























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark Shuffle Tuning In Facebook
讲解了Facebook在spark shuffle方面的优化,相关论文为 EuroSys ’18: Riffle: Optimized Shuffle Service for Large-Scale Data Analytics
展开查看详情
1 .
2 .SOS: Optimizing Shuffle I/O Brian Cho and Ergin Seyfe, Facebook Haoyu Zhang, Princeton University
3 .1. Shuffle I/O at large scale
4 .Large-scale shuffle Stage 1 Stage 2 • Shuffle: all-to-all communication between stages • >10x larger than available memory, strong fault tolerance requirements → on-disk shuffle files
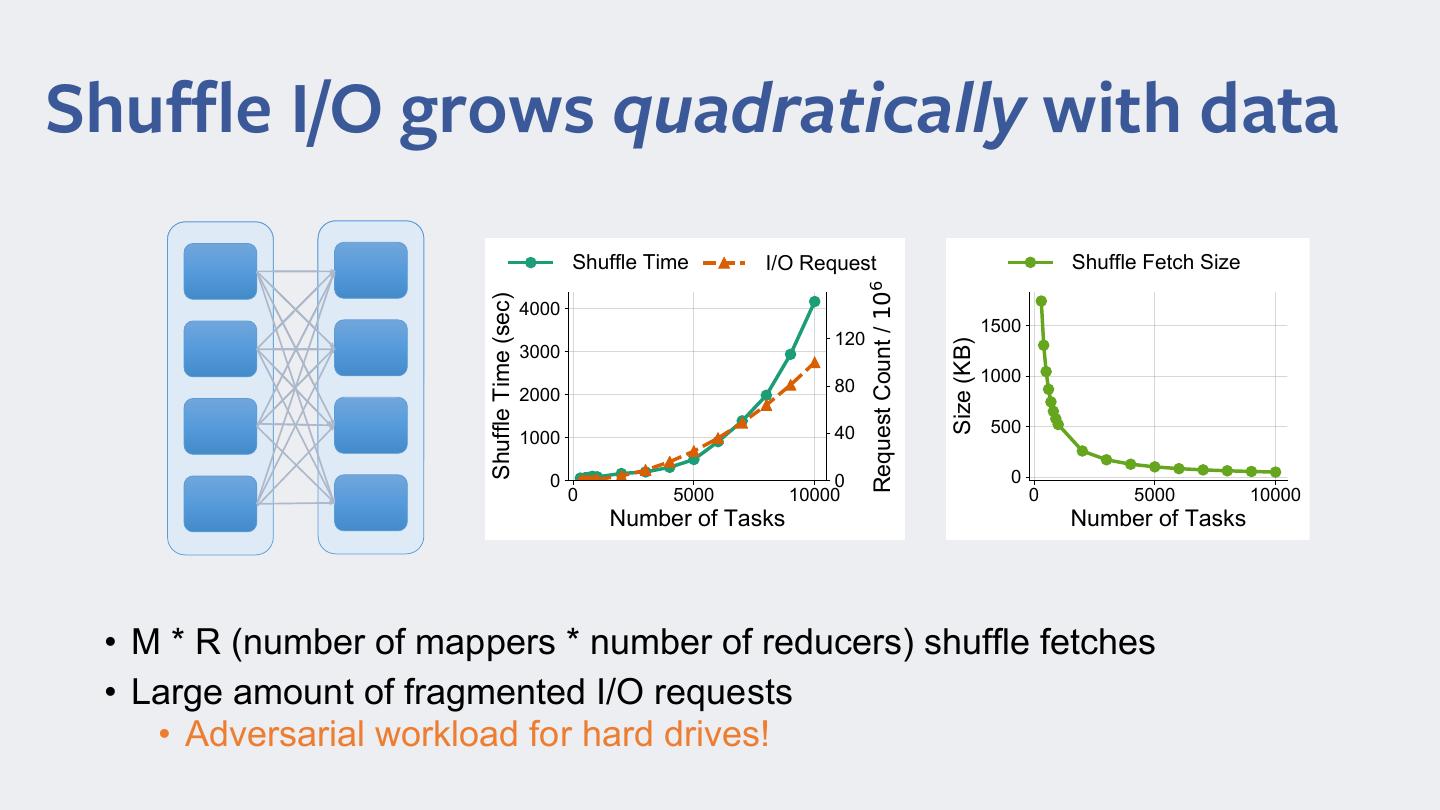
5 .Shuffle I/O grows quadratically with data ShuIIOe Time I/2 5eTuest SKuffle )etFK Size 5eTuest CRunt / 106 ShuIIOe Time (sec) 4000 1500 120 Size (KB) 3000 1000 2000 80 40 500 1000 0 0 0 0 5000 10000 0 5000 10000 1umber RI TasNs 1umber of TasNs • M * R (number of mappers * number of reducers) shuffle fetches • Large amount of fragmented I/O requests • Adversarial workload for hard drives!
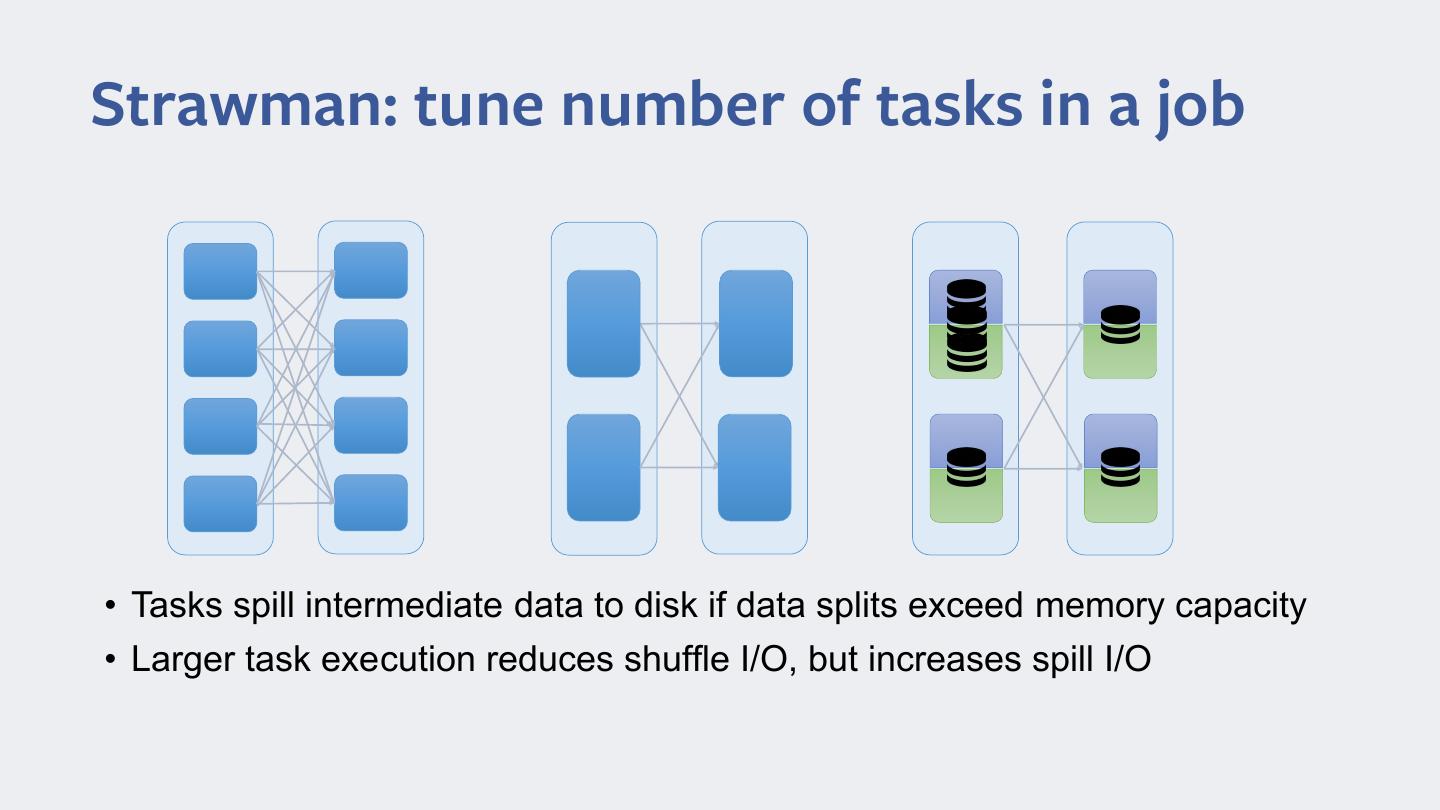
6 .Strawman: tune number of tasks in a job • Tasks spill intermediate data to disk if data splits exceed memory capacity • Larger task execution reduces shuffle I/O, but increases spill I/O
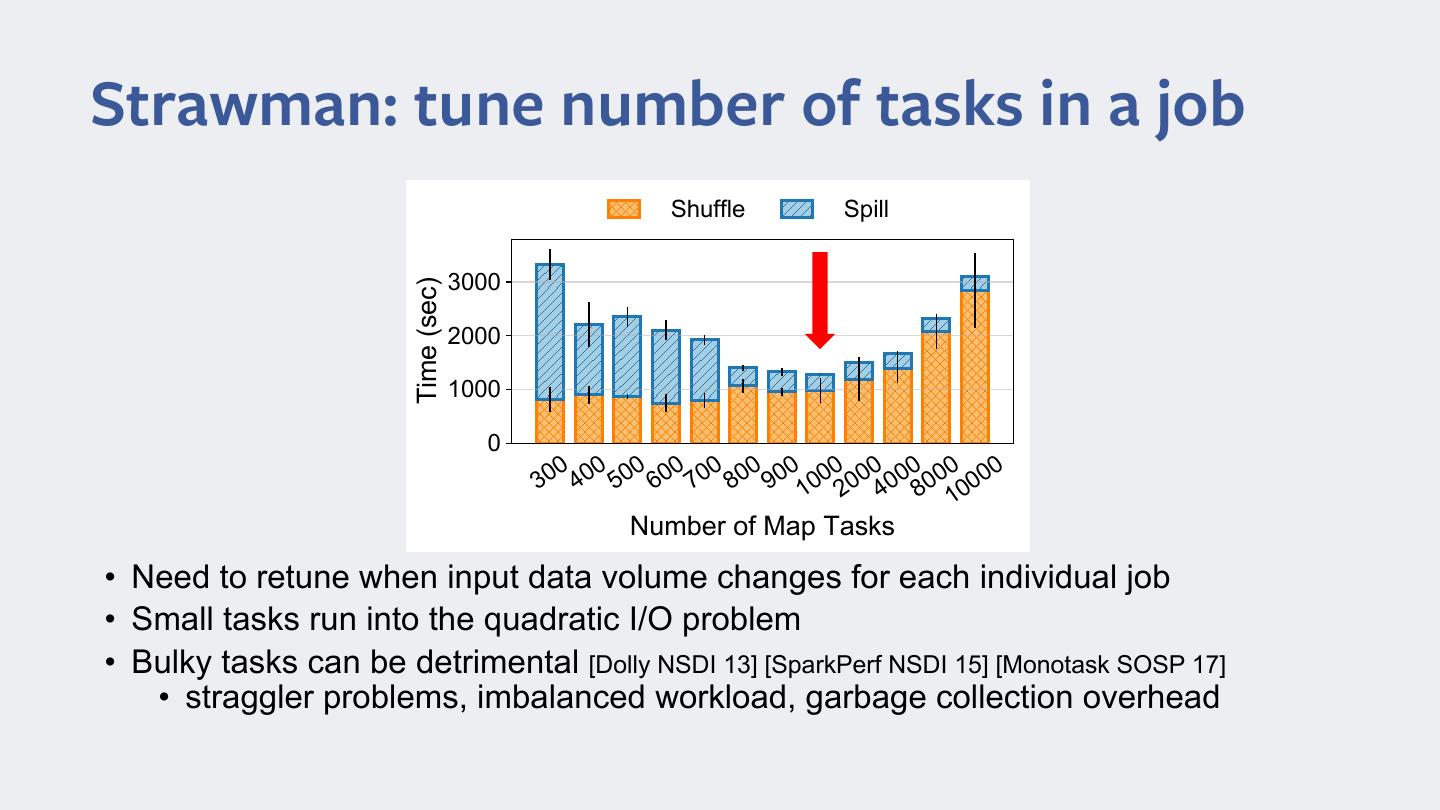
7 .Strawman: tune number of tasks in a job 6huffle 6Sill 3000 3000 7ime (sec) 2000 2000 1000 0 00 00 00 00 00 00 00 00 00 00 00 00 3 4 5 6 7 8 9 10 20 40 80 00 1 1umber of 0aS 7asNs • Need to retune when input data volume changes for each individual job • Small tasks run into the quadratic I/O problem • Bulky tasks can be detrimental [Dolly NSDI 13] [SparkPerf NSDI 15] [Monotask SOSP 17] • straggler problems, imbalanced workload, garbage collection overhead
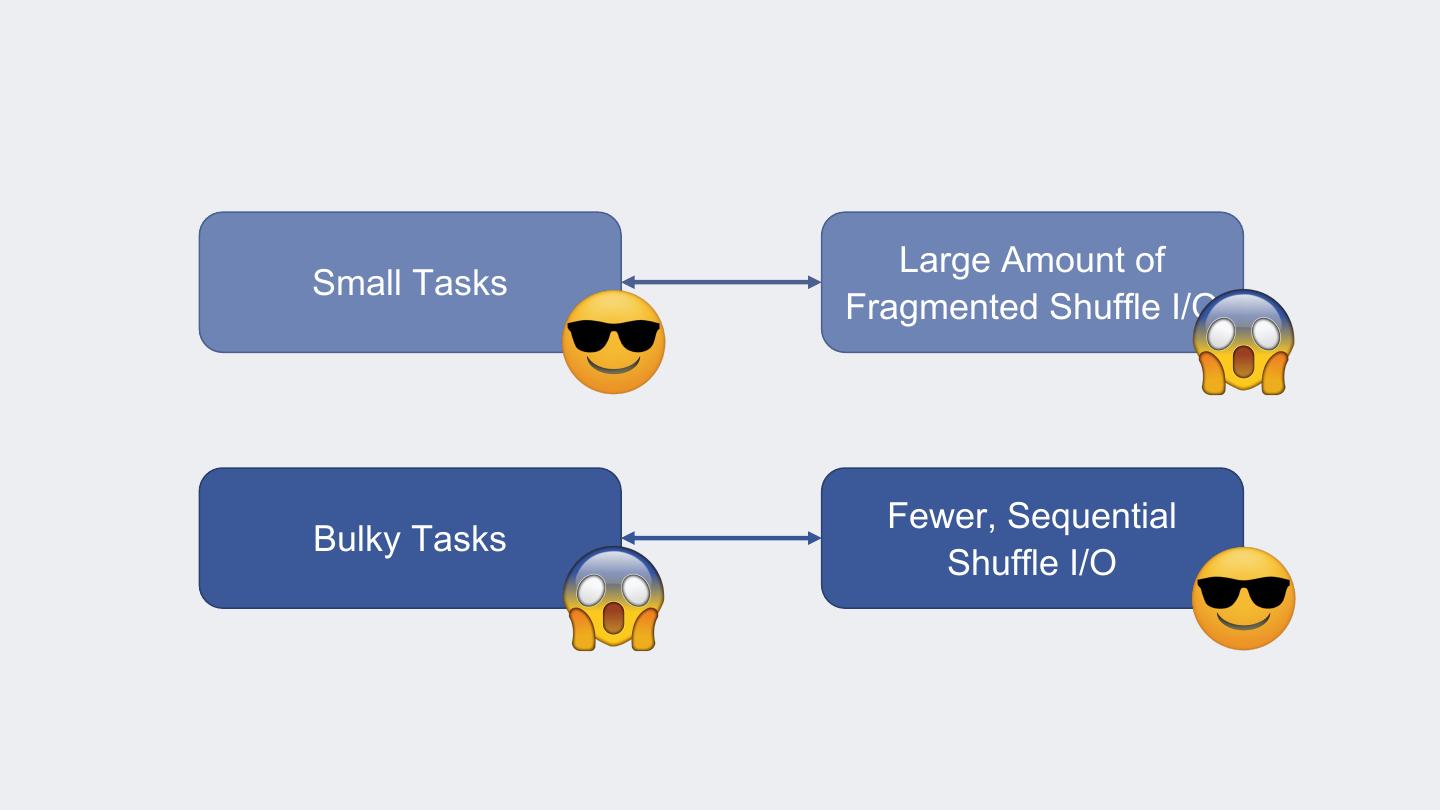
8 . Large Amount of Small Tasks Fragmented Shuffle I/O Fewer, Sequential Bulky Tasks Shuffle I/O
9 .2. SOS: optimizing shuffle I/O
10 .SOS: optimizing shuffle I/O a.k.a. Riffle, presented at Eurosys 2018 Deployed at Facebook scale
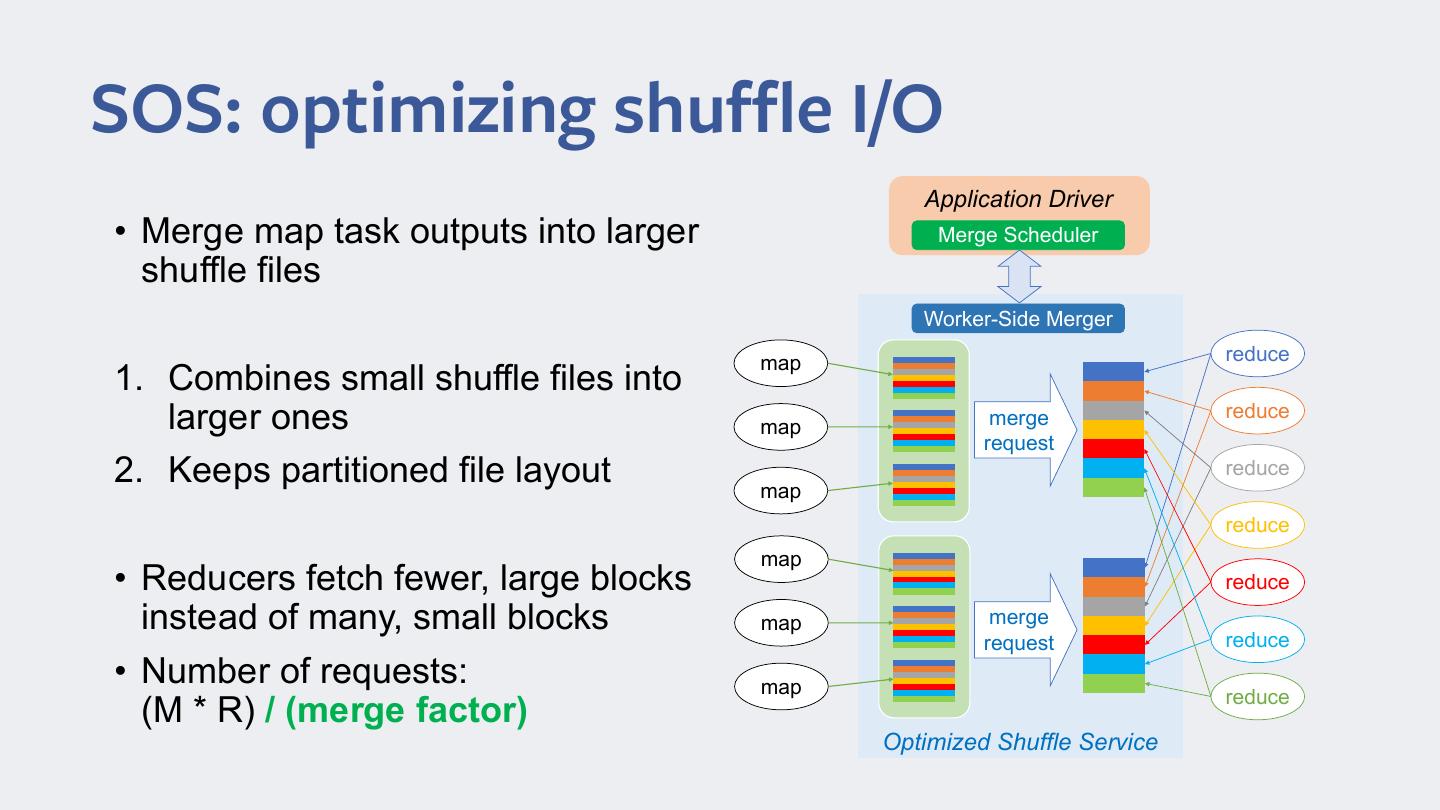
11 .SOS: optimizing shuffle I/O Application Driver • Merge map task outputs into larger Merge Scheduler shuffle files Worker-Side Merger map reduce 1. Combines small shuffle files into larger ones map merge reduce request 2. Keeps partitioned file layout map reduce reduce map • Reducers fetch fewer, large blocks reduce instead of many, small blocks map merge reduce request • Number of requests: map reduce (M * R) / (merge factor) Optimized Shuffle Service
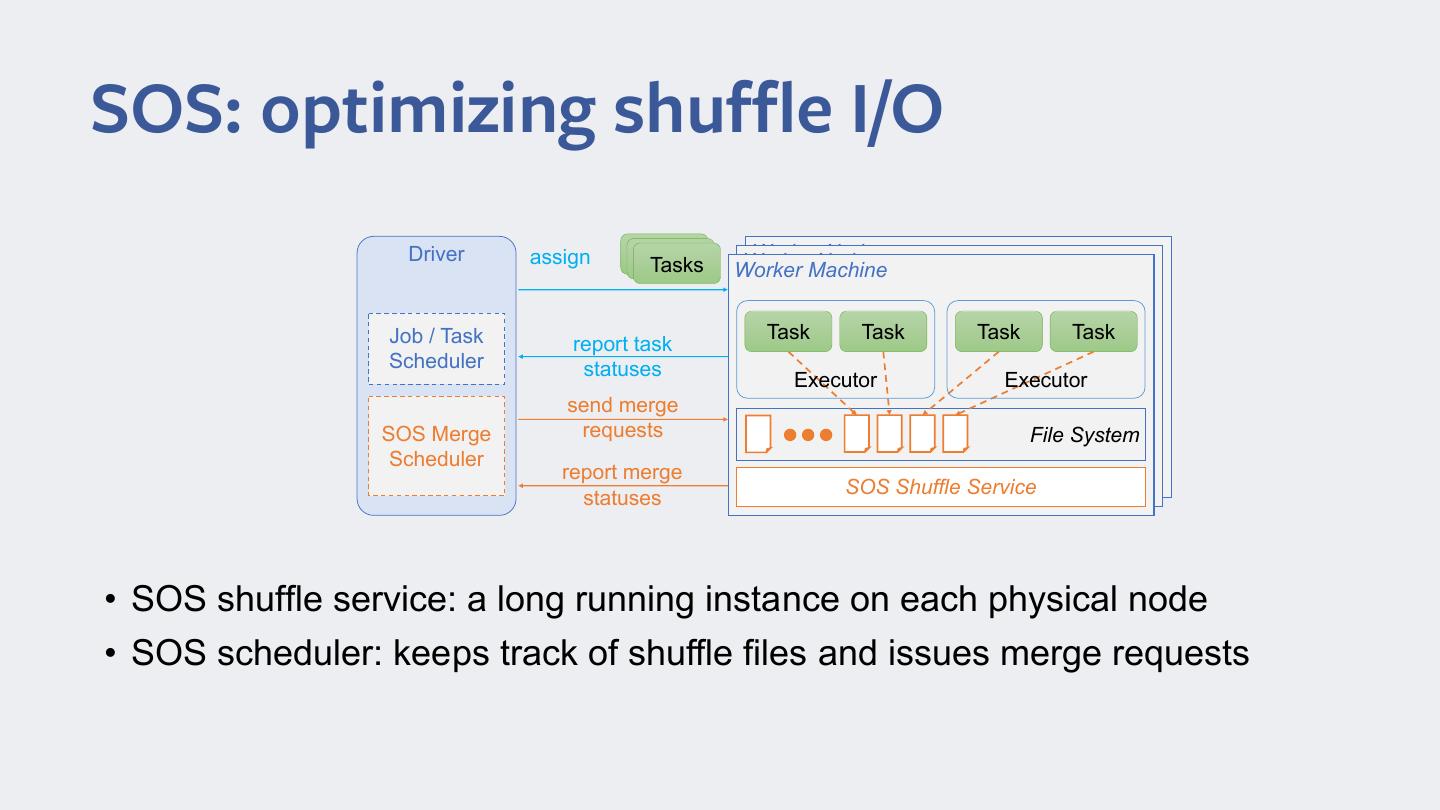
12 .SOS: optimizing shuffle I/O Driver assign Task Task WorkerNode Worker Node Tasks Worker Machine Job / Task Task Task Task Task report task Scheduler statuses Executor Executor send merge SOS Merge requests File System Scheduler report merge SOS Shuffle Service statuses • SOS shuffle service: a long running instance on each physical node • SOS scheduler: keeps track of shuffle files and issues merge requests
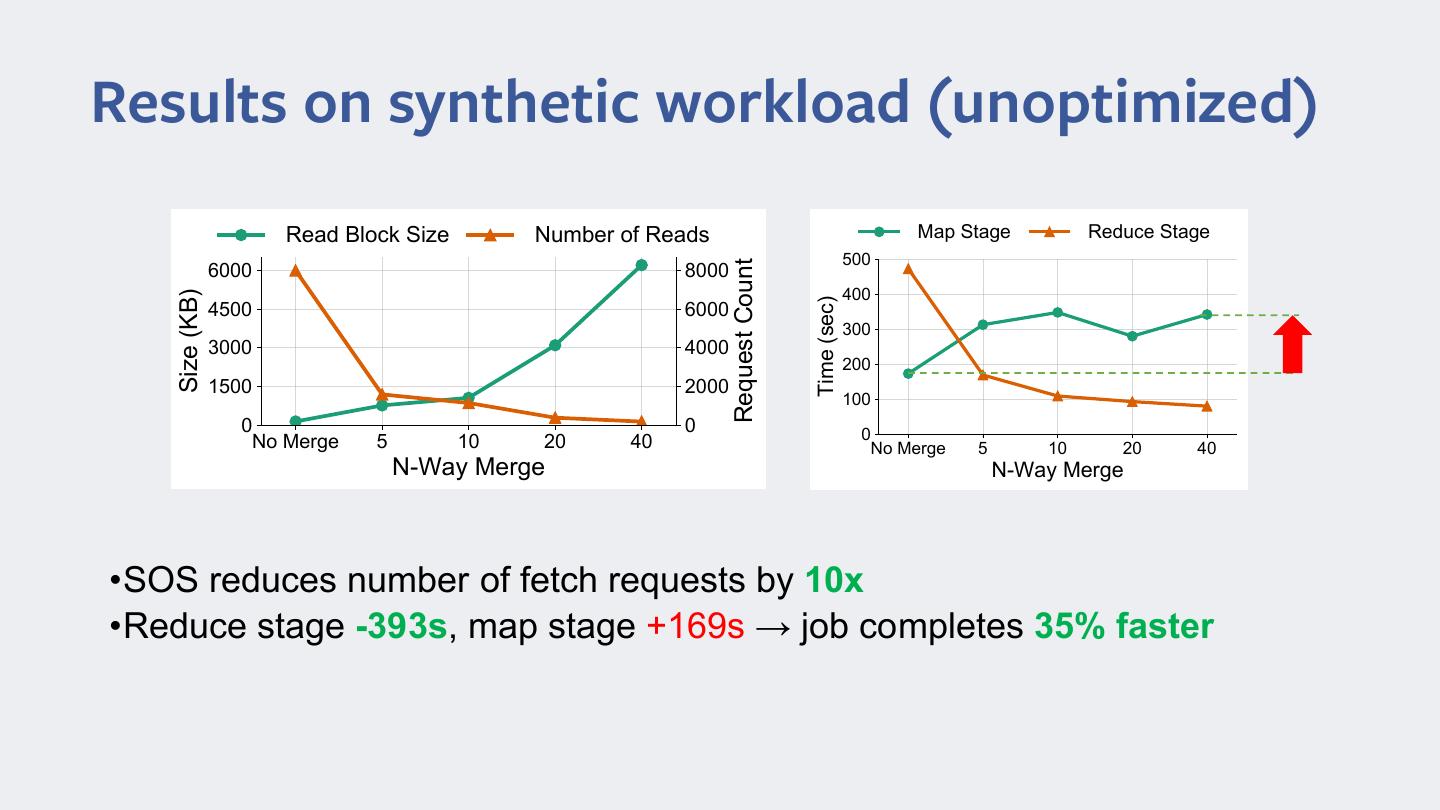
13 .Results on synthetic workload (unoptimized) 5ead BlRcN 6ize 1umber Rf 5eads 0aS SWage 5educe SWage 500 5equesW CRunW 6000 8000 400 6ize (KB) Time (sec) 4500 6000 300 3000 4000 200 1500 2000 100 0 0 0 1R 0erge 5 10 20 40 1R 0erge 5 10 20 40 1-Way 0erge 1-Way 0erge •SOS reduces number of fetch requests by 10x •Reduce stage -393s, map stage +169s → job completes 35% faster
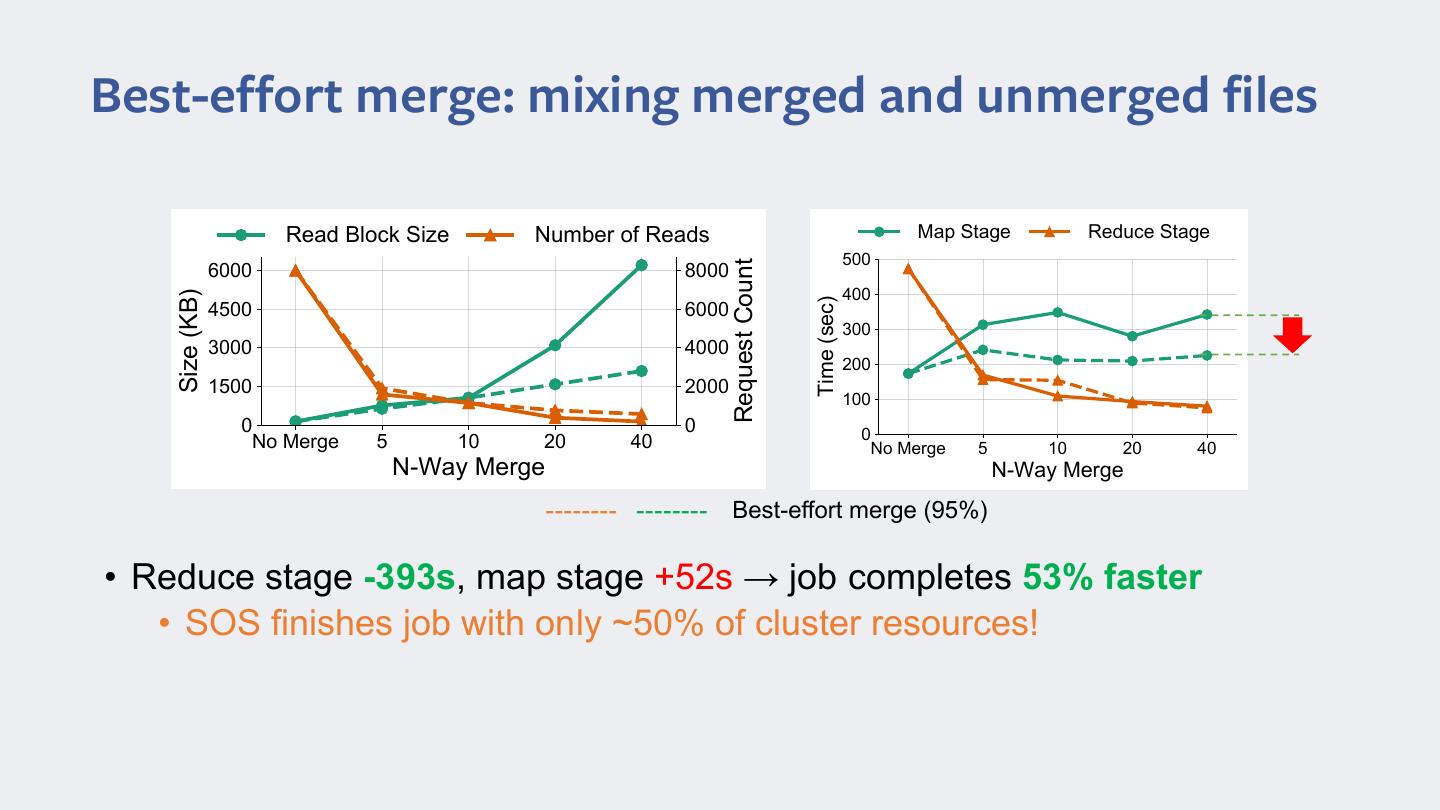
14 .Best-effort merge: mixing merged and unmerged files 5ead BlRcN 6ize 1umber Rf 5eads 0aS SWage 5educe SWage 500 5equesW CRunW 6000 8000 400 6ize (KB) Time (sec) 4500 6000 300 3000 4000 200 1500 2000 100 0 0 0 1R 0erge 5 10 20 40 1R 0erge 5 10 20 40 1-Way 0erge 1-Way 0erge Best-effort merge (95%) • Reduce stage -393s, map stage +52s → job completes 53% faster • SOS finishes job with only ~50% of cluster resources!
15 .Additional details • Merge operation fault-tolerance • Handled by falling back to the unmerged files • Efficient memory management • Merger read/write large buffers for performance and IO efficiency Buffered Read Block 65-1 Buffered Write Block 65-2 … … … … Block 65 Block 65 Block 65 Block 65-m Merge Block 66 Block 66 … Block 66 Block 66-1 Block 67 Block 67 Block 67 Block 66-2 … … … … Block 66-m
16 .3. Deployment and observed gains
17 .Deployment • Started staged rollout late last year • Completed in April, running stably for over a month
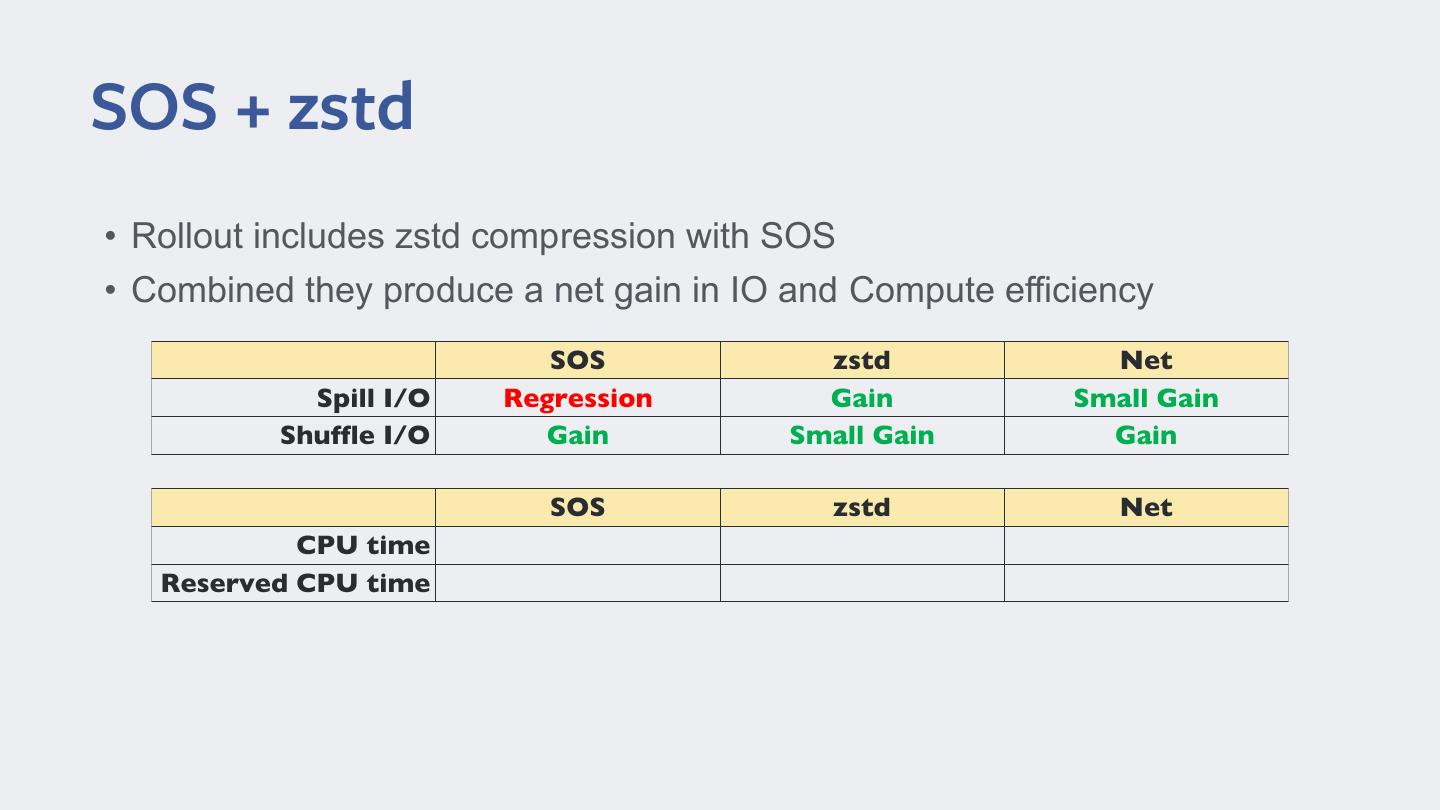
18 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency
19 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Shuffle I/O
20 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Regression Gain Small Gain Shuffle I/O
21 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Regression Gain Small Gain Shuffle I/O Gain Small Gain Gain
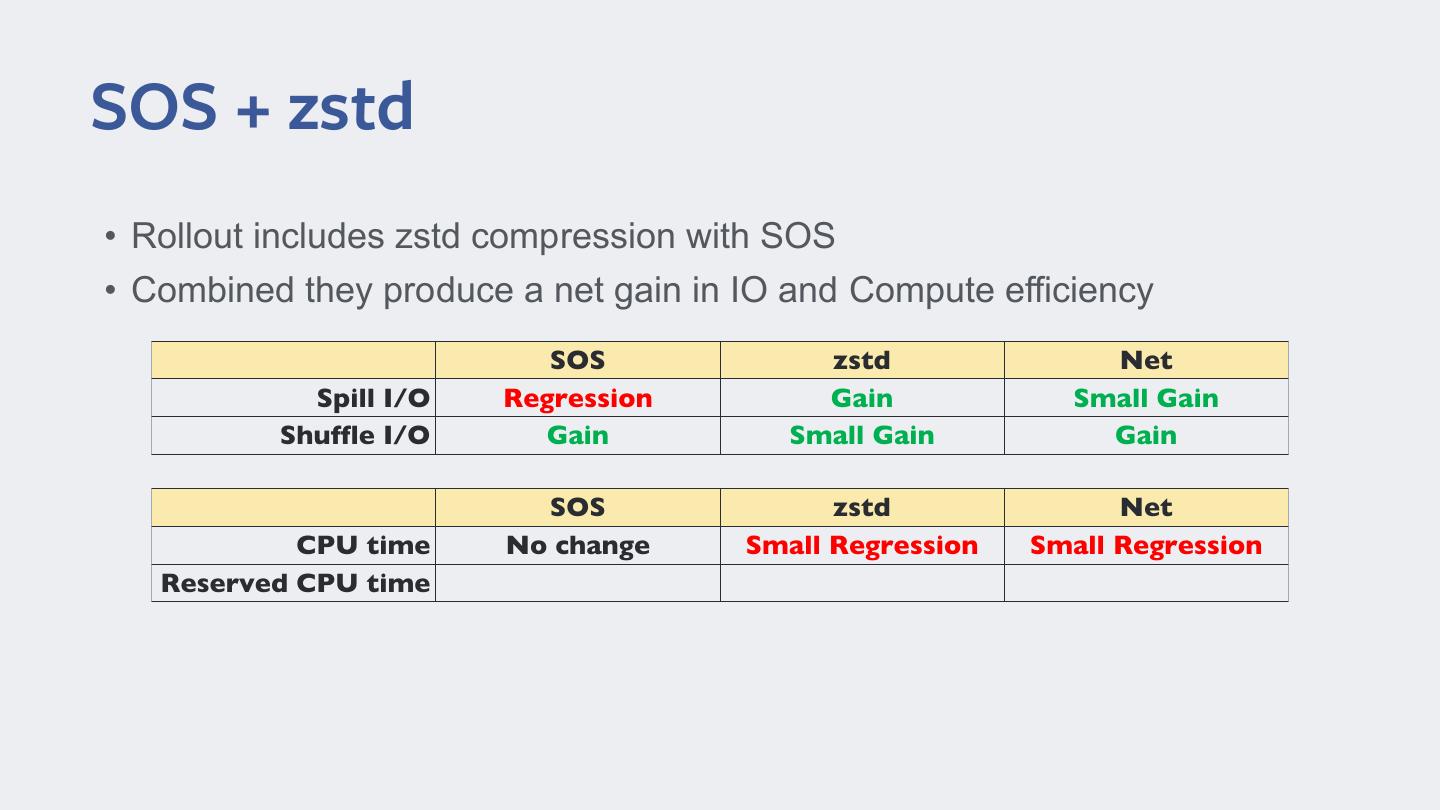
22 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Regression Gain Small Gain Shuffle I/O Gain Small Gain Gain SOS zstd Net CPU time Reserved CPU time
23 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Regression Gain Small Gain Shuffle I/O Gain Small Gain Gain SOS zstd Net CPU time No change Small Regression Small Regression Reserved CPU time
24 .SOS + zstd • Rollout includes zstd compression with SOS • Combined they produce a net gain in IO and Compute efficiency SOS zstd Net Spill I/O Regression Gain Small Gain Shuffle I/O Gain Small Gain Gain SOS zstd Net CPU time No change Small Regression Small Regression Reserved CPU time Gain No change Gain
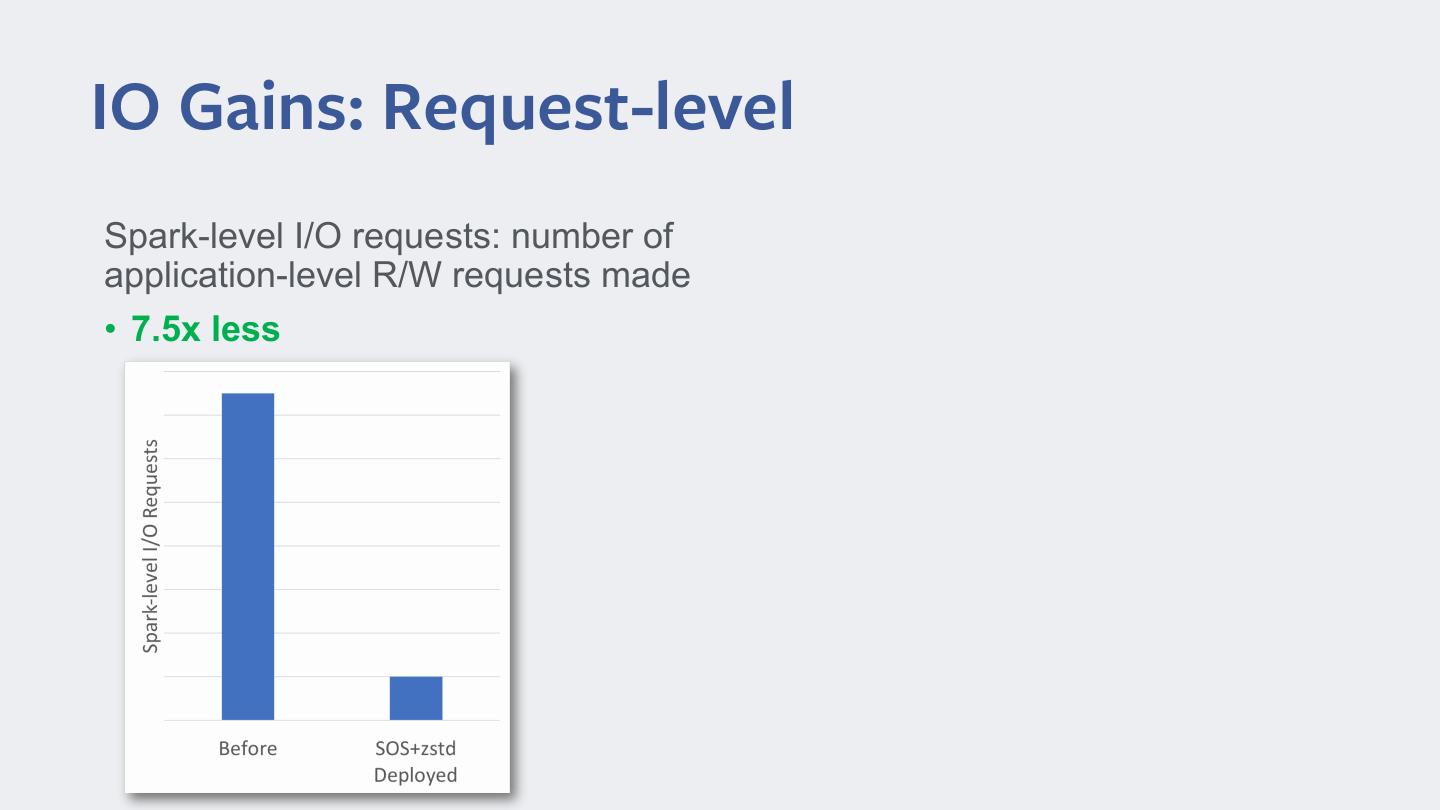
25 .IO Gains: Request-level Spark-level I/O requests: number of application-level R/W requests made • 7.5x less
26 .IO Gains: Disk-level Disk service time: time spent on disks in the storage system • 2x more efficient
27 .IO Gains: Disk-level Disk service time: time spent on Average IO Size: average size disks in the storage system of IO request at the disks • 2x more efficient • 2.5x increase
28 .Compute Gains Reserved CPU time: resources allocated for Spark executors Total 10% Gain • CPU time: time spent using CPU à 5% Regression • I/O time: time spent waiting (not using CPU) à 75% Gain Currently working on increasing these gains
29 .4. Summary
相关推荐
3秒后跳转登录页面
去登陆

