




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
尤洋-(AAAI)WideNet | User Group-机器学习专题-211226
展开查看详情
1 . Go Wider Instead of Deeper Fuzhao Xue, Ziji Shi, Yuxuan Lou, Futao Wei, Yong Liu, Yang You National University of Singapore AAAI 2022
2 .Outline 1. Background 2. Motivation 3. Methodology 4. Experiments 5. Conclusion
3 .Background Question: What is Transformer? Answer: A popular and powerful attention-based neural network architecture One Transformer model includes many Transformer blocks. Each Transformer block includes: 1. Multihead attention (MHA) layer 2. Feedforward neural network (FFN) layer 3. Residual Connection 4. Layer Normalization
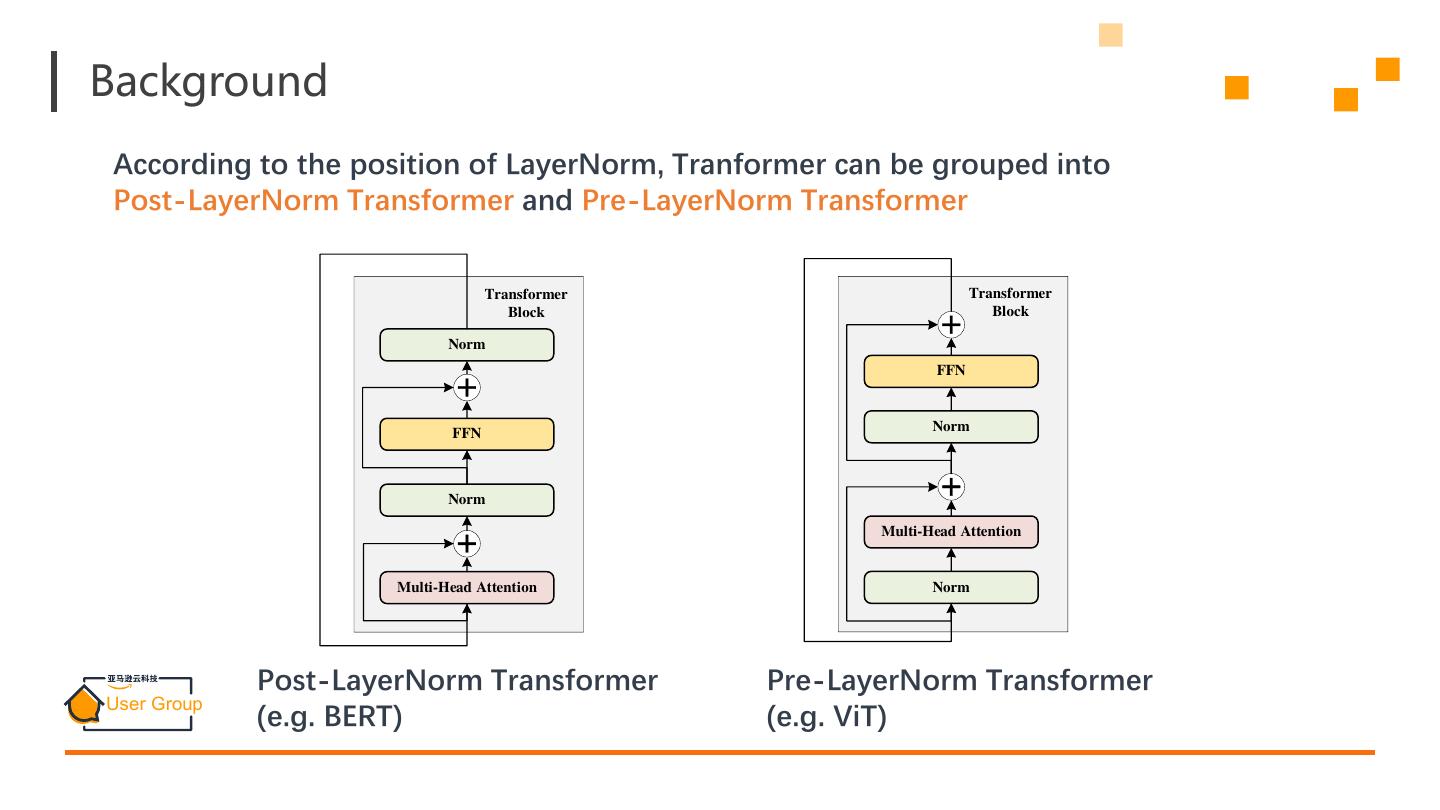
4 .Background According to the position of LayerNorm, Tranformer can be grouped into Post-LayerNorm Transformer and Pre-LayerNorm Transformer Transformer Transformer Block Block Norm FFN FFN Norm Norm Multi-Head Attention Multi-Head Attention Norm Post-LayerNorm Transformer Pre-LayerNorm Transformer (e.g. BERT) (e.g. ViT)
5 .Background Question: How to improve Transformer? Answer: Two train of thoughts Larger: → More effective 1. More trainable matrices (e.g. MoE) → Comparable efficiency 2. Larger trainable matrices (e.g. GPT-3) → Lower efficiency Smaller: → Less effective but more efficient 1. Knowledge distillation (e.g. DistillBERT) 2. Parameter sharing (e.g. ALBERT)
6 .Motivation Both of these two thoughts have their own limitations: Larger: 1. Advanced parallelisms are required. 2. The performance cannot improve linearly during scaling. 3. The sparseness of MoE based models cannot scale well on relatively small datasets. Smaller: 1. Performance is still usually under the original transformers. 2. Gradient explosion and vanishing
7 .Motivation Our target: A general parameter-efficient framework Q1: What is parameter-efficient? Answer: Better performance (accuracy) with fewer trainable parameters Q2: Why parameter-efficient is challenging? Answer: Fewer parameters mean smaller capacity
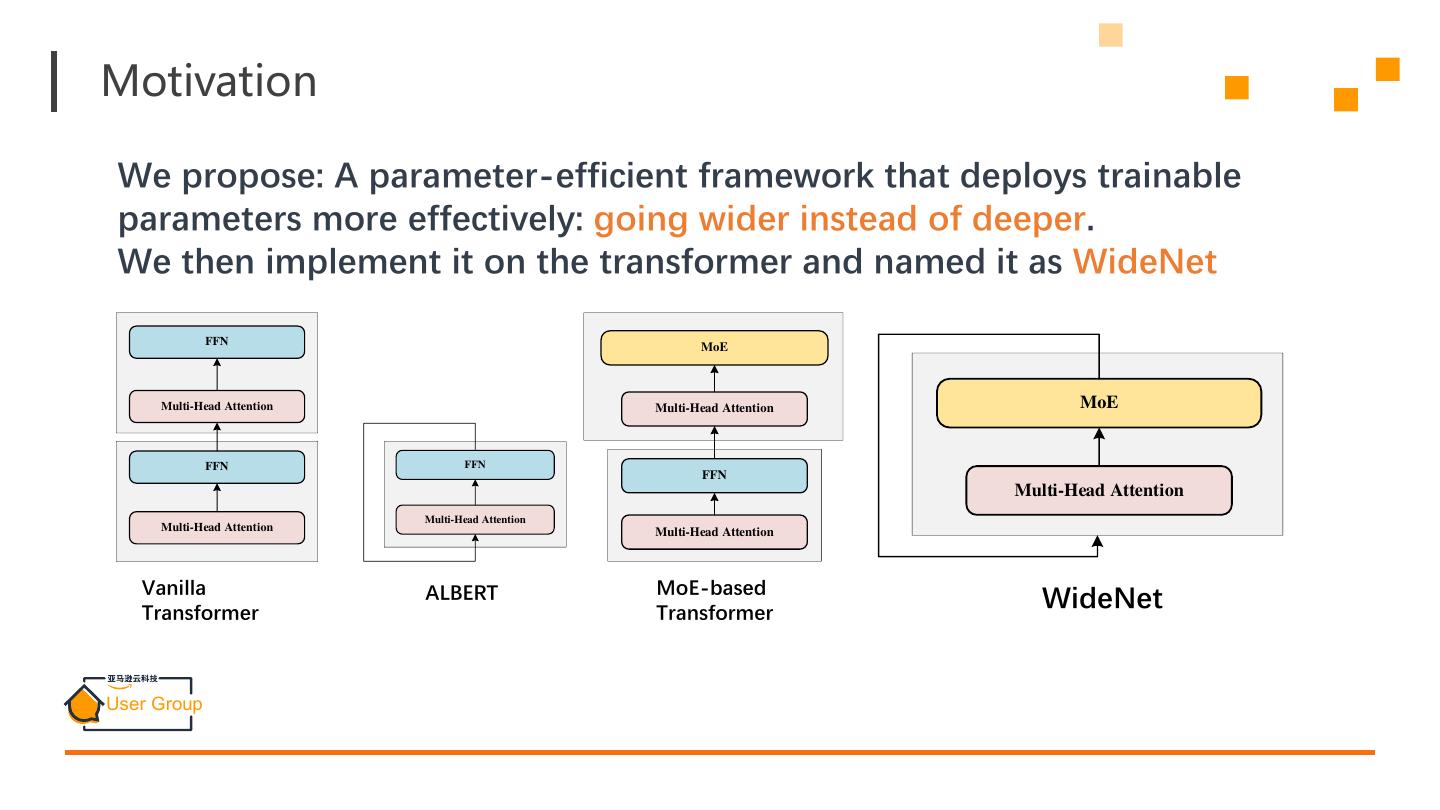
8 .Motivation We propose: A parameter-efficient framework that deploys trainable parameters more effectively: going wider instead of deeper. We then implement it on the transformer and named it as WideNet FFN MoE Multi-Head Attention Multi-Head Attention MoE FFN FFN FFN Multi-Head Attention Multi-Head Attention Multi-Head Attention Multi-Head Attention Vanilla ALBERT MoE-based Transformer Transformer WideNet
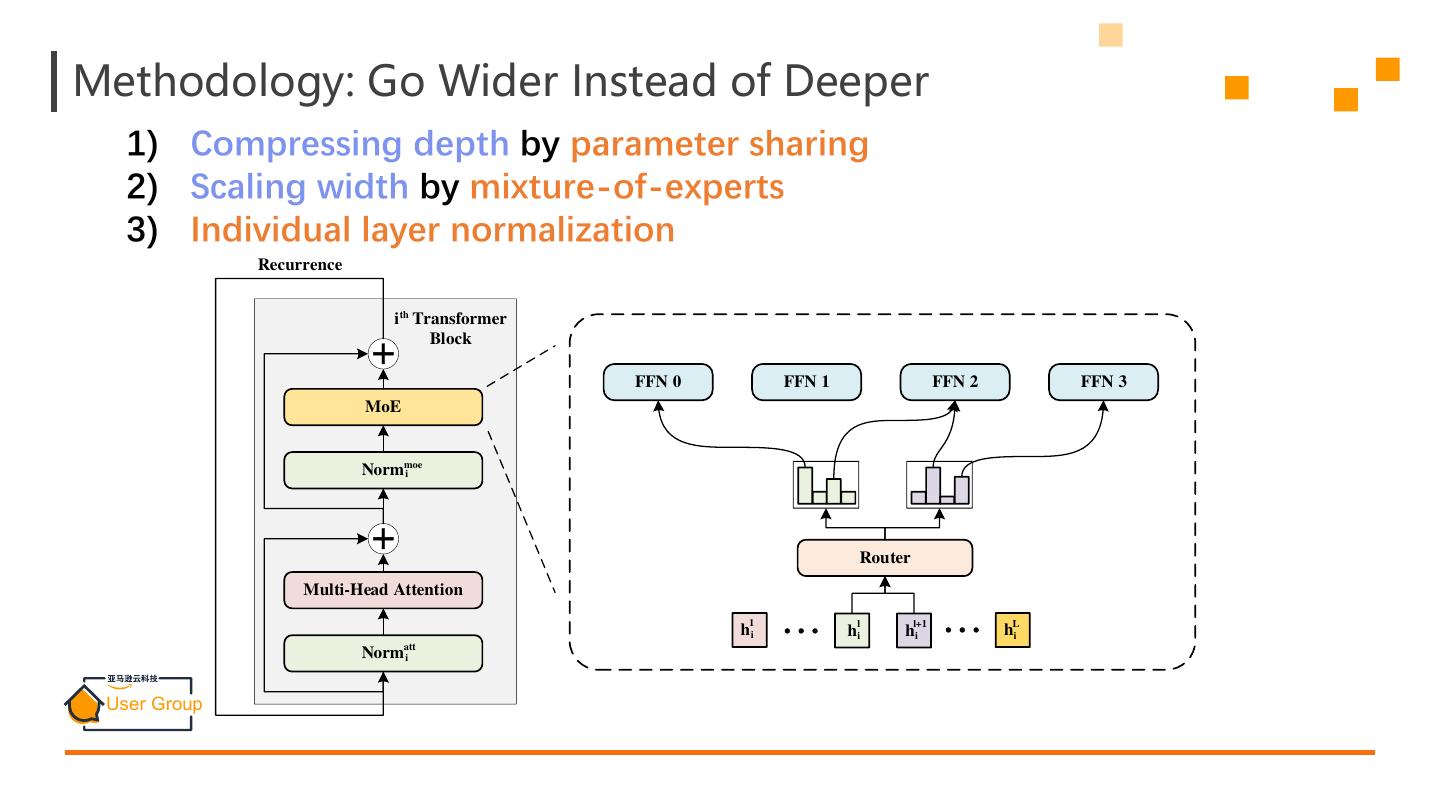
9 .Methodology: Go Wider Instead of Deeper 1) Compressing depth by parameter sharing 2) Scaling width by mixture-of-experts 3) Individual layer normalization Recurrence i th Transformer Block FFN 0 FFN 1 FFN 2 FFN 3 MoE Normmoe i Router Multi-Head Attention 1 l l+1 L hai hi hai ha i Normatt i
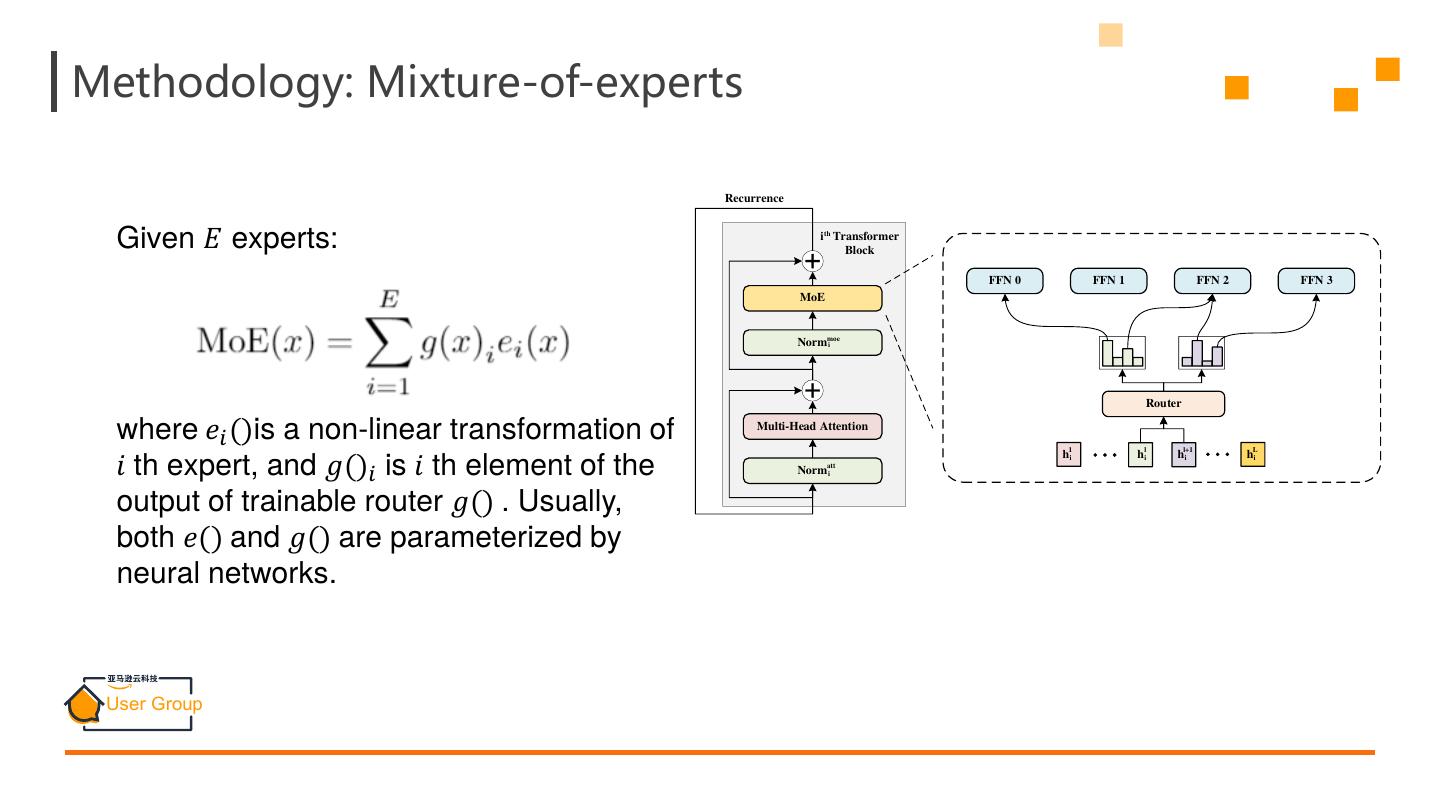
10 .Methodology: Mixture-of-experts Recurrence Given 𝐸 experts: i th Transformer Block FFN 0 FFN 1 FFN 2 FFN 3 MoE Normmoe i Router where 𝑒𝑖 ()is a non-linear transformation of Multi-Head Attention 1 l l+1 L hai hi hai ha 𝑖 th expert, and 𝑔()𝑖 is 𝑖 th element of the Norm att i i output of trainable router 𝑔() . Usually, both 𝑒() and 𝑔() are parameterized by neural networks.
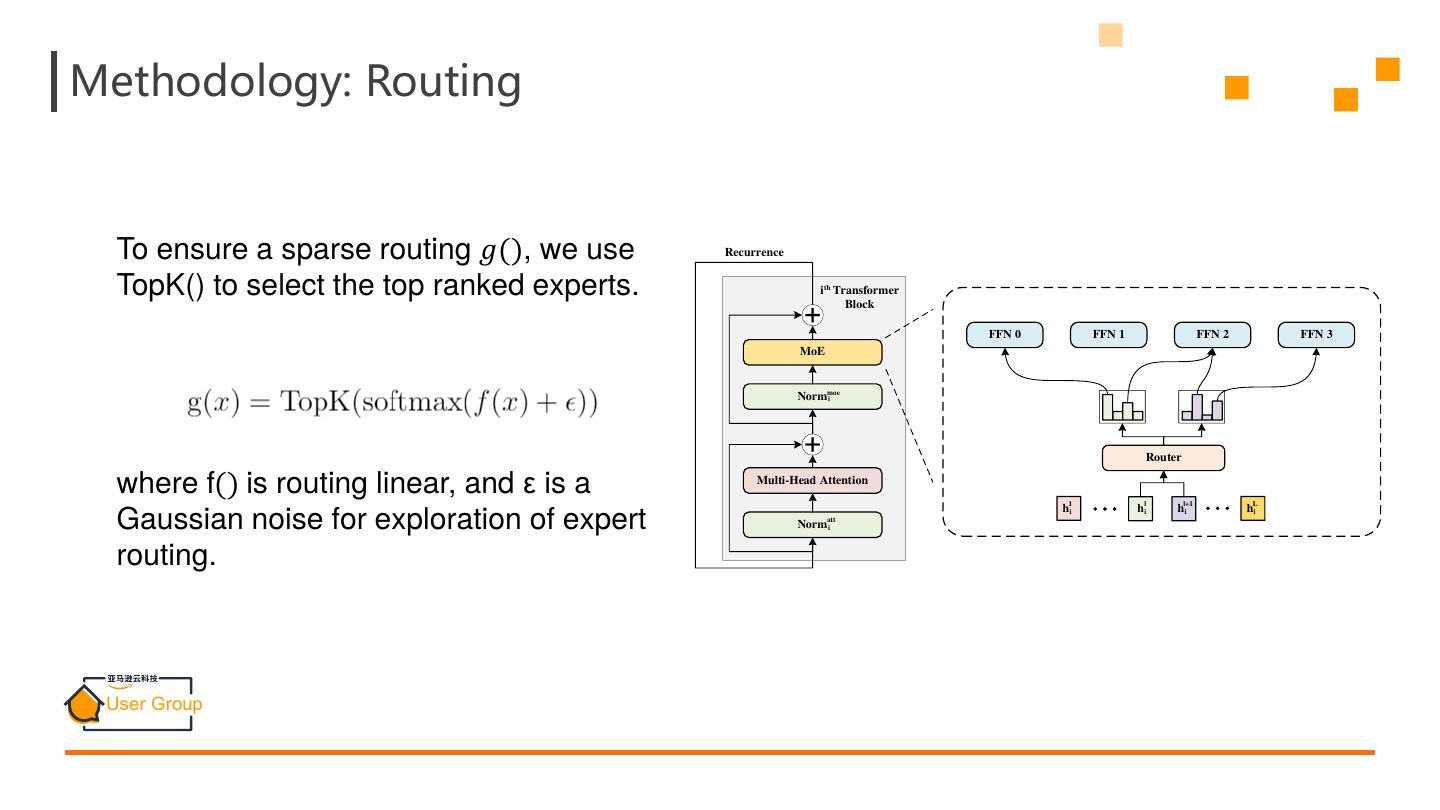
11 .Methodology: Routing To ensure a sparse routing 𝑔(), we use Recurrence TopK() to select the top ranked experts. i th Transformer Block FFN 0 FFN 1 FFN 2 FFN 3 MoE Normmoe i Router where f() is routing linear, and ε is a Multi-Head Attention 1 l l+1 L hai hi hai ha Gaussian noise for exploration of expert Norm att i i routing.
12 .Methodology: Balanced Loading An unbalanced assignment would decrease the throughput and performance of the MoE model. Therefore, We have two things to avoid: (1) too many tokens dispatched to one single expert, and (2) too few tokens received by one single expert. To solve the first issue, we define buffer capacity 𝐵 : where 𝐶 is the capacity ratio, 𝐾 is the number of selected experts for each token. 𝑁 is the batch size on each device. 𝐿 is the sequence length. For each expert, we only preserve 𝐵 token at most regardless of how many tokens are dispatched to this expert.
13 .Methodology: Balanced Loading To solve the second issue, the following auxiliary loss is added to the total model loss during training: Where 𝑚 is vector. 𝑖 th element is the fraction of tokens dispatched to expert 𝑖 : Where h() is an index vector selected by Top K. ℎ(𝑥𝑗 )𝑖 is 𝑖 th element of ℎ(𝑥𝑗 ) . 𝑚 is non-differentiable. Therefore, we define a differentiable 𝑃𝑖 as: When we minimize 𝑙𝑏𝑎𝑙𝑎𝑛𝑐𝑒 , we can see both 𝑚 and 𝑃 would close to a uniform distribution. Note: 𝑃𝑖 is the input of Top K within router 𝑔()
14 .Methodology: Sharing MoE across transformer blocks Recurrence i th Transformer Block FFN 0 FFN 1 FFN 2 FFN 3 MoE Normmoe i Router Multi-Head Attention 1 l l+1 L hai hi hai ha i att Norm i Although we share trainable parameters in the MoE layer including the router, token representations corresponding to the same token are different in every transformer block. Therefore, each expert would be trained by more varied tokens for better generalization performance
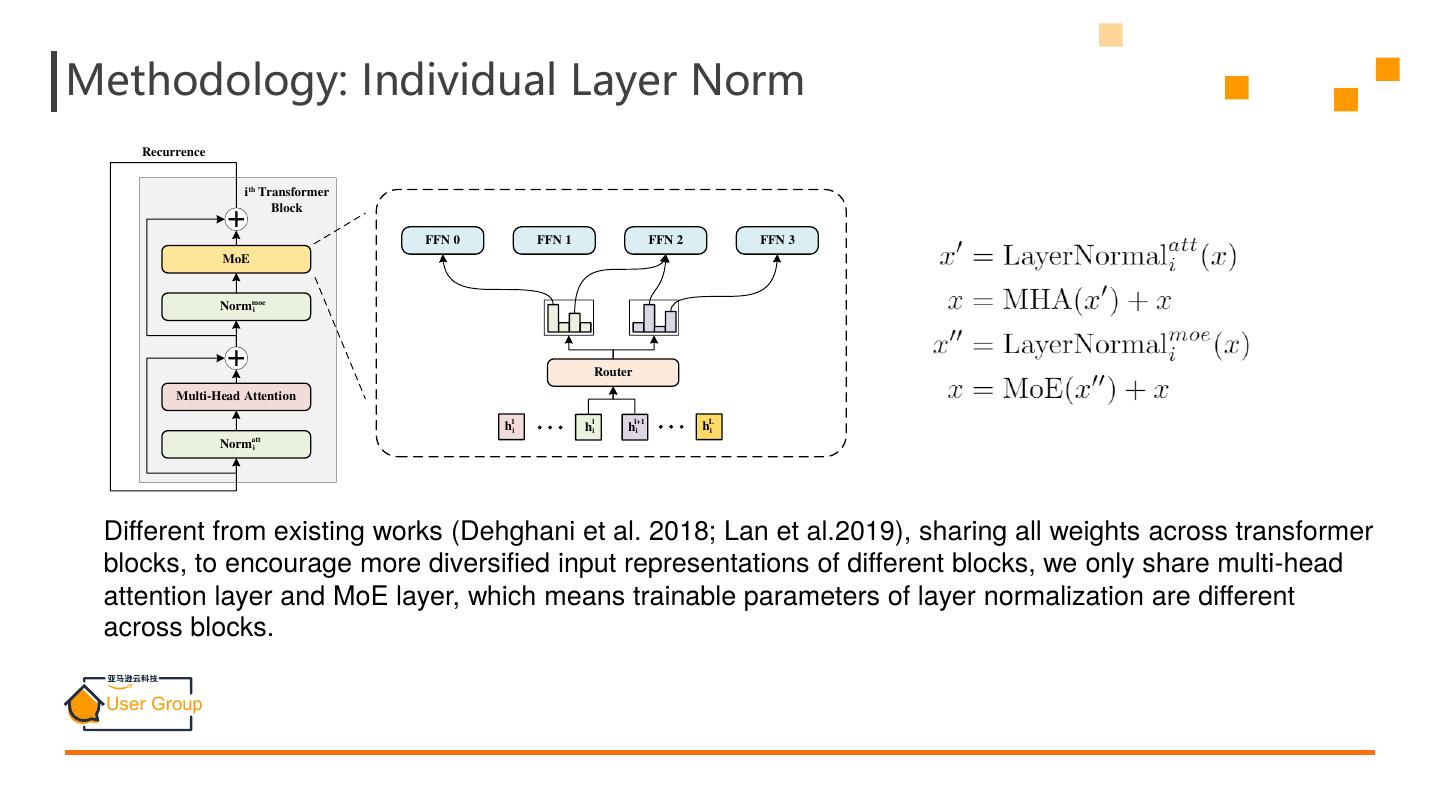
15 .Methodology: Individual Layer Norm Recurrence i th Transformer Block FFN 0 FFN 1 FFN 2 FFN 3 MoE Normmoe i Router Multi-Head Attention 1 l l+1 L hai hi hai ha i att Norm i Different from existing works (Dehghani et al. 2018; Lan et al.2019), sharing all weights across transformer blocks, to encourage more diversified input representations of different blocks, we only share multi-head attention layer and MoE layer, which means trainable parameters of layer normalization are different across blocks.
16 .Methodology: Optimization The final loss function is: Wh λ i a hy -parameter to ensure a balanced assignment, and we set it as a relatively large number, i.e.,0.01 in this work.
17 .CV Experiments: Settings Dataset: ImageNet-1K, Cifar10 Data Augmentation: Inception-style preprocessing, Mixup, RandAugment and label smoothing Optimizer: LAMB on ImageNet-1K, SGD on Cifar10 Note: We observe LAMB can achieve comparable accuracy but be more robust to hyper-parameters, so we use LAMB as optimizer in this work.
18 .CV Experiments: Hyper-parameters We use the same hyper-parameters with ViT except learning rate and weight decay. Larger learning rate and weight decay works better when we use LAMB
19 .CV Experiments: Main Results Compared with the strongest baseline, our WideNet-H outperforms ViT-B by 1.5% with fewer trainable parameters. When we scale up to WideNet-L, it has surpassed all baselines with half trainable parameters of ViT-B and 0.13 times parameters of ViT-L.
20 .NLP Experiments: Settings Pretrain Dataset: Wikipedia, Bookscorpus Finetune Dataset: SQuAD1.1, SQuAD2.0, MNLI, SST-2 Optimizer: LAMB on pretraining, AdamW on Finetuning
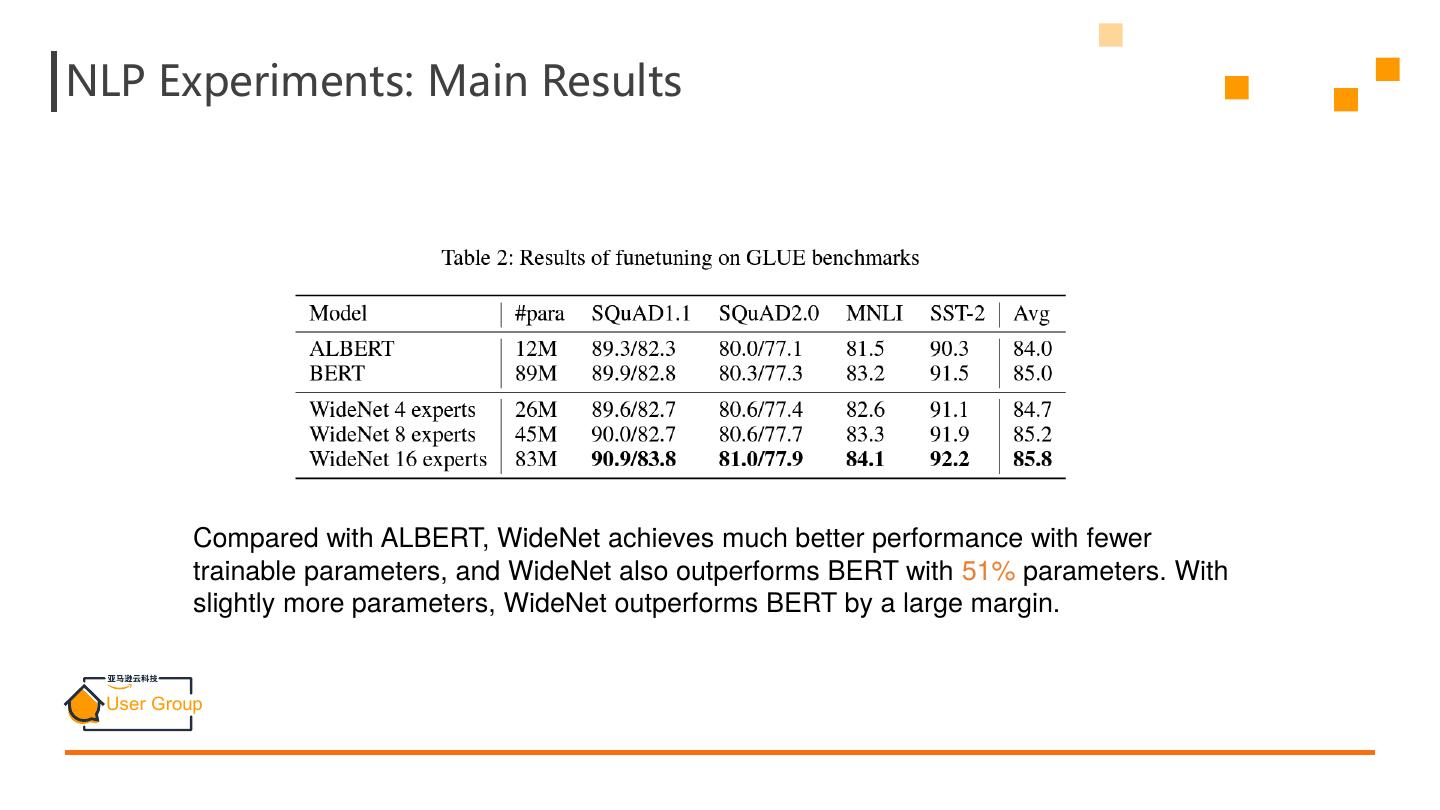
21 .NLP Experiments: Main Results Compared with ALBERT, WideNet achieves much better performance with fewer trainable parameters, and WideNet also outperforms BERT with 51% parameters. With slightly more parameters, WideNet outperforms BERT by a large margin.
22 .Experiments: Ablation Study
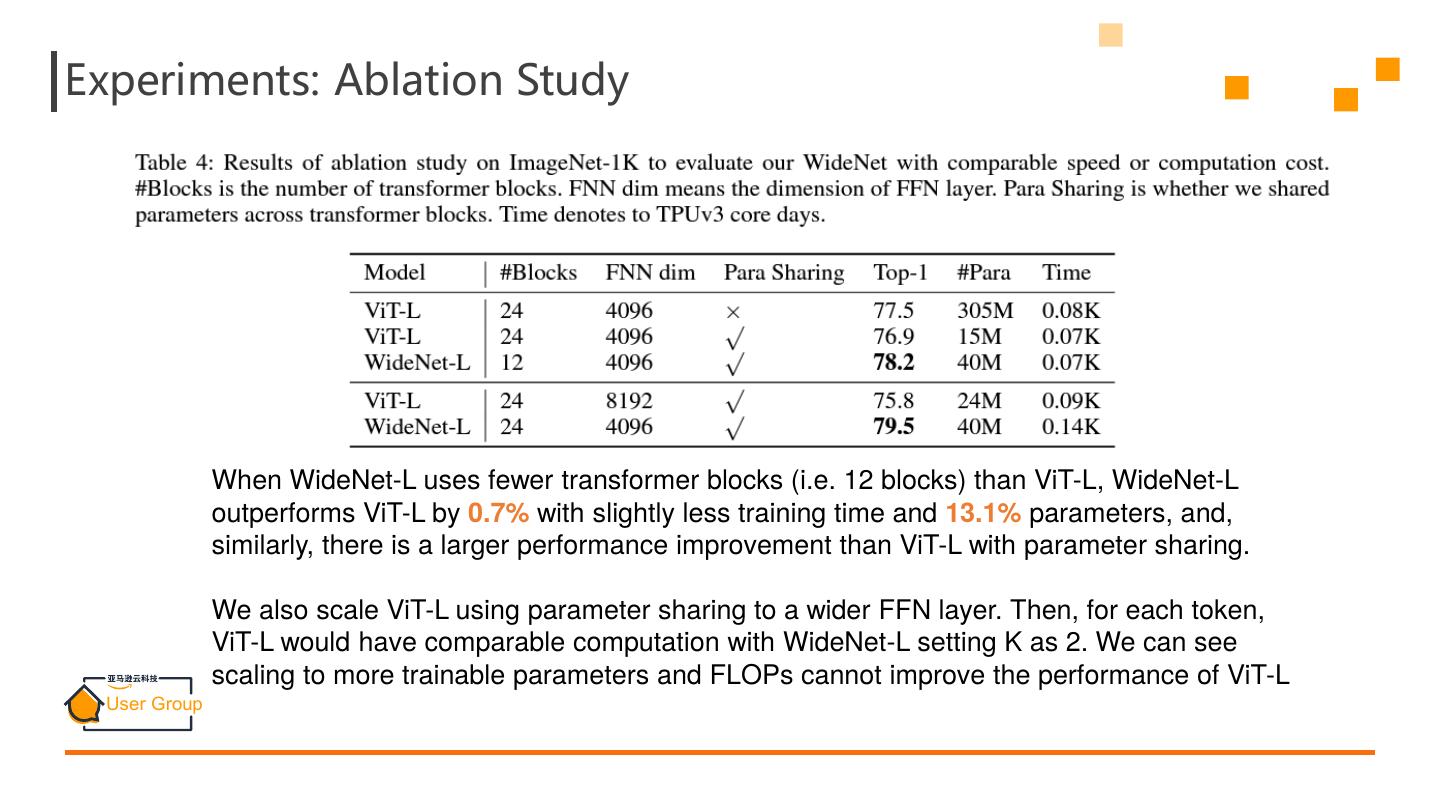
23 .Experiments: Ablation Study When WideNet-L uses fewer transformer blocks (i.e. 12 blocks) than ViT-L, WideNet-L outperforms ViT-L by 0.7% with slightly less training time and 13.1% parameters, and, similarly, there is a larger performance improvement than ViT-L with parameter sharing. We also scale ViT-L using parameter sharing to a wider FFN layer. Then, for each token, ViT-L would have comparable computation with WideNet-L setting K as 2. We can see scaling to more trainable parameters and FLOPs cannot improve the performance of ViT-L
24 .Experiments: MoE Analysis Question: Why ViT-MoE cannot work well on ImageNet-1K? ViT-MoE cannot scale to more experts well due to overfitting.
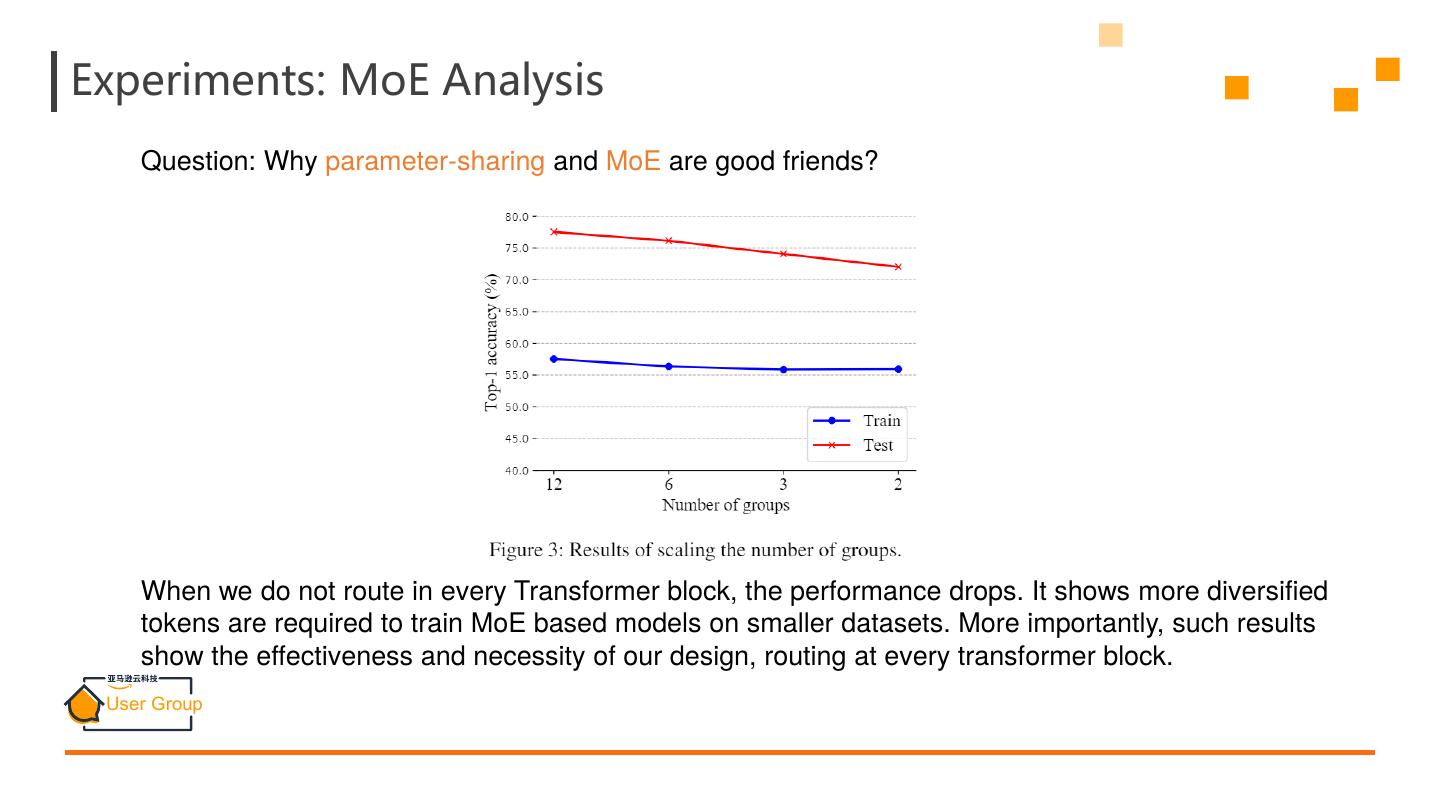
25 .Experiments: MoE Analysis Question: Why parameter-sharing and MoE are good friends? When we do not route in every Transformer block, the performance drops. It shows more diversified tokens are required to train MoE based models on smaller datasets. More importantly, such results show the effectiveness and necessity of our design, routing at every transformer block.
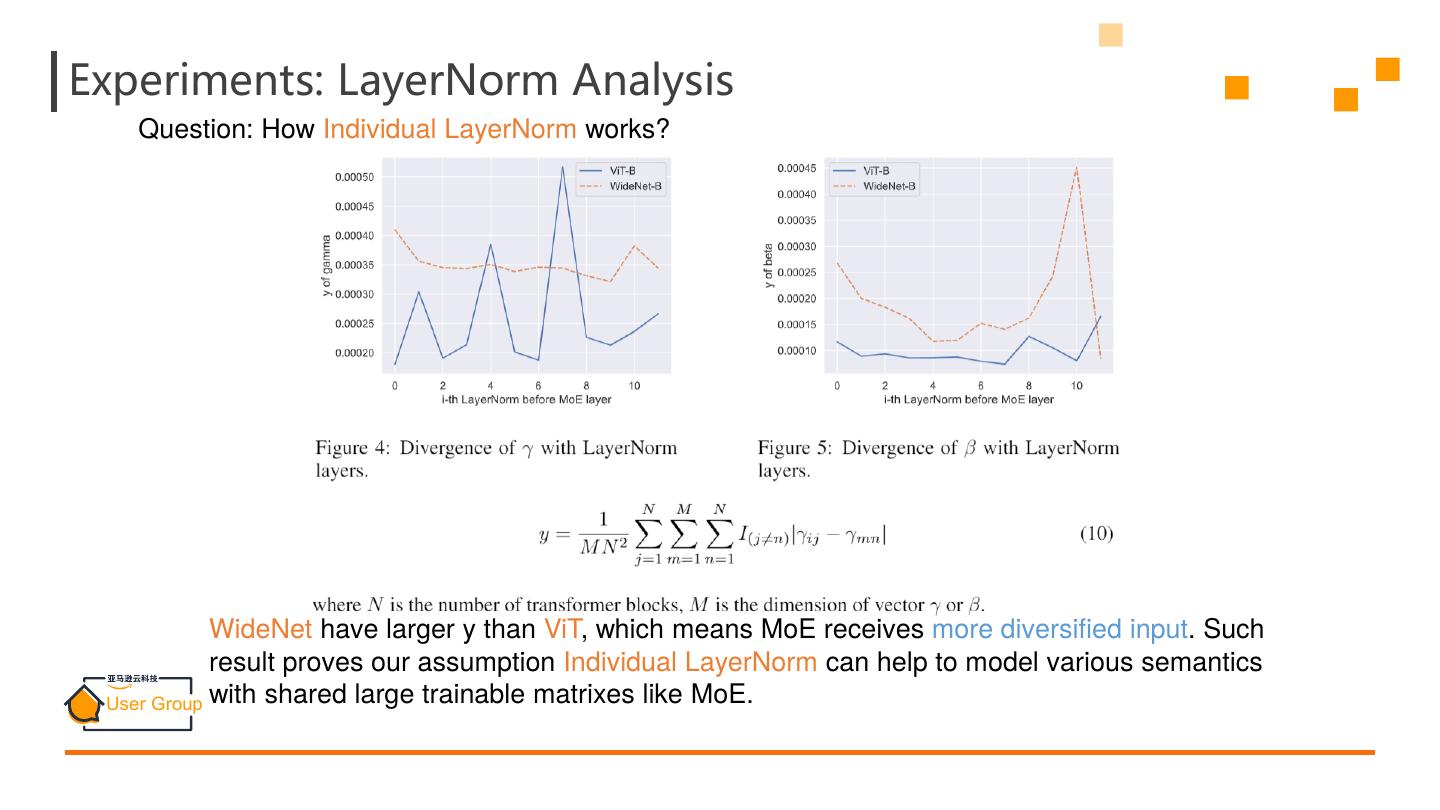
26 .Experiments: LayerNorm Analysis Question: How Individual LayerNorm works? WideNet have larger y than ViT, which means MoE receives more diversified input. Such result proves our assumption Individual LayerNorm can help to model various semantics with shared large trainable matrixes like MoE.
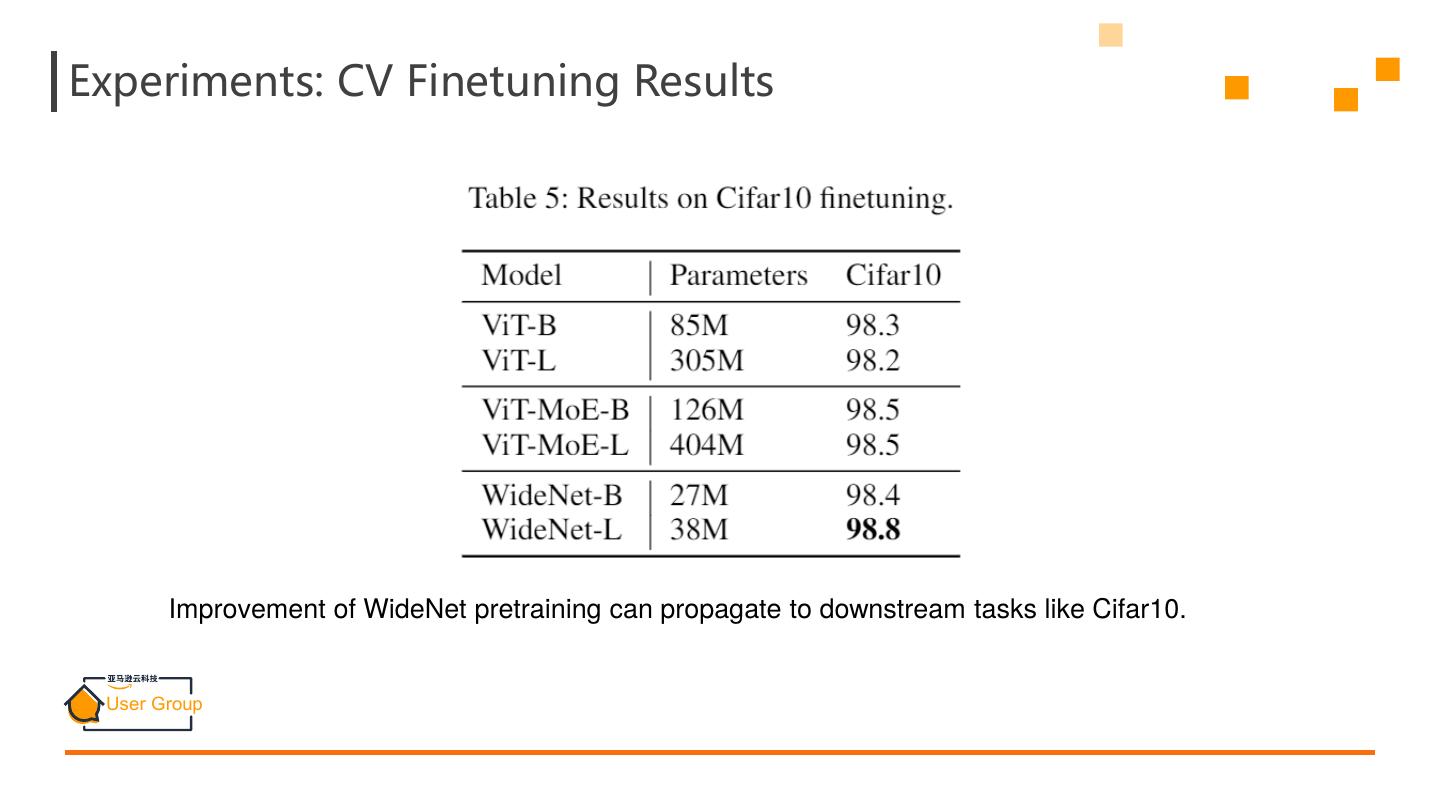
27 .Experiments: CV Finetuning Results Improvement of WideNet pretraining can propagate to downstream tasks like Cifar10.
28 .Conclusion 1) In this paper, we propose to go wider instead of deeper for more efficient and effective parameter deployment. We implement this framework as WideNet. 2) WideNet first compresses trainable parameters along with depth by parameter-sharing across transformer blocks. 3) To maximize the modeling ability of each transformer block, we replace the FFN layer with the MoE layer. 4) Individual layer normalization provides a more parameter-efficient way to transform semantic representations across blocks. 5) On ImageNet-1K, our best model achieves 80.1% Top-1 accuracy with only 63M parameters, which outperforms ViT and ViT-MoE by a large margin. On NLP tasks, we also outperform SoTAs (i.e. BERT, ALBERT) significantly.
29 .T HANKS
相关推荐
3秒后跳转登录页面
去登陆

