A Novel Flow Network Graph Based Scheduling Approach in K8S
分享
点赞
10
收藏
1
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
 圆圆
圆圆
/
发布于
/
2282
人观看
Today’s Kubernetes clusters can comprise of 5,000-10,000 nodes, increase by an order of magnitude from original design specs. The default Kubernetes scheduler dates back from earlier more modest deployments. It is queue-based, processing unscheduled pods in a sequential fashion. For a large Kubernetes cluster, such scheduler processing logic can introduce long, even unbounded scheduling latencies, negatively affecting overall throughput for workload deployments.
This talk outlines how Kubernetes is a victim of its own success, scheduling-wise. It lays out the current pod queuing challenges and describes a novel scheduling approach based on Flow Network Graph technique, enabling low workload scheduling latencies at scale.
展开查看详情
1 .A Novel Flow Network Graph Based
Scheduling Approach in Kubernetes
@kevin-wangzefeng
wangzefeng@huawei.com
�
2 .Agenda
• Scheduling in K8S
• The Default Scheduler
• Firmament & Poseidon
• Future plans
�
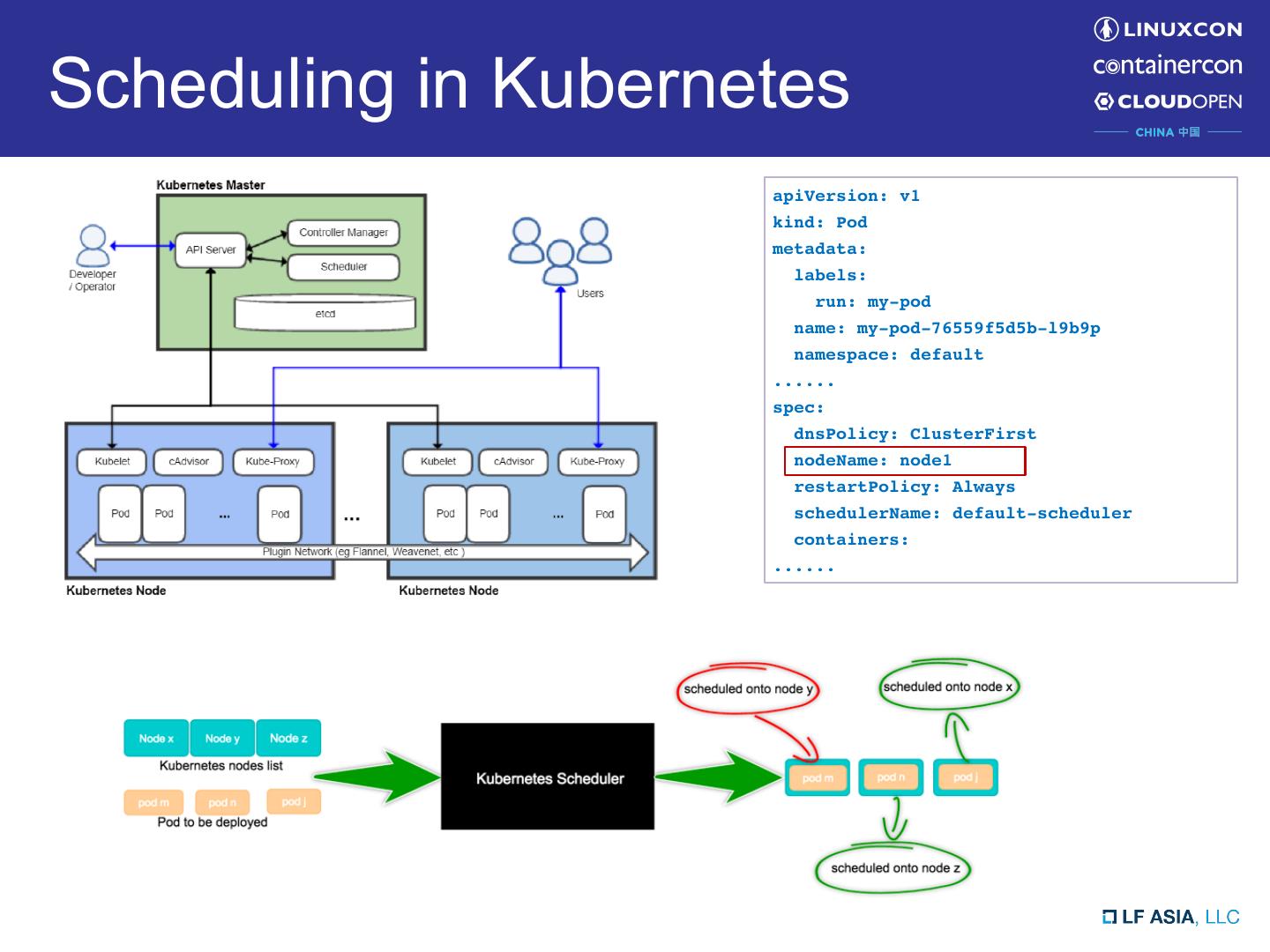
3 .Scheduling in Kubernetes
apiVersion: v1
kind: Pod
metadata:
labels:
run: my-pod
name: my-pod-76559f5d5b-l9b9p
namespace: default
......
spec:
dnsPolicy: ClusterFirst
nodeName: node1
restartPolicy: Always
schedulerName: default-scheduler
containers:
......
�
4 . The default scheduler
• Queue based
– one pod one time
– best fit (scheduling time)
• Resource allocation model
– Request based, not real-time
usage
– Low utilization (due to uncertain
user resource estimation)
• Policies implemented as two
sets of algorithms:
– Predicates
– Priorities
�
5 .What is Firmament
• Flow based scheduler
– Models workloads and cluster as a flow network (DAG)
– Policies considered at DAG build / update
– Run Min-Cost Max-Flow (MCMF) solver to find an optimal flow
– Scheduling results extracted from the optimal flow
�
6 .diff Firmament Kube-scheduler
• Similar to default scheduler
– “Global optimal solution”
– Pluggable scheduling policies
• That makes differences
– Flexible resource modeling, easy to extend to support topology (zones, racks,
NUMA, etc.)
– Built-in support with rescheduling, priority and preemption
– And a set of other cost models:
• network-ware, Quincy, load-spreading etc.
– Low decision latency at scale
• sub-second decisions at 10k+ machines
– batching approach
– By default use resource utilization instead of reservation
�
7 .Flow network example in Firmament
• Flow network
- 4 machine cluster, 2 jobs (3 tasks and 2
tasks).
• Arc labels show non-zero costs
- (values depends on policies.)
• All arcs have unit capacity
- except those between unscheduled
aggregators and the sink.
• The red arcs carry flow and form the
min-cost solution.
- All tasks except T0,1 are scheduled on
machines.
�
8 .And Poseidon?
To fill the gaps between K8S and Kubernetes Heapster
Firmament
API server Poseidon sink
• Different concepts s
at
st
Node/pod
n
bindings
– K8S: workloads, pods
events
tio
Pod
z a
ili
– Firmament: jobs, tasks ut
• Different language Utilization stats
gRPC service
– K8S: Golang
– Firmament: C++ Poseidon
Scheduling
Utilization
Node/task
decisions
• Resource Requests v.s. Real-
events
stats
time utilization
– K8S: allocate by requests and “un-
claimed” Firmament
– Firmament: utilization statistics gRPC service
�
9 .Poseidon Design
Kubernetes API server Heapster
Utilization
events
events
bindings
Node
stats
Pod
Pod
Poseidon
Node watcher Pod watcher
Utilization
Scheduler loop statistics gRPC
Node keyed Pod keyed
service
queue queue
Node worker pool Pod worker pool
Scheduling
Utilization
decisions
Schedule
events
events
tasks
Node
stats
Task
Firmament gRPC
service
�
10 .Flow Network aligned to Kubernetes Concept
Node
Affinit
P0 y
2
20 N0
7
R0
P1 3
N1
P2
5
C S
N2
ty
ini
R1
P3
A f f
5
ode N3
N
9
P4
U
15
�
11 .Status and Progress
• Incubating under K8S scheduler SIG
– https://github.com/kubernetes-sigs/poseidon
– Currently Alpha (v0.3)
– Support CPU/Memory Cost model
– Node Affinity/Anti-Affinity
– Pod Affinity/Anti-Affinity
– Automation for E2E tests, PR process etc.
– and more…
�
12 .30X algorithmic throughput
No Nodes Pods Poseidon Default Scheduler
1 200 3800 26027 761
2 400 7600 15200 361
3 600 11400 12351 265
�
13 .Future plans
• Under development
– Max allowed pods for nodes.
– Taints & Tolerations.
– Another round of benchmarking for scalabilities, performances.
• Longer future:
– Transitioning to Metrics server API (Heapster is going to be deprecated).
– High Availability / Failover for in-memory Firmament/Poseidon processes.
– Priority Pre-emption support.
– Gang Scheduling.
– Resource Utilization benchmark.
– Better cooperating with the default scheduler. (enhancements on multi-scheduler
framework)
– Checkout https://github.com/kubernetes-sigs/poseidon/issues for more…
�
14 .Join us!
• Scheduling SIG
– https://groups.google.com/forum/#!forum/kubernetes-sig-
scheduling
• Poseidon Project
– https://github.com/kubernetes-sigs/poseidon
• Follow Huawei Container team
on WeChat
�