展开查看详情
1 .Clickhouse in Telecom(From 0 to 1)
— Dataliance
�
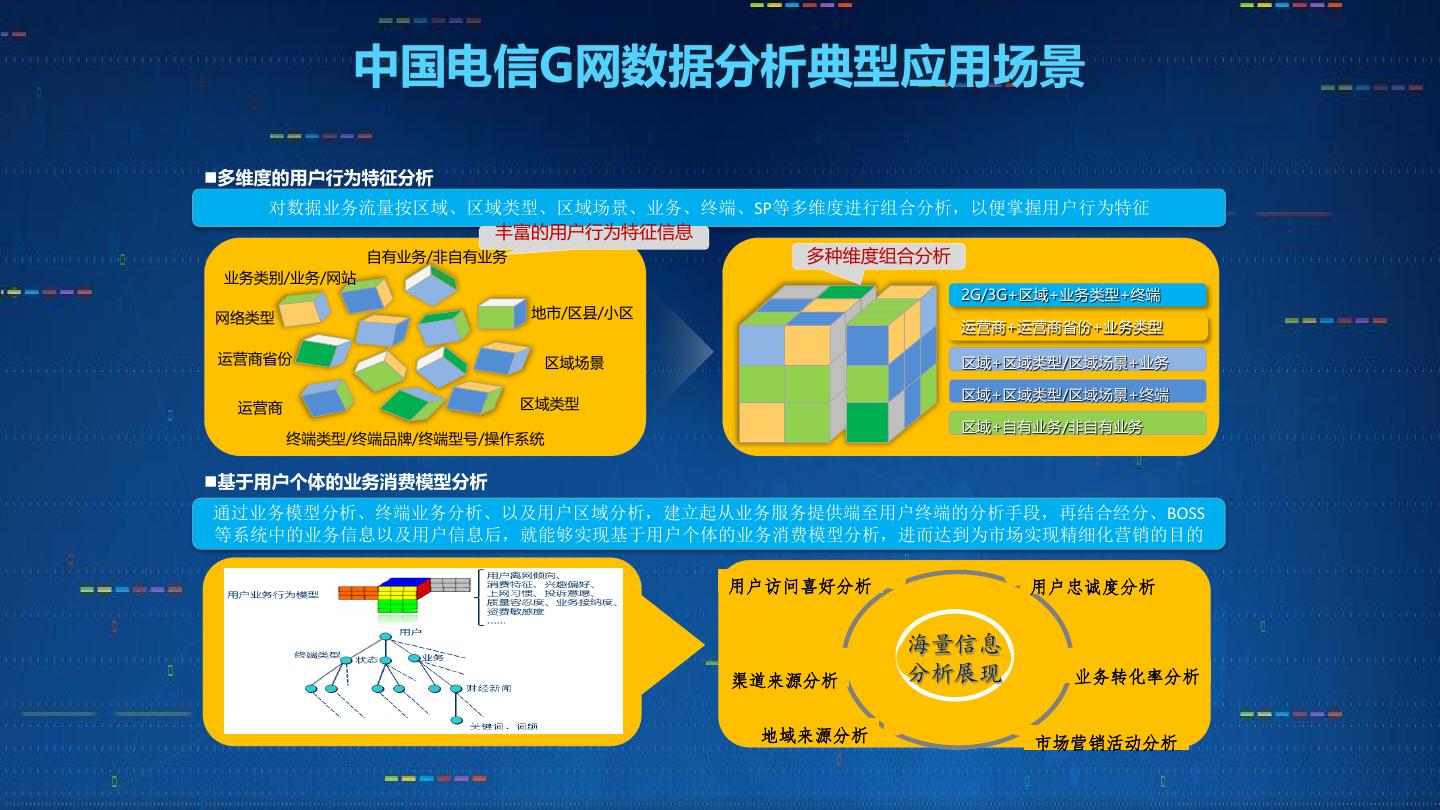
2 . 中国电信G网数据分析典型应用场景
多维度的用户行为特征分析
对数据业务流量按区域、区域类型、区域场景、业务、终端、SP等多维度进行组合分析,以便掌握用户行为特征
丰富的用户行为特征信息
自有业务/非自有业务 多种维度组合分析
业务类别/业务/网站
2G/3G+区域+业务类型+终端
网络类型 地市/区县/小区
运营商+运营商省份+业务类型
运营商省份 区域场景 区域+区域类型/区域场景+业务
区域+区域类型/区域场景+终端
运营商 区域类型
区域+自有业务/非自有业务
终端类型/终端品牌/终端型号/操作系统
基于用户个体的业务消费模型分析
通过业务模型分析、终端业务分析、以及用户区域分析,建立起从业务服务提供端至用户终端的分析手段,再结合经分、BOSS
等系统中的业务信息以及用户信息后,就能够实现基于用户个体的业务消费模型分析,进而达到为市场实现精细化营销的目的
用户访问喜好分析 用户忠诚度分析
海量信息
渠道来源分析 分析展现 业务转化率分析
地域来源分析 市场营销活动分析
�
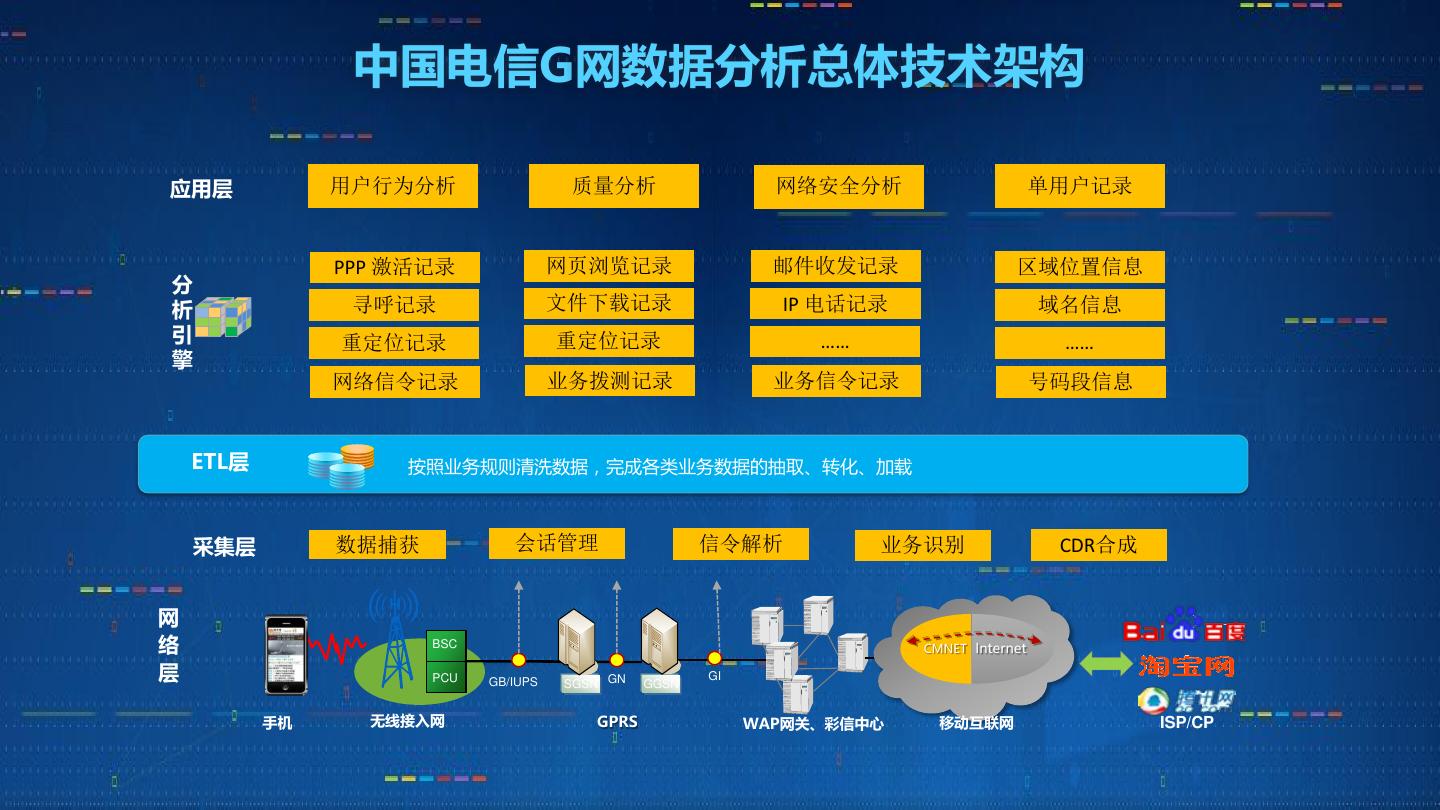
3 . 中国电信G网数据分析总体技术架构
应用层 用户行为分析 质量分析 网络安全分析 单用户记录
PPP 激活记录 网页浏览记录 邮件收发记录 区域位置信息
分
析 寻呼记录 文件下载记录 IP 电话记录 域名信息
引 重定位记录 重定位记录 …… ……
擎
网络信令记录 业务拨测记录 业务信令记录 号码段信息
ETL层 按照业务规则清洗数据,完成各类业务数据的抽取、转化、加载
采集层 数据捕获 会话管理 信令解析 业务识别 CDR合成
网
络 BSC CMNET Internet
层 PCU GB/IUPS SGSN GN GGSN
GI
手机 无线接入网 GPRS WAP网关、彩信中心 移动互联网 ISP/CP
�
4 . 电信级数据处理规模
数据处理规模:
• Ingesting from 网络基站设备、监控设备、骨干网等数据
• 50 billions Entries, ~700G/Day
• 分析后的数据结果可实时呈现在用户分析中心
�
5 . 基于位置的服务, 网络优化
业务拓展 用户维系 网络优化
基于位置的实时营销
客户体验管理 网络带宽优化
(B2B2C)
基于位置的服务
客户情感分析 网络信号放大
(B2C, B2B, B2B2C)
• 网优
– 例如. 重新路由来电到另外一个基站, 如果检测到有网络拥塞存在
• 基于位置的营销
– 匹配点击事件到订阅者资料; 如果匹配 说明是位置敏感性广告
• 挑战: 交互式实时控制台
● 简单的规则 - (CallDroppedCount > threshold) 然后告警 目前的查询场景
● 或者, 复杂 (OLAP 查询)
● TopK, 趋势分析, Join查询, 与历史数据关联 需要强大的查询分析引擎
�
6 . Comparison with Clickhouse and Hadoop
Why Choose Clickhouse? Drop Hadoop
• Hadoop Cluster has a poor performance , that is too slow to be valid.
• Hadoop Cluster is fat.
• Cant execute to query data (PB) in real time.
Clickhouse
• Rich functions
• Perfect performance
• Structure flat not fat
• Flexible way in execution
�
7 . Clickhouse功能特点与优势
数据库内压缩
采用了业内领先的压缩技术,提高性能的同时,显著地减少存储数据所需的空间。客户可以将所用空间减少
3-10倍,并提高有效的I/O性能。
千万亿字节规模的数据加载操作
高性能的并行数据装载器可以在所有节点上同步执行操作,装载速度超过50W条/秒。
随地访问数据
不管数据的位置、格式或存储介质如何,都可以从数据库向外部数据源执行查询操作,并行向数据库返回数
据。
动态扩展
对数据仓库进行便捷的小规模或大规模扩展,同时避免高成本的设备或SMP服务器升级。
集中管理
提供集群级管理工具和资源,帮助管理人员像管理一台服务器一样管理整个多维实时分析平台。
�
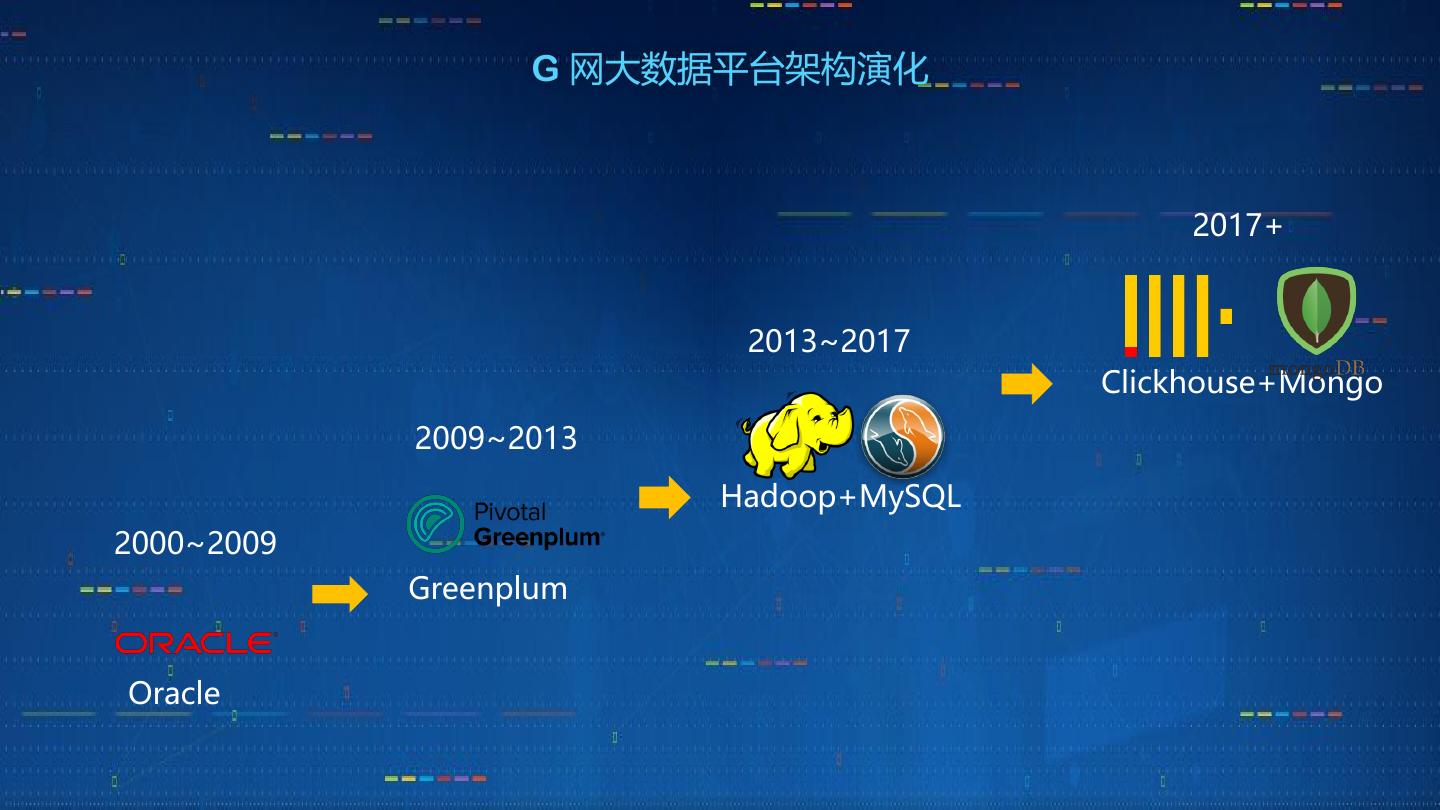
8 . G 网大数据平台架构演化
2017+
2013~2017
Clickhouse+Mongo
2009~2013
Hadoop+MySQL
2000~2009
Greenplum
Oracle
�
9 . Technology Architecture Before Clickhouse
Legacy Architecture:Kafka+Storm+Hive+Spark+MySQL
Kafka: collect and aggregate data
Storm: wrangle data
Hive: ad-hot query data
Spark: analysis offline Hive Cluster Spark Cluster
Kafka Cluster Storm Cluster HDFS Cluster MySQL Cluster
�
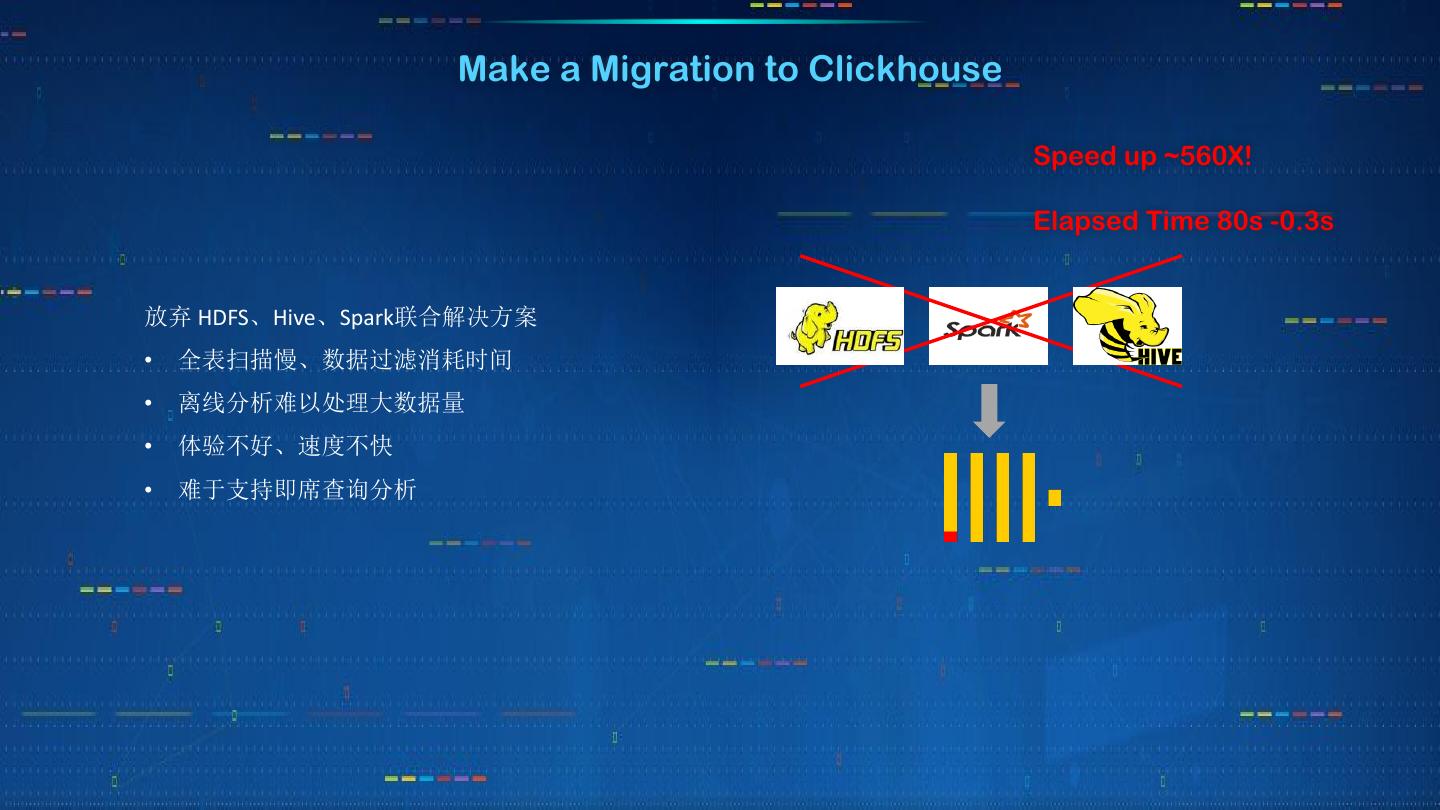
10 . Make a Migration to Clickhouse
Speed up ~560X!
Elapsed Time 80s -0.3s
放弃 HDFS、Hive、Spark联合解决方案
• 全表扫描慢、数据过滤消耗时间
• 离线分析难以处理大数据量
• 体验不好、速度不快
• 难于支持即席查询分析
�
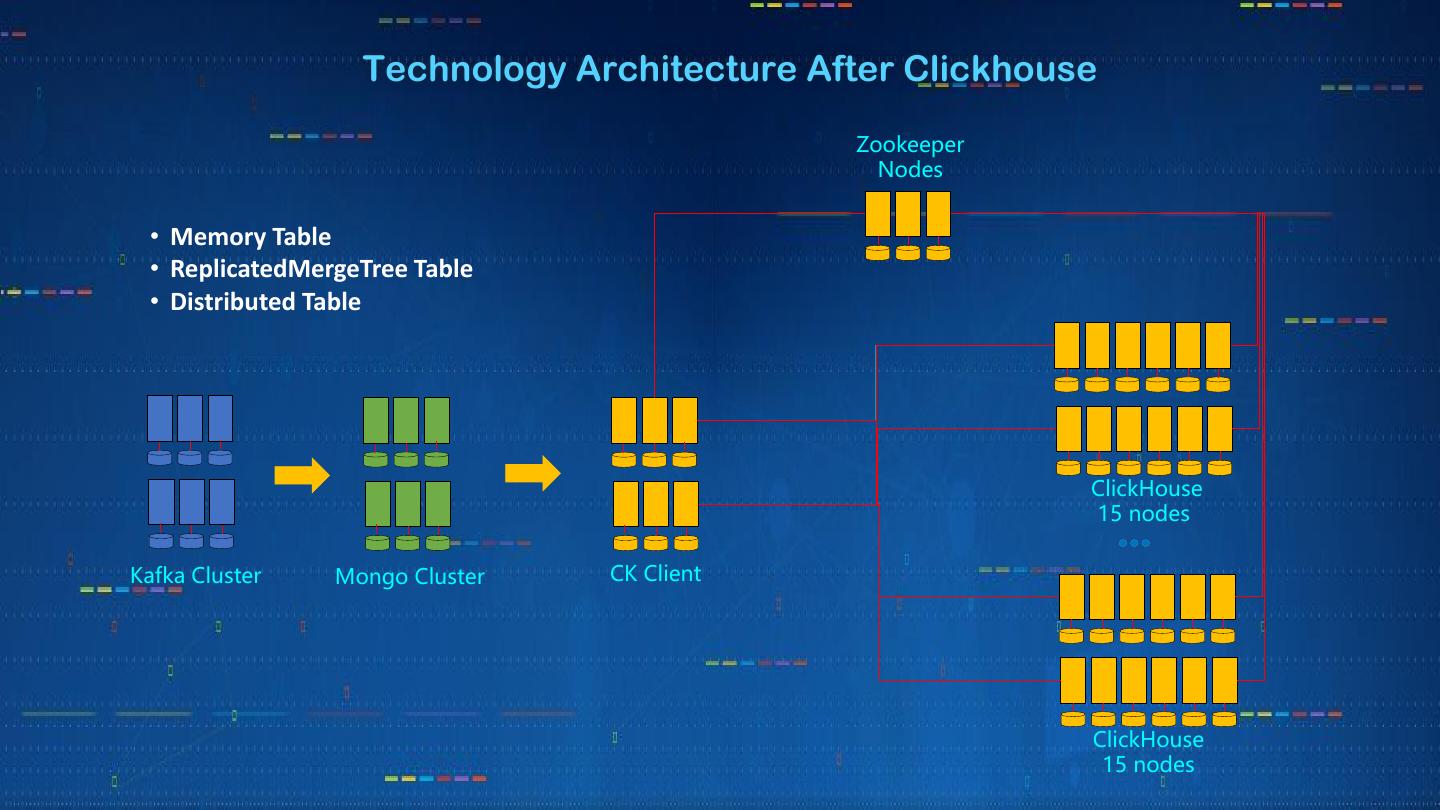
11 . Technology Architecture After Clickhouse
Zookeeper
Nodes
• Memory Table
• ReplicatedMergeTree Table
• Distributed Table
ClickHouse
15 nodes
Kafka Cluster Mongo Cluster CK Client
ClickHouse
15 nodes
�
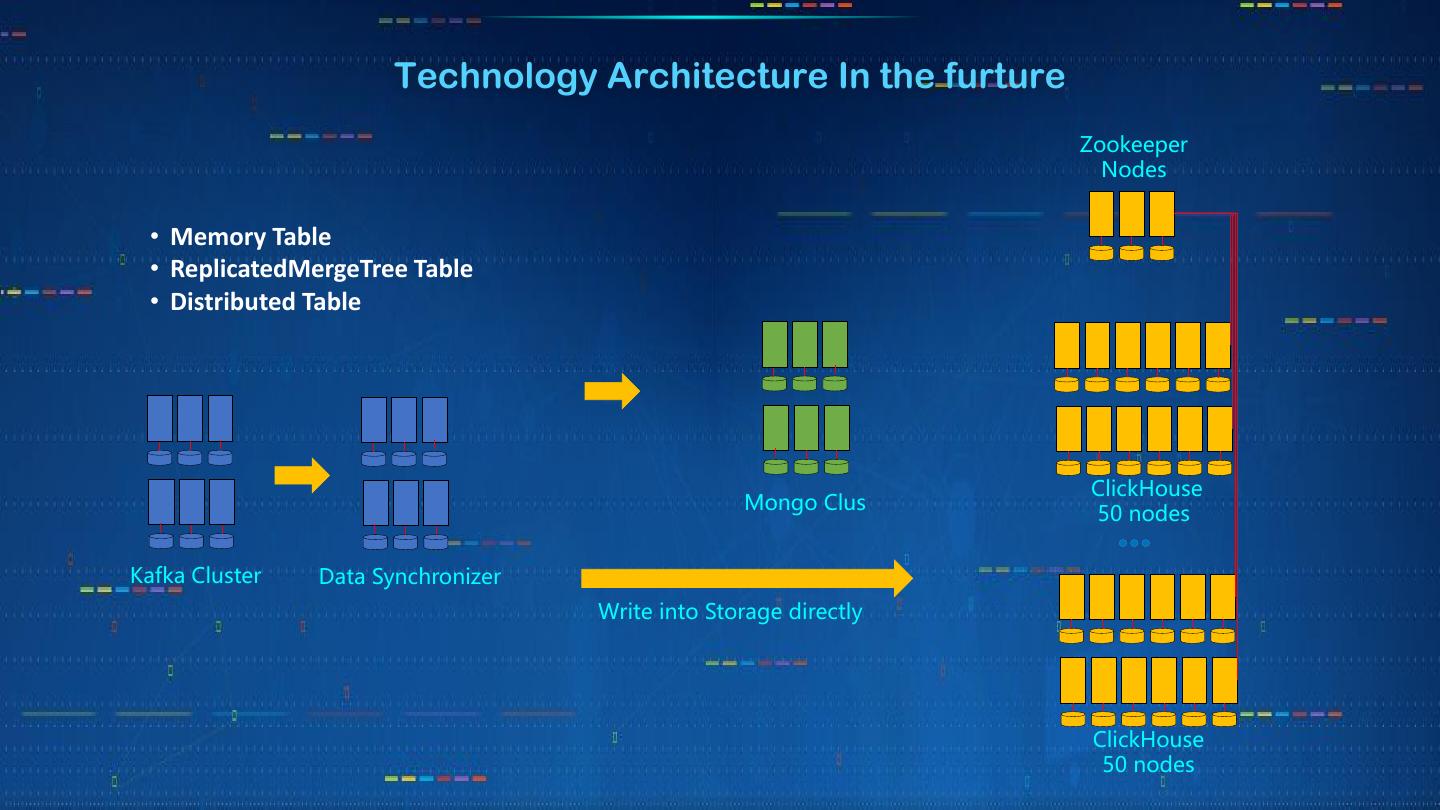
12 . Technology Architecture In the furture
Zookeeper
Nodes
• Memory Table
• ReplicatedMergeTree Table
• Distributed Table
ClickHouse
Mongo Clus 50 nodes
Kafka Cluster Data Synchronizer
Write into Storage directly
ClickHouse
50 nodes
�
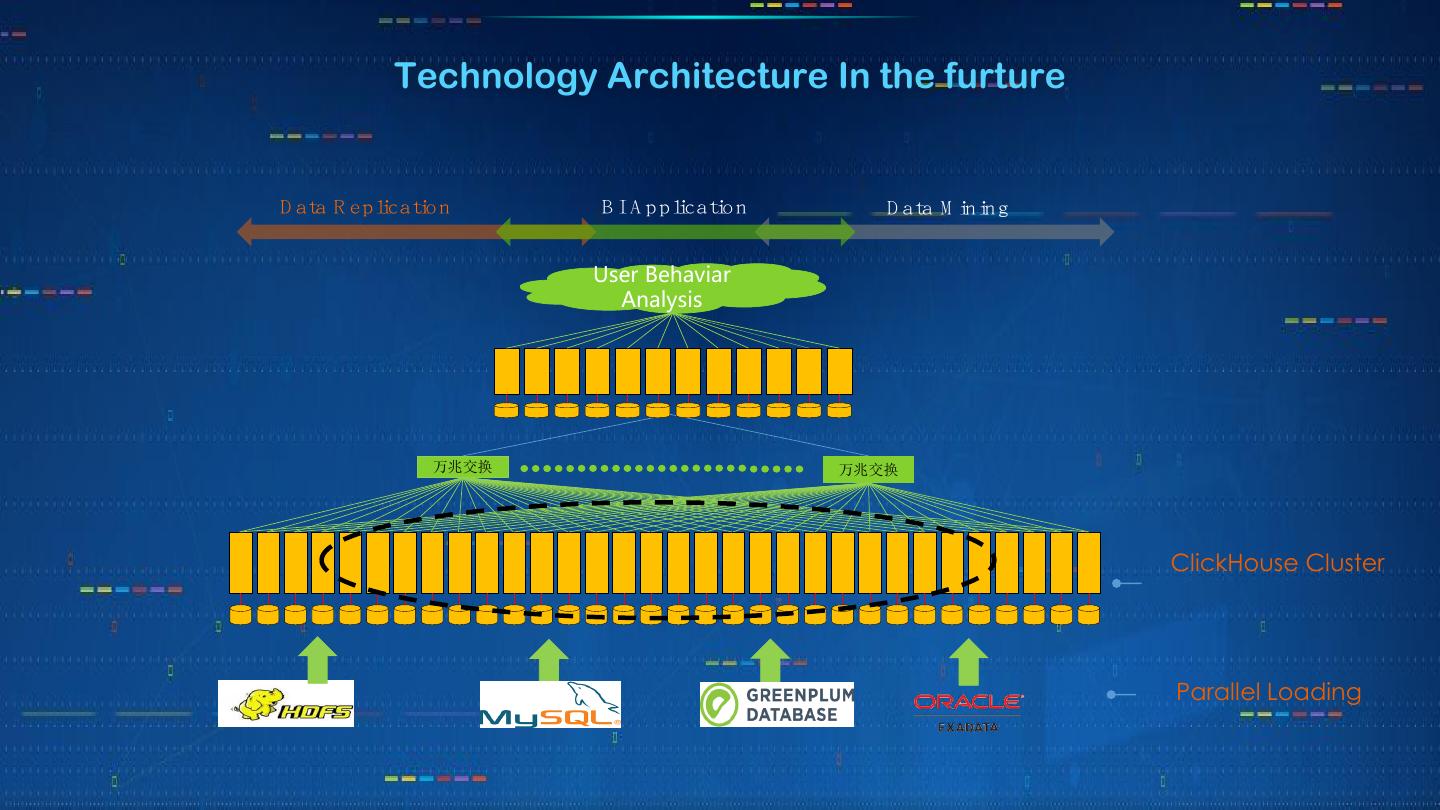
13 . Technology Architecture In the furture
Data Replication BI Application Data Mining
User Behaviar
Analysis
万兆交换 万兆交换
ClickHouse Cluster
Parallel Loading
�
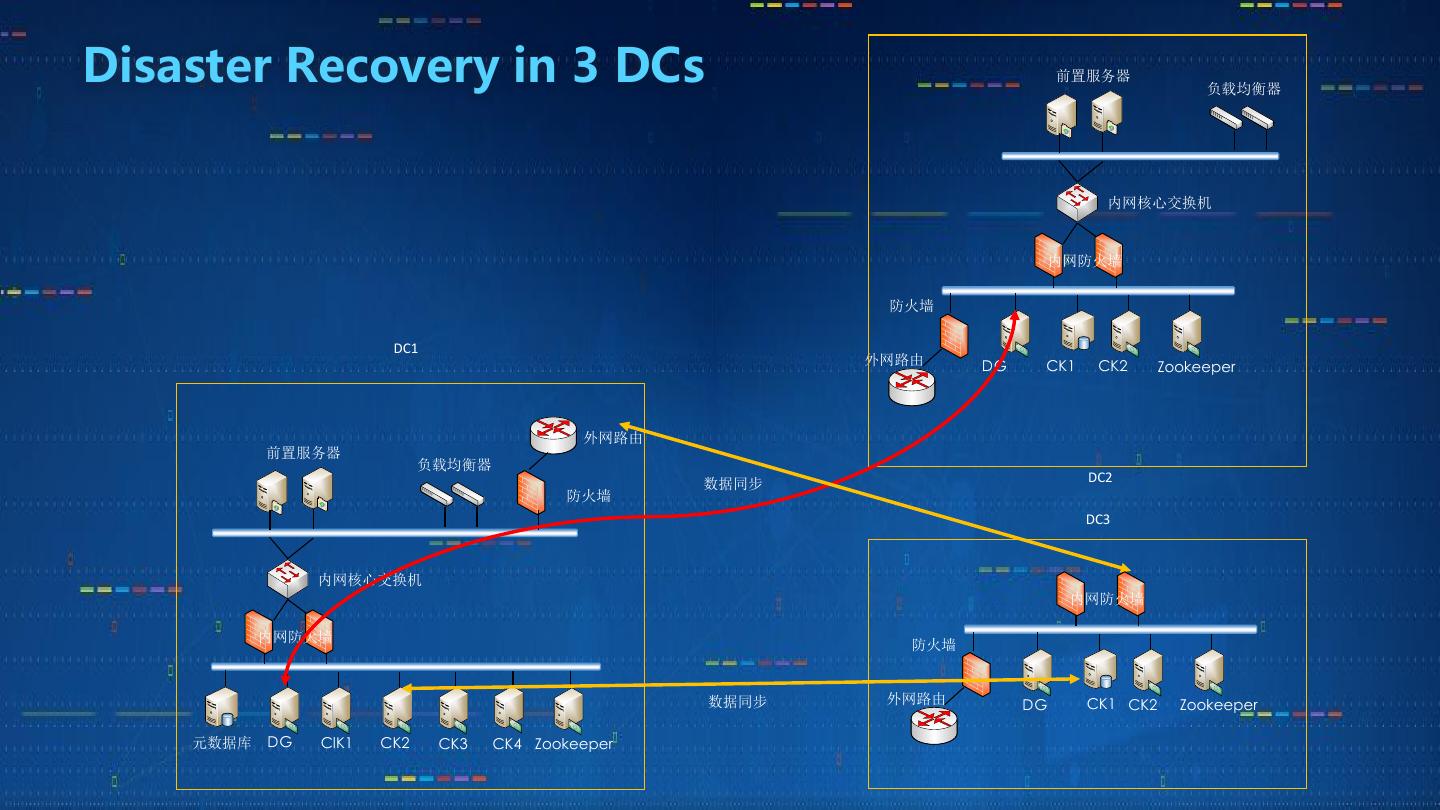
14 .Disaster Recovery in 3 DCs 前置服务器
负载均衡器
内网核心交换机
内网防火墙
防火墙
DC1
外网路由 DG CK1 CK2 Zookeeper
外网路由
前置服务器
负载均衡器
数据同步 DC2
防火墙
DC3
内网核心交换机
内网防火墙
内网防火墙 防火墙
数据同步 外网路由 DG CK1 CK2 Zookeeper
元数据库 DG ClK1 CK2 CK3 CK4 Zookeeper
�
15 . Need to work
• DML SQL(Update , Delete)
• SQL99/2003
• Automated Operation Tools
• Clickhouse on HDFS(like Hawq)
�
16 .Kill Hadoop using clickhouse
一只大象拆分后,有价值的东西所剩不多
• Kafka
• HDFS
• Spark
�
17 .ClickHouse on AWS
提供 ClickHouse Cloud云服务
�
18 . Clickhouse On AWS
Amazon Amazon Amazon AWS IoT
RDS Redshift Kinesis
MS SQL MS SQL MySQL DB MySQL
instance instance alternate instance instance alternate
Oracle DB PIOP Postgre SQL RDS DB
instance instance instance
RDS DB RDS DB SQL master SQL slave
instance standby instance read
(multi-AZ) replica
�
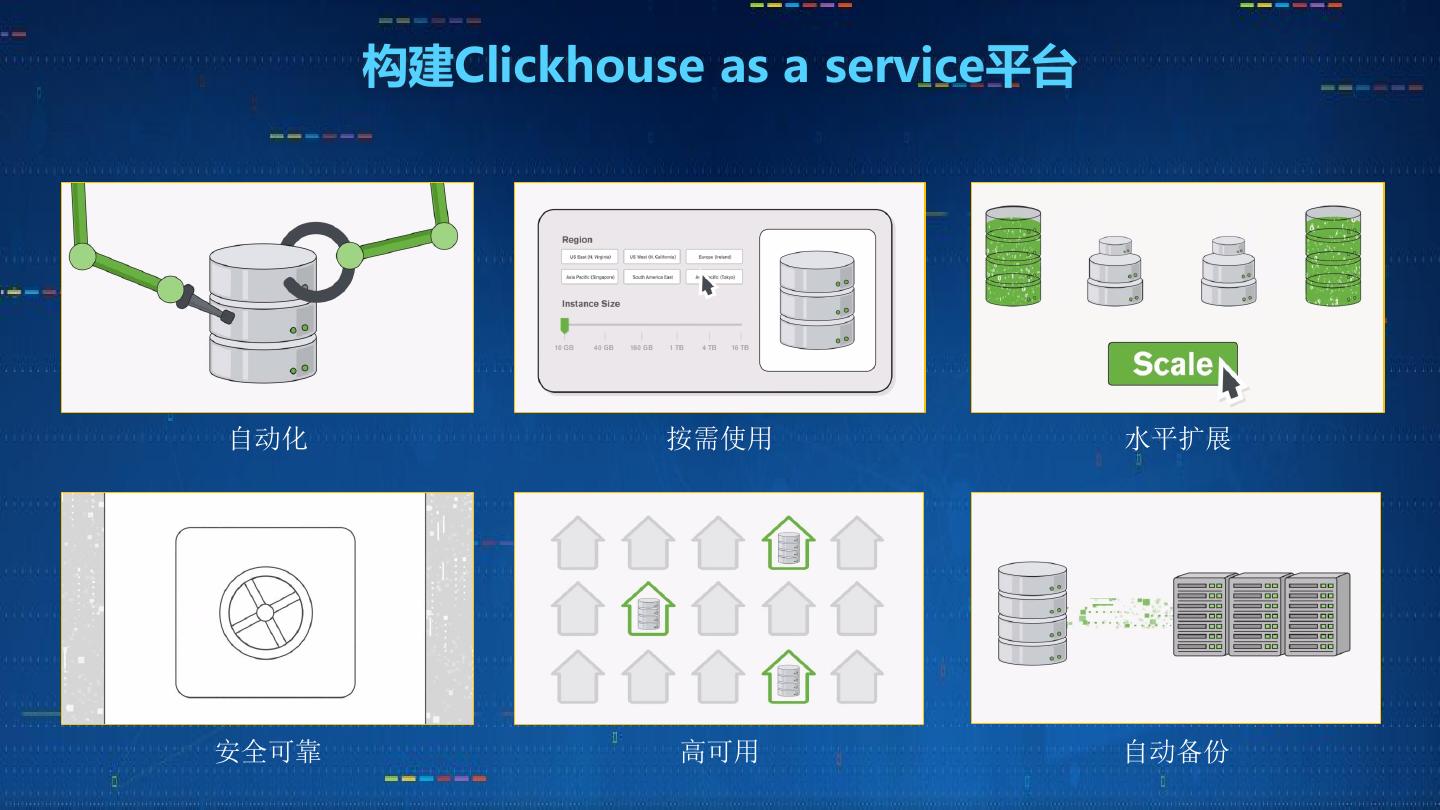
19 . 构建Clickhouse as a service平台
自动化 按需使用 水平扩展
安全可靠 高可用 自动备份
�
20 .公司招聘:
Database kernel developer
Clickhouse integration developer
欢迎加入我们
�