













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
并行和同步
线程的巩固复习
原子操作的概念
几种锁的结构
展开查看详情
1 . Goals for Today CS194-24 • Threads/Concurrency (continued) Advanced Operating Systems • Synchronization Structures and Implementation Lecture 7 Interactive is important! Parallelism and Ask Questions! Synchronization February 12th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.2 Recall: Scheduling Policy Goals/Criteria Recall: Threading models mentioned by Silbershatz book • Scheduling: deciding which threads are given access to resources from moment to moment • Minimize Response Time Simple One-to-One – Minimize elapsed time to do an operation (or job) Threading Model – Response time is what the user sees: » Time to echo a keystroke in editor » Time to compile a program • Maximize Throughput – Maximize operations (or jobs) per second – Two parts to maximizing throughput » Minimize overhead (for example, context-switching) » Efficient use of resources (CPU, disk, memory, etc) • Minimize missed deadlines (Realtime) – Efficiency is important, but predictability is essential – In RTS, performance guarantees are: » Task- and/or class centric Many-to-One Many-to-Many » Often ensured a priori 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.3 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.4
2 . Thread Level Parallelism (TLP) Multiprocessing vs Multiprogramming • In modern processors, Instruction Level Parallelism (ILP) • Remember Definitions: exploits implicit parallel operations within a loop or – Multiprocessing Multiple CPUs straight-line code segment – Multiprogramming Multiple Jobs or Processes • Thread Level Parallelism (TLP) explicitly represented by the use of multiple threads of execution that are – Multithreading Multiple threads per Process inherently parallel • What does it mean to run two threads “concurrently”? – Threads can be on a single processor – Scheduler is free to run threads in any order and – Or, on multiple processors interleaving: FIFO, Random, … • Concurrency vs Parallelism – Dispatcher can choose to run each thread to completion – Concurrency is when two tasks can start, run, and complete or time-slice in big chunks or small chunks in overlapping time periods. It doesn't necessarily mean they'll ever both be running at the same instant. A » For instance, multitasking on a single-threaded machine. Multiprocessing B C – Parallelism is when tasks literally run at the same time, eg. on a multicore processor. A B C • Goal: Use multiple instruction streams to improve – Throughput of computers that run many programs Multiprogramming A B C A B C B – Execution time of multi-threaded programs 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.5 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.6 Recall: Slowdown in Joy’s law of Performance Recall: Chip-scale features of SandyBridge 10000 3X • Significant pieces: From Hennessy and Patterson, Computer Architecture: A – Four OOO cores Quantitative Approach, 4th edition, Sept. 15, 2006 ??%/year » New Advanced Vector eXtensions (256-bit FP) 1000 » AES instructions Performance (vs. VAX-11/780) » Instructions to help with Galois-Field mult 52%/year » 4 -ops/cycle – Integrated GPU 100 – System Agent (Memory and Fast I/O) – Shared L3 cache divided in 4 banks Sea change in chip – On-chip Ring bus network 10 » Both coherent and non-coherent transactions design: multiple “cores” or » High-BW access to L3 Cache 25%/year processors per chip • Integrated I/O 1 – Integrated memory controller (IMC) 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006 » Two independent channels of DDR3 DRAM • VAX : 25%/year 1978 to 1986 – High-speed PCI-Express (for Graphics cards) • RISC + x86: 52%/year 1986 to 2002 – DMI Connection to SouthBridge (PCH) • RISC + x86: ??%/year 2002 to present 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.7 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.8
3 . Correctness for systems with concurrent threads Interactions Complicate Debugging • If dispatcher can schedule threads in any way, • Is any program truly independent? programs must work under all circumstances – Every process shares the file system, OS resources, – Can you test for this? network, etc – How can you know if your program works? – Extreme example: buggy device driver causes thread A to • Independent Threads: crash “independent thread” B – No state shared with other threads • You probably don’t realize how much you depend on – Deterministic Input state determines results reproducibility: – Reproducible Can recreate Starting Conditions, I/O – Example: Evil C compiler – Scheduling order doesn’t matter (if switch() works!!!) » Modifies files behind your back by inserting errors into C program unless you insert debugging code • Cooperating Threads: – Example: Debugging statements can overrun stack – Shared State between multiple threads • Non-deterministic errors are really difficult to find – Non-deterministic – Example: Memory layout of kernel+user programs – Non-reproducible » depends on scheduling, which depends on timer/other things • Non-deterministic and Non-reproducible means that » Original UNIX had a bunch of non-deterministic errors bugs can be intermittent – Example: Something which does interesting I/O – Sometimes called “Heisenbugs” » User typing of letters used to help generate secure keys 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.9 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.10 Why allow cooperating threads? Recall: High-level Example: Web Server • People cooperate; computers help/enhance people’s lives, so computers must cooperate – By analogy, the non-reproducibility/non-determinism of people is a notable problem for “carefully laid plans” • Advantage 1: Share resources – One computer, many users – One bank balance, many ATMs » What if ATMs were only updated at night? – Embedded systems (robot control: coordinate arm & hand) • Advantage 2: Speedup • Server must handle many requests – Overlap I/O and computation • Non-cooperating version: » Many different file systems do read-ahead – Multiprocessors – chop up program into parallel pieces serverLoop() { • Advantage 3: Modularity con = AcceptCon(); ProcessFork(ServiceWebPage(),con); – More important than you might think } – Chop large problem up into simpler pieces » To compile, for instance, gcc calls cpp | cc1 | cc2 | as | ld • What are some disadvantages of this technique? » Makes system easier to extend 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.11 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.12
4 . Threaded Web Server Thread Pools • Now, use a single process • Problem with previous version: Unbounded Threads • Multithreaded (cooperating) version: – When web-site becomes too popular – throughput sinks serverLoop() { • Instead, allocate a bounded “pool” of worker threads, connection = AcceptCon(); representing the maximum level of multiprogramming ThreadFork(ServiceWebPage(),connection); } • Looks almost the same, but has many advantages: queue Master – Can share file caches kept in memory, results of CGI Thread scripts, other things – Threads are much cheaper to create than processes, so this has a lower per-request overhead Thread Pool • Question: would a user-level (say one-to-many) worker(queue) { thread package make sense here? master() { while(TRUE) { – When one request blocks on disk, all block… allocThreads(worker,queue); while(TRUE) { con=Dequeue(queue); • What about Denial of Service attacks or digg / con=AcceptCon(); if (con==null) Slash-dot effects? Enqueue(queue,con); sleepOn(queue); wakeUp(queue); else } ServiceWebPage(con); } } } 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.13 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.14 Administrivia Other types of Linux Concurrency • Not much administrivia today • SoftIRQs and Tasklets – This lecture and next will have some duplication with – Utilized to defer work from interrupt handlers CS162, but I believe it is necessary – Runs as soon as interrupts are finished • How are the topics going? – Tasklets built on top of SoftIRQs – Too much/too little detail? – When to choose them: – Too much/too little overlap with CS162? » SoftIRQs can run simultaneously on different processors • Midterm I: Wed 3/12 (Four weeks from today) » No two Tasklets of same type run simultaneously – 2-Hour exam in 3 hours • Work Queues – Probably evening exam: 5-8pm? – Built on top of Kernel Threads – Topics: Everything up to previous Monday fair game – Simple mechanism for scheduling work to run in kernel • No class next Monday (2/17, Presidents’ Day) – Units of parallelism can sleep! 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.15 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.16
5 . Common Notions of Thread Creation Overview of POSIX Threads • cobegin/coend • Statements in block may run in parallel cobegin • cobegins may be nested • Pthreads: The POSIX threading interface – System calls to create and synchronize threads job1(a1); job2(a2); • Scoped, so you cannot have a missing coend – Should be relatively uniform across UNIX-like OS coend • fork/join tid1 = fork(job1, a1); • Forked procedure runs in parallel platforms • Wait at join point if it’s not finished – Originally IEEE POSIX 1003.1c job2(a2); join tid1; • future • Future possibly evaluated in parallel • Pthreads contain support for v = future(job1(a1)); … = …v…; • Attempt to use return value will wait – Creating parallelism • forall – Synchronizing • Separate thread launched for each iteration forall(I from 1 to N) • Implicit join at end – No explicit support for communication, because shared memory is implicit; a pointer to shared data C[I] = A[I] + B[I] end is passed to a thread • Threads expressed in the code may not turn into independent » Only for HEAP! Stacks not shared computations – Only create threads if processors idle – Example: Thread-stealing runtimes such as cilk 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.17 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.18 Forking POSIX Threads Simple Threading Example (pThreads) Signature: int pthread_create(pthread_t *, void* SayHello(void *foo) { E.g., compile using gcc –lpthread printf( "Hello, world!\n" ); const pthread_attr_t *, return NULL; void * (*)(void *), } void *); Example call: int main() { pthread_t threads[16]; errcode = pthread_create(&thread_id; &thread_attribute int tn; &thread_fun; &fun_arg); for(tn=0; tn<16; tn++) { pthread_create(&threads[tn], NULL, SayHello, NULL); } • thread_id is the thread id or handle (used to halt, etc.) for(tn=0; tn<16 ; tn++) { • thread_attribute various attributes pthread_join(threads[tn], NULL); – Standard default values obtained by passing a NULL } pointer return 0; – Sample attribute: minimum stack size } • thread_fun the function to be run (takes and returns void*) • fun_arg an argument can be passed to thread_fun when it starts • errorcode will be set nonzero if the create operation fails 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.19 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.20
6 . Shared Data and Threads Loop Level Parallelism • Variables declared outside of main are shared • Many application have parallelism in loops • Objects allocated on the heap may be shared (if double stuff [n][n]; pointer is passed) for (int i = 0; i < n; i++) • Variables on the stack are private: passing for (int j = 0; j < n; j++) pointer to these around to other threads can … pthread_create (…, update_stuff, …, cause problems &stuff[i][j]); • But overhead of thread creation is nontrivial • Often done by creating a large “thread data” – update_stuff should have a significant amount of work struct, which is passed into all threads as argument • Common Performance Pitfall: Too many threads – The cost of creating a thread is 10s of thousands of cycles char *message = "Hello World!\n"; on modern architectures – Solution: Thread blocking: use a small # of threads, often pthread_create(&thread1, NULL, equal to the number of cores/processors or hardware threads print_fun,(void*) message); 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.21 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.22 Some More Pthread Functions Thread Scheduling • pthread_yield(); main thread Time – Informs the scheduler that the thread is willing to yield its quantum, requires no arguments. • pthread_exit(void *value); Thread A Thread B – Exit thread and pass value to joining thread (if exists) • pthread_join(pthread_t *thread, void **result); – Wait for specified thread to finish. Place exit value into Thread C Thread D *result. Others: Thread E • pthread_t me; me = pthread_self(); – Allows a pthread to obtain its own identifier pthread_t • Once created, when will a given thread run? thread; – It is up to the Operating System or hardware, but it will run • pthread_detach(thread); eventually, even if you have more threads than cores – Informs the library that the threads exit status will not be – But – scheduling may be non-ideal for your application needed by subsequent pthread_join calls resulting in better • Programmer can provide hints or affinity in some cases threads performance. – E.g., create exactly P threads and assign to P cores For more information consult the library or the man pages, • Can provide user-level scheduling for some systems e.g., man -k pthread.. – Application-specific tuning based on programming model – Work in the ParLAB on making user-level scheduling easy to do (Lithe, PULSE) 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.23 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.24
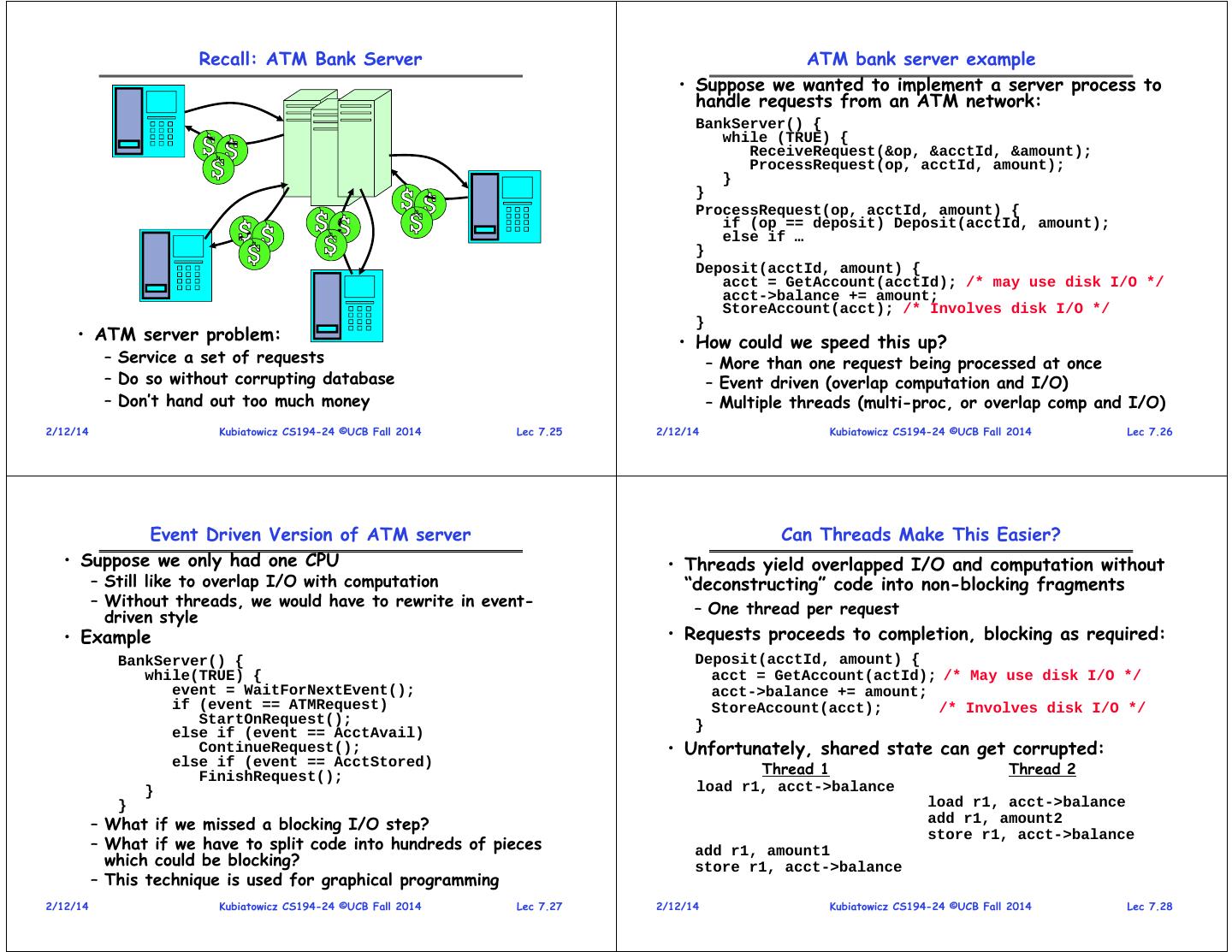
7 . Recall: ATM Bank Server ATM bank server example • Suppose we wanted to implement a server process to handle requests from an ATM network: BankServer() { while (TRUE) { ReceiveRequest(&op, &acctId, &amount); ProcessRequest(op, acctId, amount); } } ProcessRequest(op, acctId, amount) { if (op == deposit) Deposit(acctId, amount); else if … } Deposit(acctId, amount) { acct = GetAccount(acctId); /* may use disk I/O */ acct->balance += amount; StoreAccount(acct); /* Involves disk I/O */ } • ATM server problem: • How could we speed this up? – Service a set of requests – More than one request being processed at once – Do so without corrupting database – Event driven (overlap computation and I/O) – Don’t hand out too much money – Multiple threads (multi-proc, or overlap comp and I/O) 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.25 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.26 Event Driven Version of ATM server Can Threads Make This Easier? • Suppose we only had one CPU • Threads yield overlapped I/O and computation without – Still like to overlap I/O with computation “deconstructing” code into non-blocking fragments – Without threads, we would have to rewrite in event- – One thread per request driven style • Example • Requests proceeds to completion, blocking as required: BankServer() { Deposit(acctId, amount) { while(TRUE) { acct = GetAccount(actId); /* May use disk I/O */ event = WaitForNextEvent(); acct->balance += amount; if (event == ATMRequest) StoreAccount(acct); /* Involves disk I/O */ StartOnRequest(); } else if (event == AcctAvail) ContinueRequest(); • Unfortunately, shared state can get corrupted: else if (event == AcctStored) FinishRequest(); Thread 1 Thread 2 } load r1, acct->balance } load r1, acct->balance – What if we missed a blocking I/O step? add r1, amount2 store r1, acct->balance – What if we have to split code into hundreds of pieces add r1, amount1 which could be blocking? store r1, acct->balance – This technique is used for graphical programming 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.27 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.28
8 . Atomic Operations Using Locks for Synchronization • Atomic Operation: an operation that always runs to • Lock: prevents someone from doing something completion or not at all – It is indivisible: it cannot be stopped in the middle and – Lock before entering critical section and state cannot be modified by someone else in the middle before accessing shared data – Fundamental building block – if no atomic operations, then – Unlock when leaving, after accessing shared data have no way for threads to work together • On most machines, memory references and assignments – Wait if locked (i.e. loads and stores) of words are atomic » Important idea: all synchronization involves waiting • Many instructions are not atomic • Mutual Exclusion: ensuring that only one thread does a – Double-precision floating point store often not atomic particular thing at a time – VAX and IBM 360 had an instruction to copy a whole array • Some architectures can turn non-atomic instruction into – One thread excludes the other while doing its task atomic ones • Critical Section: piece of code that only one thread can – E.g. x86 – use “lock” prefix on an instruction execute at once. Only one thread at a time will get into • Synchronization: using atomic operations to ensure this section of code. cooperation between threads – For now, only loads and stores are atomic – Critical section is the result of mutual exclusion – We are going to show that its hard to build anything useful – Critical section and mutual exclusion are two ways of with only reads and writes describing the same thing. 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.29 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.30 Review: Ways of entering the kernel/ Using Locks to Protect Shared Variable changing the flow of control • Consider Previous Example: • The Timer Interrupt: Deposit(acctId, amount) { – Callbacks scheduled to be called when timer expires Acquire(depositlock); – Cause of scheduler events – change which process of thread is acct = GetAccount(actId); running acct->balance += amount; Critical Section • System Calls StoreAccount(acct); – Controlled function call into kernel from user space Release(depositlock); } – User-level code stops, kernel-level code – What about asynchronous system calls? • Locking Behavior: • Normal Interrupts – Only one critical section can be running at once! – Entered via hardware signal » Second Acquire() before release second thread waits – Typically Asynchronous to the instruction stream – As soon as Release() occurs, another Acquire() can happen – Often structured in some sort of hierarchy (some interrupts higher priority than others – If many threads request lock acquisition at same time: • Exceptions: » Might get livelock, depending on what happens on Release() – Instruction execution fails for some reason • Result of using locks: three instructions in critical – Typically Synchronous to the instruction stream section become Atomic! (cannot be separated) 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.31 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.32
9 . Recall: Network Interrupt Naïve use of Interrupt Enable/Disable Raise priority • How can we build multi-instruction atomic operations? – Scheduler gets control in two ways. Reenable All Ints External Interrupt add $r1,$r2,$r3 Save registers » Internal: Thread does something to relinquish the CPU “Interrupt Handler” subi $r4,$r1,#4 Dispatch to Handler » External: Interrupts cause dispatcher to take CPU slli $r4,$r4,#2 – On a uniprocessor, can avoid context-switching by: Transfer Network Pipeline Flush Packet from hardware » Avoiding internal events (although virtual memory tricky) to Kernel Buffers » Preventing external events by disabling interrupts lw $r2,0($r4) • Consequently, naïve Implementation of locks: lw $r3,4($r4) Restore registers Clear current Int LockAcquire { disable Ints; } add $r2,$r2,$r3 sw 8($r4),$r2 Disable All Ints LockRelease { enable Ints; } Restore priority RTI • Problems with this approach: – Can’t let user do this! Consider following: • Disable/Enable All Ints Internal CPU disable bit LockAcquire(); While(TRUE) {;} – RTI reenables interrupts, returns to user mode – Real-Time system—no guarantees on timing! • Raise/lower priority: change interrupt mask » Critical Sections might be arbitrarily long • Software interrupts can be provided entirely in – What happens with I/O or other important events? software at priority switching boundaries » “Reactor about to meltdown. Help?” 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.33 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.34 Implementation of Locks by Disabling Interrupts? Typical Linux Interfaces • Key idea: maintain a lock variable and impose mutual • Disabling and Enabling Interrupts on the Linux Kernel: exclusion only during operations on that variable local_irq_disable(); /* interrupts are disabled ... */ local_irq_enable(); int value = FREE; – These operations often single assembly instructions » The only work for local processor! Acquire() { Release() { » If competing with another processor, but use other form of disable interrupts; disable interrupts; synchronization if (value == BUSY) { if (anyone on wait queue) { – Dangerous if called when interrupts already disabled put thread on wait queue; take thread off wait queue » Then, when you code reenables, you will change semantics Go to sleep(); Place on ready queue; } else { • Saving and restoring interrupt state first: // Enable interrupts? unsigned long flags; } else { value = FREE; } value = BUSY; enable interrupts; local_irq_save(flags); // Save state } } /* Do whatever, including disable/enable*/ enable interrupts; local_irq_restore(flags); // Restore } • State of the system in_interrupt(); // In handler or bottom half in_irq(); // Specifically in handler 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.35 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.36
10 . How to implement locks? Linux Interrupt control (Con’t) Atomic Read-Modify-Write instructions • No more global cli()! • Problem with previous solution? – Used to be that cli()/sti() could be used to enable and – Can’t let users disable interrupts! (Why?) disable interrupts on all processors – Doesn’t work well on multiprocessor – First deprecated (2.5), then removed (2.6) » Disabling interrupts on all processors requires messages » Could serialize device drivers across all processors! and would be very time consuming » Just a bad idea • Alternative: atomic instruction sequences – Better option? – These instructions read a value from memory and write » Fine-grained spin-locks between processors (more later) a new value atomically » Local interrupt control for local processor – Hardware is responsible for implementing this correctly • Disabling specific interrupt (nestable) » on both uniprocessors (not too hard) disable_irq(irq); // Wait current handlers » and multiprocessors (requires help from cache coherence disable_irq_nosync(irq); // Don’t waitcurrent handler protocol) enable_irq(irq); // Reenable line synchronize_irq(irq); // Wait for current handler – Unlike disabling interrupts, can be used on both – Not great for buses with multiple interrupts per line, such as uniprocessors and multiprocessors PCI! More when we get into device drivers. 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.37 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.38 Atomic Instructions Implementing Locks with test&set: Spin Lock • test&set (&address) { /* most architectures */ result = M[address]; M[address] = 1; • Another flawed, but simple solution: return result; } int value = 0; // Free • swap (&address, register) { /* x86 */ Acquire() { temp = M[address]; while (test&set(value)); // while busy M[address] = register; } register = temp; } Release() { • compare&swap (&address, reg1, reg2) { /* 68000 */ value = 0; if (reg1 == M[address]) { } M[address] = reg2; return success; • Simple explanation: } else { – If lock is free, test&set reads 0 and sets value=1, so } return failure; lock is now busy. It returns 0 so while exits. } – If lock is busy, test&set reads 1 and sets value=1 (no • load-linked&store conditional(&address) { change). It returns 1, so while loop continues /* R4000, alpha */ loop: – When we set value = 0, someone else can get lock ll r1, M[address]; movi r2, 1; /* Can do arbitrary comp */ • Better: test&test&set sc r2, M[address]; beqz r2, loop; • Busy-Waiting: thread consumes cycles while waiting } 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.39 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.40
11 . Better Locks using test&set Using of Compare&Swap for queues • Can we build test&set locks without busy-waiting? • compare&swap (&address, reg1, reg2) { /* 68000 */ if (reg1 == M[address]) { – Can’t entirely, but can minimize! M[address] = reg2; – Idea: only busy-wait to atomically check lock value return success; } else { int guard = 0; return failure; int value = FREE; } } Acquire() { Release() { // Short busy-wait time // Short busy-wait time while (test&set(guard)); Here is an atomic add to linked-list function: while (test&set(guard)); addToQueue(&object) { if (value == BUSY) { if anyone on wait queue { take thread off wait queue do { // repeat until no conflict put thread on wait queue; ld r1, M[root] // Get ptr to current head Place on ready queue; go to sleep() & guard = 0; } else { st r1, M[object] // Save link in new object } else { } until (compare&swap(&root,r1,object)); value = FREE; } value = BUSY; } root next next guard = 0; guard = 0; } }• Note: sleep has to be sure to reset the guard variable next – Why can’t we do it just before or just after the sleep? New Object 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.41 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.42 Portable Atomic operations in Linux Portable bit operations in Linux • Linux provides atomic_t for declaring an atomic integer • Atomic bitwise operations operate on regular Ints. – Also, atomic64_t for declaring atomic 64-bit variant – For example, to set nrth bit, starting from addr: – Not necessarily same as a regular integer! » Originally on SPARC, atomic_t only 24 of 32 bits usable void set_bit(int nr, void *addr); • Example usage: – Atomicity ensures that bit transitions are always seen atomic_t v; /* define v */ atomically – regardless of competing concurrency atomic_t u = ATOMIC_INIT(0); /* define and init u=0 */ » When bit is set and cleared – actually reflected as stores atomic_set(&v, 4); /* v=4 (atomically) */ » When two different bits set – end up with two bits set, rather atomic_add(2, &v); /* v = v + 2 (atomically) */ than one set operation erasing result of another atomic_inc(&v); /* v = v + 1 (atomically) */ • Some operations (see Love, Ch 10, Table 10.3): int final = atomic_read(&v); /* final == 7 */ void set_bit() /* Atomically set bit */ void clear_bit() /* Atomically clear bit */ • Some operations (see Love, Ch 10, Table 10.1/10.2): void change__bit() /* Atomically toggle bit */ atomic_inc()/atomic_dec() /* Atomically inc/dec */ int test_and_set_bit() /* set bit, return previous*/ atomic_add()/atomic_sub() /* Atomically add/sub */ int test_and_clear_bit() /* clear bit, return prev */ int atomic_dec_and_test() /* Sub 1. True if 0 */ int test_and_change_bit()/* toggle bit, return prev */ int atomic_inc_return() /* Add 1, return result */ int test_bit() /* Return value of bit*/ 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.43 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.44
12 . Portable Locking constructs in Linux Locks (Mutexes) in POSIX Threads • Linux provides lots of synchronization constructs – We will highlight them throughout the term • To create a mutex: • Example: Spin Lock support: Not recursive! #include <pthread.h> pthread_mutex_t amutex = PTHREAD_MUTEX_INITIALIZER; #include <linux/spinlock.h> pthread_mutex_init(&amutex, NULL); DEFINE_SPINLOCK(my_lock); • To use it: spin_lock(&my_lock); /* Critical section … */ int pthread_mutex_lock(amutex); spin_unlock(&my_lock); int pthread_mutex_unlock(amutex); • Disable interrupts and grab lock (while saving and restoring • To deallocate a mutex state in case interrupts already disabled): int pthread_mutex_destroy(pthread_mutex_t *mutex); DEFINE_SPINLOCK(my_lock); unsigned long flags; spin_lock_irqsave(&my_lock,flags); /* Critical section … */ spin_unlock_irqrestore(&my_lock); 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.45 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.46 Summary • pTreads: POSIX interface for threading – Operations to create, destroy, and synchronize threads – Shared-memory model • Important concept: Atomic Operations – An operation that runs to completion or not at all – These are the primitives on which to construct various synchronization primitives • Talked about hardware atomicity primitives: – Disabling of Interrupts, test&set, swap, comp&swap, load- linked/store conditional • Showed several constructions of Locks – Must be very careful not to waste/tie up machine resources » Shouldn’t disable interrupts for long » Shouldn’t spin wait for long – Key idea: Separate lock variable, use hardware mechanisms to protect modifications of that variable • Started talking abut higher level constructs that are harder to “screw up” 2/12/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 7.47
3秒后跳转登录页面
去登陆

