









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
同步(续)
锁的实现方式和使用,信号量的用途,监视器的概念。
展开查看详情
1 . Goals for Today • Synchronization (Con’t) CS194-24 – Locks Advanced Operating Systems – Semaphores Structures and Implementation – Monitors Lecture 8 Interactive is important! Synchronization Continued Ask Questions! February 19th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.2 Recall: Using Locks to Protect Shared Variable Naïve use of Interrupt Enable/Disable • Consider Previous Example: • How can we build multi-instruction atomic operations? Deposit(acctId, amount) { – Scheduler gets control in two ways. Acquire(depositlock); » Internal: Thread does something to relinquish the CPU acct = GetAccount(actId); » External: Interrupts cause dispatcher to take CPU acct->balance += amount; Critical Section – On a uniprocessor, can avoid context-switching by: StoreAccount(acct); » Avoiding internal events (although virtual memory tricky) Release(depositlock); » Preventing external events by disabling interrupts } • Consequently, naïve Implementation of locks: • Locking Behavior: LockAcquire { disable Ints; } – Only one critical section can be running at once! LockRelease { enable Ints; } » Second Acquire() before release second thread waits • Problems with this approach: – As soon as Release() occurs, another Acquire() can happen – Can’t let user do this! Consider following: LockAcquire(); – If many threads request lock acquisition at same time: While(TRUE) {;} » Might get livelock, depending on what happens on Release() – Real-Time system—no guarantees on timing! • Result of using locks: three instructions in critical » Critical Sections might be arbitrarily long section become Atomic! (cannot be separated) – What happens with I/O or other important events? » “Reactor about to meltdown. Help?” 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.3 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.4
2 . Better Implementation of Locks by Disabling Interrupts? Typical Linux Interfaces • Key idea: maintain a lock variable and impose mutual • Disabling and Enabling Interrupts on the Linux Kernel: exclusion only during operations on that variable local_irq_disable(); /* interrupts are disabled ... */ local_irq_enable(); int value = FREE; – These operations often single assembly instructions » They only work for local processor! Acquire() { Release() { » If competing with another processor, must use other form of disable interrupts; disable interrupts; synchronization if (value == BUSY) { if (anyone on wait queue) { – Dangerous if called when interrupts already disabled put thread on wait queue; take thread off wait queue » Then, when you code reenables, you will change semantics Place on ready queue; Go to sleep(); } else { • Saving and restoring interrupt state first: // Enable interrupts? unsigned long flags; } else { value = FREE; } value = BUSY; enable interrupts; local_irq_save(flags); // Save state } } /* Do whatever, including disable/enable*/ enable interrupts; local_irq_restore(flags); // Restore } • State of the system in_interrupt(); // In handler or bottom half in_irq(); // Specifically in handler 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.5 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.6 How to implement locks? Linux Interrupt control (Con’t) Atomic Read-Modify-Write instructions • No more global cli()! • Problem with previous solution? – Used to be that cli()/sti() could be used to enable and – Can’t let users disable interrupts! (Why?) disable interrupts on all processors – Doesn’t work well on multiprocessor – First deprecated (2.5), then removed (2.6) » Disabling interrupts on all processors requires messages » Could serialize device drivers across all processors! and would be very time consuming » Just a bad idea • Alternative: atomic instruction sequences – Better option? – These instructions read a value from memory and write » Fine-grained spin-locks between processors (more later) a new value atomically » Local interrupt control for local processor – Hardware is responsible for implementing this correctly • Disabling specific interrupt (nestable) » on both uniprocessors (not too hard) disable_irq(irq); // Wait current handlers » and multiprocessors (requires help from cache coherence disable_irq_nosync(irq); // Don’t wait current handler protocol) enable_irq(irq); // Reenable line synchronize_irq(irq); // Wait for current handler – Unlike disabling interrupts, can be used on both – Not great for buses with multiple interrupts per line, such as uniprocessors and multiprocessors PCI! More when we get into device drivers. 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.7 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.8
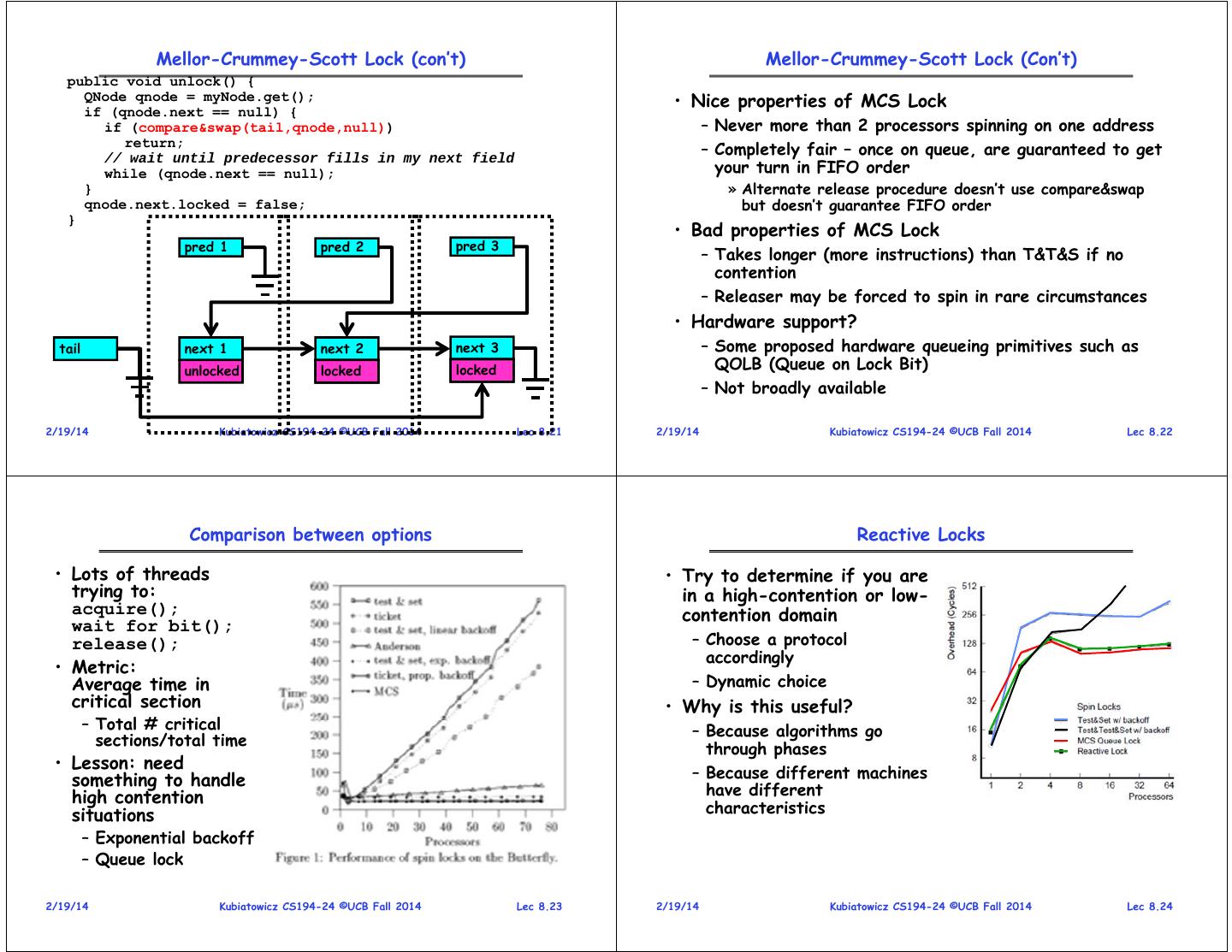
3 . Atomic Instructions Implementing Locks with test&set: Spin Lock • test&set (&address) { /* most architectures */ result = M[address]; M[address] = 1; • Another flawed, but simple solution: return result; } int value = 0; // Free • swap (&address, register) { /* x86 */ Acquire() { temp = M[address]; while (test&set(value)); // while busy M[address] = register; } register = temp; } Release() { • compare&swap (&address, reg1, reg2) { /* 68000 */ value = 0; if (reg1 == M[address]) { } M[address] = reg2; return success; • Simple explanation: } else { – If lock is free, test&set reads 0 and sets value=1, so } return failure; lock is now busy. It returns 0 so while exits. } – If lock is busy, test&set reads 1 and sets value=1 (no • load-linked&store conditional(&address) { change). It returns 1, so while loop continues /* R4000, alpha */ loop: – When we set value = 0, someone else can get lock ll r1, M[address]; movi r2, 1; /* Can do arbitrary comp */ • Problem: While spinning, performing writes sc r2, M[address]; beqz r2, loop; – Lots of cache coherence data – not capitalizing on cache } 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.9 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.10 Better: Test&Test&Set Lock Better option: Exponential backoff • The Test&Test&Set lock: • The Test&Test&Set lock with backoff: int value = 0; // Free int value = 0; // Free Acquire() { Acquire() { while (true) { int nfail = 0 while(value); // Locked, spin with reads while (true) { if (!test&set(value)) while(value); // Locked, spin with reads break; // Success! if (!test&set(value)) } break; // Success! } else Release() { value = 0; exponentialBackoff(nfail++) } } • Significant problems with Test&Test&Set? } – Multiple processors spinning on same memory location Release() { value = 0; » Release/Reacquire causes lots of cache invalidation traffic } » No guarantees of fairness – potential livelock • If someone grabs lock between when we see it free and – Scales poorly with number of processors attempt to grab it, must be contention » Because of bus traffic, average time until some processor • Backoff exponentially: acquires lock grows with number of processors – Choose backoff time randomly with some distribution • Busy-Waiting: thread consumes cycles while waiting – Double mean time with each iteration • Why does this work? 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.11 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.12
4 . Better Locks using test&set Administrivia • Can we build test&set locks without busy-waiting? – Can’t entirely, but can minimize! • Midterm I – Idea: only busy-wait to atomically check lock value – 3 weeks from today int guard = 0; – All topics up to that Monday int value = FREE; – No class day of exam Acquire() { Release() { • Readings // Short busy-wait time // Short busy-wait time while (test&set(guard)); – Love Chapter 6: Data structures while (test&set(guard)); if (value == BUSY) { if anyone on wait queue { – Love Chapter 10: Synchronization methods take thread off wait queue put thread on wait queue; Place on ready queue; go to sleep() & guard = 0; } else { } else { value = FREE; value = BUSY; } guard = 0; guard = 0; } }• Note: sleep has to be sure to reset the guard variable – Why can’t we do it just before or just after the sleep? 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.13 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.14 Using of Compare&Swap for queues Portable Atomic operations in Linux • compare&swap (&address, reg1, reg2) { /* 68000 */ • Linux provides atomic_t for declaring an atomic integer if (reg1 == M[address]) { M[address] = reg2; – Also, atomic64_t for declaring atomic 64-bit variant return success; } else { – Not necessarily same as a regular integer! return failure; » Originally on SPARC, atomic_t only 24 of 32 bits usable } } • Example usage: atomic_t v; /* define v */ Here is an atomic add to linked-list function: atomic_t u = ATOMIC_INIT(0); /* define and init u=0 */ addToQueue(&object) { do { // repeat until no conflict atomic_set(&v, 4); /* v=4 (atomically) */ ld r1, M[root] // Get ptr to current head atomic_add(2, &v); /* v = v + 2 (atomically) */ st r1, M[object] // Save link in new object atomic_inc(&v); /* v = v + 1 (atomically) */ } until (compare&swap(&root,r1,object)); } int final = atomic_read(&v); /* final == 7 */ root next next • Some operations (see Love, Ch 10, Table 10.1/10.2): atomic_inc()/atomic_dec() /* Atomically inc/dec */ next atomic_add()/atomic_sub() /* Atomically add/sub */ int atomic_dec_and_test() /* Sub 1. True if 0 */ New int atomic_inc_return() /* Add 1, return result */ Object 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.15 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.16
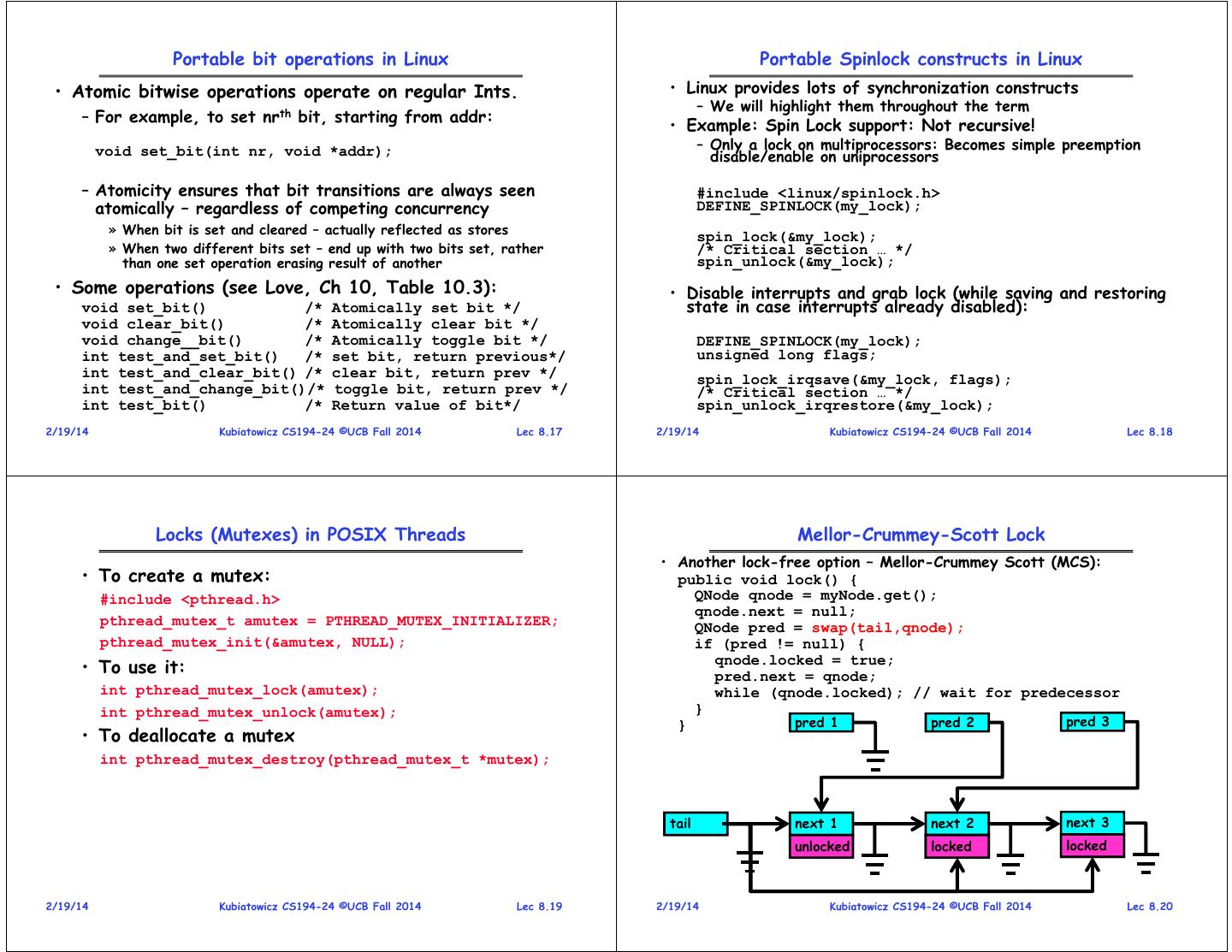
5 . Portable bit operations in Linux Portable Spinlock constructs in Linux • Atomic bitwise operations operate on regular Ints. • Linux provides lots of synchronization constructs – We will highlight them throughout the term – For example, to set nrth bit, starting from addr: • Example: Spin Lock support: Not recursive! void set_bit(int nr, void *addr); – Only a lock on multiprocessors: Becomes simple preemption disable/enable on uniprocessors – Atomicity ensures that bit transitions are always seen #include <linux/spinlock.h> atomically – regardless of competing concurrency DEFINE_SPINLOCK(my_lock); » When bit is set and cleared – actually reflected as stores spin_lock(&my_lock); » When two different bits set – end up with two bits set, rather /* Critical section … */ than one set operation erasing result of another spin_unlock(&my_lock); • Some operations (see Love, Ch 10, Table 10.3): • Disable interrupts and grab lock (while saving and restoring void set_bit() /* Atomically set bit */ state in case interrupts already disabled): void clear_bit() /* Atomically clear bit */ void change__bit() /* Atomically toggle bit */ DEFINE_SPINLOCK(my_lock); int test_and_set_bit() /* set bit, return previous*/ unsigned long flags; int test_and_clear_bit() /* clear bit, return prev */ spin_lock_irqsave(&my_lock, flags); int test_and_change_bit()/* toggle bit, return prev */ /* Critical section … */ int test_bit() /* Return value of bit*/ spin_unlock_irqrestore(&my_lock); 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.17 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.18 Locks (Mutexes) in POSIX Threads Mellor-Crummey-Scott Lock • Another lock-free option – Mellor-Crummey Scott (MCS): • To create a mutex: public void lock() { #include <pthread.h> QNode qnode = myNode.get(); qnode.next = null; pthread_mutex_t amutex = PTHREAD_MUTEX_INITIALIZER; QNode pred = swap(tail,qnode); pthread_mutex_init(&amutex, NULL); if (pred != null) { qnode.locked = true; • To use it: pred.next = qnode; int pthread_mutex_lock(amutex); while (qnode.locked); // wait for predecessor int pthread_mutex_unlock(amutex); } } pred 1 pred 2 pred 3 • To deallocate a mutex int pthread_mutex_destroy(pthread_mutex_t *mutex); tail next 1 next 2 next 3 unlocked unlocked locked unlocked locked 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.19 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.20
6 . Mellor-Crummey-Scott Lock (con’t) Mellor-Crummey-Scott Lock (Con’t) public void unlock() { QNode qnode = myNode.get(); • Nice properties of MCS Lock if (qnode.next == null) { if (compare&swap(tail,qnode,null)) – Never more than 2 processors spinning on one address return; // wait until predecessor fills in my next field – Completely fair – once on queue, are guaranteed to get while (qnode.next == null); your turn in FIFO order } » Alternate release procedure doesn’t use compare&swap qnode.next.locked = false; but doesn’t guarantee FIFO order } • Bad properties of MCS Lock pred 1 pred 2 pred 3 – Takes longer (more instructions) than T&T&S if no contention – Releaser may be forced to spin in rare circumstances • Hardware support? tail next 1 next 2 next 3 – Some proposed hardware queueing primitives such as unlocked unlocked locked unlocked locked QOLB (Queue on Lock Bit) – Not broadly available 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.21 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.22 Comparison between options Reactive Locks • Lots of threads • Try to determine if you are trying to: in a high-contention or low- acquire(); contention domain wait for bit(); release(); – Choose a protocol accordingly • Metric: Average time in – Dynamic choice critical section • Why is this useful? – Total # critical – Because algorithms go sections/total time through phases • Lesson: need – Because different machines something to handle high contention have different situations characteristics – Exponential backoff – Queue lock 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.23 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.24
7 . Higher-level Primitives than Locks Recall: Semaphores • What is the right abstraction for synchronizing • Semaphores are a kind of generalized lock threads that share memory? – First defined by Dijkstra in late 60s – Want as high a level primitive as possible – Main synchronization primitive used in original UNIX • Good primitives and practices important! • Definition: a Semaphore has a non-negative integer – Since execution is not entirely sequential, really hard to value and supports the following two operations: find bugs, since they happen rarely – P(): an atomic operation that waits for semaphore to – UNIX is pretty stable now, but up until about mid-80s become positive, then decrements it by 1 (10 years after started), systems running UNIX would » Think of this as the wait() operation crash every week or so – concurrency bugs – V(): an atomic operation that increments the semaphore • Synchronization is a way of coordinating multiple by 1, waking up a waiting P, if any concurrent activities that are using shared state » This of this as the signal() operation – This lecture and the next presents a couple of ways of – Note that P() stands for “proberen” (to test) and V() structuring the sharing stands for “verhogen” (to increment) in Dutch 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.25 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.26 Semaphores Like Integers Except Two Uses of Semaphores • Semaphores are like integers, except • Mutual Exclusion (initial value = 1) – No negative values – Also called “Binary Semaphore”. – Only operations allowed are P and V – can’t read or write – Can be used for mutual exclusion: value, except to set it initially semaphore.P(); // Critical section goes here – Operations must be atomic semaphore.V(); » Two P’s together can’t decrement value below zero • Scheduling Constraints (initial value = 0) » Similarly, thread going to sleep in P won’t miss wakeup – Locks are fine for mutual exclusion, but what if you from V – even if they both happen at same time want a thread to wait for something? • Semaphore from railway analogy – Example: suppose you had to implement ThreadJoin – Here is a semaphore initialized to 2 for resource control: which must wait for thread to terminiate: Initial value of semaphore = 0 ThreadJoin { semaphore.P(); } ThreadFinish { semaphore.V(); Value=2 Value=0 Value=1 } 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.27 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.28
8 . Producer-Consumer with a Bounded Buffer Full Solution to Bounded Buffer • Problem Definition Semaphore fullBuffer = 0; // Initially, no coke – Producer puts things into a shared buffer (wait if full) Semaphore emptyBuffers = numBuffers; – Consumer takes them out (wait if empty) // Initially, num empty slots – Use a fixed-size buffer between them to avoid lockstep Semaphore mutex = 1; // No one using machine » Need to synchronize access to this buffer • Correctness Constraints: Producer(item) { – Consumer must wait for producer to fill buffers, if none full emptyBuffers.P(); // Wait until space (scheduling constraint) mutex.P(); // Wait until buffer free Enqueue(item); – Producer must wait for consumer to empty buffers, if all full mutex.V(); (scheduling constraint) fullBuffers.V(); // Tell consumers there is – Only one thread can manipulate buffer queue at a time (mutual // more coke exclusion) } • Remember why we need mutual exclusion Consumer() { – Because computers are stupid fullBuffers.P(); // Check if there’s a coke mutex.P(); // Wait until machine free • General rule of thumb: item = Dequeue(); Use a separate semaphore for each constraint mutex.V(); – Semaphore fullBuffers; // consumer’s constraint emptyBuffers.V(); // tell producer need more – Semaphore emptyBuffers;// producer’s constraint return item; } – Semaphore mutex; // mutual exclusion 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.29 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.30 Portable Semaphores in Linux Portable (native) mutexes in Linux • Interface optimized for mutual exclusion • Initialize general semaphore: DEFINE_MUTEX(my_mutex); /* Static definition */ struct semapore my_sem; struct mutex my_mutex; sema_init(&my_sem, count); /* Initialize semaphore */ mutex_init(&my_mutex); /* Dynamic mutex init */ • Initialize mutex (semaphore with count = 1) • Simple use pattern: static DECLARE_MUTEX(my_mutex); mutex_lock(&my_mutex); /* critical section … */ mutex_unlock(&my_mutex); • Acquire semaphore: • Constraints down_interruptible(&my_sem); // Acquire sem, sleeps with – Same thread that grabs lock must release it // TASK_INTERRUPTIBLE state – pProcess cannot exit while holding mutex down(&my_sem); // Acquire sem, sleeps with – Recursive acquisitions not allowed // TASK_UNINTERRUPTIBLE state down_trylock(&my_sem); // Return ≠ 0 if lock busy – Cannot use in interrupt handlers (might sleep!) • Advantages • Release semaphore: – Simpler interface – Debugging support for checking usage up(&my_sem); // Release lock • Prefer mutexes over semaphores unless mutex really doesn’t fit your pattern! 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.31 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.32
9 . Alternative: Completion Patterns Review: Definition of Monitor • One use pattern that does not fit mutex pattern: • Semaphores are confusing because dual purpose: – Start operation in another thread/hardware container – Both mutual exclusion and scheduling constraints – Sleep until woken by completion of event – Cleaner idea: Use locks for mutual exclusion and • Can be implemented with semaphores condition variables for scheduling constraints – Start semaphore with count of 0 – Immediate down() – puts parent to sleep • Monitor: a lock and zero or more condition variables – Woken with up() for managing concurrent access to shared data • More efficient: use “completions”: – Use of Monitors is a programming paradigm DEFINED_COMPLETION(); /* Static definition */ • Lock: provides mutual exclusion to shared data: struct completion my_comp; – Always acquire before accessing shared data structure init_completion(&my_comp); /* Dynamic comp init */ – Always release after finishing with shared data • One or more threads to sleep on event: • Condition Variable: a queue of threads waiting for wait_for_completion(&my_comp); /* put thead to sleep */ something inside a critical section – Key idea: allow sleeping inside critical section by • Wake up threads (can be in interrupt handler!) atomically releasing lock at time we go to sleep complete(&my_comp); – Contrast to semaphores: Can’t wait inside critical section 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.33 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.34 Review: Programming with Monitors Summary (Synchronization) • Monitors represent the logic of the program • Important concept: Atomic Operations – Wait if necessary – An operation that runs to completion or not at all – Signal when change something so any waiting threads – These are the primitives on which to construct various can proceed synchronization primitives • Basic structure of monitor-based program: • Talked about hardware atomicity primitives: lock – Disabling of Interrupts, test&set, swap, comp&swap, while (need to wait) { Check and/or update load-linked/store conditional condvar.wait(); state variables } • Showed several constructions of Locks Wait if necessary unlock – Must be very careful not to waste/tie up machine resources do something so no need to wait » Shouldn’t disable interrupts for long lock » Shouldn’t spin wait for long Check and/or update – Key idea: Separate lock variable, use hardware condvar.signal(); mechanisms to protect modifications of that variable state variables unlock • Talked about Semaphores, Monitors, and Condition Variables – Higher level constructs that are harder to “screw up” 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.35 2/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 8.36
3秒后跳转登录页面
去登陆

