1 .Spark 源码性能优化 案例分析 李智慧
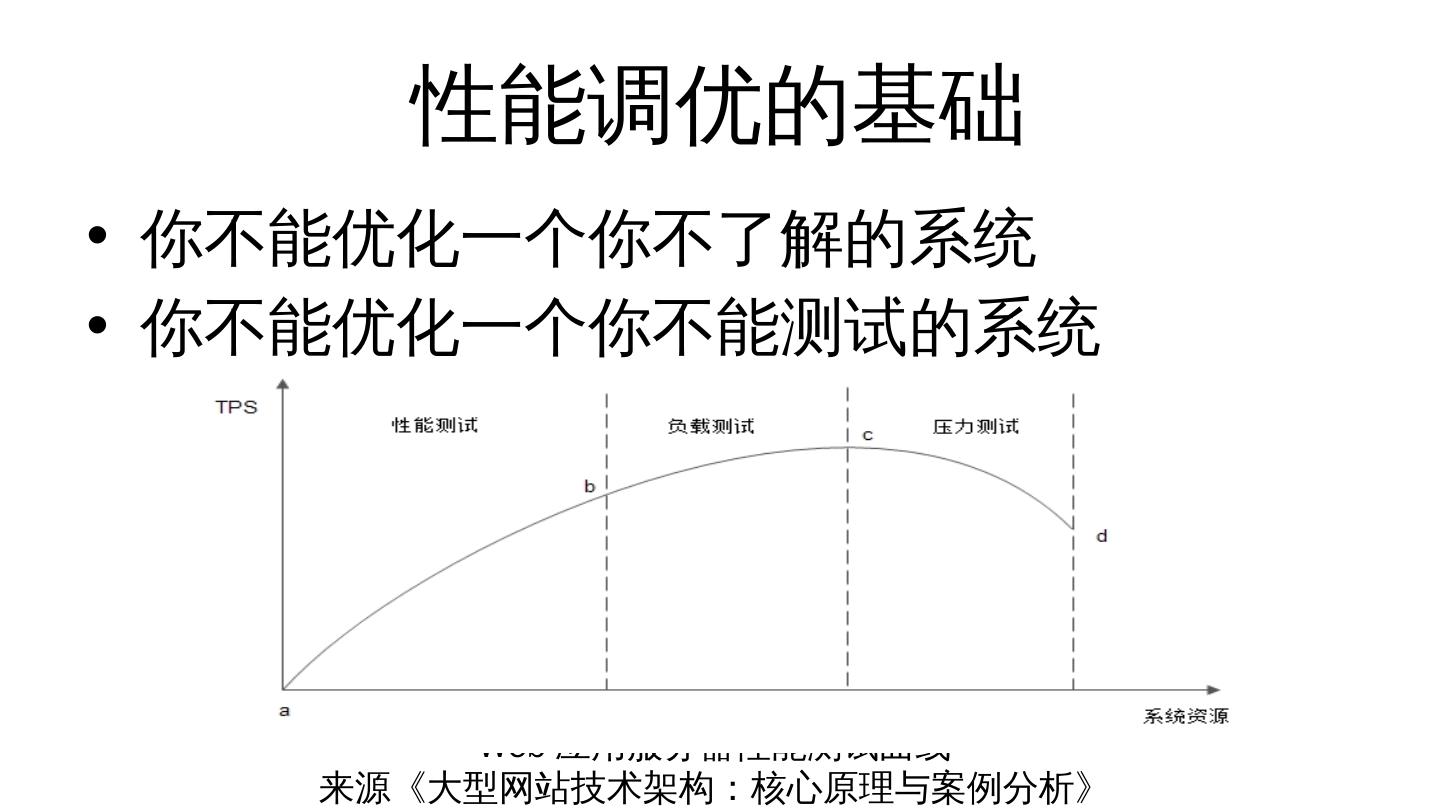
2 .性能调优的基础 你不能优化一个你不了解的系统 你不能优化一个你不能测试的系统 Web 应用服务器性能测试曲线 来源 《 大型网站技术架构:核心原理与案例分析 》
3 .性能调优的步骤 性能测试,观察系统性能特性 资源( CPU 、 Memory 、 Disk 、 Net )利用分析,寻找资源瓶颈 ,提高资源利用 系统架构、代码分析,发现资源利用关键所在 代码、架构、基础设施调优,优化、平衡资源利用 性能测试,观察系统性能特性
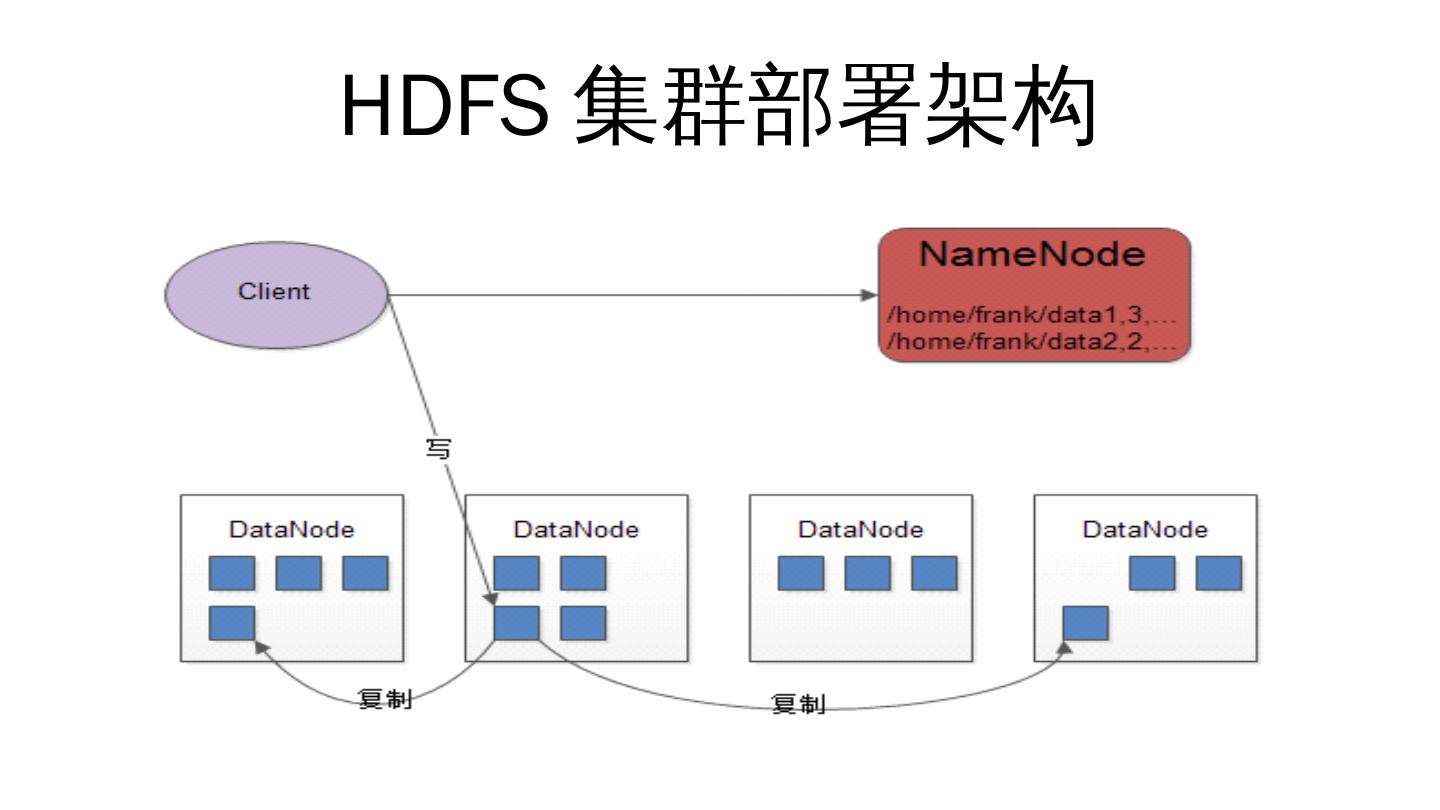
4 .HDFS 集群部署架构
5 .Spark 集群部署架构
6 .Spark 性能测试工具 Spark 性能测试基准程序 Benchmark https://github.com/intel-hadoop/ HiBench Spark 性能测试与分析可视化工具 https://github.com/zhihuili/ Dew
7 .Spark 性能测试 Spark 作业调度的几个概念: Job , Stage , Task
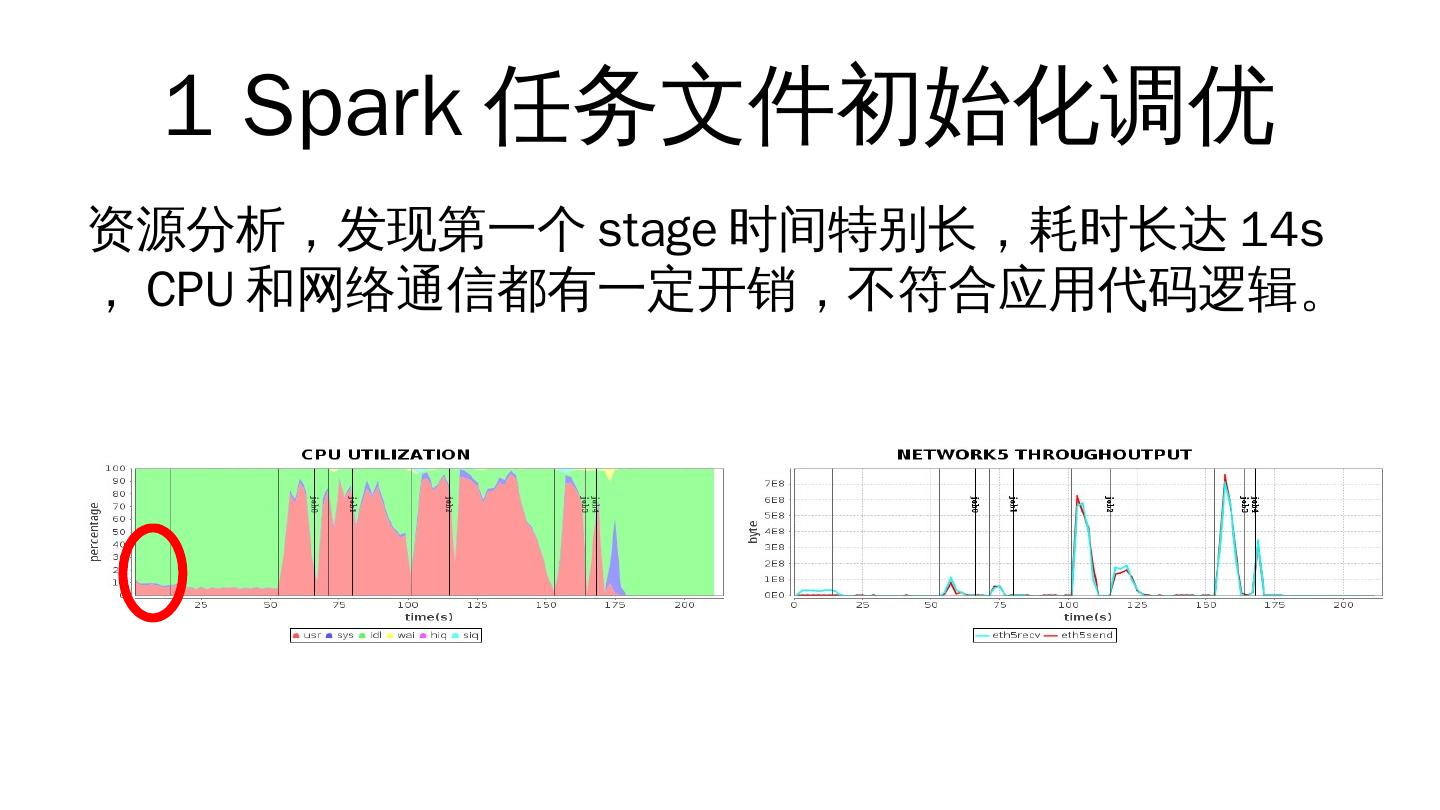
8 .1 Spark 任务文件初始化调优 资源分析,发现第一个 stage 时间特别长,耗时长达 14s , CPU 和网络通信都有一定开销,不符合应用代码逻辑。
9 .打开 Spark 作业 log ,分析这段时间的 Spark 运行状况。 根据 log 分析结果,阅读 Spark 相关源码。 发现 Spark 在任务初始化加载应用代码的时候,每个 Executor 都加载一次应用代码,当时每台服务器最多可启动 48 个 Executor ,每个应用代码包 17M 大小,导致加载开销巨大。
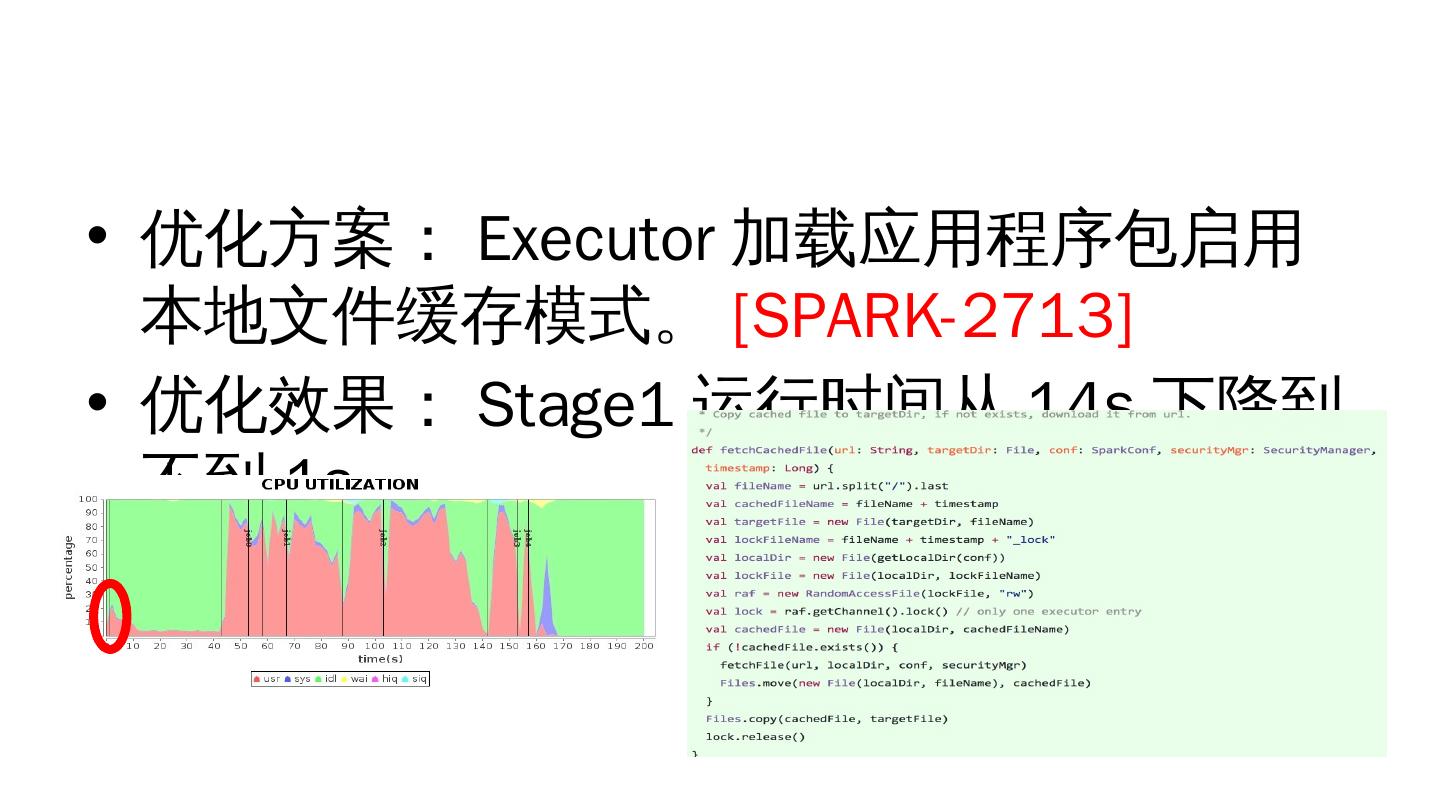
10 .优化方案: Executor 加载应用程序包启用本地文件缓存模式。 [SPARK-2713 ] 优化效果: Stage1 运行时间从 14s 下降到不到 1s 。
11 .2 Spark 任务调度优化 资源分析,发现 stage2 只有一台服务器上的 CPU 被使用,其他服务器 CPU 完全空闲。
12 .打开 Spark 作业 log ,分析这段时间的 Spark 运行状况。 根据 log 分析结果, 阅读 Spark 相关源码。 通过源码发现, Spark Driver 在任务分配的时候 ,仅针对当前已经向 Driver 注册过的 Executor 进行任务分配,而 Executor 的注册是有先后的,如果第一个 job 的任务数比较少,就会出现第一个 Worker 的 Executor 注册的时候将所有任务领走的情况。
13 .优化方案:增加两个配置项,当注册 Executor 达到一定比例时,才开始任务分配。 [SPARK-1946][SPARK-2635] spark.scheduler.minRegisteredResourcesRatio spark.scheduler.maxRegisteredResourcesWaitingTime 优化效果: stage2 运行时间缩短,性能提升 1.32 倍
14 .3 任务分配算法调优 在做 log 分析的时候,发现在 Executor 领取任务的时候,在最后总会有一两个 Executor 领取的任务是非 local 的。比如,最后两个任务 A [ 2,3,1] 和 B[1,3,4] , Executor [ 1][2] ,当 Executor[1] 领取了任务 A ,则 Executor [ 2] 领到的任务 B 就是非 local 的。 解决方案:对任务进行偏序排序后再分配 [SPARK-2193]
15 .4 OS 配置调优 资源分析,发现服务器大量 CPU 资源消耗为 sys 类型 调查发现,是因为某些 Linux 版本的 t ransparent huge page 默认为 enable 状态导致 优化方案:关闭 OS 的 transparent huge pages Echo never > /sys/kernel/mm/ transparent_hugepage /enabled Echo never > /sys/kernel/mm/ transparent_hugepage / defrag Transparent huge page 开启 Transparent huge page 关闭
16 .5 网卡调优 资源分析,发现大量作业时间消耗在网络传输上。 解决方案:网卡带宽从 1G 升级到 10G 1G 网卡 10G 网卡
17 .Thank you for watching
确定删除吗?