






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2021年中国数据处理器行业概览
后摩尔定律时代,CPU 计 算能力增速滞后网络传输速率,激发DPU市场需求。
在自2015年起,CPU频率趋于稳定。数据中心提升算力 的边际成本显著提高。然而, 应用的激增使得当代数据 中心中的网络流量以每年25%的速度急剧增长。为了适 应这种巨大的流量增长,数据中心网络向高带宽和新型 传输体系发展,其网络传输速率迈向100Gbps,且快速 向200Gbps与400Gbps发展。数据中心算力提升遭遇瓶 颈,难以匹配快速增长的网络传输速率,激发了DPU需 求。此外,CPU适合于处理串行的复杂指令操作,对大 量并行的固定模式的计算并不适用,例如网络传输的协 议栈(TCP/IP)。DPU的出现一方面更好地执行网络传 输的协议栈,提升传输效率,另一方面也可以降低CPU 负荷,让CPU更有效地处理业务数据。
摘要
01 DPU市场处于早期阶段,技术路线与产品形态不清晰,中小企业试错成本高
• DPU产品最初主要游有一定市场和技术储备的成熟网络设备生产商以及芯片巨头 提供,包括Mellanox,Netronome,Broadcom,Cavium。随着数据流量的暴涨以 及CPU算力瓶颈的凸显,中小企业亦开始布局DPU市场,例如BittWare与Ethernity 等。DPU市场处于早期阶段,技术路线与产品形态均不明确, 中小企业试错成本高,难以迅速发展。云计算厂商巨头包括亚马逊以及华为云通过收购优质的DPU 企业或自研DPU用于自身部署。
02 DPU成本高,云计算厂商与大型互联网企业是DPU市场的高意向客户
• DPU价格是传统网卡的5倍左右,成本较高,导致目标客户群体较窄。DPU产品的 高意向客户群体具备两大特征:(1)服务器数量多(30万以上),通过DPU释放 CPU的算力可带来巨大的经济收益;(2)对数据传输速率要求严苛。同时满足以 上两个条件的企业主要包括大型的互联网企业以及云计算厂商。DPU并非是中小 企业的刚需产品。中小企业对数据与网络的要求相对较低,会优先考虑传统的网 卡或者软件加速方案。
03 在DPU市场,国际芯片巨头领先中国本土企业1-2代
• 国际DPU市场上, 英伟达、英特尔以及博通均推出了多款产品,数据的传输速率 以及存储的读写速率分别达到40Gbps以及32Gbps。中国本土DPU企业起步较晚, 数据的传输速率以及存储的读写速率分别为10Gbps与8Gbps,与国际头部厂商有 着1-2代的技术差距。同时,本土企业DPU商用化不足,在性能上以及可靠性上都 无法满足当代云计算厂商的需求。
展开查看详情
1 . www.leadleo.com 2021年中国数据处理器行业概览 2021 China Data Processing Unit Industry Research Report 2021年中国の DPU 業界の概要 概览标签 :CPU、DPU、芯片异构、数据中心 报告主要作者:张顺 报告提供的任何内容(包括但不限于数据、文字、图表、图像等)均系 2021/06 头豹研究院独有的高度机密性文件(在报告中另行标明出处者除外)。 未经头豹研究院事先书面许可,任何人不得以任何方式擅自复制、再造 、传播、出版、引用、改编、汇编本报告内容,若有违反上述约定的行 为发生,头豹研究院保留采取法律措施,追究相关人员责任的权利。头 豹研究院开展的所有商业活动均使用“头豹研究院”或“头豹”的商号、商标 ,头豹研究院无任何前述名称之外的其他分支机构,也未授权或聘用其 1 他任何第三方代表头豹研究院开展商业活动。
2 .摘要 后 摩 尔 定 律 时 代 , CPU 计 算能力增速滞后网络传输 01 速率,激发DPU市场需求 DPU市场处于早期阶段,技术路线与产品形态不清晰,中小企业 失试错成本高 • DPU产品最初主要游有一定市场和技术储备的成熟网络设备生产商以及芯片巨头 —— 提供,包括Mellanox,Netronome,Broadcom,Cavium。随着数据流量的暴涨以 在自2015年起,CPU频率趋于稳定。数据中心提升算力 及CPU算力瓶颈的凸显,中小企业亦开始布局DPU市场,例如BittWare与Ethernity 等。DPU市场处于早期阶段,技术路线与产品形态均不明确,中小企业试错成本 的边际成本显著提高。然而,应用的激增使得当代数据 高,难以迅速发展。云计算厂商巨头包括亚马逊以及华为云通过收购优质的DPU 企业或自研DPU用于自身部署。 中心中的网络流量以每年25%的速度急剧增长。为了适 02 DPU成本高,云计算厂商与大型互联网企业是DPU市场的高意向 客户 • DPU价格是传统网卡的5倍左右,成本较高,导致目标客户群体较窄。DPU产品的 应这种巨大的流量增长,数据中心网络向高带宽和新型 传输体系发展,其网络传输速率迈向100Gbps,且快速 高意向客户群体具备两大特征:(1)服务器数量多(30万以上),通过DPU释放 向200Gbps与400Gbps发展。数据中心算力提升遭遇瓶 CPU的算力可带来巨大的经济收益;(2)对数据传输速率要求严苛。同时满足以 上两个条件的企业主要包括大型的互联网企业以及云计算厂商。DPU并非是中小 颈,难以匹配快速增长的网络传输速率,激发了DPU需 企业的刚需产品。中小企业对数据与网络的要求相对较低,会优先考虑传统的网 求。此外,CPU适合于处理串行的复杂指令操作,对大 卡或者软件加速方案。 量并行的固定模式的计算并不适用,例如网络传输的协 03 在DPU市场,国际芯片巨头领先中国本土企业1-2代 议栈(TCP/IP)。DPU的出现一方面更好地执行网络传 • 国际DPU市场上,英伟达、英特尔以及博通均推出了多款产品,数据的传输速率 以及存储的读写速率分别达到40Gbps以及32Gbps。中国本土DPU企业起步较晚, 输的协议栈,提升传输效率,另一方面也可以降低CPU 数据的传输速率以及存储的读写速率分别为10Gbps与8Gbps,与国际头部厂商有 负荷,让CPU更有效地处理业务数据。 着1-2代的技术差距。同时,本土企业DPU商用化不足,在性能上以及可靠性上都 无法满足当代云计算厂商的需求。 2 www.leadleo.com 400-072-5588 ©2021 LeadLeo
3 . 名词解释 目录 行业综述 ---------------------------------------- ---------------------------------------- 07 08 CONTENTS • 定义 ---------------------------------------- 09 • 分类 ---------------------------------------- 10 • 技术路线 ---------------------------------------- 11 • 产业链分析 ---------------------------------------- 12 商业模式分析 ---------------------------------------- 18 • 中国初期企业商业模式 ---------------------------------------- 19 • 国际巨头商业模式 ---------------------------------------- 20 市场规模分析 ---------------------------------------- 21 • 中国DPU市场规模 ---------------------------------------- 22 • 全球DPU市场规模 ---------------------------------------- 23 驱动因素分析 ---------------------------------------- 24 • 数通市场驱动 ---------------------------------------- 25 • 电信市场驱动 ---------------------------------------- 27 • 自动驾驶驱动 ---------------------------------------- 28 • 政策驱动 ---------------------------------------- 29 竞争格局分析 ---------------------------------------- 30 • 国际市场 ---------------------------------------- 31 • 中国市场 ---------------------------------------- 33 方法论 ---------------------------------------- 34 法律声明 ---------------------------------------- 35 3 www.leadleo.com 400-072-5588 ©2021 LeadLeo
4 . Terms 目录 Overview of 5G DPU Industry ---------------------------------------- ---------------------------------------- 07 08 CONTENTS • Definition ---------------------------------------- 09 • Classification ---------------------------------------- 10 • Technical Route ---------------------------------------- 11 • Industry Chain Analysis ---------------------------------------- 12 Business Model Analysis ---------------------------------------- 18 • China Early Corporates Business Model ---------------------------------------- 19 • International Giant Business Model ---------------------------------------- 20 Market Size Analysis ---------------------------------------- 21 • China DPU Market Size ---------------------------------------- 22 • Global DPU Market Size ---------------------------------------- 23 Market Drivers Analysis ---------------------------------------- 24 • Data Communication Market ---------------------------------------- 25 • Telecom Market ---------------------------------------- 27 • AutoDrive ---------------------------------------- 28 • Policy ---------------------------------------- 29 Competitive Landscape Analysis ---------------------------------------- 30 • International Market ---------------------------------------- 31 • China Market ---------------------------------------- 33 Methodology ---------------------------------------- 34 Legal Statement ---------------------------------------- 35 4
5 .名词解释 DPU:Data Processing Unit,数据处理器,其核心是通过协处理器协助主控CPU处理网络负载,编程网络接口功能 摩尔时代:摩尔定律是由英特尔(Intel)创始人之一戈登·摩尔(Gordon Moore)提出来的。其内容为:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月 便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻一倍以上。这一定律揭示了信息技术进步的速度。 FPGA:FPGA(Field-Programmable Gate Array),即现场可编程门阵列,它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路 (ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。 ASIC:ASIC芯片是用于供专门应用的集成电路(ASIC,Application Specific Integrated Circuit)芯片技术,在集成电路界被认为是一种为专门目的而设计的集成电路。 EDA:电子设计自动化(英语:Electronic design automation,缩写:EDA)是指利用计算机辅助设计(CAD)软件,来完成超大规模集成电路(VLSI)芯片的功能设计、 综合、验证、物理设计(包括布局、布线、版图、设计规则检查等)等流程的设计方式。 VxLAN:是一种网络虚拟化技术,可以改进大型云计算在部署时的扩展问题,是对VLAN的一种扩展。VXLAN是一种功能强大的工具,可以穿透三层网络对二层进行扩展。 它可通过封装流量并将其扩展到第三层网关,以此来解决VMS(虚拟内存系统)的可移植性限制,使其可以访问在外部IP子网上的服务器。 OVS: Openvswitch是一个虚拟交换软件,主要用于虚拟机VM环境,作为一个虚拟交换机,支持Xen/XenServer,KVM以及virtualBox多种虚拟化技术。在这种虚拟化的 环境中,一个虚拟交换机主要有两个作用:传递虚拟机之间的流量,以及实现虚拟机和外界网络的通信。 Infiniband:直译为“无限带宽”技术,缩写为IB,是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互 连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。 NFVI:网络功能虚拟化基础设施解决方案,是用来托管和连接虚拟功能的一组资源。具体来说就是,NFVI是一种包含服务器、虚拟化管理程序(hypervisor)、操作系 统、虚机、虚拟交换机和网络资源的云数据中心。 VNF:虚拟网络功能,其被看作是NFV的关键。VNF在基础设施层提供的服务是NFV的主要运营目标,这意味着前者左右着网络虚拟化的前景。 UPF:User Plane Function,用户面功能,为 5GC 的基本组成部分。 MEC:边缘计算技术(Mobile Edge Computing)是ICT融合的产物,同时成为支撑运营商进行5G网络转型的关键技术,以满足高清视频、VR/AR、工业互联网、车联网 等业务发展需求。 5 www.leadleo.com 400-072-5588 ©2021 LeadLeo
6 . 01 02 03 04 05 行业综述 6 www.leadleo.com 400-072-5588 ©2021 LeadLeo
7 .中国DPU行业综述——本质:DPU市场萌发及DPU核心作用 DPU市场双向推手: 1、CPU算力相对网络传输速率的差距持续扩大,激发网络侧专用计算需求; 2、DPU结构和产品形态灵活,承载多元功能(虚拟交换、存储、数据、网络加密等),术业可专攻 DPU产线萌生:网络侧专用算力需求+供给侧CPU算力瓶颈难突破 DPU工作本质在于任务转移:网络堆栈算法转移+传输协议运算转移 CPU主频算力相对网络数据传输速率升级的差距 DPU工作原理(网络传输运算)与传统网卡工作原理对比 Host CPU 单位: CPU主频算力[GHz] 数据传输速率[Gbps] Core Core Core PClex 存储 100Gbps Core Core Core 网卡 网络 Core Core 传输 Core CPU计算能力滞后, 安全 2025年算力差距: 激发专用性的网络 Core Core Core 或>60Gbps 数据传输需求—— 催生DPU产线 Host CPU DPU CPU主频算力 Core Core Core 存储 PCle 25Gbps Core Core Core 安全 Core Core Core 网络 Core Core Core 10Gbps 2015 2019 2022 2025 任务转移 数据中心网络向高带宽和新型传输体系发展,其网络传输速率迈向25Gbps,且快 DPU本质作用在于承载网络侧专用性的网络堆栈算法和传输协议运算转移, 速向100Gbps发展。数据中心算力提升遭遇瓶颈,难以匹配快速增长的网络传输 核心效用在于释放CPU算力资源、助力其他计算模块高效处理业务数据。 速率,激发DPU需求。此外,CPU相对更适合处理串行的复杂指令操作,对大量并 相对而言,传统网卡仅负责数据链路的传输,故而CPU承担存储、数据、 行的固定模式计算并不适用,例如网络传输的协议栈(TCP/IP)等。 网络加密等繁杂事务,占用大量业务计算资源。 来源:头豹研究院 7 www.leadleo.com 400-072-5588 ©2021 LeadLeo
8 .中国DPU行业综述——分类:DPU核心处理器+DPU主流产品形态 理论角度:DPU可基于FPGA、MP(Multi-core,MP)与ASIC三类核心处理器进行设计; 产品实现角度:已商用的DPU产品形态包括“ASIC+GP”(NVIDIA等采用)、“ASIC+NP”(华为等采用) 基于不同核心处理器的DPU类别及其特点 总体优势 总体劣势 供应商自用/市场商用情况 低能耗:逻辑单元丰富,支持对数据快速的 高复杂性:FPGA对应的硬件编程语言复杂度 中国初创供应商处于实验阶 基于FPGA 并行处理,能耗开销相对ASIC处理器、MP处 较高,需要高效编程框架(如ClickNP)支持; 段,境外头部供应商已自研、 设计的DPU 理器减少约50%。 高成本:FPGA价格昂贵,数据中心大量部署 自 用 基 于 FPGA 的 DPU ( 如 将显著拉高成本。 Intel、微软等)。 高性价比:在预定义范围内对数据平面进行 低可编程性:基于ASIC的DPU性能最强但可 基于ASIC 业界部分头部厂商推出基于 可编程处理,并提供有限范围内的硬件加速 编程性最差,在成熟的应用场景可发挥算力 设计的DPU “ ASIC+GP” 的 DPU , 例 如 支持,如批量使用等。 优势,但缺乏可编程的灵活性将限制其在新 Mellanox ( 被 NVIDIA 收 购 ) 应用场景的渗透。 的 BlueField 系 列 , 解 决 ASIC 可编程性不足以及GP性能不 基于 SoC-GP: FPGA 排序原因: SoC-GP 足的问题,寻求灵活性与性 基于MP SoC-GP 通用处理器 性能 > NP并行数据处理速 > 能之间的平衡点。 设计的 SoC-NP 可编程性 SoC-NP 基于 SoC-GP: 表现 度领先GP,但两者 DPU > SoC-NP 网络处理器 的性能均不及基于 > SoC-GP FPGA的性能。 FPGA 差异化技术路径满足用户差异化需求:基于FPGA、MP、ASIC的DPU在性能、成本、可编程性等方面的表现存在较大差异,供应商可通过不同处理器组合的技术路径, 实现单点突破的产品模式,或寻求不同需求点之间的平衡。 来源:头豹研究院 8 www.leadleo.com 400-072-5588 ©2021 LeadLeo
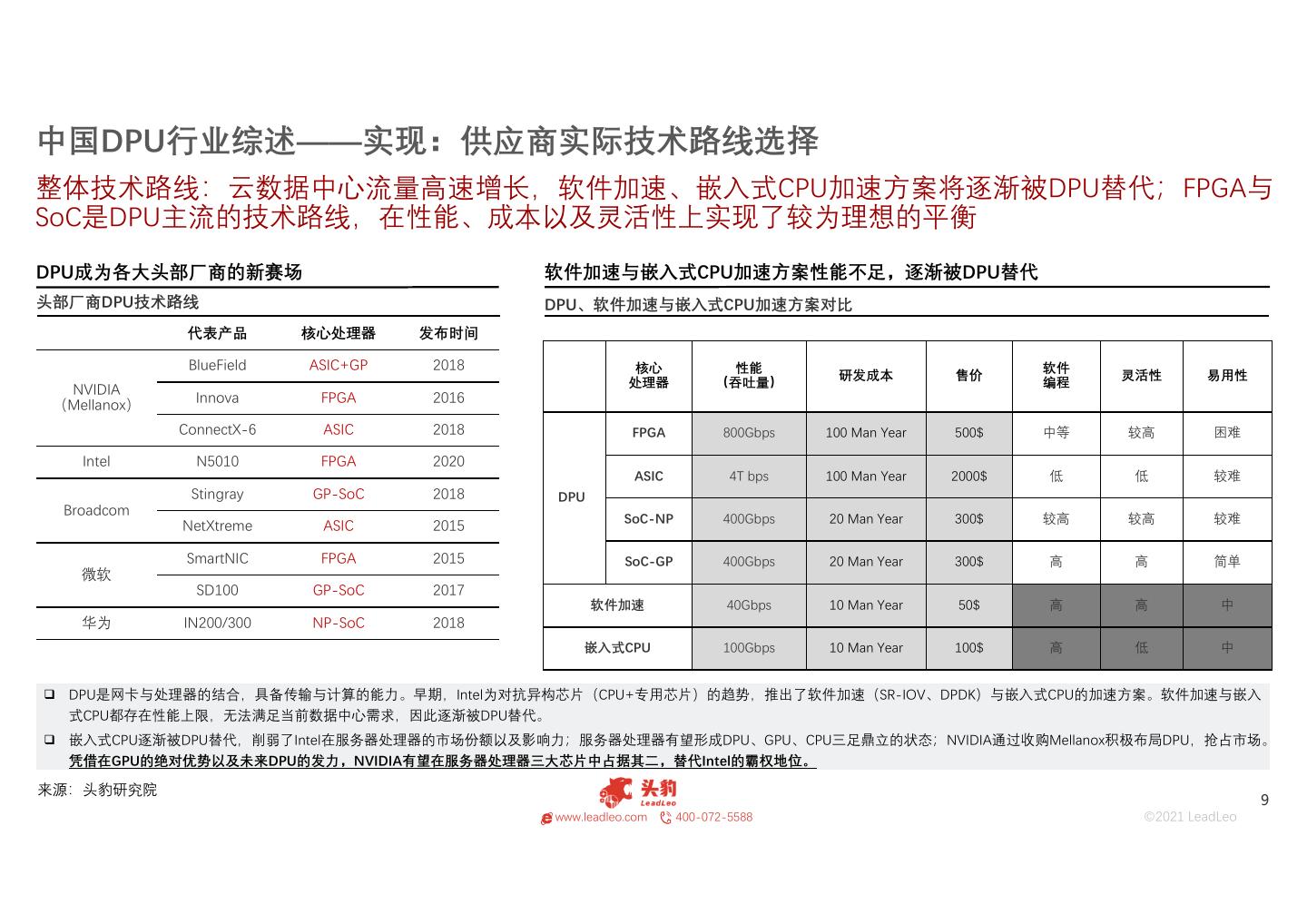
9 .中国DPU行业综述——实现:供应商实际技术路线选择 整体技术路线:云数据中心流量高速增长,软件加速、嵌入式CPU加速方案将逐渐被DPU替代;FPGA与 SoC是DPU主流的技术路线,在性能、成本以及灵活性上实现了较为理想的平衡 DPU成为各大头部厂商的新赛场 软件加速与嵌入式CPU加速方案性能不足,逐渐被DPU替代 头部厂商DPU技术路线 DPU、软件加速与嵌入式CPU加速方案对比 代表产品 核心处理器 发布时间 BlueField ASIC+GP 2018 核心 性能 软件 研发成本 售价 灵活性 易用性 NVIDIA 处理器 (吞吐量) 编程 Innova FPGA 2016 (Mellanox) ConnectX-6 ASIC 2018 FPGA 800Gbps 100 Man Year 500$ 中等 较高 困难 Intel N5010 FPGA 2020 ASIC 4T bps 100 Man Year 2000$ 低 低 较难 Stingray GP-SoC 2018 DPU Broadcom SoC-NP 400Gbps 20 Man Year 300$ 较高 较高 较难 NetXtreme ASIC 2015 SmartNIC FPGA 2015 SoC-GP 400Gbps 20 Man Year 300$ 高 高 简单 微软 SD100 GP-SoC 2017 软件加速 40Gbps 10 Man Year 50$ 高 高 中 华为 IN200/300 NP-SoC 2018 嵌入式CPU 100Gbps 10 Man Year 100$ 高 低 中 DPU是网卡与处理器的结合,具备传输与计算的能力。早期,Intel为对抗异构芯片(CPU+专用芯片)的趋势,推出了软件加速(SR-IOV、DPDK)与嵌入式CPU的加速方案。软件加速与嵌入 式CPU都存在性能上限,无法满足当前数据中心需求,因此逐渐被DPU替代。 嵌入式CPU逐渐被DPU替代,削弱了Intel在服务器处理器的市场份额以及影响力;服务器处理器有望形成DPU、GPU、CPU三足鼎立的状态;NVIDIA通过收购Mellanox积极布局DPU,抢占市场。 凭借在GPU的绝对优势以及未来DPU的发力,NVIDIA有望在服务器处理器三大芯片中占据其二,替代Intel的霸权地位。 来源:头豹研究院 9 www.leadleo.com 400-072-5588 ©2021 LeadLeo
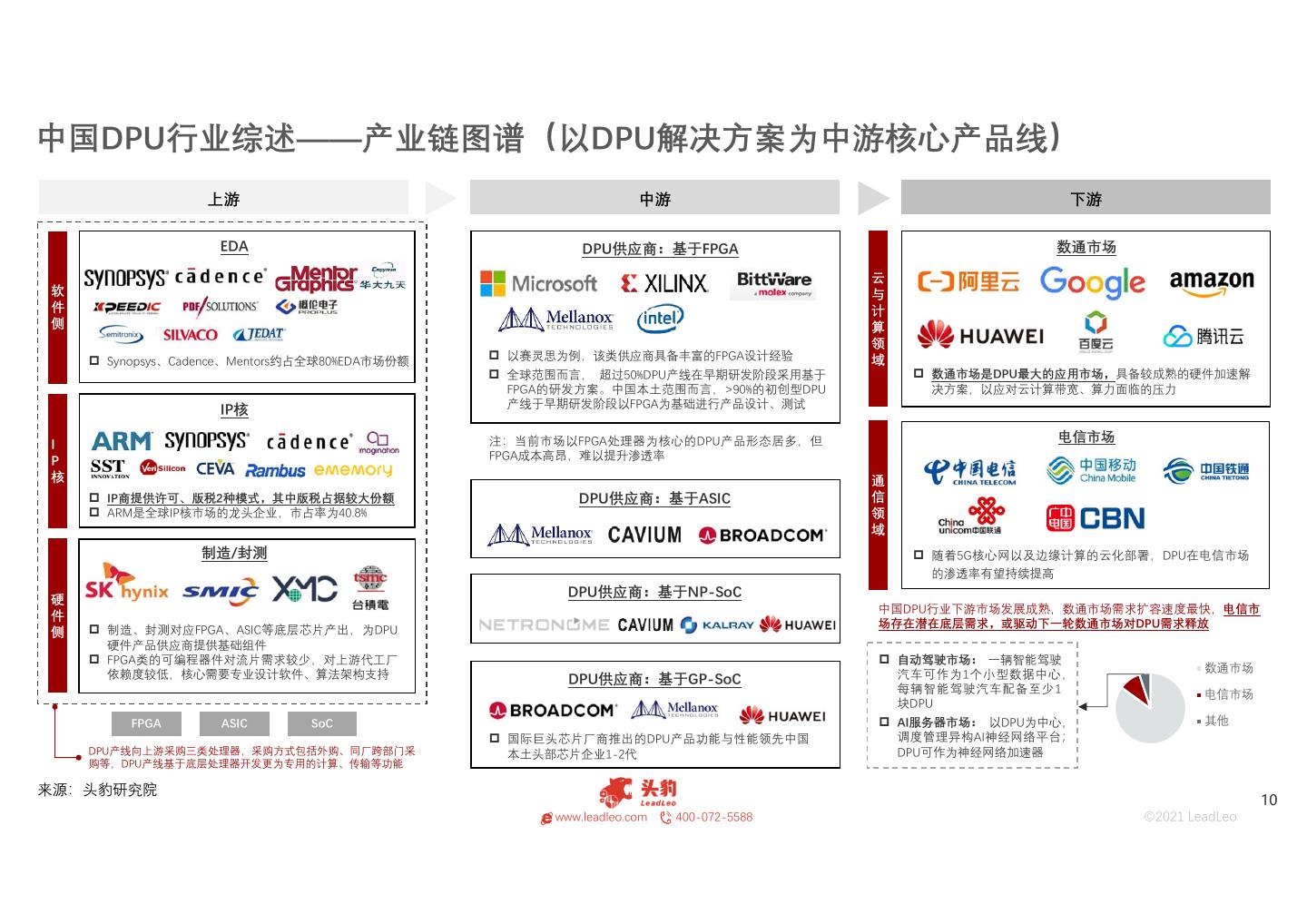
10 .中国DPU行业综述——产业链图谱(以DPU解决方案为中游核心产品线) 上游 中游 下游 EDA DPU供应商:基于FPGA 数通市场 云 软 与 件 计 侧 算 领 Synopsys、Cadence、Mentors约占全球80%EDA市场份额 以赛灵思为例,该类供应商具备丰富的FPGA设计经验 域 全球范围而言, 超过50%DPU产线在早期研发阶段采用基于 数通市场是DPU最大的应用市场,具备较成熟的硬件加速解 FPGA的研发方案。中国本土范围而言,>90%的初创型DPU 决方案,以应对云计算带宽、算力面临的压力 IP核 产线于早期研发阶段以FPGA为基础进行产品设计、测试 注:当前市场以FPGA处理器为核心的DPU产品形态居多,但 电信市场 I P FPGA成本高昂,难以提升渗透率 核 通 IP商提供许可、版税2种模式,其中版税占据较大份额 DPU供应商:基于ASIC 信 ARM是全球IP核市场的龙头企业,市占率为40.8% 领 域 制造/封测 随着5G核心网以及边缘计算的云化部署,DPU在电信市场 的渗透率有望持续提高 硬 DPU供应商:基于NP-SoC 中国DPU行业下游市场发展成熟,数通市场需求扩容速度最快,电信市 件 场存在潜在底层需求,或驱动下一轮数通市场对DPU需求释放 侧 制造、封测对应FPGA、ASIC等底层芯片产出,为DPU 硬件产品供应商提供基础组件 FPGA类的可编程器件对流片需求较少,对上游代工厂 自动驾驶市场: 一辆智能驾驶 数通市场 依赖度较低,核心需要专业设计软件、算法架构支持 DPU供应商:基于GP-SoC 汽车可作为1个小型数据中心, 每辆智能驾驶汽车配备至少1 电信市场 块DPU FPGA ASIC SoC AI服务器市场: 以DPU为中心, 其他 国际巨头芯片厂商推出的DPU产品功能与性能领先中国 调度管理异构AI神经网络平台; DPU产线向上游采购三类处理器,采购方式包括外购、同厂跨部门采 本土头部芯片企业1-2代 DPU可作为神经网络加速器 购等,DPU产线基于底层处理器开发更为专用的计算、传输等功能 来源:头豹研究院 10 www.leadleo.com 400-072-5588 ©2021 LeadLeo
11 .中国DPU行业综述——产业链上游(1/2) ①上游EDA软件服务: DPU产线上游EDA市场已在全球范围形成较为成熟、全面、分工明晰的产品线, EDA三巨头已通过兼并购形成壁垒。中国本土EDA厂商可通过行业资源整合、定制化产品路线突围 全球范围:EDA市场高度集中,产品线分化明晰,国产替代是趋势 突破垄断:整合行业资源是突破美国封锁的关键 EDA全产线覆盖难度极高,美国EDA供应商垄断全球EDA软件市场 Synopsys部分收购事件,2009年-2019年 频繁并购是三巨头掌控市场的通用手段。Synopsys通过滚动并购的操作实现扩大业务规模、 头部垄断企业共同特征:产品线完整,在细分领域拥有绝对优势 技术整合、抢占市场份额的目的。Synopsys在2008年超越Cadence成为全球最大的EDA工具 全 厂商。Cadence与Mentor同样通过频繁收购各细分市场的优秀公司提升自身实力。 球 E 逻辑综合工具 D Synopsys 时间 事件 备注 位例全球第一(2020) 平均营收 A 时序分析工具 2009 收购MIPS公司的模块业务Chipidea 模拟IP 市 >10亿美元 场 2010 收购Optical Research Associate 致力于强半导体制造方面光学技术 模拟/混合信号 : 定制化电路 Cadence 2012 收购Eve 致力于硬件加速仿真器解决方案 头 市占率最高(2020) 部 版图设计 2012 收购Luminescent Technologies 致力于生产掩模处理业务 企 业 Mentors 中国本土EDA企 2012 收购Magma Design Automation 致力于全流程EDA工具 垄 布局布线工具 市占率最高(2020) 业收入与国际 断 巨头差距明显 2012 收购SpringSoft 致力于纠错与全定制技术 绝对优势领域 2017 收购Black Duck Software 致力于开源软件的安全和管理 2018 收购Kilopass 内存IP供应商 本 平均收入 具有模拟集成电路设计全流程系统工具、SoC 2019 收购DINI Group 致力于FPGA电路板和解决方案领域 土 >2,000万美元 E 集成电路设计与晶圆生产制造所需的部分工具 D 绝对优势可能方向:高度定制化电路设计 中国企业可效仿美国企业,通过横向并购完善产业布局,扩宽产品线及加强技术; A 亦可通过纵向并购整合上下游资源,产生协同效应。 来源:头豹研究院 11 www.leadleo.com 400-072-5588 ©2021 LeadLeo
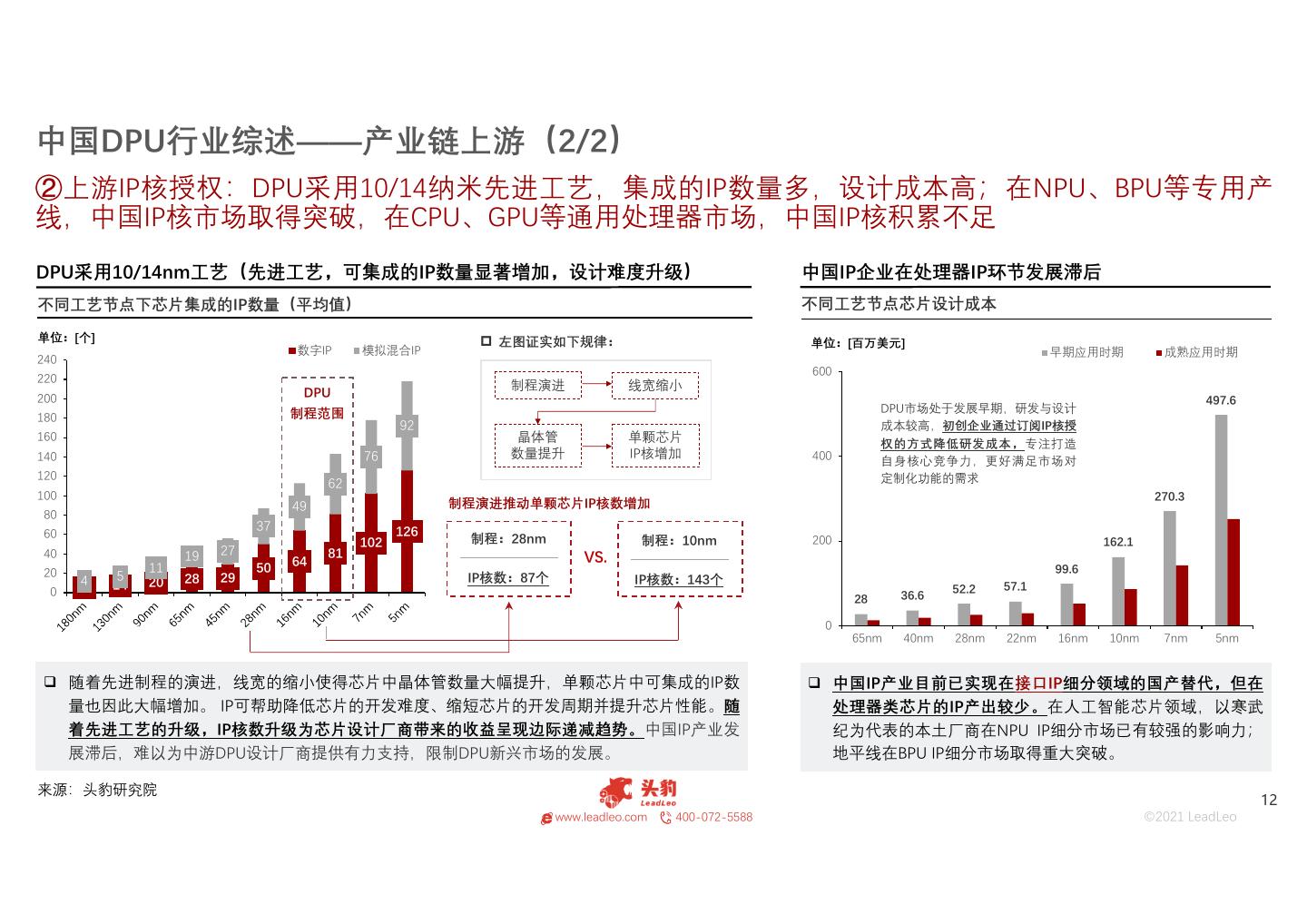
12 .中国DPU行业综述——产业链上游(2/2) ②上游IP核授权:DPU采用10/14纳米先进工艺,集成的IP数量多,设计成本高;在NPU、BPU等专用产 线,中国IP核市场取得突破,在CPU、GPU等通用处理器市场,中国IP核积累不足 DPU采用10/14nm工艺(先进工艺,可集成的IP数量显著增加,设计难度升级) 中国IP企业在处理器IP环节发展滞后 不同工艺节点下芯片集成的IP数量(平均值) 不同工艺节点芯片设计成本 单位:[个] 左图证实如下规律: 单位:[百万美元] 数字IP 模拟混合IP 早期应用时期 成熟应用时期 240 600 220 制程演进 线宽缩小 200 DPU 497.6 制程范围 DPU市场处于发展早期,研发与设计 180 92 成本较高,初创企业通过订阅IP核授 160 晶体管 单颗芯片 权的方式降低研发成本,专注打造 140 76 数量提升 IP核增加 400 自身核心竞争力,更好满足市场对 120 定制化功能的需求 62 100 270.3 49 制程演进推动单颗芯片IP核数增加 80 37 126 60 制程:28nm 102 制程:10nm 200 162.1 40 27 81 19 64 VS. 20 11 50 99.6 4 5 20 28 29 IP核数:87个 IP核数:143个 0 10 14 52.2 57.1 28 36.6 0 65nm 40nm 28nm 22nm 16nm 10nm 7nm 5nm 随着先进制程的演进,线宽的缩小使得芯片中晶体管数量大幅提升,单颗芯片中可集成的IP数 中国IP产业目前已实现在接口IP细分领域的国产替代,但在 量也因此大幅增加。 IP可帮助降低芯片的开发难度、缩短芯片的开发周期并提升芯片性能。随 处理器类芯片的IP产出较少。在人工智能芯片领域,以寒武 着先进工艺的升级,IP核数升级为芯片设计厂商带来的收益呈现边际递减趋势。中国IP产业发 纪为代表的本土厂商在NPU IP细分市场已有较强的影响力; 展滞后,难以为中游DPU设计厂商提供有力支持,限制DPU新兴市场的发展。 地平线在BPU IP细分市场取得重大突破。 来源:头豹研究院 12 www.leadleo.com 400-072-5588 ©2021 LeadLeo
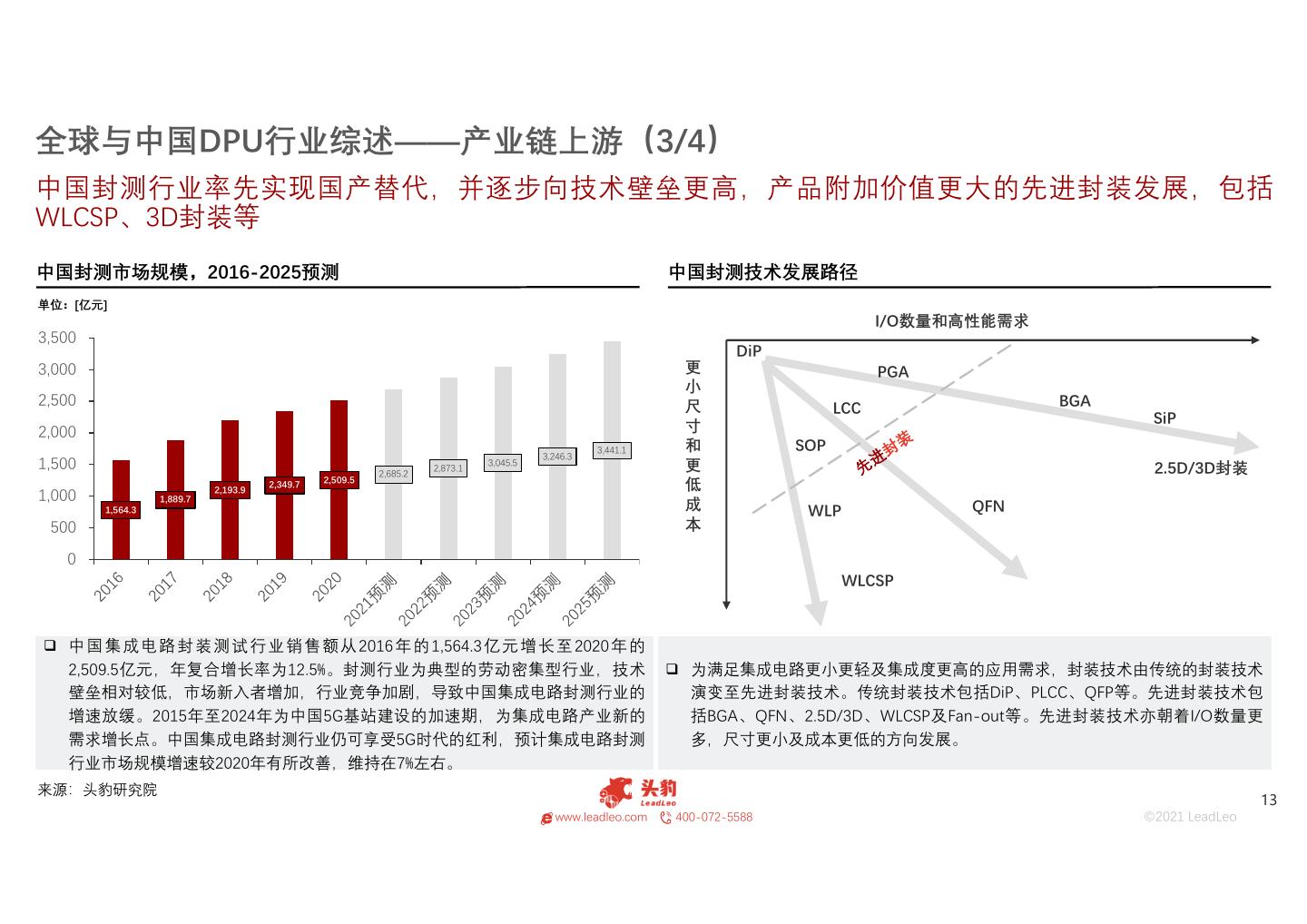
13 .全球与中国DPU行业综述——产业链上游(3/4) 中国封测行业率先实现国产替代,并逐步向技术壁垒更高,产品附加价值更大的先进封装发展,包括 WLCSP、3D封装等 中国封测市场规模,2016-2025预测 中国封测技术发展路径 单位:[亿元] I/O数量和高性能需求 3,500 DiP 3,000 更 PGA 小 2,500 尺 LCC BGA 寸 SiP 2,000 3,441.1 和 SOP 3,246.3 1,500 2,873.1 3,045.5 更 2.5D/3D封装 2,685.2 2,509.5 2,193.9 2,349.7 低 1,000 1,889.7 1,564.3 成 WLP QFN 500 本 0 WLCSP 中 国 集 成 电 路 封 装 测 试 行 业 销 售 额 从 2016 年 的 1,564.3 亿 元 增 长 至 2020 年 的 2,509.5亿元,年复合增长率为12.5%。封测行业为典型的劳动密集型行业,技术 为满足集成电路更小更轻及集成度更高的应用需求,封装技术由传统的封装技术 壁垒相对较低,市场新入者增加,行业竞争加剧,导致中国集成电路封测行业的 演变至先进封装技术。传统封装技术包括DiP、PLCC、QFP等。先进封装技术包 增速放缓。2015年至2024年为中国5G基站建设的加速期,为集成电路产业新的 括BGA、QFN、2.5D/3D、WLCSP及Fan-out等。先进封装技术亦朝着I/O数量更 需求增长点。中国集成电路封测行业仍可享受5G时代的红利,预计集成电路封测 多,尺寸更小及成本更低的方向发展。 行业市场规模增速较2020年有所改善,维持在7%左右。 来源:头豹研究院 13 www.leadleo.com 400-072-5588 ©2021 LeadLeo
14 .全球与中国DPU行业综述——产业链上游(4/4) 中国大陆晶圆制程龙头企业中芯国际已成功突破14nm技术节点,与中国台湾台积电的技术差距进一步缩 小至1-2代 主流晶圆制造厂商逻辑制程节点 分析 IDM 台积电制程节点在2016年反超IDM 随着芯片的制程工艺逼近物理极限,芯片制程升级的技术 40nm 28nm 20nm 14nm 10nm 7nm 难度和资金投入大幅上升。面向消费电子领域的处理器芯 片产品迭代速度快,IDM企业难以同时兼顾芯片设计与制 32/28nm 22nm 14nm 10nm 造先进技术的研发。在此背景下,芯片产业的分工逐渐明 显,以台积电和中芯国际为代表的晶圆代工厂在芯片制造 Foundry 行业的价值凸显。 65nm 55nm 28nm 2016年,台积电成功研发10nm工艺,制程节点反超IDM 模式下的三星与英特尔。随后几年里,台积电遵从摩尔定 微米制程 90nm 55nm 25nm 律,平均2年完成一次技术迭代,是业内第一家推出7nm 与5nm工艺的企业,稳居行业龙头。 40nm 28nm 14nm 2018年,宣布退出10nm 中芯国际与台积电在制程上差距缩小至两代 及以下先进制程研发 中国以华为海思为首的芯片设计行业与以长电科技为首的 2018 年 , 退 出 封测行业在近年均取得重大突破,而晶圆制造行业发展相 40nm 32nm 28nm 14nm 12nm 10nm以下的研发 对缓慢。华为海思(Fabless)已成功推出7nm与5nm制程 40nm 28nm 16nm 10nm 7nm 5nm 的芯片,但中国大陆芯片制造环节薄弱,尚未出现成熟的 7nm与5nm制造工艺,导致华为长期寻求台积电代工。 65nm 44/45nm 28nm 14nm 中国大陆可量产28nm及以下芯片的企业仅有中芯国际与 华虹集团。2019年,中芯国际成功商用14nm工艺,在制 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 程上与台积电的差距缩小至2代。 注:英特尔10nm芯片性能与台积电第一代7nm芯片性能相似 来源:头豹研究院 14 www.leadleo.com 400-072-5588 ©2021 LeadLeo
15 .中国DPU行业综述——产业链下游 ①数通领域是DPU最大的应用市场,可为终端政企用户提供较为成熟的硬件加速解决方案; ②随着NFV 技术的演进,电信市场对DPU的需求将逐步释放 DPU 4类核心功能对应各类应用场景+NFV技术演进激发电信市场对DPU潜在需求 DPU可应用于数据传输、虚拟交换、数据安全、存储等场景 NFV+边缘计算:网络虚拟化(Network Functiong Virtulizaiton)是5G关键技术之 一。NFV技术推动下,运营商对于边缘计算开放生态、降本增效、缩减部署周期的 功能实现 应用场景 数据面 控制面 诉求愈发明晰。边缘计算是赋能行业数字化转型的关键技术,对网络带宽、时延、 可靠性要求严苛,进而激发电信行业对DPU硬件加速技术的需求。 数据 虚拟路由 定义转发 通信 数据分组寻路 分组查表 虚拟交换机 规则 产业 边缘计算建设痛点 DPU解决路径 • 边缘机房供电成本高,散热 • DPU硬件加速技术提升边缘机房 数据 防火墙/ 数据分组解析 规则下放 能力、承重能力有限 单位面积算力 分组检测 安全组 /帧头修改 • DC化改造余地小、成本大, • 突破当前虚拟化转发性能瓶颈、 无法提供足够的X86计算资源 转发时延瓶颈(单服务器(双网卡) 数据加密 加/解密算法 云安全 维护密匙 吞吐量提升至3倍(180 Gps)、时延降 数据解密 实现 低90%(低于10 μs)、功耗降低55%,) 云计算 产业 连接配置 存储 云存储 NVMe实现 云计算厂商对DPU的诉求侧重点: 数 据 中 心 带 宽 平 均 2-3 年 迭 代 一 次 , RAID配置 DPU企业需要具备为客户提供持续服务 A、计算速率: 25Gbps~40Gbps之间 的能力: 数通市场是DPU最大的应用市场 1、支持用户数据中心带宽的升级 B、可靠性:>99.99% 云计算厂商与大型互联网企业是DPU在数通市场最大客户,应 2、支持在原有的硬件架构上灵活部署 用场景集中于防火墙、云安全、云存储等方面 C、灵活性:满足最低灵活性 新的功能 来源:头豹研究院 15 www.leadleo.com 400-072-5588 ©2021 LeadLeo
16 .01 02 03 04 05 商业模式 16 www.leadleo.com 400-072-5588 ©2021 LeadLeo
17 .中国DPU行业商业模式梳理——中国本土初创DPU供应商 回本周期最短:采用商业模式一的初创团队凸显轻资产运营优势,初步预判在5至8年收回前期成本 回本周期最长:模式二远期对上下游议价成本低,以高出货量回本,前期投入或超其他模式数十倍 模式一: 模式二: 模式三: • 自研:中高级软件 • 自研:处理器微架构+中高级软件 • 自研:网络芯片+中高级软件 • 外购:处理器、网络芯片 • 外购:网络芯片 • 外购:处理器 门槛适中,依据软件设计、调 门槛较高,依据工艺流程拆解 门槛适中,从软件落地及网络芯 模式难度 试、落地周期判断,DPU产线 模式难度 环节判断,DPU产线核心研发 模式难度 片自研流程拆解角度而言,DPU 核心研发团队需至少10人 团队需具备至少40人 产线核心研发团队需至少25人 代表企业 芯启源 代表企业 中科驭数(自主KPU)、云豹 代表企业 芯启源(战略转型方向) 早期带领用户参与软件设计, 将附加值较低的网络芯片外包, 利用低成本的基础网络芯片产线, 中期根据用户发展周期,层级 聚焦资源自研高附加值的处理 配合软件服务实现营收,处理器 回本方向 回本方向 回本方向 推进存储、安全、传输能力, 器微架构,推动标准化产品的 搭载方面,选择灵活度高,以灵 提高软件附加值,继而回本 规模化商用,实现回本 活适配的特点为卖点 获客方向 新赛道机房核心服务器 获客方向 大机房批量服务器 获客方向 旧机房+中小型机房边缘服务器 利润空间 定制化服务的高议价空间 利润空间 对产业链上游的议价空间 利润空间 低成本采购方案,盘活既有渠道 • 服务形态持续:推动软件标 • 产业链议价持续:远期配合 • 客群定位持续:持续服务旧 盈利 盈利 盈利 准化+保留软件定制服务 高级软件,提升对下游用户 机房客群,筛选未被其他竞 持续性 持续性 持续性 • 定价策略持续:歧视定价 的议价权 争者覆盖的边缘机房客户 总结:前期资本充足的情况下,初创DPU团队可自主研发处理器微架构,该类企业或将成为推动DPU国产替代的主力;以高级软件自研为核心 的初创企业通过定制化服务方案积累第一批熟客,以平均低于境外同类服务>10%的价格,满足并理解中国云计算市场复杂应用场景的需求。 来源:头豹研究院 17 www.leadleo.com 400-072-5588 ©2021 LeadLeo
18 .中国DPU行业商业模式梳理——全球DPU供应商 市场份额蚕食:软硬件解耦推进业态变化,头部竞争者或成为新型商业模式的跟随者 竞争地位维护:复制新进入竞争者成功的商业策略,扩大免费服务覆盖的范围,持续收并购 模式三: 模式四: 模式五: • 自研:网络芯片+高级软件 • 自研:网络芯片+处理器 • 自研:网络芯片+处理器+高级软件 • 外购:处理器 代表性 NVIDIA(Mellanox)、 代表性 Intel、NVIDIA(Mellanox)、 代表性 Intel、NVIDIA(Mellanox)、 全球供应商 Broadcom 全球供应商 Broadcom 全球供应商 Broadcom 固有产线出新+成本维稳:依靠 市场话语权策略:定义市场基 (1)绑定客户:为客户提供完 自身在传统产线的技术积累, 调,在下游应用场景将DPU打 整的软、硬件解决方案; 盈利空间 盈利空间 盈利空间 在网络芯片升级的同时保持或 造成和CPU、GPU同等地位的三 (2)持续服务:后期升级、维 压低成本 大通用处理器,大规模铺开 护以及咨询服务扩大赢利空间 (1)垄断DPU硬件:不断向先 模式三对头部供应商而言属于 进制程以及更高性能迈进; (1)开放生态:通过开放的软 过渡阶段; (2)持续集成:NVIDIA 件开发平台构建生态,软件社 远期随SoC方案愈发成熟,头部 战略趋向 (Mellanox)未来或将GPU集成 区加速产品研发速度; 战略趋向 战略趋向 供应商采用FPGA方案占比降低, 至DPU,以提升DPU硬件性能, (2)低成本吸引开发者:聚集 其DPU产线将向模式四、模式 Intel秉持“FPGA与SOC”两条腿走 业界优秀开发者,丰富DPU功 五转型,走向一站式服务 路的策略 能,采取差异化竞争路径 总结:收并购扩充产线是DPU头部供应商巩固现有市场地位的惯用手段。初创企业通过相同技术与产品难以颠覆头部企业的市场地位,只有结 合商业模式以及逻辑上的创新才有机会突破头部企业的封锁 来源:头豹研究院 18 www.leadleo.com 400-072-5588 ©2021 LeadLeo
19 .01 02 03 04 05 市场规模 19 www.leadleo.com 400-072-5588 ©2021 LeadLeo
20 .DPU行业市场规模——中国DPU市场规模 周期性:中国DPU市场规模增长周期与数据中心升级周期契合(3年左右),周期过程中,增长略平稳 市场规模:到2025年,中国DPU市场规模预计接近40亿美元 中国DPU市场规模,2020-2025年预测 分析 单位:[万美元] 2020 年 , 中 国 DPU 产 品 主 要 由 NVIDIA 400,000 (Mellanox)、Intel与Broadcom三家企业提 374,092.92 供,其中Mellanox凭借在网卡上积累的优势, 350,000 326,855.10 占据市场龙头位置。 307,299.18 300,000 中国DPU市场规模预计在2025年达到40亿美 元。通常数据中心带宽升级周期在3年左右。 250,000 中国将在2023-2025年进入下一轮服务器设备 200,000 以及DPU更换周期,DPU市场规模有明显的 增幅。 150,000 110,554.84 数通市场是DPU最大的应用市场,其中裸金 100,000 https://www.leadleo.com/pdfcore/show?id=60e27d0020410e62e7960dda 属服务器对DPU存在刚需。DPU在电信市场 52,051.30 50,000 的应用主要为边缘计算场景,渗透率不足5%。 8,814.75 针对智能驾驶领域的DPU仍在探索阶段,预 ‐ 计在2023年DPU才有望布局在智能驾驶领域。 2020年 2021年预测 2022年预测 2023年预测 2024年预测 2025年预测 来源:头豹研究院 20 www.leadleo.com 400-072-5588 ©2021 LeadLeo
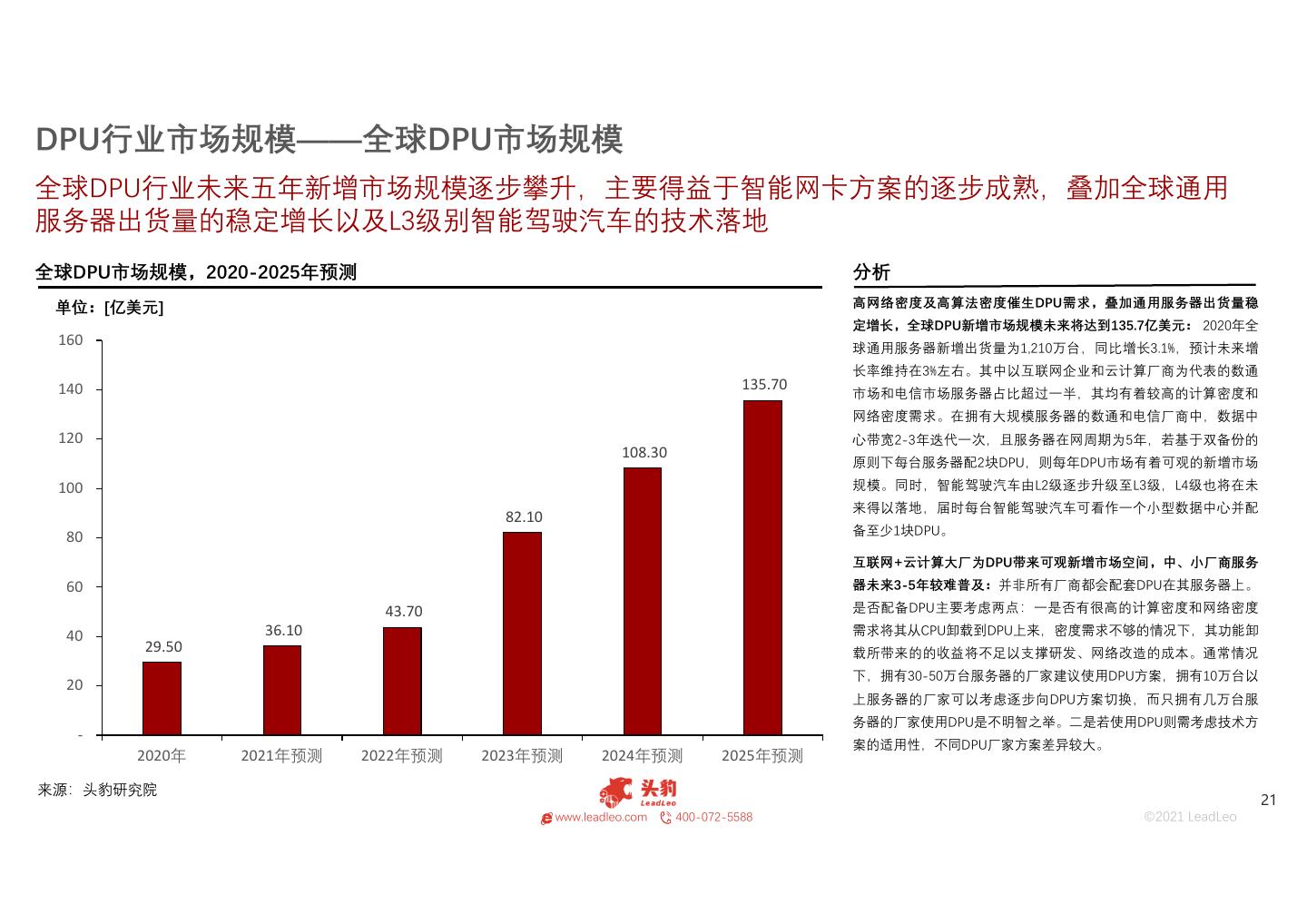
21 .DPU行业市场规模——全球DPU市场规模 全球DPU行业未来五年新增市场规模逐步攀升,主要得益于智能网卡方案的逐步成熟,叠加全球通用 服务器出货量的稳定增长以及L3级别智能驾驶汽车的技术落地 全球DPU市场规模,2020-2025年预测 分析 单位:[亿美元] 高网络密度及高算法密度催生DPU需求,叠加通用服务器出货量稳 定增长,全球DPU新增市场规模未来将达到135.7亿美元: 2020年全 160 球通用服务器新增出货量为1,210万台,同比增长3.1%,预计未来增 长率维持在3%左右。其中以互联网企业和云计算厂商为代表的数通 140 135.70 市场和电信市场服务器占比超过一半,其均有着较高的计算密度和 网络密度需求。在拥有大规模服务器的数通和电信厂商中,数据中 120 心带宽2-3年迭代一次,且服务器在网周期为5年,若基于双备份的 108.30 原则下每台服务器配2块DPU,则每年DPU市场有着可观的新增市场 100 规模。同时,智能驾驶汽车由L2级逐步升级至L3级,L4级也将在未 来得以落地,届时每台智能驾驶汽车可看作一个小型数据中心并配 82.10 备至少1块DPU。 80 互联网+云计算大厂为DPU带来可观新增市场空间,中、小厂商服务 60 器未来3-5年较难普及:并非所有厂商都会配套DPU在其服务器上。 43.70 是否配备DPU主要考虑两点:一是否有很高的计算密度和网络密度 40 36.10 需求将其从CPU卸载到DPU上来,密度需求不够的情况下,其功能卸 29.50 载所带来的的收益将不足以支撑研发、网络改造的成本。通常情况 下,拥有30-50万台服务器的厂家建议使用DPU方案,拥有10万台以 20 上服务器的厂家可以考虑逐步向DPU方案切换,而只拥有几万台服 务器的厂家使用DPU是不明智之举。二是若使用DPU则需考虑技术方 ‐ 案的适用性,不同DPU厂家方案差异较大。 2020年 2021年预测 2022年预测 2023年预测 2024年预测 2025年预测 来源:头豹研究院 21 www.leadleo.com 400-072-5588 ©2021 LeadLeo
22 .01 02 03 04 05 驱动因素 22 www.leadleo.com 400-072-5588 ©2021 LeadLeo
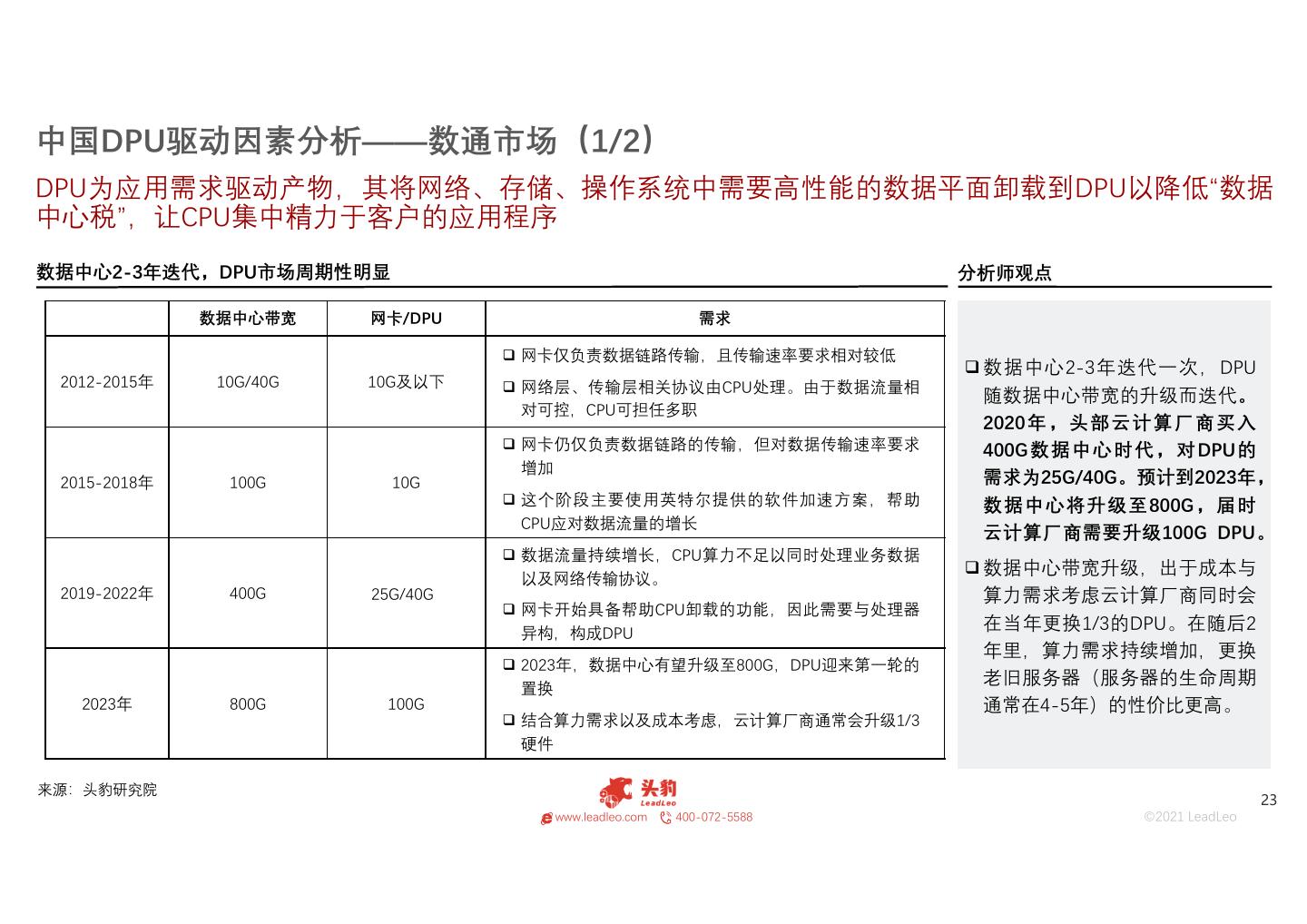
23 .中国DPU驱动因素分析——数通市场(1/2) DPU为应用需求驱动产物,其将网络、存储、操作系统中需要高性能的数据平面卸载到DPU以降低“数据 中心税”,让CPU集中精力于客户的应用程序 数据中心2-3年迭代,DPU市场周期性明显 分析师观点 数据中心带宽 网卡/DPU 需求 网卡仅负责数据链路传输,且传输速率要求相对较低 数据中心2-3年迭代一次,DPU 2012-2015年 10G/40G 10G及以下 网络层、传输层相关协议由CPU处理。由于数据流量相 随数据中心带宽的升级而迭代。 对可控,CPU可担任多职 2020 年,头部云计算厂商买入 网卡仍仅负责数据链路的传输,但对数据传输速率要求 400G数据中心时代,对DPU的 增加 2015-2018年 100G 10G 需求为25G/40G。预计到2023年, 这个阶段主要使用英特尔提供的软件加速方案,帮助 数据中心将升级至800G,届时 CPU应对数据流量的增长 云计算厂商需要升级100G DPU。 数据流量持续增长,CPU算力不足以同时处理业务数据 数据中心带宽升级,出于成本与 以及网络传输协议。 2019-2022年 400G 25G/40G 算力需求考虑云计算厂商同时会 网卡开始具备帮助CPU卸载的功能,因此需要与处理器 在当年更换1/3的DPU。在随后2 异构,构成DPU 年里,算力需求持续增加,更换 2023年,数据中心有望升级至800G,DPU迎来第一轮的 老旧服务器(服务器的生命周期 置换 2023年 800G 100G 通常在4-5年)的性价比更高。 结合算力需求以及成本考虑,云计算厂商通常会升级1/3 硬件 来源:头豹研究院 23 www.leadleo.com 400-072-5588 ©2021 LeadLeo
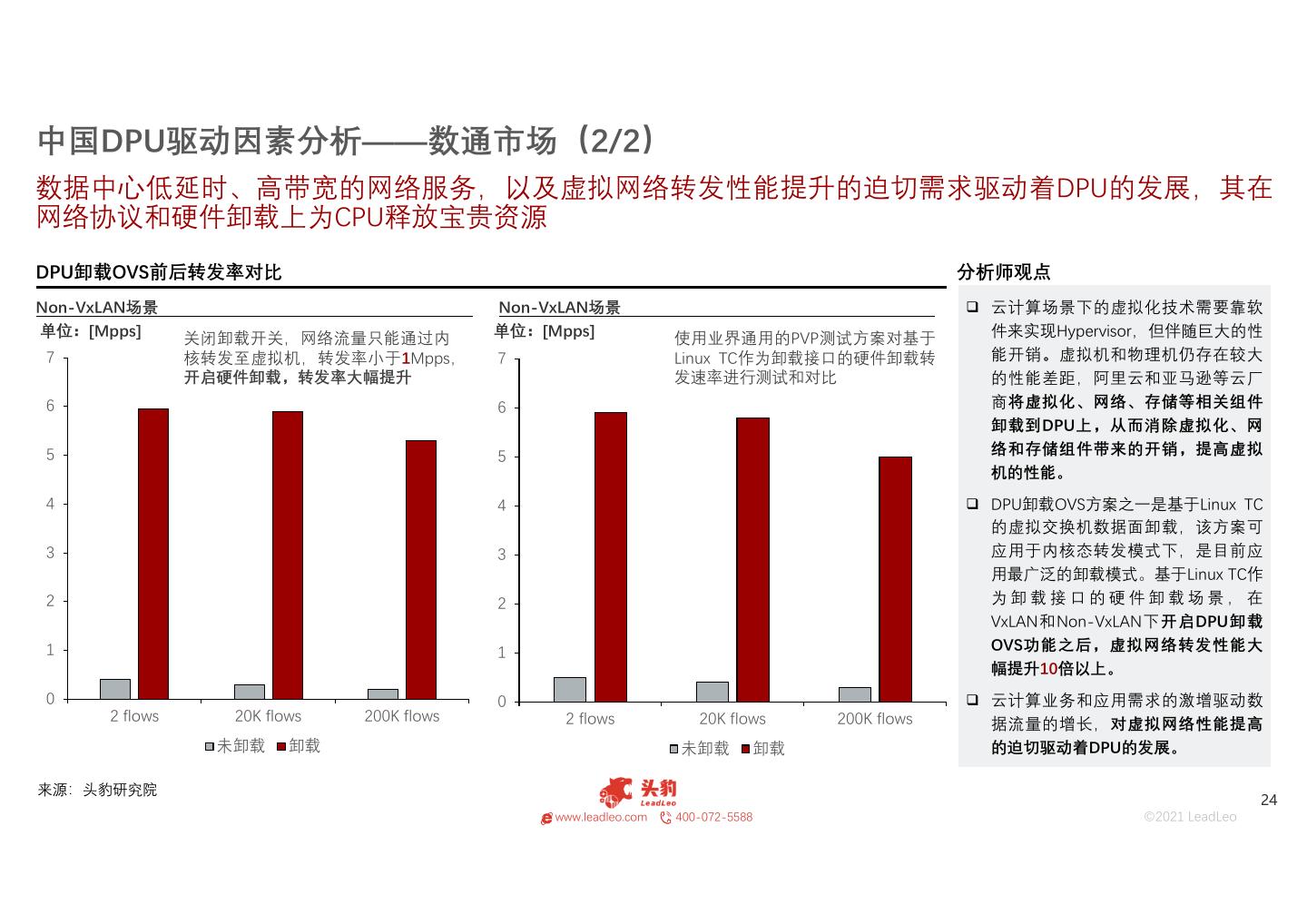
24 .中国DPU驱动因素分析——数通市场(2/2) 数据中心低延时、高带宽的网络服务,以及虚拟网络转发性能提升的迫切需求驱动着DPU的发展,其在 网络协议和硬件卸载上为CPU释放宝贵资源 DPU卸载OVS前后转发率对比 分析师观点 Non-VxLAN场景 Non-VxLAN场景 云计算场景下的虚拟化技术需要靠软 单位:[Mpps] 关闭卸载开关,网络流量只能通过内 单位:[Mpps] 使用业界通用的PVP测试方案对基于 件来实现Hypervisor,但伴随巨大的性 7 核转发至虚拟机,转发率小于1Mpps, 7 Linux TC作为卸载接口的硬件卸载转 能开销。虚拟机和物理机仍存在较大 开启硬件卸载,转发率大幅提升 发速率进行测试和对比 的性能差距,阿里云和亚马逊等云厂 6 6 商将虚拟化、网络、存储等相关组件 卸载到DPU上,从而消除虚拟化、网 5 5 络和存储组件带来的开销,提高虚拟 机的性能。 4 4 DPU卸载OVS方案之一是基于Linux TC 的虚拟交换机数据面卸载,该方案可 3 3 应用于内核态转发模式下,是目前应 用最广泛的卸载模式。基于Linux TC作 2 2 为卸载接口的硬件卸载场景,在 VxLAN和Non-VxLAN下开启DPU卸载 1 1 OVS功能之后,虚拟网络转发性能大 幅提升10倍以上。 0 0 云计算业务和应用需求的激增驱动数 2 flows 20K flows 200K flows 2 flows 20K flows 200K flows 据流量的增长,对虚拟网络性能提高 未卸载 卸载 未卸载 卸载 的迫切驱动着DPU的发展。 来源:头豹研究院 24 www.leadleo.com 400-072-5588 ©2021 LeadLeo
25 .中国DPU驱动因素分析——电信市场 DPU的引入可解决边缘机房升级改造成本过大且无法为MEC提供足够算力的问题,并为MEC在第三方应 用、OVS加速等方面提供硬件加速的支持 MEC加速需求场景 分析师观点 NFVI层OVS加速 VNF层虚拟化用户面加速 5G技术要求网络实现“大容量、大带宽、大 联结、低延迟、低功耗”驱动了DPU在边缘 MEC应用对基础设施性的低延时、高速率转发 虚拟化用户面UPF下沉到MEC,降低传输时延, 机房部署的可能。在当前网络架构中,核 性能有很高的要求。转发能力提升的关键为缓 减少带宽占用,实现软硬解耦,但相对于传统 心网部署在远端,传输时延较大,且无法 DPU功能 存,数据并行处理能力提升的关键在核数。后 专用硬件性能有所下降,对于超低延时的应用 满足5G时代下数字化和智能化对算力的高 要求。 摩尔时代CPU的缓存和核数增长缓慢,引入 和业务无法满足其性能要求,亦可引入DPU作 为了分担终端算力,将算力向云端移动, DPU可突破转发性能和数据处理能力的瓶颈 为硬件加速 同时为了降低时延,将业务向边缘移动。 OVS-vswitch控制面接受SDN控制器的流表配置 虚拟化用户面UPF加速主要是将GTP(GPRS隧 MEC部署在网络边缘,可以减少数据传输 消息,将流表配置写入数据库,更新到OVS- 道协议)业务卸载。同一条数据流的后续数据 过程中的转发和处理时延,并降低终端成 DPU加速方案 本。但随着各种业务和应用汇聚在边缘端, datapath。Ovs-datapath数据通道下沉到DPU, 报文由DPU接收、解包、处理后直接转发,降 导致MEC边缘云的计算开销激增,而边缘 可节省超过2核的CPU 低节点内转发处理层次 机房的供电、散热及承重能力有限,无法 VNF VNF 通过堆加大量的X86 CPU来提升算力,且 GUEST OS DPU加速 GUEST OS CPU性能已无法按摩尔定律增长。此时,在 数据经过多层级拷贝 数据经过DPU直接传 加速原理 传输,时延大、传输 HostOS HostOS 输,降低时延,提升 MEC边缘云上,可将消耗CPU资源高的业 速率低 传输速率 务卸载至DPU上,释放边缘机房CPU的算力, 10G 25G 降低机房功耗,同时提升边缘业务体验。 传统网卡 DPU 来源:头豹研究院 25 www.leadleo.com 400-072-5588 ©2021 LeadLeo
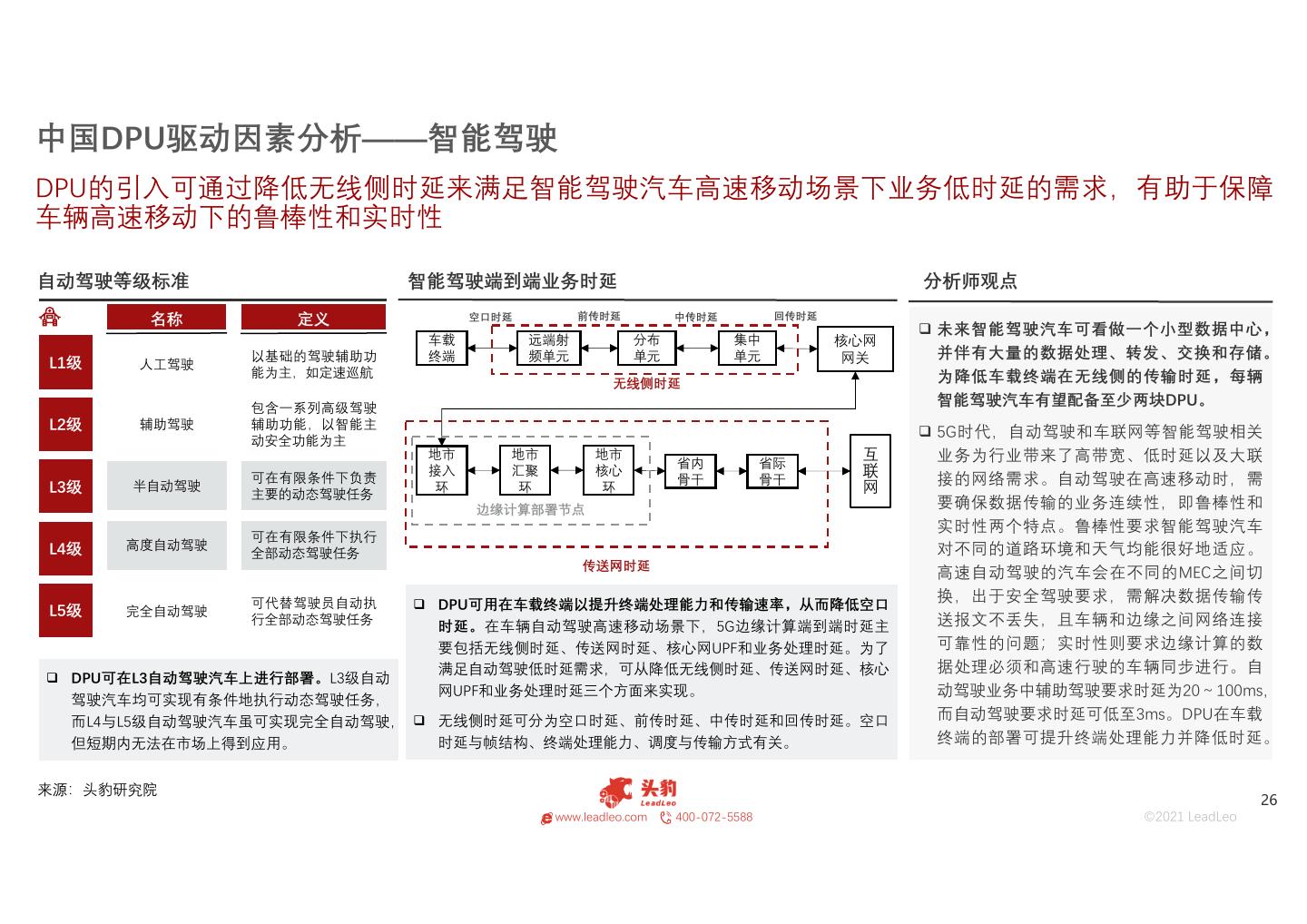
26 .中国DPU驱动因素分析——智能驾驶 DPU的引入可通过降低无线侧时延来满足智能驾驶汽车高速移动场景下业务低时延的需求,有助于保障 车辆高速移动下的鲁棒性和实时性 自动驾驶等级标准 智能驾驶端到端业务时延 分析师观点 名称 定义 空口时延 前传时延 中传时延 回传时延 未来智能驾驶汽车可看做一个小型数据中心, 车载 远端射 分布 集中 核心网 以基础的驾驶辅助功 终端 频单元 单元 单元 网关 并伴有大量的数据处理、转发、交换和存储。 L1级 人工驾驶 能为主,如定速巡航 为降低车载终端在无线侧的传输时延,每辆 无线侧时延 包含一系列高级驾驶 智能驾驶汽车有望配备至少两块DPU。 L2级 辅助驾驶 辅助功能,以智能主 5G时代,自动驾驶和车联网等智能驾驶相关 互联网 动安全功能为主 地市 地市 地市 省内 省际 业务为行业带来了高带宽、低时延以及大联 接入 汇聚 核心 L3级 半自动驾驶 可在有限条件下负责 环 环 环 骨干 骨干 接的网络需求。自动驾驶在高速移动时,需 主要的动态驾驶任务 边缘计算部署节点 要确保数据传输的业务连续性,即鲁棒性和 实时性两个特点。鲁棒性要求智能驾驶汽车 可在有限条件下执行 L4级 高度自动驾驶 对不同的道路环境和天气均能很好地适应。 全部动态驾驶任务 传送网时延 高速自动驾驶的汽车会在不同的MEC之间切 可代替驾驶员自动执 DPU可用在车载终端以提升终端处理能力和传输速率,从而降低空口 换,出于安全驾驶要求,需解决数据传输传 L5级 完全自动驾驶 行全部动态驾驶任务 时延。在车辆自动驾驶高速移动场景下,5G边缘计算端到端时延主 送报文不丢失,且车辆和边缘之间网络连接 要包括无线侧时延、传送网时延、核心网UPF和业务处理时延。为了 可靠性的问题;实时性则要求边缘计算的数 满足自动驾驶低时延需求,可从降低无线侧时延、传送网时延、核心 据处理必须和高速行驶的车辆同步进行。自 DPU可在L3自动驾驶汽车上进行部署。L3级自动 网UPF和业务处理时延三个方面来实现。 动驾驶业务中辅助驾驶要求时延为20~100ms, 驾驶汽车均可实现有条件地执行动态驾驶任务, 而L4与L5级自动驾驶汽车虽可实现完全自动驾驶, 无线侧时延可分为空口时延、前传时延、中传时延和回传时延。空口 而自动驾驶要求时延可低至3ms。DPU在车载 但短期内无法在市场上得到应用。 时延与帧结构、终端处理能力、调度与传输方式有关。 终端的部署可提升终端处理能力并降低时延。 来源:头豹研究院 26 www.leadleo.com 400-072-5588 ©2021 LeadLeo
27 .中国DPU驱动因素分析——政策 集成电路是中国战略性产业,受到政府的大力支撑。DPU作为新一代服务器处理器,亦将受到政策资源 的倾斜 中国集成电路利好政策 评价 集成电路在电子信息产业的地位促使国家近 颁布主体 政策名称/重要会议 颁布日期 政策要点 二十年来不断出台政策鼓励行业发展,其中 • 工信部就加快支持工业半导体芯片技术研发及产业化自 最直接的政策是2011年《国务院关于印发进 主发展的政策扶持、开放合作、关键技术突破、以及人 一步鼓励软件产业和集成电路产业发展若干 《关于政协十三届全国委员会第二 才培养等四个方面做出了答复,工信部将继续支持中国 政策的通知》中明确对IC设计和软件企业实 国家工信部 次会议第2282号(公交邮电类256号) 2019-10 工业半导体领域成熟技术发展,推动中国芯片制造领域 提案答复的函》 良率、产量的提升。积极部署新材料及新一代产品技术 施所得税“两免三减半”优惠政策,该政策一 的研发,推动中国工业半导体材料、芯片、器件、IGBT 直延续至今。2019年5月22日,财政部、税 模块产业的发展 务总局发布公告,为支持IC设计和软件产业 • 先进工艺制造:重点引进12英寸先进工艺生产线。推动 深圳市进一步推动集成电路产业 制造企业与设计企业共同研发高性能CPU/GPU/FPGA和 发展,依法成立且符合条件的IC设计企业和 深圳工信部 2019-05 发展行动计划(2019-2023年) 智能手机SoC芯片。支持集成电路制造企业向晶圆级先 软件企业,在2018年12月31日前自获利年度 进封装拓展 起计算优惠期,第一年至第二年免征企业所 • 重点支持电力电子器件核心产业,其中包括金属氧化物 得税,第三年至第五年按照25%的法定税率 半导体场效应管(MOSFET)、绝缘栅双极晶体管芯片 减半征收企业所得税,并享受至期满为止。 《战略性新兴产业重点产品和服 (IGBT)及模块、快恢复二极管(FRD)、垂直双扩散 国家发改委 2017-12 务指导目录(2016版)》 金 属 - 氧 化 物 场 效 应 晶 体 管 ( VDMOS ) 、 可 控 硅 此前,国常会就决定延续集成电路企业所得 (SCR)、5英寸以上大功率晶闸管(GTO)、集成门极 税优惠政策,会议决定,在已对集成电路生 换流晶闸管(IGCT)、中小功率智能模块 产企业或项目按规定的不同条件分别实行企 • 制定国家信息领域核心技术设备发展战略纲要,以体系 业所得税“两免三减半”或“五免五减半”的基 化思维弥补单点弱势,打造国际先进、安全可控的核心 国务院 《国家信息化发展战略纲要》 2016-07 础上,继续实施2011年明确的所得税“两免 技术体系,带动集成电路、基础软件、核心元器件等薄 弱环节实现根本性突破 三减半”优惠政策。 来源:中央人民政府网,头豹研究院 27 www.leadleo.com 400-072-5588 ©2021 LeadLeo
28 .01 02 03 04 05 竞争格局 28 www.leadleo.com 400-072-5588 ©2021 LeadLeo
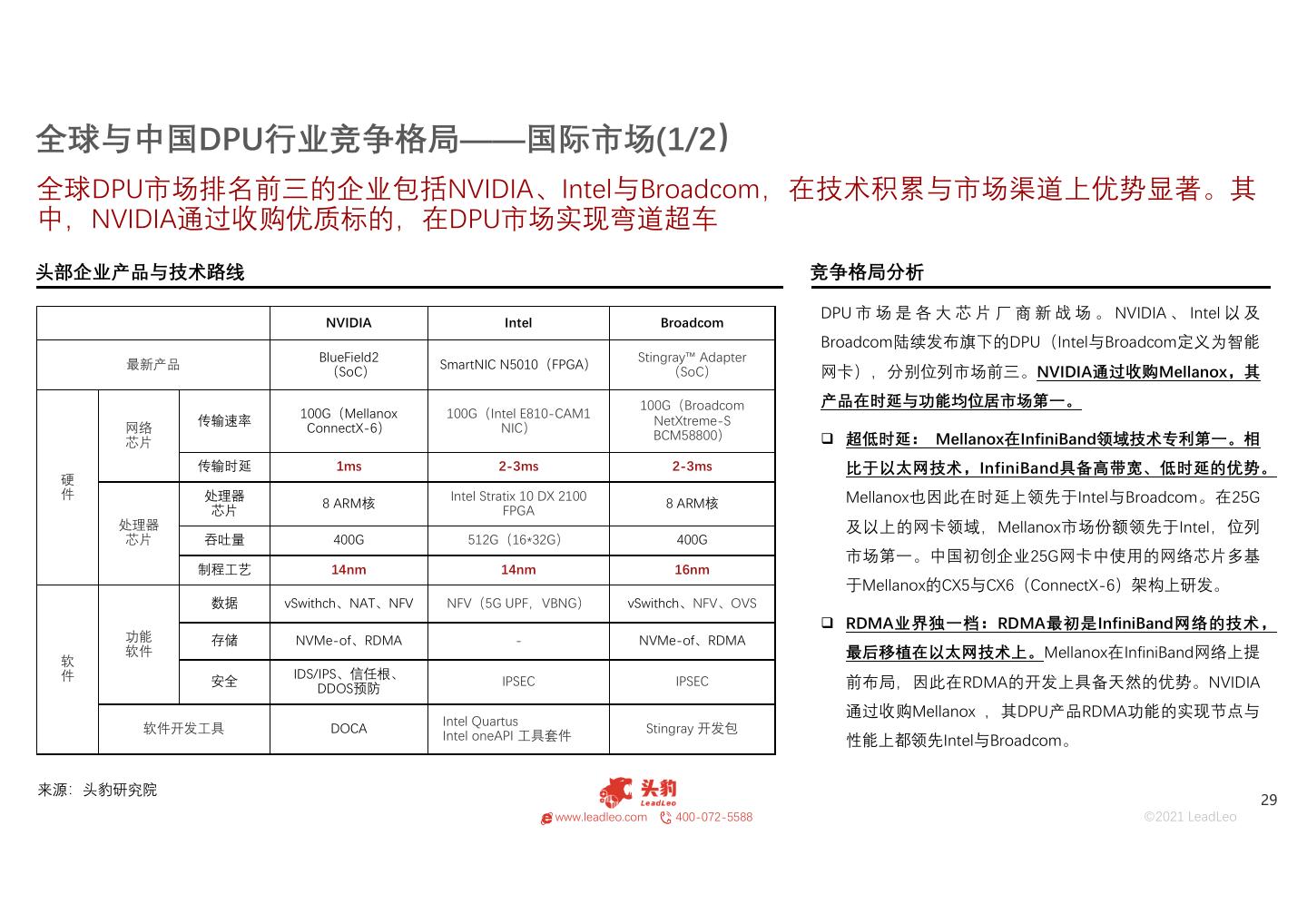
29 .全球与中国DPU行业竞争格局——国际市场(1/2) 全球DPU市场排名前三的企业包括NVIDIA、Intel与Broadcom,在技术积累与市场渠道上优势显著。其 中,NVIDIA通过收购优质标的,在DPU市场实现弯道超车 头部企业产品与技术路线 竞争格局分析 DPU 市 场 是 各 大 芯 片 厂 商 新 战 场 。 NVIDIA 、 Intel 以 及 NVIDIA Intel Broadcom Broadcom陆续发布旗下的DPU(Intel与Broadcom定义为智能 BlueField2 Stingray™ Adapter 最新产品 SmartNIC N5010(FPGA) (SoC) (SoC) 网卡),分别位列市场前三。NVIDIA通过收购Mellanox,其 100G(Broadcom 产品在时延与功能均位居市场第一。 100G(Mellanox 100G(Intel E810-CAM1 传输速率 NetXtreme-S 网络 ConnectX-6) NIC) BCM58800) 超低时延: Mellanox在InfiniBand领域技术专利第一。相 芯片 传输时延 1ms 2-3ms 2-3ms 比于以太网技术,InfiniBand具备高带宽、低时延的优势。 硬 件 处理器 Intel Stratix 10 DX 2100 Mellanox也因此在时延上领先于Intel与Broadcom。在25G 8 ARM核 8 ARM核 芯片 FPGA 处理器 及以上的网卡领域,Mellanox市场份额领先于Intel,位列 芯片 吞吐量 400G 512G(16*32G) 400G 市场第一。中国初创企业25G网卡中使用的网络芯片多基 制程工艺 14nm 14nm 16nm 于Mellanox的CX5与CX6(ConnectX-6)架构上研发。 数据 vSwithch、NAT、NFV NFV(5G UPF,VBNG) vSwithch、NFV、OVS RDMA业界独一档:RDMA最初是InfiniBand网络的技术, 功能 存储 NVMe-of、RDMA - NVMe-of、RDMA 软 软件 最后移植在以太网技术上。Mellanox在InfiniBand网络上提 件 IDS/IPS、信任根、 安全 DDOS预防 IPSEC IPSEC 前布局,因此在RDMA的开发上具备天然的优势。NVIDIA 通过收购Mellanox ,其DPU产品RDMA功能的实现节点与 Intel Quartus 软件开发工具 DOCA Stingray 开发包 Intel oneAPI 工具套件 性能上都领先Intel与Broadcom。 来源:头豹研究院 29 www.leadleo.com 400-072-5588 ©2021 LeadLeo
相关推荐

加关注
3秒后跳转登录页面
去登陆

