展开查看详情
1 .The Power of Choice in Data-Aware Cluster Scheduling Shivaram Venkataraman 1 , Aurojit Panda 1 Ganesh Ananthanarayanan 2 , Michael Franklin 1 , Ion Stoica 1 1 UC Berkeley, 2 Microsoft Research Present by Qi Wang Borrow some slides from the author
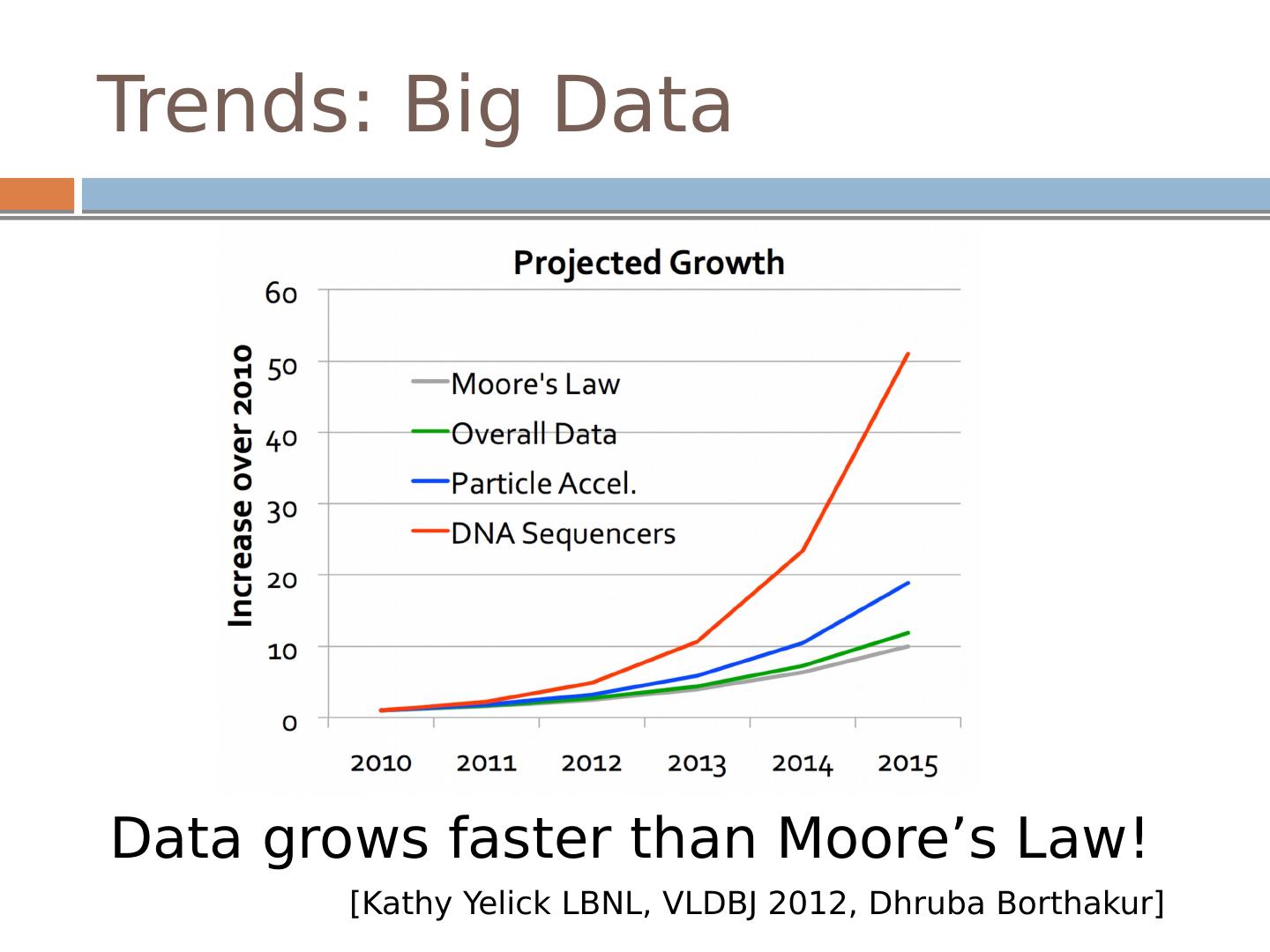
2 .Trends: Big Data Data grows faster than Moore’s Law! [Kathy Yelick LBNL, VLDBJ 2012, Dhruba Borthakur ]
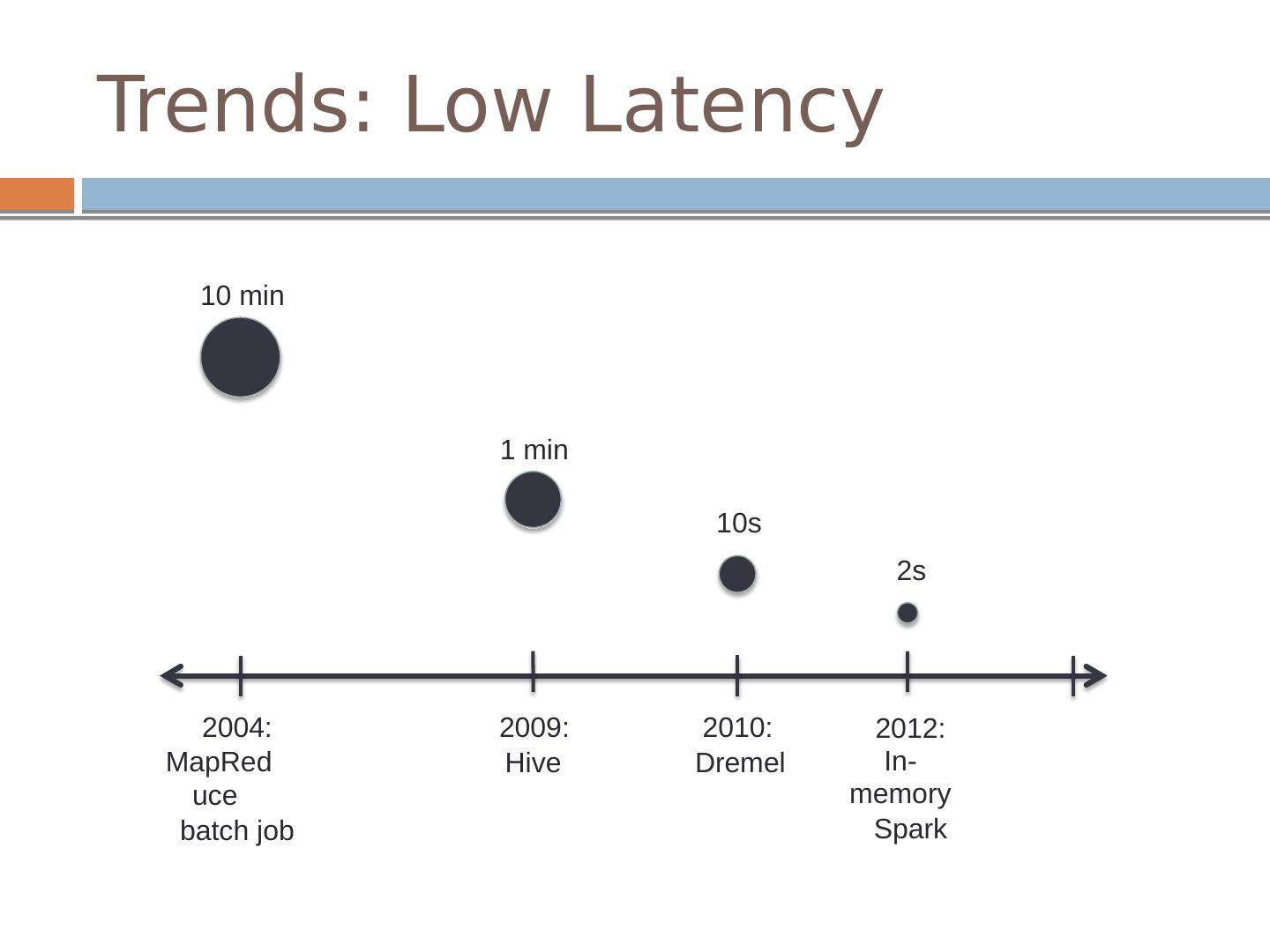
3 .Trends: Low Latency 10 min 1 min 10s 2s 2004: MapReduce batch job 2009: Hive 2010: D r emel 2012: In-memory Spark
4 .Big Data or Low Latency SQL Query : 2.5 TB on 100 machines ? < 10s > 15 minutes 1 - 5 Minutes
5 .Trends: Sampling Use a subset of the input data
6 .Applications Approximate Query Processing blinkdb presto minitable Machine learning algorithms stochastic gradient coordinate descent
7 .Combinatorial Choices A n y K N Sampling -> Smaller inputs + Choice
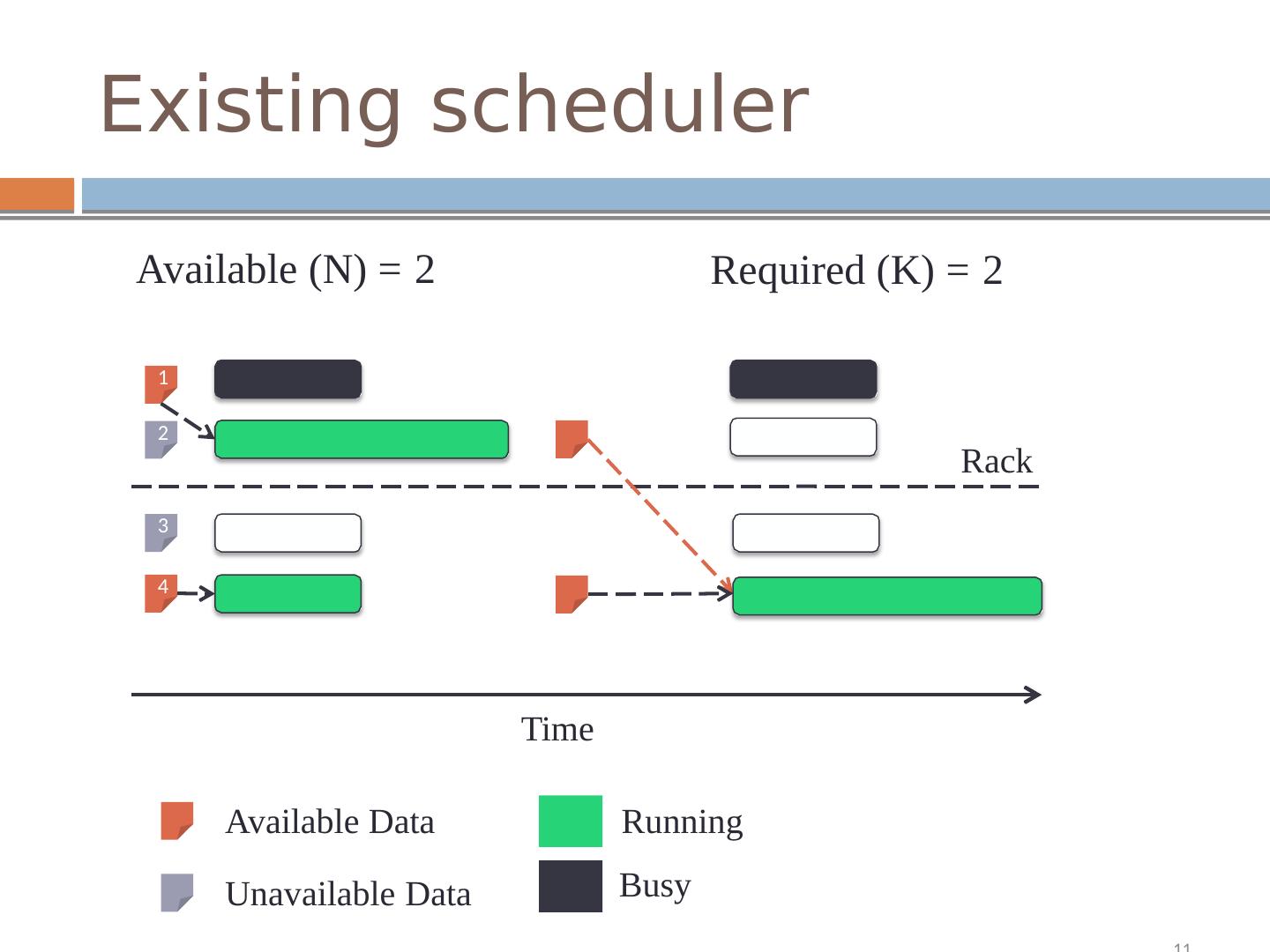
8 .Existing scheduler Available (N) = 2 Required (K) = 2 1 2 Rack 3 4 Time Available Data Running Busy Unavailable Data 11
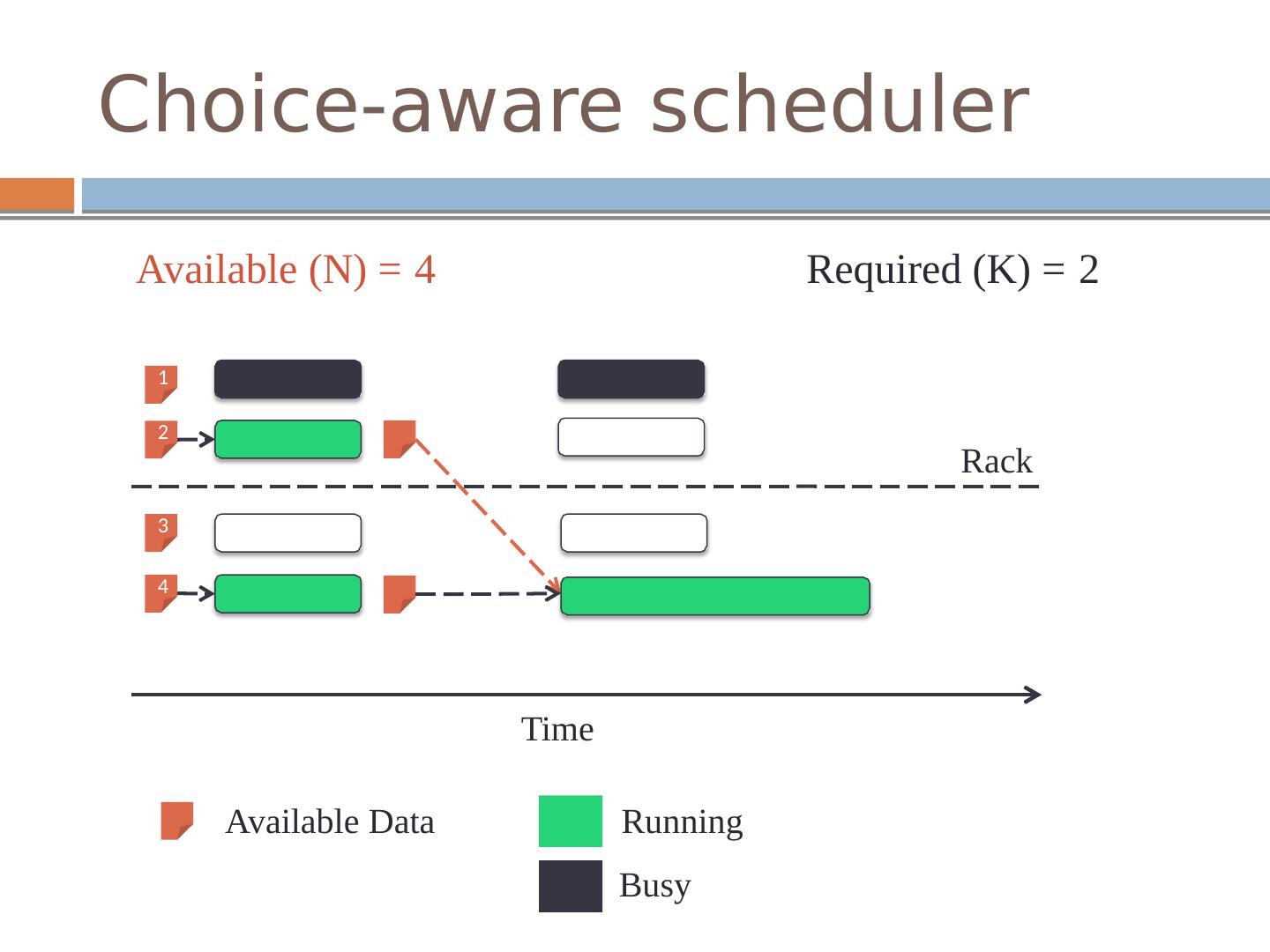
9 .Choice-aware scheduler Available (N) = 4 Required (K) = 2 1 2 Rack 3 4 Time Available Data Running Busy
10 .Data-aware scheduling Input stage Less than 60% of tasks achieve locality even with three replica Tasks have to be scheduled with memory locality Intermediate stages The runtime is dictated by the amount of data transferred across racks To schedule the task at a machine that minimizes the time it takes to transfer all remote inputs
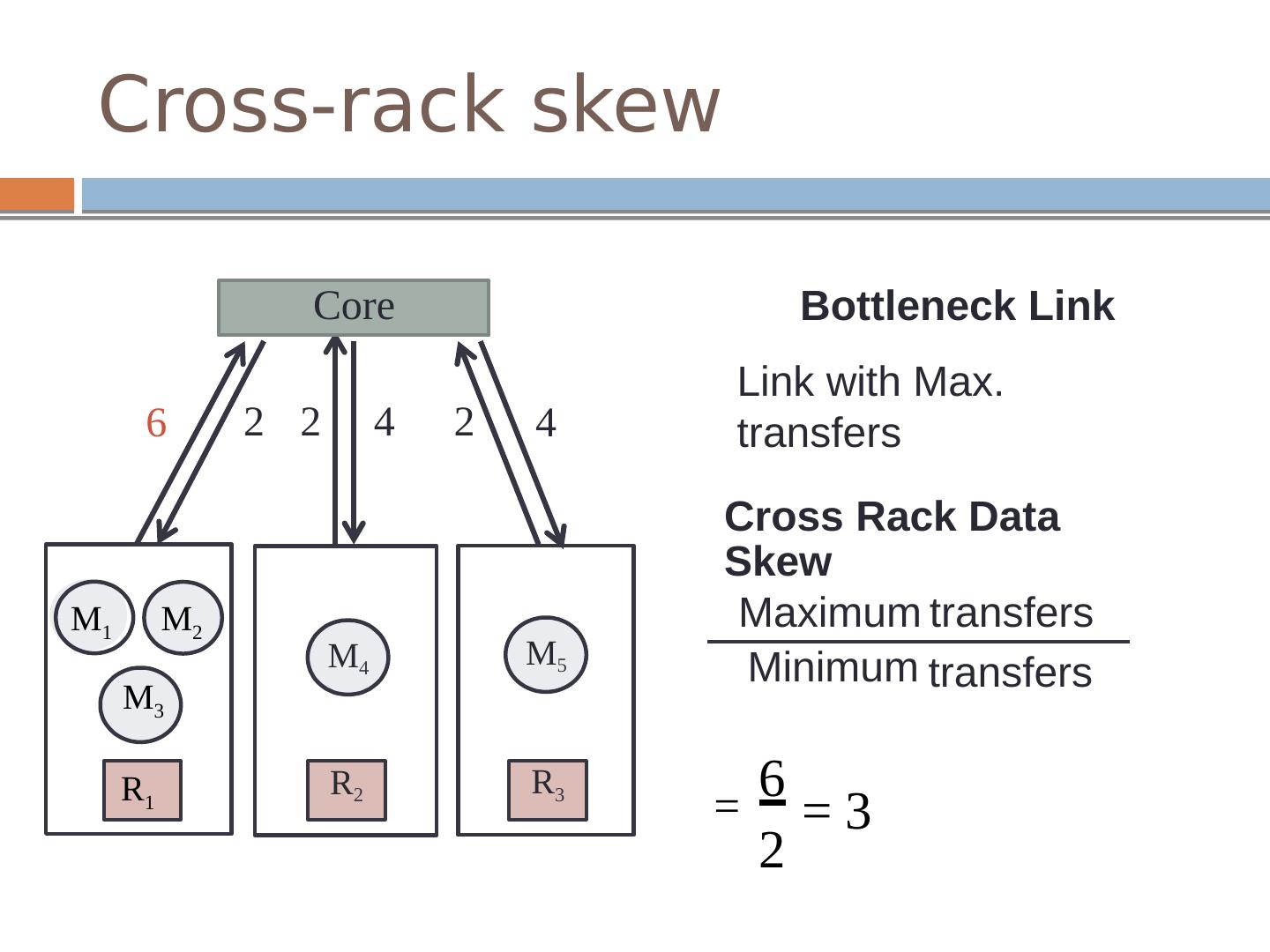
11 .Cross-rack skew Bottleneck Link Link with Max. transfers 6 4 Cross Rack Data Skew Maximum Minimum transfers transfers 6 2 = 3 = M 5 R 3 Core 2 2 4 2 M 4 R 2 M 1 M 2 M 3 R 1
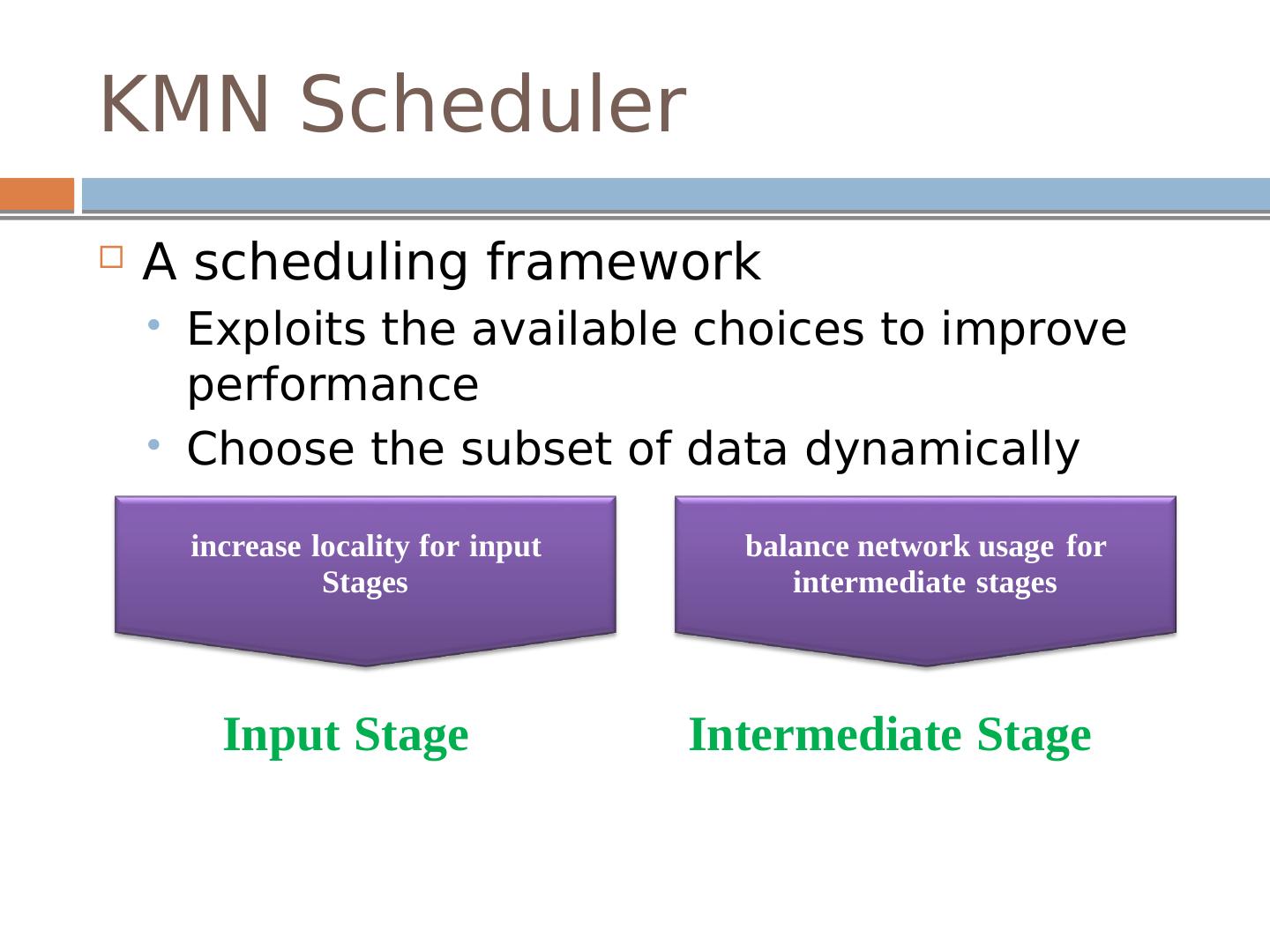
12 .KMN Scheduler A scheduling framework Exploits the available choices to improve performance Choose the subset of data dynamically i ncr ease lo c al i ty f o r i nput S tag e s b alan c e n e t w o rk usage fo r i n t er m ed i a t e stag e s Input S tage In t e r medi a t e S tage
13 .Input stage Jobs which can use any K of the N input blocks
14 .Input stage Jobs which use a custom sampling functions
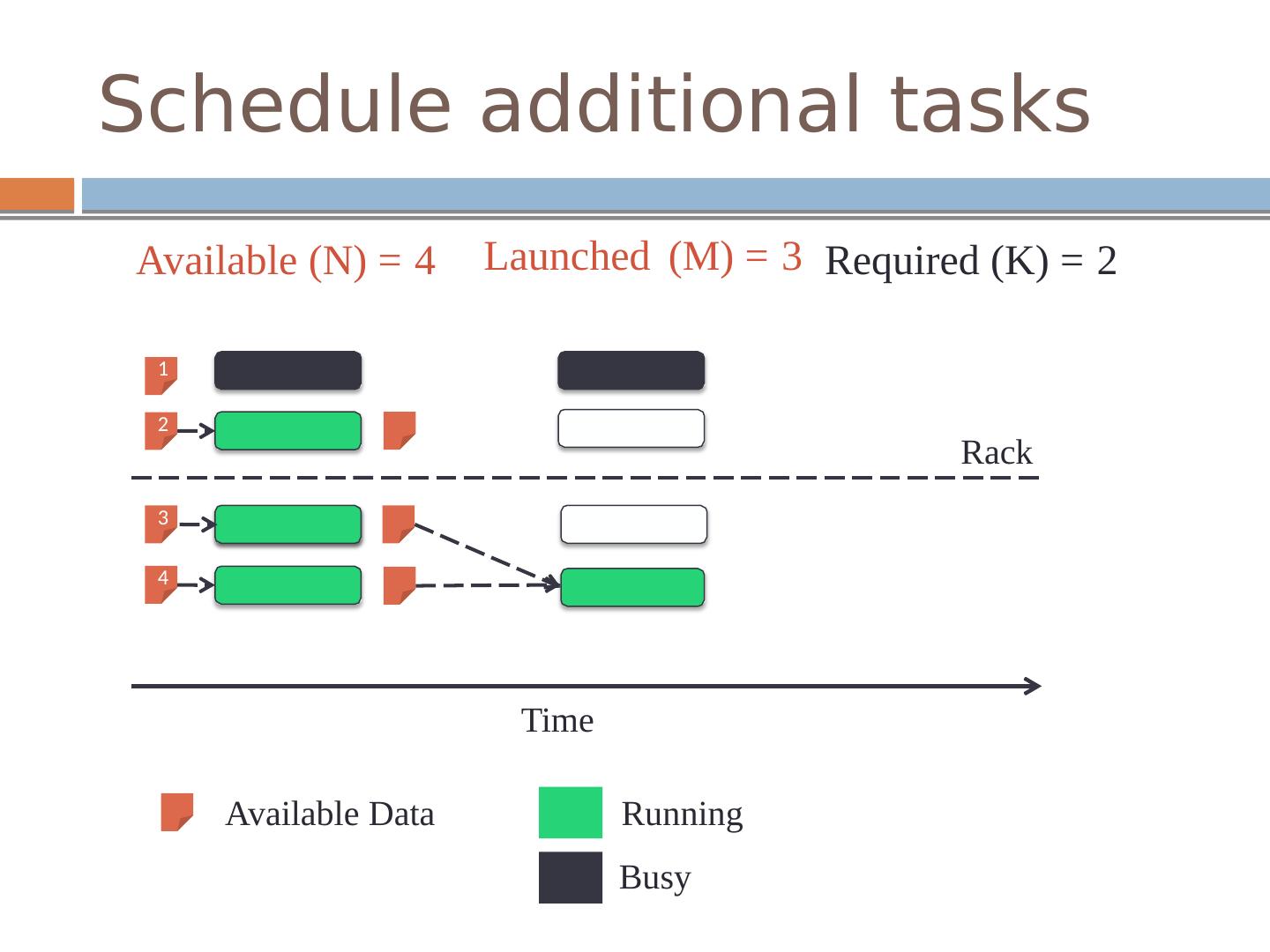
15 .Intermediate stage Challenges Main idea Scheduling a few additional tasks at upstream stage Schedule M tasks for an upstream stage with K tasks
16 .Schedule additional tasks Launched (M) = 3 Available (N) = 4 Required (K) = 2 1 2 Rack 3 4 Time Available Data Running Busy
17 .Select best upstream outputs Round-robin strategy Spread choice of K outputs across as many racks as possible K = 5 c r os s- rack s k ew = 3 M M M M M
18 .Select best upstream outputs After running extra tasks M = 7 K = 5 c r oss - r a ck s k ew = 3 M M M M M M M
19 .Select best upstream outputs M = 7 K = 5 c r oss - r a ck s k ew = 2 M M M M M M M
20 .Handling Stragglers Wait all M can be inefficient due to stragglers Balance between waiting and losing choice A delay-based approach Bounding transfer Whenever the delay D K’ is greater than the maximum improvement, we can stop the search as the succeeding delays will increase the total time Coalescing tasks Coalesce a number of task finish events to further reduce the search space
21 .Using KMN KMN is built on top of Spark
22 .Evaluation Cluster Setup 100 m2.4xlarge EC2 machines, 68GB RAM/mc Baseline Using existing schedulers with pre-selected samples Metrics % improvement = (baseline time – KMN time)/baseline time
23 .Conviva Sampling jobs Running 4 real-world sampling queries obtained from Conviva
24 .Machine learning workload Stochastic Gradient Descent Agg r egate3 Aggregate2 Agg r egate1 Gradient
25 .Machine learning workload Overall benefits
27 .Conclusion Application trends Operate on subsets of data KMN Exploit the available choices to improve performance Increasing locality balancing intermediate data transfers Reduce average job duration by 80% using just 5% additional resources
28 .Cons Reduce the randomness of the selection Extra resources are used The utilization spikes also are not taken into account by the model and jobs which arrive during a spike do not get locality Need to modify threads Not helpful for small jobs No benefits for longer stages Not general to other applications ……
29 .Questions Is round-robin the best heuristic that can be used here? What is the recommended value for extra upstream tasks? In evaluation part, authors tested with 0%, 5%, and 10%, but they did not discuss the optimal value for the extra portion of upstream tasks. How would the system scale with the number of stages in the computation?