










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
文件系统(续2)
•分布式文件系统
•点对点系统
•特定于应用程序的文件系统
展开查看详情
1 . Goals for Today CS194-24 • Distributed file systems Advanced Operating Systems • Peer-to-Peer Systems Structures and Implementation • Application-specific file systems Lecture 13 Interactive is important! File Systems (Con’t) Ask Questions! RAID/Journaling/VFS March 17th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.2 Recall:Network-Attached Storage and the CAP Theorem Network File System (NFS) • Three Layers for NFS system – UNIX file-system interface: open, read, write, close calls + file descriptors – VFS layer: distinguishes local from remote files Network » Calls the NFS protocol procedures for remote requests – NFS service layer: bottom layer of the architecture » Implements the NFS protocol • NFS Protocol: RPC for file operations on server – Reading/searching a directory • Consistency: – manipulating links and directories – Changes appear to everyone in the same serial order – accessing file attributes/reading and writing files • Availability: • Write-through caching: Modified data committed to – Can get a result at any time server’s disk before results are returned to the client • Partition-Tolerance – lose some of the advantages of caching – System continues to work even when network becomes – time to perform write() can be long partitioned – Need some mechanism for readers to eventually notice • Consistency, Availability, Partition-Tolerance (CAP) Theorem: changes! (more on this later) Cannot have all three at same time – Otherwise known as “Brewer’s Theorem” 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.3 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.4
2 . NFS Continued NFS Cache consistency • NFS servers are stateless; each request provides all • NFS protocol: weak consistency arguments require for execution – E.g. reads include information for entire operation, such – Client polls server periodically to check for changes as ReadAt(inumber,position), not Read(openfile) » Polls server if data hasn’t been checked in last 3-30 – No need to perform network open() or close() on file – seconds (exact timeout it tunable parameter). each operation stands on its own » Thus, when file is changed on one client, server is notified, but other clients use old version of file until timeout. • Idempotent: Performing requests multiple times has same effect as performing it exactly once – Example: Server crashes between disk I/O and message cache F1 still ok? send, client resend read, server does operation again F1:V2 F1:V1 No: (F1:V2) – Example: Read and write file blocks: just re-read or re- write file block – no side effects Client – Example: What about “remove”? NFS does operation Server cache twice and second time returns an advisory error F1:V2 • Failure Model: Transparent to client system cache – Is this a good idea? What if you are in the middle of F1:V2 reading a file and server crashes? Client – Options (NFS Provides both): – What if multiple clients write to same file? » Hang until server comes back up (next week?) » Return an error. (Of course, most applications don’t know » In NFS, can get either version (or parts of both) they are talking over network) » Completely arbitrary! 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.5 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.6 Sequential Ordering Constraints Schematic View of NFS Architecture • What sort of cache coherence might we expect? – i.e. what if one CPU changes file, and before it’s done, another CPU reads file? • Example: Start with file contents = “A” Read: gets A Write B Read: parts of B or C Client 1: Client 2: Read: gets A or B Write C Client 3: Read: parts of B or C Time • What would we actually want? – Assume we want distributed system to behave exactly the same as if all processes are running on single system » If read finishes before write starts, get old copy » If read starts after write finishes, get new copy » Otherwise, get either new or old copy – For NFS: » If read starts more than 30 seconds after write, get new copy; otherwise, could get partial update 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.7 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.8
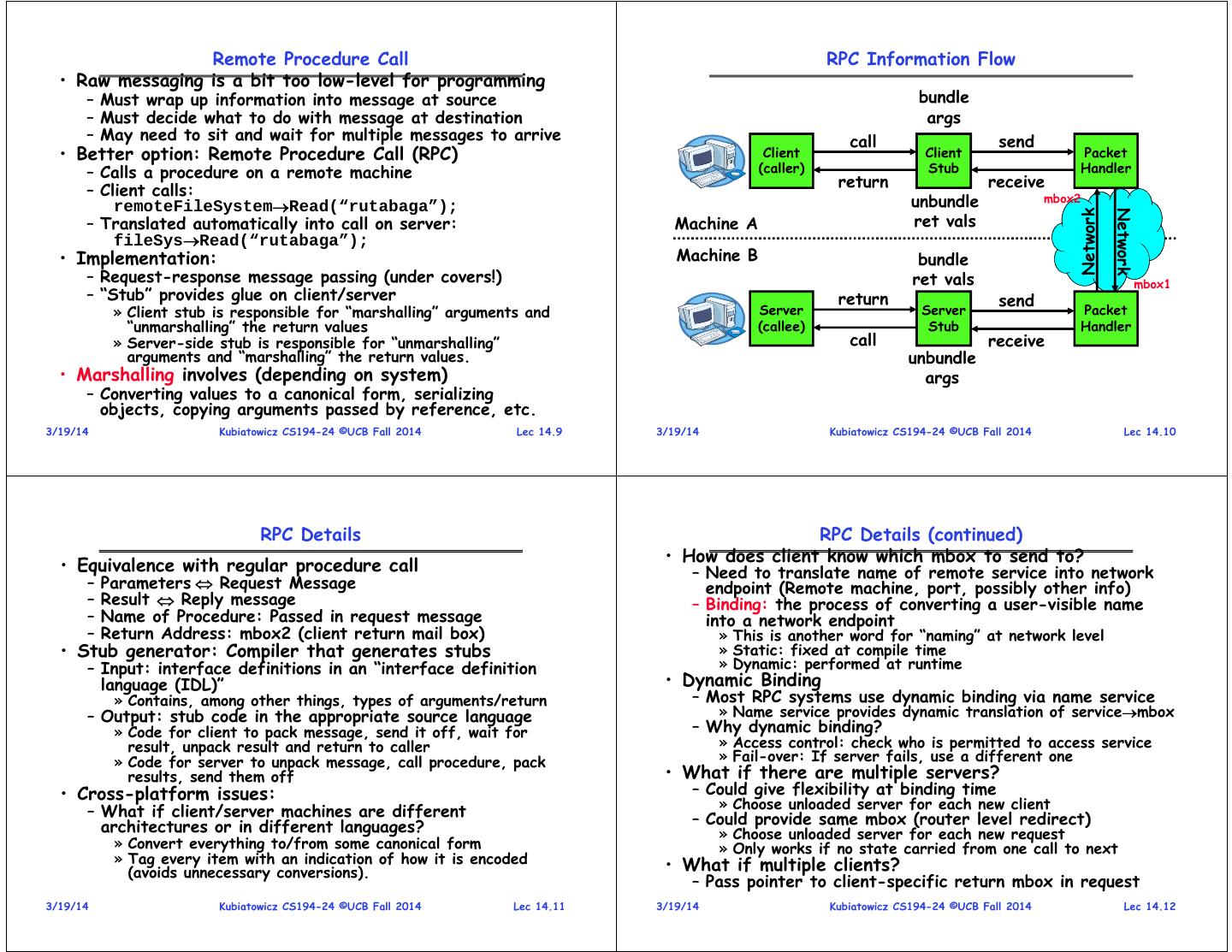
3 . Remote Procedure Call RPC Information Flow • Raw messaging is a bit too low-level for programming – Must wrap up information into message at source bundle – Must decide what to do with message at destination args – May need to sit and wait for multiple messages to arrive call send • Better option: Remote Procedure Call (RPC) Client Client Packet – Calls a procedure on a remote machine (caller) Stub Handler – Client calls: return receive remoteFileSystemRead(“rutabaga”); unbundle mbox2 Network Network – Translated automatically into call on server: Machine A ret vals fileSysRead(“rutabaga”); • Implementation: Machine B bundle – Request-response message passing (under covers!) ret vals mbox1 – “Stub” provides glue on client/server return send » Client stub is responsible for “marshalling” arguments and Server Server Packet “unmarshalling” the return values (callee) Stub Handler » Server-side stub is responsible for “unmarshalling” call receive arguments and “marshalling” the return values. unbundle • Marshalling involves (depending on system) args – Converting values to a canonical form, serializing objects, copying arguments passed by reference, etc. 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.9 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.10 RPC Details RPC Details (continued) • How does client know which mbox to send to? • Equivalence with regular procedure call – Need to translate name of remote service into network – Parameters Request Message endpoint (Remote machine, port, possibly other info) – Result Reply message – Binding: the process of converting a user-visible name – Name of Procedure: Passed in request message into a network endpoint – Return Address: mbox2 (client return mail box) » This is another word for “naming” at network level • Stub generator: Compiler that generates stubs » Static: fixed at compile time – Input: interface definitions in an “interface definition » Dynamic: performed at runtime language (IDL)” • Dynamic Binding » Contains, among other things, types of arguments/return – Most RPC systems use dynamic binding via name service – Output: stub code in the appropriate source language » Name service provides dynamic translation of servicembox » Code for client to pack message, send it off, wait for – Why dynamic binding? result, unpack result and return to caller » Access control: check who is permitted to access service » Code for server to unpack message, call procedure, pack » Fail-over: If server fails, use a different one results, send them off • What if there are multiple servers? • Cross-platform issues: – Could give flexibility at binding time » Choose unloaded server for each new client – What if client/server machines are different – Could provide same mbox (router level redirect) architectures or in different languages? » Choose unloaded server for each new request » Convert everything to/from some canonical form » Only works if no state carried from one call to next » Tag every item with an indication of how it is encoded • What if multiple clients? (avoids unnecessary conversions). – Pass pointer to client-specific return mbox in request 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.11 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.12
4 . Problems with RPC Andrew File System • Non-Atomic failures • Andrew File System (AFS, late 80’s) DCE DFS – Different failure modes in distributed system than on a (commercial product) single machine – Consider many different types of failures • Callbacks: Server records who has copy of file » User-level bug causes address space to crash – On changes, server immediately tells all with old copy » Machine failure, kernel bug causes all processes on same machine to fail – No polling bandwidth (continuous checking) needed » Some machine is compromised by malicious party – Before RPC: whole system would crash/die • Write through on close – After RPC: One machine crashes/compromised while – Changes not propagated to server until close() others keep working – Session semantics: updates visible to other clients only – Can easily result in inconsistent view of the world after the file is closed » Did my cached data get written back or not? » Did server do what I requested or not? » As a result, do not get partial writes: all or nothing! – Answer? Distributed transactions/Byzantine Commit » Although, for processes on local machine, updates visible • Performance immediately to other programs who have file open – Cost of Procedure call « same-machine RPC « network RPC • In AFS, everyone who has file open sees old version – Means programmers must be aware that RPC is not free » Caching can help, but may make failure handling complex – Don’t get newer versions until reopen file 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.13 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.14 Andrew File System (con’t) More Relaxed Consistency? • Data cached on local disk of client as well as memory • Can we get better performance by relaxing consistency? – On open with a cache miss (file not on local disk): » Get file from server, set up callback with server – More extensive use of caching – On write followed by close: – No need to check frequently to see if data up to date » Send copy to server; tells all clients with copies to fetch – No need to forward changes immediately to readers new version from server on next open (using callbacks) » AFS fixes this problem with “update on close” behavior • What if server crashes? Lose all callback state! – Frequent rewriting of an object does not require all – Reconstruct callback information from client: go ask everyone “who has which files cached?” changes to be sent to readers • AFS Pro: Relative to NFS, less server load: » Consider Write Caching behavior of local file system – is this a relaxed form of consistency? – Disk as cache more files can be cached locally » No, because all requests go through the same cache – Callbacks server not involved if file is read-only • For both AFS and NFS: central server is bottleneck! • Issues with relaxed consistency: – Performance: all writesserver, cache missesserver – When updates propagated to other readers? – Availability: Server is single point of failure – Consistent set of updates make it to readers? – Cost: server machine’s high cost relative to workstation – Updates lost when multiple simultaneous writers? 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.15 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.16
5 . Possible approaches to relaxed consistency Data Deduplication • Usual requirement: Coherence – Writes viewed by everyone in the same serial order Wide Area Network • Free-for-all – Writes happen at whatever granularity the system • How to address performance issues with network file chooses: block size, etc systems over wide area? What about caching? • Update on close – Files are often opened multiple times – As in AFS » Caching works – Makes sure that writes are consistent – Files are often changed incrementally • Conflict resolution: Clean up inconsistencies later » Caching less works less well – Different files often share content or groups of bytes – Often includes versioned data solution » Caching doesn’t work well at all! » Many branches, someone or something merges branches • Why doesn’t file caching work well in many cases? – At server or client – Because it is based on names rather than data – Server side made famous by Coda file system » Name of file, absolute position within file, etc » Every update that goes to server contains predicate to be run on data before commit • Better option? Base caching on contents rather than names » Provide a set of possible data modifications to be chosen – Called “Data de-duplication” based on predicate 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.17 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.18 Data-based Caching (Data “De-Duplication”) Low Bandwidth File System • Use a sliding-window hash function to break files into chunks – Rabin Fingerprint: randomized function of data window • LBFS (Low Bandwidth File System) » Pick sensitivity: e.g. 48 bytes at a time, lower 13 bits = 0 2-13 probability of happening, expected chunk size 8192 – Based on NFS v3 protocol » Need minimum and maximum chunk sizes – Uses AFS consistency, however » Writes made visible on close – Now – if data stays same, chunk stays the same – All messages passed through de-duplication process • Blocks named by cryptographic hashes such as SHA-1 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.19 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.20
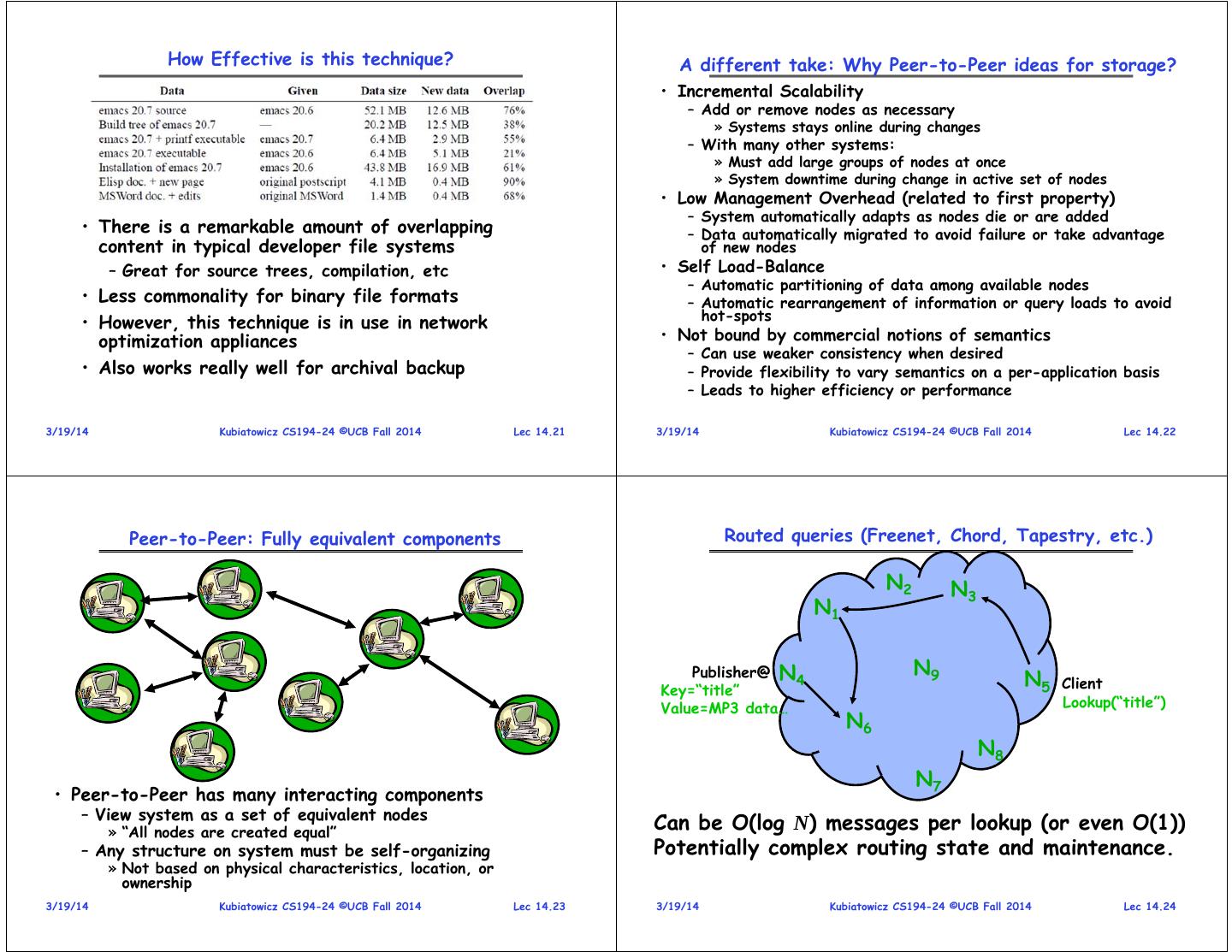
6 . How Effective is this technique? A different take: Why Peer-to-Peer ideas for storage? • Incremental Scalability – Add or remove nodes as necessary » Systems stays online during changes – With many other systems: » Must add large groups of nodes at once » System downtime during change in active set of nodes • Low Management Overhead (related to first property) – System automatically adapts as nodes die or are added • There is a remarkable amount of overlapping – Data automatically migrated to avoid failure or take advantage content in typical developer file systems of new nodes – Great for source trees, compilation, etc • Self Load-Balance – Automatic partitioning of data among available nodes • Less commonality for binary file formats – Automatic rearrangement of information or query loads to avoid • However, this technique is in use in network hot-spots optimization appliances • Not bound by commercial notions of semantics – Can use weaker consistency when desired • Also works really well for archival backup – Provide flexibility to vary semantics on a per-application basis – Leads to higher efficiency or performance 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.21 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.22 Peer-to-Peer: Fully equivalent components Routed queries (Freenet, Chord, Tapestry, etc.) N2 N3 N1 Publisher@ N N9 Key=“title” 4 N5 Client Value=MP3 data… Lookup(“title”) N6 N8 N7 • Peer-to-Peer has many interacting components – View system as a set of equivalent nodes » “All nodes are created equal” Can be O(log N) messages per lookup (or even O(1)) – Any structure on system must be self-organizing Potentially complex routing state and maintenance. » Not based on physical characteristics, location, or ownership 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.23 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.24
7 . Consistent hashing [Karger 97] Lookup with Leaf Set Key 5 • Assign IDs to nodes Source K5 Node 105 – Map hash values to node with closest ID N105 K20 • Leaf set is 111… successors and predecessors 0… Circular 160-bit – All that’s needed for 110… ID space N32 correctness • Routing table N90 matches successively longer prefixes – Allows efficient 10… K80 lookups A key is stored at its successor: node with next higher ID • Data Replication: Lookup ID – On leaf set 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.25 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.26 Advantages/Disadvantages of Consistent Hashing Dynamo Assumptions • Advantages: • Query Model – Simple interface exposed to application level – Automatically adapts data partitioning as node membership – Get(), Put() changes – No Delete() – Node given random key value automatically “knows” how to – No transactions, no complex queries participate in routing and data management – Random key assignment gives approximation to load balance • Atomicity, Consistency, Isolation, Durability • Disadvantages – Operations either succeed or fail, no middle ground – Uneven distribution of key storage natural consequence of – System will be eventually consistent, no sacrifice of availability random node names Leads to uneven query load to assure consistency – Key management can be expensive when nodes transiently fail – Conflicts can occur while updates propagate through system » Assuming that we immediately respond to node failure, must – System can still function while entire sections of network are transfer state to new node set down » Then when node returns, must transfer state back » Can be a significant cost if transient failure common • Efficiency – Measure system by the 99.9th percentile • Disadvantages of “Scalable” routing algorithms – Important with millions of users, 0.1% can be in the 10,000s – More than one hop to find data O(log N) or worse • Non Hostile Environment – Number of hops unpredictable and almost always > 1 – No need to authenticate query, no malicious queries » Node failure, randomness, etc – Behind web services, not in front of them 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.27 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.28
8 . Service Level Agreements (SLA) Replication • Each data item is replicated at N hosts • Application can deliver its functionality in a bounded • “preference list”: The list of nodes responsible for storing time: a particular key – Every dependency in the – Successive nodes not guaranteed platform needs to deliver its to be on different physical nodes functionality with even tighter – Thus preference list includes physically distinct nodes bounds. • Sloppy Quorum • Example: service guaranteeing – R (or W) is the minimum number of nodes that must participate that it will provide a response in a successful read (or write) operation. within 300ms for 99.9% of its – Setting R + W > N yields a quorum-like system. requests for a peak client load – Latency of a get (or put) is dictated by the slowest of the R of 500 requests per second (or W) replicas. For this reason, R and W are usually • Contrast to services which configured to be less than N, to provide better latency. focus on mean response time • Replicas synchronized via anti-entropy protocol – Use of Merkle tree for each unique range Service-oriented architecture – Nodes exchange root of trees for shared key range of Amazon’s platform 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.29 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.30 Data Versioning Vector clock example • A put() call may return to its caller before the update has been applied at all the replicas • A get() call may return many versions of the same object. • Challenge: an object having distinct version sub- histories, which the system will need to reconcile in the future. • Solution: uses vector clocks in order to capture causality between different versions of the same object – A vector clock is a list of (node, counter) pairs – Every version of every object is associated with one vector clock – If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.31 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.32
9 . Conflicts (multiversion data) Haystack File System • Client must resolve conflicts • Does it ever make sense to adapt a file system to a – Only resolve conflicts on reads particular usage pattern? – Different resolution options: – Perhaps » Use vector clocks to decide based on history • Good example: Facebook’s “Haystack” filesystem » Use timestamps to pick latest version – Specific application (Photo Sharing) – Examples given in paper: » Large files!, Many files! » For shopping cart, simply merge different versions » 260 Billion images, 20 PetaBytes (1015 bytes!) » For customer’s session information, use latest version » One billion new photos a week (60 TeraBytes) – Stale versions returned on reads are updated (“read repair”) – Presence of Content Delivery Network (CDN) • Vary N, R, W to match requirements of applications » Distributed caching and – High performance reads: R=1, W=N distribution network – Fast writes with possible inconsistency: W=1 » Facebook web servers return – Common configuration: N=3, R=2, W=2 special URLs that encode requests to CDN • When do branches occur? » Pay for service by bandwidth – Branches uncommon: 0.06% of requests saw > 1 version over – Specific usage patterns: 24 hours » New photos accessed a – Divergence occurs because of high write rate (more lot (caching well) coordinators), not necessarily because of failure » Old photos accessed little, but likely to be requested Number of photos at any time NEEDLES requested in day 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.33 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.34 Old Solution: NFS New Solution: Haystack • Issues with this design? • Finding a needle (old photo) in Haystack • Long Tail Caching does not • Differentiate between old work for most photos and new photos – Every access to back end storage – How? By looking at “Writeable” must be fast without benefit of vs “Read-only” volumes caching! – New Photos go to Writeable volumes • Linear Directory scheme works • Directory: Help locate photos badly for many photos/directory – Name (URL) of photo has – Many disk operations to find embedded volume and photo ID even a single photo • Let CDN or Haystack Cache – Directory’s block map too big to cache in memory Serve new photos – rather than forwarding them to – “Fixed” by reducing directory size, however still not great Writeable volumes • Meta-Data (FFS) requires ≥ 3 disk accesses per lookup • Haystack Store: Multiple “Physical Volumes” – Caching all iNodes in memory might help, but iNodes are big – Physical volume is large file (100 GB) which stores millions of photos • Fundamentally, Photo Storage different from other – Data Accessed by Volume ID with offset into file storage: – Since Physical Volumes are large files, use XFS which is optimized for large files – Normal file systems fine for developers, databases, etc 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.35 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.36
10 . Haystack Details Haystack Details (Con’t) • Replication for reliability and performance: – Multiple physical volumes combined into logical volume » Factor of 3 – Four different sizes » Thumbnails, Small, Medium, Large • Each physical volume is stored as single file in XFS • Lookup – Superblock: General information about the volume – User requests Webpage – Each photo (a “needle”) stored by appending to file – Webserver returns URL of form: • Needles stored sequentially in file » http://<CDN>/<Cache>/<Machine id>/<Logical volume,photo> – Naming: [Volume ID, Key, Alternate Key, Cookie] » Possibly reference cache only if old image – Cookie: random value to avoid guessing attacks – CDN will strip off CDN reference if missing, forward to cache – Key: Unique 64-bit photo ID – Cache will strip off cache reference and forward to Store – Alternate Key: four different sizes, ‘n’, ‘a’, ‘s’, ‘t’ • Deleted Needle Simply marked as “deleted” • In-memory index on Store for each volume map: – Overwritten Needle – new version appended at end [Key, Alternate Key] Offset 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.37 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.38 Summary (2/2) • Distributed File System: – Transparent access to files stored on a remote disk – Caching for performance • Data De-Duplication: Caching based on data contents • Peer-to-Peer: – Use of 100s or 1000s of nodes to keep higher performance or greater availability – May need to relax consistency for better performance • Application-Specific File Systems (e.g. Haystack): – Optimize system for particular usage pattern 3/19/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 14.39
3秒后跳转登录页面
去登陆

