






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
SIMD-ADMS18
涉及向量化计算的历史及背景知识,并重点介绍了SIMD(Single Instruction Multiple Data)在数据处理领域的用途。在数据库技术中,向量化数据处理对于提升性能有着举足轻重的作用,来自甲骨文内存数据库计算VP和Vector Flow Analytics的技术总监一起介绍了向量化技术优化方案的案例,比如:数据压缩解压,字典类型数据编解码,条件计算,搜索,HashJoin,聚合函数,半结构化数据搜索,排序等等。
展开查看详情
1 .A Comprehensive Review of SIMD Techniques for Data Processing ADMS Workshop VLDB 2018, Rio De Janeiro, Brazil Shasank Chavan Vice President, In-Memory Database Technologies Oracle Weiwei Gong Dev Manager, Vector Flow Analytics Oracle
2 .
3 .Talk Agenda History / Background Instruction-Level Intrinsics Early SIMD Adoption for Data Processing Compression and Complex Predicates SIMD Beyond Scans What Does Industry Need
4 .SIMD : History / Background SIMD ( Single Instruction Multiple Data ) technology in microprocessors allows one instruction to process multiple data items at the same time. SIMD technology was first used in the late 60s and early 70s, as the basis for vector supercomputers (Cray, CDC Star-100, in the ILLIAC IV (1966) SIMD processing shifted from super-computer market to desktop market Real-time graphics and gaming, audio/video processing (e.g. MPEG decoding), etc. For example, “Change the brightness of an image” (i.e. add/sub value from R-G-B fields of pixel) VIS (Sun Microsystems ), MMX (Intel), AltiVec (IBM), SSE (Intel) – 1999 Initial adoption of SIMD systems in personal computers was slow FP registers reused. Conversions from FP to MMX registers. Lack of compiler support.
5 .SIMD : Intrinsics (Intel) Instruction-level intrinsics are C-style functions representing assembly instruction(s) which compilers inline into the source program. E.g. __ popcnt () maps to the popcnt instruction which returns number of set bits in reg With SSE came 128-bit SIMD registers and rich set of intrinsics , which started making SIMD programming more main-stream for performance Intel’s compiler- intrinsics are available online via an interactive guide ** ** https://software.intel.com/sites/landingpage/IntrinsicsGuide/ MMX (~124 intrins ) SSE4.2 (~624 intrins ) AVX2 (~997 intrins ) AVX-512 ( ~4864 intrins ) _ mm_cmpeq_pi * _ mm_blendv_epi * _mm256_srlv_epi* _mm512_conflict_epi* _ mm_srli_pi * _ mm_max_epi * _mm256_i32_gather_epi* _mm512_mask_cmp_epu*_mask _ mm_add_pi * _mm_shuffle_epi8 _mm256_permute4x64_epi64 _mm512_maskz_compress_epi*
6 .SIMD : Intrinsics (Intel) Instruction-level intrinsics are C-style functions representing assembly instruction(s) which compilers inline into the source program. E.g. __ popcnt () maps to the popcnt instruction which returns number of set bits in reg With SSE came 128-bit SIMD registers and rich set of intrinsics , which started making SIMD programming more main-stream for performance Intel’s compiler- intrinsics are available online via an interactive guide ** ** https://software.intel.com/sites/landingpage/IntrinsicsGuide/ MMX (~124 intrins ) SSE4.2 (~624 intrins ) AVX2 (~997 intrins ) AVX-512 ( ~4864 intrins ) _ mm_cmpeq_pi * _ mm_blendv_epi * _mm256_srlv_epi* _mm512_conflict_epi* _ mm_srli_pi * _ mm_max_epi * _mm256_i32_gather_epi* _mm512_mask_cmp_epu*_mask _ mm_add_pi * _mm_shuffle_epi8 _mm256_permute4x64_epi64 _mm512_maskz_compress_epi*
7 .SIMD : Early Adoption For Data Processing CPU and memory performance become bottleneck for columnar databases (in-memory processing and modern hardware). Intel SSE arrived w/ 128-bit SIMD registers and rich ISA to replace MMX Jingren Zhou and Kenneth Ross wrote in 2002 that SIMD technology can be employed in many database operations “Implementing Database Operations Using SIMD Instructions” , Sigmod 2002 SIMD Implementations for Database Operations Scans & Filters, Joins, Aggregations, Index Search
8 .SIMD : Early Adoption For Data Processing : Scan Filters Parallelize predicate evaluation – load, eval , store/consume result Select count(*) from T where a > 10 and b < 20 [Load] A [Load] Temp = 10 [Compare] A > Temp Load B, Compare 20 And Mask, Store Bit-Map 51 95182 1 69 96 64 32 0 10 10 10 10 > > > > 1 1 0 1 0 1 1 1 0 1 0 1 & & & & 0101
9 .SIMD : Early Adoption For Data Processing : Miscellaneous Simple aggregation (min, max, sum) of a column vector is straightforward Initialize a temporary SIMD register T (e.g. all zeroes) Load N values into SIMD register A and perform aggregation with SIMD register T. Loop until all values processed. Perform Horizontal aggregation on T to aggregate over the partial aggregates. Simple group-by aggregation could be done by sorting column vector first by grouping key – avoids conficts and fast aggregation within group. Nested Loop Join Join key extracted from outer table gets broadcasted into SIMD register T Join keys from inner table are loaded into SIMD register A to then compare to T
10 .SIMD : Early Adoption For Data Processing : Miscellaneous Simple aggregation (min, max, sum) of a column vector is straightforward Initialize a temporary SIMD register T (e.g. all zeroes) Load N values into SIMD register A and perform aggregation with SIMD register T. Loop until all values processed. Perform Horizontal aggregation on T to aggregate over the partial aggregates. Simple group-by aggregation could be done by sorting column vector first by grouping key – avoids conficts and fast aggregation within group. Nested Loop Join Join key extracted from outer table gets broadcasted into SIMD register T Join keys from inner table are loaded into SIMD register A to then compare to T
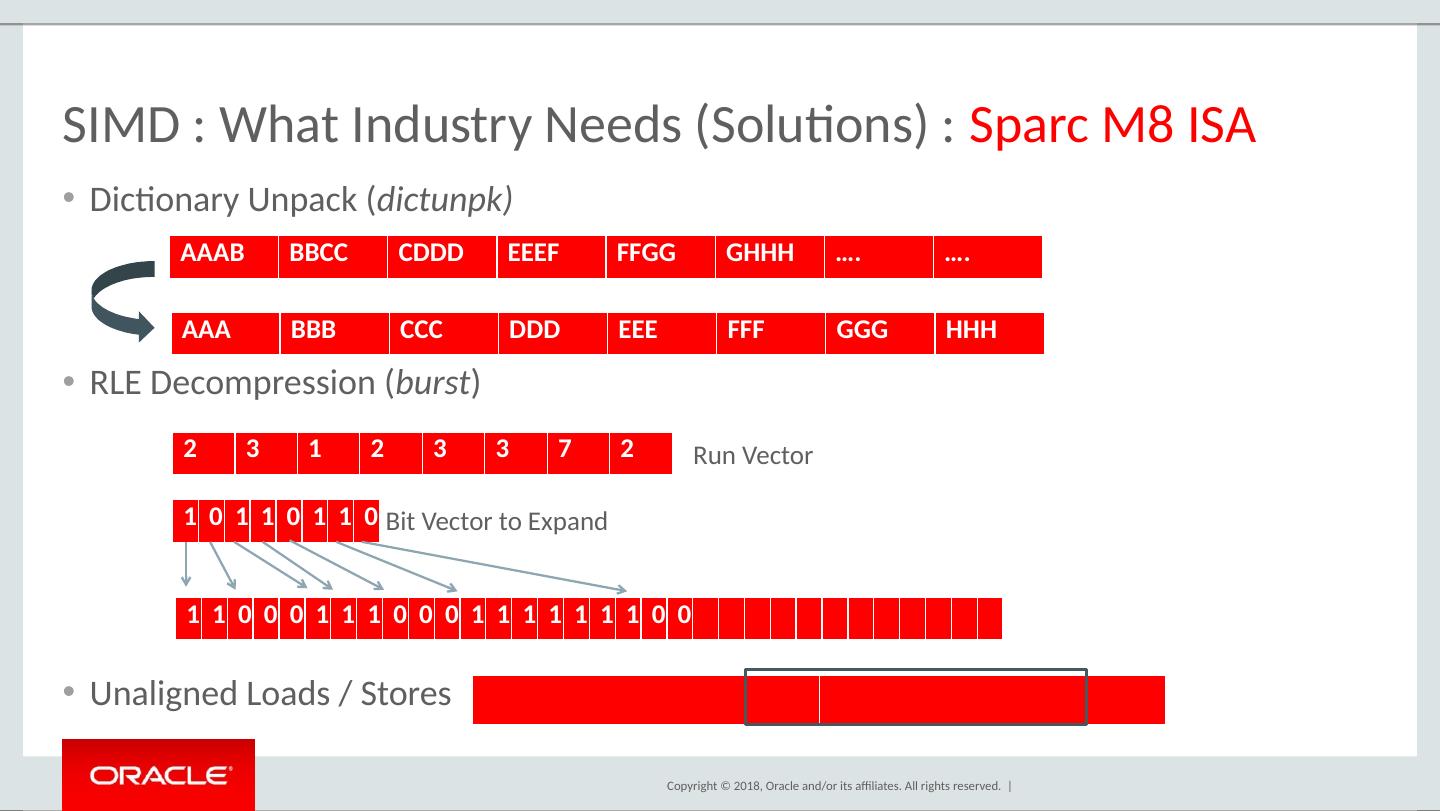
11 .SIMD : Columnar Compression : Dictionary Encoding In-Memory Columnar DBs compress data with lightweight compressors Dictionary Encoding is heavily used because it gives excellent compression without requiring data to be decoded / decompressed for many operations Dictionary Encoding format: Maintain an order-preserving dictionary of distinct symbols in a column. Map those symbols to codes [0..N] Replace symbols in column with the codes For additional compression, bit-pack the codes in the value stream (log(N) bits needed) and similarly pack symbols in dictionary. For more compression, run-length encode the value stream
12 .SIMD : Columnar Compression : Dictionary Unpacking Load Byte Shuffle And Mask
13 .SIMD : Compression Data compression still matters – working data sets can’t fit into memory Many lightweight compression techniques benefit with SIMD Dictionary Encoding, Bit-Packing, Run-Length-Encoding Integer compression using SIMD has been studied extensively “Fast Integer Compression using SIMD Instructions”, DaMoN 2010. Null Suppression – Encode leading zeroes w/ bits & remove from integers (1) SIMD LZCNT = [3, 2, 1, 0] bytes, SIMD MASK = [11100100] (2) Fetch Shuffle Mask, Shuffle Data, Variable Bit-Shift, Stitch In LZCNT 0x 000000 25 0x 0000 55EF 0x 00 6E5A22 0x FFFFFFFF Shuffle M1 Shuffle M2 … Shuffle M 256 b’11 , 0x25 b’10 , 0x55EF b’01 , 0x6E5A22 b’00 , 0x FFFFFFFF ** EVEN FASTER WITH VPCOMPRESS INST **
14 .SIMD : Decompression Decompression is usually more important than Compression for In-Memory Columnar Databases focused on Analytics (write once, read many) Oracle developed a compressor called OZIP which provides compression ratios similar to LZO, but at must faster decompression speeds. HW-Friendly format that was implemented for Sparc M7 DAX coprocessor. Compressed format looks like Dictionary Encoding: Small dictionary of 1024 symbols maintained (high frequency). Dictionary symbols are between 1-8 bytes long – nibble lengths stored. Uncompressed stream is dictionary-encoded. Decompression involves Bit-Unpacking, Gather, Unaligned Stores
15 .SIMD : OZIP Decompression HEADER DICTIONARY Symbols 1-8 bytes. Max 1024 symbols Packed together SYMBOL LENGTHS 1. Nibble size lens CODES Bit-packed 0 1 2 3 4 5 6 … 3 5 8 2 4 7 3 … 3 1 4 5 4 2 6 3 Decompressed Buffer: VPCOMPRESS Requires Immediate Mask Permutation Table Too Large to Keep : 3^8 * 64B
16 .SIMD : Complex Predicates T. Willhalm soon started worked on a more generic framework for evaluating arbitrary complex predicates with SIMD on columnar data “ Vectorizing Database Column Scans with Complex Predicates” Generate specialized kernels for each bit-width (e.g. 1-32), and integrate decompression (e.g. bit-unpacking) with predicate evaluation E.g. GT_LT range comparison, 5-bit dictionary codes, output found indexes In-List Support (where A in (‘yak’, ‘dog’, …, ‘tiger’)) This becomes a set-membership problem (generic eval using SIMD for complex preds ) In-List elements are converted into codes belonging to column value domain [0..N]. For each code in A, check if it’s found in the set. If found, return TRUE, else return FALSE. Implementation is like bloom filter evaluation, so more on this later.
17 .SIMD : Bit-Weaving, Byte-Slicing, Brain-Splitting, … Along came Jignesh Patel and crew to re-organize bit-packed dictionary codes vertically instead of horizontally , just to get super-fast scans… Assuming you have 3-bit codes: [ 1 0 1 1 1 1 1 0 0 1 1 1 1 0 0 1 0 1 1 0 1 0 1 0 ] Store them vertically into 3 segments so that all bits at position k are stored together [ 11111110 ] ( High Bits ), [ 01010001 ] ( Med Bits ), [ 11010110 ] ( Low Bits ) Great for scans with early termination (reduced loads and comparions ) E.g. Match for “000” involves searching Green and Red before returning “No Match” Theta compares boil down to sequence of SIMD logical operations (and, not, or, xor ) Stitching vertical bits back into horizontal form for projection is costly
18 .SIMD : Bit-Weaving, Byte-Slicing, Brain-Splitting, … Byte-Slicing was introduced to get the best of both worlds Slice vertically at byte granularity. Still get blazing fast SIMD byte comparisons. Stitching it simplified, although still expensive. However, most benefit still really only applies to early termination – i.e. when less work is needed. How likely is it that an evaluated slice across all segments indicates early termination? How likely will a single slice in a segment terminate early for conditional evaluation? Do we need to make blazing fast scans even faster? AVX-512 allows for conditional evaluation – more on this later
19 .Talk Agenda History / Background Instruction-Level Intrinsics Early SIMD Adoption for Data Processing Columnar Compression and SIMD SIMD Beyond Scans What Does Industry Need
20 .SIMD : Selective Evaluation AVX-512 allows most instructions to conditionally / selectively execute the specified operation against elements in the SIMD register. A conditional 64-bit bitmap k is provided which indicates which of the 64 bytes in the SIMD register are to participate in the operation. Separate code-paths for optimal execution based on selectivity not needed Example : select count(*) from T where a > 10 and b < 20 If “a > 10” is highly selective, prior to AVX-512 we may not vectorize “b < 20” With AVX-512, we could use bitmap result from “a > 10” as conditional mask into SIMD execution of “b < 20”. Main benefit is to avoid loads of “b” and stores of result bit-map (assuming zero initialized). Pipelined operations benefit too (select sum(a) from T where b > 20 )
21 .SIMD : Index Search Many modern-day memory indexes use SIMD to scan keys in inner nodes. Techniques generally include binary searching and/or linear searching. Linear Search ( simd_cmp_GT (‘SNAKE’) ) Binary Search For wider inner nodes, start in middle of keys and linear search for k keys. If lzcnt is k or 0, then search left or right, respectively. ART, FAST, etc, all use some variant of approaches above ANT CAT DOG EEL FISH GOAT LION PIG SNAIL TIGER WHALE ZEBRA 0 0 0 0 0 0 0 0 0 1 1 1 000000000111 LZCNT = 9 Children[9]
22 .SIMD : Hash Joins Vectorizing Hash Joins has been looked at in numerous papers recently “Rethinking SIMD Vectorization for In-Memory Databases”, Sigmod 2015 “Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization , and Prefetching Work Together At Last”, VLDB 2018 Hash Join has many components that can benefit with SIMD Hashing (multiplicative hashing), Partitioning, Bloom Filter, Probe, Gather and Project Probe (2 flavors) Compare probe key to all keys in a hash bucket(s) (chaining, linear probing) Gather N keys across multiple HT buckets and compare against N probe keys at once Better efficiency of SIMD lanes - Proposed by O. Polychroniou
23 .SIMD : Bloom Filter Bloom Filters are used in Hash Joins for fast filtering during inner table scan Keys from build table are hashed and bits are set in a (segmented) bitmap Bloom filter evaluation can be vectorized with SIMD using a combination of instructions – loads, shuffles, shifts, variable shifts, gather, ands, masks. O. Polychroniou et al. “ Vectorized Bloom filters for advanced SIMD processors” A variation of this is used by Oracle for Key Vector filtering “Accelerating Joins and Aggregations on the Oracle In-Memory Database” , ICDE 2018 A Key Vector is just like a bloom filter except multiple bits are used depending on the number of possible grouping keys – e.g. 1, 2, 4, 8, or 32 SIMD processing alone makes IMA run about 2X faster with SSB queries
24 .SIMD : Key Vector Filtration JK4 JK3 JK2 JK1 96 64 32 0 Segment Index Nibble Index in segment Join keys from fact table loaded into a SIMD register ( assuming join key is 4 byte value ) Byte Index in segment KV_seg [ ][ ] Intel AVX-512 VPSRLVW VPSRLVD VPSRLVQ — Variable Bit Shift Right Logical + Mask LSB of nibble index Dense key from KV >>1 Example shows looking up join keys in a nibble packed segmented key vector Shift
25 .SIMD : Group-By and Aggregation Group-By and Aggregation clauses are highly suitable for SIMD processing Select a, b, sum(c) from T where <blah> group by a, b Hash Group-By is the most common implementation method. Grouping key is hashed to index into Hash Table where results are accumulated. Array-based Aggregation is preferable when grouping key cardinality is relatively low and space is available. Conflict detection is still required in order to parallelize aggregation across groups Partition-based Aggregation is also suitable – contention is avoided at the cost of slow partitioning.
26 .SIMD : Group-By and Aggregation Array-based Aggregation Grouping columns X and Y are both dictionary-encoded, with cardinality 10 and 20. Create multi-dimensional Agg [10][20] buffer to store aggregate results. Agg [Unpack[X]][Unpack[Y]] += Gather[Unpack[A]] Partition-based Aggregation Sort rows by (Unpack[X], Unpack[Y]), then parallel sum A up to change in composite grouping key. Frequency-based Aggregation (for software-implemented numbers) If grouping key(s) cardinality is low, then maintain counts of each distinct A symbol across *each* group. Multiply count (frequency) by A value in dictionary Select sum(A) from T group by X, Y
27 .SIMD : Semi-Structure Data Search Parsing semi-structured data like JSON can be expensive “Filter Before You Parse: Faster Analytics on Raw Data with Sparser” , VLDB 2018 Apply generic filters on the raw byte-stream first for first-pass filtering E.g. where (A like ‘% fish%cat %’) --> A contains “dog” and A contains “cat” Search using SIMD by packing multiple copies of search string in register, and create N additional registers representing N shifts of the string [FISH,FISH,FISH,FISH], [ FIS,HFIS,HFIS,HFIS], [ FI,SHFI,SHFI,SHFI], [ F,ISHF,ISHF,ISHF] Scan through the raw string and apply SIMD comparisons to N registers. Multiple patterns lends itself to predicate reordering optimizations. In the end, merge results found to eliminate false positives.
28 .SIMD : Sorting and Partitioning Optimizing Sorting and Partitioning with SIMD has been extensively studied “A Comprehensive Study of Main-Memory Partitioning and its Application to Large-Scale Comparison- and Radix-Sort“ , Sigmod 2014 “Efficient implementation of sorting on multi-core SIMD CPU architecture” , VLDB 2008 In-Register Sorting Networks can utilize SIMD. Sorted runs are merged. For example: [ 50, 12, 85, 8 , 38, 30, 501, 29 , 15, 9, 100, 6 , 28, 98, 105, 40 ] Perform a series of SIMD MINs and MAXs so that sequence is sorted vertically [ 15, 12, 85, 6 , 28, 15, 100, 8 , 38, 28, 105, 29 , 50, 30, 501, 40 ] Shuffle to transpose columns back to rows of sorted runs. [ 15, 28, 38, 50 , 12, 15, 28, 30 , 85, 100, 105, 501 , 6, 8, 29, 40 ] More complicated SIMD sequences by O. Polychroniou for partitioning and comparison sorts utilizing comparisons, blend, logic operators, etc.
29 .SIMD : Many Research Areas Spatial – “ Adaptive Geospatial Joins for Modern Hardware” String Search – “ Exploiting SIMD instructions in current processors to improve classical string algorithms ” Skyline Computations – “ VSkyline : Vectorization for Efficient Skyline Computation” Skip Lists – “Parallelizing Skip Lists for In-memory Multi-core Database Systems” Set Intersection – “Faster Set Intersection with SIMD instructions by Reducing Branch Mispredictions ”
相关推荐
3秒后跳转登录页面
去登陆

