喜马拉雅FM在数据计算中的落地
分享
点赞
7
收藏
3
下载 5
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
介绍喜马拉雅FM大数据平台的逻辑架构,基本功能,应用场景和问题解决方案,特别是需求变迁所带来的平台演化必要性的总结,本篇是对喜马拉雅FM大数据平台在实际应用场景中的落地和演化过程的完整记录和介绍。
展开查看详情
1 .喜⻢马拉雅数据计算平台XQL
数据组 陈涛
2017.11
�
2 .Outline
» XQL系统介绍
» 系统演进过程
» 周边产品
» 经验总结
» 未来展望
�
3 .XQL系统介绍
» 研发背景
» 系统规模
» 使⽤用⼈人群与场景
�
4 .XQL系统介绍 研发背景
» 数据源分散,关联数据源困难
» hive执⾏行行慢
» 基于原始埋点⽇日志分析困难
» 分库分表下报表制作困难
» spark依赖hive元数据,但对hive兼容性⼜又有限
» spark版本变更更频繁,我们业务下特定bad case需要兼容和fix
�
5 .XQL系统介绍 系统规模
» 使⽤用内存4T,⽇日均spark task超过200w
» XQL id达到40W,每天4000+任务
» ⽀支撑公司⼤大部分的ETL和分析需求
» 接⼊入的数据源有hdfs、hive、hbase、es、kafka、mysql和pg
» ⽀支持的数据格式有parquet、orc、csv、json和xml
�
6 .XQL系统介绍 使⽤用⼈人群与场景
» 增⻓长部⻔门:ETL、分析需求
» 数据部⻔门:SDK调⽤用、机器器学习的数据交互
» 业务部⻔门:报表需求、REST接⼝口、单独提交、异构数据同步
» 运营部⻔门:可视化界⾯面、分析需求
�
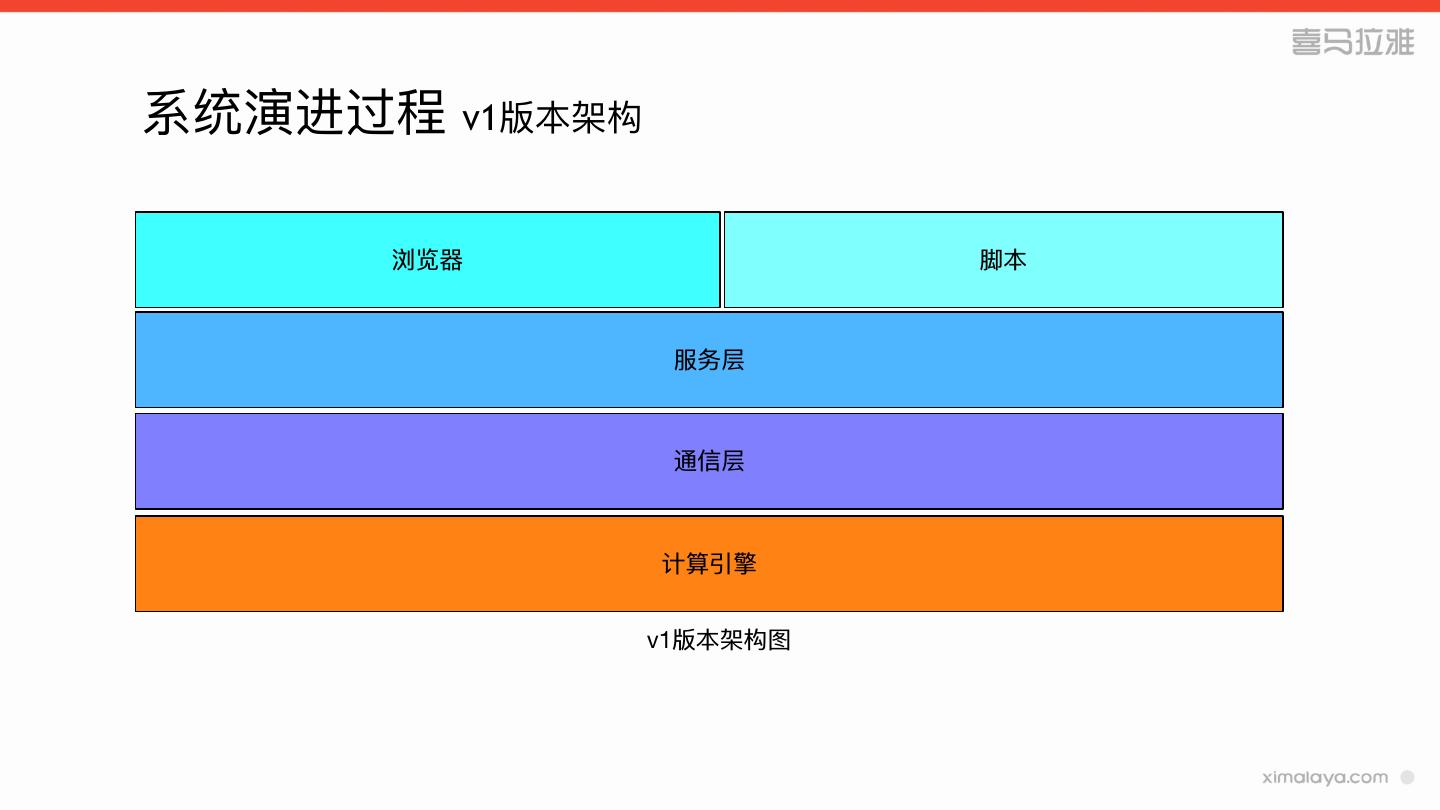
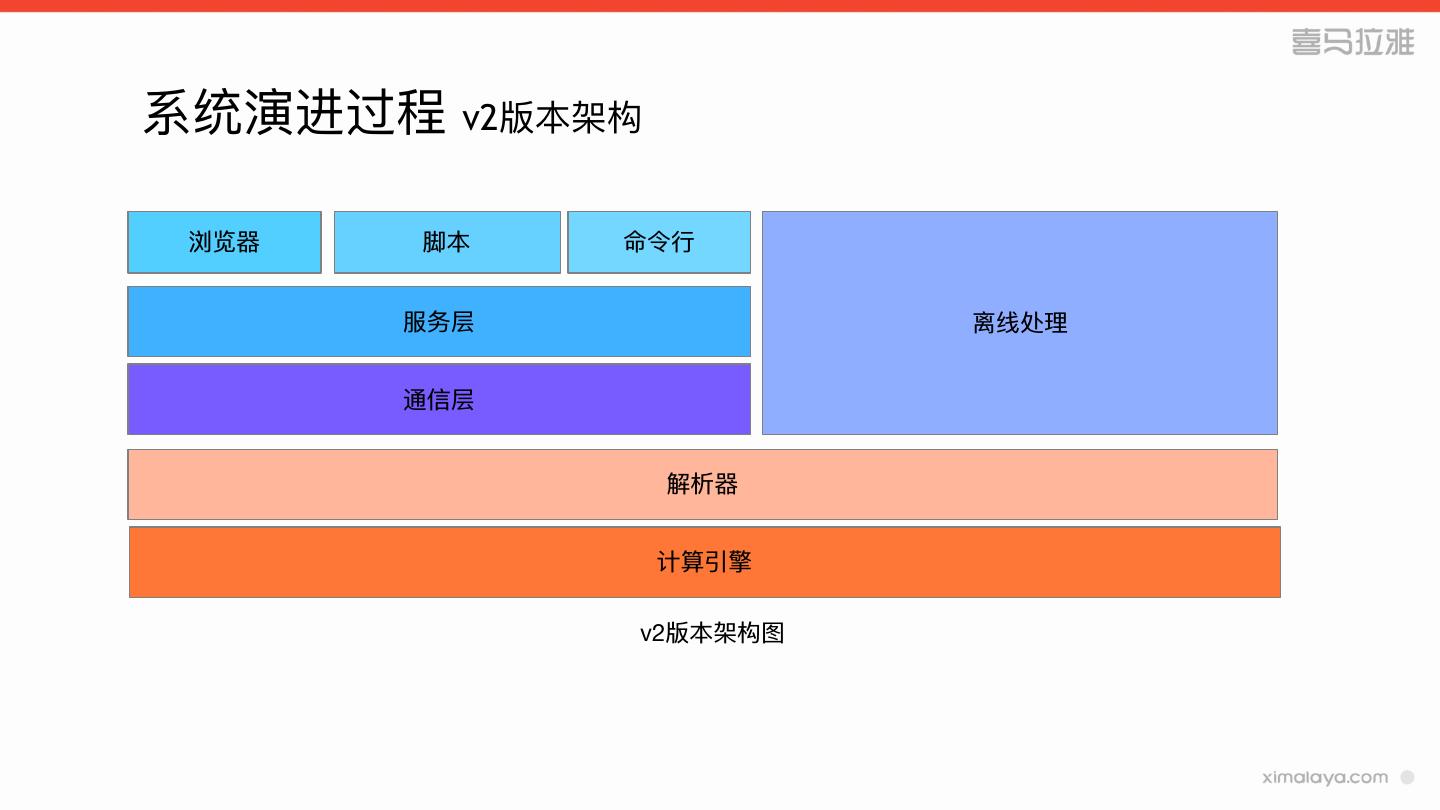
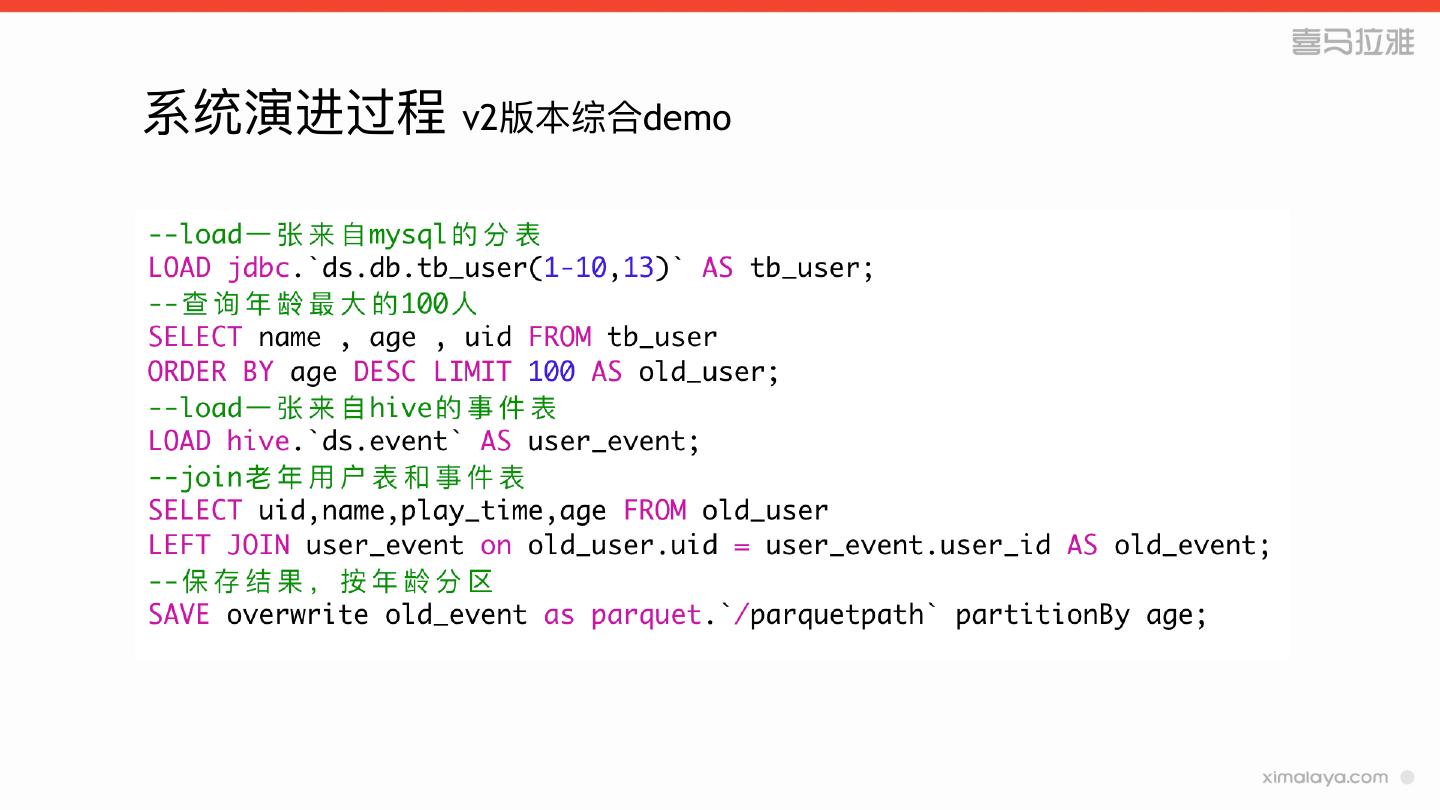
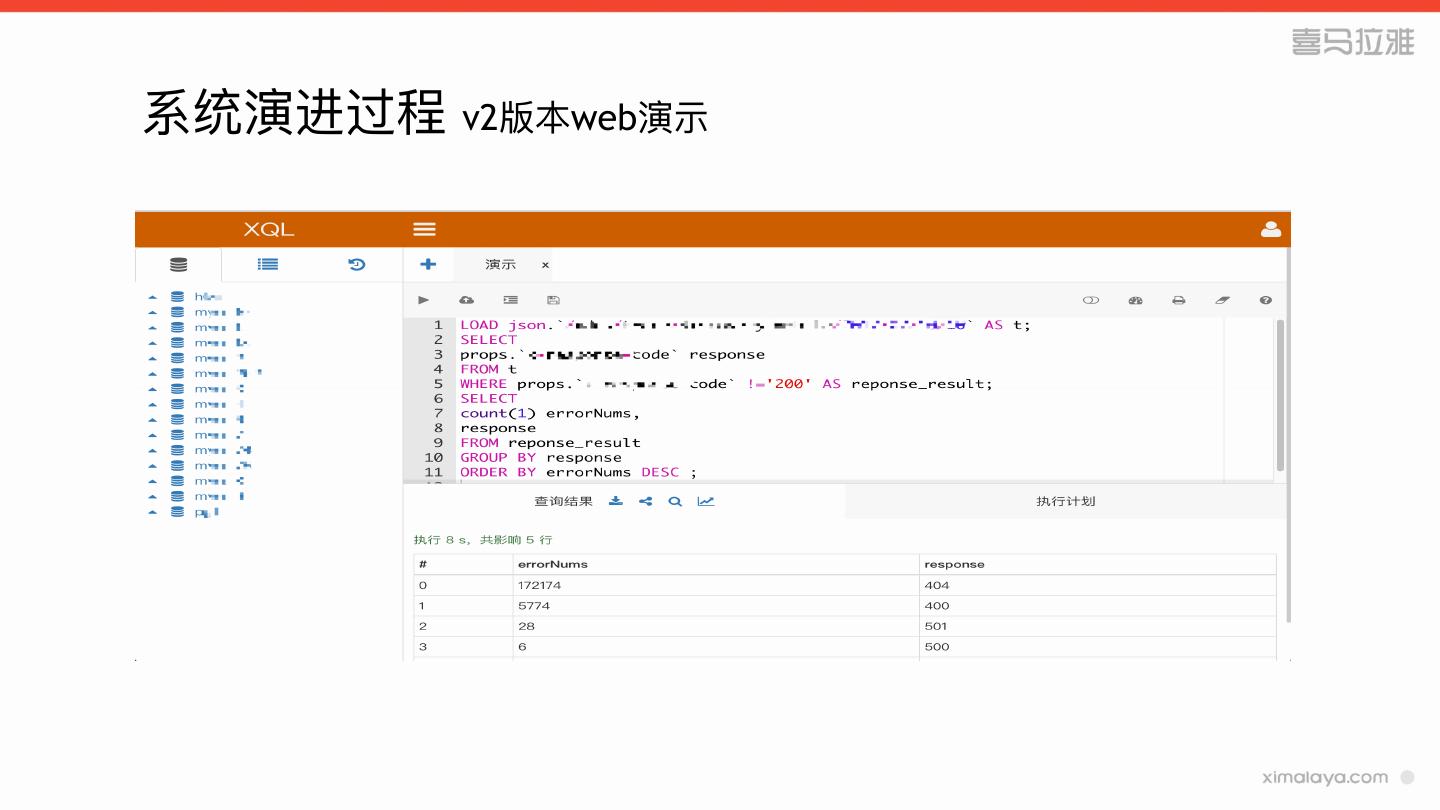
7 .系统演进过程
» v1版本
» v2版本
» v3版本
�
10 .系统演进过程 v1版本其他功能
» 采⽤用spark sql代替hive
» spark常驻服务
» 对hbase和json的hive表做了了适配
» ⽀支持⽂文件的上传下载
» 提供rest接⼝口,⽀支持shell脚本和程序调⽤用
�
11 .系统演进过程 v1版本存在的问题
» 数据源⽀支持⽐比较有限
» 依赖hive的元数据
» sql可读性差的问题仍未解决
» 服务稳定性不不⾼高
» 没有⽤用户权限验证
» ⼤大任务会耗尽所有资源
�
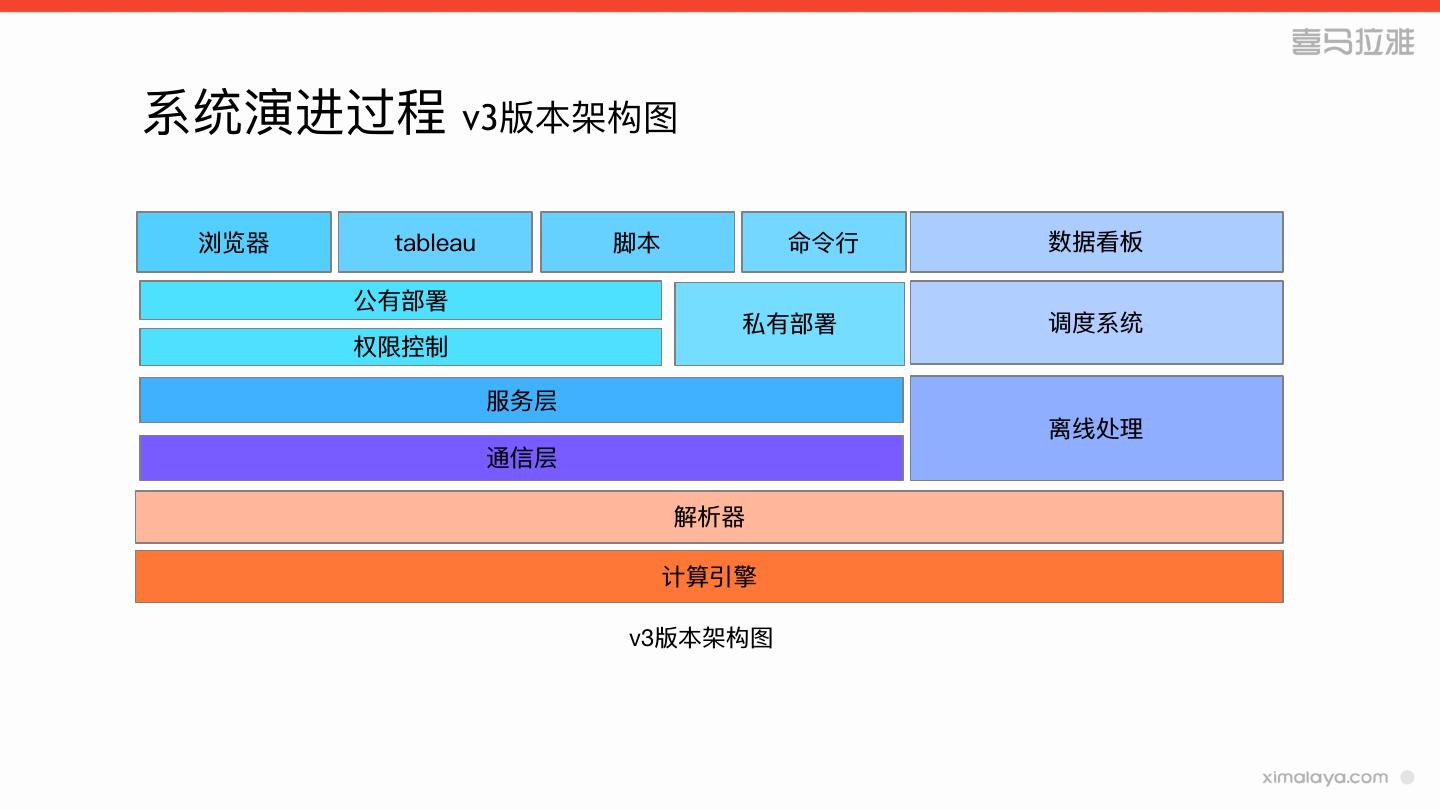
18 .系统演进过程 v2版本其他功能
» 账号系统
» 采⽤用spark的fair调度
» ⽀支持邮件订阅结果
» 查询结果分享
» 上传下载智能转码
» 语法帮助,sql⾃自动⽣生成
�
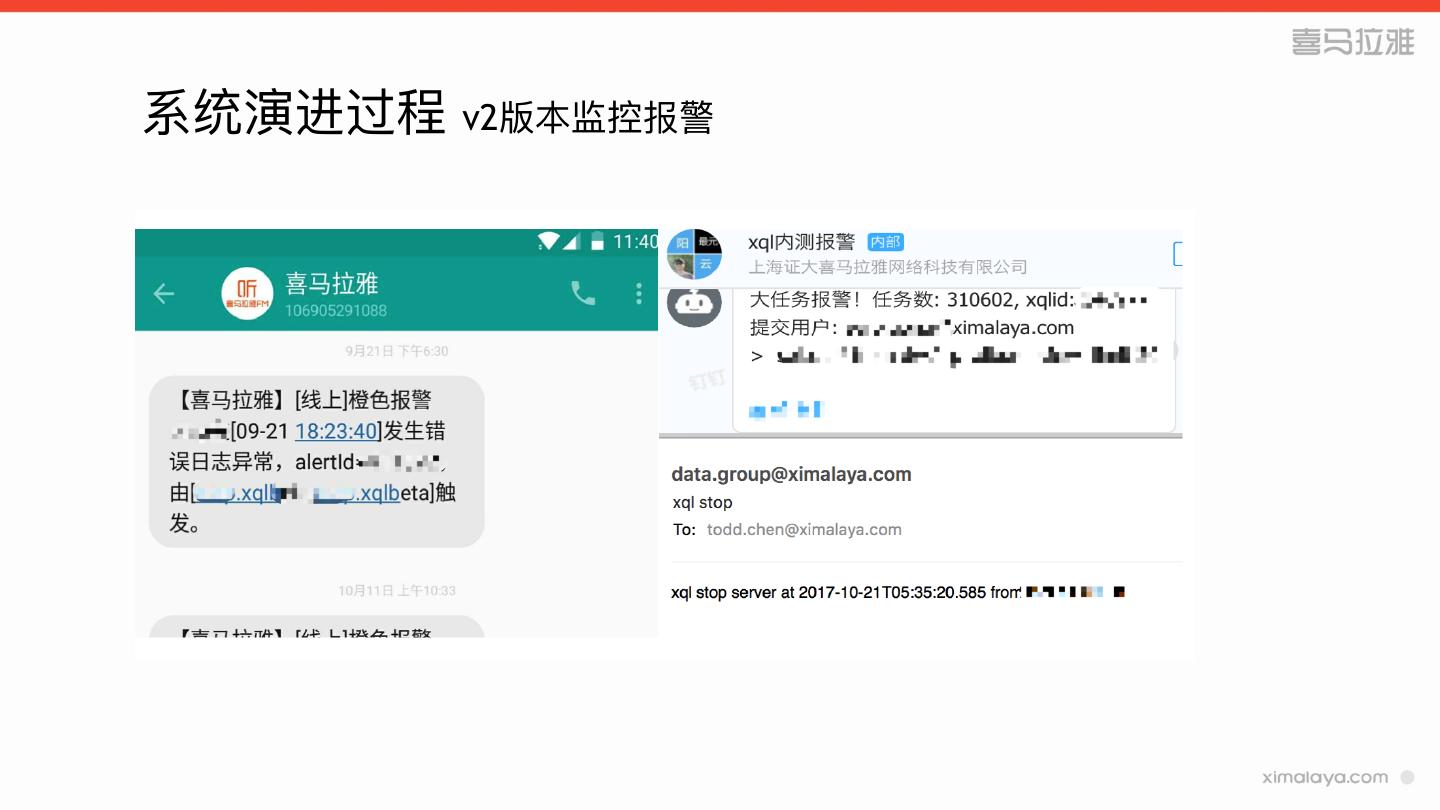
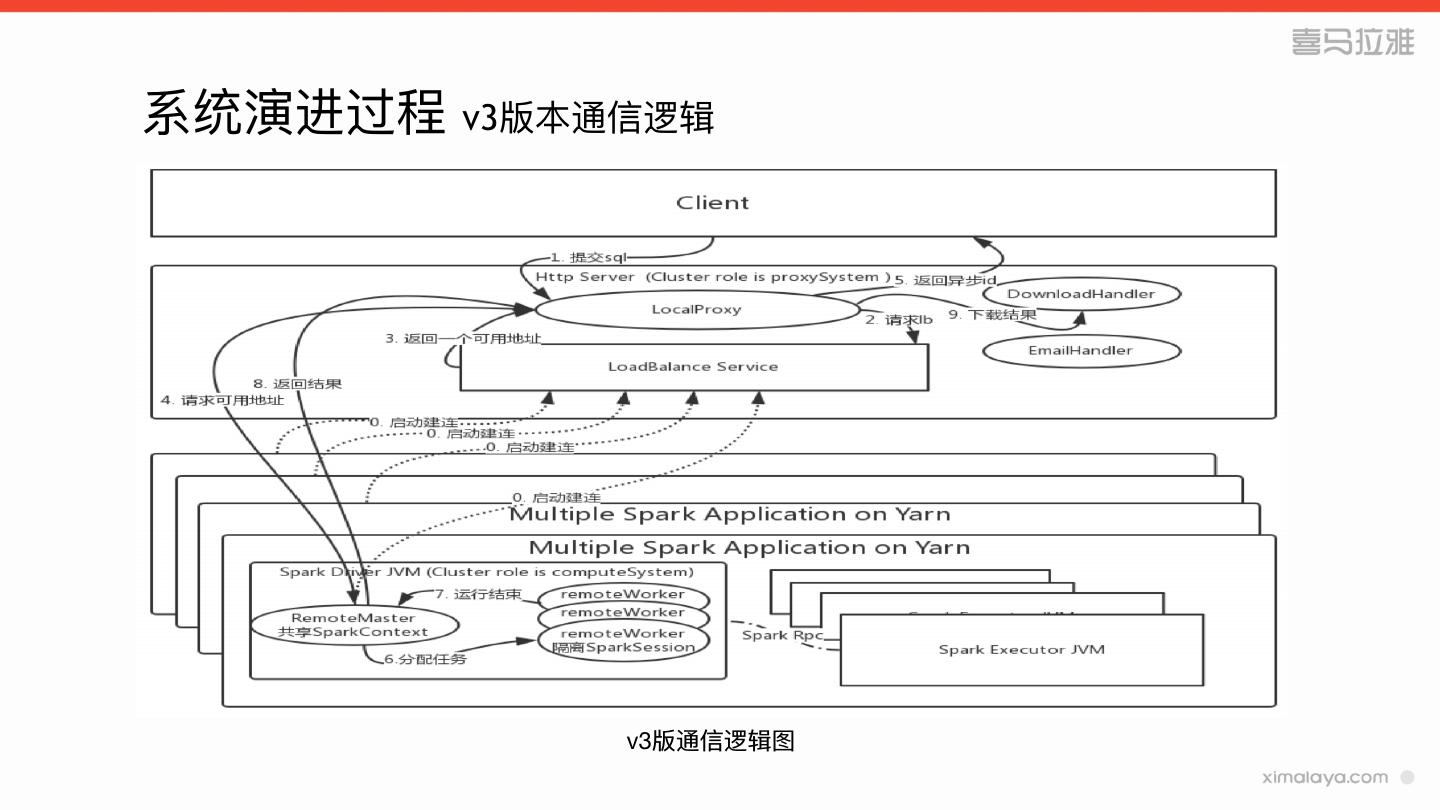
19 .系统演进过程 v2版本存在的问题
» 没有负载均衡
» 缺少权限和审计
» tableau的最后⼀一公⾥里里
» 开发⼈人员的拓拓展需求
�
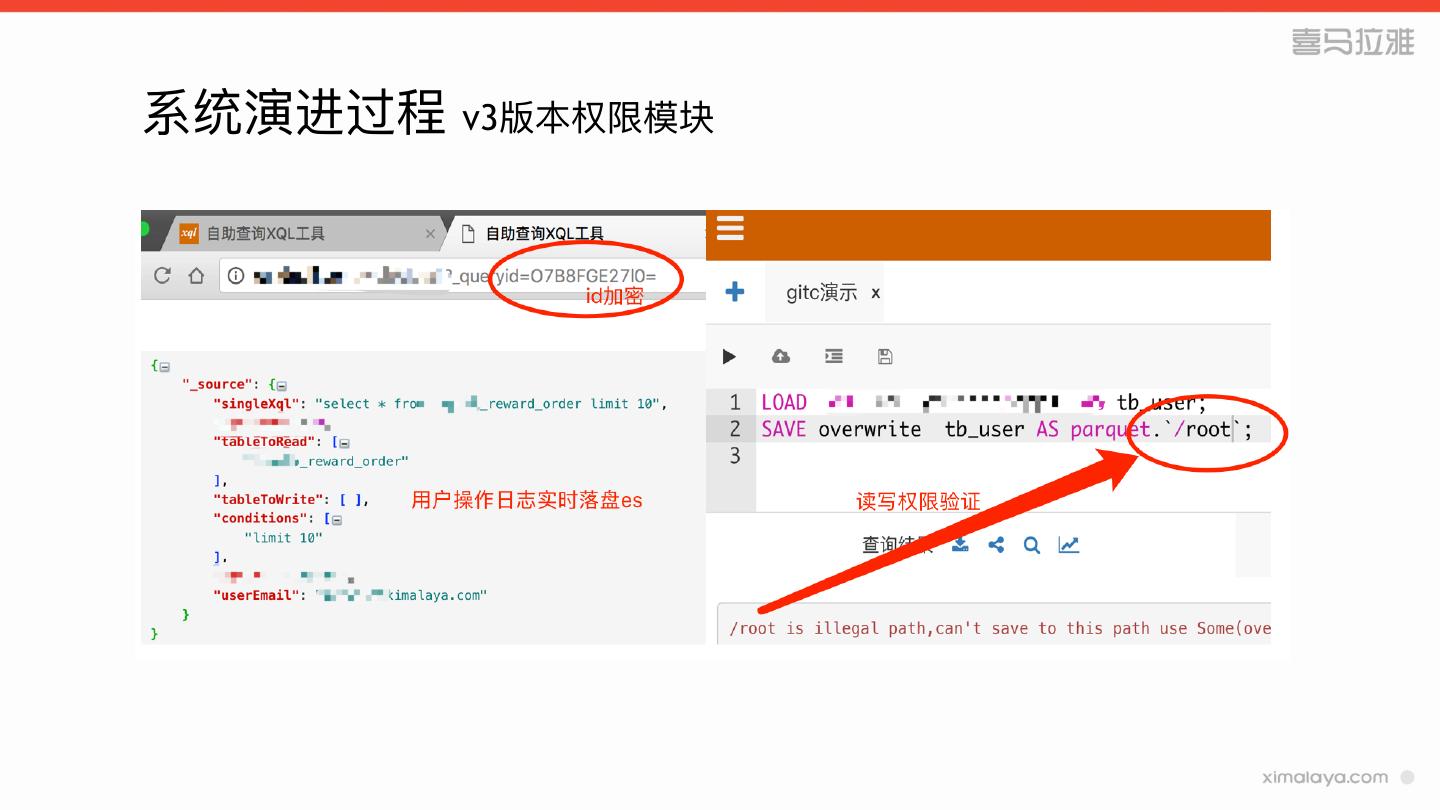
22 .系统演进过程 v3版本权限模块
» id加密混淆
» 数据源读写权限验证
» ⽤用户操作⽇日志实时落盘
�
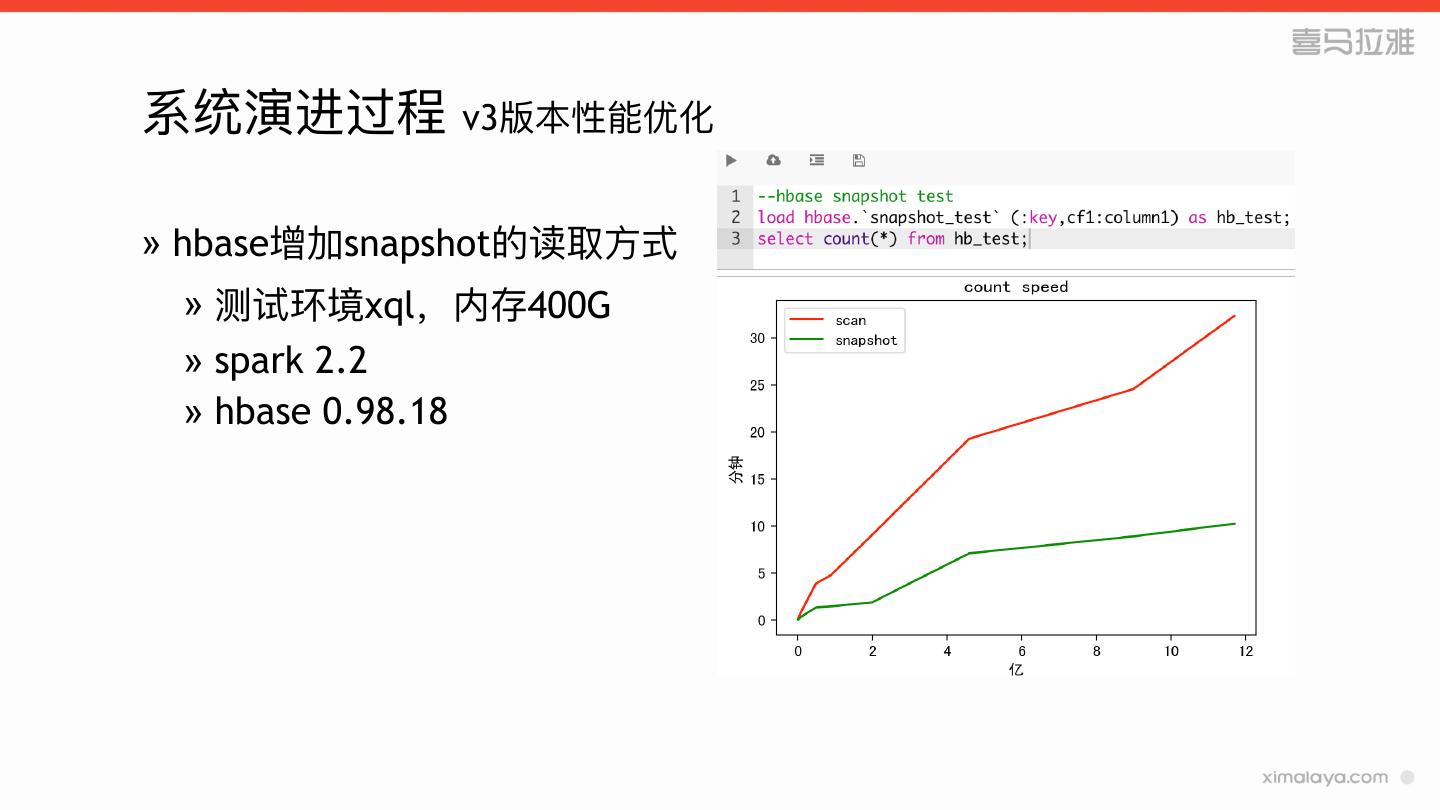
24 .系统演进过程 v3版本性能优化
» hbase增加snapshot的读取⽅方式
» 测试环境xql,内存400G
» spark 2.2
» hbase 0.98.18
�
25 .系统演进过程 v3版本性能优化
» ⼩小⽂文件写⼊入优化
» ⽀支持按字段merge
» ⽀支持数据重排
�
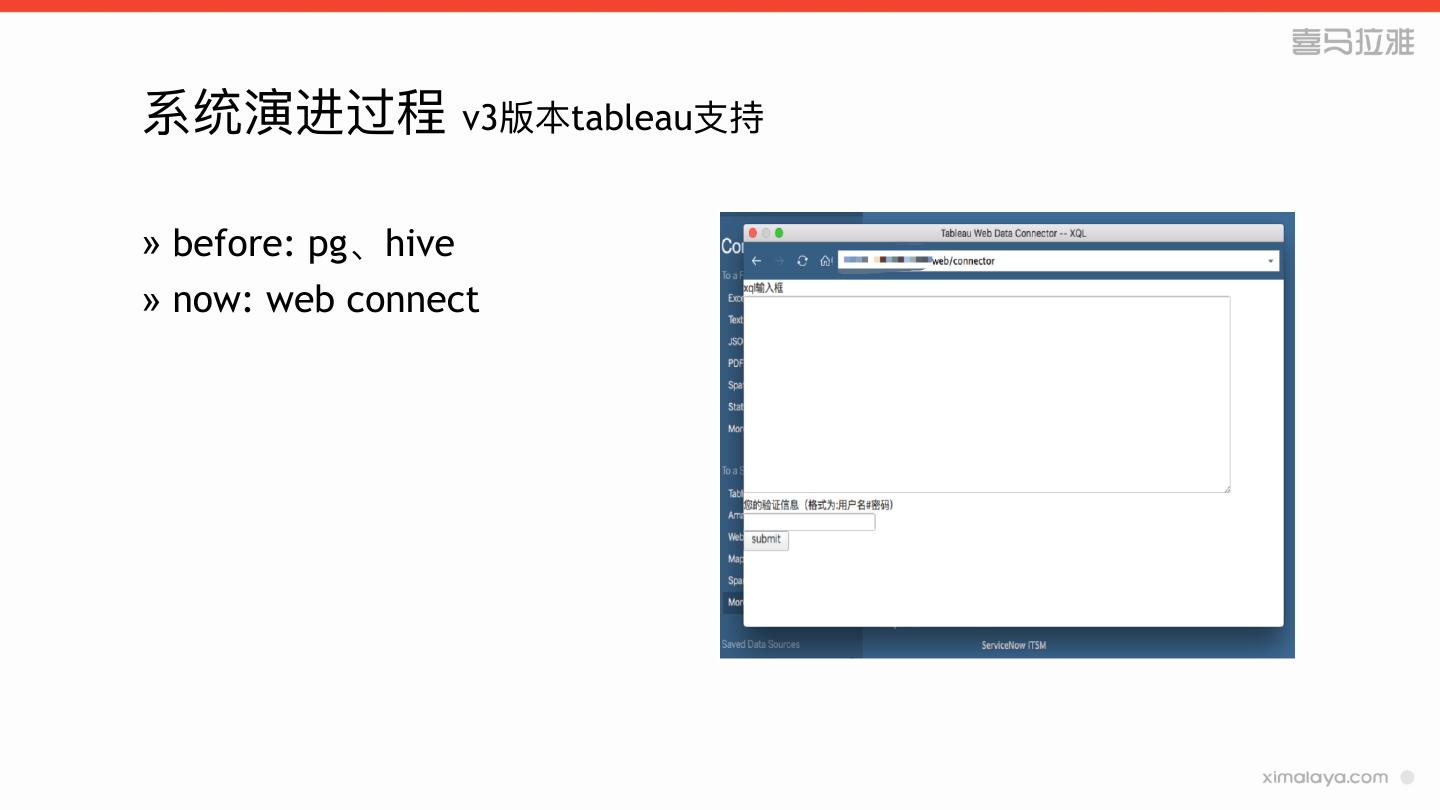
26 .系统演进过程 v3版本tableau⽀支持
» before: pg、hive
» now: web connect
�
27 .系统演进过程 v3版本其他功能
» 离线版本⽀支持⽤用户udf反射注册
» 提供公共classpath和私有classpath并存的部署模式,减少冲突
» ⽀支持kafka、es作为数据源
» ⽀支持xml格式的hdfs⽂文件
» ⽀支持灰度发布
�
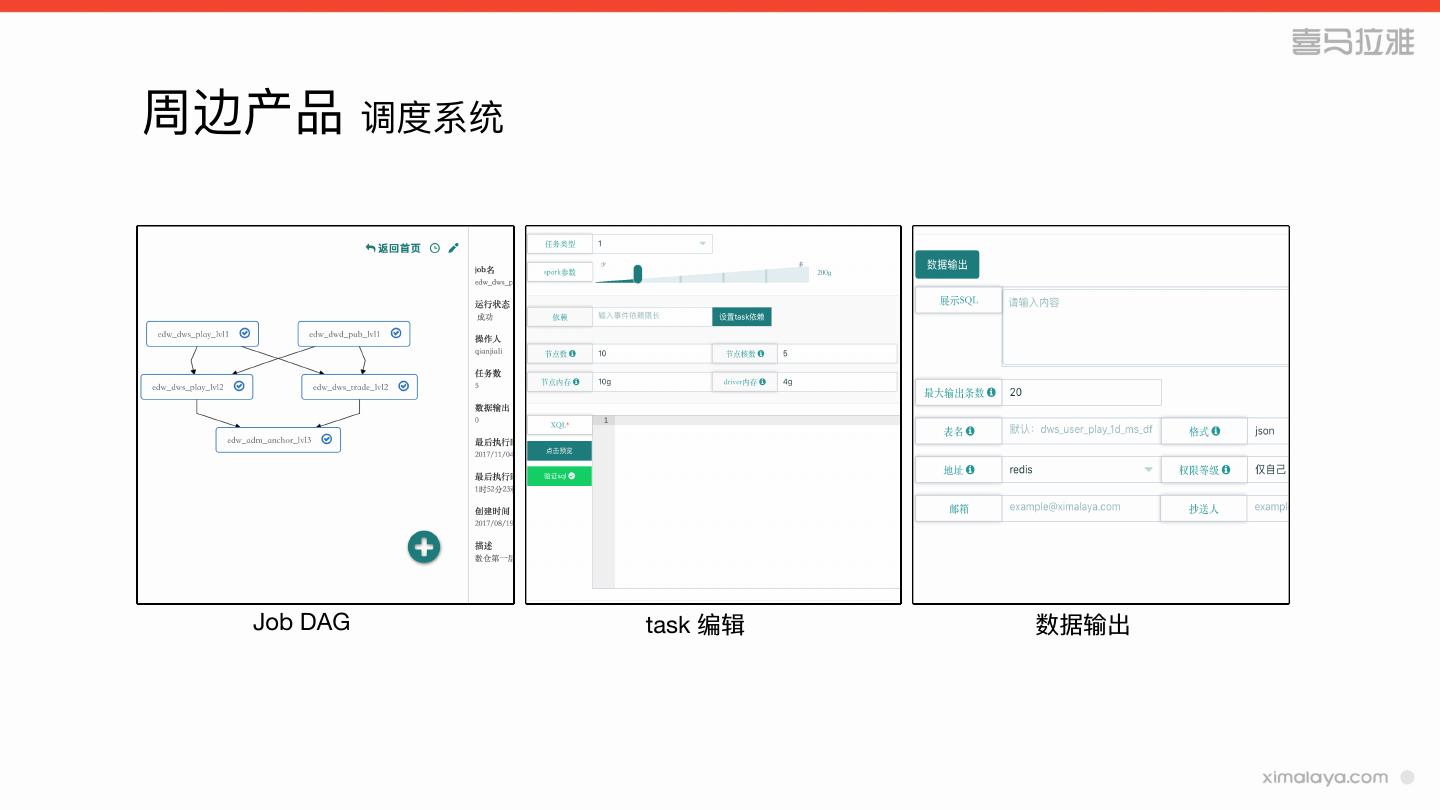
28 .周边产品 调度系统
Job DAG task
�