










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
LinuxCon18_Share_Virtual_Address
Shared Virtual Addressing (SVA) means share process address spaces with devices. It is also called Shared Virtual Memory(SVM) by OpenCL and some IOMMU architectures. Sharing process address spaces with devices allows to rely on core kernel memory management for DMA, i.e. after apply SVA, device is able to perform DMA on buffers obtained with simple malloc by using the points it return, which highly remove some complexity from application and device drivers, especially when device DMA buffer use the advance data structure like list, tree or graph. Meanwhile, based on device’s IO page fault, the device can use memory on demand, which can reduce the use of memory.
展开查看详情
1 .Share Virtual Address www.huawei.com Yisheng Xie/ xieyisheng1@hauwei.com Bob Liu / liubo95@Huawei.com HUAWEI TECHNOLOGIES CO., LTD.
2 .Agenda What is SVA? Why SVA ? How SVA works? Our works Upstream status page 2
3 .What is SVA?(cont.) SVA (Share Virtual Address) means device use the same virtual address with CPU which get the same thing. But they may have different achievement in HW and SW. DMAR (IOMMU, SMMU) or MMU Use the same page table or not Same physical address or not Support zero copy or not Support IO-Page Fault or not page 3
4 .What is SVA? Intel - SVM (Share Virtual Memory) : CPU access DDR through MMU Device access DDR through IOMMU MMU share the same page table with IOMMU (used by AMD’s Secure Virtual Machine in Linux) CPU Device VA VA IOMMU PASID MMU (Vt-d) B ATS ATC U S PageTable DDR PCIe page 4
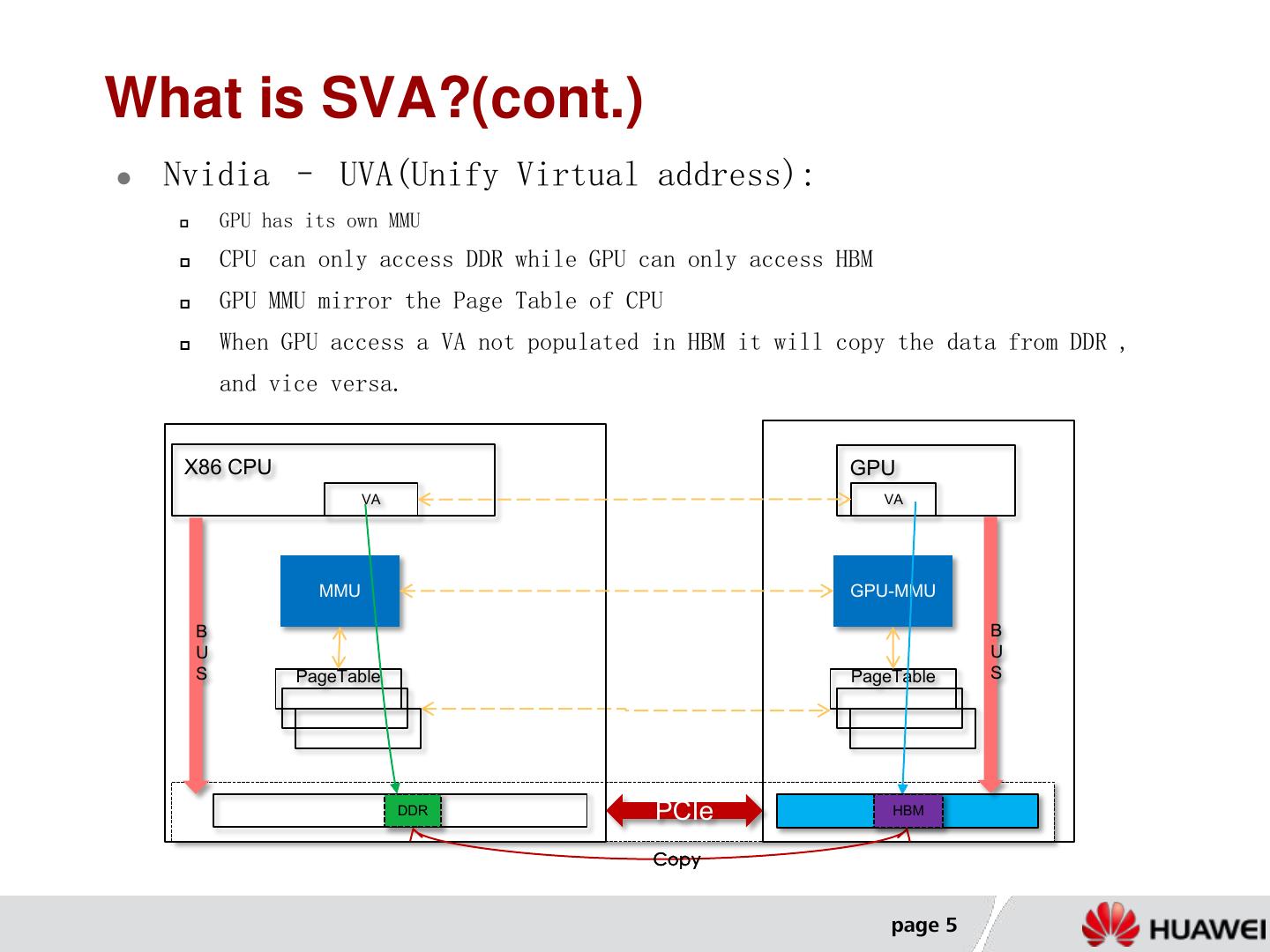
5 .What is SVA?(cont.) Nvidia – UVA(Unify Virtual address): GPU has its own MMU CPU can only access DDR while GPU can only access HBM GPU MMU mirror the Page Table of CPU When GPU access a VA not populated in HBM it will copy the data from DDR , and vice versa. X86 CPU GPU VA VA MMU GPU-MMU B B U U S PageTable PageTable S DDR PCIe HBM HBM Copy page 5
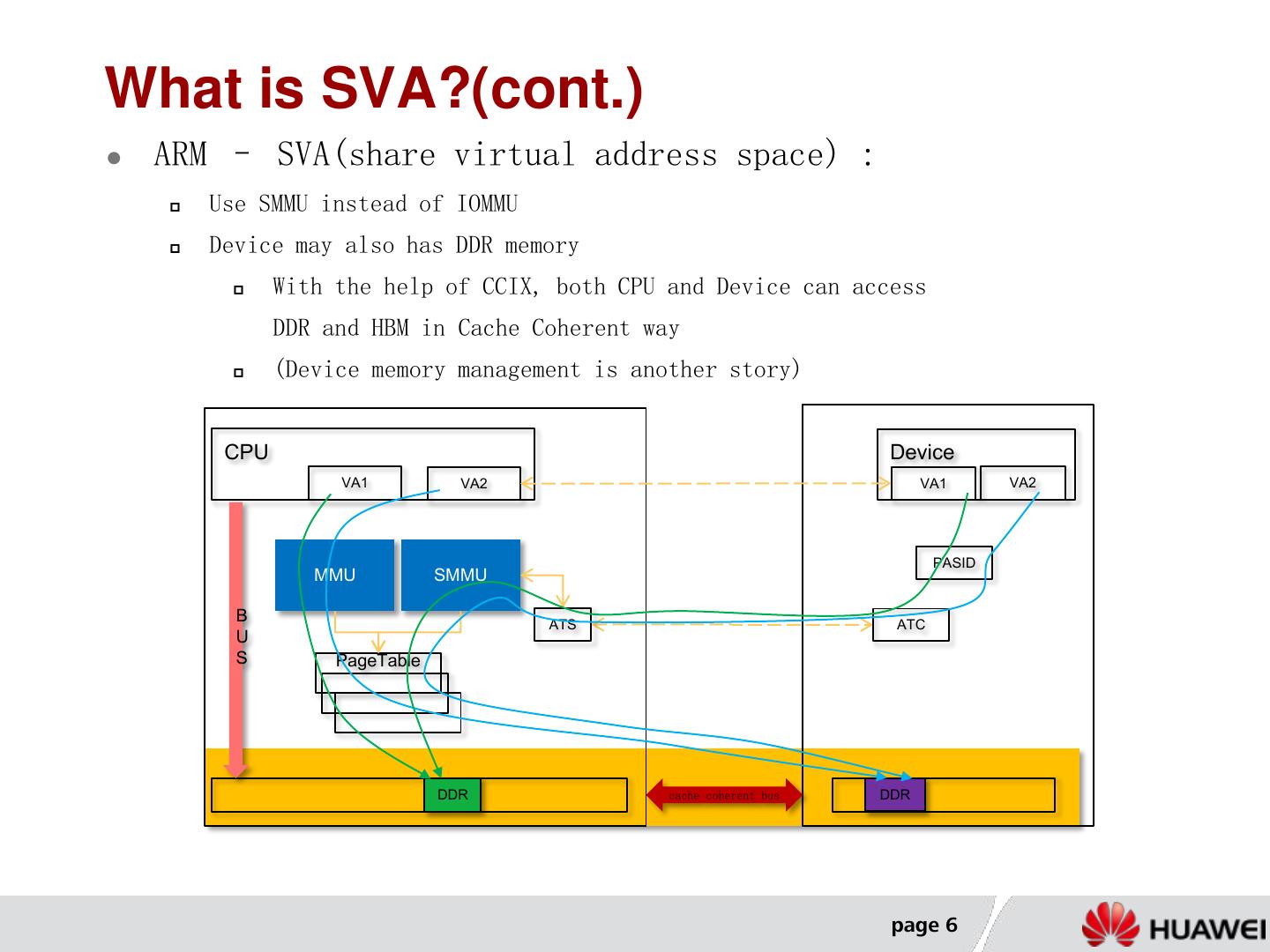
6 .What is SVA?(cont.) ARM – SVA(share virtual address space) : Use SMMU instead of IOMMU Device may also has DDR memory With the help of CCIX, both CPU and Device can access DDR and HBM in Cache Coherent way (Device memory management is another story) CPU Device VA1 VA2 VA1 VA2 PASID MMU SMMU B ATS ATC U S PageTable DDR cache coherent bus DDR page 6
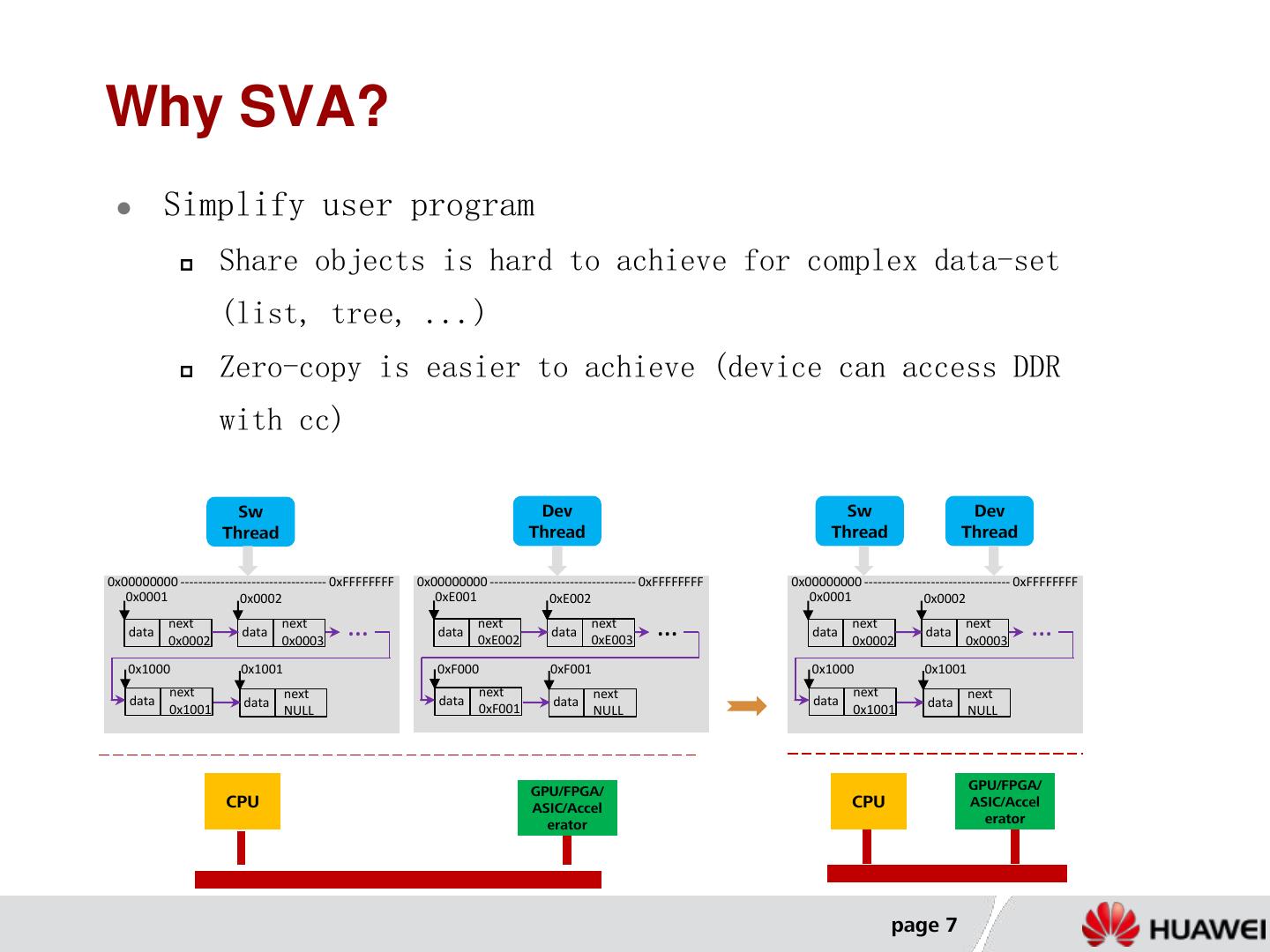
7 .Why SVA? Simplify user program Share objects is hard to achieve for complex data-set (list, tree, ...) Zero-copy is easier to achieve (device can access DDR with cc) Sw Dev Sw Dev Thread Thread Thread Thread 0x00000000 --------------------------------- 0xFFFFFFFF 0x00000000 --------------------------------- 0xFFFFFFFF 0x00000000 --------------------------------- 0xFFFFFFFF 0x0001 0x0002 0xE001 0xE002 0x0001 0x0002 data next 0x0002 data next 0x0003 … data next 0xE002 data next 0xE003 … data next 0x0002 data next 0x0003 … 0x1000 0x1001 0xF000 0xF001 0x1000 0x1001 next next next next next next data data data data data data 0x1001 NULL 0xF001 NULL 0x1001 NULL GPU/FPGA/ GPU/FPGA/ CPU ASIC/Accel CPU ASIC/Accel erator erator page 7
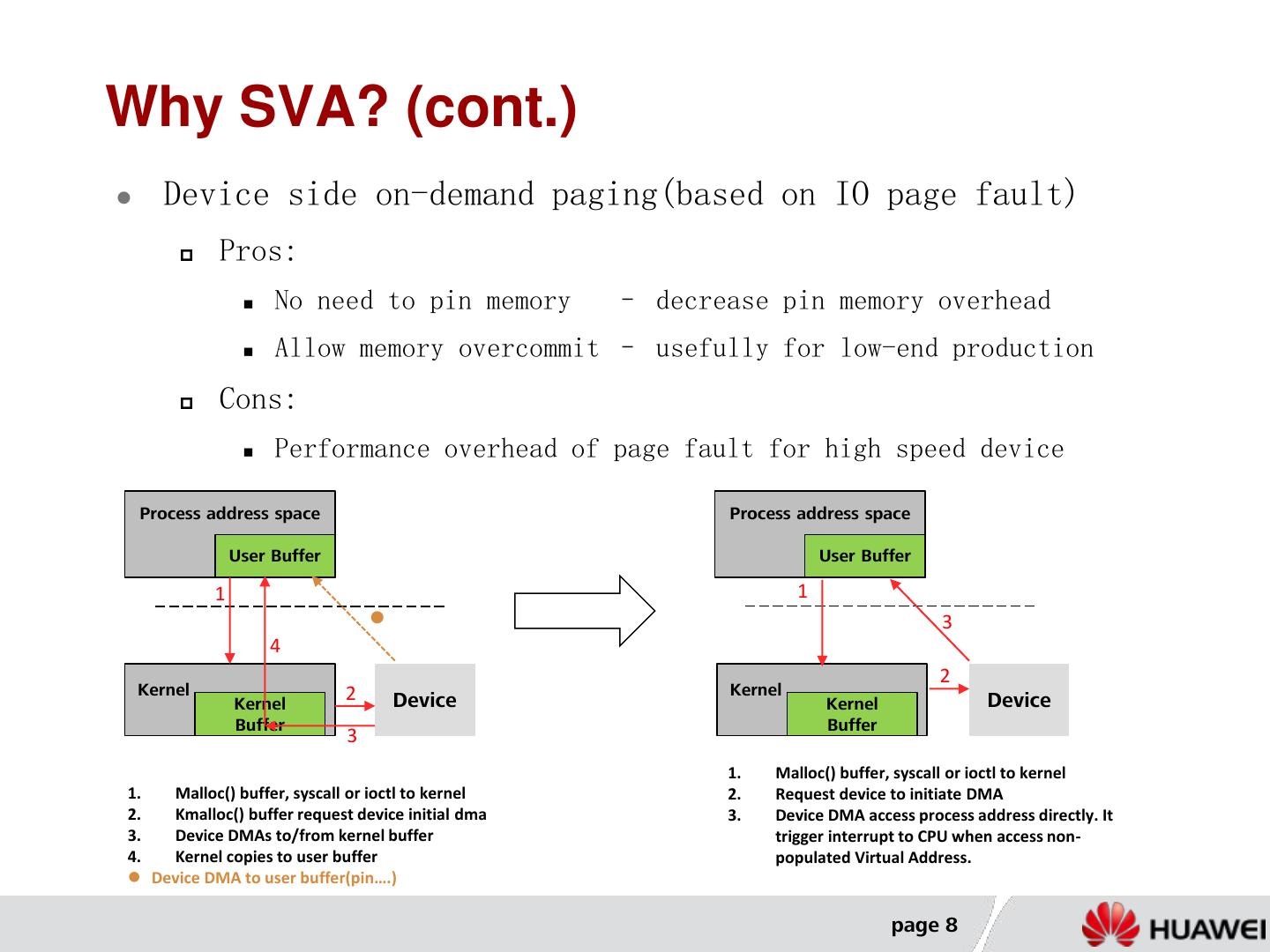
8 .Why SVA? (cont.) Device side on-demand paging(based on IO page fault) Pros: No need to pin memory – decrease pin memory overhead Allow memory overcommit – usefully for low-end production Cons: Performance overhead of page fault for high speed device Process address space Process address space User Buffer User Buffer 1 1 3 4 2 Kernel 2 Kernel Kernel Device Kernel Device Buffer Buffer 3 1. Malloc() buffer, syscall or ioctl to kernel 1. Malloc() buffer, syscall or ioctl to kernel 2. Request device to initiate DMA 2. Kmalloc() buffer request device initial dma 3. Device DMA access process address directly. It 3. Device DMAs to/from kernel buffer trigger interrupt to CPU when access non- 4. Kernel copies to user buffer populated Virtual Address. Device DMA to user buffer(pin….) page 8
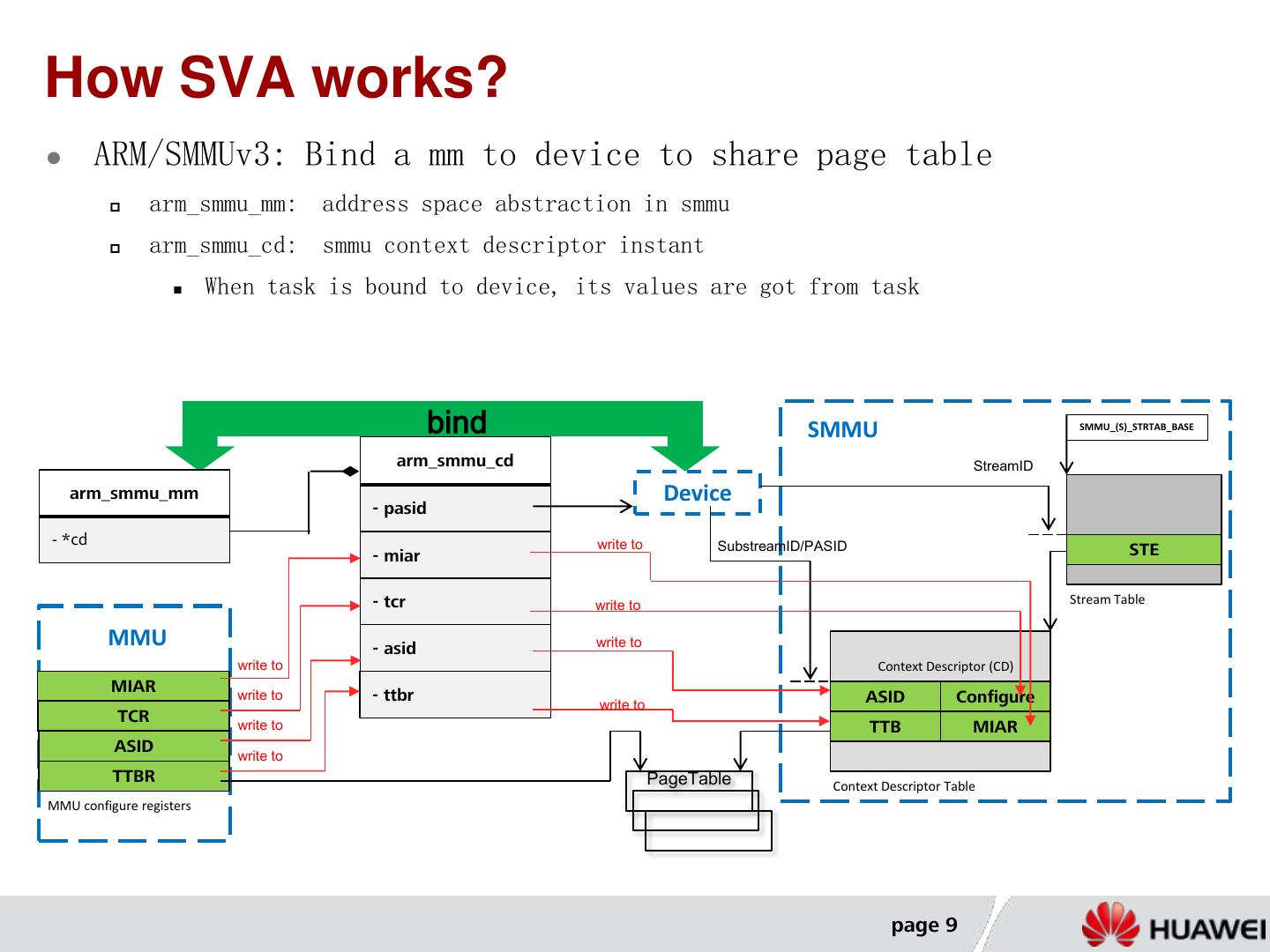
9 .How SVA works? ARM/SMMUv3: Bind a mm to device to share page table arm_smmu_mm: address space abstraction in smmu arm_smmu_cd: smmu context descriptor instant When task is bound to device, its values are got from task bind SMMU SMMU_(S)_STRTAB_BASE arm_smmu_cd StreamID arm_smmu_mm Device - pasid - *cd write to SubstreamID/PASID - miar STE - tcr write to Stream Table MMU - asid write to write to Context Descriptor (CD) MIAR write to - ttbr write to ASID Configure TCR write to TTB MIAR ASID write to TTBR PageTable Context Descriptor Table MMU configure registers page 9
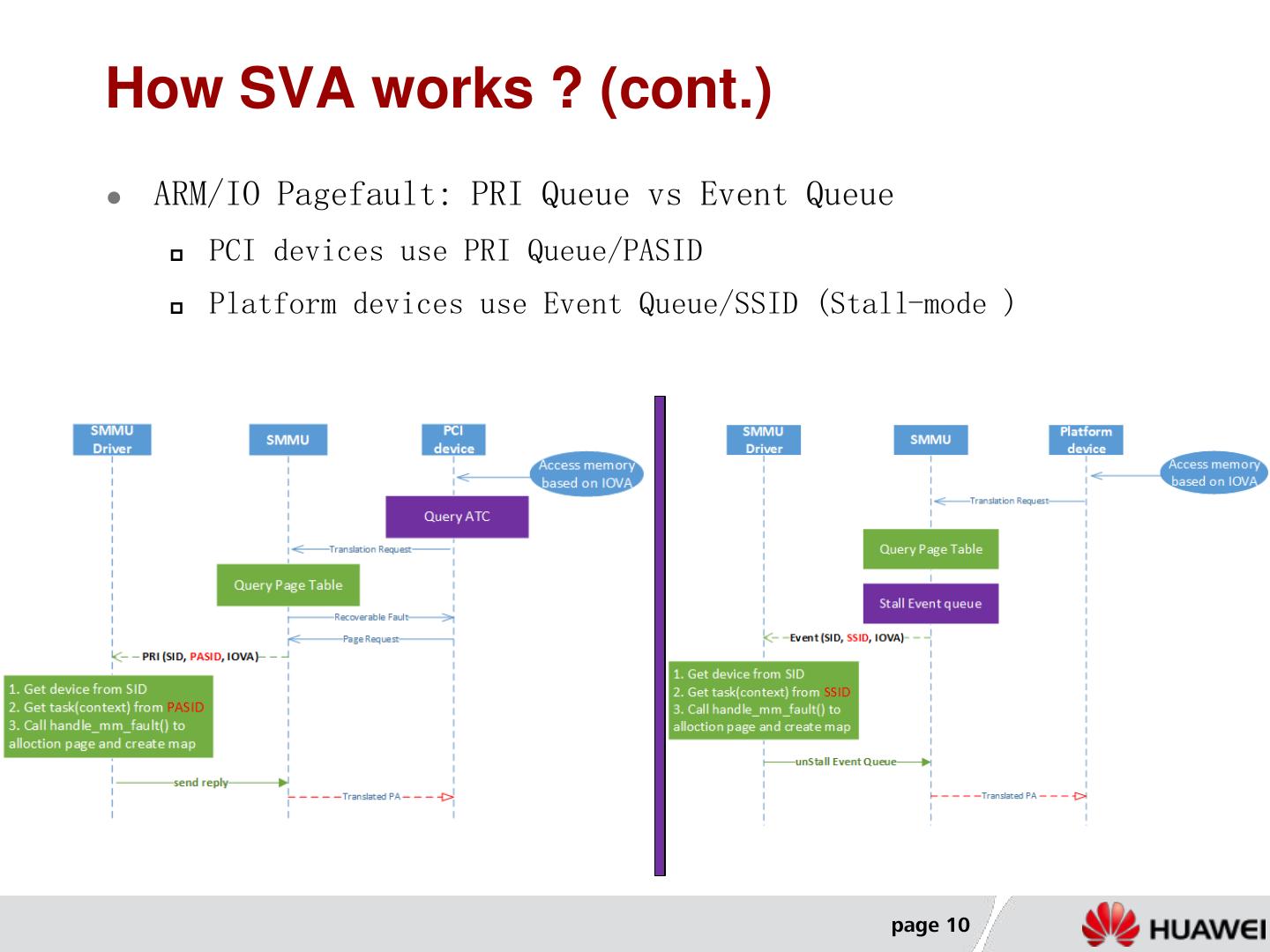
10 .How SVA works ? (cont.) ARM/IO Pagefault: PRI Queue vs Event Queue PCI devices use PRI Queue/PASID Platform devices use Event Queue/SSID (Stall-mode ) page 10
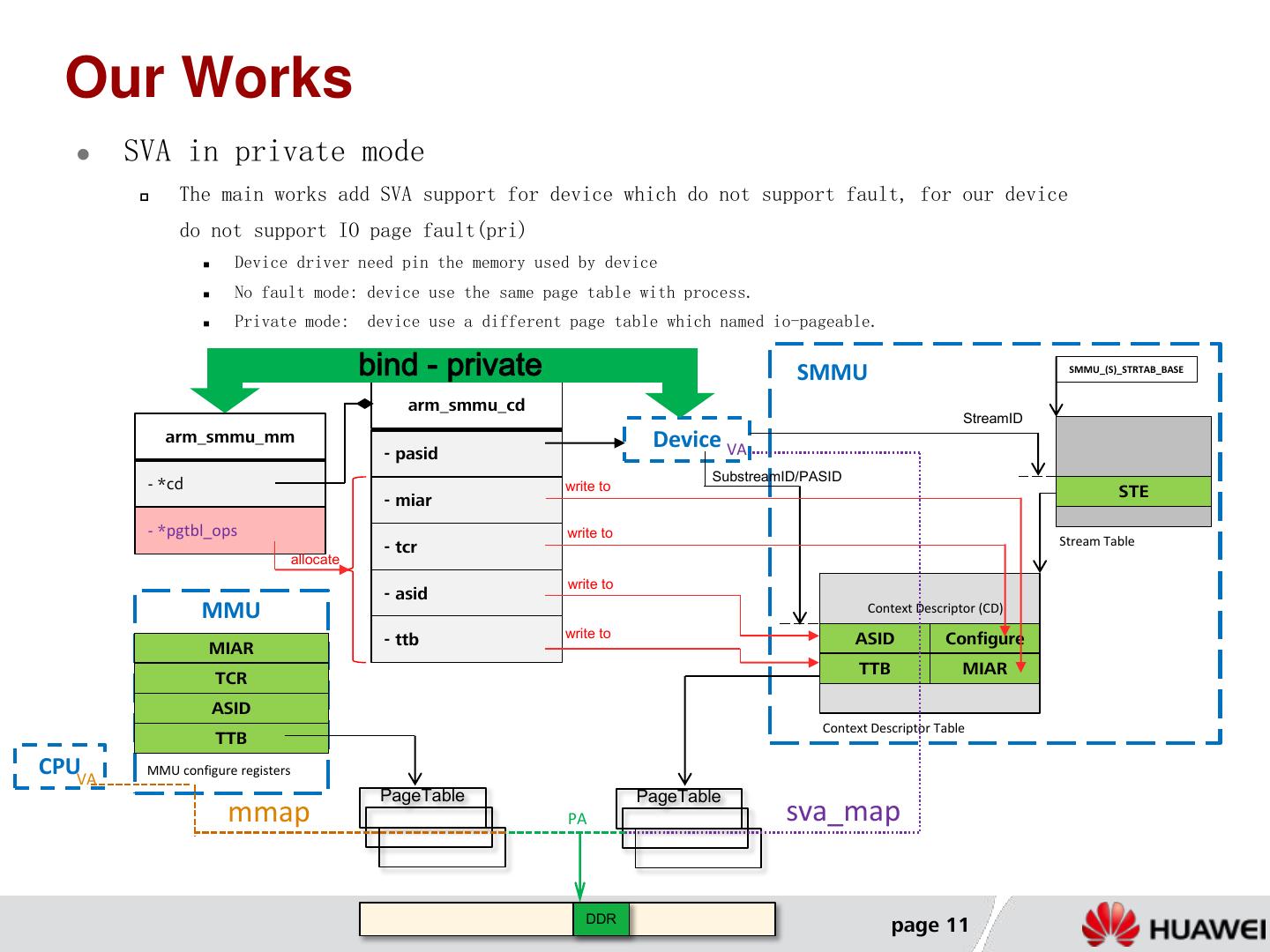
11 . Our Works SVA in private mode The main works add SVA support for device which do not support fault, for our device do not support IO page fault(pri) Device driver need pin the memory used by device No fault mode: device use the same page table with process. Private mode: device use a different page table which named io-pageable. bind - private SMMU SMMU_(S)_STRTAB_BASE arm_smmu_cd StreamID arm_smmu_mm Device VA - pasid SubstreamID/PASID - *cd write to STE - miar - *pgtbl_ops write to - tcr Stream Table allocate write to - asid MMU Context Descriptor (CD) - ttb write to ASID Configure MIAR TTB MIAR TCR ASID Context Descriptor Table TTB CPUVA MMU configure registers PageTable PageTable mmap PA sva_map DDR page 11
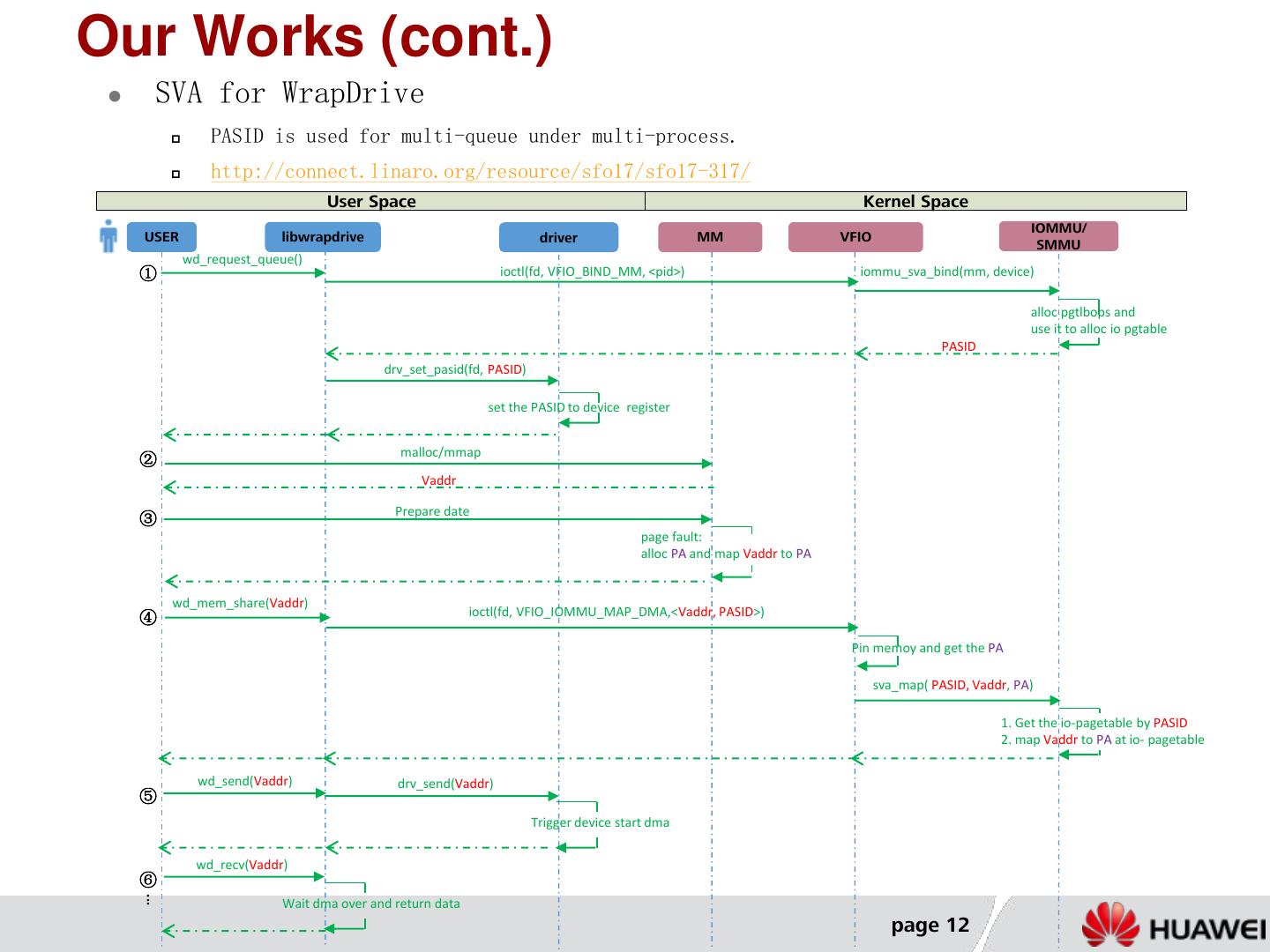
12 .Our Works (cont.) SVA for WrapDrive PASID is used for multi-queue under multi-process. http://connect.linaro.org/resource/sfo17/sfo17-317/ User Space Kernel Space IOMMU/ USER libwrapdrive driver MM VFIO SMMU wd_request_queue() ① ioctl(fd, VFIO_BIND_MM, <pid>) iommu_sva_bind(mm, device) alloc pgtlbops and use it to alloc io pgtable PASID drv_set_pasid(fd, PASID) set the PASID to device register malloc/mmap ② Vaddr Prepare date ③ page fault: alloc PA and map Vaddr to PA wd_mem_share(Vaddr) ④ ioctl(fd, VFIO_IOMMU_MAP_DMA,<Vaddr, PASID>) Pin memoy and get the PA sva_map( PASID, Vaddr, PA) 1. Get the io-pagetable by PASID 2. map Vaddr to PA at io- pagetable wd_send(Vaddr) drv_send(Vaddr) ⑤ Trigger device start dma wd_recv(Vaddr) ⑥ ... Wait dma over and return data page 12
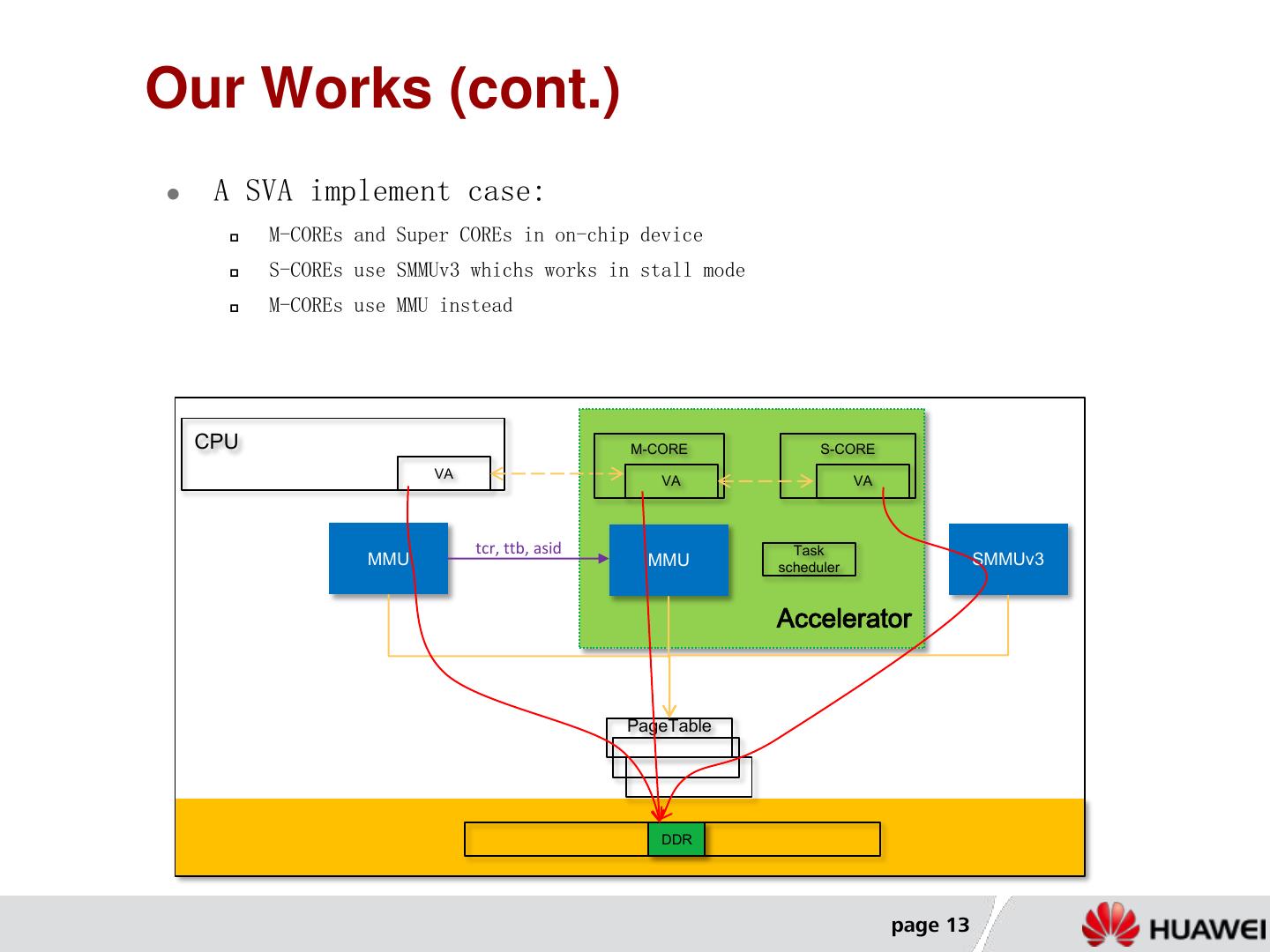
13 .Our Works (cont.) A SVA implement case: M-COREs and Super COREs in on-chip device S-COREs use SMMUv3 whichs works in stall mode M-COREs use MMU instead CPU M-CORE S-CORE VA VA VA PASID tcr, ttb, asid Task MMU MMU scheduler SMMUv3 Accelerator PageTable DDR page 13
14 .Our Works (cont.) User Space Kernel Space Hardware/ Accelerator IOMMU/SMMU Task S-CORE M-CORE USER MM SVA Driver Driver Scheduler malloc/mmap ① Vaddr Prepare date ② page fault: alloc PA and map Vaddr to PA ioctrl(fd, <pid>, TASK_BIND….) ③ 1. Get task’s mm from pid 2. Alloc sva_mm to tack the mm 3. Get ASID from task’s mm 4. Get pgd(TTB) from task’s mm 5. Get TCR from system reg iommu_sva_bind(mm, device) PASID; (ASID, TTB, TCR) PASID ioctrl (fd, OFFLOAD_TASK, <Vaddr, PASID, ASID,TTB, TCR>) case 1: dispatch to Super CORE ④ with Vaddr, PASID IO page fault from Super CORE: Vaddr, PASID 1. get mm from PASID 2. handle_mm_fault(mm, Vaddr) reply ok case 2: dispatch to Normal CORE with Vaddr, ASID, TTB, TCR IO page fault from Normal CORE: Vaddr, ASID 1. Get mm ASID 2. handle_mm_fault(mm, Vaddr) reply ok free/munmap (Vaddr) ⑤ page 14
15 .Upstream status SVA for SMMUv3 RFC1: [RFC PATCH 00/30] Add PCIe SVM support to ARM SMMUv3 Only works for PCIE pri RFC2: [RFCv2 PATCH 00/36] Process management for IOMMU + SVM for SMMUv3 Add support of stall mode for platform device V1/V2: [PATCH v2 00/40] Shared Virtual Addressing for the IOMMU Only support devices which have IO-Page Fault ability. Our works is in upstream plan, which will be coming soon... page 15
16 .Thank you
17 . Huawei OS Kernel Lab Huawei Operating System R&D Department - OS Kernel Lab Linux Kernel (ARM/x86/ heterogeneous platforms) R&D and Innovation R&D on a Next-generation OS kernel with Low Latency, High Security, Strong Reliability, Intelligence, etc. Job Vacancy Contact us Next-generation Operating System Researcher and Senior Engineer Tel: Mr. Wang/18658102676 Formal Verification Researcher and Senior Engineer Email:hr.kernel@huawei.com Linux Kernel Architect and Senior Engineer Locations Hangzhou, Beijing, Shanghai page 17
相关推荐
3秒后跳转登录页面
去登陆

