






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Speeding up deep learning service on cloud with GPU and
深度学习需要大量的计算力,在云端往往可以利用共享GPU完成更大算力需求,但是这会碰到很多架构和性能问题,来自IBM的研究人员对于这些问题进行了梳理,并提出自己的解决方案和思路。
展开查看详情
1 .Speeding up Deep Learning Services: When GPUs meet Container Clouds Dr. Seetharami Seelam & Dr. Yubo Li Research Staff Members IBM Research 1 GPU Tech Conference: San Jose, CA – May 10, 2017
2 . Outline • Who are we • Why should you listen to us • What problems are we trying to solve • Challenges with delivering DL on Cloud • What have we done in Mesos and Kubernetes • What is left to do 2 • How can you help IBM 5/8/17
3 . Who are we Dr. Yubo Li(李玉博) Dr. Seetharami Seelam Dr. Seelam is a Research Staff Member at the T. J. Dr. Yubo Li is a Research Staff Member at IBM Watson Research Center. He is an expert at delivering Research, China. He is the architect of the GPU hardware, middleware, applications as-a-service acceleration and deep learning service on using containers. He delivered Autoscaling, Business SuperVessel, an open-access cloud running Rules, Containers on Bluemix and multiple others OpenStack on OpenPOWER machines. He is internally. currently working on GPU support for several cloud container technologies, including Mesos, Kubernetes, 3Marathon and OpenStack. IBM 5/8/17 2
4 . Why should you listen to us • We have multiple years of developing, optimizing, and operating container clouds • Heterogeneous HW (POWER and x86) • Long running and batch jobs • OpenStack, Docker, Mesos, Kubernetes • Container clouds with Accelerators (GPUs) 4 IBM 5/8/17
5 . What problems are we trying to solve • Enable Deep Learning in the Cloud • Need flexible access to hardware (GPUs) • Training times in hours, days, weeks, months • Long running inferencing services • Support old, new and emerging frameworks • Share hardware among multiple workloads and users 5 IBM Speech 5/8/17 Vision
6 . DL in the Cloud: State-of-the-art • Historically DL is on-prem infrastructure and SW stack – high-performance environment • Baremetal GPU systems (x86 and POWER), Ethernet, IB network connectivity, GPFS • Spectrum LSF, MPI and RDMA support, single SW stack • Cloud – Frees researchers & developers from infrastructure & SW Stack • All infrastructure from Cloud as services: GPUs, object store, NFS, SDN, etc, • Job submission with APIs: Torch, Caffe, Tensorflow, Theano • 24/7 service, elastic and resilient 6 Appropriate visibility and control • IBM 5/8/17
7 .Challenges with DL on Cloud • Data, data, data, data, … • Access to different hardware and accelerators (GPU, IB, … ) • Support for different application models • Visibility and control of infrastructure • Dev and Ops challenges with 24/7 state full service 7 IBM 5/8/17
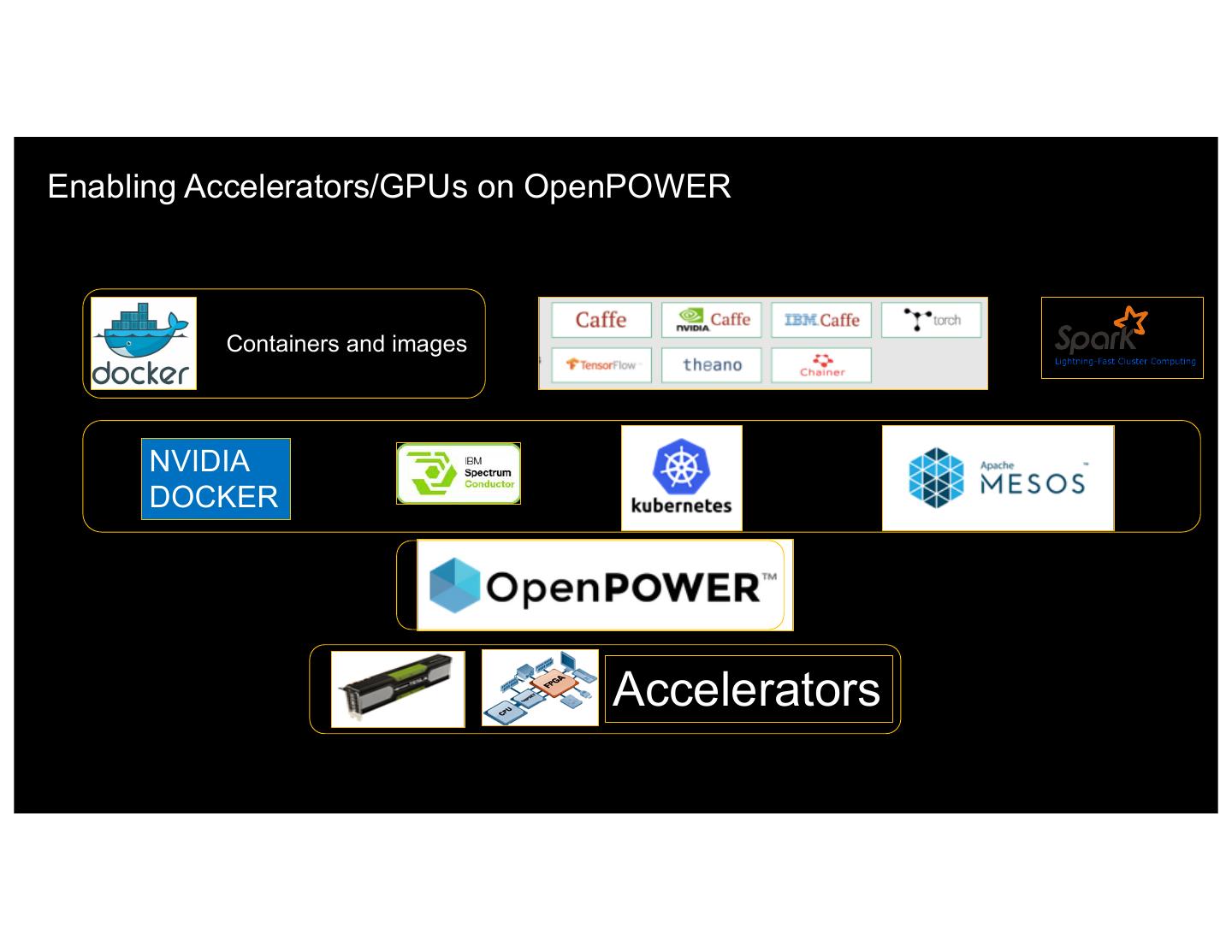
8 .Journey started in 2016… promised to deliver DL on Cloud • Excellent promise, go ahead and built a DL cloud service • Container support GPU: minimal or non-existent • The idea could have died on day 1 but failure is not an option … • We chose containers with Mesos and Kubernetes to address some of these challenges • Developed and operated Mesos and Kubernetes based GPU Clouds for over a year • What follows are lessons learned from this experience 8 IBM 5/8/17
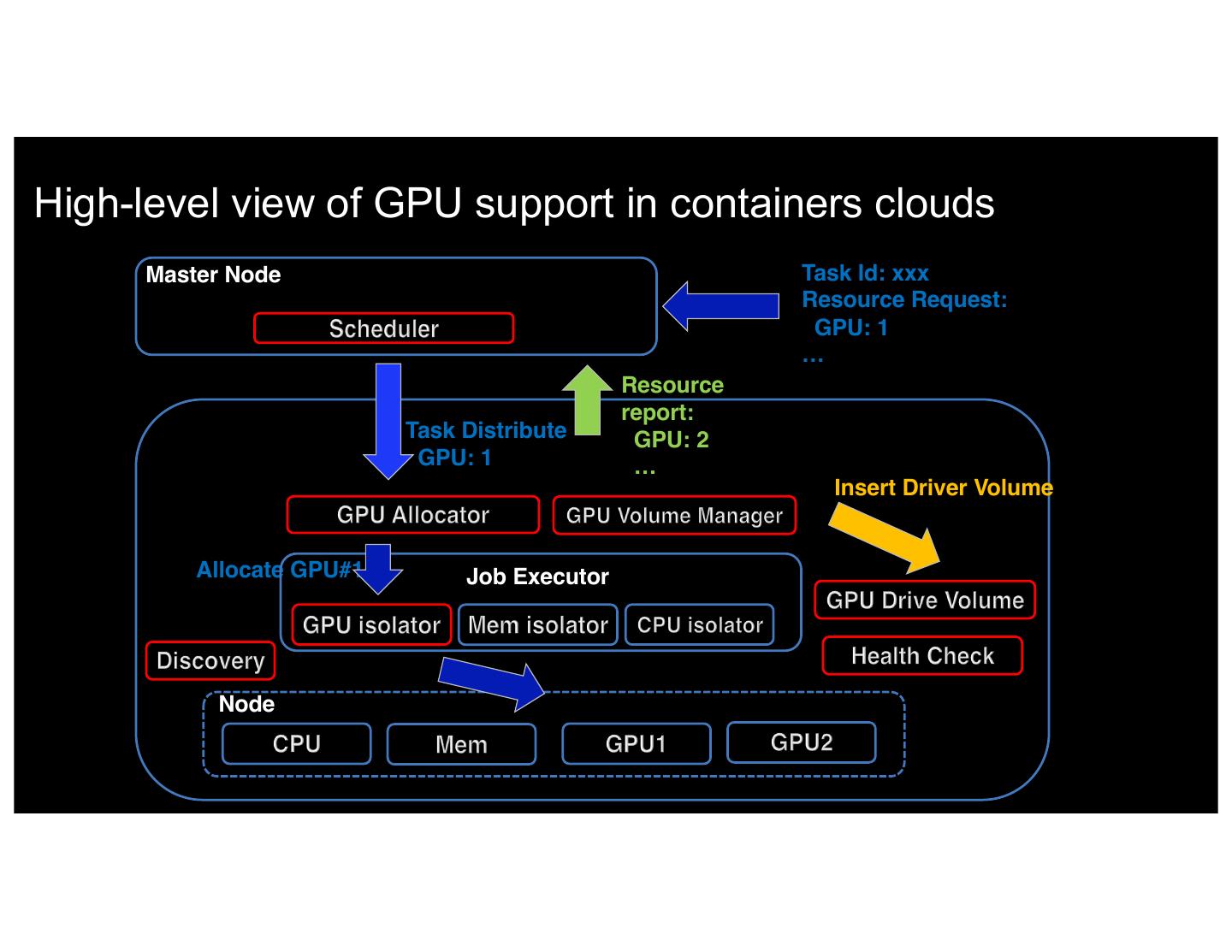
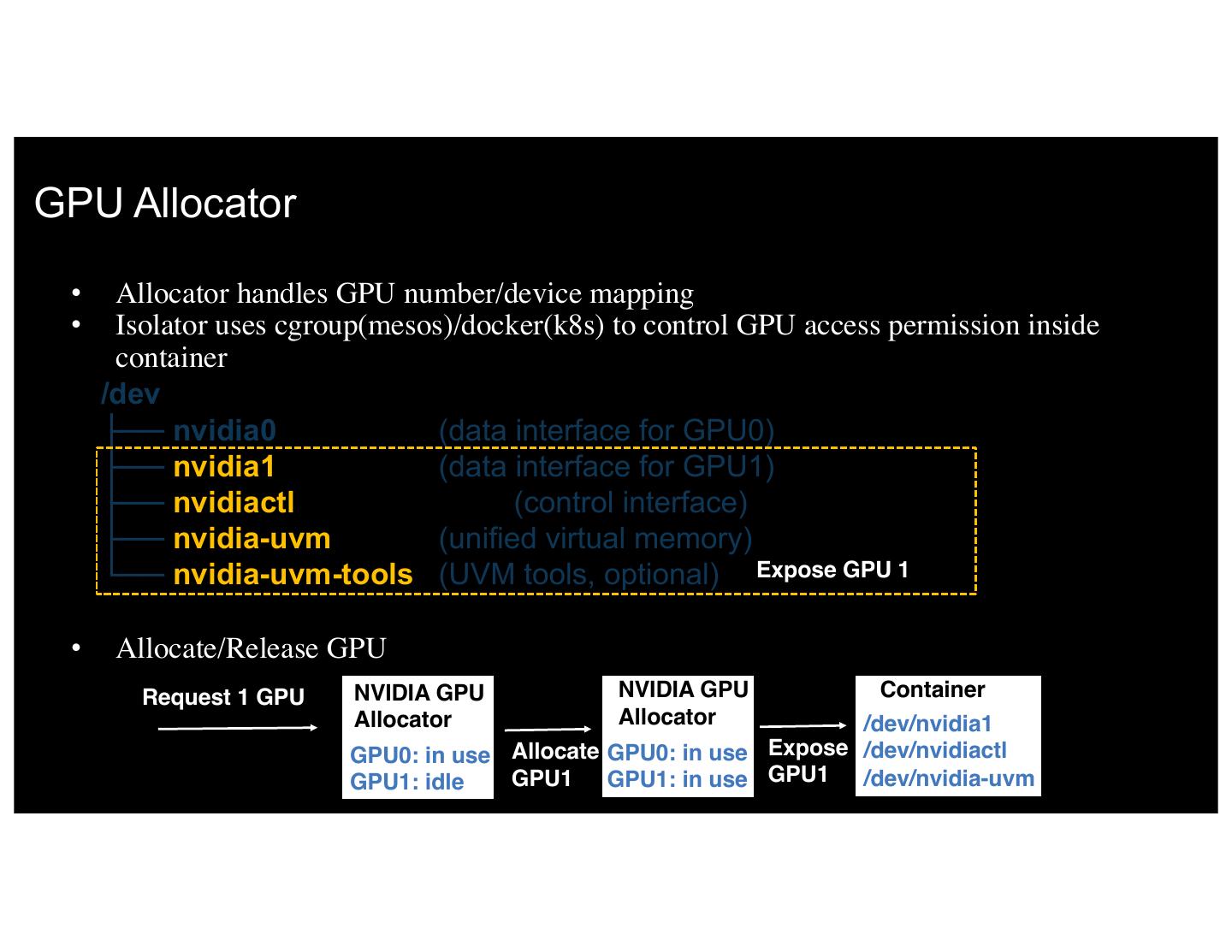
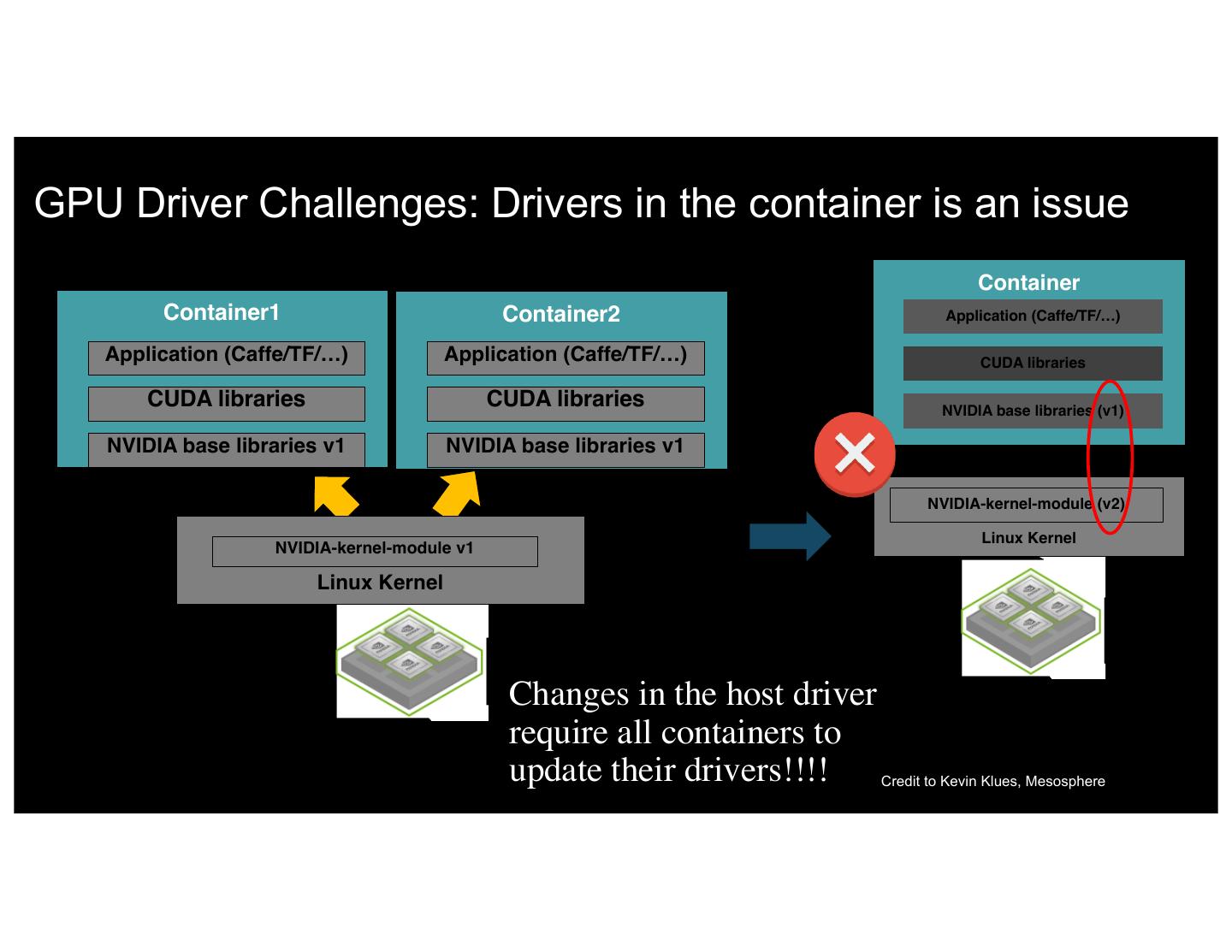
9 .DL on Containers: DevOps challenges • Multiple GPUs per node –> multiple containers per node: need to maintain GPU <–> Container mapping (GPU Allocator) • Images need NVIDIA Drivers: makes them non-portable (Volume Manager) • Cluster quickly becomes heterogeneous (K80, M60, P100…): need to be able to pick GPU type (GPU Discovery) • Fragmentation of GPUs is a real problem (Priority placement) • Like everything else GPUs fail à must identify and remove unhealthy GPUs from scheduling (Liveness check) 9 • IBM control, Visibility, 5/8/17 and sharing (to be done)
10 .High-level view of GPU support in containers clouds Master Node Task Id: xxx Resource Request: GPU: 1 … Resource report: Worker Node Task Distribute GPU: 2 GPU: 1 … Insert Driver Volume Allocate GPU#1 Job Executor Node IBM 5/8/17 11
11 .GPU Allocator • Allocator handles GPU number/device mapping • Isolator uses cgroup(mesos)/docker(k8s) to control GPU access permission inside container /dev ├── nvidia0 (data interface for GPU0) ├── nvidia1 (data interface for GPU1) ├── nvidiactl (control interface) ├── nvidia-uvm (unified virtual memory) └── nvidia-uvm-tools (UVM tools, optional) Expose GPU 1 • Allocate/Release GPU Request 1 GPU NVIDIA GPU NVIDIA GPU Container Allocator Allocator /dev/nvidia1 GPU0: in use Allocate GPU0: in use Expose /dev/nvidiactl 11 IBM 5/8/17idle GPU1: GPU1 GPU1: in use GPU1 12 /dev/nvidia-uvm
12 .GPU Driver Challenges: Drivers in the container is an issue Container Container1 Container2 Application (Caffe/TF/…) Application (Caffe/TF/…) Application (Caffe/TF/…) CUDA libraries CUDA libraries CUDA libraries NVIDIA base libraries (v1) NVIDIA base libraries v1 NVIDIA base libraries v1 NVIDIA-kernel-module (v2) Linux Kernel NVIDIA-kernel-module v1 Linux Kernel Changes in the host driver require all containers to 12 IBM 5/8/17 update their drivers!!!! Credit to Kevin Klues, Mesosphere
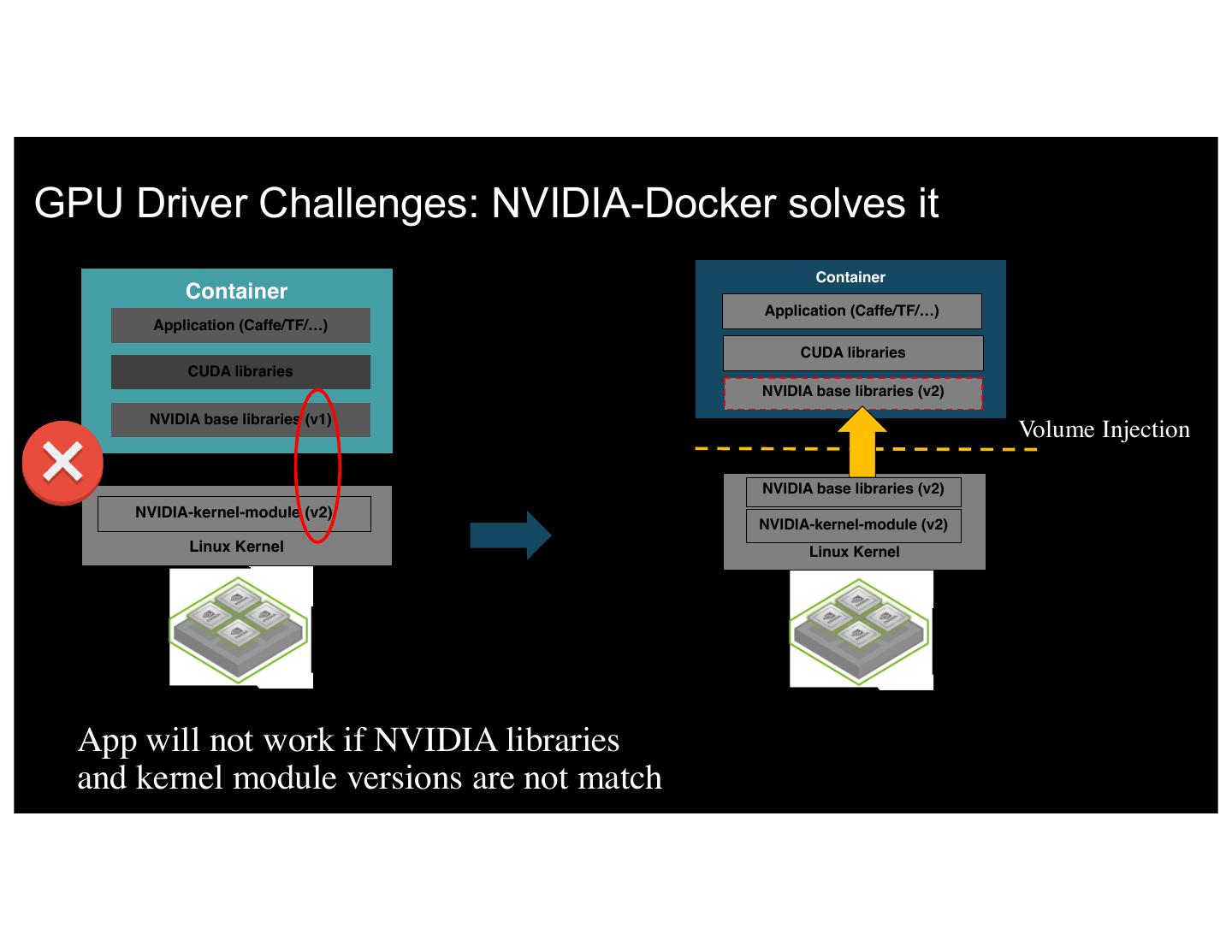
13 .GPU Driver Challenges: NVIDIA-Docker solves it Container Container Application (Caffe/TF/…) Application (Caffe/TF/…) CUDA libraries CUDA libraries NVIDIA base libraries (v2) NVIDIA base libraries (v1) Volume Injection NVIDIA base libraries (v2) NVIDIA-kernel-module (v2) NVIDIA-kernel-module (v2) Linux Kernel Linux Kernel App will not work if NVIDIA libraries and kernel module versions are not match
14 .GPU Volume Manager •Mimic functionality of nvidia-docker-plugin • Finds all standard NVIDIA libraries / binaries on the host and consolidates them into a single place. Image label: /var/lib/mesos/volumes com.nvidia.volumes.needed = nvidia_driver └── nvidia_XXX.XX (version number) ├── bin GPU container ├── lib Inject └── lib64 /usr/local/nvidia • Inject volume with read-only (“ro”) to container if needed 14 IBM 5/8/17
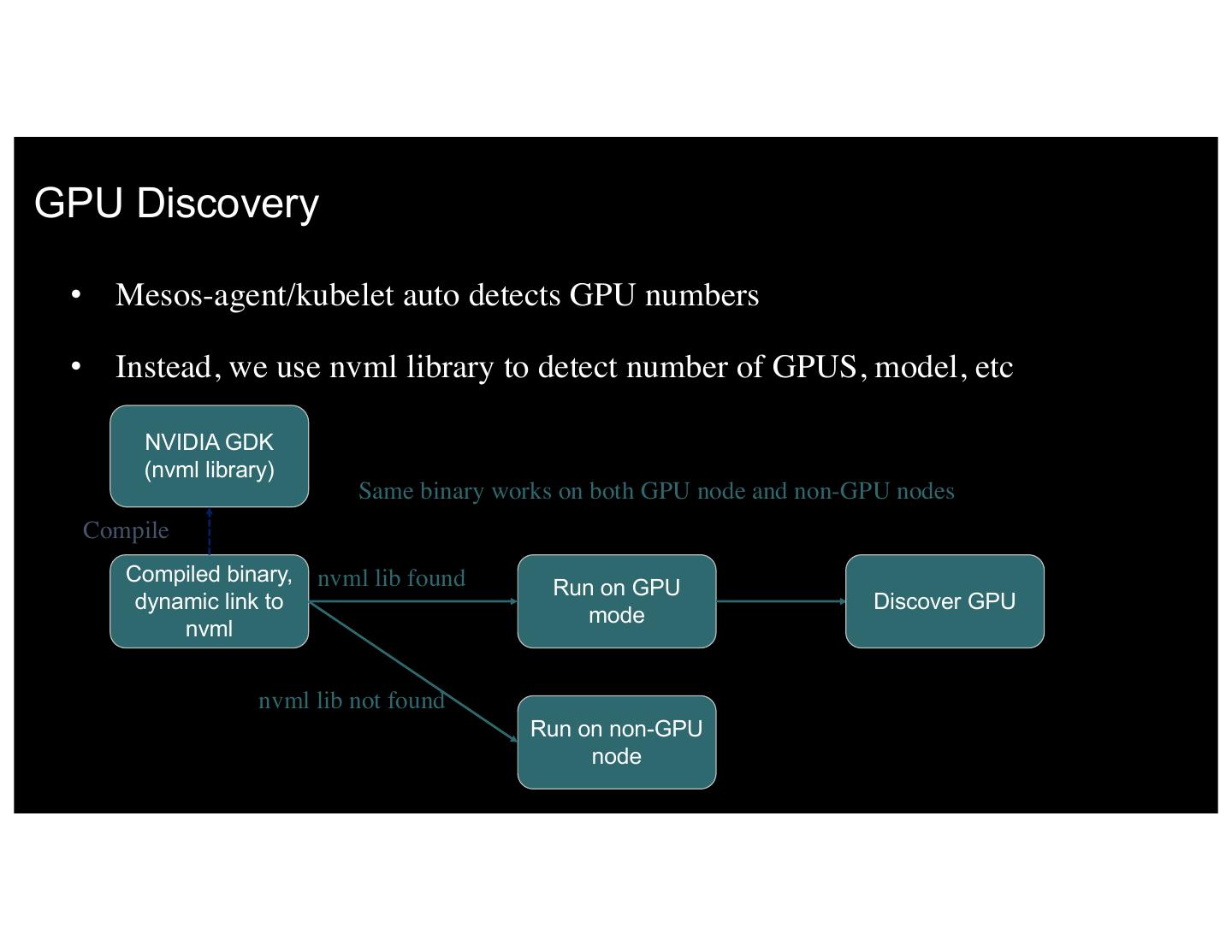
15 .GPU Discovery • Mesos-agent/kubelet auto detects GPU numbers • Instead, we use nvml library to detect number of GPUS, model, etc NVIDIA GDK (nvml library) Same binary works on both GPU node and non-GPU nodes Compile Compiled binary, nvml lib found Run on GPU dynamic link to Discover GPU mode nvml nvml lib not found Run on non-GPU node 15 IBM 5/8/17 15
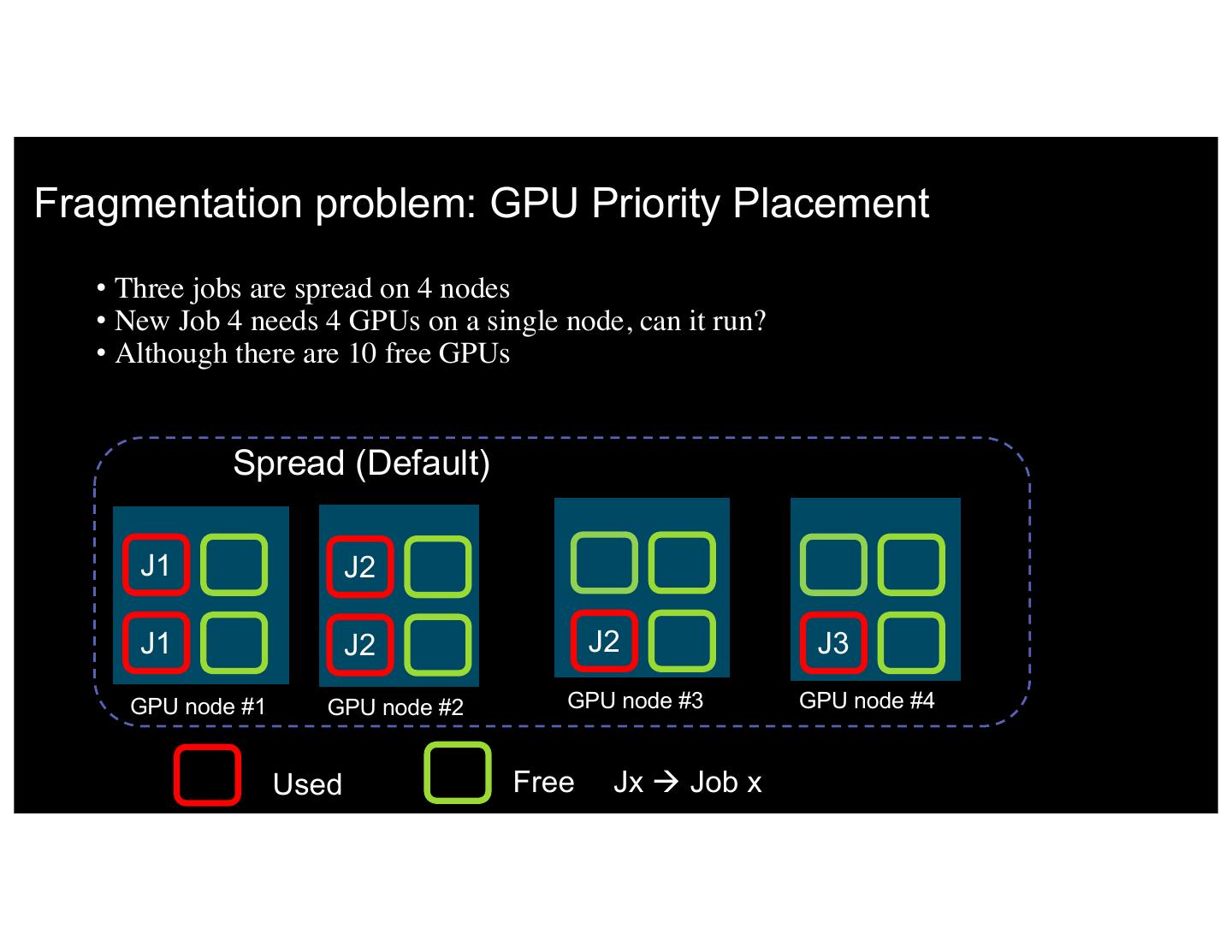
16 .Fragmentation problem: GPU Priority Placement • Three jobs are spread on 4 nodes • New Job 4 needs 4 GPUs on a single node, can it run? • Although there are 10 free GPUs Spread (Default) J1 J2 J1 J2 J2 J3 GPU node #1 GPU node #2 GPU node #3 GPU node #4 16 IBM 5/8/17 Used Free Jx à Job x 17
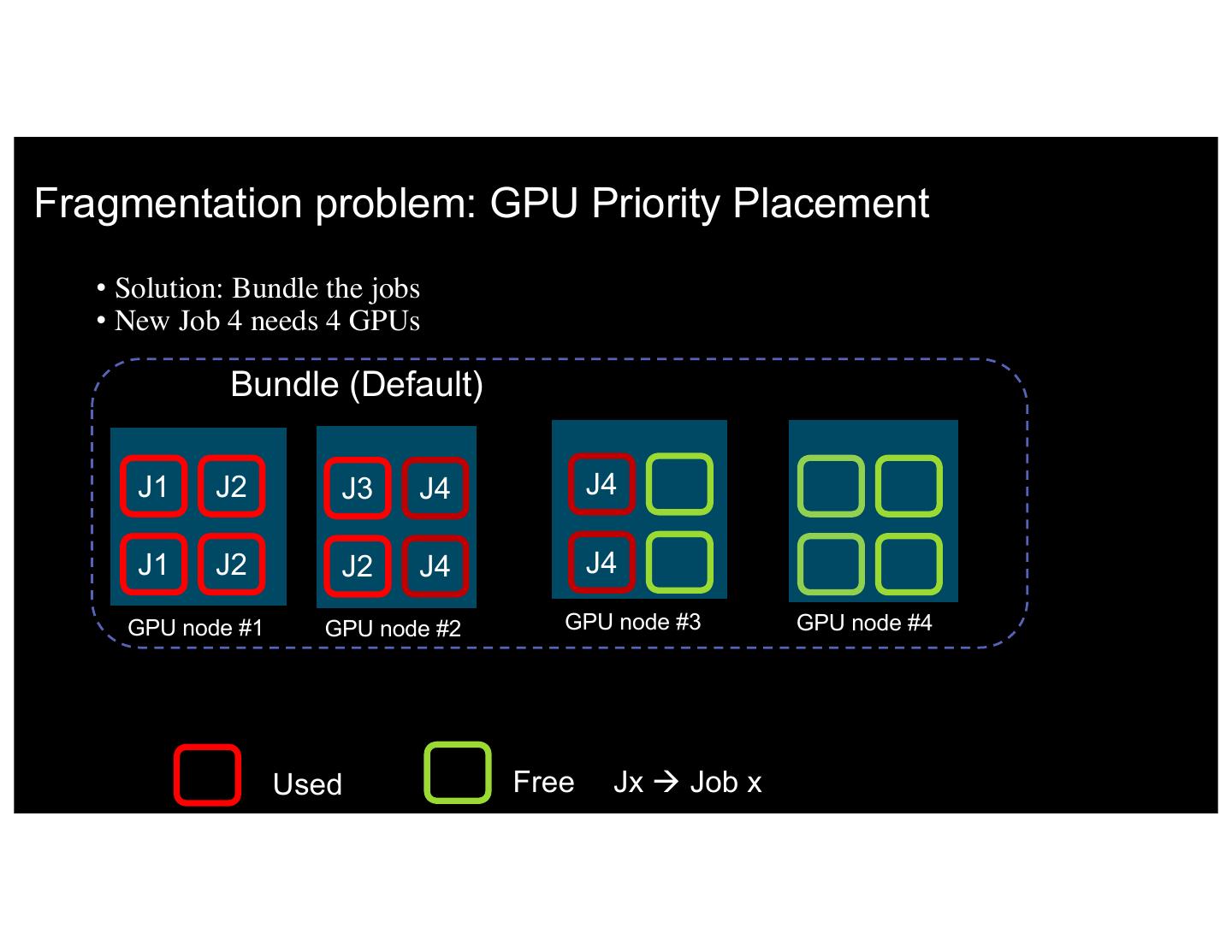
17 .Fragmentation problem: GPU Priority Placement • Solution: Bundle the jobs • New Job 4 needs 4 GPUs Bundle (Default) J1 J2 J3 J4 J4 J1 J2 J2 J4 J4 GPU node #1 GPU node #2 GPU node #3 GPU node #4 17 IBM 5/9/17 Used Free Jx à Job x 17
18 .Fragmentation problem: GPU Priority Placement • Solution: Bundle the jobs • New Job 4 needs 4 GPUs on a single node Bundle (Default) J1 J2 J3 J4 J4 J1 J2 J2 J4 J4 GPU node #1 GPU node #2 GPU node #3 GPU node #4 18 IBM 5/9/17 Used Free Jx à Job x 18
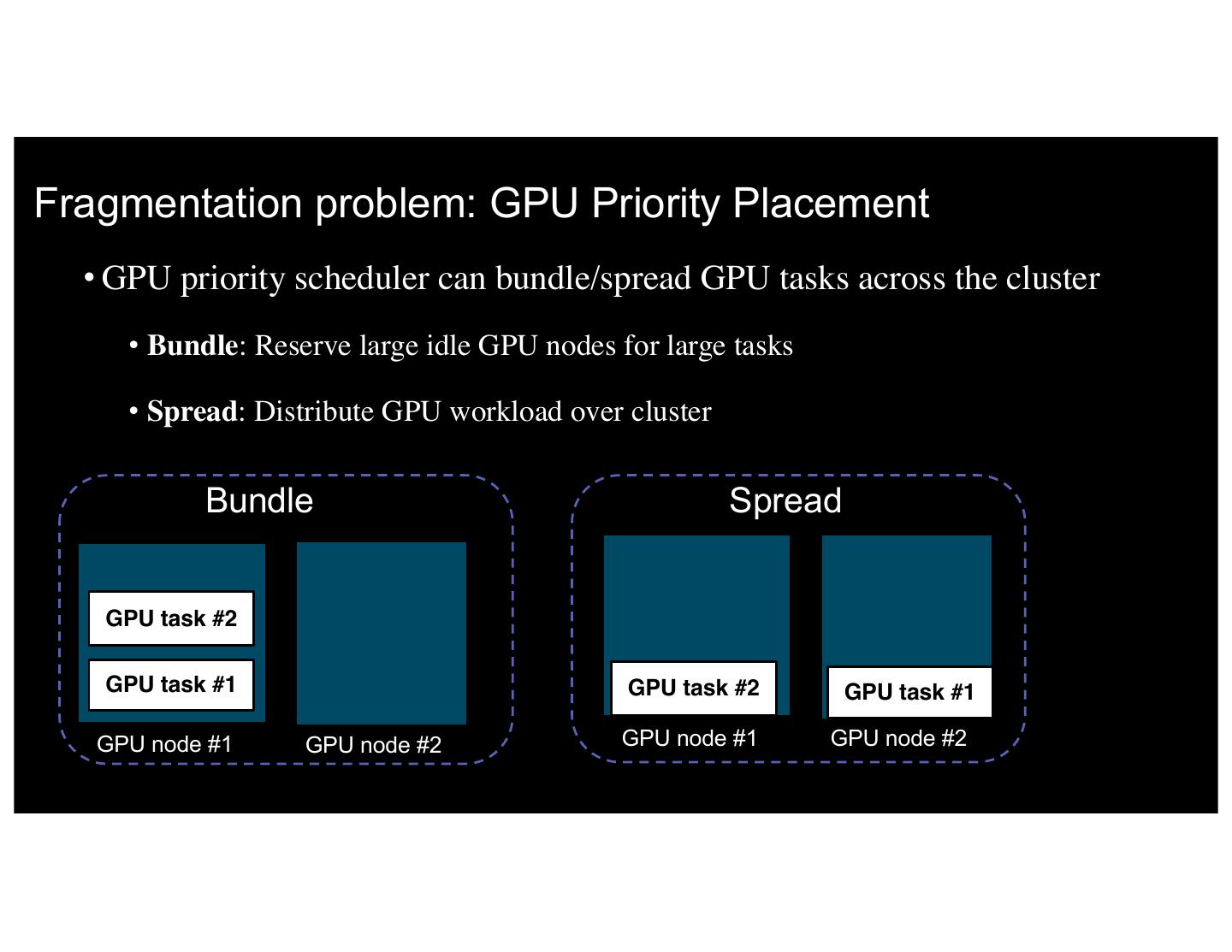
19 .Fragmentation problem: GPU Priority Placement • GPU priority scheduler can bundle/spread GPU tasks across the cluster • Bundle: Reserve large idle GPU nodes for large tasks • Spread: Distribute GPU workload over cluster Bundle Spread GPU task #2 GPU task #1 GPU task #2 GPU task #1 GPU node #1 GPU node #2 GPU node #1 GPU node #2 19 IBM 5/9/17 19
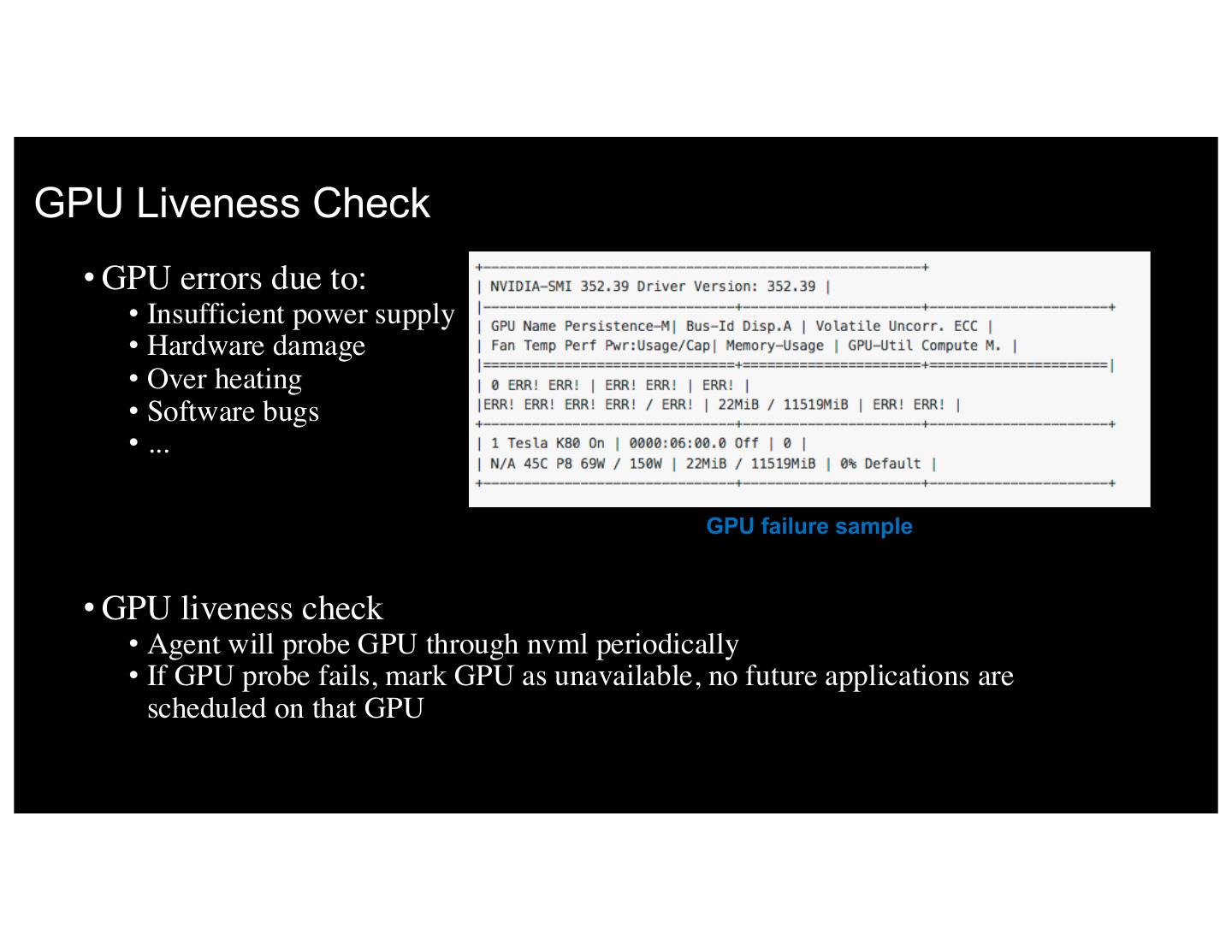
20 .GPU Liveness Check • GPU errors due to: • Insufficient power supply • Hardware damage • Over heating • Software bugs • ... GPU failure sample • GPU liveness check • Agent will probe GPU through nvml periodically • If GPU probe fails, mark GPU as unavailable, no future applications are scheduled on that GPU 20 IBM 5/8/17
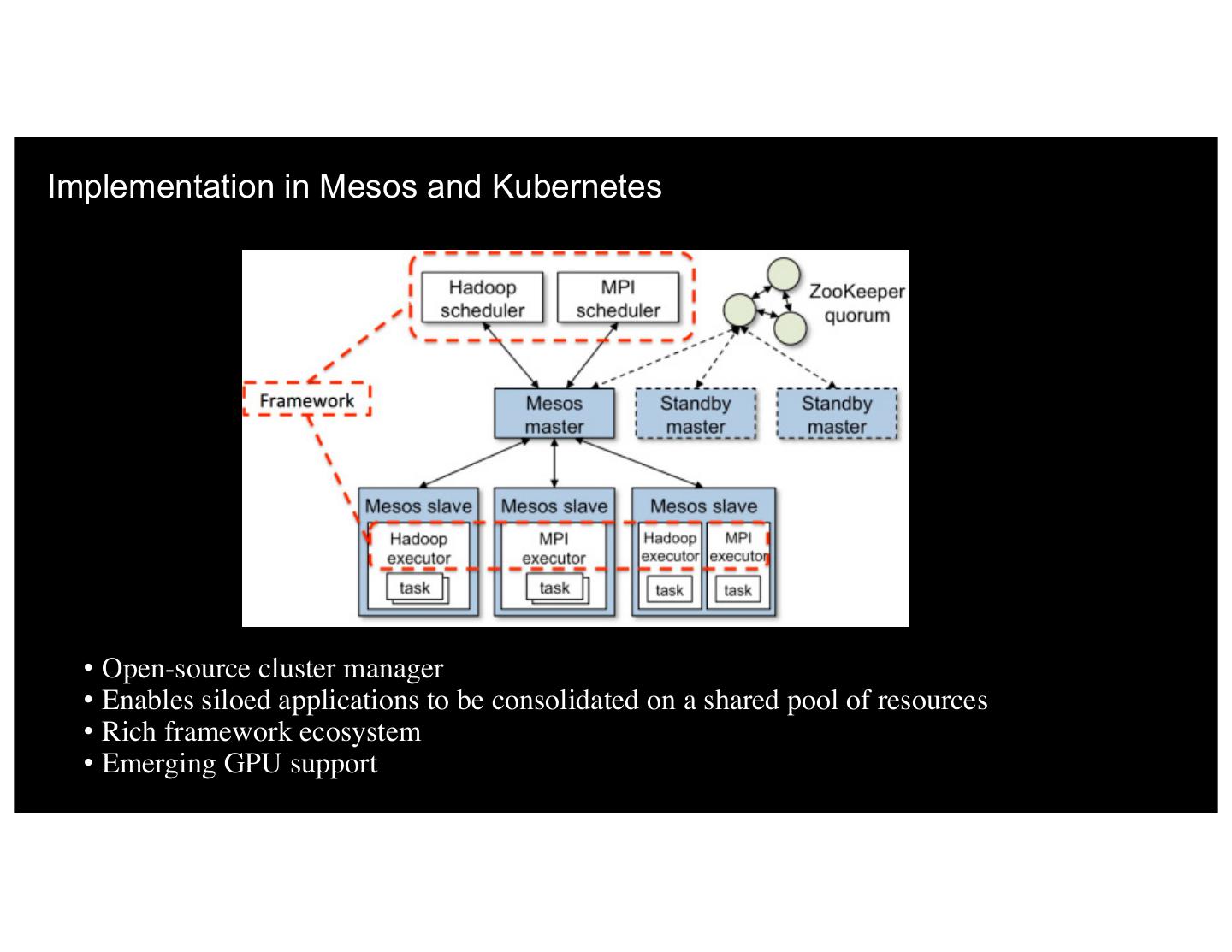
21 .Implementation in Mesos and Kubernetes • Open-source cluster manager • Enables siloed applications to be consolidated on a shared pool of resources • Rich framework ecosystem 21• Emerging GPU support
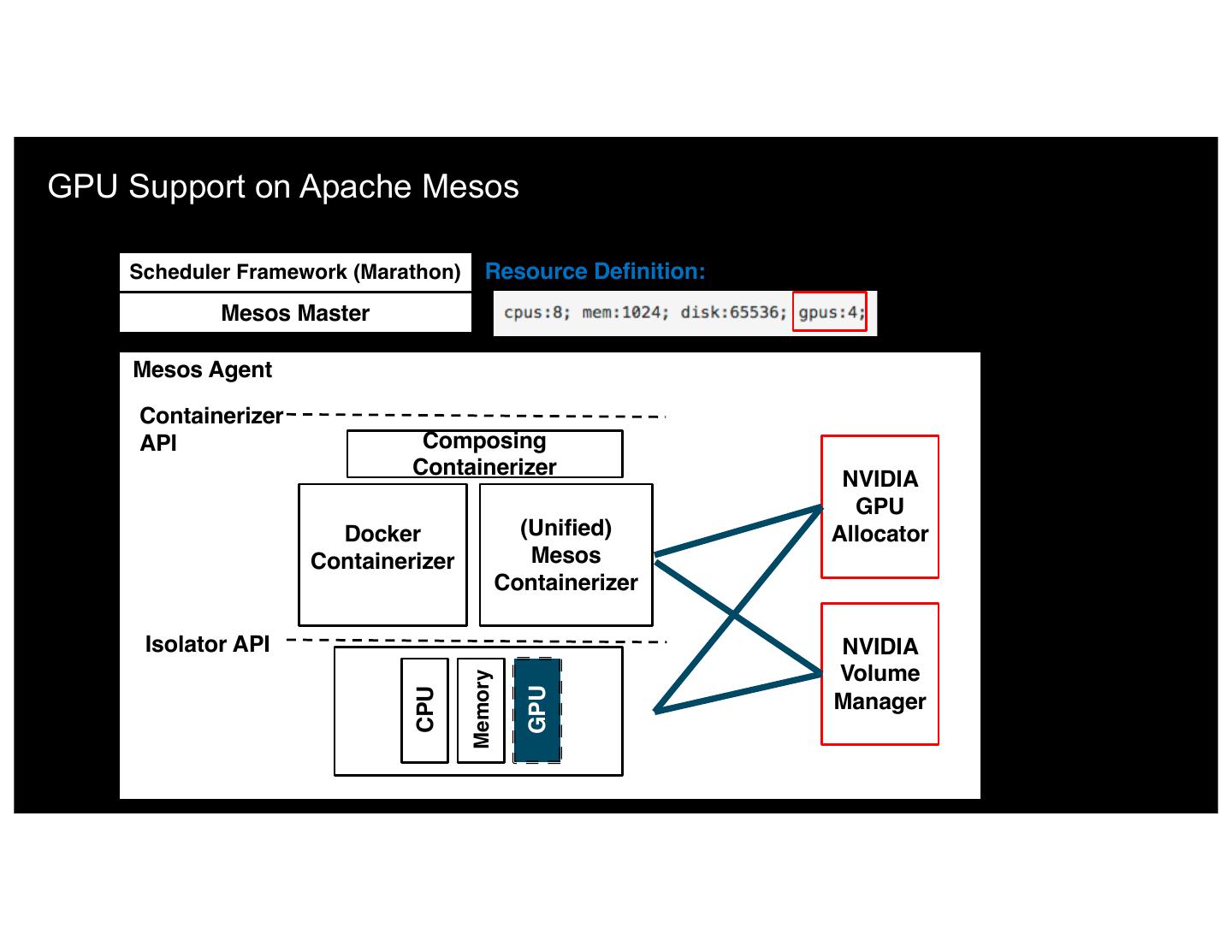
22 .GPU Support on Apache Mesos Scheduler Framework (Marathon) Resource Definition: Mesos Master Mesos Agent Containerizer API Composing Containerizer NVIDIA GPU Docker (Unified) Allocator Containerizer Mesos Containerizer Isolator API NVIDIA Volume Memory GPU CPU Manager 22
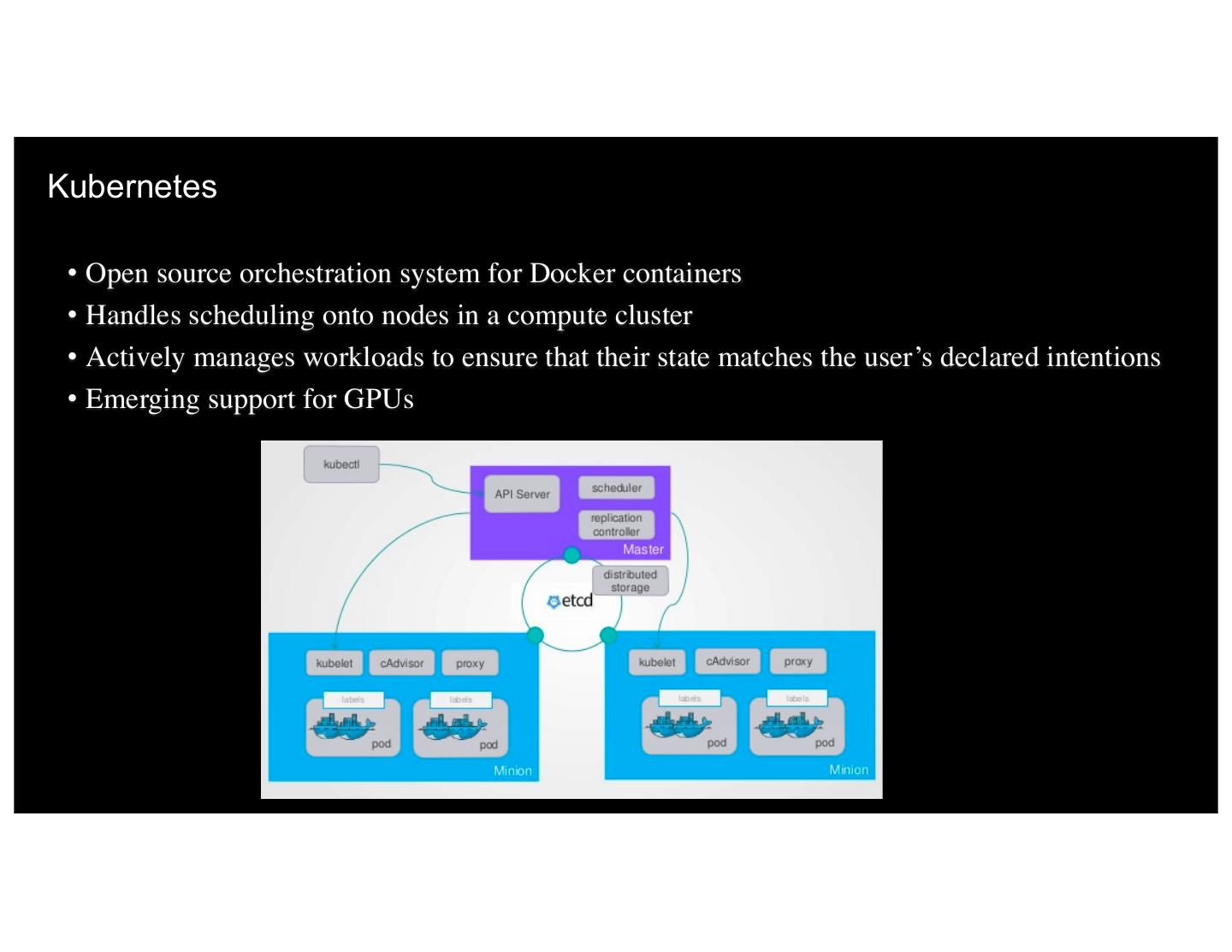
23 .Kubernetes • Open source orchestration system for Docker containers • Handles scheduling onto nodes in a compute cluster • Actively manages workloads to ensure that their state matches the user’s declared intentions • Emerging support for GPUs 22
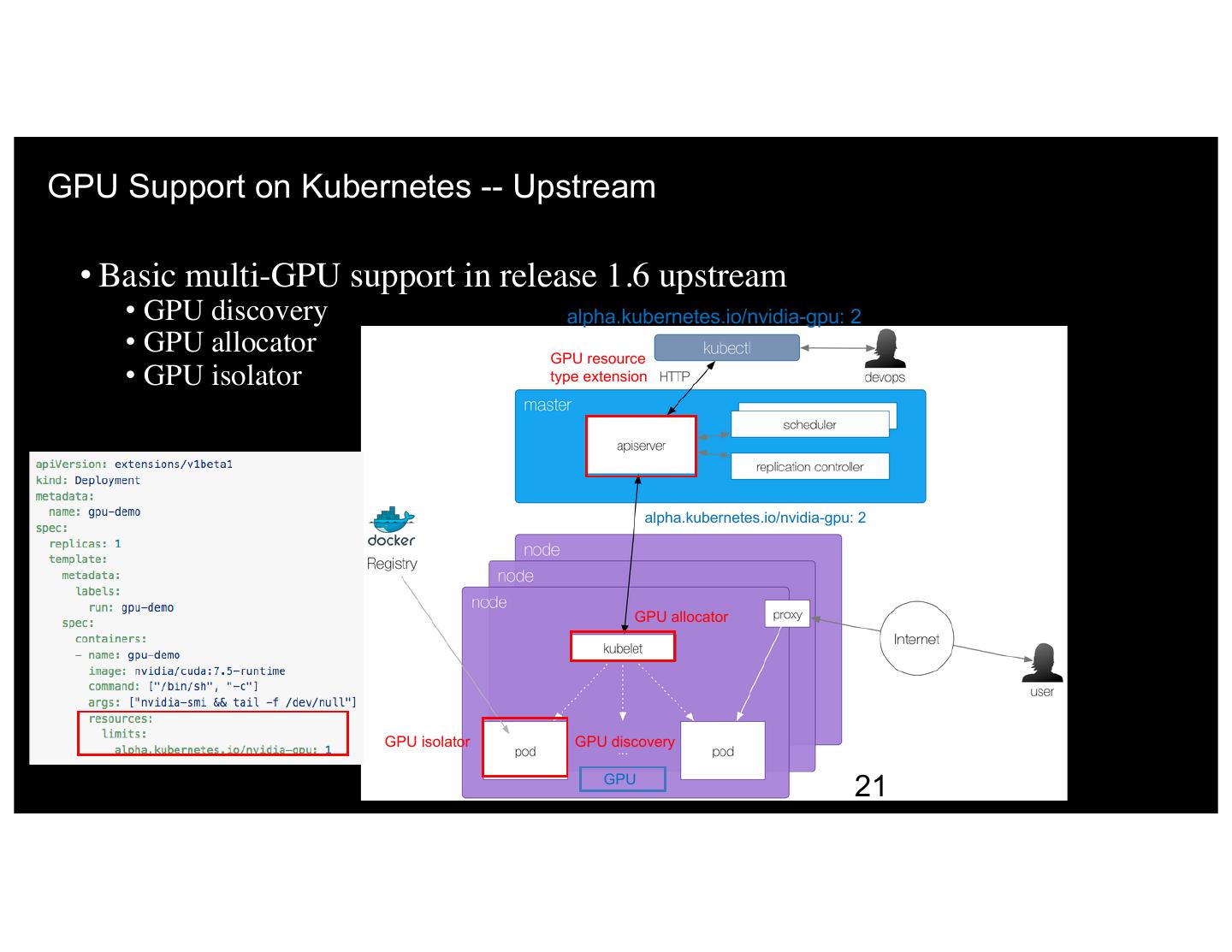
24 .GPU Support on Kubernetes -- Upstream • Basic multi-GPU support in release 1.6 upstream • GPU discovery alpha.kubernetes.io/nvidia-gpu: 2 • GPU allocator GPU resource • GPU isolator type extension alpha.kubernetes.io/nvidia-gpu: 2 GPU allocator GPU isolator GPU discovery GPU 24 21
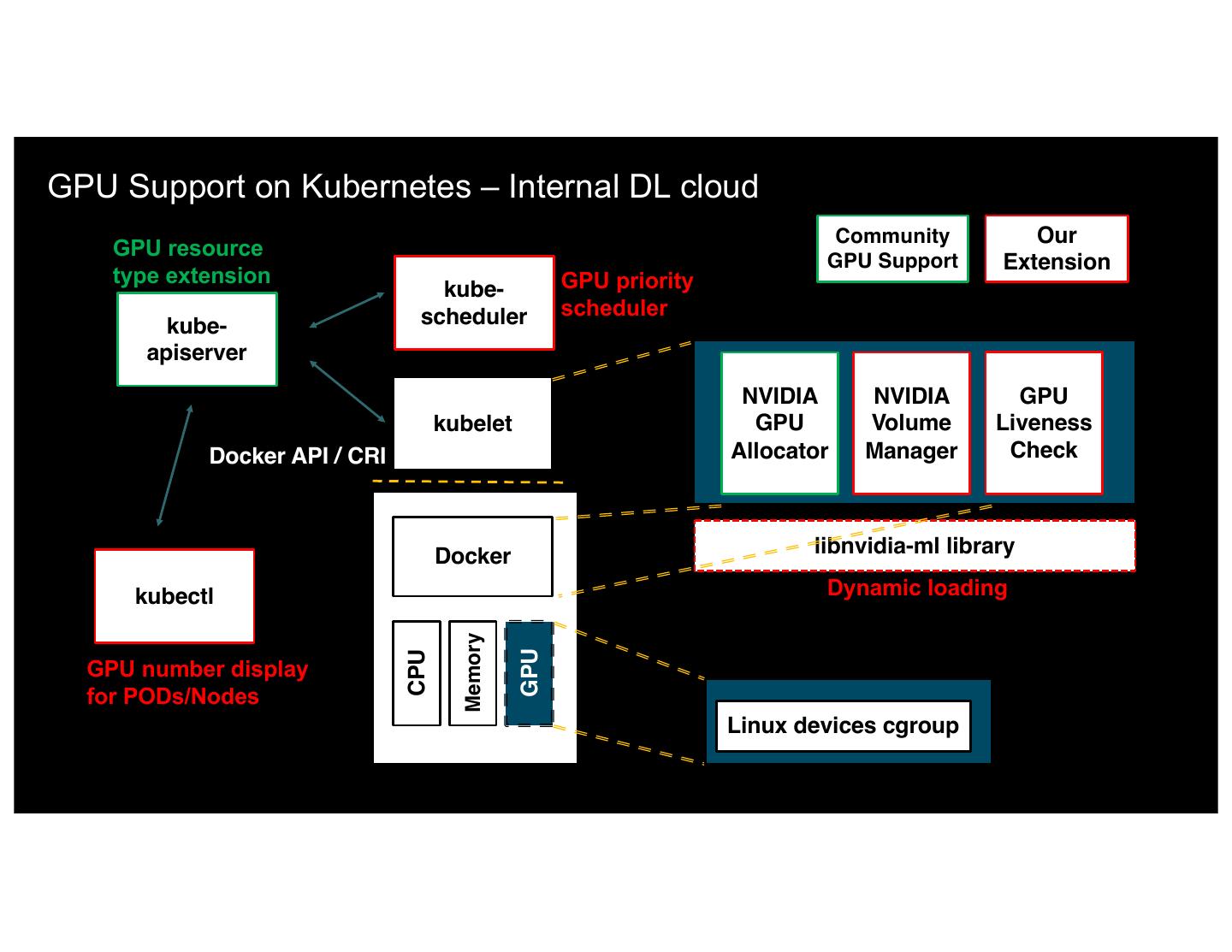
25 .GPU Support on Kubernetes – Internal DL cloud Community Our GPU resource GPU Support Extension type extension GPU priority kube- scheduler scheduler NVIDIA GPU Manager kube- apiserver NVIDIA NVIDIA GPU kubelet GPU Volume Liveness Docker API / CRI Allocator Manager Check Docker libnvidia-ml library kubectl Dynamic loading Memory GPU CPU GPU number display for PODs/Nodes Linux devices cgroup 24
26 .Demo 26
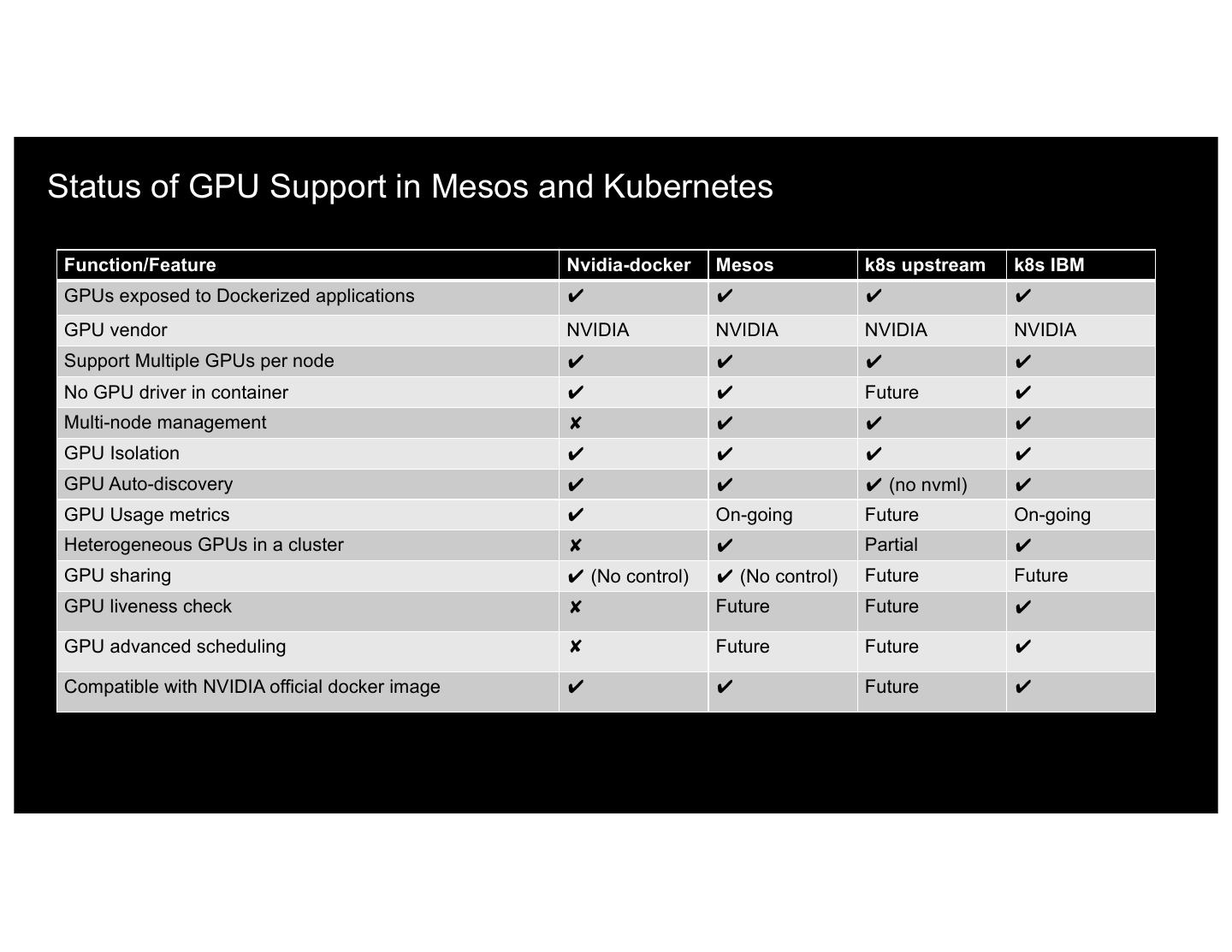
27 .Status of GPU Support in Mesos and Kubernetes Function/Feature Nvidia-docker Mesos k8s upstream k8s IBM GPUs exposed to Dockerized applications ✔ ✔ ✔ ✔ GPU vendor NVIDIA NVIDIA NVIDIA NVIDIA Support Multiple GPUs per node ✔ ✔ ✔ ✔ No GPU driver in container ✔ ✔ Future ✔ Multi-node management ✘ ✔ ✔ ✔ GPU Isolation ✔ ✔ ✔ ✔ GPU Auto-discovery ✔ ✔ ✔ (no nvml) ✔ GPU Usage metrics ✔ On-going Future On-going Heterogeneous GPUs in a cluster ✘ ✔ Partial ✔ GPU sharing ✔ (No control) ✔ (No control) Future Future GPU liveness check ✘ Future Future ✔ GPU advanced scheduling ✘ Future Future ✔ Compatible with NVIDIA official docker image ✔ ✔ Future ✔ 27
28 .Our DL service • Mesos/Marathon GPU support • Support NVIDIA GPU resource management • Developing and operating deep learning and AI Vision internal services • Code contributed back to community • Presentations at MesosCon EU 2016 and MesosCon Asia 2016 • Kubernetes GPU support • Support NVIDIA GPU resource management • Developing and operating deep learning and AI Vision internal services • GPU support in IBM Spectrum Conductor for Containers (CfC) • Engagement with community to bring several of these features 28
29 .IBM Spectrum Conductor for Containers § Community Edition available now! Free to download and use as you wish (optional paid support) • Customer-managed, on-premises Kubernetes offering from IBM on x86 or Power • Simple container based installation with integrated orchestration & resource management • Authorization and access control (built-in user registry or LDAP) • Private Docker registry • Dashboard UI • Metrics and log aggregation • Calico networking • Pre-populated app catalog • GPU support in 1.1; paid support in 1.2 (June) § Learn more and register on our community page: http://ibm.biz/ConductorForContainers Demo on YouTube 29
相关推荐
3秒后跳转登录页面
去登陆

