
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
FPGA-BASED ACCELERATION ARCHITEC
This slide show you how to use Intel FPGA to accelerate the Spark SQL workload
展开查看详情
1 .Qi Xie ( qi.xie@intel.com) Hao Cheng ( hao.cheng@intel.com) Quanfu Wang ( quanfu.wang@intel.com ) FPGA-BASED ACCELERATION ARCHITECTURE FOR SPARK SQL
2 .LEGAL NOTICES You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. N o license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm. Intel, the Intel logo, Intel® are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark , are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks. Copyright © 2017 Intel Corporation. 2
3 .About me Software engineer from Intel Big Data Engineering Spark team Focused on Spark optimization for Intel Architecture 3
4 .Outline What’s an FPGA Intel FPGA Platform W orkload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 4
5 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 5
6 .What is an FPGA ? Field Programmable Gate Array 6 Configurable Logic Blocks (CLB ) Embedded Memory Digital signal processing (DSP) blocks I/O pads Hard IP(PCIe, DDR, GigE, etc )
7 .7 Why FPGA ? Truth Table a b c y 0 0 0 1 0 0 1 0 0 1 0 1 0 1 1 1 1 0 0 1 1 0 1 0 1 1 0 1 1 1 1 1 Programmed LUT Required Function Reconfigurable architecture CLB consists of LUTs. LUT is a RAM with data width of 1 bit. The contents are programmed at power up. Low-power, energy efficiency, compared with CPU/GPU Extreme degree of customizations, Well positioned for High performance and providing flexibility
8 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 8
9 .Discrete and Integrated FPGA platforms 9
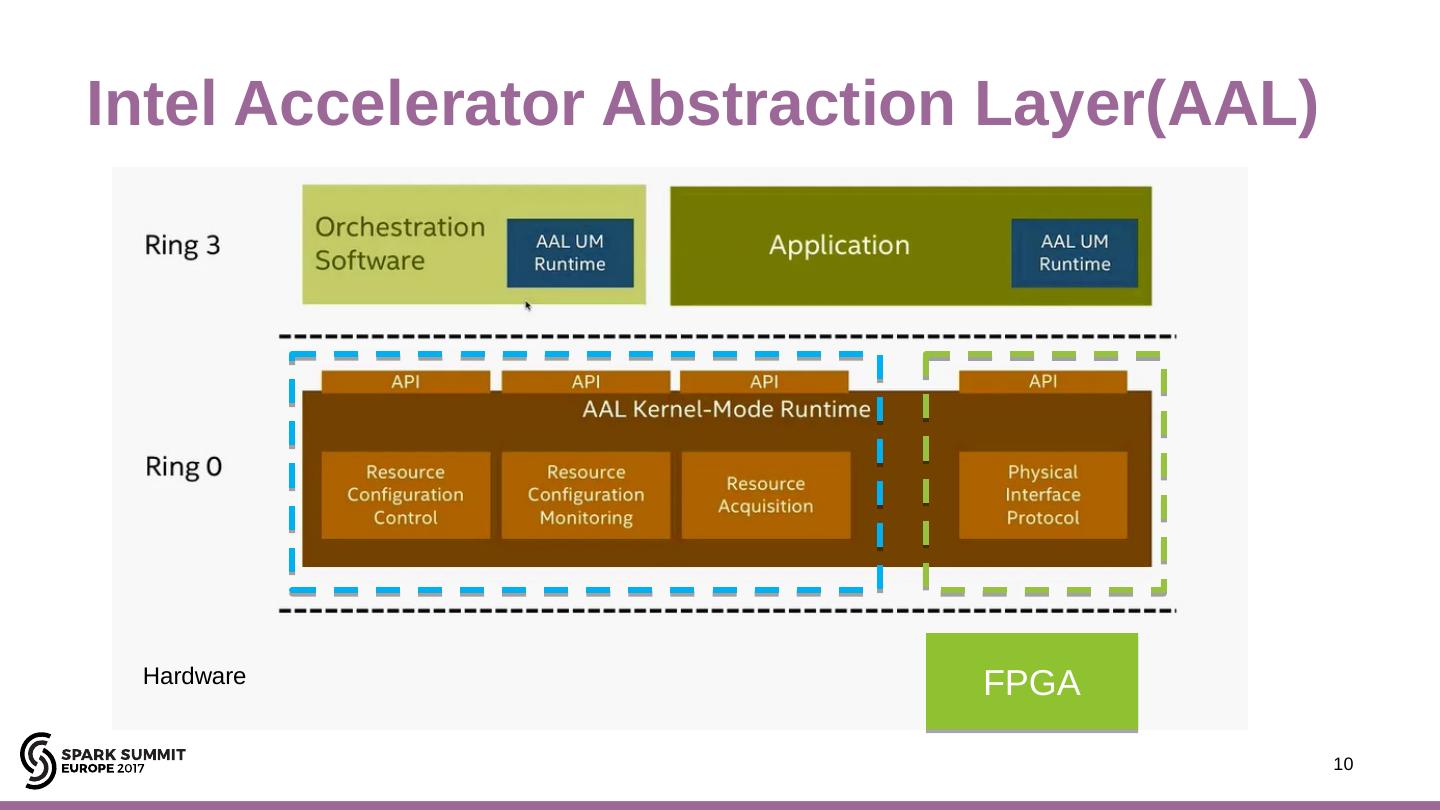
10 .Intel Accelerator Abstraction Layer(AAL) 10 FPGA Hardware
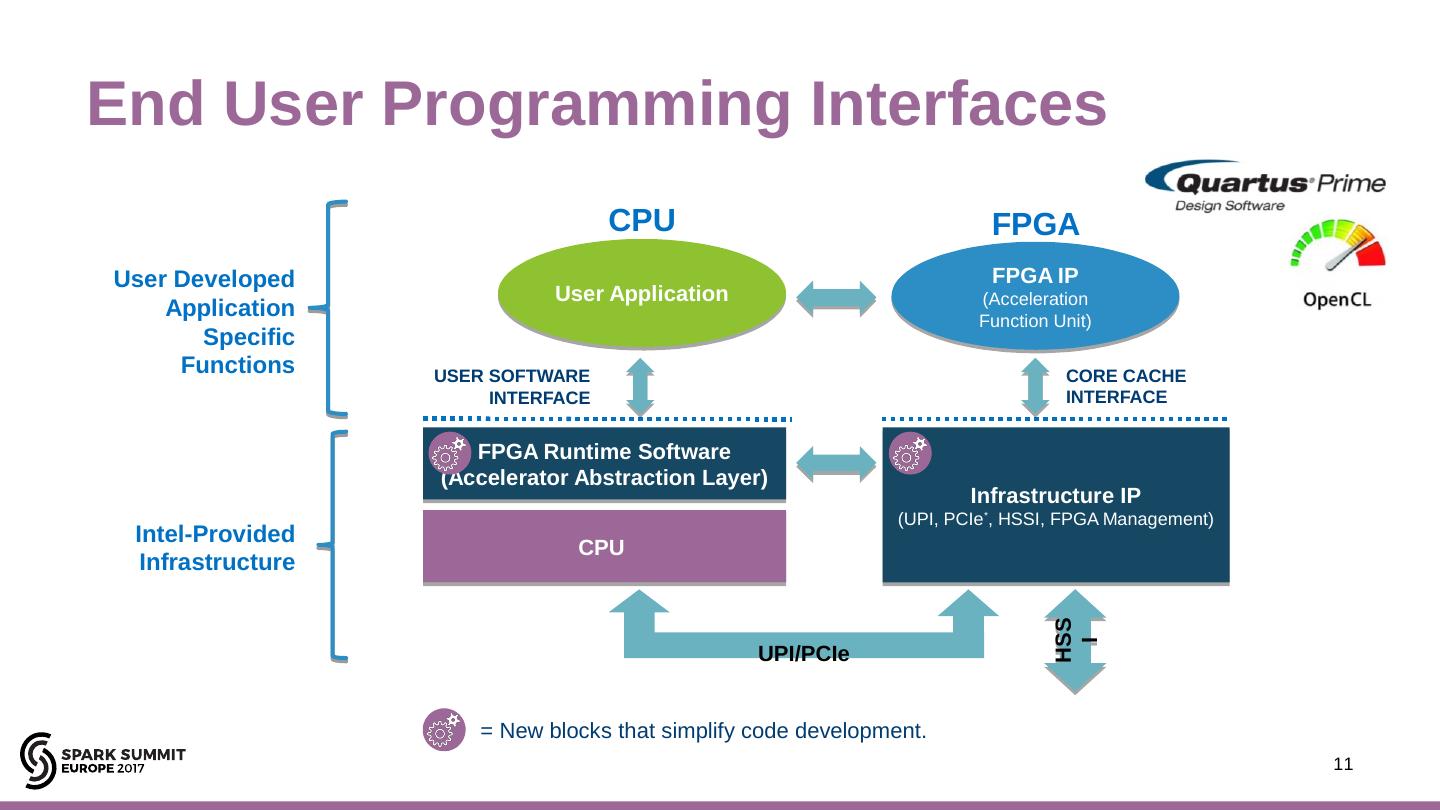
11 .End User Programming Interfaces 11 FPGA CPU User Application CPU Infrastructure IP (UPI, PCIe * , HSSI, FPGA Management) FPGA Runtime Software (Accelerator Abstraction Layer) FPGA IP (Acceleration Function Unit) Intel-Provided Infrastructure USER SOFTWARE INTERFACE User Developed Application Specific Functions UPI/PCIe HSSI = New blocks that simplify code development. CORE CACHE INTERFACE Intel ® Confidential
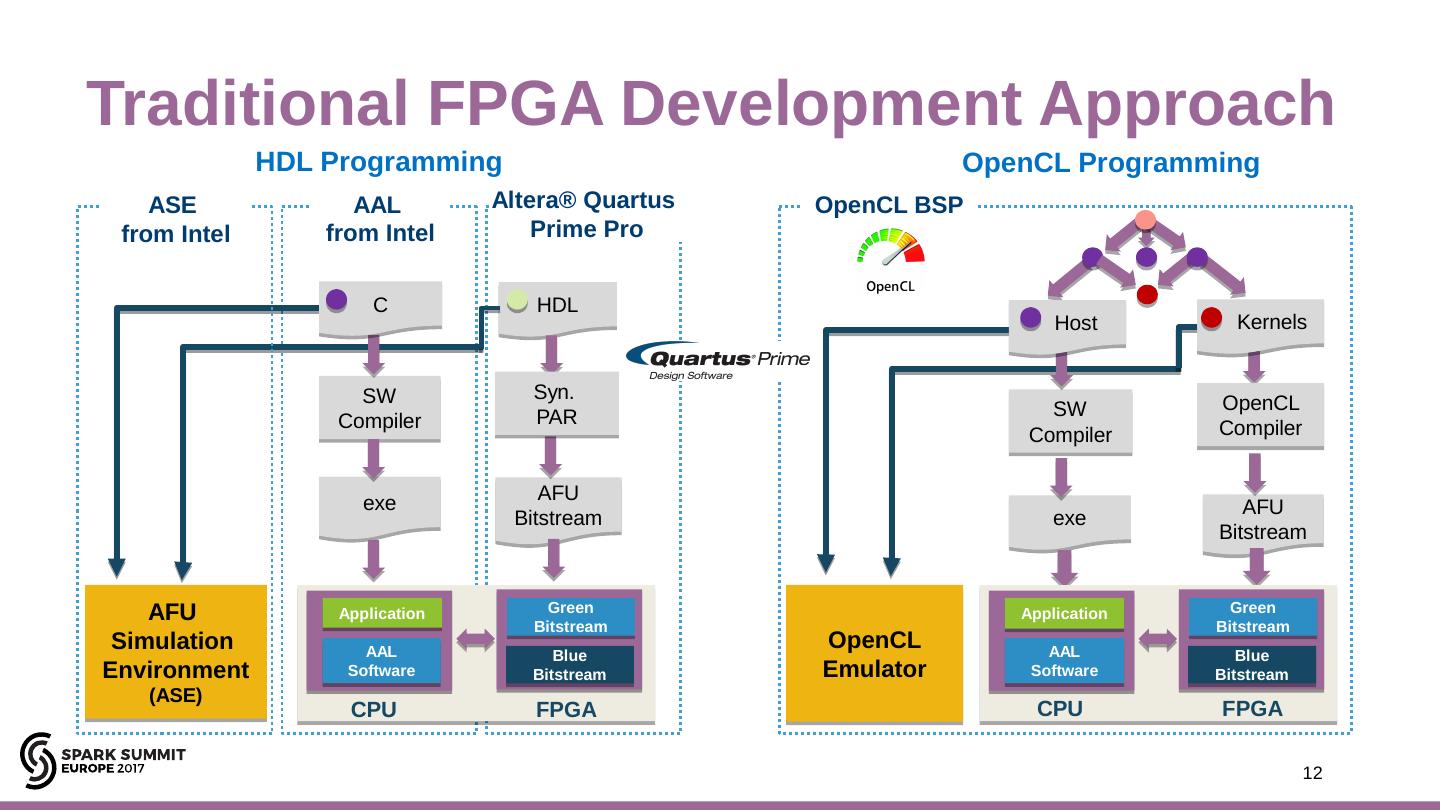
12 .Traditional FPGA Development Approach Kernels exe AFU Bitstream SW Compiler OpenCL Compiler HDL SW Compiler exe AFU Bitstream HDL Programming Syn. PAR AAL Software Blue Bitstream CPU FPGA Green Bitstream OpenCL Emulator Application Host AFU Simulation Environment (ASE) C OpenCL Programming ASE from Intel AAL from Intel Altera® Quartus Prime Pro OpenCL BSP AAL Software Blue Bitstream Green Bitstream Application CPU FPGA 12
13 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 13
14 .Workload Introduction 14 Intel Confidential The test case is from a customer and it utilizes SQL query to get the accounting summaries by USER_ID on a big table. The SQL query contains heavy expression evaluations. Accounting Big Table: TIME_ID MBUSER_ID OPER_TID SUM_TIMES CHARGE1 … 20140407 2700007679977 5B013363363w 3 0 … 20140407 2704012998344 31011G13iG0 48 57180 … 20140407 2704040114238 31Q11512ZT0 1 180 … 20140407 2700007012466 31011G13iG0 8 52320 … 20140407 2700001523491 1T0311G80610ydH10G00 2 0 … 20140407 2700000765632 310103015G0 1 30 … 20140407 2700007800325 4562210021 1 0 … … 1.6x10^8 Rows 38 Columns SQL queries to summarize customers consumption characteristics utilizing billing data. 5GB parquet format stored on HDFS, 160 Million rows.
15 .Workload code snippet Function Count Max 13 Sum 155 Substr 329 Case 133 Implicit Data type cast (String to Double) n/a Total 630 // Prepare val parquet = spark.read.parquet ("/ mnt / nvme / inputParquet /") parquet.createOrReplaceTempView (" inputTable ") // Query A very Long SQL statement, intensive use build-in functions :
16 .16 Intel Confidential SQL Query Physical Execution Plan Two stages and with a shuffle(cross the data in network), the map stage contains file scan, projection and partial aggregation while the reduce stage do further aggregation by merging the partial aggregation results. Stage 1 (Map) File Scan Read data from source. Projection Expression evaluation c onsumes most CPU cycles. Partial Aggregation Aggregate per partition. S huffle Stage 2 (Reduce) Full Aggregation. Tiny task, c onsumes minor CPU cycles.
17 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 17
18 .Benchmark H/W Setup 18 Intel Confidential In a single server for profiling and performance evaluation. MCP( Skylake -FPGA Multiple Chips Package) CPU Intel Xeon Skylake -P, 2Socketsx14Cores@2.8GHz, 56Hyper Threads FPGA 1xArria10 GX, 427,200ALM, 8MB RAM (10AX115U3F45E2SG) DMA Channels 1xUPI (80Gbps) Memory 384GB, DDR4@2133 MHz Disk 1xIntel SSD P3700, 1.6TB, SR:2800MB/s, SW:1900MB/s, RR:450K IOPS, RW:150K IOPS
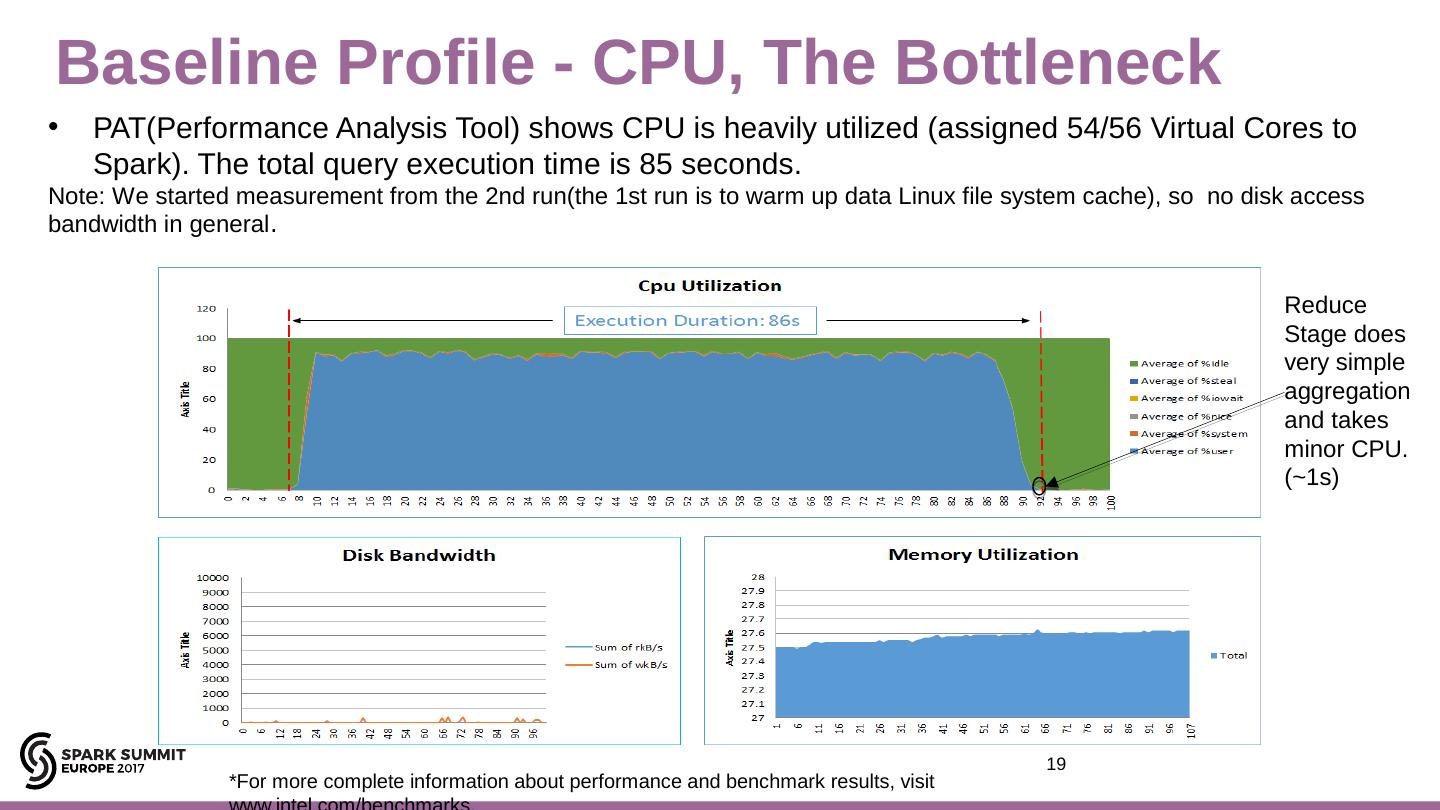
19 .19 Intel Confidential Baseline Profile - CPU, The Bottleneck PAT(Performance Analysis Tool) shows CPU is heavily utilized (assigned 54/56 Virtual Cores to Spark). The total query execution time is 85 seconds. Note: We started measurement from the 2nd run(the 1st run is to warm up data Linux file system cache), so no disk access bandwidth in general . Reduce Stage does very simple aggregation and takes minor CPU .(~1s) *For more complete information about performance and benchmark results, visit www.intel.com/benchmarks .
20 .20 Intel Confidential Baseline Profile - CPU, The Bottleneck, Contd. From the VisualVM map task’s CPU breakdown we can see the projection consumes 66.7% CPU. Projection takes 66.7% of CPU *For more complete information about performance and benchmark results, visit www.intel.com/benchmarks .
21 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 21
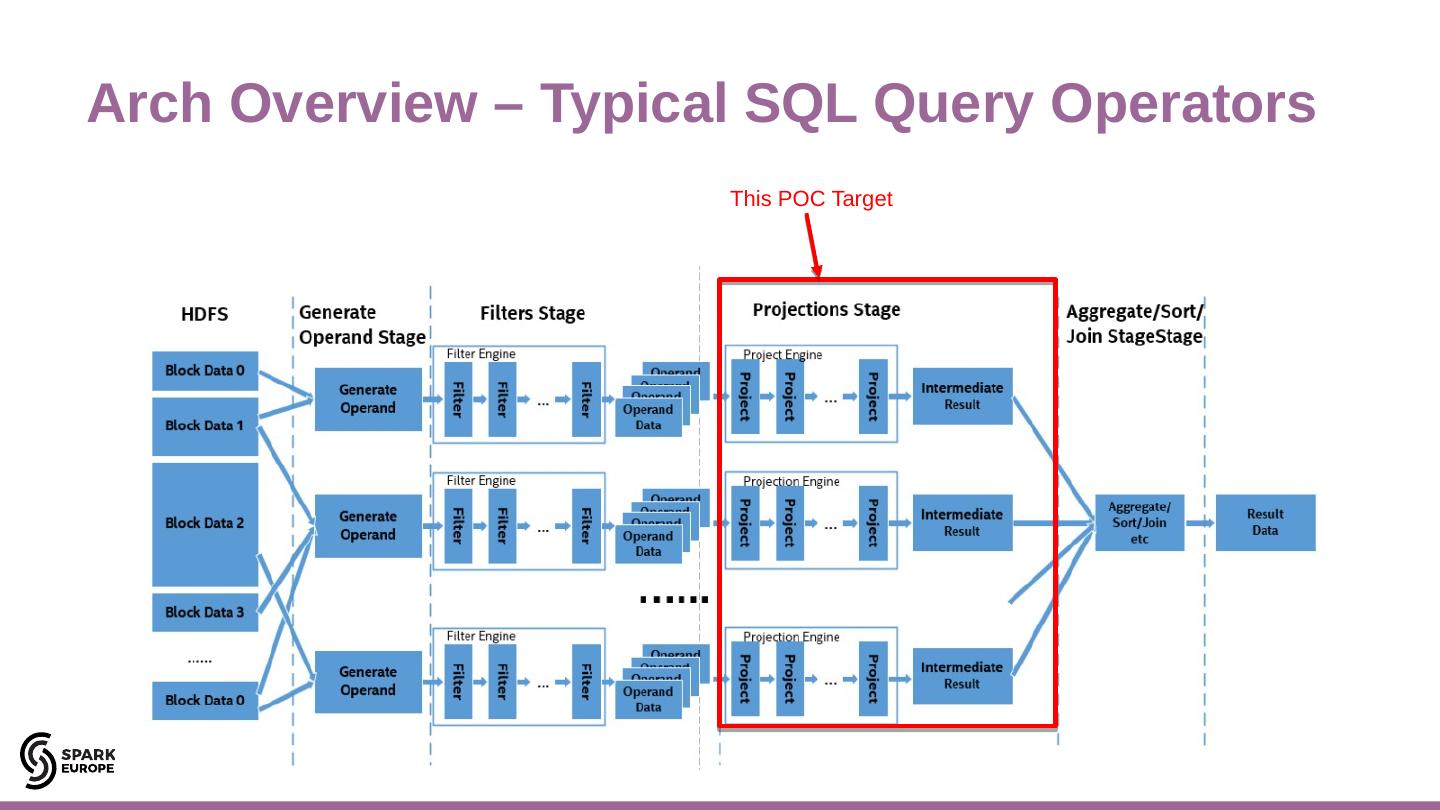
22 .Arch Overview – Typical SQL Query Operators 2121aa Intel Confidential This POC Target
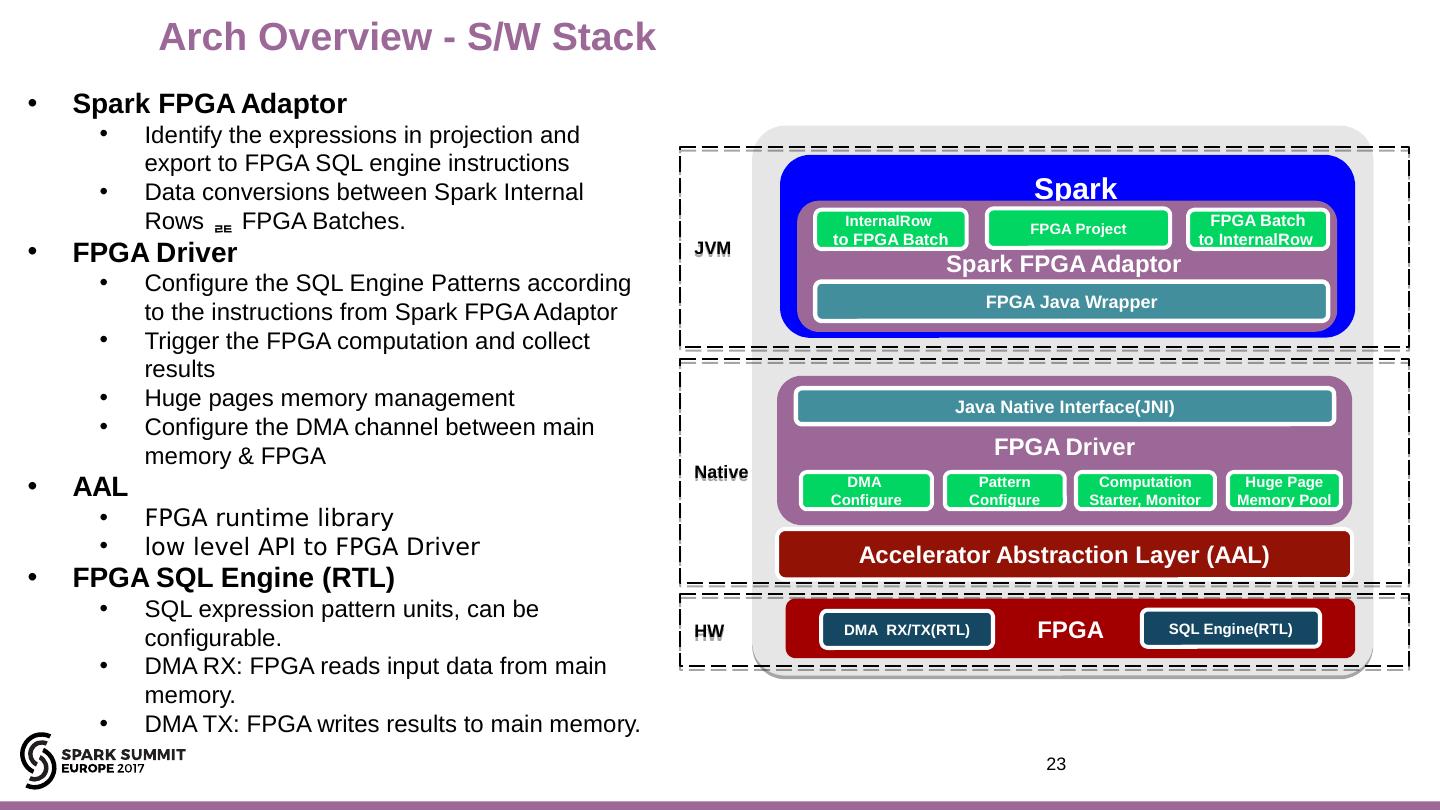
23 .JVM Spark Spark FPGA Adaptor Native HW InternalRow to FPGA Batch FPGA Batch to InternalRow FPGA Java Wrapper FPGA Driver FPGA FPGA Project Pattern Configure DMA Configure Huge Page Memory Pool Computation Starter, Monitor Java Native Interface(JNI) Accelerator Abstraction Layer (AAL) Spark FPGA Adaptor Identify the expressions in projection and export to FPGA SQL engine instructions D ata conversions between Spark Internal Rows FPGA Batches. FPGA Driver C onfigure the SQL Engine Patterns according to the instructions from Spark FPGA Adaptor Trigger the FPGA computation and collect results Huge pages memory management Configure the DMA channel between main memory & FPGA AAL FPGA runtime library low level API to FPGA Driver FPGA SQL Engine (RTL) SQL expression pattern units, can be configurable. DMA RX: FPGA reads input data from main memory. DMA TX: FPGA writes results to main memory. 23 Arch Overview - S/W Stack DMA RX/TX(RTL) SQL Engine(RTL)
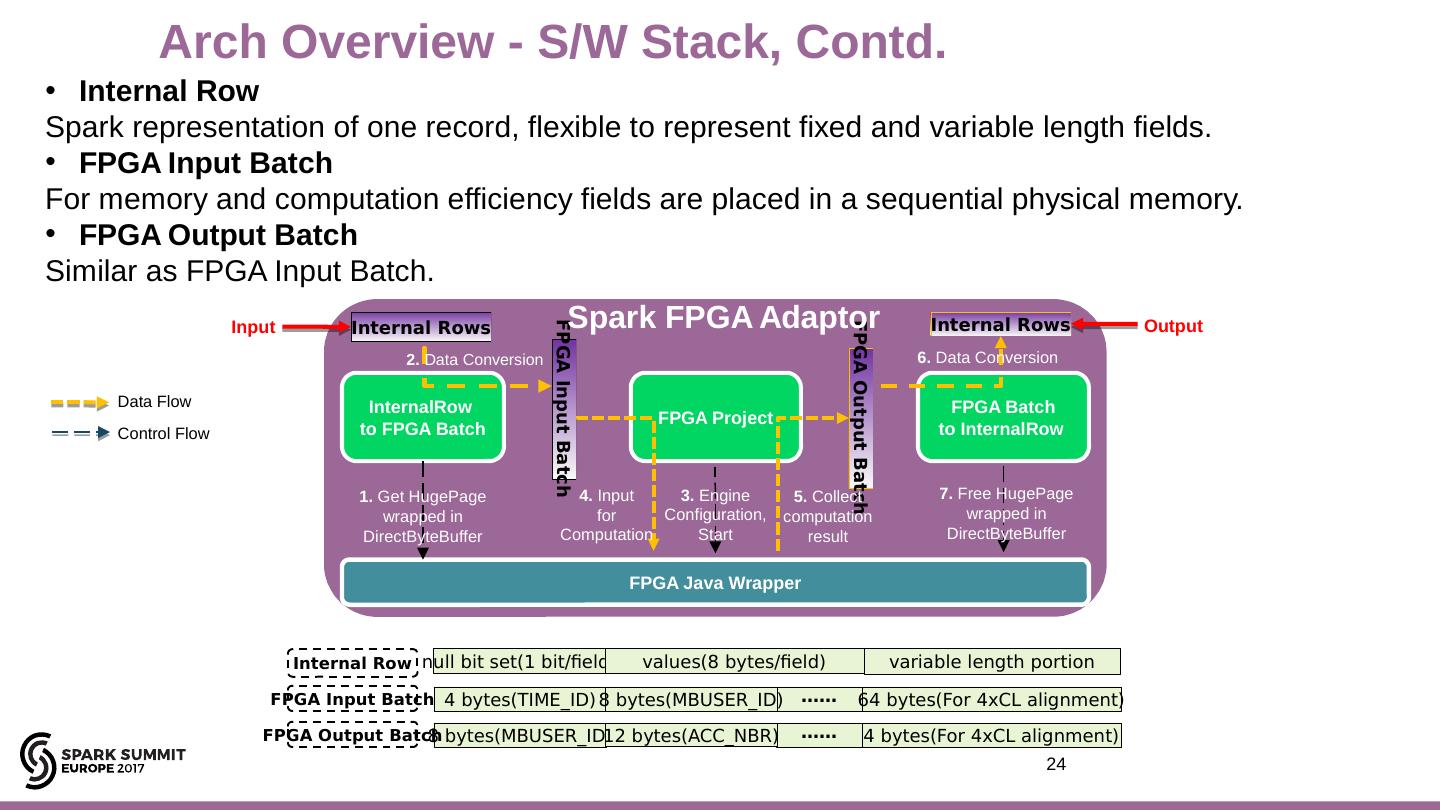
24 .null bit set(1 bit/field) values(8 bytes/field) variable length portion 4 bytes(TIME_ID) …… 64 bytes(For 4xCL alignment) …… 4 bytes(For 4xCL alignment) 8 bytes(MBUSER_ID) 8 bytes(MBUSER_ID) FPGA Input Batch FPGA Output Batch Internal Row InternalRow to FPGA Batch FPGA Batch to InternalRow FPGA Java Wrapper FPGA Project 1. Get HugePage wrapped in DirectByteBuffer Internal Rows FPGA Input Batch FPGA Output Batch Internal Rows 4. Input f or Computation 5. Collect computation result 2. Data Conversion 6. Data Conversion 7. Free HugePage wrapped in DirectByteBuffer Internal Row Spark representation of one record, flexible to represent fixed and variable length fields. FPGA Input Batch For memory and computation efficiency fields are placed in a sequential physical memory. FPGA Output Batch Similar as FPGA Input Batch. 3. Engine Configuration, Start 24 Arch Overview - S/W Stack, Contd. 12 bytes(ACC_NBR) Input Output Data Flow Control Flow Spark FPGA Adaptor
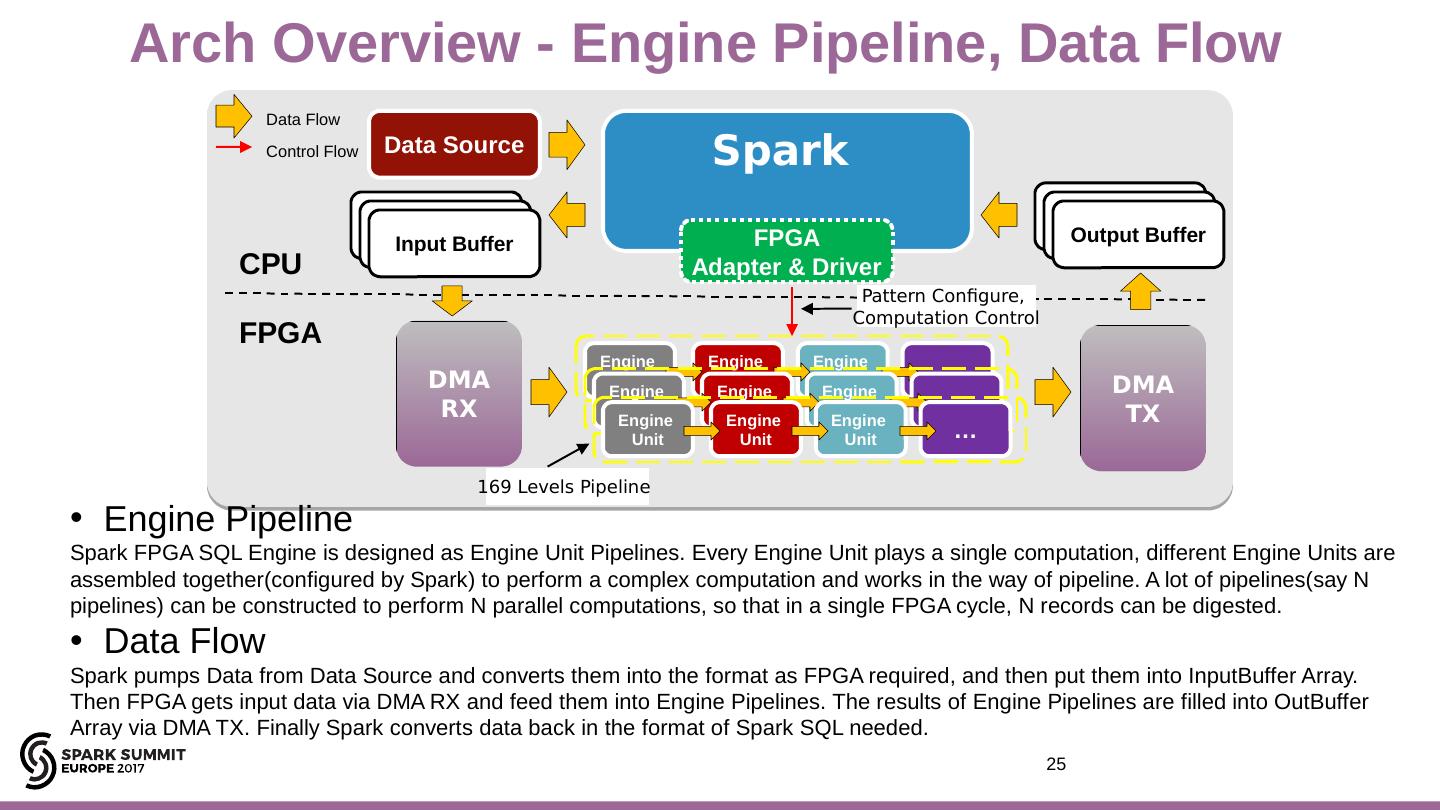
25 .Spark Engine Unit Engine Unit Engine Unit … DMA RX DMA TX Output Buffer Input Buffer CPU FPGA FPGA Adapter & Driver Data Source Input Buffer Input Buffer Output Buffer Output Buffer Engine Unit Engine Unit Engine Unit … Engine Unit Engine Unit Engine Unit … 169 Levels Pipeline Data Flow Control Flow Pattern Configure, Computation Control 25 Arch Overview - Engine Pipeline, Data Flow Engine Pipeline Spark FPGA SQL Engine is designed as Engine Unit Pipelines. Every Engine Unit plays a single computation, different Engine Units are assembled together(configured by Spark) to perform a complex computation and works in the way of pipeline. A lot of pipelines(say N pipelines) can be constructed to perform N parallel computations, so that in a single FPGA cycle, N records can be digested. Data Flow Spark pumps Data from Data Source and converts them into the format as FPGA required, and then put them into InputBuffer Array. Then FPGA gets input data via DMA RX and feed them into Engine Pipelines. The results of Engine Pipelines are filled into OutBuffer Array via DMA TX. Finally Spark converts data back in the format of Spark SQL needed.
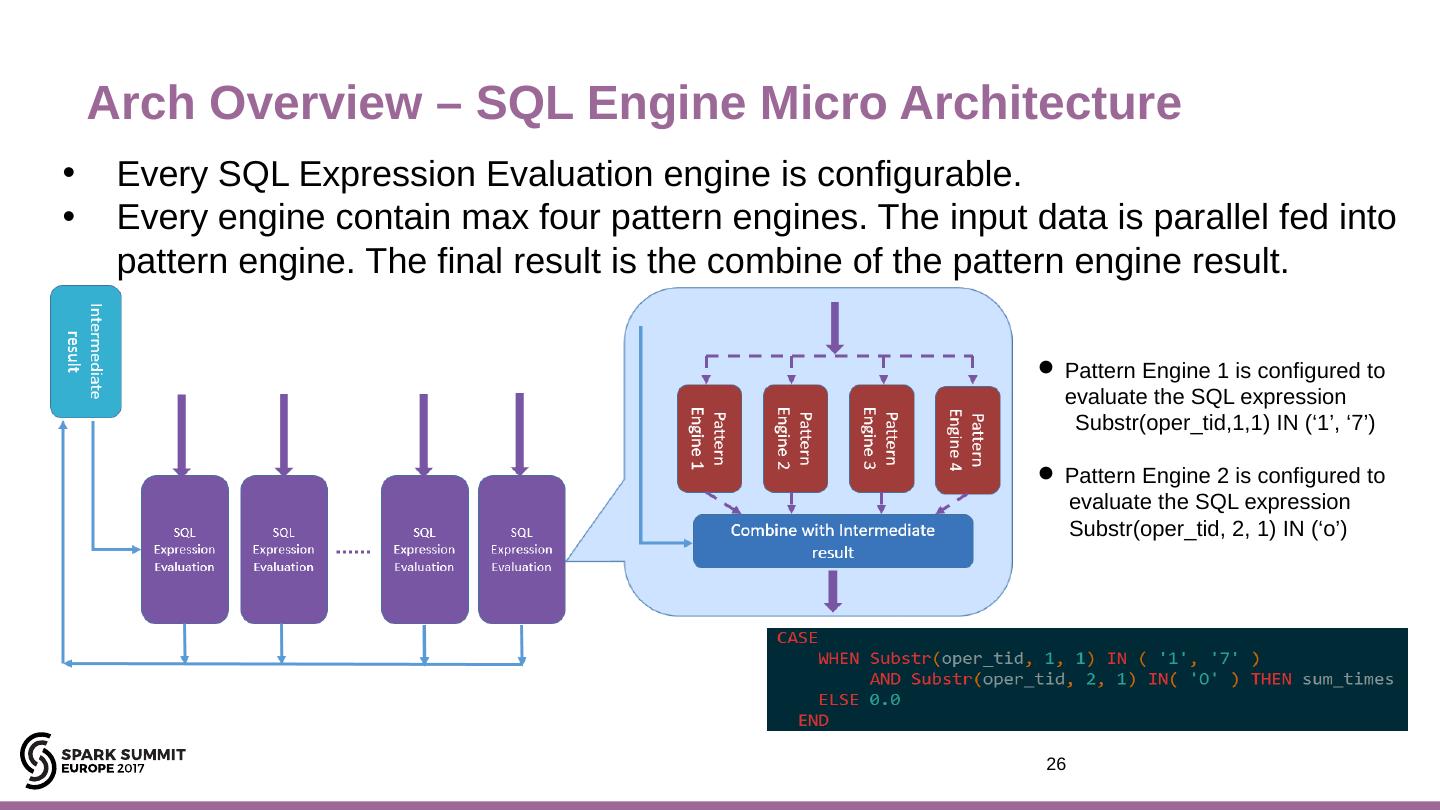
26 .Arch Overview – SQL Engine Micro A rchitecture 26 Every SQL Expression Evaluation engine is configurable. Every engine contain max four pattern engines. The input data is parallel fed into pattern engine. The final result is the combine of the pattern engine result. Pattern Engine 1 is configured to evaluate the SQL expression Substr (oper_tid,1,1) IN (‘1’, ‘7’) Pattern Engine 2 is configured to evaluate the SQL expression Substr ( oper_tid , 2, 1) IN (‘o’)
27 .Outline What’s an FPGA Intel FPGA Platform Workload & Benchmark Introduction Baseline Profile - Hotspot Analysis FPGA Acceleration Arch Overview Performance Comparison Future Works 27
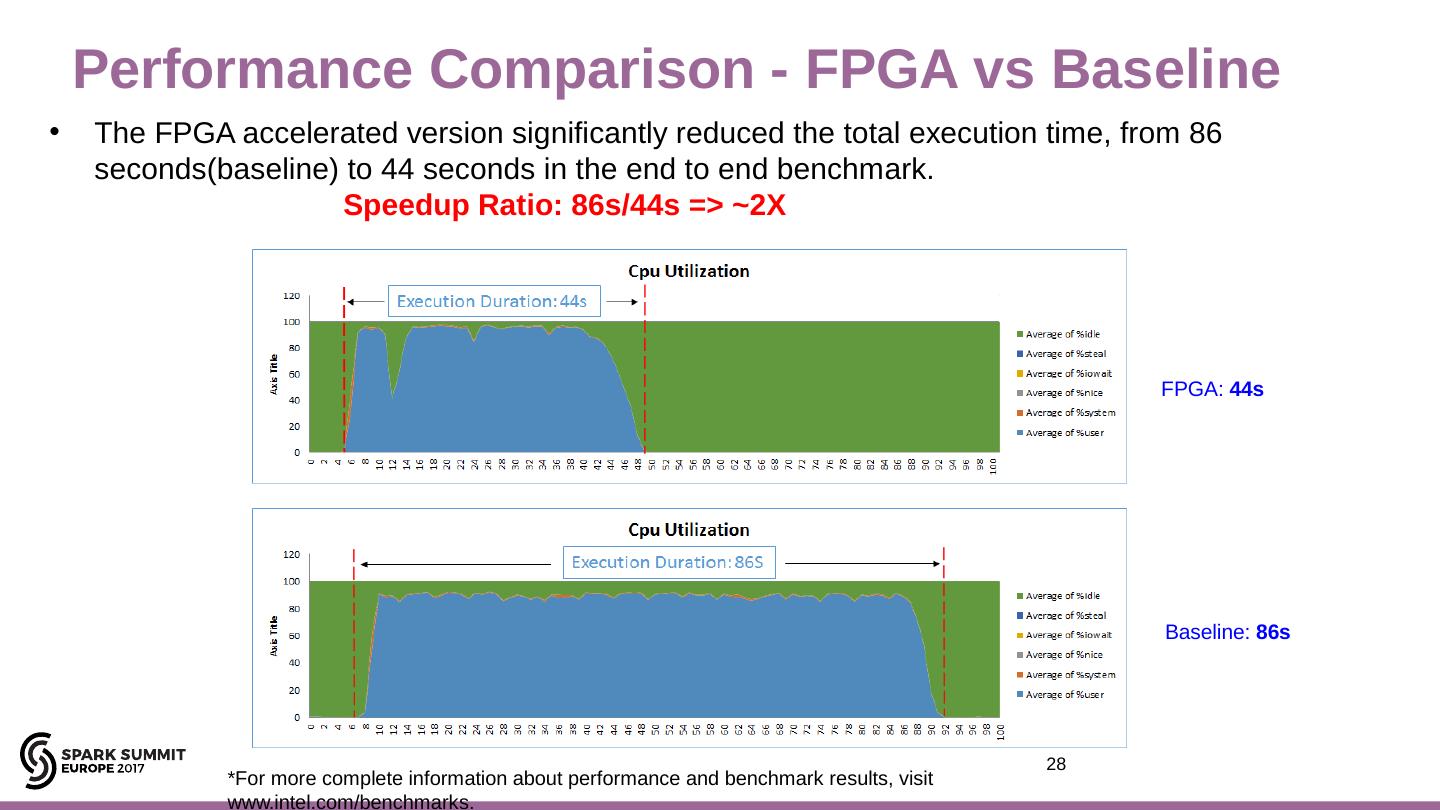
28 .The FPGA accelerated version significantly reduced the total execution time, from 86 seconds(baseline ) to 44 seconds in the end to end benchmark. Speedup Ratio: 86s/44s => ~2X FPGA: 44s Baseline: 86s Performance Comparison - FPGA vs Baseline 28 *For more complete information about performance and benchmark results, visit www.intel.com/benchmarks .
29 .The FPGA accelerated version reduced the CPU time in expression evaluation, from 66.7%(baseline) to 6.6-% in Map stage. Projection with FPGA, less than 6.6% Projection in Baseline, 66.7% 29 Performance Comparison - FPGA vs Baseline, Contd. *For more complete information about performance and benchmark results, visit www.intel.com/benchmarks .
3秒后跳转登录页面
去登陆

