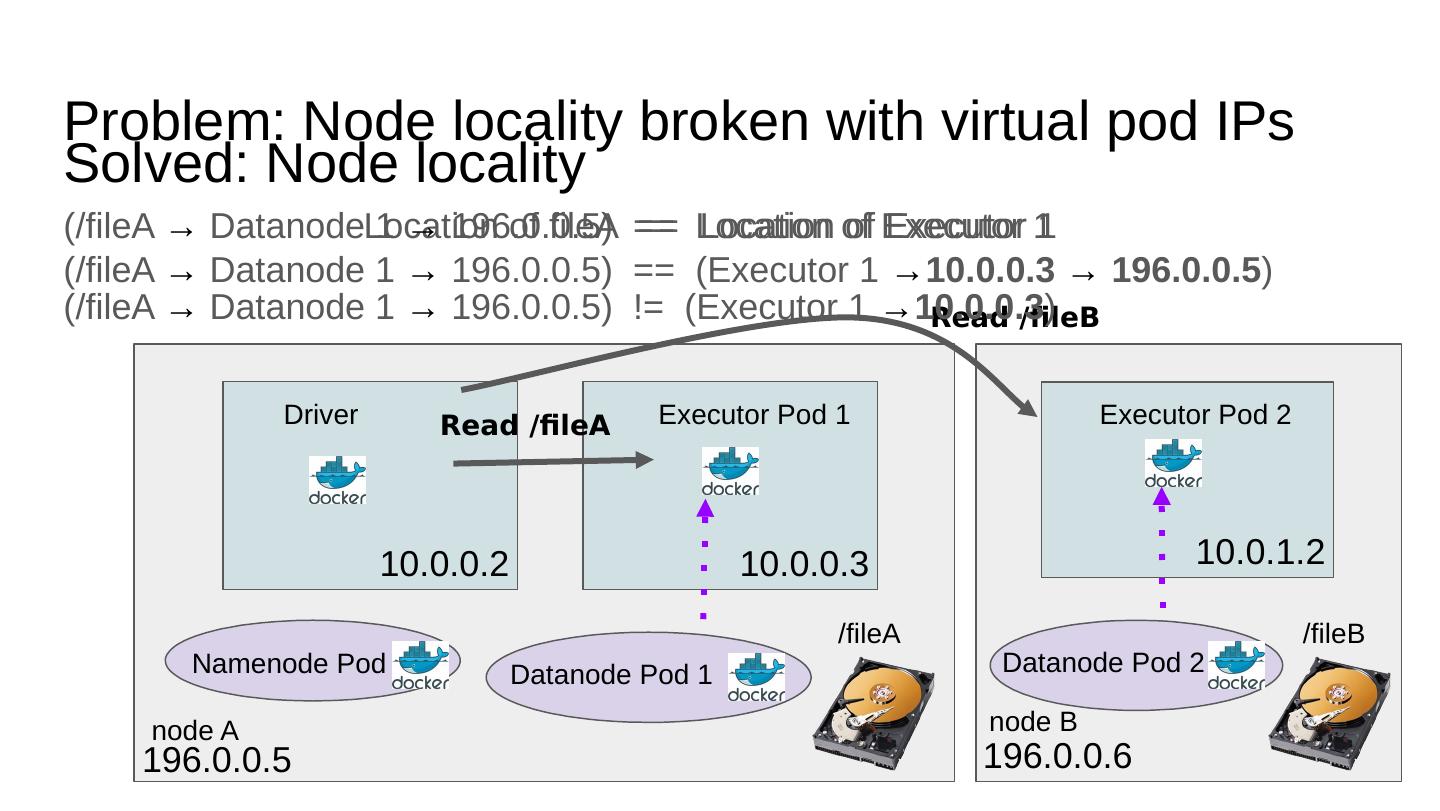
25 .Problem: Node locality broken with virtual pod IPs Executor Pod 2 10.0.1.2 Driver Executor Pod 1 10.0.0.2 10.0.0.3 Location of fileA == Location of Executor 1 Read /fileA Read /fileB /fileA /fileB node A 196.0.0.5 node B 196.0.0.6 Datanode Pod 1 Datanode Pod 2 Namenode Pod (/fileA → Datanode 1 → 196.0.0.5) == Location of Executor 1 (/fileA → Datanode 1 → 196.0.0.5) ! = (Executor 1 → 10.0.0.3 ) (/fileA → Datanode 1 → 196.0.0.5) == (Executor 1 → 10.0.0.3 → 196.0.0.5 ) Solved: Node locality
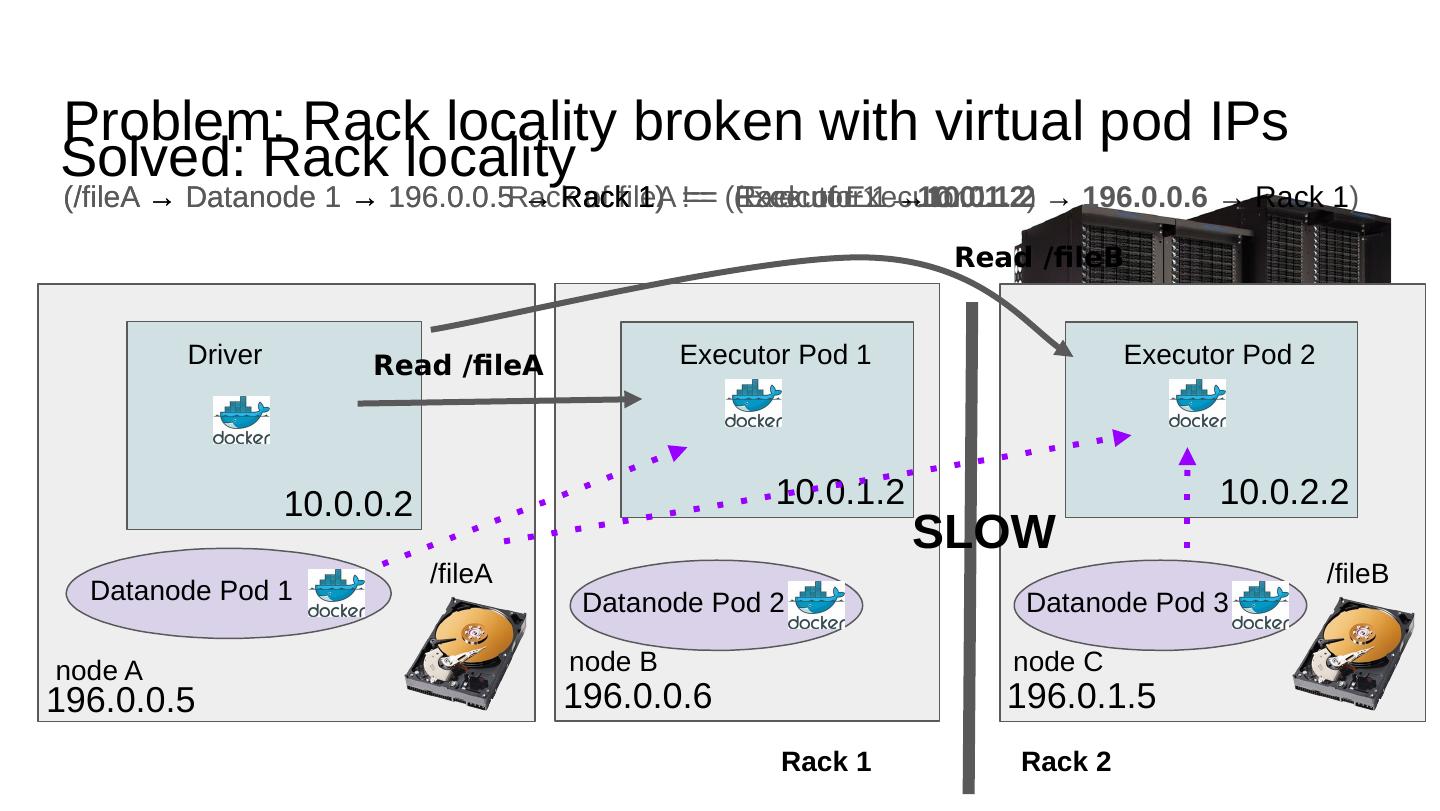
26 .Problem: Rack locality broken with virtual pod IPs Executor Pod 1 10.0.1.2 Driver 10.0.0.2 Read /fileA /fileA node A 196.0.0.5 node B 196.0.0.6 Datanode Pod 1 Datanode Pod 2 (/fileA → Datanode 1 → 196.0.0.5 → Rack 1 ) != (Executor 1 → 10.0.1.2 ) Executor Pod 2 10.0.2.2 Read /fileB /fileB node C 196.0.1.5 Datanode Pod 3 Rack 1 Rack 2 Rack of fileA == Rack of Executor 1 (/fileA → Datanode 1 → 196.0.0.5 → Rack 1 ) == (Executor 1 → 10.0.1.2 → 196.0.0.6 → Rack 1 ) SLOW Solved: Rack locality
27 .Solved: Node preference Hey K8s, I’d like node A much more for my executors Driver Executor Pod 1 10.0.0.2 10.0.0.3 /fileA node A 196.0.0.5 node B 196.0.0.6 Datanode Pod 1 Datanode Pod 2 /fileB Executor Pod 2 10.0.0.4 Node affinity
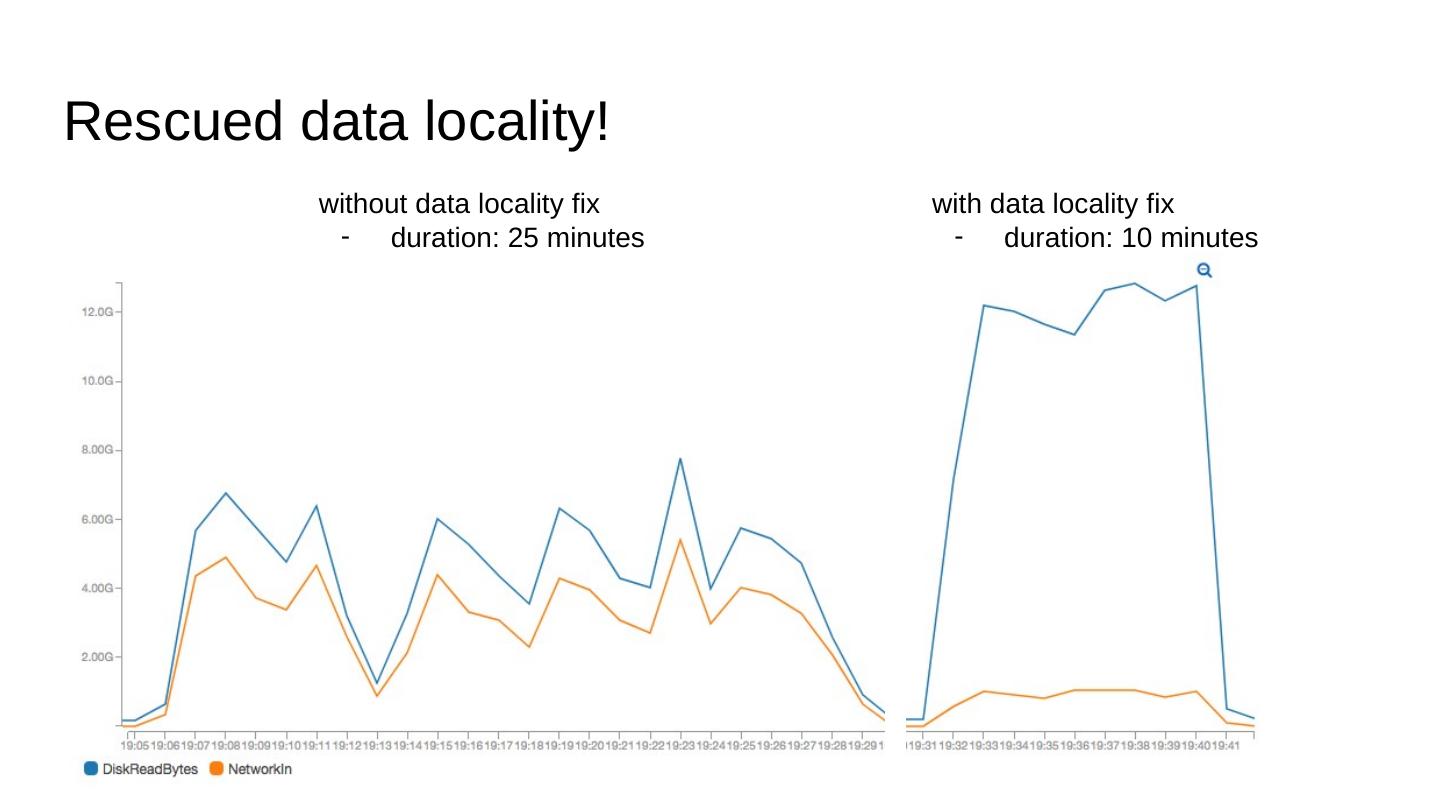
28 .Rescued data locality! with data locality fix duration: 10 minutes without data locality fix duration: 25 minutes
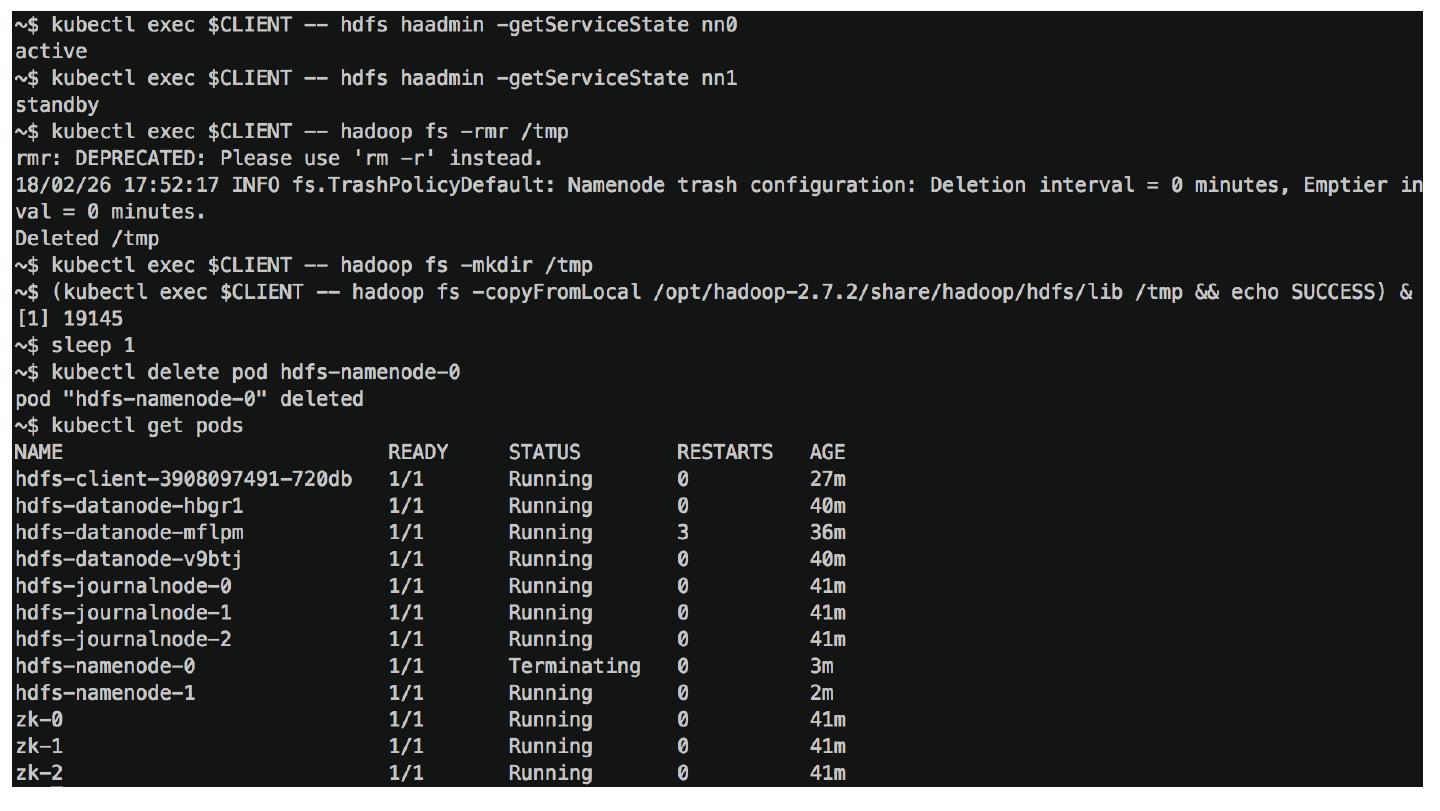
29 .Demo - Namenode HA Source code in github.com/apache-spark-on-k8s/kubernetes-HDFS/pull/33 Launch HDFS pods ( 8x fast-forward ) Copy data while killing a namenode ( normal-speed , slow-motion )
相关推荐
3秒后跳转登录页面
去登陆

