展开查看详情
1 .Elasticsearch 集群运维实战 Presented by xu peng
2 .Elasticsearch 在数据湖中的地位
5 .Part II Elasticsearch 集群
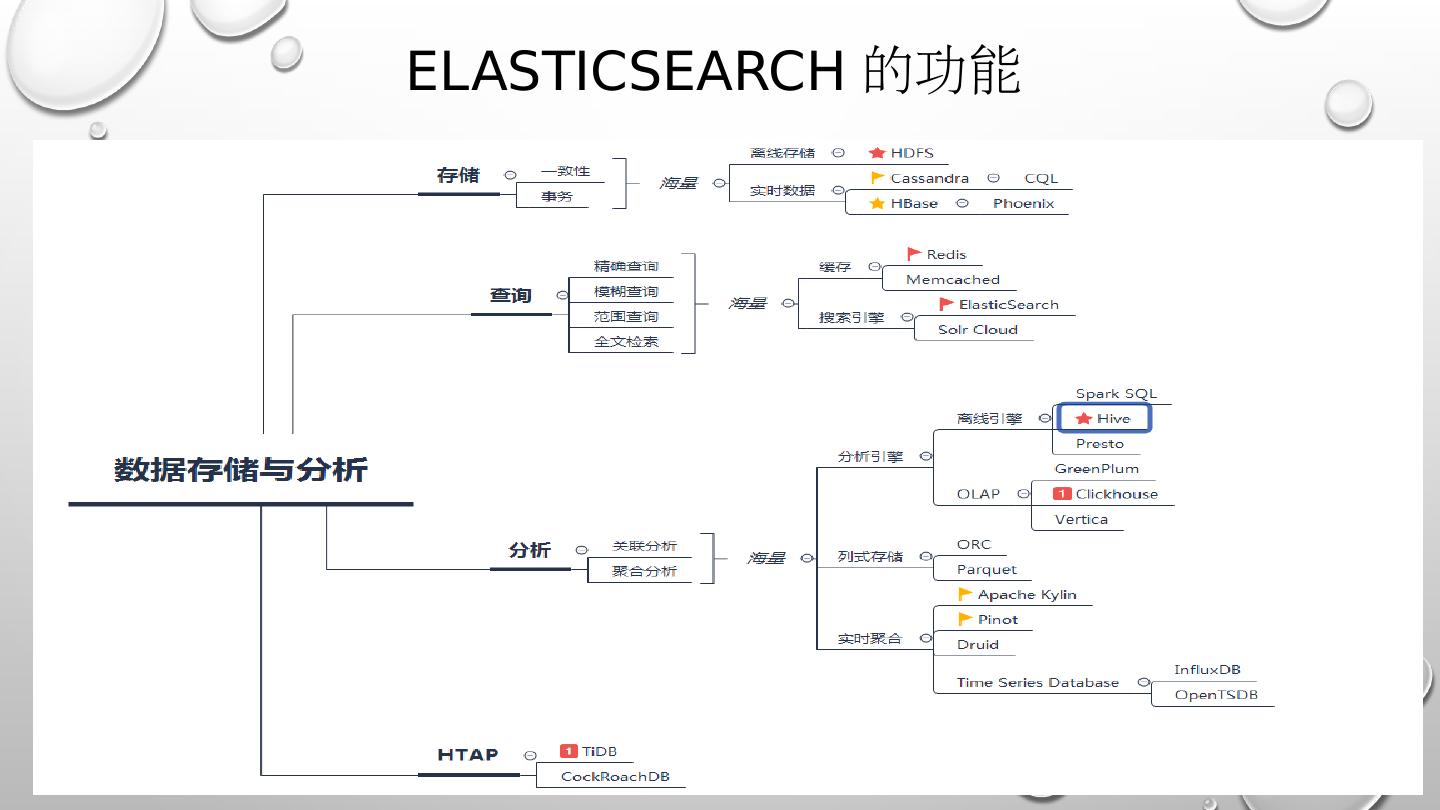
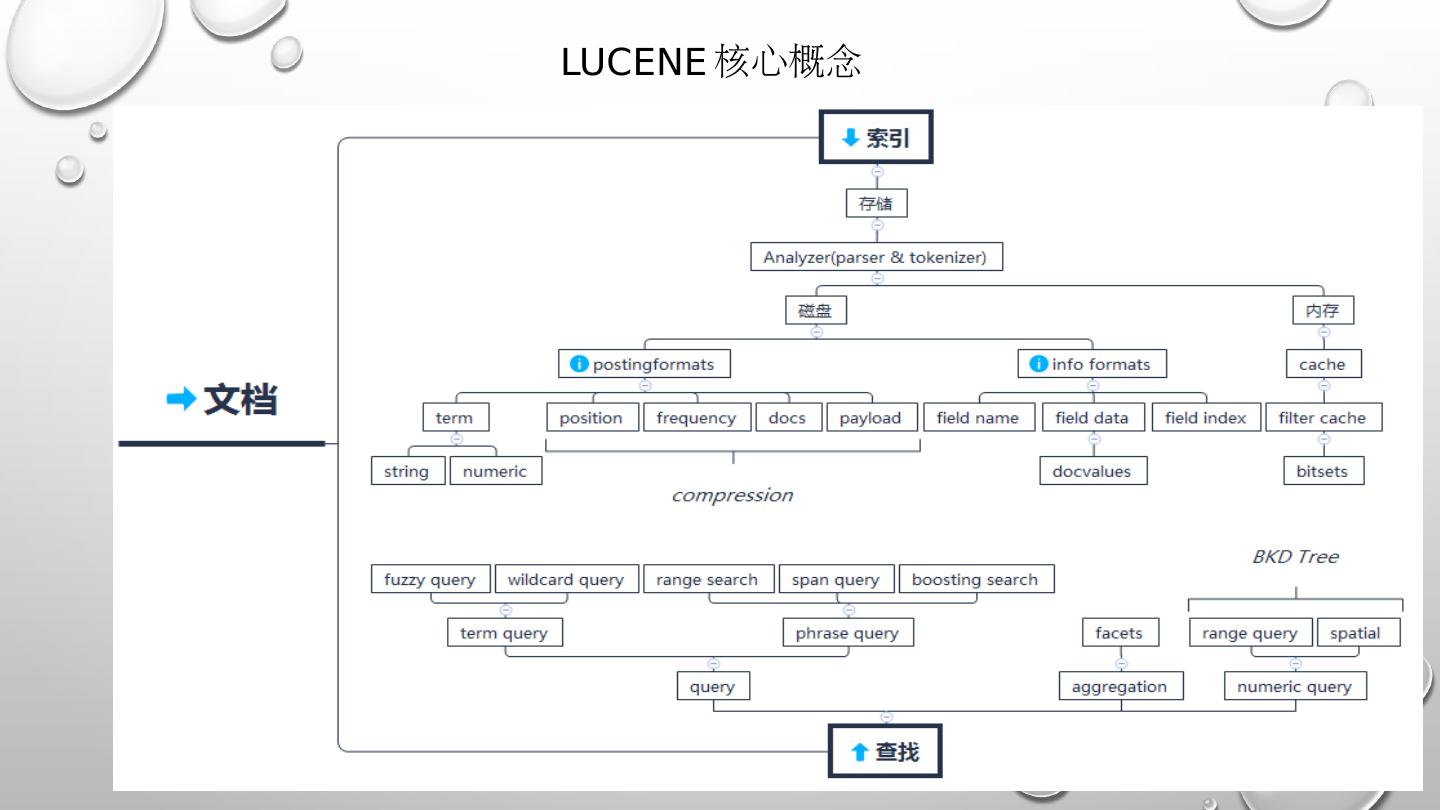
6 .Elasticsearch – 分布式 Lucene 索引 集群管理,节点层面 分布式索引管理 Schema 管理 索引分布 索引迁移 索引查询 query-and-fetch
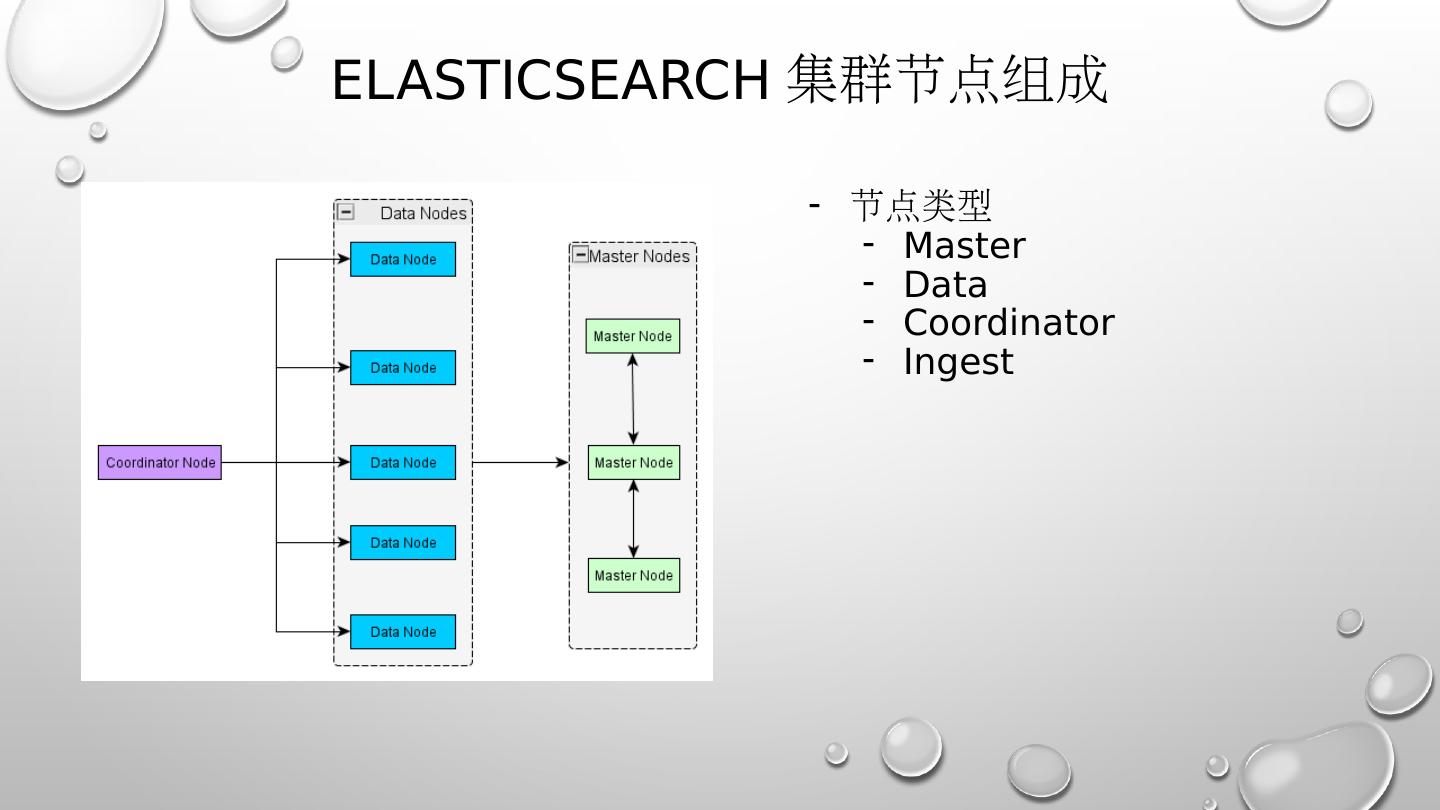
7 .ELASTICSEARCH 集群节点组成 节点类型 Master Data Coordinator Ingest
8 .节点发现机制 Zen Discovery Master 节点包含 cluster 状态信息 节点的加入或离开 Index 的创建、删除、打开、关闭 Shards 的 分配和路由信息 Schema 改变 curl –XGET localhost:9200/_cluster/state
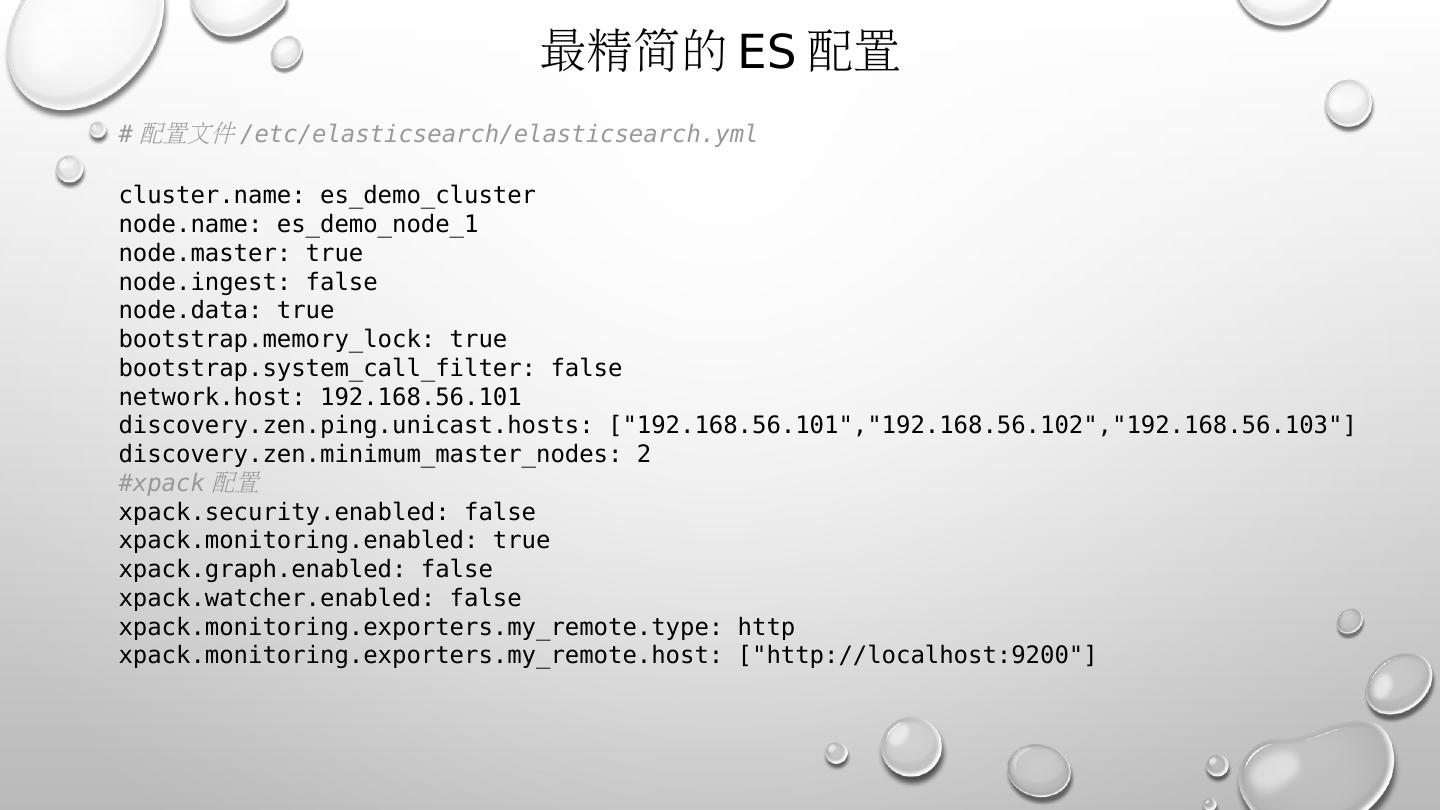
9 .最精简的 ES 配置 # 配置文件 / etc / elasticsearch / elasticsearch.yml cluster.name: es_demo_cluster node.name: es_demo_node_1 node.master : true node.ingest : false node.data : true bootstrap.memory_lock : true bootstrap.system_call_filter : false network.host : 192.168.56.101 discovery.zen.ping.unicast.hosts : ["192.168.56.101","192.168.56.102","192.168.56.103"] discovery.zen.minimum_master_nodes : 2 # xpack 配置 xpack.security.enabled : false xpack.monitoring.enabled : true xpack.graph.enabled : false xpack.watcher.enabled : false xpack.monitoring.exporters.my_remote.type : http xpack.monitoring.exporters.my_remote.host : ["http://localhost:9200"]
12 .Index Settings { "settings" : { "index" : { "routing" : { "allocation" : { " total_shards_per_node " : "3" } }, " refresh_interval " : "120s" , " number_of_shards " : "18" , " translog " : { " flush_threshold_size " : " 2g“, “durability”: “ async ”, “ sync_interval ”: “15s” }, "merge" : { "scheduler" : { " max_thread_count " : "1" } }, " store.type " : " mmapfs " , " number_of_replicas " : "0" , "warmer" : { "enabled" : "false" } } } } } 最佳实践 避免 同一个 index 的所有 shard 落入同一个数据节点 根据业务场景动态调整 refresh_interval 调整 flush_threshold_size 大小 每一个 shard 占用的磁盘空间控制在 10GB~15GB 同一个节点所管理的分片数不超过 600 个, 20 shard/per gb heap 注意索引写入过程中 Throttling 的次数 根据历史统计信息,动态调整索引配置,维护一个健康稳定的集群 不要把 Elasticsearch 做为核心关键数据的主要存储
13 .Mappings – 定义 Schema _all _source enabled 重建索引时有用,最好不要禁止 properties Text 与 keyword 的区别 index doc_values "mappings" : { "logs" : { "_all" : { "enabled" : false }, "properties" : { " builtinTimestamp " : { "type" : "date" , "format" : "YYYY-MM- dd HH:mm:ss.SSS " }, "exception" : { "type" : "keyword" , " ignore_above " : 10915 }, "request" : { "type" : "text" , "index" : false }, "response" : { "type" : "keyword" }, "timestamp" : { "type" : "date" }, }}}}} Notes: 时间类型的格式 " yyyy -MM- dd HH:mm:ss || yyyy -MM- dd || epoch_millis "
14 .集群索引恢复 "transient": { "cluster": { "routing": { "allocation": { " node_initial_primaries_recoveries": "25", "balance": { "index": "16.0f", "threshold": "1.0f", "shard": "0.02f" }, "enable": "all", "cluster_concurrent_rebalance": "120", "node_concurrent_recoveries": "8", "exclude": { "_name": "", “_ip”: “1 92.168.0.101 , 192.168.0.102 ” } } } }
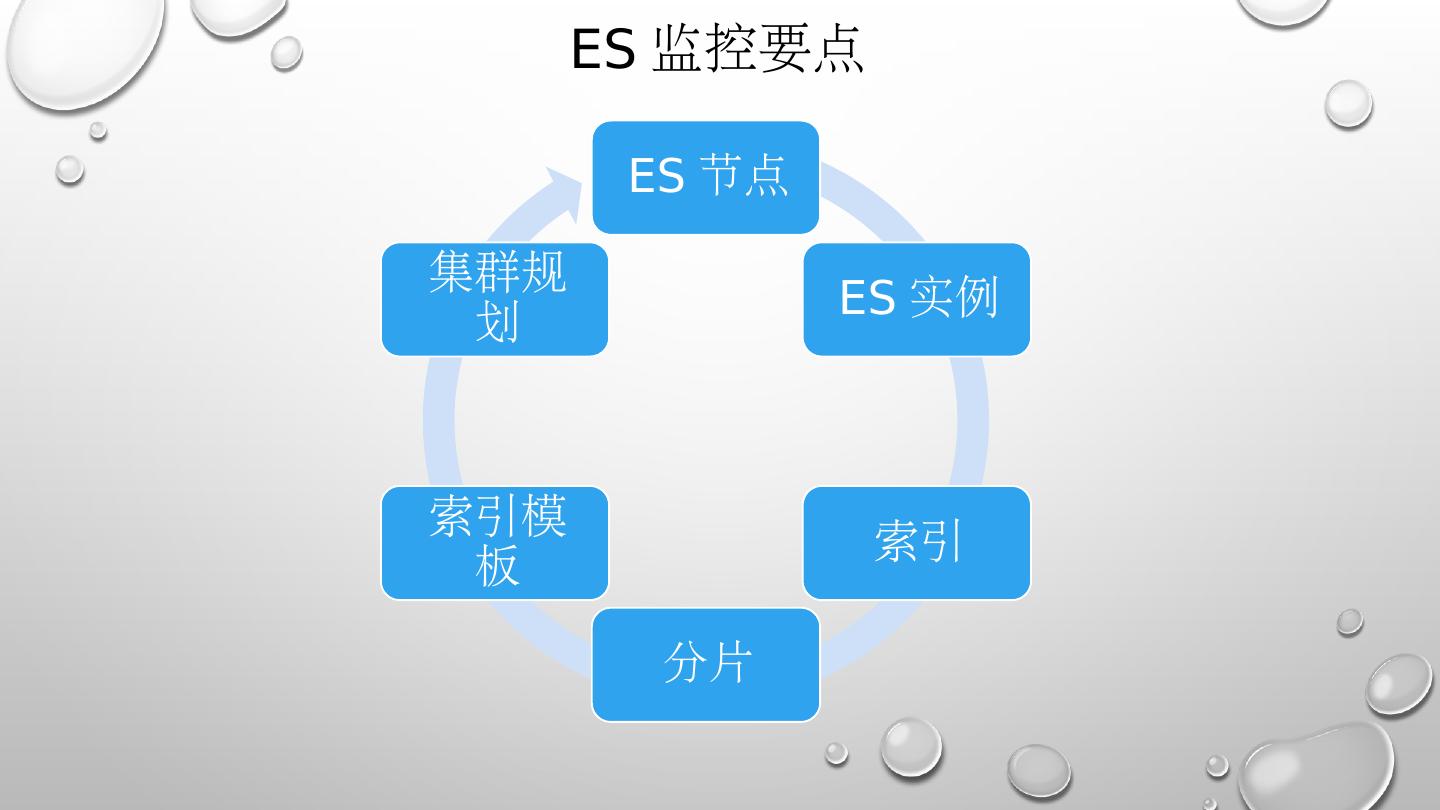
16 .集群配置和监控 - OS 层面 内存 vm.dirty_ratio vm.dirty_background_ratio I/O scheduler /sys/block/ sd$i /queue/scheduler /sys/block/ sd$i /queue/ read_ahead_db 监控 索引 Shard 数 Shard 分布均匀 是否存在大量查询 避免 mapping 中字段过多,引起 mapping 的频繁更新 聚合操作常易引起 OOM 运行实例节点 内存不超过 32GB 避免调整 thread_pool
17 .CAT API GET _cat/health GET _cluster/ health?pretty GET _cluster/state 集群状态 节点状态 GET _cat/indices 索引信息 GET _cat/shards shard 信息 GET _ cat/ nodes?help 查询具体参数 GET _nodes/stat 统计信息 GET _nodes/ 基础配置信息
19 .应用开发 采用 Rest API, 推荐 Elastic4s 打开 sniffer 嗅探整个集群,或者使用 nginx 来进行 load-balance 处理返回异常,在同个 bulk 处理中,不是都失败或都成功,要识别出失败的指令,并重试