





























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Bagging & Boosting
Ensemble Methods,Bagging,Boosting,Random Forests,Gradient Boosting Decision Trees
展开查看详情
1 .Bagging & Boosting HITSCIR-TM zkli - 李泽魁 March. 24, 2015
2 .Outline Ensemble Methods Bagging Boosting Random Forests Gradient Boosting Decision Trees
3 .Outline Ensemble Methods Bagging Boosting Random Forests Gradient Boosting Decision Trees
4 .Ensemble Methods 求助现场观众?
5 .Ensemble learning ——Train Basic idea: if one classifier works well, why not use multiple classifiers! Training Data model 1 learning alg Training learning alg … model 2 learning alg model m
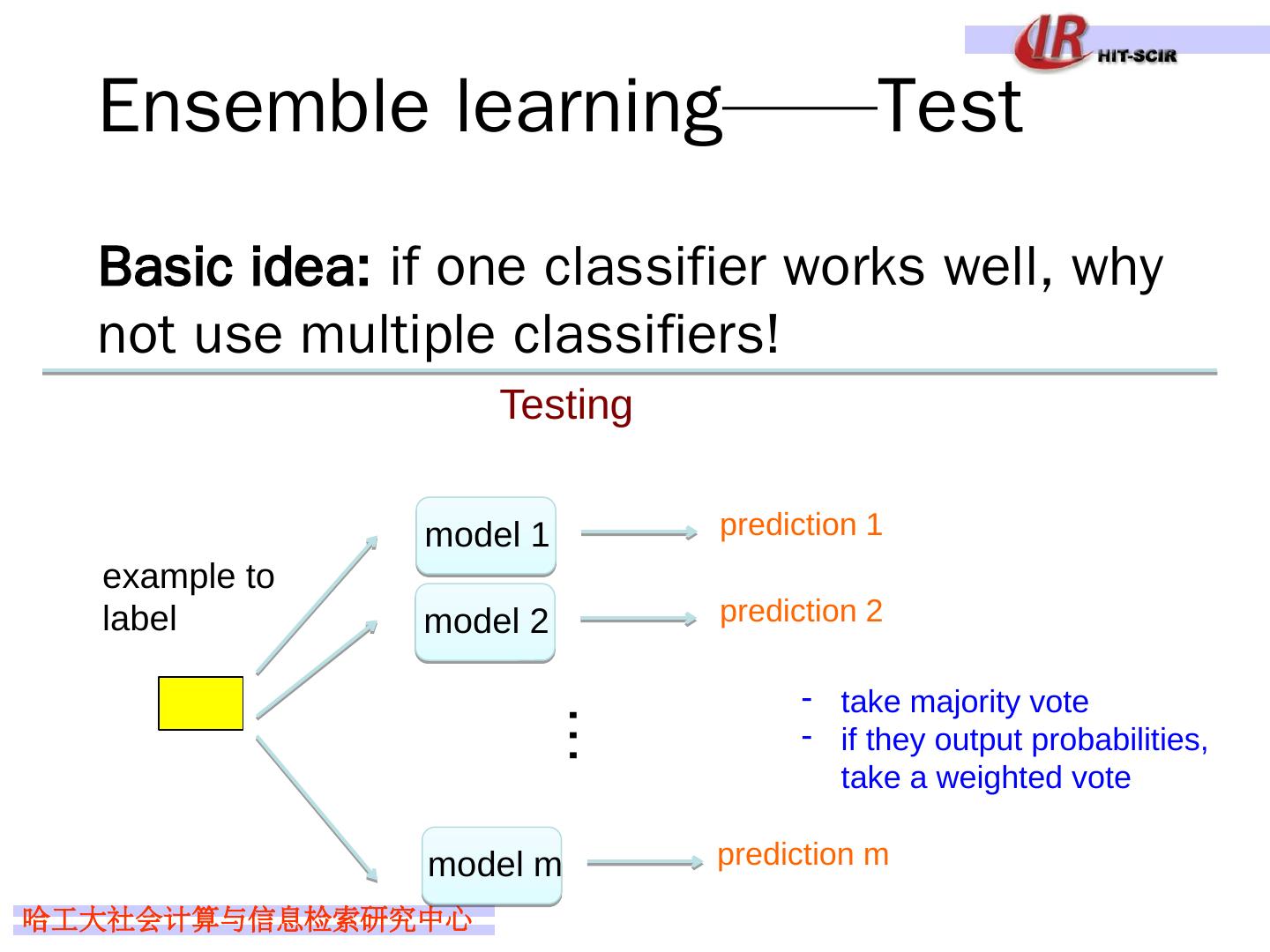
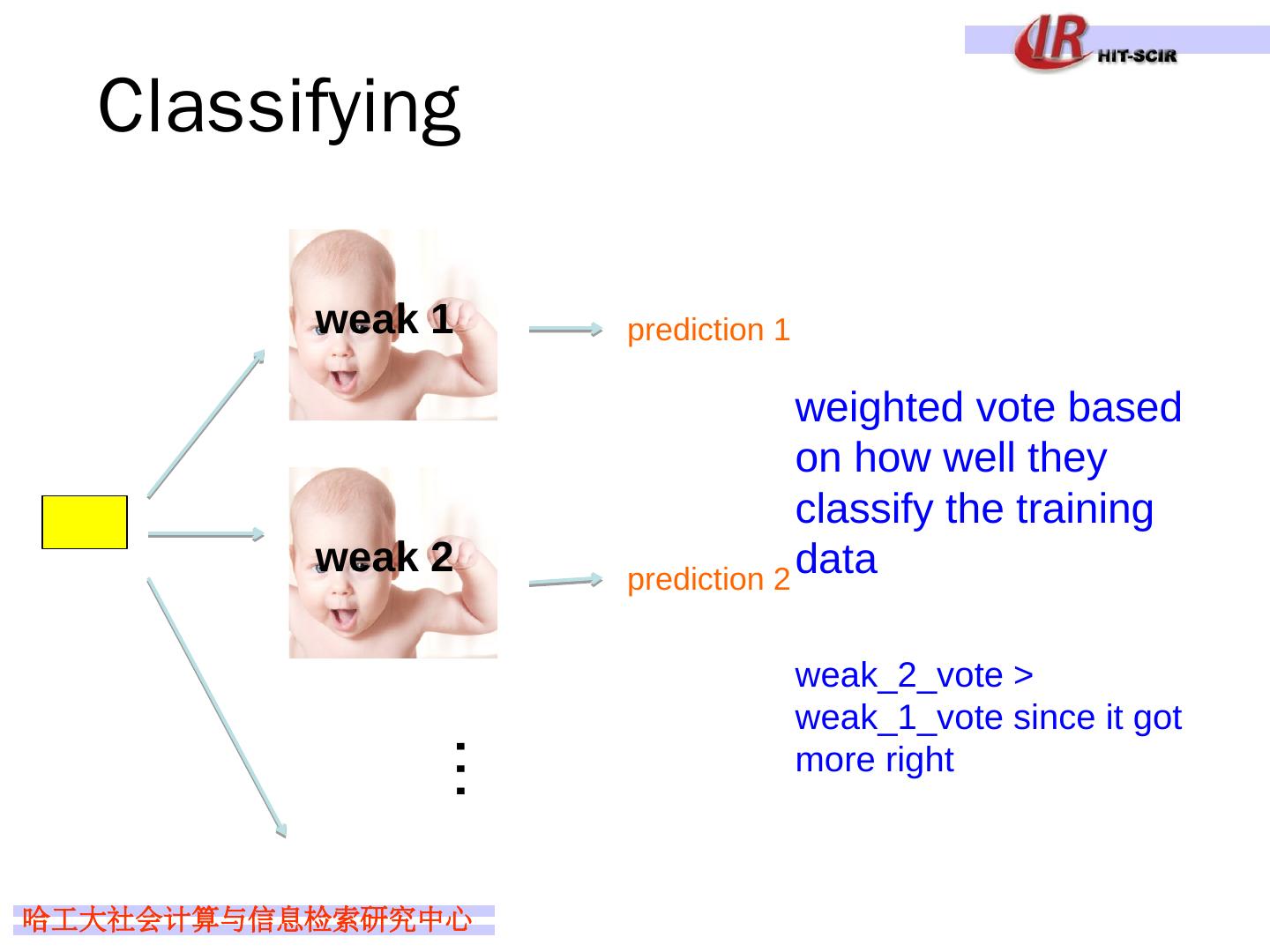
6 .Ensemble learning —— Test Basic idea: if one classifier works well, why not use multiple classifiers! model 1 Testing model 2 model m example to label … prediction 1 prediction 2 prediction m take majority vote if they output probabilities, take a weighted vote
7 .Benefits of ensemble learning Assume each classifier makes a mistake with some probability (e.g. 0.4, that is a 40% error rate) model 1 model 2 model 3 prob C C C .6*.6*.6=0.216 C C I .6*.6*.4=0.144 C I C .6*.4*.6=0.144 C I I .6*.4*.4=0.096 I C C .4*.6*.6=0.144 I C I .4*.6*.4=0.096 I I C .4*.4*.6=0.096 I I I .4*.4*.4=0.064 0.096+ 0.096+ 0.096+ 0.064 = 35% error!
8 .Given enough classifiers… r = 0.4
9 .三个臭皮匠顶个诸葛亮 通过集成 学习提高分类器的整体泛化能力是有条件 的 : 分类器之间应该具有差异 性 分类器的精度,每个个体分类器的分类精度必须大于 0.5
10 .Obtaining independent classifiers Where to we get m independent classifiers? Training Data model 1 learning alg learning alg … model 2 learning alg model m
11 .Idea 1: different learning methods decision tree k- nn perceptron naïve bayes gradient descent variant 1 gradient descent variant 2 … Pros/cons? Training Data model 1 learning alg 1 learning alg 2 … model 2 learning alg 3 model m
12 .Idea 1: different learning methods Pros: Lots of existing classifiers already Can work well for some problems Cons/concerns: Often, classifiers are not independent, that is, they make the same mistakes! e.g. many of these classifiers are linear models voting won’t help us if they’re making the same mistakes
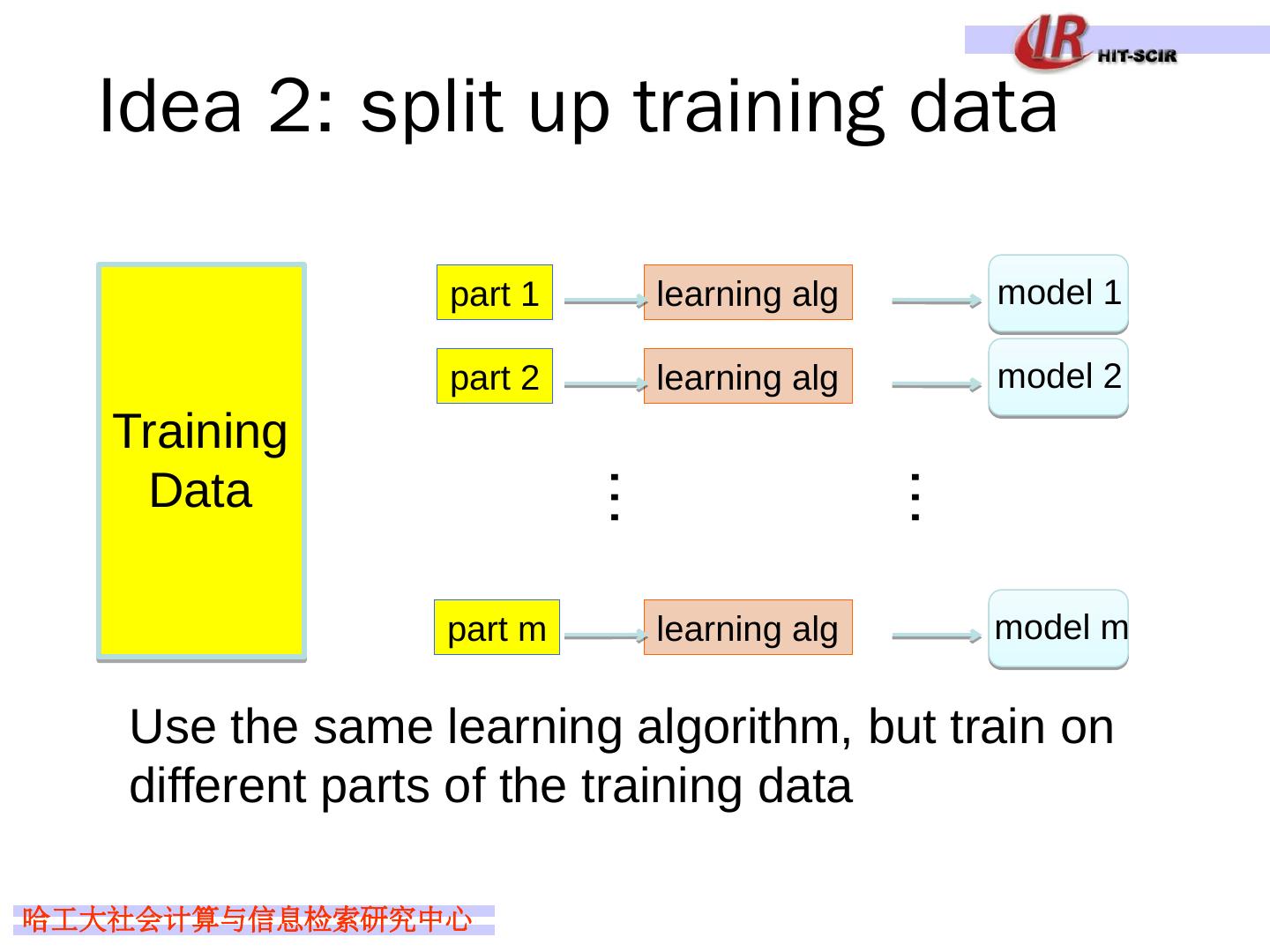
13 .Idea 2: split up training data Training Data model 1 learning alg … part 1 … model 2 learning alg part 2 model m learning alg part m Use the same learning algorithm, but train on different parts of the training data
14 .Idea 2 : split up training data Pros: Learning from different data, so can’t overfit to same examples Easy to implement fast Cons/concerns: Each classifier is only training on a small amount of data Not clear why this would do any better than training on full data and using good regularization
15 .Idea 2 : split up training data Pros: Learning from different data, so can’t overfit to same examples Easy to implement fast Cons/concerns: Each classifier is only training on a small amount of data Not clear why this would do any better than training on full data and using good regularization
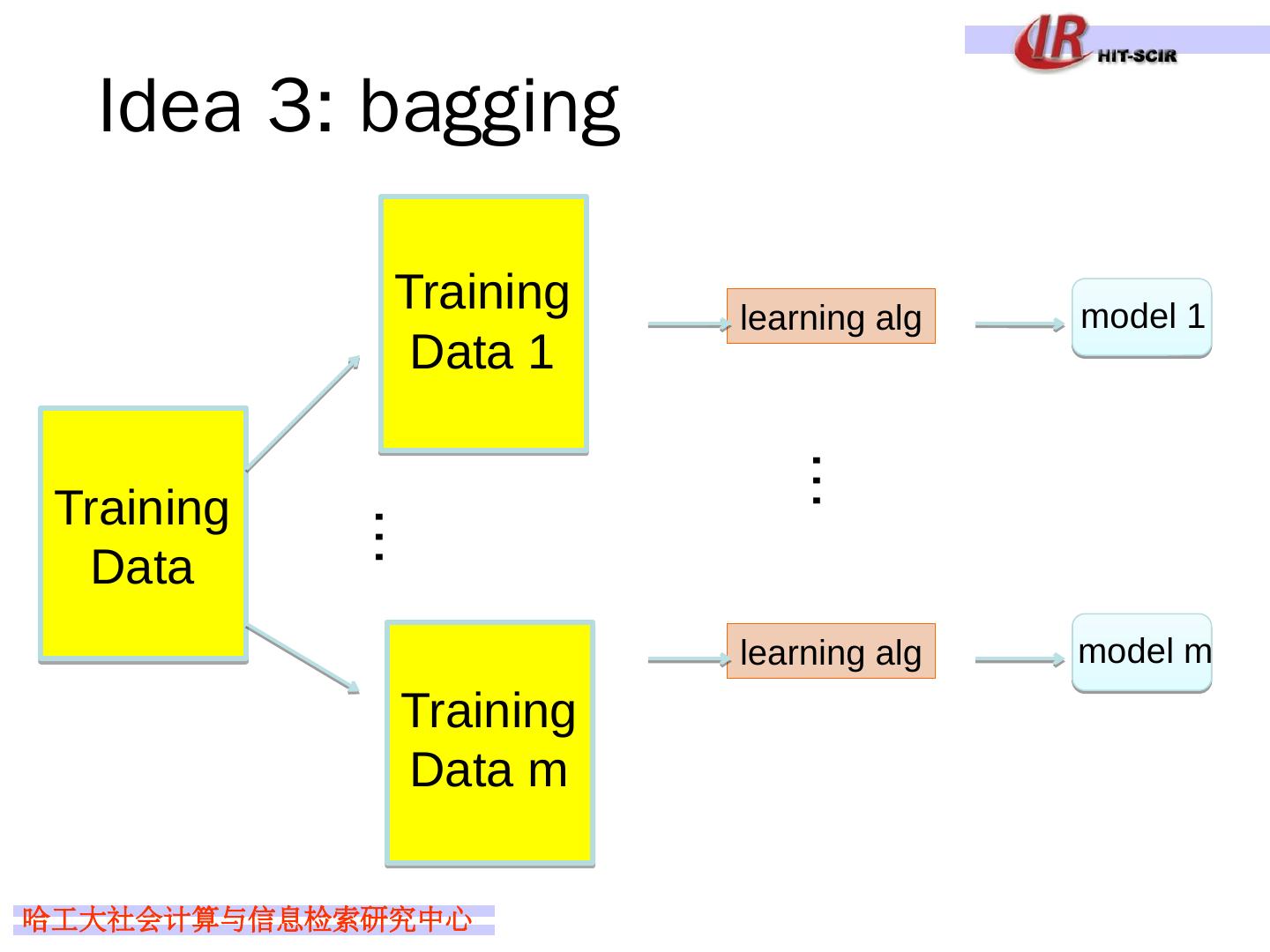
16 .Idea 3: bagging Training Data model 1 learning alg … … model m learning alg Training Data 1 Training Data m
17 .bagging Training data “Training” data 1 … “Training” data 2 Use training data as a proxy for the data generating distribution sampling with replacements
18 .bagging create m “new” training data sets by sampling with replacement from the original training data set (called m “ bootstrap ” samples) train a classifier on each of these data sets to classify, take the majority vote from the m classifiers
19 .Bootstraping pull up by your own bootstraps 自助法、自举法、拔 靴 法。。。 简单理解: 现有 100 个数据 , 但是 100 个数据没办法真实反映样本的全貌 , 就 把这 100 个数据重新 随机的 SAMPLING 1000 次 , 这样你就有了 100*1000 个数 据点了,这样样本量 就会增大 很多 在已知数据的基础上 , 通过用计算机来模拟 N 趋近于无穷大时候的情况 , 把已知的 DATA 不断的重新 SAMPLING, 从而在新的数据中得出原始数据的 信息
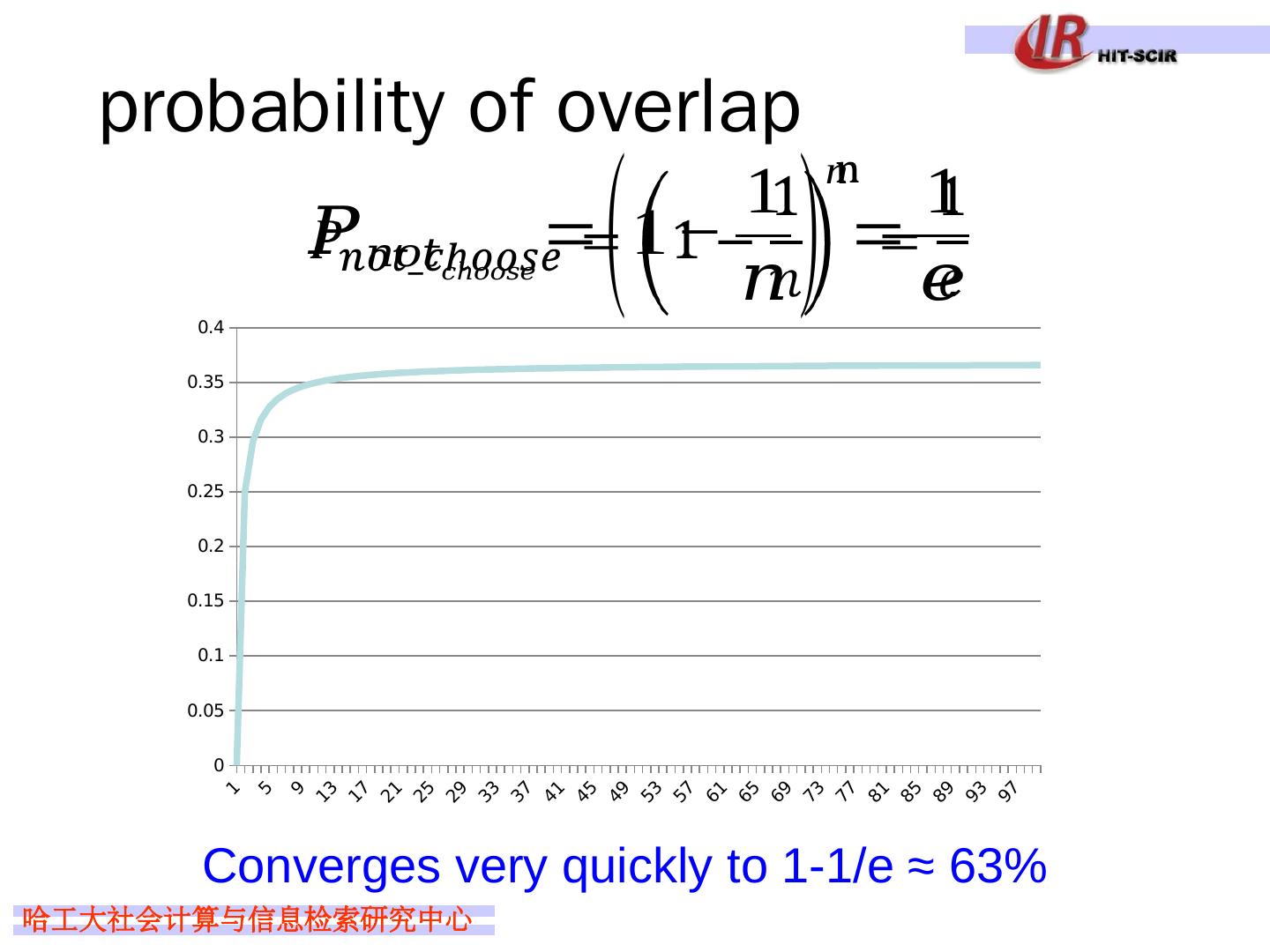
20 .bagging overlap … Training Data 1 Training Data m Training Data Won’t these all be basically the same? On average, a randomly sampled data set will only contain 63% of the examples in the original
21 .probability of overlap Converges very quickly to 1-1/e ≈ 63%
22 .When does bagging work Let’s say 10% of our examples are noisy (i.e. don’t provide good information) W hen bagging sampling data, a third of the original noisy examples not use for training For some classifiers that have trouble with noisy classifiers, this can help
23 .When does bagging work Bagging tends to reduce the variance of the classifier By voting, the classifiers are more robust to noisy examples Bagging is most useful for classifiers that are: Unstable: small changes in the training set produce very different models Prone to overfitting
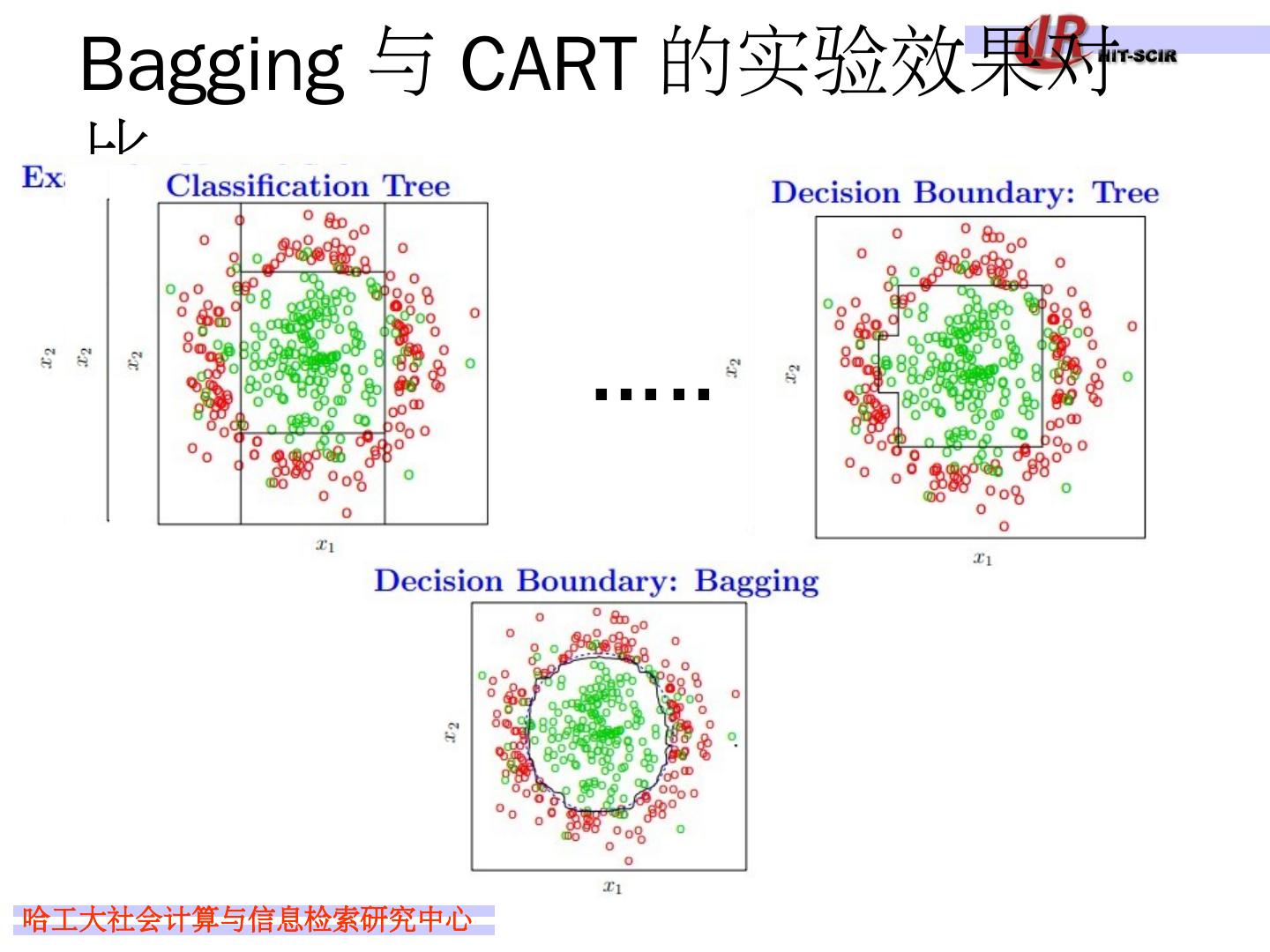
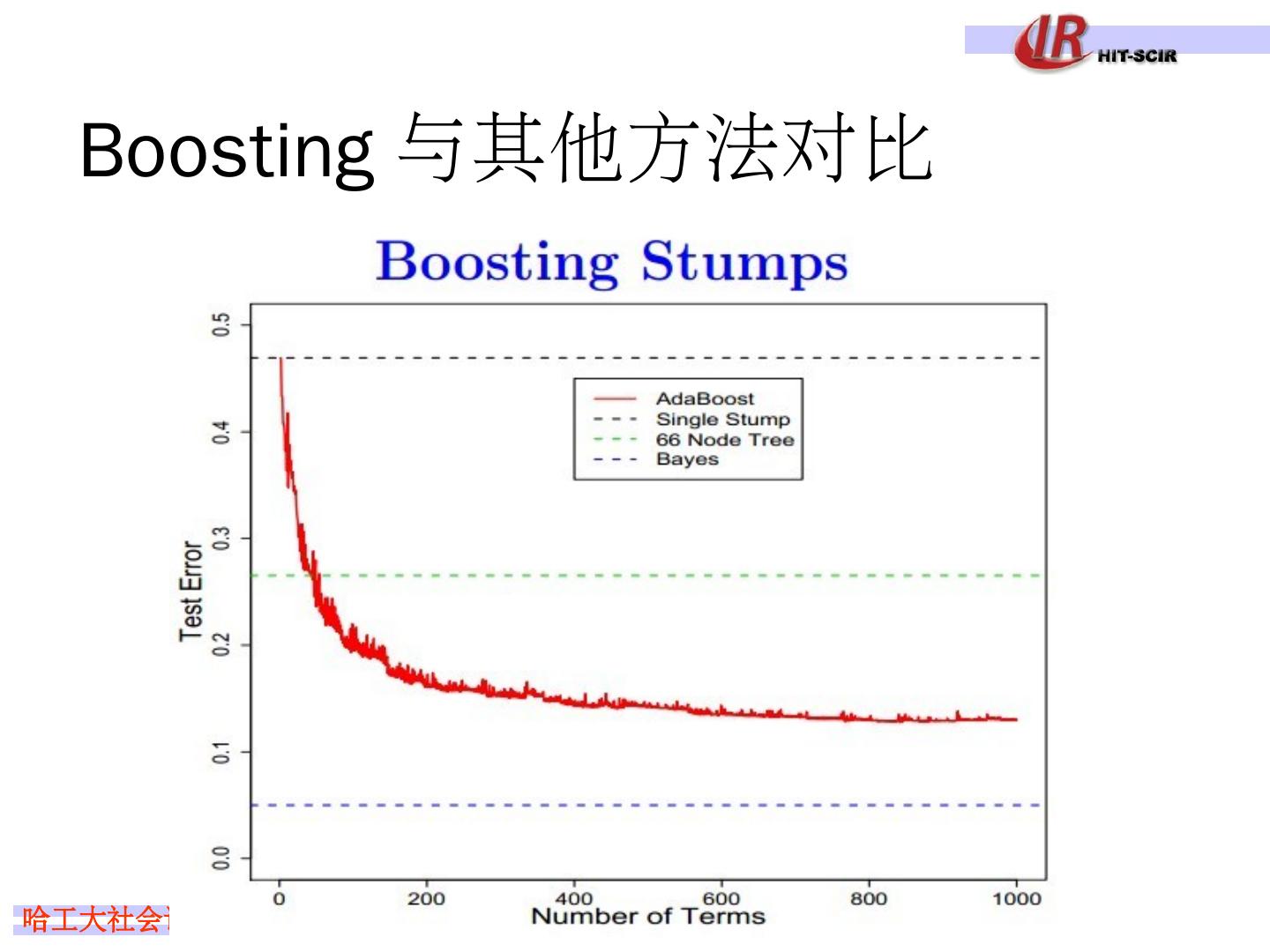
24 .Bagging 与 CART 的实验效果对比 ……
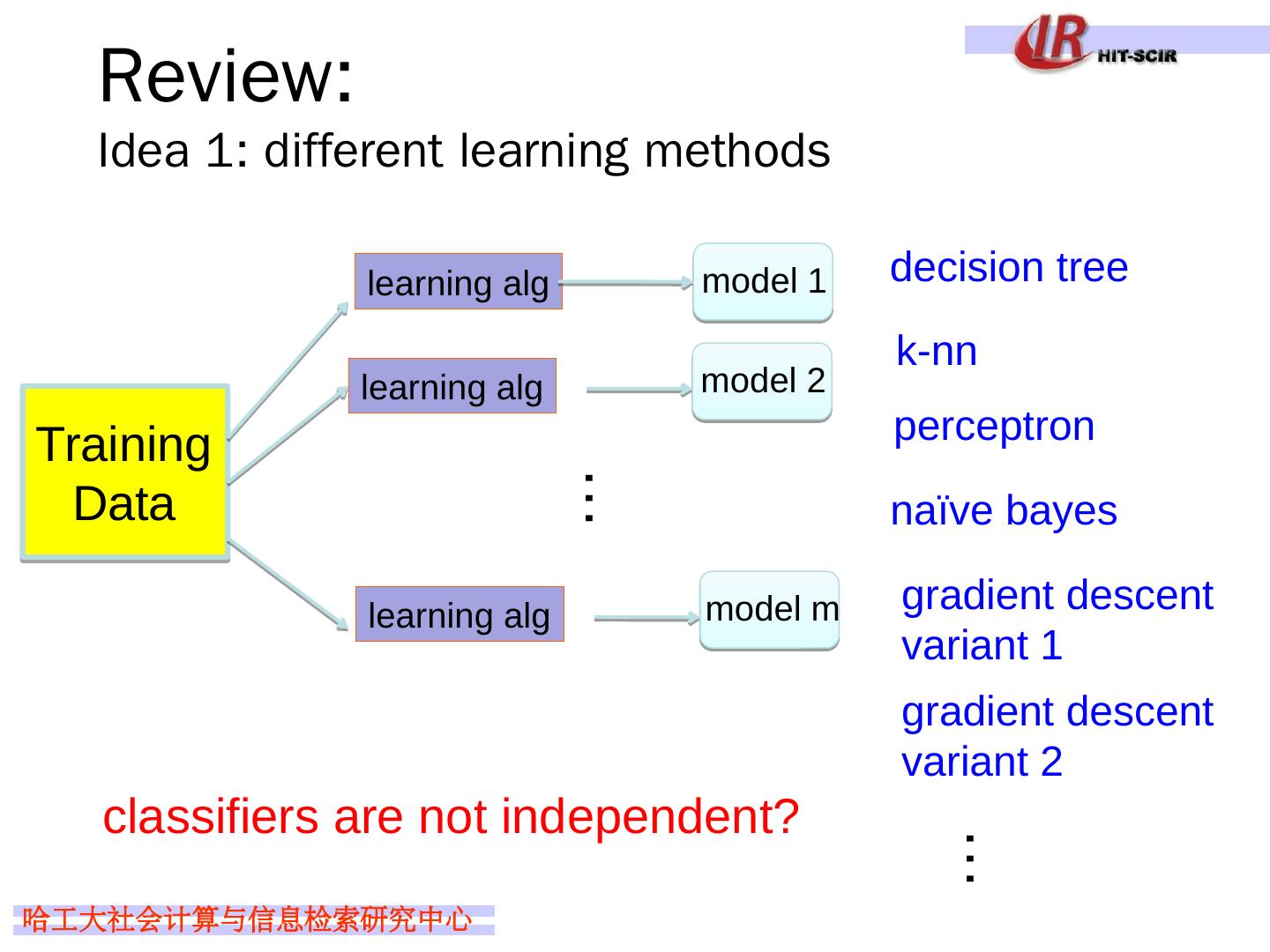
25 .Review: Idea 1: different learning methods decision tree k- nn perceptron naïve bayes gradient descent variant 1 gradient descent variant 2 … classifiers are not independent? Training Data model 1 learning alg learning alg … model 2 learning alg model m
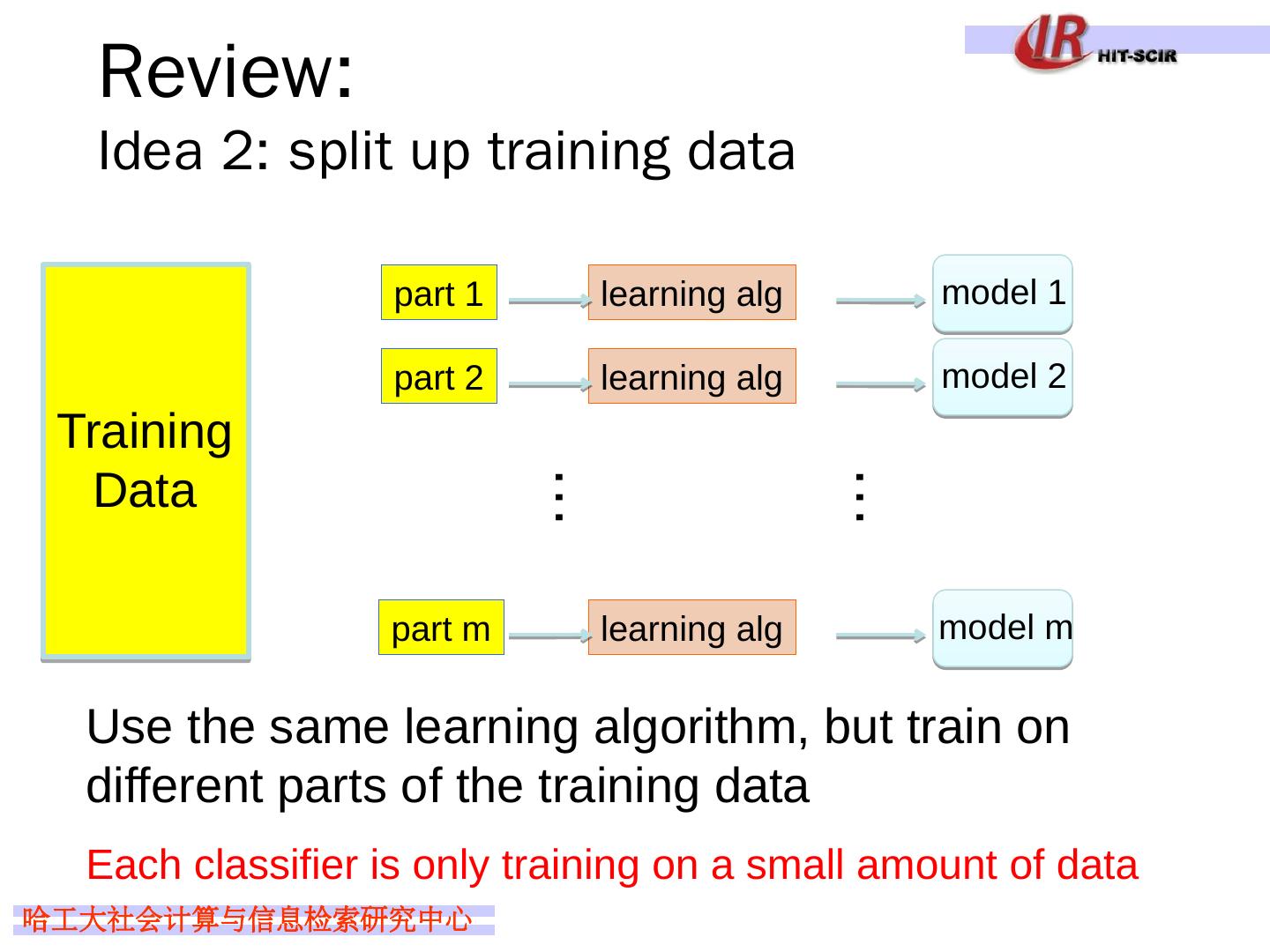
26 .Review: Idea 2: split up training data Training Data model 1 learning alg … part 1 … model 2 learning alg part 2 model m learning alg part m Use the same learning algorithm, but train on different parts of the training data Each classifier is only training on a small amount of data
27 .Review: Idea 3: bagging Training Data model 1 learning alg … … model m learning alg Training Data 1 Training Data m more robust to noisy examples
28 .Review: Idea 3: bagging Training Data model 1 learning alg … … model m learning alg Training Data 1 Training Data m more robust to noisy examples
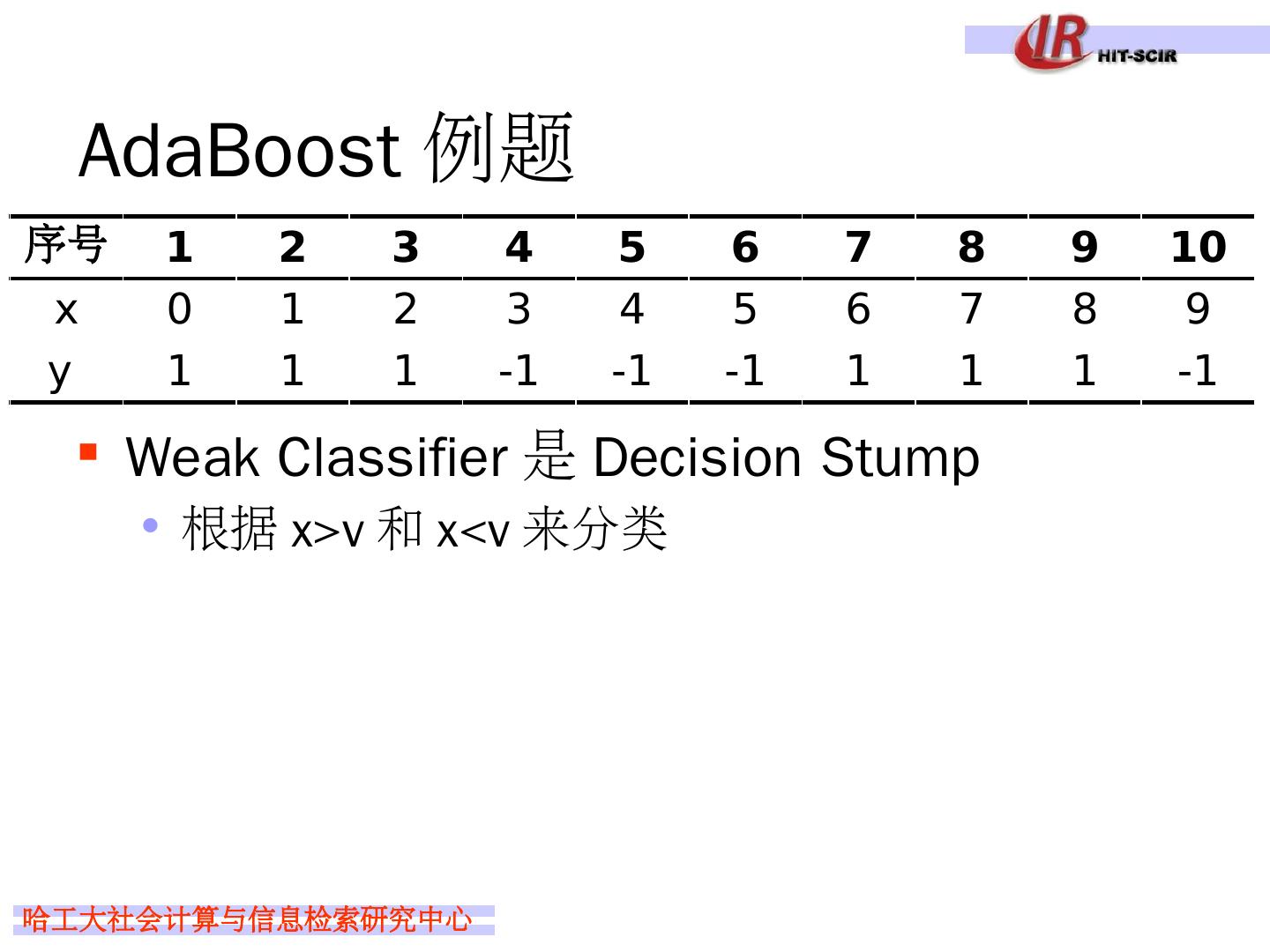
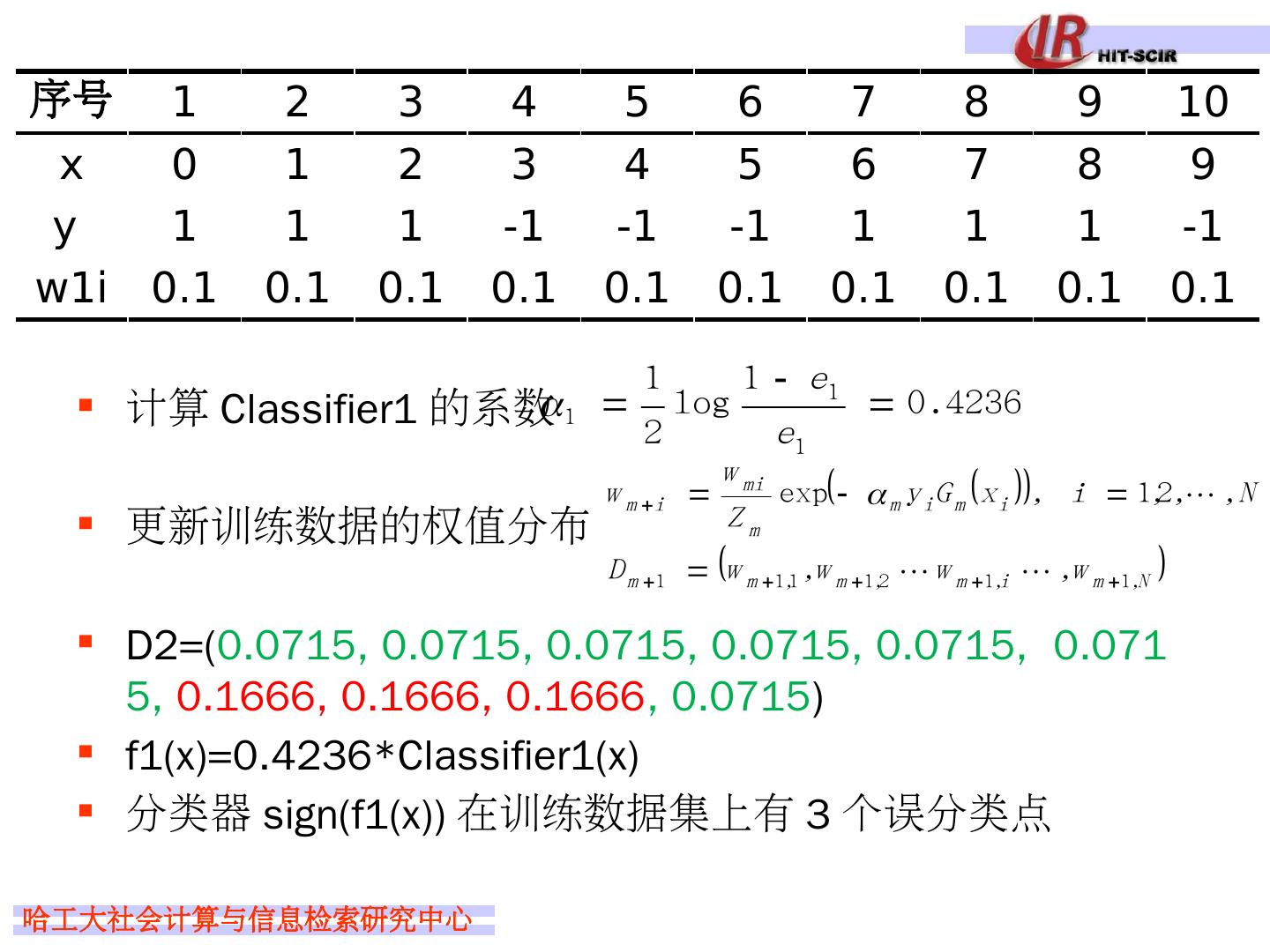
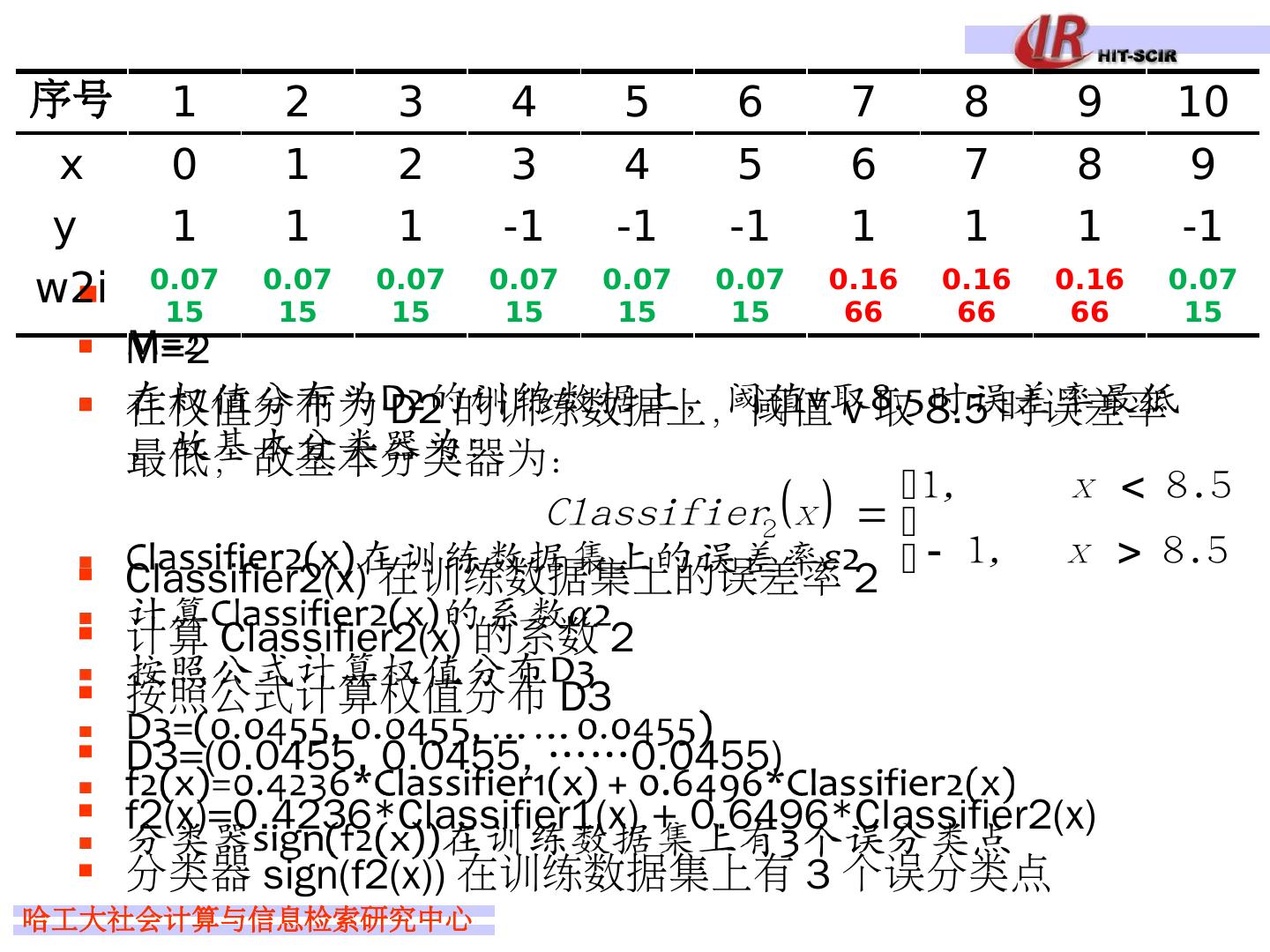
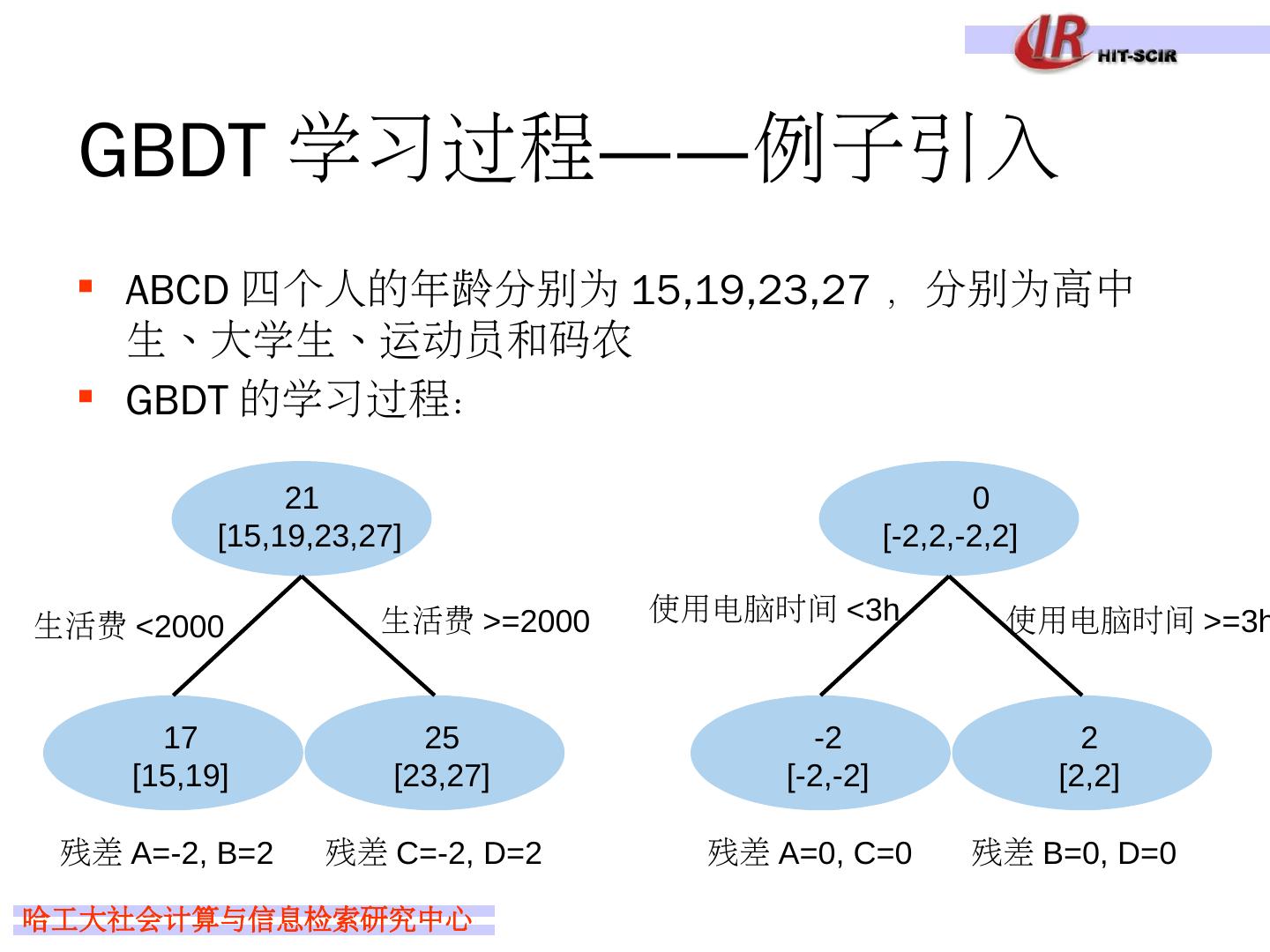
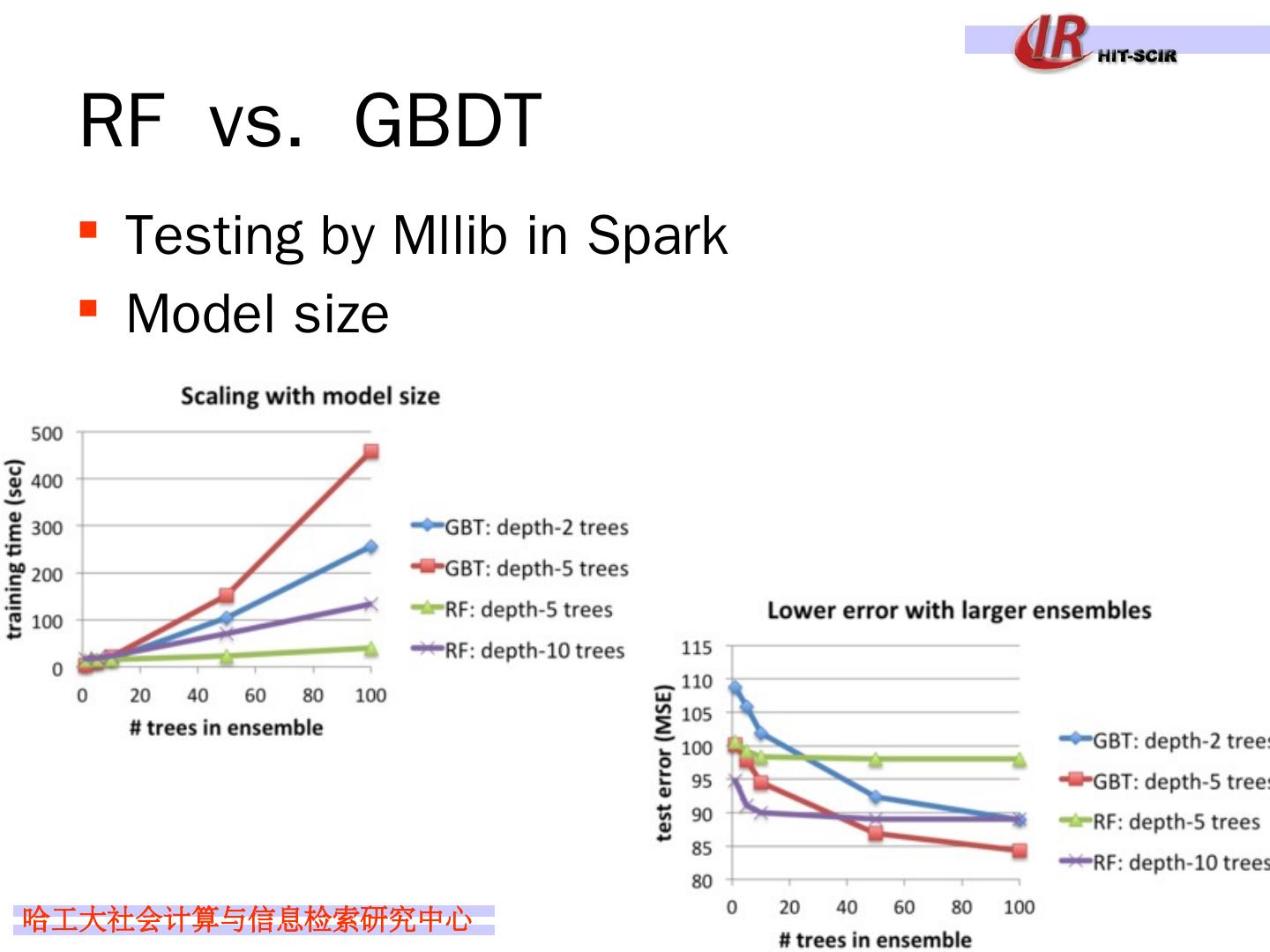
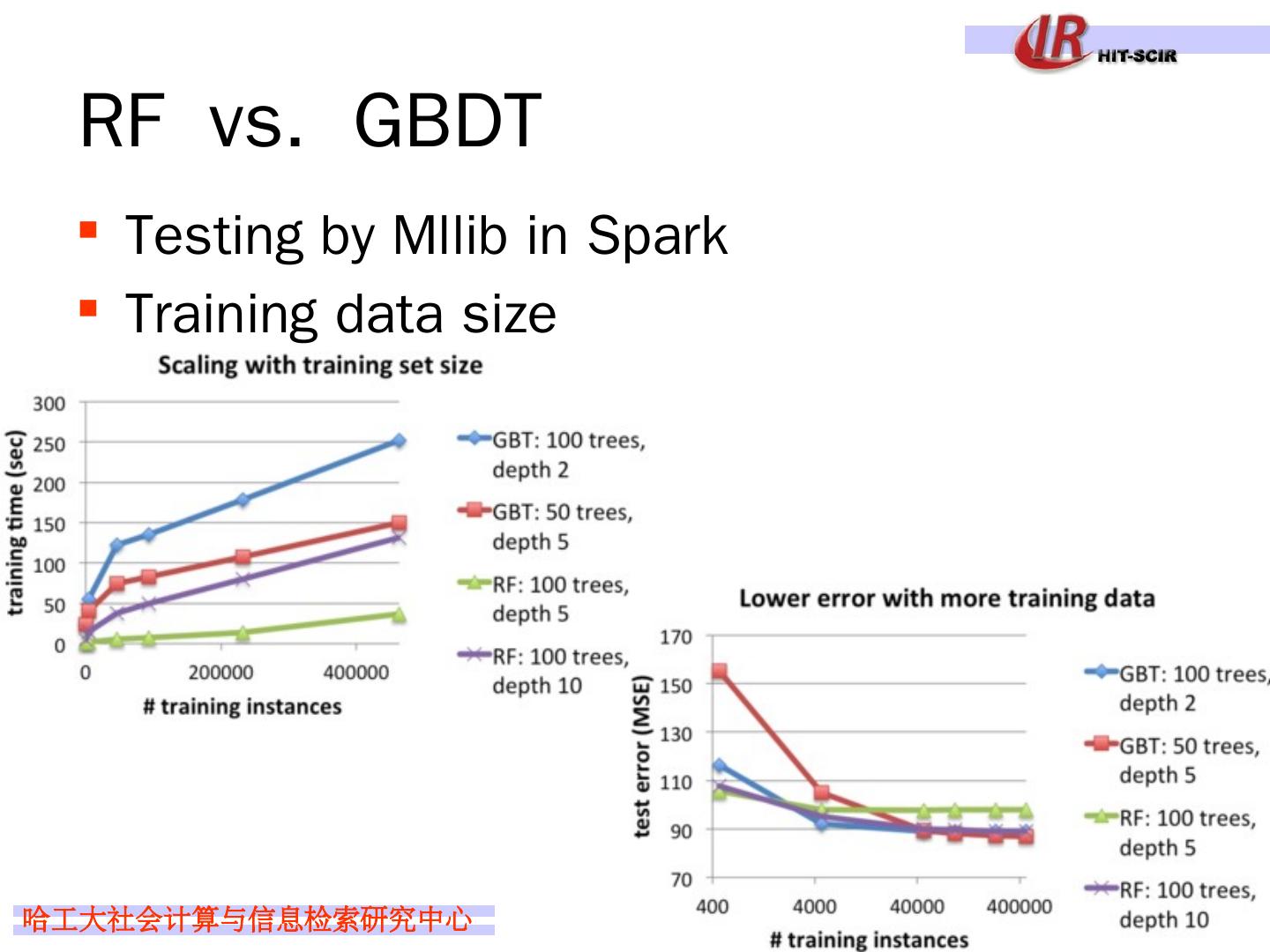
29 .Idea 4: boosting
相关推荐
3秒后跳转登录页面
去登陆

