











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
调度
-调度准则
-短程调度算法
-实时调度
展开查看详情
1 . Goals for Today CS194-24 Advanced Operating Systems • Application-Specific filesystems (con’t) Structures and Implementation • Scheduling Lecture 16 Interactive is important! Specialized File Systems (con’t) Ask Questions! Scheduling March 31st, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.2 Recall: Lookup with Leaf Set Recall: Dynamo Assumptions • Assign IDs to nodes Source • Query Model – Simple interface exposed to application level – Map hash values to – Get(), Put() node with closest ID – No Delete() • Leaf set is 111… – No transactions, no complex queries successors and • Atomicity, Consistency, Isolation, Durability predecessors 0… – Operations either succeed or fail, no middle ground 110… – System will be eventually consistent, no sacrifice of availability – All that’s needed for to assure consistency correctness – Conflicts can occur while updates propagate through system • Routing table – System can still function while entire sections of network are matches successively down longer prefixes • Efficiency – Measure system by the 99.9th percentile – Important with millions of users, 0.1% can be in the 10,000s – Allows efficient 10… lookups • Non Hostile Environment – No need to authenticate query, no malicious queries • Data Replication: Lookup ID – Behind web services, not in front of them – On leaf set 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.3 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.4
2 . Data Versioning Vector clock example • A put() call may return to its caller before the update has been applied at all the replicas • A get() call may return many versions of the same object. • Challenge: an object having distinct version sub- histories, which the system will need to reconcile in the future. • Solution: uses vector clocks in order to capture causality between different versions of the same object – A vector clock is a list of (node, counter) pairs – Every version of every object is associated with one vector clock – If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.5 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.6 Conflicts (multiversion data) Haystack File System • Client must resolve conflicts • Does it ever make sense to adapt a file system to a – Only resolve conflicts on reads particular usage pattern? – Different resolution options: – Perhaps » Use vector clocks to decide based on history • Good example: Facebook’s “Haystack” filesystem » Use timestamps to pick latest version – Specific application (Photo Sharing) – Examples given in paper: » Large files!, Many files! » For shopping cart, simply merge different versions » 260 Billion images, 20 PetaBytes (1015 bytes!) » For customer’s session information, use latest version » One billion new photos a week (60 TeraBytes) – Stale versions returned on reads are updated (“read repair”) – Presence of Content Delivery Network (CDN) • Vary N, R, W to match requirements of applications » Distributed caching and – High performance reads: R=1, W=N distribution network – Fast writes with possible inconsistency: W=1 » Facebook web servers return – Common configuration: N=3, R=2, W=2 special URLs that encode requests to CDN • When do branches occur? » Pay for service by bandwidth – Branches uncommon: 0.06% of requests saw > 1 version over – Specific usage patterns: 24 hours » New photos accessed a – Divergence occurs because of high write rate (more lot (caching well) coordinators), not necessarily because of failure » Old photos accessed little, but likely to be requested Number of photos at any time NEEDLES requested in day 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.7 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.8
3 . Old Solution: NFS New Solution: Haystack • Issues with this design? • Finding a needle (old photo) in Haystack • Long Tail Caching does not • Differentiate between old work for most photos and new photos – Every access to back end storage – How? By looking at “Writeable” must be fast without benefit of vs “Read-only” volumes caching! – New Photos go to Writeable volumes • Linear Directory scheme works • Directory: Help locate photos badly for many photos/directory – Name (URL) of photo has – Many disk operations to find embedded volume and photo ID even a single photo • Let CDN or Haystack Cache – Directory’s block map too big to cache in memory Serve new photos – rather than forwarding them to – “Fixed” by reducing directory size, however still not great Writeable volumes • Meta-Data (FFS) requires ≥ 3 disk accesses per lookup • Haystack Store: Multiple “Physical Volumes” – Caching all iNodes in memory might help, but iNodes are big – Physical volume is large file (100 GB) which stores millions of photos • Fundamentally, Photo Storage different from other – Data Accessed by Volume ID with offset into file storage: – Since Physical Volumes are large files, use XFS which is optimized for large files – Normal file systems fine for developers, databases, etc 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.9 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.10 Haystack Details Haystack Details (Con’t) • Replication for reliability and performance: – Multiple physical volumes combined into logical volume » Factor of 3 – Four different sizes » Thumbnails, Small, Medium, Large • Each physical volume is stored as single file in XFS • Lookup – Superblock: General information about the volume – User requests Webpage – Each photo (a “needle”) stored by appending to file – Webserver returns URL of form: • Needles stored sequentially in file » http://<CDN>/<Cache>/<Machine id>/<Logical volume,photo> – Naming: [Volume ID, Key, Alternate Key, Cookie] » Possibly reference cache only if old image – Cookie: random value to avoid guessing attacks – CDN will strip off CDN reference if missing, forward to cache – Key: Unique 64-bit photo ID – Cache will strip off cache reference and forward to Store – Alternate Key: four different sizes, ‘n’, ‘a’, ‘s’, ‘t’ • Deleted Needle Simply marked as “deleted” • In-memory index on Store for each volume map: – Overwritten Needle – new version appended at end [Key, Alternate Key] Offset 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.11 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.12
4 . Administrivia Review: CPU Scheduling • How to specify behaviors for Scheduling Algorithm? • One option: Statistically – Set up a bunch of jobs to run – Let them run – keep statistics about their behavior » How much CPU time they get » Do they ever miss deadlines – Sample state of scheduler regularly to make sure that statistical behavior is good • A more detailed option: Snapshot state machine • Earlier, we talked about the life-cycle of a thread – We ask you to build a snapshot facility to grab state of – Active threads work their way from Ready queue to scheduler (or any other part of kernel!) with a set of Running to various waiting queues. snapshot commands • Question: How is the OS to decide which of several » Think of the setup for this as a specification of a set of tasks to take off a queue? snapshot commands that must run – Then, grab results after snapshots have happened – Obvious queue to worry about is ready queue – Others can be scheduled as well, however • Export of test information? – /proc file system • Scheduling: deciding which threads are given access to resources from moment to moment 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.13 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.14 Recall: Assumption: CPU Bursts Scheduling Policy Goals/Criteria • Minimize Response Time – Minimize elapsed time to do an operation (or job) Weighted toward small bursts – Response time is what the user sees: » Time to echo a keystroke in editor » Time to compile a program » Real-time Tasks: Must meet deadlines imposed by World • Maximize Throughput – Maximize operations (or jobs) per second – Throughput related to response time, but not identical: » Minimizing response time will lead to more context switching than if you only maximized throughput • Execution model: programs alternate between bursts of CPU and I/O – Two parts to maximizing throughput » Minimize overhead (for example, context-switching) – Program typically uses the CPU for some period of time, » Efficient use of resources (CPU, disk, memory, etc) then does I/O, then uses CPU again – Each scheduling decision is about which job to give to the • Fairness CPU for use by its next CPU burst – Share CPU among users in some equitable way – With timeslicing, thread may be forced to give up CPU – Fairness is not minimizing average response time: before finishing current CPU burst » Better average response time by making system less fair 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.15 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.16
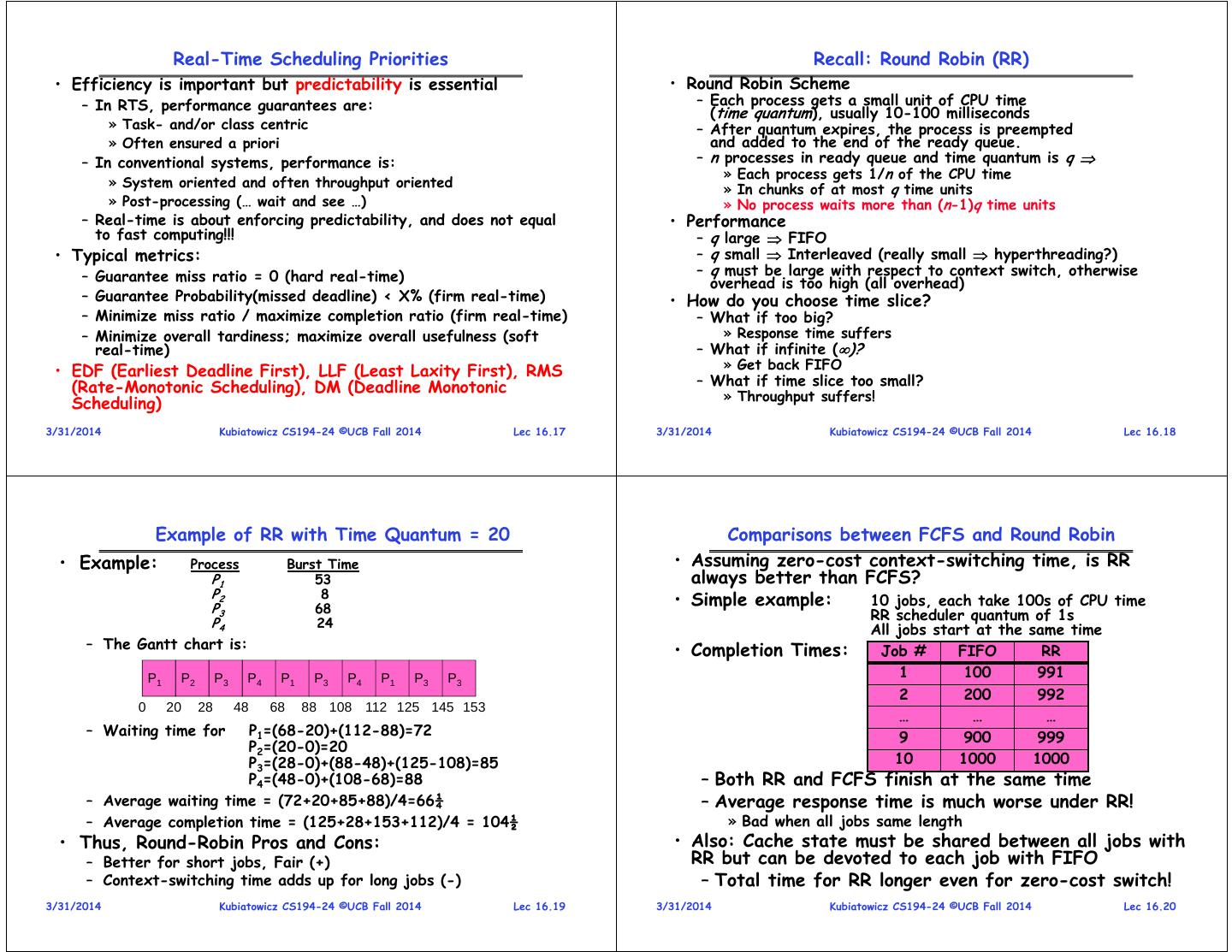
5 . Real-Time Scheduling Priorities Recall: Round Robin (RR) • Efficiency is important but predictability is essential • Round Robin Scheme – In RTS, performance guarantees are: – Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds » Task- and/or class centric – After quantum expires, the process is preempted » Often ensured a priori and added to the end of the ready queue. – In conventional systems, performance is: – n processes in ready queue and time quantum is q » Each process gets 1/n of the CPU time » System oriented and often throughput oriented » In chunks of at most q time units » Post-processing (… wait and see …) » No process waits more than (n-1)q time units – Real-time is about enforcing predictability, and does not equal • Performance to fast computing!!! – q large FIFO • Typical metrics: – q small Interleaved (really small hyperthreading?) – Guarantee miss ratio = 0 (hard real-time) – q must be large with respect to context switch, otherwise overhead is too high (all overhead) – Guarantee Probability(missed deadline) < X% (firm real-time) • How do you choose time slice? – Minimize miss ratio / maximize completion ratio (firm real-time) – What if too big? – Minimize overall tardiness; maximize overall usefulness (soft » Response time suffers real-time) – What if infinite ()? » Get back FIFO • EDF (Earliest Deadline First), LLF (Least Laxity First), RMS (Rate-Monotonic Scheduling), DM (Deadline Monotonic – What if time slice too small? » Throughput suffers! Scheduling) 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.17 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.18 Example of RR with Time Quantum = 20 Comparisons between FCFS and Round Robin • Example: Process Burst Time • Assuming zero-cost context-switching time, is RR P1 53 always better than FCFS? P2 8 • Simple example: 10 jobs, each take 100s of CPU time P3 68 P4 24 RR scheduler quantum of 1s All jobs start at the same time – The Gantt chart is: • Completion Times: Job # FIFO RR P1 P2 P3 P4 P1 P3 P4 P1 P3 P3 1 100 991 2 200 992 0 20 28 48 68 88 108 112 125 145 153 … … … – Waiting time for P1=(68-20)+(112-88)=72 9 900 999 P2=(20-0)=20 P3=(28-0)+(88-48)+(125-108)=85 10 1000 1000 P4=(48-0)+(108-68)=88 – Both RR and FCFS finish at the same time – Average waiting time = (72+20+85+88)/4=66¼ – Average response time is much worse under RR! – Average completion time = (125+28+153+112)/4 = 104½ » Bad when all jobs same length • Thus, Round-Robin Pros and Cons: • Also: Cache state must be shared between all jobs with – Better for short jobs, Fair (+) RR but can be devoted to each job with FIFO – Context-switching time adds up for long jobs (-) – Total time for RR longer even for zero-cost switch! 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.19 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.20
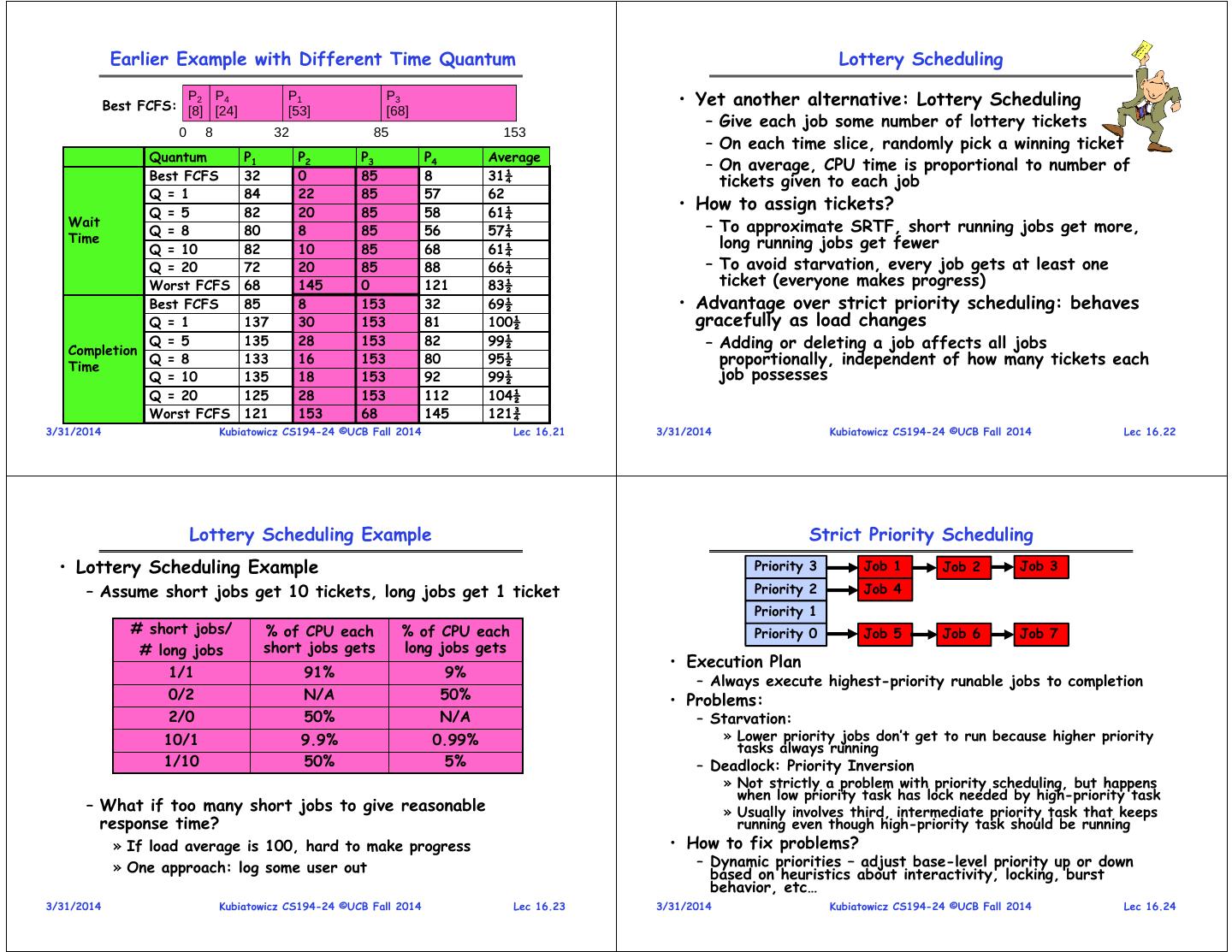
6 . Earlier Example with Different Time Quantum Lottery Scheduling P2 P4 Best FCFS: [8] [24] P1 P3 • Yet another alternative: Lottery Scheduling [53] [68] – Give each job some number of lottery tickets 0 8 32 85 153 – On each time slice, randomly pick a winning ticket Quantum P1 P2 P3 P4 Average – On average, CPU time is proportional to number of Best FCFS 32 0 85 8 31¼ tickets given to each job Q = 1 84 22 85 57 62 Q = 5 82 20 85 58 61¼ • How to assign tickets? Wait – To approximate SRTF, short running jobs get more, Q = 8 80 8 85 56 57¼ Time long running jobs get fewer Q = 10 82 10 85 68 61¼ Q = 20 72 20 85 88 66¼ – To avoid starvation, every job gets at least one Worst FCFS 68 145 0 121 83½ ticket (everyone makes progress) Best FCFS 85 8 153 32 69½ • Advantage over strict priority scheduling: behaves Q = 1 137 30 153 81 100½ gracefully as load changes Completion Q = 5 135 28 153 82 99½ – Adding or deleting a job affects all jobs Time Q = 8 133 16 153 80 95½ proportionally, independent of how many tickets each Q = 10 135 18 153 92 99½ job possesses Q = 20 125 28 153 112 104½ Worst FCFS 121 153 68 145 121¾ 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.21 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.22 Lottery Scheduling Example Strict Priority Scheduling • Lottery Scheduling Example Priority 3 Job 1 Job 2 Job 3 – Assume short jobs get 10 tickets, long jobs get 1 ticket Priority 2 Job 4 Priority 1 # short jobs/ % of CPU each % of CPU each Priority 0 Job 5 Job 6 Job 7 # long jobs short jobs gets long jobs gets • Execution Plan 1/1 91% 9% – Always execute highest-priority runable jobs to completion 0/2 N/A 50% • Problems: 2/0 50% N/A – Starvation: 10/1 9.9% 0.99% » Lower priority jobs don’t get to run because higher priority tasks always running 1/10 50% 5% – Deadlock: Priority Inversion » Not strictly a problem with priority scheduling, but happens when low priority task has lock needed by high-priority task – What if too many short jobs to give reasonable » Usually involves third, intermediate priority task that keeps response time? running even though high-priority task should be running » If load average is 100, hard to make progress • How to fix problems? » One approach: log some user out – Dynamic priorities – adjust base-level priority up or down based on heuristics about interactivity, locking, burst behavior, etc… 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.23 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.24
7 . How to handle simultaneous mix of different Recall: Assumption: CPU Bursts types of applications? • Can we use Burst Time (observed) to decide which application gets CPU time? Weighted toward small bursts • Consider mix of interactive and high throughput apps: – How to best schedule them? – How to recognize one from the other? » Do you trust app to say that it is “interactive”? – Should you schedule the set of apps identically on servers, workstations, pads, and cellphones? • Assumptions encoded into many schedulers: – Apps that sleep a lot and have short bursts must be interactive apps – they should get high priority – Apps that compute a lot should get low(er?) priority, since • Execution model: programs alternate between bursts of they won’t notice intermittent bursts from interactive apps CPU and I/O • Hard to characterize apps: – Program typically uses the CPU for some period of time, – What about apps that sleep for a long time, but then compute then does I/O, then uses CPU again for a long time? – Each scheduling decision is about which job to give to the – Or, what about apps that must run under all circumstances CPU for use by its next CPU burst (say periodically) – With timeslicing, thread may be forced to give up CPU before finishing current CPU burst 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.25 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.26 What if we Knew the Future? Discussion • Could we always mirror best FCFS? • SJF/SRTF are the best you can do at minimizing • Shortest Job First (SJF): average response time – Run whatever job has the least amount of – Provably optimal (SJF among non-preemptive, SRTF computation to do among preemptive) – Sometimes called “Shortest Time to Completion First” (STCF) – Since SRTF is always at least as good as SJF, focus on SRTF • Shortest Remaining Time First (SRTF): – Preemptive version of SJF: if job arrives and has a • Comparison of SRTF with FCFS and RR shorter time to completion than the remaining time on – What if all jobs the same length? the current job, immediately preempt CPU » SRTF becomes the same as FCFS (i.e. FCFS is best can – Sometimes called “Shortest Remaining Time to do if all jobs the same length) Completion First” (SRTCF) – What if jobs have varying length? • These can be applied either to a whole program or » SRTF (and RR): short jobs not stuck behind long ones the current CPU burst of each program – Idea is to get short jobs out of the system – Big effect on short jobs, only small effect on long ones – Result is better average response time 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.27 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.28
8 . Example to illustrate benefits of SRTF SRTF Example continued: Disk Utilization: A or B C C A B 9/201 C ~ 4.5% C’s C’s C’s C’s RR 100ms time slice DiskC’s Utilization: I/O I/O I/O I/O ~90%I/Obut lots of • Three jobs: wakeups! CABAB… C – A,B: both CPU bound, run for week C: I/O bound, loop 1ms CPU, 9ms disk I/O – If only one at a time, C uses 90% of the disk, A or B RR 1ms time slice could use 100% of the CPU C’s C’s • With FIFO: I/O I/O Disk Utilization: – Once A or B get in, keep CPU for two weeks C A A A 90% • What about RR or SRTF? – Easier to see with a timeline SRTF C’s C’s I/O I/O 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.29 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.30 SRTF Further discussion Predicting the Length of the Next CPU Burst • Starvation • Adaptive: Changing policy based on past behavior – SRTF can lead to starvation if many small jobs! – CPU scheduling, in virtual memory, in file systems, etc – Large jobs never get to run – Works because programs have predictable behavior • Somehow need to predict future » If program was I/O bound in past, likely in future – How can we do this? » If computer behavior were random, wouldn’t help – Some systems ask the user • Example: SRTF with estimated burst length » When you submit a job, have to say how long it will take – Use an estimator function on previous bursts: » To stop cheating, system kills job if takes too long Let tn-1, tn-2, tn-3, etc. be previous CPU burst lengths. – But: Even non-malicious users have trouble predicting Estimate next burst n = f(tn-1, tn-2, tn-3, …) runtime of their jobs – Function f could be one of many different time series • Bottom line, can’t really know how long job will take estimation schemes (Kalman filters, etc) – However, can use SRTF as a yardstick – For instance, for measuring other policies exponential averaging – Optimal, so can’t do any better n = tn-1+(1-)n-1 • SRTF Pros & Cons with (0<1) – Optimal (average response time) (+) – Hard to predict future (-) – Unfair (-) 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.31 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.32
9 . Multi-Level Feedback Scheduling Scheduling Details • Result approximates SRTF: Long-Running Compute – CPU bound jobs drop like a rock Tasks Demoted to Low Priority – Short-running I/O bound jobs stay near top • Scheduling must be done between the queues – Fixed priority scheduling: » serve all from highest priority, then next priority, etc. • Another method for exploiting past behavior – Time slice: – First used in CTSS » each queue gets a certain amount of CPU time – Multiple queues, each with different priority » e.g., 70% to highest, 20% next, 10% lowest » Higher priority queues often considered “foreground” tasks • Countermeasure: user action that can foil intent of – Each queue has its own scheduling algorithm the OS designer » e.g. foreground – RR, background – FCFS – For multilevel feedback, put in a bunch of meaningless » Sometimes multiple RR priorities with quantum increasing I/O to keep job’s priority high exponentially (highest:1ms, next:2ms, next: 4ms, etc) – Of course, if everyone did this, wouldn’t work! • Adjust each job’s priority as follows (details vary) • Example of Othello program: – Job starts in highest priority queue – Playing against competitor, so key was to do computing – If timeout expires, drop one level at higher priority the competitors. – If timeout doesn’t expire, push up one level (or to top) » Put in printf’s, ran much faster! 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.33 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.34 Scheduling Fairness Case Study: Linux O(1) Scheduler • What about fairness? – Strict fixed-priority scheduling between queues is unfair Kernel/Realtime Tasks User Tasks (run highest, then next, etc): 0 100 139 » long running jobs may never get CPU » In Multics, shut down machine, found 10-year-old job • Priority-based scheduler: 140 priorities – Must give long-running jobs a fraction of the CPU even – 40 for “user tasks” (set by “nice”), 100 for “Realtime/Kernel” when there are shorter jobs to run – Lower priority value higher priority (for nice values) – Tradeoff: fairness gained by hurting avg response time! – Lower priority value Lower priority (for realtime values) • How to implement fairness? – All algorithms O(1) – Could give each queue some fraction of the CPU » Timeslices/priorities/interactivity credits all computed when job finishes time slice » What if one long-running job and 100 short-running ones? » 140-bit bit mask indicates presence or absence of job at » Like express lanes in a supermarket—sometimes express given priority level lanes get so long, get better service by going into one of • Two separate priority queues: the other lines – The “active queue” and the “expired queue” – Could increase priority of jobs that don’t get service – All tasks in the active queue use up their timeslices and get » What is done in some variants of UNIX placed on the expired queue, after which queues swapped » This is ad hoc—what rate should you increase priorities? – However, “interactive tasks” get special dispensation » And, as system gets overloaded, no job gets CPU time, so » To try to maintain interactivity everyone increases in priorityInteractive jobs suffer » Placed back into active queue, unless some other task has 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.35 3/31/2014 been starved for too long Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.36
10 . O(1) Scheduler Continued What about Linux “Real-Time Priorities” (0-99)? • Real-Time Tasks: Strict Priority Scheme • Heuristics – No dynamic adjustment of priorities (i.e. no heuristics) – User-task priority adjusted ±5 based on heuristics – Scheduling schemes: (Actually – POSIX 1.1b) » p->sleep_avg = sleep_time – run_time » SCHED_FIFO: preempts other tasks, no timeslice limit » Higher sleep_avg more I/O bound the task, more » SCHED_RR: preempts normal tasks, RR scheduling amongst reward (and vice versa) tasks of same priority – Interactive Credit • With N processors: » Earned when a task sleeps for a “long” time – Always run N highest priority tasks that are runnable » Spend when a task runs for a “long” time – Rebalancing task on every transition: » IC is used to provide hysteresis to avoid changing » Where to place a task optimally on wakeup? interactivity for temporary changes in behavior » What to do with a lower-priority task when it wakes up but • Real-Time Tasks is on a runqueue running a task of higher priority? – Always preempt non-RT tasks » What to do with a low-priority task when a higher-priority task on the same runqueue wakes up and preempts it? – No dynamic adjustment of priorities » What to do when a task lowers its priority and causes a – Scheduling schemes: previously lower-priority task to have the higher priority? » SCHED_FIFO: preempts other tasks, no timeslice limit – Optimized implementation with global bit vectors to quickly identify where to place tasks » SCHED_RR: preempts normal tasks, RR scheduling amongst tasks of same priority • More on this later… 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.37 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.38 Linux Completely Fair Scheduler (CFS) CFS (Continued) • First appeared in 2.6.23, modified in 2.6.24 • Idea: track amount of “virtual time” received by each • “CFS doesn't track sleeping time and doesn't use process when it is executing heuristics to identify interactive tasks—it just makes – Take real execution time, scale by weighting factor sure every process gets a fair share of CPU within a » Lower priority real time divided by greater weight set amount of time given the number of runnable » Actually – multiply by sum of all weights/current weight processes on the CPU.” – Keep virtual time advancing at same rate • Inspired by Networking “Fair Queueing” • Targeted latency ( ): period of time after which all processes get to run at least a little – Each process given their fair share of resources – Each process runs with quantum ⁄∑ – Models an “ideal multitasking processor” in which N processes execute simultaneously as if they truly got – Never smaller than “minimum granularity” 1/N of the processor • Use of Red-Black tree to hold all runnable processes » Tries to give each process an equal fraction of the as sorted on vruntime variable processor – O(log n) time to perform insertions/deletions – Priorities reflected by weights such that increasing a » Cash the item at far left (item with earliest vruntime) task’s priority by 1 always gives the same fractional – When ready to schedule, grab version with smallest increase in CPU time – regardless of current priority vruntime (which will be item at the far left). 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.39 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.40
11 . CFS Examples Characteristics of a RTS • Suppose Targeted latency = 20ms, • Extreme reliability and safety Minimum Granularity = 1ms – Embedded systems typically control the environment in which • Two CPU bound tasks with same priorities they operate – Both switch with 10ms – Failure to control can result in loss of life, damage to environment or economic loss • Two CPU bound tasks separated by nice value of 5 • Guaranteed response times – One task gets 5ms, another gets 15 – We need to be able to predict with confidence the worst case • 40 tasks: each gets 1ms (no longer totally fair) response times for systems – Efficiency is important but predictability is essential • One CPU bound task, one interactive task same priority » In RTS, performance guarantees are: – While interactive task sleeps, CPU bound task runs and • Task- and/or class centric increments vruntime • Often ensured a priori – When interactive task wakes up, runs immediately, since it » In conventional systems, performance is: is behind on vruntime • System oriented and often throughput oriented • Group scheduling facilities (2.6.24) • Post-processing (… wait and see …) – Can give fair fractions to groups (like a user or other • Soft Real-Time mechanism for grouping processes) – Attempt to meet deadlines with high probability – So, two users, one starts 1 process, other starts 40, – Important for multimedia applications each will get 50% of CPU 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.41 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.42 Summary Summary (Con’t) • Scheduling: selecting a waiting process from the ready • Shortest Job First (SJF)/Shortest Remaining Time First queue and allocating the CPU to it (SRTF): – Run whatever job has the least amount of computation to • Round-Robin Scheduling: do/least remaining amount of computation to do – Give each thread a small amount of CPU time when it – Pros: Optimal (average response time) executes; cycle between all ready threads – Cons: Hard to predict future, Unfair – Pros: Better for short jobs • Multi-Level Feedback Scheduling: – Cons: Poor when jobs are same length – Multiple queues of different priorities – Automatic promotion/demotion of process priority in order • Lottery Scheduling: to approximate SJF/SRTF – Give each thread a priority-dependent number of tokens • Linux O(1) Scheduler: Priority Scheduling with dynamic (short tasksmore tokens) Priority boost/retraction – Reserve a minimum number of tokens for every thread to – All operations O(1) ensure forward progress/fairness – Fairly complex heuristics to perform dynamic priority alterations – Every task gets at least a little chance to run • Realtime Schedulers: RMS, EDF, CBS – All attempting to provide guaranteed behavior 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.43 3/31/2014 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 16.44
3秒后跳转登录页面
去登陆

