











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Device Drivers (Con’t) Disk Modeling
• Device Drivers (Continued)
• Disk Drives and Queueing Theory
展开查看详情
1 . Goals for Today CS194-24 • Device Drivers (Continued) Advanced Operating Systems • Disk Drives and Queueing Theory Structures and Implementation Lecture 20 Device Drivers (Con’t) Disk Modeling Interactive is important! Ask Questions! April 14th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.2 Recall: How does the processor talk to the device? Recall: PCI Architecture Processor Memory Bus Regular Memory Memory Bus Bus RAM CPU CPU Bus Adaptor Adaptor Device Address+ Controller Other Devices Data Host Bridge Bus Hardware Interrupt or Buses PCI #0 Controller Interface Controller Interrupt Request ISA Bridge PCI Bridge read write Addressable PCI #1 • CPU interacts with a Controller control Memory status and/or – Contains a set of registers that ISA can be read and written Registers Queues Controller PCI Slots USB SCSI (port 0x20) Scanner – May contain memory for request Memory Mapped Controller Controller queues or bit-mapped images Region: 0x8f008020 Legacy Root • Regardless of the complexity of the connections and Devices Hub Hard Disk buses, processor accesses registers in two ways: CD ROM – I/O instructions: in/out instructions Hub Webcam » Example from the Intel architecture: out 0x21,AL – Memory mapped I/O: load/store instructions » Registers/memory appear in physical address space Mouse Keyboard » I/O accomplished with load and store instructions 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.3 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.4
2 . PCI Details (con’t) PCI Details (con’t) • Device identification: – vendorID (16 bits): global registry of vendors – deviceID (16-bits): vendor-assigned device – class (16-bits): top 8 bits identify “base class” (i.e. network) – subsystem vendorID/subsystem deviceID PCI Configuration » Used to help identify bridges/interfaces PCI Configuration Space (Address Registers): • Example initialization: Space (first 64 bytes) Type: 0x0: 32-bits #ifndef CONFIG_PCI 0x2: 64-bits (2 regs) # error "This driver needs PCI support to be available" #endif • Access configuration space with special functions: int pci_read_config_byte(struct pci_dev *dev, int where, u8 *ptr); int mydev_find_all_devices(void) { int pci_read_config_word(struct pci_dev *dev, int where, u16 *ptr); struct pci_dev *dev = NULL; int pci_read_config_dword(struct pci_dev *dev, int where, u32 *ptr); int pci_write_config_byte (struct pci_dev *dev, int where, u8 val); int found; int pci_write_config_word (struct pci_dev *dev, int where, u16 val); if (!pci_present()) return -ENODEV; int pci_write_config_dword (struct pci_dev *dev, int where, u32 val); for (found=0; found < MYDEV_MAX_DEV;) { • Example: Figure out which interrupt line result = pci_read_config_byte(dev, PCI_INTERRUPT_LINE, &myirq); dev = pci_find_device(MYDEV_VENDOR, MYDEV_ID, dev); if (result) { /* deal with error */ } if (!dev) /* no more devices are there */ int request_irq(myirq, break; /* do device-specific actions and count the device */ void (*handler)(int, void *, struct pt_regs *), found += mydev_init_one(dev); unsigned long flags, const char *dev_name, } void *dev_id); return (index == 0) ? -ENODEV : 0; } void free_irq(unsigned int irq, void *dev_id); 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.5 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.6 Device Drivers Life Cycle of An I/O Request • Device Driver: Device-specific code in the kernel that interacts directly with the device hardware User – Supports a standard, internal interface Program – Same kernel I/O system can interact easily with different device drivers – Special device-specific configuration supported with the ioctl() system call Kernel I/O • Linux Device drivers often installed via a Module Subsystem – Interface for dynamically loading code into kernel space – Modules loaded with the “insmod” command and can contain parameters Interrupt Handler • Driver-specific structure Bottom Half – One per driver – Contains a set of standard kernel interface routines Device Driver » Open: perform device-specific initialization Top Half » Read: perform read » Write: perform write » Release: perform device-specific shutdown Device » Etc. Hardware – These routines registered at time device registered 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.7 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.8
3 . Transfering Data To/From Controller I/O Device Notifying the OS • Programmed I/O: • The OS needs to know when: – Each byte transferred via processor in/out or load/store – The I/O device has completed an operation – Pro: Simple hardware, easy to program – The I/O operation has encountered an error – Con: Consumes processor cycles proportional to data size • I/O Interrupt: • Direct Memory Access: – Device generates an interrupt whenever it needs service – Give controller access to memory bus – Handled in top half of device driver – Ask it to transfer data to/from memory directly » Often run on special kernel-level stack • Sample interaction with DMA controller (from book): – Pro: handles unpredictable events well – Con: interrupts relatively high overhead • Polling: – OS periodically checks a device-specific status register » I/O device puts completion information in status register » Could use timer to invoke lower half of drivers occasionally – Pro: low overhead – Con: may waste many cycles on polling if infrequent or unpredictable I/O operations • Actual devices combine both polling and interrupts – For instance: High-bandwidth network device: » Interrupt for first incoming packet » Poll for following packets until hardware empty 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.9 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.10 Administrivia Heartbleed • No Class on Wednesday • SSL/TLS vulnerability in the OpenSSL library – Off at a DOE workshop implementation of “heartbeats” • Use extra time on Wednesday to finish up Lab 3 • RFC 6520: Transport Layer Security (TLS) and – How’s it going? Datagram Transport Layer Security (DTLS) • Special Topics lecture Heartbeat Extension – On Monday 5/5 during RRR week – What topics would you like me to talk about? • What it does? » Send me email! – Provides a keep-alive “heartbeat,” and discovers how big a packet can be sent (Path Max Transfer Unit) • Why? – Need to periodically send data on TCP/UDP connection so NAT boxes/firewalls don’t close connection 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.11 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.12
4 . How? OpenSSL Code Analysis • Message format: Request or hbtype = *p++; Macro to extract TWO BYTE Length struct { n2s(p, payload); Request or Response 14-bit Length (16-bit HeartbeatMessageType type; pl = p; Response uint16 payload_length; field!) Payload opaque payload[HeartbeatMessage.payload_length]; • The length in the SSLv3 record is not checked! opaque padding[padding_length]; } HeartbeatMessage; • Later in the function: Allocate as much mem as requester unsigned char *buffer, *bp; Random Data int r; • One side sends request with random data Random Length asked for – up to ~64K bytes! Padding buffer = OPENSSL_malloc(1 + 2 + payload + padding); • Other side replies with response containing the bp = buffer; SAME random data • Then: • All traffic is encrypted /* Enter response type, length and copy payload */ *bp++ = TLS1_HB_RESPONSE;Copies payload AND server memory beyond s2n(payload, bp); memcpy(bp, pl, payload); payload! • Bug was an error in how the heartbeat receiver checks the message values • Repeat to read server memory! – No log entries, so no forensic information Analysis by http://blog.existentialize.com/diagnosis-of-the-openssl-heartbleed-bug.html 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.13 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.14 Interrupt handling More on Synchronization • Interrupt routines typically divided into two pieces: • Must always be aware that interrupt handlers can – Top half: run as interrupt routine » Gets input or transfers next block of output interrupt running code! » Handles any direct access to hardware – Must come up with a synchronization methodology to » Handles any time-sensitive aspects of handling interrupts deal with this issue » Runs in the ATOMIC Context (cannot sleep) – May need to deal with multiple processors – Bottom half: accessed later to finish processing » Perform any interrupt-related work not performed by the • Some possible ways of dealing with synchronization: interrupt handler itself » Scheduled “later” with interrupts re-enabled – Build some sort of lock-free queue implemented as a » Some options for bottom halves can sleep circular buffer • Since you typically have two halves of code, must – Spinlocks remember to synchronize shared data – Lock variables that are atomically incremented and – Since interrupt handler is running in interrupt (ATOMIC) decremented context, cannot sleep! • Note about spinlocks – Good choice: spin lock to synchronize data structures – Many variants, make sure to use variants to disable – Must be careful never to hold spinlock for too long interrupts as well as spin » When non-interrupt code holds a spinlock, must make sure – Bovet Chapter 9 has lots of discussion of to disable interrupts! synchronization » Consider “spin_lock_irqsave()” or “spin_lock_bh()” variants – Consider lock free queue variants as well 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.15 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.16
5 . Recall: Portable Spinlock constructs in Linux Recall: Portable Atomic operations in Linux • Linux provides lots of synchronization constructs • Linux provides atomic_t for declaring an atomic integer – We will highlight them throughout the term – Also, atomic64_t for declaring atomic 64-bit variant • Example: Spin Lock support: Not recursive! – Only a lock on multiprocessors: Becomes simple preemption – Not necessarily same as a regular integer! disable/enable on uniprocessors » Originally on SPARC, atomic_t only 24 of 32 bits usable • Example usage: #include <linux/spinlock.h> DEFINE_SPINLOCK(my_lock); atomic_t v; /* define v */ atomic_t u = ATOMIC_INIT(0); /* define and init u=0 */ spin_lock(&my_lock); /* Critical section … */ atomic_set(&v, 4); /* v=4 (atomically) */ spin_unlock(&my_lock); atomic_add(2, &v); /* v = v + 2 (atomically) */ atomic_inc(&v); /* v = v + 1 (atomically) */ • Disable interrupts and grab lock (while saving and restoring state in case interrupts already disabled): int final = atomic_read(&v); /* final == 7 */ DEFINE_SPINLOCK(my_lock); • Some operations (see Love, Ch 10, Table 10.1/10.2): unsigned long flags; atomic_inc()/atomic_dec() /* Atomically inc/dec */ spin_lock_irqsave(&my_lock, flags); atomic_add()/atomic_sub() /* Atomically add/sub */ /* Critical section … */ int atomic_dec_and_test() /* Sub 1. True if 0 */ spin_unlock_irqrestore(&my_lock); int atomic_inc_return() /* Add 1, return result */ 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.17 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.18 Recall: Portable bit operations in Linux Options for Bottom Half • Atomic bitwise operations operate on regular Ints. • Bottom Half used for handling work after interrupt is re- enabled (i.e. deferred work): – For example, to set nrth bit, starting from addr: – Perform any interrupt-related work not performed by the interrupt handler void set_bit(int nr, void *addr); – Ideally most of the work – What to minimize amount of work done in an interrupt – Atomicity ensures that bit transitions are always seen handler because they run with interrupts disabled atomically – regardless of competing concurrency • Many different mechanisms for handling bottom halves » When bit is set and cleared – actually reflected as stores – Original “Bottom Half” (deprecated) » When two different bits set – end up with two bits set, rather than one set operation erasing result of another – Task Queues » Put work on a task queue for later execution • Some operations (see Love, Ch 10, Table 10.3): – Softirqs are statically defined bottom halves that can run void set_bit() /* Atomically set bit */ simultaneously on any processor void clear_bit() /* Atomically clear bit */ – Tasklets: dynamically created bottom halves built on top of void change__bit() /* Atomically toggle bit */ softirq mechanism int test_and_set_bit() /* set bit, return previous*/ » Only one of each type of tasklet can run at given time int test_and_clear_bit() /* clear bit, return prev */ » Simplifies synchronization int test_and_change_bit()/* toggle bit, return prev */ int test_bit() /* Return value of bit*/ 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.19 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.20
6 . Recall: Completion Patterns Hard Disk Drives • One use pattern that does not fit mutex pattern: – Start operation in another thread/hardware container – Sleep until woken by completion of event • Can be implemented with semaphores – Start semaphore with count of 0 – Immediate down() – puts parent to sleep – Woken with up() • More efficient: use “completions”: Read/Write Head DEFINED_COMPLETION(); /* Static definition */ Side View struct completion my_comp; init_completion(&my_comp); /* Dynamic comp init */ • One or more threads to sleep on event: wait_for_completion(&my_comp); /* put thead to sleep */ Western Digital Drive • Wake up threads (can be in interrupt handler!) http://www.storagereview.com/guide/ complete(&my_comp); IBM/Hitachi Microdrive 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.21 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.22 Example: Seagate Barracuda (2014) Properties of a Hard Magnetic Disk Track Sector • 6TB! 1000 Gb/in2 • 6 (3.5”) platters?, 2 heads each Sector • Perpendicular recording Head Cylinder • 7200 RPM, 4.16ms latency Track Platter • 4KB sectors (512 emulation?) • Properties • 216MB/sec sustained – Head moves in to address circular track of information transfer speed – Independently addressable element: sector • 128MB cache » OS always transfers groups of sectors together—”blocks” • Error Characteristics: – Items addressable without moving head: cylinder – MBTF: 1.4M hours – A disk can be rewritten in place: it is possible to read/modify/write a block from the disk – Bit error rate: 10-15 • Typical numbers (depending on the disk size): • Special considerations: – 500 to more than 20,000 tracks per surface – Normally need special “bios” (EFI): Bigger than easily handled by 32-bit OSes. – 32 to 800 sectors per track – Seagate provides special “Disk Wizard” software that • Zoned bit recording virtualizes drive into multiple chunks that makes it bootable on – Constant bit density: more sectors on outer tracks these OSes. – Speed varies with track location 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.23 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.24
7 . Performance Model Typical Numbers of a Magnetic Disk • Read/write data is a three-stage process: • Average seek time as reported by the industry: – Seek time: position the head/arm over the proper track – Typically in the range of 4 ms to 12 ms (into proper cylinder) – Locality of reference may only be 25% to 33% of the – Rotational latency: wait for the desired sector advertised number to rotate under the read/write head • Rotational Latency: – Transfer time: transfer a block of bits (sector) – Most disks rotate at 3,600 to 7200 RPM (Up to 15,000RPM under the read-write head or more) – Approximately 16 ms to 8 ms per revolution, respectively • Disk Latency = Queueing Time + Controller time + – An average latency to the desired information is halfway around the disk: 8 ms at 3600 RPM, 4 ms at 7200 RPM Seek Time + Rotation Time + Xfer Time • Transfer Time is a function of: – Transfer size (usually a sector): 512B – 1KB per sector Controller Hardware Request Software Result Media Time – Rotation speed: 3600 RPM to 15000 RPM Queue (Seek+Rot+Xfer) – Recording density: bits per inch on a track (Device Driver) – Diameter: ranges from 1 in to 5.25 in • Highest Bandwidth: – Typical values: up to 216 MB per second (sustained) – Transfer large group of blocks sequentially from one track • Controller time depends on controller hardware 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.25 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.26 Example: Disk Performance What about other non-volatile options? • Question: How long does it take to fetch 1 Kbyte sector? • There are a number of non-mechanical options for • Assumptions: non-volatile storage – Ignoring queuing and controller times for now – FLASH, MRAM, PCM – Avg seek time of 5ms, avg rotational delay of 4ms • Form Factors: – Transfer rate of 4MByte/s, sector size of 1 KByte – SSD (same form factor and interface as disk) • Random place on disk: » Complex on-board controllers perform maintenance – Seek (5ms) + Rot. Delay (4ms) + Transfer (0.25ms) operations – Roughly 10ms to fetch/put data: 100 KByte/sec – SIMMs/DIMMs • Random place in same cylinder: » May need to have device driver perform wear-leveling – Rot. Delay (4ms) + Transfer (0.25ms) or other operations – Roughly 5ms to fetch/put data: 200 KByte/sec • Current SSD densities • Next sector on same track: – 1TB no problem (< $500) – Transfer (0.25ms): 4 MByte/sec – Seems to be pretty competitive • Key to using disk effectively (esp. for filesystems) is to minimize seek and rotational delays 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.27 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.28
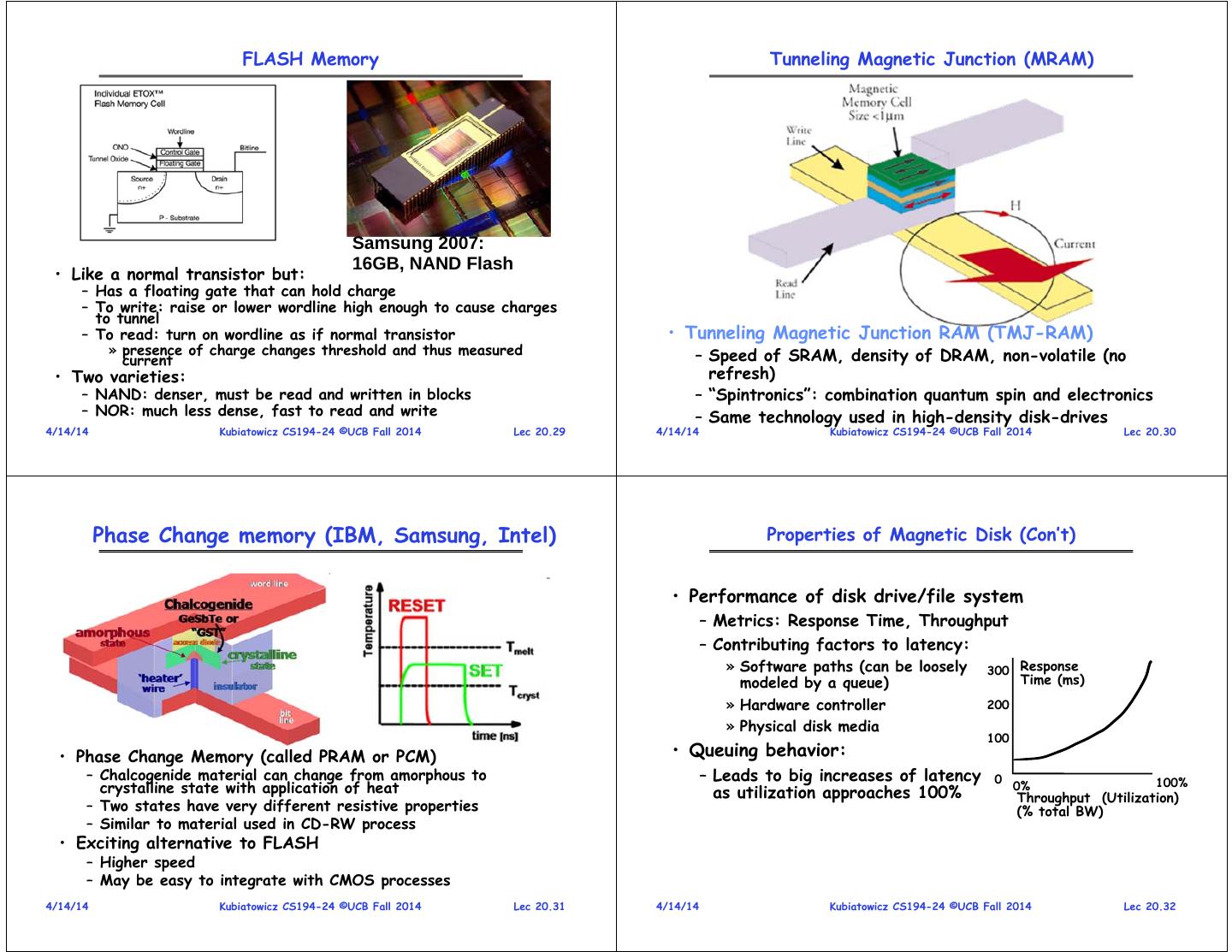
8 . FLASH Memory Tunneling Magnetic Junction (MRAM) Samsung 2007: 16GB, NAND Flash • Like a normal transistor but: – Has a floating gate that can hold charge – To write: raise or lower wordline high enough to cause charges to tunnel – To read: turn on wordline as if normal transistor • Tunneling Magnetic Junction RAM (TMJ-RAM) » presence of charge changes threshold and thus measured – Speed of SRAM, density of DRAM, non-volatile (no current • Two varieties: refresh) – NAND: denser, must be read and written in blocks – “Spintronics”: combination quantum spin and electronics – NOR: much less dense, fast to read and write – Same technology used in high-density disk-drives 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.29 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.30 Phase Change memory (IBM, Samsung, Intel) Properties of Magnetic Disk (Con’t) • Performance of disk drive/file system – Metrics: Response Time, Throughput – Contributing factors to latency: » Software paths (can be loosely 300 Response modeled by a queue) Time (ms) » Hardware controller 200 » Physical disk media 100 • Phase Change Memory (called PRAM or PCM) • Queuing behavior: – Chalcogenide material can change from amorphous to – Leads to big increases of latency 0 100% crystalline state with application of heat as utilization approaches 100% 0% Throughput (Utilization) – Two states have very different resistive properties (% total BW) – Similar to material used in CD-RW process • Exciting alternative to FLASH – Higher speed – May be easy to integrate with CMOS processes 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.31 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.32
9 . A Little Queuing Theory: Some Results A Little Queuing Theory: An Example • Assumptions: • Example Usage Statistics: – System in equilibrium; No limit to the queue – User requests 10 8KB disk I/Os per second – Time between successive arrivals is random and memoryless – Requests & service exponentially distributed (C=1.0) – Avg. service = 20 ms (controller+seek+rot+Xfertime) Queue • Questions: Server – How utilized is the disk? Arrival Rate Service Rate μ=1/Tser » Ans: server utilization, u = Tser • Parameters that describe our system: – What is the average time spent in the queue? – : mean number of arriving customers/second » Ans: Tq – Tser: mean time to service a customer (“m1”) – What is the number of requests in the queue? – C: squared coefficient of variance = 2/m12 » Ans: Lq = Tq – μ: service rate = 1/Tser – What is the avg response time for disk request? » Ans: Tsys = Tq + Tser (Wait in queue, then get served) – u: server utilization (0u1): u = /μ = Tser • Computation: • Parameters we wish to compute: – Tq: Time spent in queue (avg # arriving customers/s) = 10/s – Lq: Length of queue = Tq (by Little’s law) Tser (avg time to service customer) = 20 ms (0.02s) • Results: u (server utilization) = Tser= 10/s .02s = 0.2 – Memoryless service distribution (C = 1): Tq (avg time/customer in queue) = Tser u/(1 – u) » Called M/M/1 queue: Tq = Tser x u/(1 – u) = 20 x 0.2/(1-0.2) = 20 0.25 = 5 ms (0 .005s) – General service distribution (no restrictions), 1 server: Lq (avg length of queue) = Tq=10/s .005s = 0.05 » Called M/G/1 queue: Tq = Tser x ½(1+C) x u/(1 – u)) Tsys (avg time/customer in system) =Tq + Tser= 25 ms 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.33 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.34 Disk Scheduling Summary (1/2) • Disk can do only one request at a time; What order do • I/O Devices Types: you choose to do queued requests? – Many different speeds (0.1 bytes/sec to GBytes/sec) User – Different Access Patterns: 2,2 5,2 7,2 3,10 2,1 2,3 Head » Block Devices, Character Devices, Network Devices Requests – Different Access Timing: • FIFO Order » Blocking, Non-blocking, Asynchronous – Fair among requesters, but order of arrival may be to • I/O Controllers: Hardware that controls actual random spots on the disk Very long seeks device • SSTF: Shortest seek time first – Processor Accesses through I/O instructions, Disk Head – Pick the request that’s closest on the disk 3 load/store to special physical memory – Although called SSTF, today must include – Report their results through either interrupts or a rotational delay in calculation, since 2 status register that processor looks at occasionally rotation can be as long as seek 1 (polling) – Con: SSTF good at reducing seeks, but • Notification mechanisms may lead to starvation 4 – Interrupts • SCAN: Implements an Elevator Algorithm: take the – Polling: Report results through status register that closest request in the direction of travel processor looks at periodically – No starvation, but retains flavor of SSTF • Device Driver: Code specific to device which handles • C-SCAN: Circular-Scan: only goes in one direction unique aspects of device – Skips any requests on the way back – Fairer than SCAN, not biased towards pages in middle 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.35 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.36
10 . Summary (2/2) • Disk Storage: Cylinders, Tracks, Sectors – Access Time: 4-12ms – Rotational Velocity: 3600—15000 – Transfer Speed: Up to 200MB/sec • Disk Time = queue + controller + seek + rotate + transfer • Advertised average seek time benchmark much greater than average seek time in practice 1 1 C x u xu • Queueing theory: W 2 1u for (c=1): W 1 u 4/14/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 20.37
3秒后跳转登录页面
去登陆

