










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Variance-based Regularization with Convex Objectives
We develop an approach to risk minimization and stochastic optimization that provides
a convex surrogate for variance, allowing near-optimal and computationally
efficient trading between approximation and estimation error.
展开查看详情
1 . Variance-based Regularization with Convex Objectives Hongseok Namkoong John C. Duchi Stanford University Stanford University hnamk@stanford.edu jduchi@stanford.edu Abstract We develop an approach to risk minimization and stochastic optimization that pro- vides a convex surrogate for variance, allowing near-optimal and computationally efficient trading between approximation and estimation error. Our approach builds off of techniques for distributionally robust optimization and Owen’s empirical likelihood, and we provide a number of finite-sample and asymptotic results char- acterizing the theoretical performance of the estimator. In particular, we show that our procedure comes with certificates of optimality, achieving (in some scenarios) faster rates of convergence than empirical risk minimization by virtue of auto- matically balancing bias and variance. We give corroborating empirical evidence showing that in practice, the estimator indeed trades between variance and absolute performance on a training sample, improving out-of-sample (test) performance over standard empirical risk minimization for a number of classification problems. 1 Introduction Let X be a sample space, P0 a distribution on X , and ⇥ a parameter space. For a loss function ` : ⇥ ⇥ X ! R, consider the problem of finding ✓ 2 ⇥ minimizing the risk Z R(✓) := E[`(✓, X)] = `(✓, x)dP (x) (1) given a sample {X1 , . . . , Xn } drawn i.i.d. according to the distribution P . Under appropriate conditions on the loss `, parameter space ⇥, and random variables X, a number of researchers [2, 6, 12, 7, 3] have shown results of the form that with high probability, n r 1X Var(`(✓, X)) C2 R(✓) `(✓, Xi ) + C1 + for all ✓ 2 ⇥ (2) n i=1 n n where C1 and C2 depend on the parameters of problem (1) and the desired confidence guarantee. Pn Such bounds justify empirical risk minimization, which chooses ✓bn to minimize n1 i=1 `(✓, Xi ) over ✓ 2 ⇥. Further, these bounds showcase a tradeoff between Pn bias and variance, where we identify the bias (or approximation error) with the empirical risk n1 i=1 `(✓, Xi ), while the variance arises from the second term in the bound. Considering the bias-variance tradeoff (1) in statistical learning, it is natural to instead choose ✓ to directly minimize a quantity trading between approximation and estimation error: s n 1X VarPbn (`(✓, X)) `(✓, Xi ) + C , (3) n i=1 n where VarPbn denotes the empirical variance. Maurer and Pontil [16] consider this idea, giving guarantees on the convergence and good performance of such a procedure. Unfortunately, even when 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
2 .the loss ` is convex in ✓, the formulation (3) is generally non-convex, which limits the applicability of procedures that minimize the variance-corrected empirical risk (3). In this paper, we develop an approach based on Owen’s empirical likelihood [19] and ideas from distributionally robust optimization [4, 5, 10] that—whenever the loss ` is convex—provides a tractable convex formulation closely approximating the penalized risk (3). We give a number of theoretical guarantees and empirical evidence for its performance. To describe our approach, R we dPrequire a few definitions. For a convex function : R+ ! R with (1) = 0, D (P ||Q) = X ( dQ )dQ is the -divergence between distributions P and Q defined on X . Throughout this paper, we use (t) = 12 (t 1)2 , which gives the 2 -divergence. Given and an i.i.d. sample X1 , . . . , Xn , we define the ⇢-neighborhood of the empirical distribution n ⇢o Pn := distributions P s.t. D (P ||Pbn ) , n where Pbn denotes the empirical distribution of the sample {Xi }ni=1 , and our choice (t) = 12 (t 1)2 means that Pn has support {Xi }ni=1 . We then define the robustly regularized risk n ⇢o Rn (✓, Pn ) := sup EP [`(✓, X)] = sup EP [`(✓, X)] : D (P ||Pbn ) . (4) P 2Pn P n As it is the supremum of a family of convex functions, the robust risk ✓ 7! Rn (✓, Pn ) is convex in ✓ regardless of the value of ⇢ 0 whenever the original loss `(·; X) is convex and ⇥ is a convex set. Namkoong and Duchi [18] propose a stochastic procedure for minimizing (4) almost as fast as stochastic gradient descent. See Appendix C for a detailed account of an alternative method. We show that the robust risk (4) provides an excellent surrogate for the variance-regularized quan- tity (3) in a number of ways. Our first result (Thm. 1 in Sec. 2) is that for bounded loss functions, r 2⇢ Rn (✓, Pn ) = EPbn [`(✓, X)] + VarPbn (`(✓, X)) + "n (✓), (5) n where "n (✓) 0 and is O(1/n) uniformly in ✓. We show that when `(✓, X) has suitably large variance, we have "n = 0 with high probability. With the expansion (5) in hand, we can show a number of finite-sample convergence guarantees for the robustly regularized estimator ⇢ n ⇢o ✓bnrob 2 argmin sup EP [`(✓, X)] : D (P ||Pbn ) . (6) ✓2⇥ P n Based on the expansion (5), solutions ✓bnrob of problem (6) enjoy automatic finite sample optimality certificates: for ⇢ 0, with probability at least 1 C1 exp( ⇢) we have C2 ⇢ C2 ⇢ E[`(✓bnrob ; X)] Rn (✓bnrob ; Pn ) + = inf Rn (✓, Pn ) + n ✓2⇥ n where C1 , C2 are constants (which we specify) that depend on the loss ` and domain ⇥. That is, with high probability the robust solution has risk no worse than the optimal finite sample robust objective up to an O(⇢/n) error term. To guarantee a desired level of risk performance with probability 1 , we may specify the robustness penalty ⇢ = O(log 1 ). Secondly, we show that the procedure (6) allows us to automatically and near-optimally trade between approximation and estimation error (bias and variance), so that ( r ) 2⇢ C⇢ E[`(✓bn ; X)] inf E[`(✓; X)] + 2 rob Var(`(✓; X)) + ✓2⇥ n n with high probability. When there are parameters ✓ with small risk R(✓) (relative to the optimal parameter ✓? ) and small variance Var(`(✓, X)), this guarantees that the excess risk R(✓bnrob ) R(✓? ) is essentially of order O(⇢/n), where ⇢ governs our desired confidence level. We give an explicit example in Section p 3.2 where our robustly regularized procedure (6) converges at O(log n/n) compared to O(1/ n) of empirical risk minimization. Bounds that trade between risk and variance are known in a number of cases in the empirical risk minimization literature [15, 22, 2, 1, 6, 3, 7, 12], which is relevant when one wishes to achieve “fast 2
3 .rates” of convergence for statistical learning algorithms. In many cases, such tradeoffs require either conditions such as the Mammen-Tsybakov noise condition [15, 6] or localization results [3, 2, 17] made possible by curvature conditions that relate the risk and variance. The robust solutions (6) enjoy a variance-risk tradeoff that is differen but holds essentially without conditions except compactness of ⇥. We show in Section 3.3 that the robust solutions enjoy fast rates of convergence under typitcal curvature conditions on the risk R. We complement our theoretical results in Section 4, where we conclude by providing two experiments comparing empirical risk minimization (ERM) strategies to robustly-regularized risk minimization (6). These results validate our theoretical predictions, showing that the robust solutions are a practical alternative to empirical risk minimization. In particular, we observe that the robust solutions outper- form their ERM counterparts on “harder” instances with higher variance. In classification problems, for example, the robustly regularized estimators exhibit an interesting tradeoff, where they improve performance on rare classes (where ERM usually sacrifices performance to improve the common cases—increasing variance slightly) at minor cost in performance on common classes. 2 Variance Expansion We begin our study of the robust regularized empirical risk Rn (✓, Pn ) by showing that it is a good approximation to the empirical risk plus a variance term (5). Although the variance of the loss is in general non-convex, the robust formulation (6) is a convex optimization problem for variance regularization whenever the loss function is convex [cf. 11, Prop. 2.1.2.]. To gain intuition for the variance expansion that follows, we consider the following equivalent formulation for the robust objective supP 2Pn EP [Z] X n ⇢ 1 2 maximize pi zi subject to p 2 Pn = p 2 Rn+ : knp 1k2 ⇢, h1, pi = 1 , (7) p i=1 2 2 2 where z 2 Rn is a vector. For simplicity, let s2n = n1 kzk2 (z)2 = n1 kz zk2 denote the empirical “variance” of the vector z, where z = n1 h1, zi is the mean value of z. Then by introducing the variable u = p n1 1, the objective in problem (7) satisfies hp, zi = z + hu, zi = z + hu, z zi because hu, 1i = 0. Thus problem (7) is equivalent to solving 2⇢ 2 1 maximize z + hu, z zi subject to kuk2 2 , h1, ui = 0, u . n u2R n n p p Notably, by the Cauchy-Schwarz inequality, we have hu, z zi 2⇢ kz zk2 /n = 2⇢s2n /n, and equality is attained if and only if p p 2⇢(zi z) 2⇢(zi z) ui = = p . n kz zk2 n ns2n Of course, it is possible to choose such ui while satisfying the constraint ui 1/n if and only if p 2⇢(zi z) min p 1. (8) i2[n] ns2n Thus, if inequality (8) holds for the vector z—that is, there is enough variance in z—we have r 2⇢s2n sup hp, zi = z + . p2Pn n For losses `(✓, X) with enough variance relative to `(✓, Xi ) EPbn [`(✓, Xi )], that is, those satisfying inequality (8), then, we have r 2⇢ Rn (✓, Pn ) = EPbn [`(✓, X)] + VarPbn (`(✓, X)). n A slight elaboration of this argument, coupled with the application of a few concentration inequalities, yields the next theorem. Recall that (t) = 12 (t 1)2 in our definition of the -divergence. 3
4 .Theorem 1. Let Z be a random variable taking values in [M0 , M1 ] where M = M1 M0 and fix ⇢ 0. Then r ! r 2⇢ 2M ⇢ n ⇢o 2⇢ VarPbn (Z) sup EP [Z] : D (P ||Pbn ) EPbn [Z] VarPbn (Z). n n P n n + q (9) 24⇢ p p M2 Var(Z) If n max{ Var(Z) , Var(Z) , 1}M and we set tn = Var(Z) 1 n 16 2 1 1 2 n 18 , r 2⇢ sup EP [Z] = EPbn [Z] + VarPbn (Z) (10) bn ) ⇢ P :D (P ||P n n nt2n nVar(Z) with probability at least 1 exp( 2M 2 ) 1 exp( 36M 2 ). See Appendix A.1 for the proof. Inequality (9) and the exact expansion (10) show that, at least for bounded loss functions `, the robustly regularized risk (4) is a natural (and convex) surrogate for empirical risk plus standard deviation of the loss, and the robust formulation approximates exact variance regularization with a convex penalty. We also provide a uniform variant of Theorem 1 based on the standard notion of the covering number, which we now define. Let V be a vector space with (semi)norm k·k on V, and let V ⇢ V. We say a collection v1 , . . . , vN ⇢ V is an ✏-cover of V if for each v 2 V , there exists vi such that kv vi k ✏. The covering number of V with respect to k·k is then N (V, ✏, k·k) := inf {N 2 N : there is an ✏-cover of V with respect to k·k}. Now, let F be a collection of functions f : X ! R, and define the L1 (X )-norm by kf gkL1 (X ) := supx2X |f (x) g(x)|. Although we state our results abstractly, we typically take F := {`(✓, ·) | ✓ 2 ⇥}. As a motivating example, we give the following standard bound on the covering number of Lipschitz losses [24]. Example 1: Let ⇥ ⇢ Rd and assume that ` : ⇥ ⇥ X ! R is L-Lipschitz in ✓ with respect to the `2 -norm for all x 2 X , meaning that |`(✓, x) `(✓0 , x)| L k✓ ✓0 k2 . Then taking F = {`(✓, ·) : ✓ 2 ⇥}, any ✏-covering {✓1 , . . . , ✓N } of ⇥ in `2 -norm guarantees that mini |`(✓, x) `(✓i , x)| L✏ for all ✓, x. That is, ✓ ◆d diam(⇥)L N (F, ✏, k·kL1 (X ) ) N (⇥, ✏/L, k·k2 ) 1 + , ✏ where diam(⇥) = sup✓,✓0 2⇥ k✓ ✓0 k2 . Thus `2 -covering numbers of ⇥ control L1 -covering numbers of the family F. ⌥ With this definition, we provide a result showing that the variance expansion (5) holds uniformly for all functions with enough variance. Theorem 2. Let F be a collection of bounded functions f : X ! [M0 , M1 ] wherepM = M1 M0 , and let ⌧ 0 be a constant. Define F ⌧ := f 2 F : Var(f ⇣ ) ⌧ and tn⌘ = ⌧ (⇣ 1 n⌘ 2 1 1 2) M2 32⇢M 2 nt2n n . If ⌧ 2 , then with probability at least 1 , we have ⌧ n N F, 32 , k·kL1 (X ) exp 2M 2 for all f 2 F ⌧ r 2⇢ sup EP [f (X)] = EPbn [f (X)] + VarPbn (f (X)). (11) bn ) ⇢ P :D (P ||P n n We prove the theorem in Section A.2. Theorem 2 shows that the variance expansion of Theorem 1 holds uniformly for all functions f with sufficient variance. See Duchi, Glynn, and Namkoong [10] for an asymptotic analogue of the equality (11) for heavier tailed random variables. 3 Optimization by Minimizing the Robust Loss Based on the variance expansions in the preceding section, we show that the robust solution (6) automatically trades between approximation and estimation error. In addition to k·kL1 (X ) -covering 4
5 .numbers defined in the previous section, we use the tighter notion of empirical `1 -covering numbers. For x 2 X n , define F(x) = {(f (x1 ), . . . , f (xn )) : f 2 F} and the empirical `1 -covering numbers N1 (F, ✏, n) := supx2X n N (F(x), ✏, k·k1 ), which bound the number of `1 -balls of radius ✏ required to cover F(x). Note that we always have N1 (F) N (F). Typically, we consider the function class F := {`(✓, ·) : ✓ 2 ⇥}, though we state our minimization results abstractly. Although the below result is in terms of covering numbers for ease of exposition, a variant holds depending on localized Rademacher averages [2] of the class F, which can yield tighter guarantees (we omit such results for lack of space). We prove the following theorem in Section A.3. Theorem 3. Let F be a collection of functions f : X ! [M0 , M1 ] with M = M1 M0 . Define the empirical minimizer ⇢ n b ⇢o f 2 argmin sup EP [f (X)] : D (P ||Pbn ) . f 2F P n Then for ⇢ t, with probability at least 1 2(N (F, ✏, k·kL1 (X ) ) + 1)e t , r ! b b 7M ⇢ 2t E[f (X)] sup EP [f (X)] + + 2+ ✏ (12a) bn ) ⇢ P :D (P ||P n n 1 n ( r ) r ! 2⇢ 11M ⇢ 2t inf E[f ] + 2 Var(f ) + + 2+ ✏. (12b) f 2F n n n 1 8M 2 Further, for n t , t log 12, and ⇢ 9t, with probability at least 1 2(3N1 (F, ✏, 2n)+1)e t , r ! b b 11 M ⇢ 2t E[f (X)] sup EP [f (X)] + + 2+4 ✏ (13a) bn ) ⇢ P :D (P ||P 3 n n n ( r ) r ! 2⇢ 19M ⇢ 2t inf E[f ] + 2 Var(f ) + + 2+4 ✏. (13b) f 2F n 3n n Unlike analogous results for empirical risk minimization [6], Theorem 3 does not require the self- bounding type assumption Var(f ) BE[f ]. A consequencep of this is that when v = Var(f ⇤ ) is small, where f 2 argminf 2F E[f ], we achieve O(1/n + v/n) (fast) rates of convergence. ⇤ This condition is different from the typical conditions required for empirical risk minimization to have fast rates of convergence, highlighting the possibilities of variance-based regularization. It will be interesting to understand appropriate low-noise conditions (e.g. the Mammen-Tsybakov noise condition [15, 6]) guaranteeing good performance. Additionally, the robust objective Rn (✓, Pn ) is an empirical likelihood confidence bound on the population risk [10], and as empirical likelihood confidence bounds are self-normalizing [19], other fast-rate generalizations may exist. 3.1 Consequences of Theorem 3 We now turn to a number of corollaries that expand on Theorem 3 to investigate its consequences. Our first corollary shows that Theorem 3 applies to standard Vapnik-Chervonenkis (VC) classes. As VC dimension is preserved through composition, this result also extends to the procedure (6) in typical empirical risk minimization scenarios. See Section A.4 for its proof. Corollary 3.1. In addition to the conditions of Theorem 3, let F have finite VC-dimension ⇣ Then for a numerical VC(F). constant ⌘ c < 1, the bounds (13) hold with probability at least 16M ne VC(F ) 1 1 c VC(F) ✏ +2 e . t Next, we focus more explicitly on the estimator ✓bnrob defined by minimizing the robust regularized risk (6). Let us assume that ⇥ ⇢ Rd , and that we have a typical linear modeling situation, where a loss h is applied to an inner product, that is, `(✓, x) = h(✓> x). In this case, by making the substitution that the class F = {`(✓, ·) : ✓ 2 ⇥} in Corollary 3.1, we have VC(F) d, and we obtain the following corollary. Recall the definition (1) of the population risk R(✓) = E[`(✓, X)], and the uncertainty set Pn = {P : D (P ||Pbn ) n⇢ }, and that Rn (✓, Pn ) = supP 2Pn EP [`(✓, X)]. By setting ✏ = M/n in Corollary 3.1, we obtain the following result. 5
6 .Corollary 3.2. Let the conditions of the previous paragraph hold and assume that `(✓, x) 2 [0, M ] for all ✓ 2 ⇥, x 2 X . Then if n ⇢ 9 log 12, ( r ) 11M ⇢ 4M 2⇢ 11M ⇢ R(✓bnrob ) Rn (✓bnrob , Pn ) + + inf R(✓) + 2 Var(`(✓; X)) + 3n n ✓2⇥ n n with probability at least 1 2 exp(c1 d log n c2 ⇢), where ci are universal constants with c2 1/9. Unpacking Theorem 3 and Corollary 3.2 a bit, the first result (13a) provides a high-probability guarantees that the true expectation E[fb] cannot be more than O(1/n) worse than its robustly- regularized empirical counterpart, that is, R(✓bnrob ) Rn (✓bnrob , Pn ) + O(⇢/n), which is (roughly) a consequence of uniform variants of Bernstein’s inequality. The second result (13b) guarantee the convergence of the empirical minimizer to a parameter with risk at most O(1/n) larger than the best possible variance-corrected risk. In the case that the losses take values in [0, M ], then Var(`(✓, X)) M R(✓), and thus for ✏ = 1/n in Theorem 3, we obtain r M ⇢R(✓? ) M⇢ R(✓bn ) R(✓ ) + C rob ? +C , n n a type of result well-known and achieved by empirical risk minimization for bounded nonnegative losses [6, 26, 25]. In some scenarios, however, the variance may satisfy Var(`(✓, X)) ⌧ M R(✓), yielding improvements. To give an alternative variant of Corollary 3.2, let ⇥ ⇢ Rd and assume that for each x 2 X , inf ✓2⇥ `(✓, x) = 0 and that ` is L-Lipschitz in ✓. If D := diam(⇥) = sup✓,✓0 2⇥ k✓ ✓0 k < 1, then 0 `(✓, x) L diam(⇥) =: M . Corollary 3.3. Let the conditions of the preceeding paragraph hold. Set t = ⇢ = log 2n + d log(2nDL) and ✏ = n1 in Theorem 3 and assume that D . nk and L . nk for a numerical constant k. With probability at least 1 1/n, ( r ) d Var(`(✓, X)) dLD log n E[`(✓bn ; X)] = R(✓bn ) inf R(✓) + C rob rob log n + C ✓2⇥ n n where C is a numerical constant. 3.2 Beating empirical risk minimization We now provide an example in which the robustly-regularized estimator (6) exhibits a substantial improvement over empirical risk minimization. We expect the robust approach to offer performance benefits in situations in which the empirical risk minimizer is highly sensitive to noise, say, because the losses are piecewise linear, and slight under- or over-estimates of slope may significantly degrade solution quality. With this in mind, we construct a toy 1-dimensional example—estimating the median of a distribution supported on X = { 1, 0, 1}—in which the robust-regularized p estimator has convergence rate log n/n, while empirical risk minimization is at best 1/ n. Define the loss `(✓; x) = |✓ x| |x|, and for 2 (0, 1) let the distribution P be defined by P (X = 1) = 1 2 , P (X = 1) = 1 2 , P (X = 0) = . Then for ✓ 2 R, the risk of the loss is 1 1 R(✓) = |✓| + |✓ 1| + |✓ + 1| (1 ). 2 2 By symmetry, it is clear that ✓? := argmin✓ R(✓) = 0, which satisfies R(✓? ) = 0. (Note that `(✓, x) = `(✓, x) `(✓? , x).) Without loss of generality, we assume that ⇥ = [ 1, 1]. Define the empirical risk minimizer and the robust solution ✓berm := argmin EPbn [`(✓, X)] = argmin EPbn [|✓ X|], ✓bnrob 2 argmin Rn (✓, Pn ). ✓2R ✓2[ 1,1] ✓2⇥ Intuitively, if too many of the observations satisfy Xi = 1 or too many satisfy Xi = 1, then ✓berm will be either 1 or 1; for small , such events become reasonably probable. On the other hand, we have `(✓? ; x) = 0 for all x 2 X , so that Var(`(✓? ; X)) = 0 and p variance regularization achieves the rate O(log n/n) as opposed to empirical risk minimizer’s O(1/ n). See Section A.6 for the proof. 6
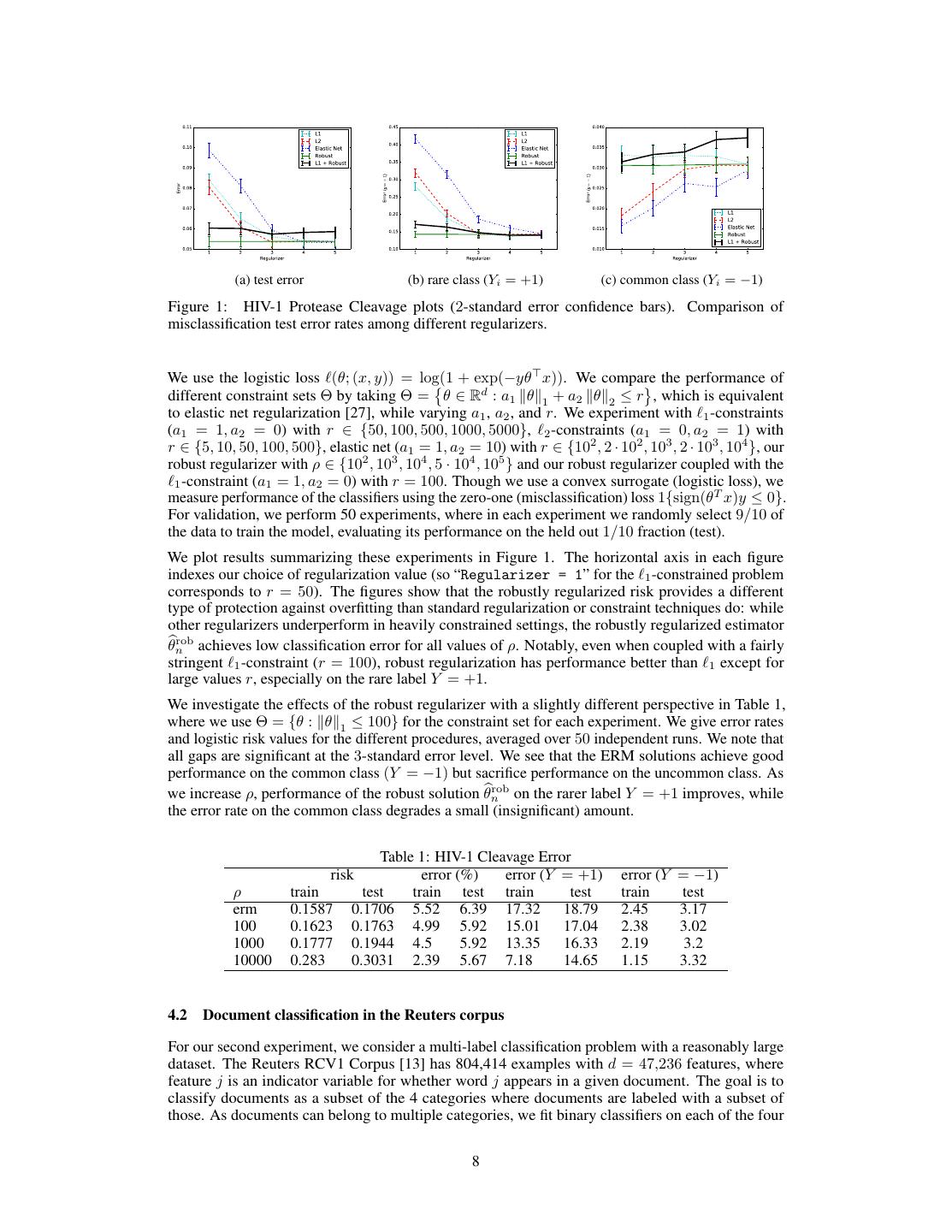
7 .Proposition 1. Under the conditions of the previous paragraph, for n ⇢ = 3 log n, with probability q at least 1 n4 , we have R(✓bnrob ) R(✓? ) 45 log n n . However, with probability at least 2 ( n n 1) p p q n 2 , we have R(✓berm ) R(✓? ) + n 2 . n 1 1 2 2/ ⇡en 2 ( n 1) For n 20, the probability of the latter event is .088. Hence, for this (specially constructed) 1 example, we see that there is a gap of nearly n 2 in order of convergence. 3.3 Fast Rates In cases in which the risk R has curvature, empirical risk minimization often enjoys faster rates of convergence [6, 21]. The robust solution ✓bnrob similarly attains faster rates of conver- gence in such cases, even with approximate minimizers of Rn (✓, Pn ). For the risk R and ✏ 0, let S ✏ := {✓ 2 ⇥ : R(✓) inf ✓? 2⇥ R(✓? ) + ✏} denote the ✏-sub-optimal (solution) set, and similarly let Sb✏ := {✓ 2 ⇥ : Rn (✓, Pn ) inf ✓0 2⇥ Rn (✓0 , Pn ) + ✏}. For a vector ✓ 2 ⇥, let ⇡S (✓) = argmin✓? 2S k✓? ✓k2 denote the Euclidean projection of ✓ onto the set S. Our below result depends on a local notion of Rademacher complexity. For i.i.d. random signs "i 2 {±1}, the empirical Rademacher complexity of a function class F ⇢ {f : X ! R} is n 1X Rn F := E sup "i f (Xi ) | X . f 2F n i=1 Although we state our results abstractly, we typicallyptake F := {`(✓, ·) | ✓ 2 ⇥}. For example, when F is a VC-class, we typically have E[Rn F] . VC(F)/n. Many other bounds on E[Rn F] are possible [1, 24, Ch. 2]. For A ⇢ ⇥ let Rn (A) denote the Rademacher complexity of the localized process {x 7! `(✓; x) `(⇡S (✓); x) : ✓ 2 A}. We then have the following result, whose proof we provide in Section A.7. Theorem 4. Let ⇥ ⇢ Rd be convex and let `(·; x) be convex and L-Lipshitz for all x 2 X . For constants > 0, > 1, and r > 0, assume that R satisfies R(✓) inf R(✓) dist(✓, S) for all ✓ such that dist(✓, S) r. (14) ✓2⇥ Let t > 0. If 0 ✏ 1 2 r satisfies ✓ ◆ 2( ✓ ◆ 1 ✓ ◆1 r 8L2 ⇢ 1) 2 1 ✏ 2✏ 2✏ 2t ✏ and 2E[Rn (S )] + L , (15) n 2 n 2 then P(Sb✏ ⇢ S 2✏ ) 1 e t , and inequality (15) holds for all ✏ & ( L (t+⇢+d) 2( 2/ n ) 1) . 4 Experiments We present two real classification experiments to carefully compare standard empirical risk minimiza- tion (ERM) to the variance-regularized approach we present. Empirically, we show that the ERM estimator ✓berm performs poorly on rare classes with (relatively) more variance, where the robust solution achieves improved classification performance on rare instances. In all our experiments, this occurs with little expense over the more common instances. 4.1 Protease cleavage experiments For our first experiment, we compare our robust regularization procedure to other regularizers using the HIV-1 protease cleavage dataset from the UCI ML-repository [14]. In this binary classification task, one is given a string of amino acids (a protein) and a featurized representation of the string of dimension d = 50960, and the goal is to predict whether the HIV-1 virus will cleave the amino acid sequence in its central position. We have a sample of n = 6590 observations of this process, where the class labels are somewhat skewed: there are 1360 examples with label Y = +1 (HIV-1 cleaves) and 5230 examples with Y = 1 (does not cleave). 7
8 . (a) test error (b) rare class (Yi = +1) (c) common class (Yi = 1) Figure 1: HIV-1 Protease Cleavage plots (2-standard error confidence bars). Comparison of misclassification test error rates among different regularizers. We use the logistic loss `(✓; (x, y)) = log(1 + exp( y✓> x)). We compare the performance of different constraint sets ⇥ by taking ⇥ = ✓ 2 Rd : a1 k✓k1 + a2 k✓k2 r , which is equivalent to elastic net regularization [27], while varying a1 , a2 , and r. We experiment with `1 -constraints (a1 = 1, a2 = 0) with r 2 {50, 100, 500, 1000, 5000}, `2 -constraints (a1 = 0, a2 = 1) with r 2 {5, 10, 50, 100, 500}, elastic net (a1 = 1, a2 = 10) with r 2 {102 , 2 · 102 , 103 , 2 · 103 , 104 }, our robust regularizer with ⇢ 2 {102 , 103 , 104 , 5 · 104 , 105 } and our robust regularizer coupled with the `1 -constraint (a1 = 1, a2 = 0) with r = 100. Though we use a convex surrogate (logistic loss), we measure performance of the classifiers using the zero-one (misclassification) loss 1{sign(✓T x)y 0}. For validation, we perform 50 experiments, where in each experiment we randomly select 9/10 of the data to train the model, evaluating its performance on the held out 1/10 fraction (test). We plot results summarizing these experiments in Figure 1. The horizontal axis in each figure indexes our choice of regularization value (so “Regularizer = 1” for the `1 -constrained problem corresponds to r = 50). The figures show that the robustly regularized risk provides a different type of protection against overfitting than standard regularization or constraint techniques do: while other regularizers underperform in heavily constrained settings, the robustly regularized estimator ✓bnrob achieves low classification error for all values of ⇢. Notably, even when coupled with a fairly stringent `1 -constraint (r = 100), robust regularization has performance better than `1 except for large values r, especially on the rare label Y = +1. We investigate the effects of the robust regularizer with a slightly different perspective in Table 1, where we use ⇥ = {✓ : k✓k1 100} for the constraint set for each experiment. We give error rates and logistic risk values for the different procedures, averaged over 50 independent runs. We note that all gaps are significant at the 3-standard error level. We see that the ERM solutions achieve good performance on the common class (Y = 1) but sacrifice performance on the uncommon class. As we increase ⇢, performance of the robust solution ✓bnrob on the rarer label Y = +1 improves, while the error rate on the common class degrades a small (insignificant) amount. Table 1: HIV-1 Cleavage Error risk error (%) error (Y = +1) error (Y = 1) ⇢ train test train test train test train test erm 0.1587 0.1706 5.52 6.39 17.32 18.79 2.45 3.17 100 0.1623 0.1763 4.99 5.92 15.01 17.04 2.38 3.02 1000 0.1777 0.1944 4.5 5.92 13.35 16.33 2.19 3.2 10000 0.283 0.3031 2.39 5.67 7.18 14.65 1.15 3.32 4.2 Document classification in the Reuters corpus For our second experiment, we consider a multi-label classification problem with a reasonably large dataset. The Reuters RCV1 Corpus [13] has 804,414 examples with d = 47,236 features, where feature j is an indicator variable for whether word j appears in a given document. The goal is to classify documents as a subset of the 4 categories where documents are labeled with a subset of those. As documents can belong to multiple categories, we fit binary classifiers on each of the four 8
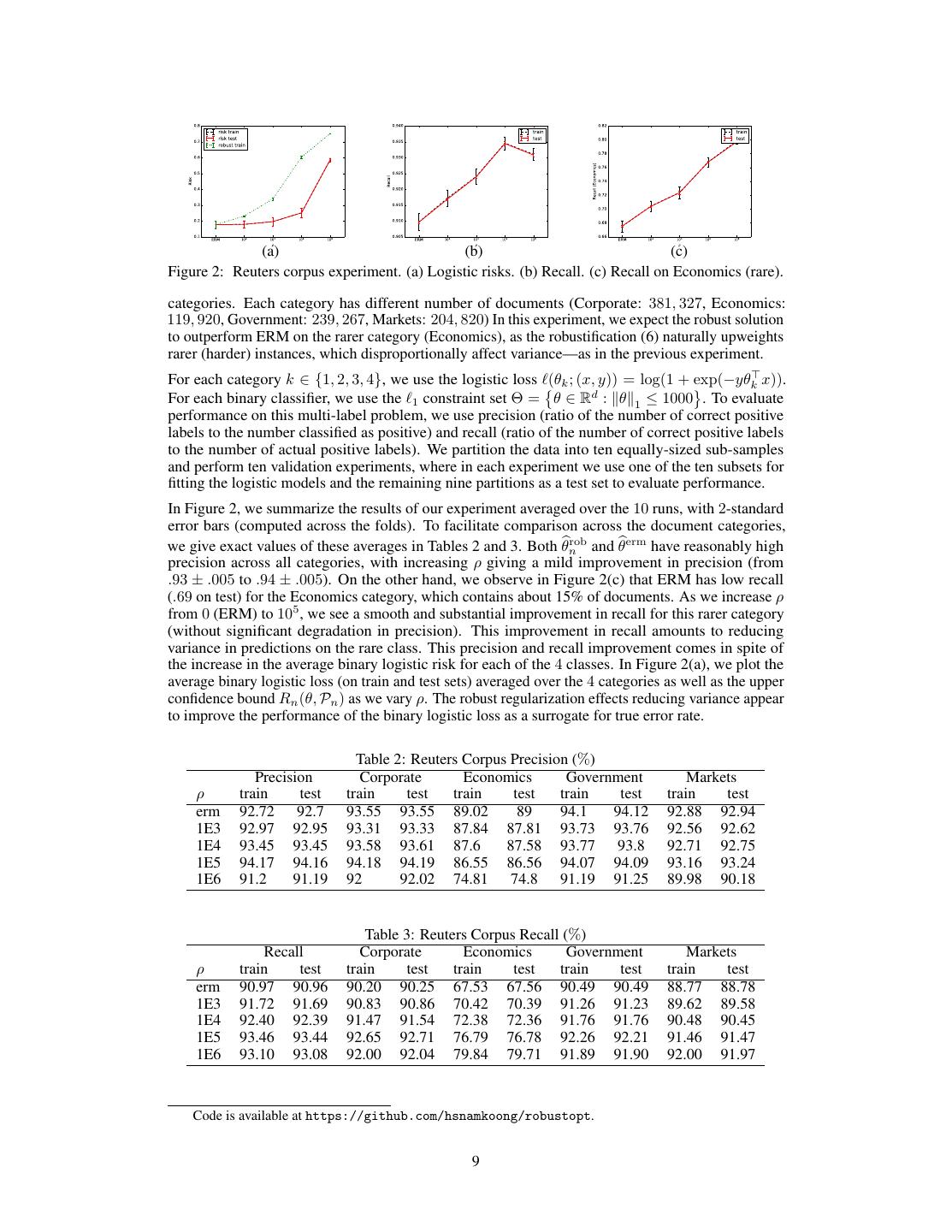
9 . (a) (b) (c) Figure 2: Reuters corpus experiment. (a) Logistic risks. (b) Recall. (c) Recall on Economics (rare). categories. Each category has different number of documents (Corporate: 381, 327, Economics: 119, 920, Government: 239, 267, Markets: 204, 820) In this experiment, we expect the robust solution to outperform ERM on the rarer category (Economics), as the robustification (6) naturally upweights rarer (harder) instances, which disproportionally affect variance—as in the previous experiment. For each category k 2 {1, 2, 3, 4}, we use the logistic loss `(✓k ; (x, y)) = log(1 + exp( y✓k> x)). For each binary classifier, we use the `1 constraint set ⇥ = ✓ 2 Rd : k✓k1 1000 . To evaluate performance on this multi-label problem, we use precision (ratio of the number of correct positive labels to the number classified as positive) and recall (ratio of the number of correct positive labels to the number of actual positive labels). We partition the data into ten equally-sized sub-samples and perform ten validation experiments, where in each experiment we use one of the ten subsets for fitting the logistic models and the remaining nine partitions as a test set to evaluate performance. In Figure 2, we summarize the results of our experiment averaged over the 10 runs, with 2-standard error bars (computed across the folds). To facilitate comparison across the document categories, we give exact values of these averages in Tables 2 and 3. Both ✓bnrob and ✓berm have reasonably high precision across all categories, with increasing ⇢ giving a mild improvement in precision (from .93 ± .005 to .94 ± .005). On the other hand, we observe in Figure 2(c) that ERM has low recall (.69 on test) for the Economics category, which contains about 15% of documents. As we increase ⇢ from 0 (ERM) to 105 , we see a smooth and substantial improvement in recall for this rarer category (without significant degradation in precision). This improvement in recall amounts to reducing variance in predictions on the rare class. This precision and recall improvement comes in spite of the increase in the average binary logistic risk for each of the 4 classes. In Figure 2(a), we plot the average binary logistic loss (on train and test sets) averaged over the 4 categories as well as the upper confidence bound Rn (✓, Pn ) as we vary ⇢. The robust regularization effects reducing variance appear to improve the performance of the binary logistic loss as a surrogate for true error rate. Table 2: Reuters Corpus Precision (%) Precision Corporate Economics Government Markets ⇢ train test train test train test train test train test erm 92.72 92.7 93.55 93.55 89.02 89 94.1 94.12 92.88 92.94 1E3 92.97 92.95 93.31 93.33 87.84 87.81 93.73 93.76 92.56 92.62 1E4 93.45 93.45 93.58 93.61 87.6 87.58 93.77 93.8 92.71 92.75 1E5 94.17 94.16 94.18 94.19 86.55 86.56 94.07 94.09 93.16 93.24 1E6 91.2 91.19 92 92.02 74.81 74.8 91.19 91.25 89.98 90.18 Table 3: Reuters Corpus Recall (%) Recall Corporate Economics Government Markets ⇢ train test train test train test train test train test erm 90.97 90.96 90.20 90.25 67.53 67.56 90.49 90.49 88.77 88.78 1E3 91.72 91.69 90.83 90.86 70.42 70.39 91.26 91.23 89.62 89.58 1E4 92.40 92.39 91.47 91.54 72.38 72.36 91.76 91.76 90.48 90.45 1E5 93.46 93.44 92.65 92.71 76.79 76.78 92.26 92.21 91.46 91.47 1E6 93.10 93.08 92.00 92.04 79.84 79.71 91.89 91.90 92.00 91.97 Code is available at https://github.com/hsnamkoong/robustopt. 9
10 .Acknowledgments We thank Feng Ruan for pointing out a much simpler proof of Theorem 1 than in our original paper. JCD and HN were partially supported by the SAIL-Toyota Center for AI Research and HN was partially supported Samsung Fellowship. JCD was also partially supported by the National Science Foundation award NSF-CAREER-1553086 and the Sloan Foundation. References [1] P. L. Bartlett and S. Mendelson. Rademacher and Gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3:463–482, 2002. [2] P. L. Bartlett, O. Bousquet, and S. Mendelson. Local Rademacher complexities. Annals of Statistics, 33(4): 1497–1537, 2005. [3] P. L. Bartlett, M. I. Jordan, and J. McAuliffe. Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101:138–156, 2006. [4] A. Ben-Tal, D. den Hertog, A. D. Waegenaere, B. Melenberg, and G. Rennen. Robust solutions of optimization problems affected by uncertain probabilities. Management Science, 59(2):341–357, 2013. [5] D. Bertsimas, V. Gupta, and N. Kallus. Robust SAA. arXiv:1408.4445 [math.OC], 2014. URL http: //arxiv.org/abs/1408.4445. [6] S. Boucheron, O. Bousquet, and G. Lugosi. Theory of classification: a survey of some recent advances. ESAIM: Probability and Statistics, 9:323–375, 2005. [7] S. Boucheron, G. Lugosi, and P. Massart. Concentration Inequalities: a Nonasymptotic Theory of Independence. Oxford University Press, 2013. [8] S. Boyd and L. Vandenberghe. Convex Optimization. Cambridge University Press, 2004. [9] J. C. Duchi, S. Shalev-Shwartz, Y. Singer, and T. Chandra. Efficient projections onto the `1 -ball for learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning, 2008. [10] J. C. Duchi, P. W. Glynn, and H. Namkoong. Statistics of robust optimization: A generalized empirical likelihood approach. arXiv:1610.03425 [stat.ML], 2016. URL https://arxiv.org/abs/1610.03425. [11] J. Hiriart-Urruty and C. Lemaréchal. Convex Analysis and Minimization Algorithms I & II. Springer, New York, 1993. [12] V. Koltchinskii. Local Rademacher complexities and oracle inequalities in risk minimization. Annals of Statistics, 34(6):2593–2656, 2006. [13] D. Lewis, Y. Yang, T. Rose, and F. Li. RCV1: A new benchmark collection for text categorization research. Journal of Machine Learning Research, 5:361–397, 2004. [14] M. Lichman. UCI machine learning repository, 2013. URL http://archive.ics.uci.edu/ml. [15] E. Mammen and A. B. Tsybakov. Smooth discrimination analysis. Annals of Statistics, 27:1808–1829, 1999. [16] A. Maurer and M. Pontil. Empirical Bernstein bounds and sample variance penalization. In Proceedings of the Twenty Second Annual Conference on Computational Learning Theory, 2009. [17] S. Mendelson. Learning without concentration. In Proceedings of the Twenty Seventh Annual Conference on Computational Learning Theory, 2014. [18] H. Namkoong and J. C. Duchi. Stochastic gradient methods for distributionally robust optimization with f -divergences. In Advances in Neural Information Processing Systems 29, 2016. [19] A. B. Owen. Empirical likelihood. CRC press, 2001. [20] P. Samson. Concentration of measure inequalities for Markov chains and -mixing processes. Annals of Probability, 28(1):416–461, 2000. [21] A. Shapiro, D. Dentcheva, and A. Ruszczy´nski. Lectures on Stochastic Programming: Modeling and Theory. SIAM and Mathematical Programming Society, 2009. [22] A. B. Tsybakov. Optimal aggregation of classifiers in statistical learning. Annals of Statistics, pages 135–166, 2004. [23] A. B. Tsybakov. Introduction to Nonparametric Estimation. Springer, 2009. [24] A. W. van der Vaart and J. A. Wellner. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, New York, 1996. [25] V. N. Vapnik. Statistical Learning Theory. Wiley, 1998. [26] V. N. Vapnik and A. Y. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. Theory of Probability and its Applications, XVI(2):264–280, 1971. [27] H. Zou and T. Hastie. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B, 67(2):301–320, 2005. [28] A. Zubkov and A. Serov. A complete proof of universal inequalities for the distribution function of the binomial law. Theory of Probability & Its Applications, 57(3):539–544, 2013. 10
相关推荐
3秒后跳转登录页面
去登陆

