





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark Performance Tuning_rev4
This is a slide to share our experience for Spark performance tuning.
展开查看详情
1 .Spark Performance Tuning Weiting Chen <weiting.chen@intel.com>
2 . legal notices and disclaimers Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as HiBench, TPC-DS, and TPCx-BB, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks. Configurations: 1. Intel Xeon E5-2650 V3(Haswell), 256GB RAM, 480GB SSD for OS Disk, 1TB SATA HDD x8, 1.2TB Intel® s3520 SSD x8, 1.6TB Intel® p3600 SSD x3. Hadoop 2.7.3, Spark 2.1.0, JDK 1.8.0_112 2. Intel Xeon E5-2680 V4(Broadwell), 256GB RAM, 480GB SSD for OS Disk, 1TB SATA HDD x8, 1.2TB Intel® s3520 SSD x8, 1.6TB Intel® p3600 SSD x3. Hadoop 2.7.3, Spark 2.1.0, JDK 1.8.0_112 3. Intel Xeon E5-2650 V3(Haswell), 256GB RAM, 480GB SSD for OS Disk, 1TB SATA HDD x8, 1.2TB Intel® s3520 SSD x8, 1.6TB Intel® p3600 SSD x3. Hadoop 2.7.3, Spark 2.1.0, JDK 1.8.0_112 4. Intel® E5-2699 v4, 512GB RAM, 400GB Intel® s3700 for OS Disk, 2TB Intel® p3700 x4, 10GbE Intel X540-AT2, 40GbE Intel® XL710, Hadoop 2.7.3, Spark 2.1.0, JDK 1.8.0_111 5. Intel® Platinum 8160, 768GB RAM, 400GB Intel® s3700 for OS Disk, 2TB Intel® p3700 x4, 10GbE Intel X540-AT2, 40GbE Intel® XL710, Hadoop 2.7.3, Spark 2.1.0, JDK 1.8.0_111 6. c3.xlarge/c3.4xlarge in AWS EMR: Intel Xeon E5-2680 v2(Ivy Bridge) 7. m4.xlarge/m4.4xlarge in AWS EMR: Intel Xeon E5-2676 v3(Haswell) 8. r3.xlarge/r3.4xlarge in AWS EMR: Intel Xeon E5-2670 v2(Ivy Bridge) 2
3 . LEGAL NOTICES and disclaimers Intel, the Intel logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel technologies' features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Cost reduction scenarios described are intended as examples of how a given Intel- based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction. "For use only by product developers, software developers, and system integrators. For evaluation only; not FCC approved for resale." "This device has not been authorized as required by the rules of the Federal Communications Commission. This device is not, and may not be, offered for sale or lease, or sold or leased, until authorization is obtained." 3
4 . AGENDA • BACKGROUND • PERFORMANCE EVALUATION UTILITIES • PERFORMANCE FACTORS & RESULTS • SUMMARY 4
5 .BACKGROUND 5
6 . ABOUT SPARK Spark User App Job Server Visualization … SQL / DF / ML / Structured Streaming MLlib Spark* GraphX (Machine Streaming (graphs) Catalyst Learning) Core & RDD API Google* Stand Alone Yarn* Mesos* Kubernetes* OpenStack* Cloud AWS* Platform Hive* Cassandra* Redis* … Parquet ORC CSV HBase* Tables *Other names and brands may be claimed as the property of others. 6
7 . performance factors How to run Spark* Spark supports to run on Standalone, Yarn*, Mesos* as well as Kubernetes*. Where to run Spark applications Run your Spark application on private cloud or public cloud including Bare Metal, OpenStack*, AWS*, GCP*, …etc. What to run on Spark What kind of the workloads are going to run on Spark like CPU-intensive or IO-intensive. Hardware Components The hardware components use for your Spark platform including CPU, Memory, Storage, and Network. Optimize Spark/Hadoop* Parameters Some parameters like Core#, Memory, Executor#, Task# may impact huge for performance. *Other names and brands may be claimed as the property of others. 7
8 .PERFORMANCE EVALUATION UTILITIES 8
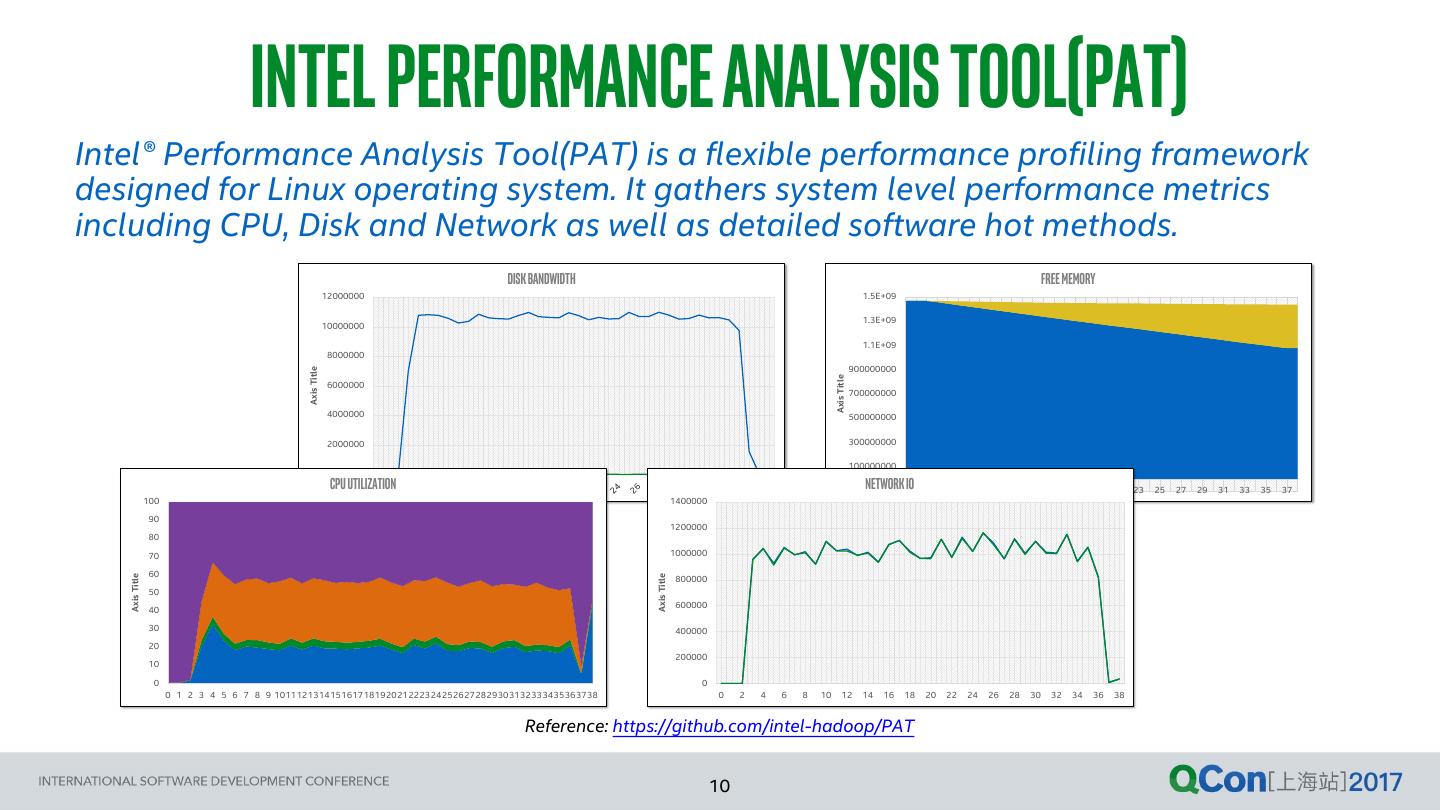
9 . BENCHMARKing your spark applications 1. FIO* Fio spawns a number of threads or processes doing a particular type of I/O action as specified by the user. Reference: https://github.com/axboe/fio 2. iPerf* A tool for active measurements of the maximum achievable bandwidth on IP networks. It supports tuning of various paramters related to timing, buffers and protocols(TCP, UDP, SCTP with IPv4 and IPv6). Reference: https://iperf.fr/ 3. Intel® Performance Analysis Tool(PAT) PAT is a flexible performance profiling framework designed for Linux operating system. It gathers system level performance metrics including CPU, Disk, and Network as well as detailed software hot methods. Reference: https://github.com/intel-hadoop/PAT *Other names and brands may be claimed as the property of others. 9
10 . INTEL PERFORMANCE ANALYSIS TOOL(PAT) Intel® Performance Analysis Tool(PAT) is a flexible performance profiling framework designed for Linux operating system. It gathers system level performance metrics including CPU, Disk and Network as well as detailed software hot methods. Disk Bandwidth Free Memory 12000000 1.5E+09 1.3E+09 10000000 1.1E+09 8000000 900000000 Axis Title Axis Title 6000000 700000000 4000000 500000000 2000000 300000000 100000000 0 Cpu Utilization Network -1E+08 1IO 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 100 1400000 90 1200000 80 70 1000000 60 800000 Axis Title Axis Title 50 600000 40 30 400000 20 200000 10 0 0 0 1 2 3 4 5 6 7 8 9 1011121314151617181920212223242526272829303132333435363738 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 Reference: https://github.com/intel-hadoop/PAT FOR MORE INFORMATION: https://github.com/intel-hadoop/PAT 10
11 . BENCHMARKing your spark applications(cont.) 4. HiBench* A big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. Reference: https://github.com/intel-hadoop/HiBench 5. TPC-DS* A decision support benchmark that models several generally applicable aspects of a decision support system, including queries and data maintenance. Reference: http://www.tpc.org/tpcds/ 6. TPCx-BB* A big data benchmark measures the performance of Hadoop-based Big Data systems. It measures the performance of both hardware and software components by executing 30 frequently performed analytical queries in the context of retailers with physical and online store presence. Reference: http://www.tpc.org/tpcx-bb/ *Other names and brands may be claimed as the property of others. 11
12 .performance FACTORS - SPARK VERSION 12
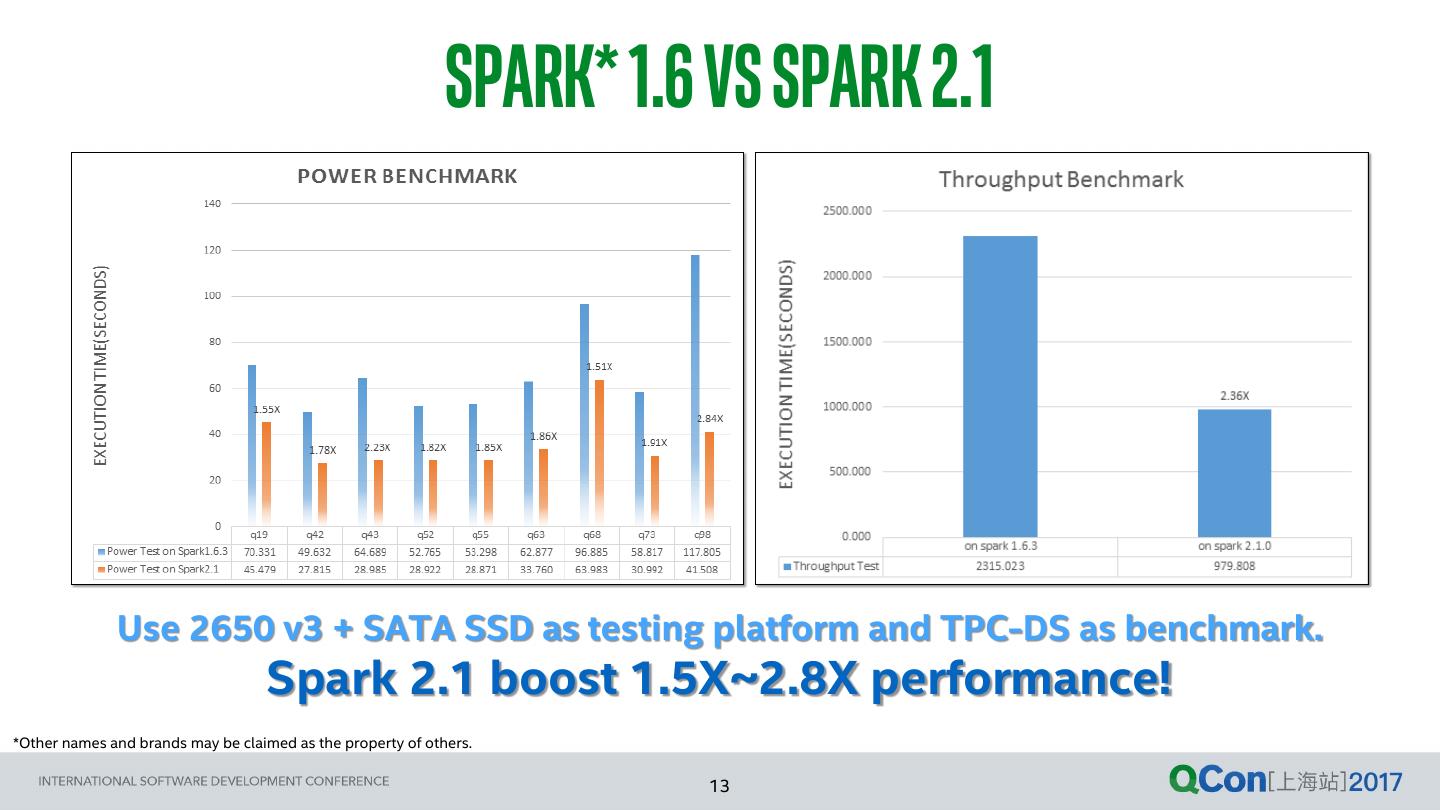
13 . SPARK* 1.6 vs SPARK 2.1 Use 2650 v3 + SATA SSD as testing platform and TPC-DS as benchmark. Spark 2.1 boost 1.5X~2.8X performance! *Other names and brands may be claimed as the property of others. 13
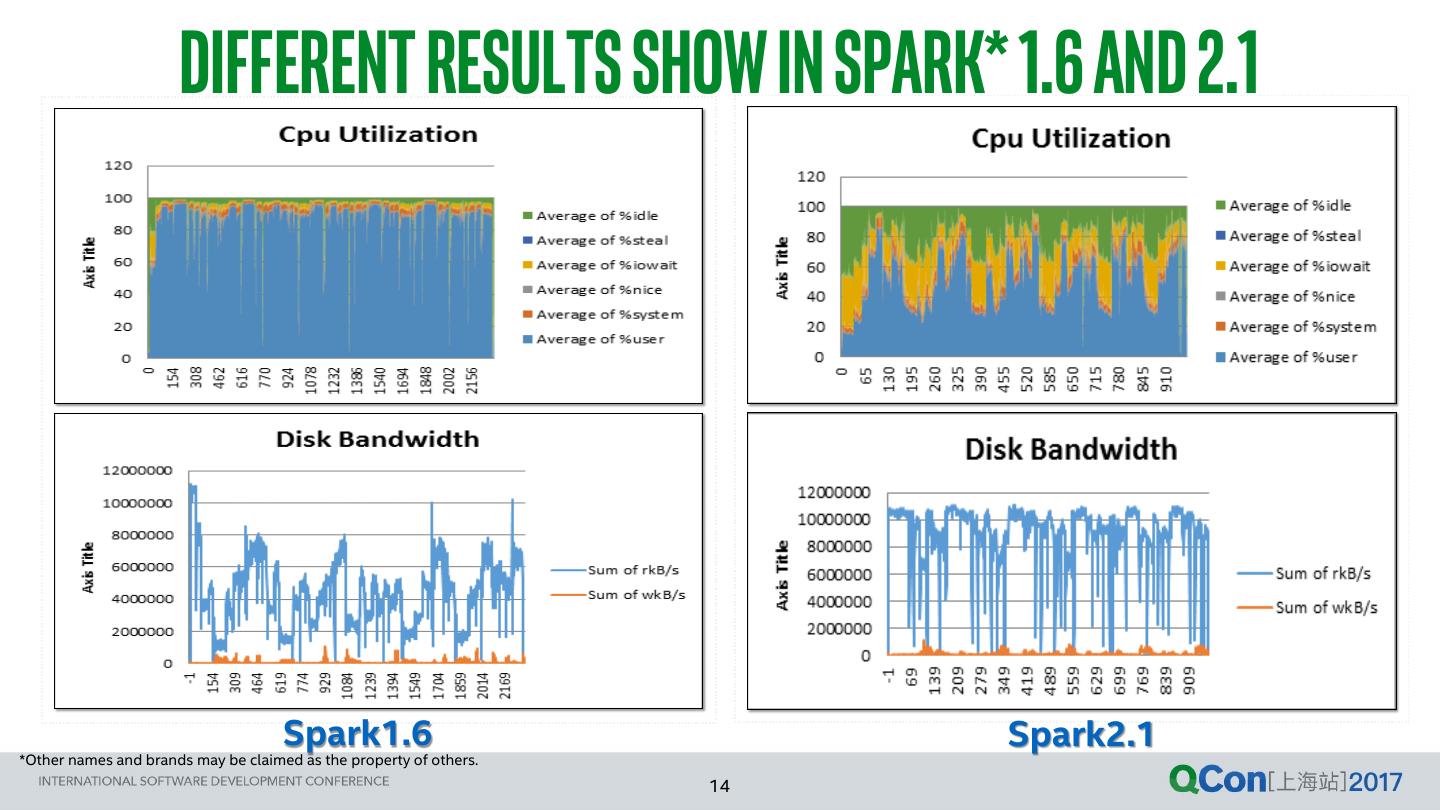
14 . DIFFERENT RESULTS SHOW in SPARK* 1.6 and 2.1 Spark1.6 Spark2.1 *Other names and brands may be claimed as the property of others. 14
15 . WHOLE STAGE CODEGEN impact performance huge “WholeStage Codegen” provides 3X performance boost! Notes: WholeStage Codegen can only support for Spark* SQL Reference: https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html *Other names and brands may be claimed as the property of others. 15
16 . WHOLE STAGE CODE GENERATION SPARK*-12795: This feature fuses multiple operators together into a single Java function that is aimed at improving execution performance. It collapses a query into a single optimized function that eliminates virtual function calls and leverages CPU registers for intermediate data. *Other names and brands may be claimed as the property of others. 16
17 .performance FACTORS - SPARK/HADOOP PARAMETERS 17
18 . Spark*/Hadoop* Related Configuration Node Manager About Server Physical Cores(Cores by flavor size), Physical Memory(Memory by flavor size) Executor Executor ex: In AWS EMR,c3.4xlarge has 16 cores and 30GB About YARN* T T T T T T yarn.nodemanager.resource.cpu-vcores = Phy. cores T T T T T T yarn.nodemanager.resource.memory-mb = Phy. memory * 0.75(AWS Default) ex: In AWS EMR, c3.4xlarge has 16 vcores and 30*0.75 = 22.5GB memory for node manager. About Executors Server spark.executor.instances = 2(default) spark.executor.cores = 1(default), usually use 4-6 for better performance spark.executor.memory = 4GB(default) spark.yarn.executor.memoryOverhead = spark.executor.memory*0.1(default) The number of executors is “total cores/executor cores” or “total memory/(executor memory+memoryoverhead)” HDFS HDFS HDFS ex: For c3.4xlarge, we set spark.executor.instances = 4 and for every executor it has cores = 4 and memory = 4GB. About Tasks About HDFS spark.cores.max = max. amount of CPU cores(default) spark.default.parallelism = depend on workloads spark.task.cpus = 1(default) dfs.blocksize = 128MB(default) The number of concurrent task is spark.cores.max/spark.task.cpus *Other names and brands may be claimed as the property of others. ex: For c3.4xlarge, it has 16 concurrent tasks running at the same time
19 . ABOUT EXECUTORS, CORES, and MEMORY In Terasort, the number of core per executor is better to set 4~6 cores. The reason is for higher HDFS throughput support. In Kmeans, there is no obvious benefits. https://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/ *Other names and brands may be claimed as the property of others. 19
20 .performance FACTORS - cpu & platform 20
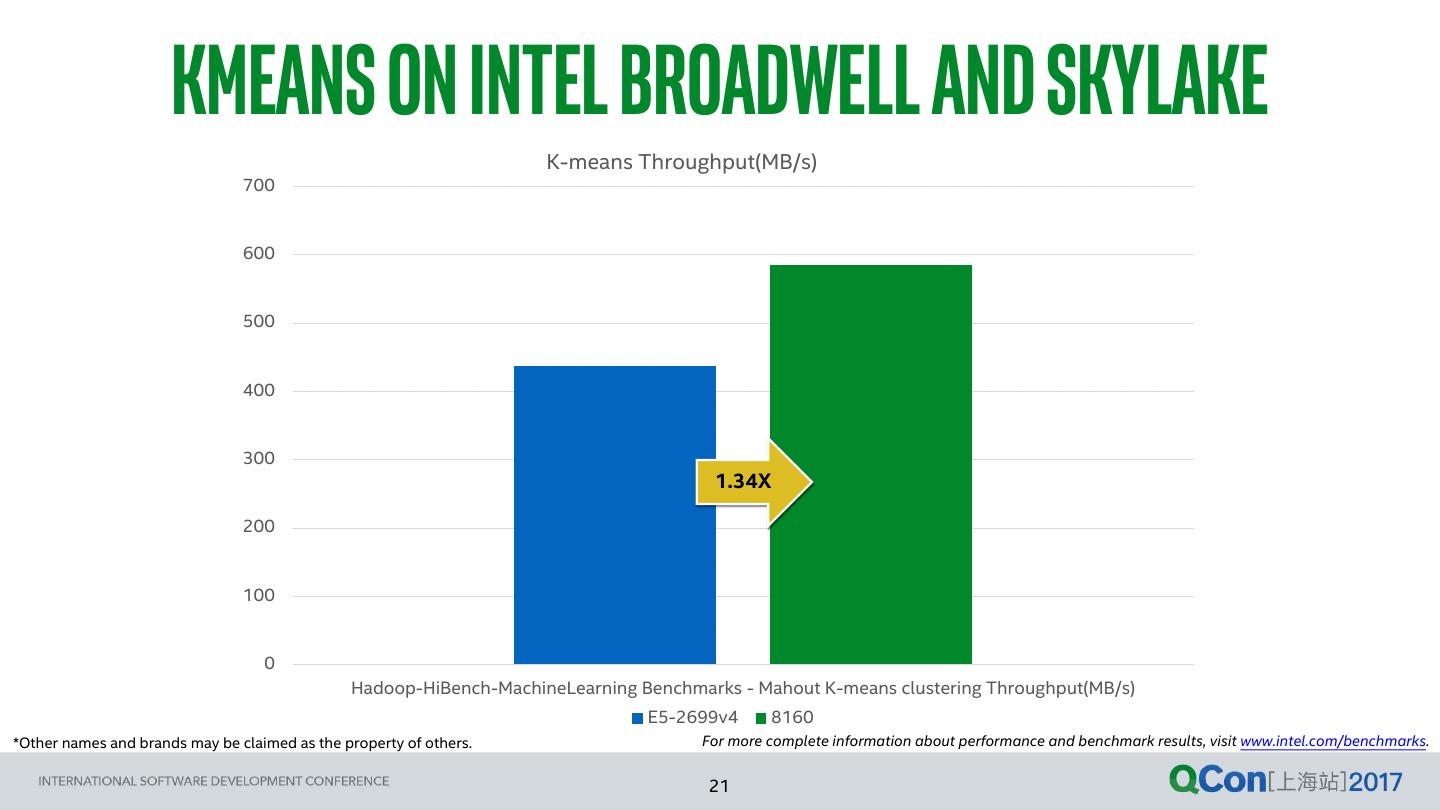
21 . kmeans on intel Broadwell and skylake K-means Throughput(MB/s) 700 600 500 400 300 1.34X 200 100 0 Hadoop-HiBench-MachineLearning Benchmarks - Mahout K-means clustering Throughput(MB/s) E5-2699v4 8160 *Other names and brands may be claimed as the property of others. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 21
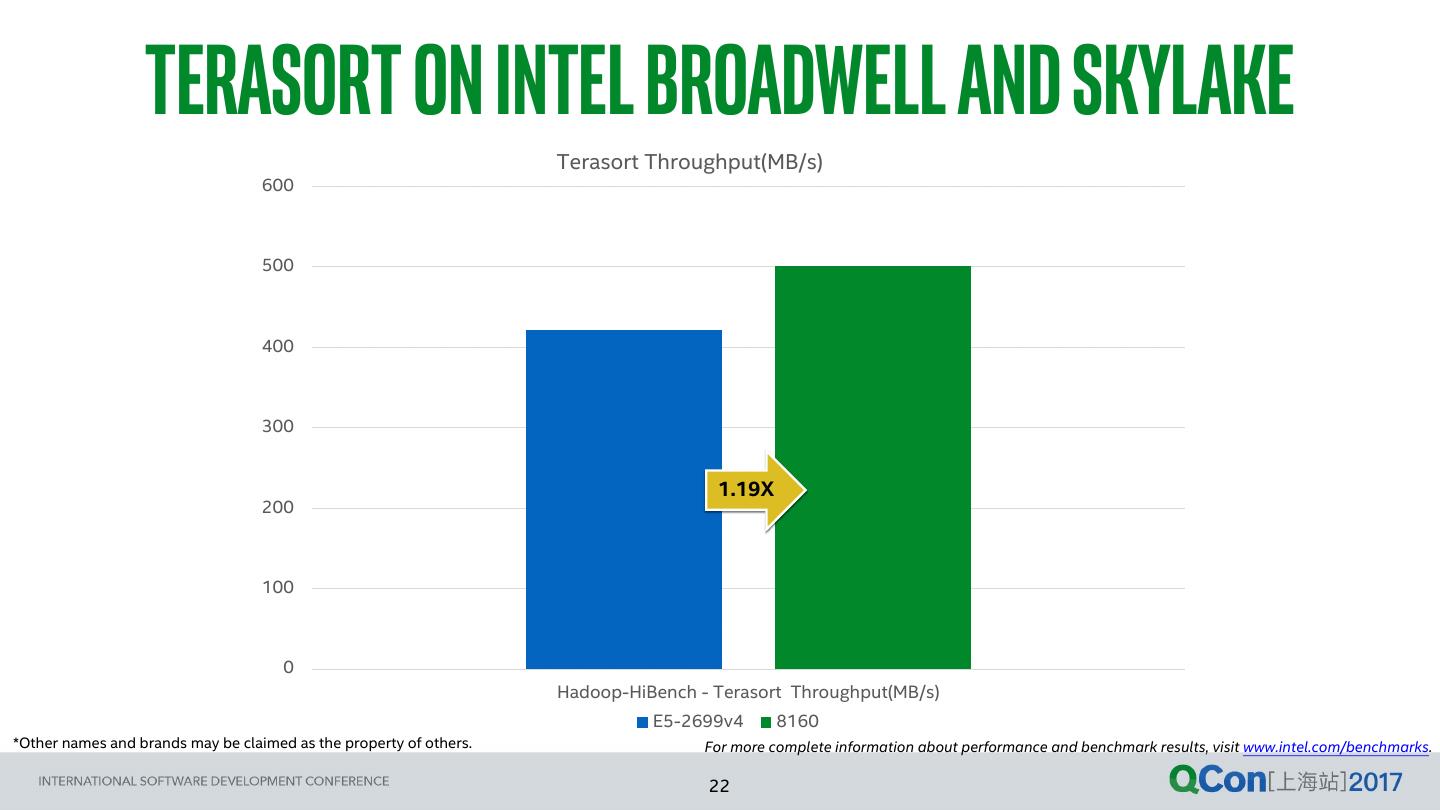
22 . terasort on intel Broadwell and skylake Terasort Throughput(MB/s) 600 500 400 300 1.19X 200 100 0 Hadoop-HiBench - Terasort Throughput(MB/s) E5-2699v4 8160 *Other names and brands may be claimed as the property of others. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. 22
23 .performance FACTORS - storage disk TYPES 23
24 . 2500 storage impact - tpc-ds* Throughput Benchmark 1X (Lower is better) 2000 Intel® SATA SSD s3520*8 provide 2.66X performance boost. Intel® PCIe p3600*3 provide 2.83X Execution Time(second) 1500 performance boost. 1000 2.66X 2.83X 500 HDD to SATA SSD SATA SSD to PCIe SSD 0 2650v3+HDD*8+256Gmem 2650v3+SSD(s3520)*8+256Gmem 2650v3+PCIE(p3600)*3+256Gmem Throughput Test 2301.44 866.029 812.13 *Other names and brands may be claimed as the property of others. 24
25 . storage impact - HIBENCH* terasort Terasort HiBench (HSW 2650v3) 8000 7000 1X Intel® SATA SSD s3520*8 provide 2.75X 6000 performance boost. Execution Time(seconds) 5000 Intel® PCIe p3600*3 provide 3.81X performance boost. 4000 3000 2.75X 2000 3.81X 1000 HDD to SATA SSD SATA SSD to PCIe SSD 0 HSW2650 +HDD HSW2650 +S3520 HSW2650v3 +P3600 3TB 6811.931 2473.165 1787.602 *Other names and brands may be claimed as the property of others. 25
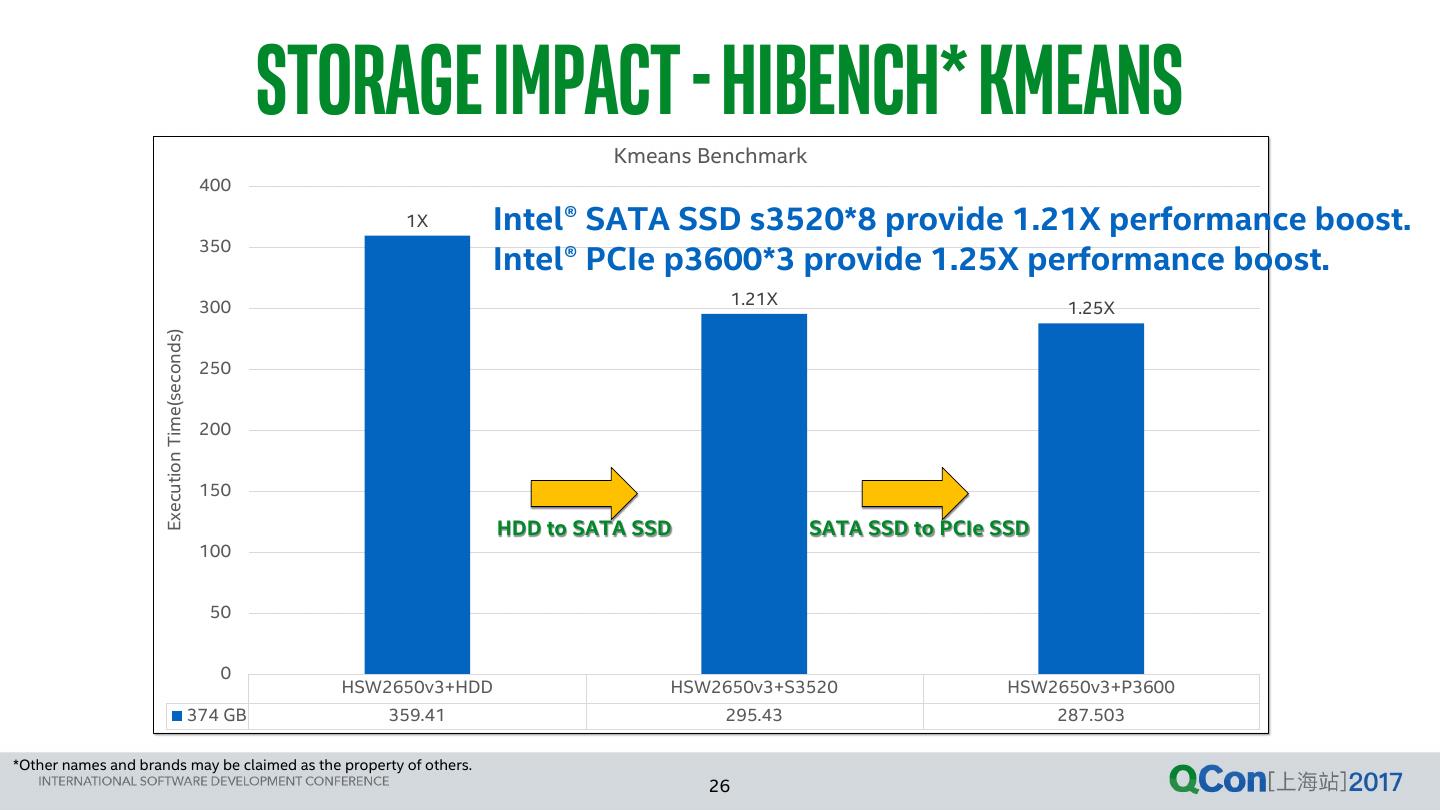
26 . storage impact - HIBENCH* Kmeans Kmeans Benchmark 400 1X Intel® SATA SSD s3520*8 provide 1.21X performance boost. 350 Intel® PCIe p3600*3 provide 1.25X performance boost. 300 1.21X 1.25X Execution Time(seconds) 250 200 150 HDD to SATA SSD SATA SSD to PCIe SSD 100 50 0 HSW2650v3+HDD HSW2650v3+S3520 HSW2650v3+P3600 374 GB 359.41 295.43 287.503 *Other names and brands may be claimed as the property of others. 26
27 . performance FACTORs - aws emr* *Other names and brands may be claimed as the property of others. 27
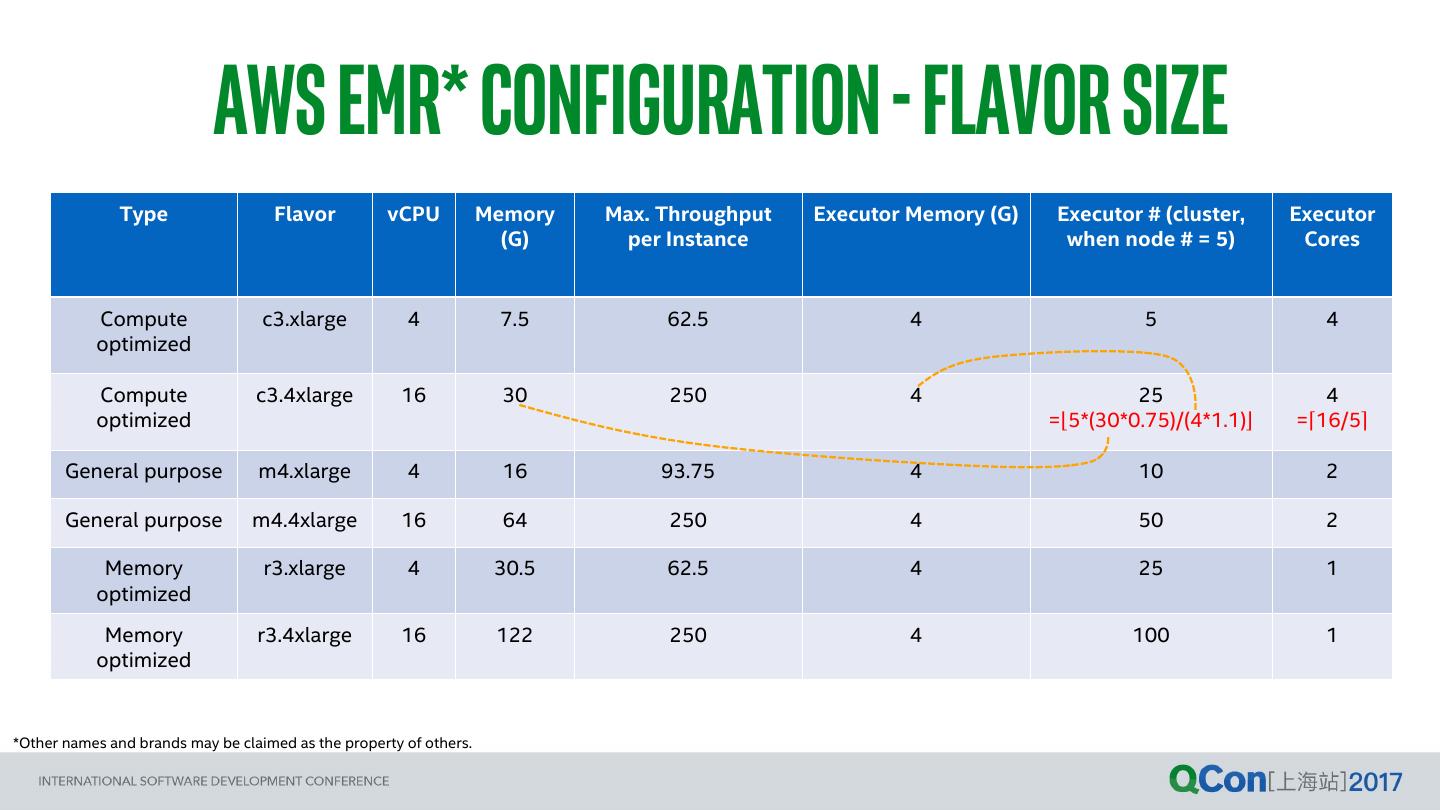
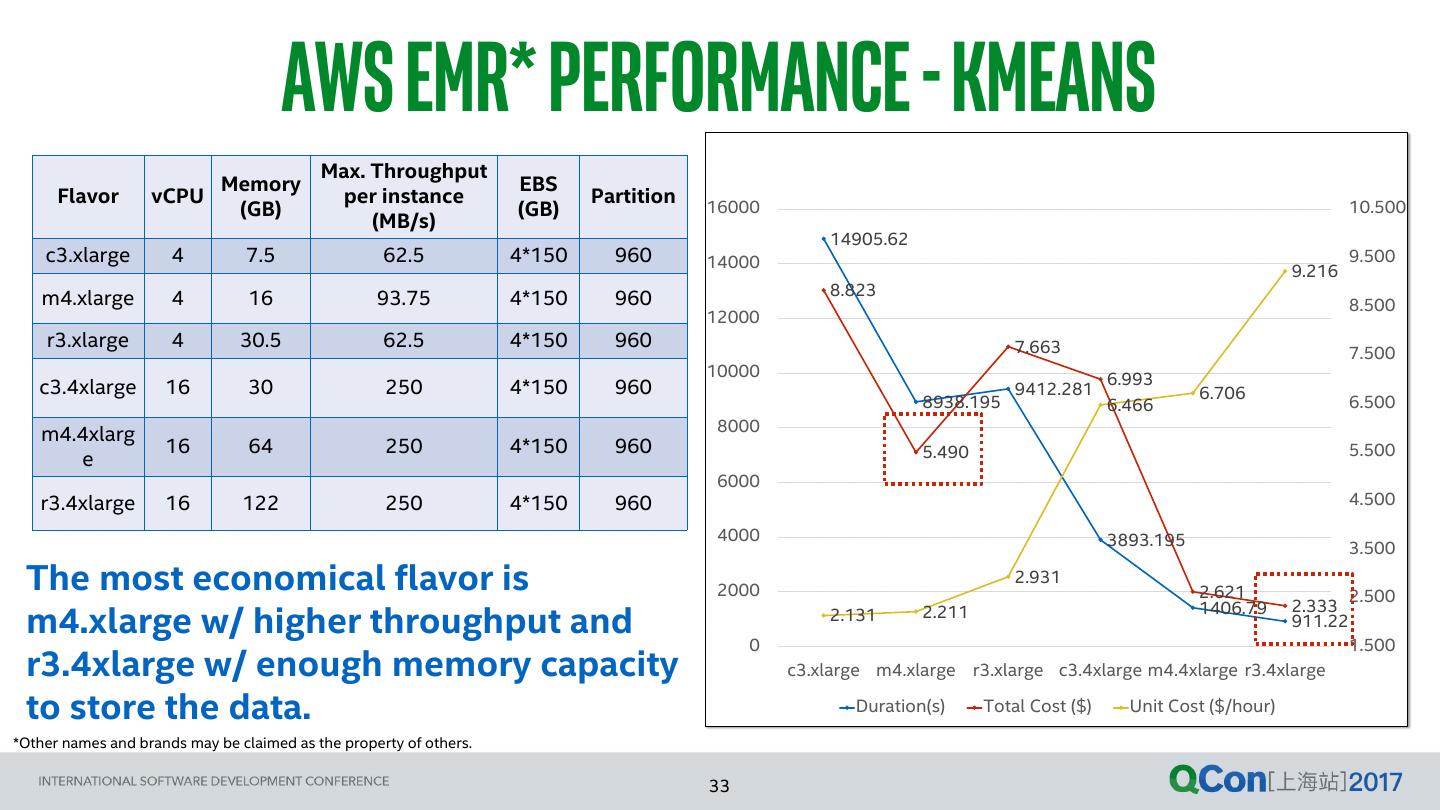
28 . AWS EMR* Configuration - Flavor Size Type Flavor vCPU Memory Max. Throughput Executor Memory (G) Executor # (cluster, Executor (G) per Instance when node # = 5) Cores Compute c3.xlarge 4 7.5 62.5 4 5 4 optimized Compute c3.4xlarge 16 30 250 4 25 4 optimized =⌊5*(30*0.75)/(4*1.1)⌋ =⌈16/5⌉ General purpose m4.xlarge 4 16 93.75 4 10 2 General purpose m4.4xlarge 16 64 250 4 50 2 Memory r3.xlarge 4 30.5 62.5 4 25 1 optimized Memory r3.4xlarge 16 122 250 4 100 1 optimized *Other names and brands may be claimed as the property of others.
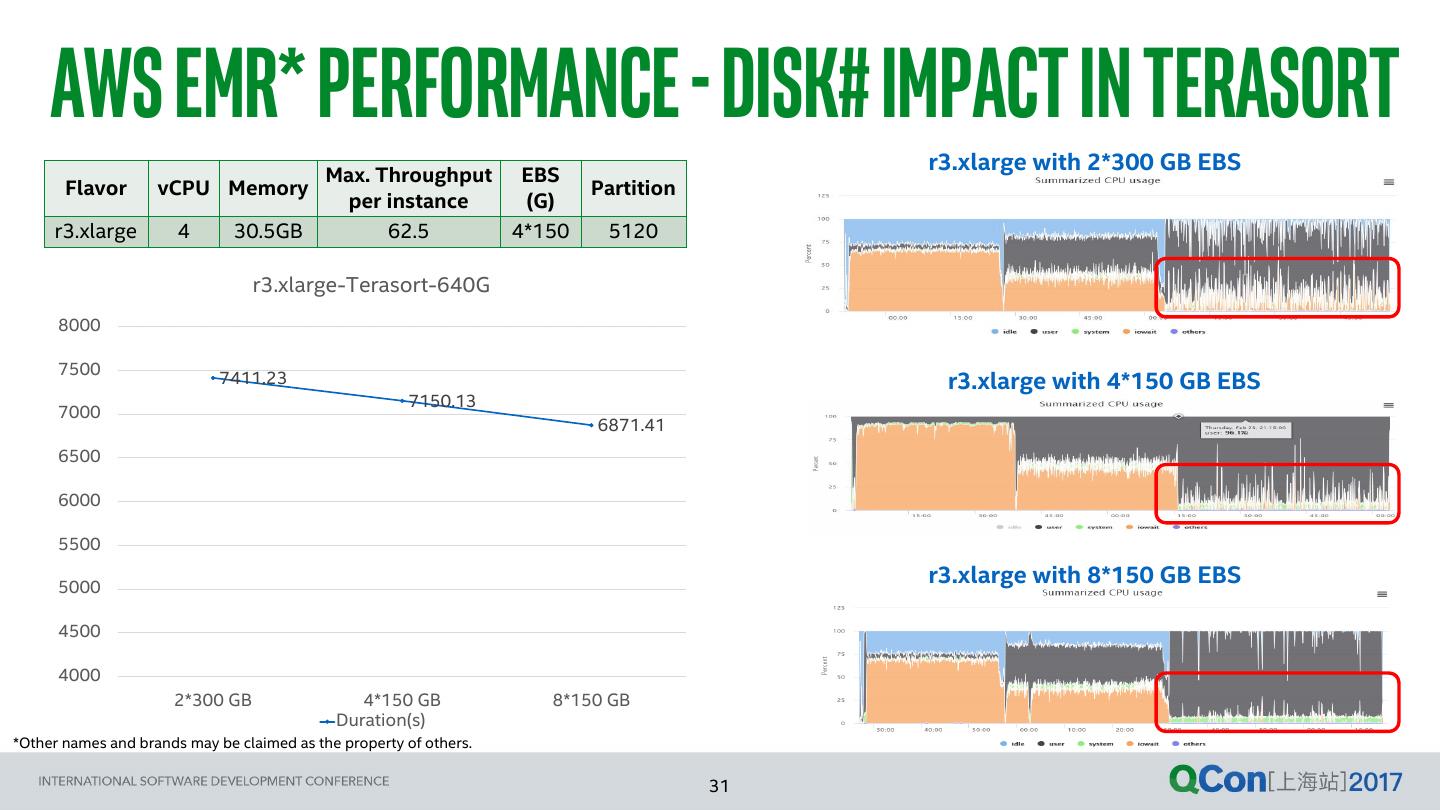
29 . Basic Performance - storage Disk EBS* General-purpose (GP2) Storage Volume Size R/W Throughput (MB/s) R/W IOPS • Testing tool: Flexible I/O Tester (FIO) (GB) (16 KB I/O size) • Testing results: The upper right table 100 131 ~3000 • Official Reference values 180 131 ~3000 • Max. Throughput per Volume: 160 MB/s 190 164 ~3000 • Burst IOPS (<= 1000GB, 16 KB I/O size): 3000 200 164 ~3000 400 164 ~3000 • Largely consistent with the testing results. 800 164 ~3000 • EBS performance is also restricted by instance type. 1000 164 ~3000 • E.g., Max. throughput (official reference value ) for Instance R/W Official R/W Official m4.4xlarge is 250 MB/s no matter how large the Type Throughput Reference IOPS Reference EBS volume size or number is. (MB/s) Value Value (MB/s) When choosing the EBS type and volume, the flavor type should also be taken into account. M4.4xlarge 239 250 - 16000 We recommend to choose enough EBS volumes in order M4.10xlarge 956 500 - 32000 to reach the Max. Throughput limited by instances. *Other names and brands may be claimed as the property of others.
相关推荐

加关注
3秒后跳转登录页面
去登陆

