













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
文件系统(续1)
•分布式文件系统
•点对点系统
•特定于应用程序的文件系统
展开查看详情
1 . Goals for Today CS194-24 • Durability Advanced Operating Systems – RAID Structures and Implementation – Log-structured File System, Journaling Lecture 13 • VFS • Distributed file systems File Systems (Con’t) • Peer-to-Peer Systems RAID/Journaling/VFS March 17th, 2014 Interactive is important! Prof. John Kubiatowicz Ask Questions! http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.2 Recall: Redundant Arrays of Disks Recall: Important “ilities” RAID 1: Disk Mirroring/Shadowing • Availability: the probability that the system can recovery accept and process requests group – Often measured in “nines” of probability. So, a 99.9% probability is considered “3-nines of availability” – Key idea here is independence of failures • Durability: the ability of a system to recover data despite faults • Each disk is fully duplicated onto its "shadow" – This idea is fault tolerance applied to data Very high availability can be achieved – Doesn’t necessarily imply availability: information on pyramids was very durable, but could not be accessed • Bandwidth sacrifice on write: until discovery of Rosetta Stone Logical write = two physical writes • Reliability: the ability of a system or component to perform its required functions under stated conditions • Reads may be optimized for a specified period of time (IEEE definition) – Usually stronger than simply availability: means that the • Most expensive solution: 100% capacity overhead system is not only “up”, but also working correctly – Includes availability, security, fault tolerance/durability – Must make sure data survives system crashes, disk Targeted for high I/O rate , high availability environments crashes, other problems 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.3 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.4
2 . Recall: Redundant Arrays of Disks RAID 5 Reed-Solomon Codes • RAID6: Capable of dealing with 2 disk failures Increasing – More complex than simple parity A logical write D0 D1 D2 D3 P Logical – Should not use only RAID5 with modern disk sizes becomes four Disk physical I/Os Addresses • Reed-Solomon codes: D4 D5 D6 P D7 – Based on polynomials in GF(2k) (I.e. k-bit symbols) Independent writes possible because of – Data as coefficients, code space as values of polynomial: D8 D9 P D10 D11 interleaved parity – P(x)=a0+a1x1+… ak-1xk-1 – Coded: P(0),P(1),P(2)….,P(n-1) Reed-Solomon D12 P D13 D14 D15 Codes ("Q") for Stripe – Can recover polynomial as long as get any k of n protection during • Properties: can choose number of check symbols reconstruction P D16 D17 D18 D19 Stripe – Reed-Solomon codes are “maximum distance separable” Unit (MDS) D20 D21 D22 D23 P – Can add d symbols for distance d+1 code . . . . . – Often used in “erasure code” mode: as long as no more . . Disk .Columns . . than n-k coded symbols erased, can recover data . . . . . 4/20/2011 cs252-S11, Lecture 23 6 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.5 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.6 Aside: Why erasure coding? High Durability/overhead ratio! Log Structured and Journaled File Systems • Better (write) performance through use of log – Optimized for writes to disk (log is contiguous) – Assume that reads handled through page cache • Better reliability through use of log – All changes are treated as transactions – A transaction is committed once it is written to the log » Data forced to disk for reliability Fraction Blocks Lost » Process can be accelerated with NVRAM Per Year (FBLPY) – Although File system may not be updated immediately, data preserved in the log • Difference between “Log Structured” and “Journaled” – In a Log Structured filesystem, data stays in log form – In a Journaled filesystem, Log used for recovery • For Journaled system: – Log used to asynchronously update filesystem • Exploit law of large numbers for durability! » Log entries removed after used – After crash: • 6 month repair, FBLPY: » Remaining transactions in the log performed (“Redo”) – Replication: 0.03 » Modifications done in way that can survive crashes – Fragmentation: 10-35 • Examples of Journaled File Systems: – Ext3 (Linux), XFS (Unix), etc. 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.7 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.8
3 . Log-Structured File System – Motivation LFS Basic Idea • Radically different file system design • Log all data and metadata with efficient, large, sequential writes • Technology motivations: • Treat the log as the truth, but keep an index on its – CPUs outpacing disks: I/O becoming more-and-more of a contents bottleneck • Rely on a large memory to provide fast access through – Large RAM: file caches work well, making most disk caching traffic writes • Data layout on disk has “temporal locality” (good for • Problems with (then) current file systems: writing), rather than “logical locality” (good for reading) – Lots of little writes – Why is this a better? Because caching helps reads but not – Synchronous: wait for disk in too many places – makes it writes! hard to win much from RAIDs, too little concurrency • Two potential problems: – 5 seeks to create a new file: (rough order) – Log retrieval on cache misses 1. file i-node (create) – Wrap-around: what happens when end of disk is reached? 2. file data » No longer any big, empty runs available 3. directory entry » How to prevent fragmentation? 4. file i-node (finalize) 5. directory i-node (modification time) 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.9 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.10 Comparison of LFS and FFS LFS Log Retrieval • Keep same basic file structure as UNIX (inode, indirect blocks, data) • Retrieval is just a question of finding a file’s inode • UNIX inodes kept in one or a few big arrays, LFS inodes must float to avoid update-in- place • Solution: an inode map that tells where each inode is • Comparison of LFS (Sprite) with FFS (Unix) (Also keeps other stuff: version number, last access – Creation of two single-block files named dir1/file1 and dir2/file2 time, free/allocated) – Each writes new blocks and inodes for file 1 and file 2 • inode map gets written to log like everything else – Each writes new data blocks and inodes for directories • FFS Traffic: • Map of inode map gets written in special checkpoint – Ten non-sequential writes for new information location on disk; used in crash recovery – Inodes each written twice to ease recovery from crashes • LFS Traffic: – Single large write • For both when reading back: same number of disk accesses 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.11 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.12
4 . LFS Disk Wrap-Around LFS Segment Cleaning • Compact live info to open up large runs of free space • Which segments to clean? – Problem: long-lived information gets copied over-and-over – Keep estimate of free space in each segment to help • Thread log through free spaces find segments with lowest utilization – Problem: disk fragments, causing I/O to become inefficient – Always start by looking for segment with utilization=0, again since those are trivial to clean… – If utilization of segments being cleaned is U: • Solution: segmented log » write cost = – Divide disk into large, fixed-size segments (total bytes read & written)/(new data written) = 2/(1-U) (unless U is 0) – Do compaction within a segment; thread between segments » write cost increases as U increases: U = .9 => cost = 20! – When writing, use only clean segments (i.e. no live data) » Need a cost of less than 4 to 10; => U of less than .75 – Occasionally clean segments: read in several, write out live to .45 data in compacted form, leaving some fragments free – Try to collect long-lived info into segments that never need to • How to clean a segment? be cleaned – Segment summary block contains map of the segment – Note there is not free list or bit map (as in FFS), only a list – Must list every i-node and file block of clean segments – For file blocks you need {i-number, block #} 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.13 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.14 Analysis and Evolution of Journaling File Systems Three modes for a JFS • Write-ahead logging: commit data by writing it to • Writeback mode: log, synchronously and sequentially – Journal only metadata • Unlike LFS, then later moved data to its normal – Write back data and metadata independently (FFS-like) location – this write is called – Metadata may thus have dangling references after a checkpointing and like segment cleaning, it makes crash (if metadata written before the data with a crash in between) room in the (circular) journal • Better for random writes, slightly worse for big • Ordered mode: sequential writes – Journal only metadata, but always write data blocks • All reads go the the fixed location blocks, not the before their referring metadata is journaled journal, which is only read for crash recovery and – This mode generally makes the most sense and is used by checkpointing Windows NTFS and IBM’s JFS • Much better than FFS (fsck) for crash recovery (covered below) because it is much faster • Data journaling mode: • Ext3/ReiserFS/Ext4 filesystems are the main ones – Write both data and metadata to the journal in Linux – Huge increase in journal traffic; plus have to write most blocks twice, once to the journal and once for checkpointing 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.15 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.16
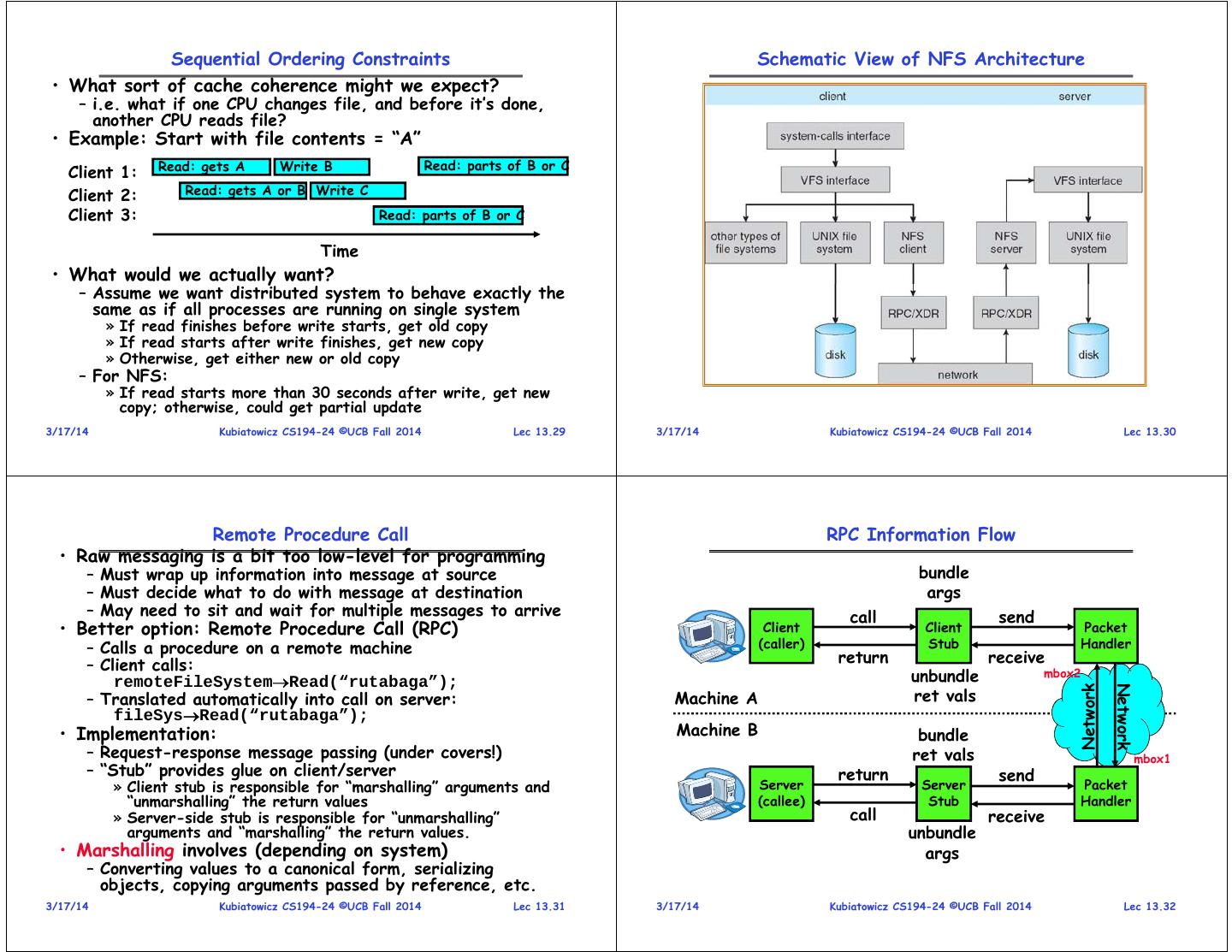
5 . What about remote file systems? Virtual Filesystem Switch (VFS) • Remote File System: – Storage available over a network – Local storage is only a cache on permanent storage • Advantages? – Someone else worries about keeping data safe – Data Accessible from multiple physical locations • Disadvantages? – Performance – may take one or more network • VFS: Virtual abstraction similar to local file system roundtrips to fetch data – Instead of “inodes” has “vnodes” – Privacy: your data is available over the network, – Compatible with a variety of local and remote file systems others can possibly see your data » provides object-oriented way of implementing file systems – Integrity: without sufficient protections, others • VFS allows the same system call interface (the API) to can overwrite/delete your data be used for different types of file systems – The API is to the VFS interface, rather than any specific type of file system 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.17 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.18 Virtual Filesystem Switch (VFS) VFS Common File Model • Four primary object types for VFS: – superblock object: represents a specific mounted filesystem • VFS: Virtual abstraction similar to local file system – inode object: represents a specific file – Provides virtual superblocks, inodes, files, etc – dentry object: represents a directory entry – Compatible with a variety of local and remote file systems – file object: represents open file associated with process » provides object-oriented way of implementing file systems • There is no specific directory object (VFS treats • VFS allows the same system call interface (the API) to directories as files) be used for different types of file systems • May need to fit the model by faking it – The API is to the VFS interface, rather than any specific – Example: make it look like directories are files type of file system – Example: make it look like have inodes, superblocks, etc. 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.19 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.20
6 . Linux VFS Network-Attached Storage and the CAP Theorem filesystem’s write() sys_write() write method user-space VFS filesystem physical Network media • An operations object is contained within each primary object type to set operations of specific filesystems – “super_operations”: methods that kernel can invoke on a specific filesystem, i.e. write_inode() and sync_fs(). • Consistency: – “inode_operations”: methods that kernel can invoke on a specific – Changes appear to everyone in the same serial order file, such as create() and link() • Availability: – “dentry_operations”: methods that kernel can invoke on a specific – Can get a result at any time directory entry, such as d_compare() or d_delete() • Partition-Tolerance – “file_operations”: methods that process can invoke on an open – System continues to work even when network becomes file, such as read() and write() partitioned • Consistency, Availability, Partition-Tolerance (CAP) Theorem: • There are a lot of operations Cannot have all three at same time – You need to read Bovet Chapter 12 and Love Chapter 13 – Otherwise known as “Brewer’s Theorem” 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.21 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.22 Simple Distributed File System Use of caching to reduce network load read(f1)V1 cache Read (RPC) Read (RPC) read(f1)V1 F1:V1 Return (Data) Return (Data) read(f1)V1 Client Client read(f1)V1 Server cache Server cache F1:V2 F1:V1 cache write(f1)OK F1:V2 Client read(f1)V2 Client • Remote Disk: Reads and writes forwarded to server • Idea: Use caching to reduce network load – Use RPC to translate file system calls – In practice: use buffer cache at source and destination – No local caching/can be caching at server-side • Advantage: if open/read/write/close can be done • Advantage: Server provides completely consistent view locally, don’t need to do any network traffic…fast! of file system to multiple clients • Problems: • Problems? Performance! – Failure: – Going over network is slower than going to local memory » Client caches have data not committed at server – Lots of network traffic/not well pipelined – Cache consistency! – Server can be a bottleneck » Client caches not consistent with server/each other 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.23 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.24
7 . Failures Crash! Network File System (NFS) • Three Layers for NFS system • What if server crashes? Can client wait until server – UNIX file-system interface: open, read, write, close comes back up and continue as before? calls + file descriptors – Any data in server memory but not on disk can be lost – VFS layer: distinguishes local from remote files – Shared state across RPC: What if server crashes after » Calls the NFS protocol procedures for remote requests seek? Then, when client does “read”, it will fail – NFS service layer: bottom layer of the architecture – Message retries: suppose server crashes after it does » Implements the NFS protocol UNIX “rm foo”, but before acknowledgment? • NFS Protocol: RPC for file operations on server » Message system will retry: send it again » How does it know not to delete it again? (could solve with – Reading/searching a directory two-phase commit protocol, but NFS takes a more ad hoc – manipulating links and directories approach) – accessing file attributes/reading and writing files • Stateless protocol: A protocol in which all information • Write-through caching: Modified data committed to required to process a request is passed with request server’s disk before results are returned to the client – Server keeps no state about client, except as hints to – lose some of the advantages of caching help improve performance (e.g. a cache) – Thus, if server crashes and restarted, requests can – time to perform write() can be long continue where left off (in many cases) – Need some mechanism for readers to eventually notice • What if client crashes? changes! (more on this later) – Might lose modified data in client cache 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.25 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.26 NFS Continued NFS Cache consistency • NFS servers are stateless; each request provides all • NFS protocol: weak consistency arguments require for execution – E.g. reads include information for entire operation, such – Client polls server periodically to check for changes as ReadAt(inumber,position), not Read(openfile) » Polls server if data hasn’t been checked in last 3-30 – No need to perform network open() or close() on file – seconds (exact timeout it tunable parameter). each operation stands on its own » Thus, when file is changed on one client, server is notified, but other clients use old version of file until timeout. • Idempotent: Performing requests multiple times has same effect as performing it exactly once – Example: Server crashes between disk I/O and message cache F1 still ok? send, client resend read, server does operation again F1:V2 F1:V1 No: (F1:V2) – Example: Read and write file blocks: just re-read or re- write file block – no side effects Client – Example: What about “remove”? NFS does operation Server cache twice and second time returns an advisory error F1:V2 • Failure Model: Transparent to client system cache – Is this a good idea? What if you are in the middle of F1:V2 reading a file and server crashes? Client – Options (NFS Provides both): – What if multiple clients write to same file? » Hang until server comes back up (next week?) » Return an error. (Of course, most applications don’t know » In NFS, can get either version (or parts of both) they are talking over network) » Completely arbitrary! 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.27 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.28
8 . Sequential Ordering Constraints Schematic View of NFS Architecture • What sort of cache coherence might we expect? – i.e. what if one CPU changes file, and before it’s done, another CPU reads file? • Example: Start with file contents = “A” Read: gets A Write B Read: parts of B or C Client 1: Client 2: Read: gets A or B Write C Client 3: Read: parts of B or C Time • What would we actually want? – Assume we want distributed system to behave exactly the same as if all processes are running on single system » If read finishes before write starts, get old copy » If read starts after write finishes, get new copy » Otherwise, get either new or old copy – For NFS: » If read starts more than 30 seconds after write, get new copy; otherwise, could get partial update 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.29 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.30 Remote Procedure Call RPC Information Flow • Raw messaging is a bit too low-level for programming – Must wrap up information into message at source bundle – Must decide what to do with message at destination args – May need to sit and wait for multiple messages to arrive call send • Better option: Remote Procedure Call (RPC) Client Client Packet – Calls a procedure on a remote machine (caller) Stub Handler – Client calls: return receive remoteFileSystemRead(“rutabaga”); unbundle mbox2 Network Network – Translated automatically into call on server: Machine A ret vals fileSysRead(“rutabaga”); • Implementation: Machine B bundle – Request-response message passing (under covers!) ret vals mbox1 – “Stub” provides glue on client/server return send » Client stub is responsible for “marshalling” arguments and Server Server Packet “unmarshalling” the return values (callee) Stub Handler » Server-side stub is responsible for “unmarshalling” call receive arguments and “marshalling” the return values. unbundle • Marshalling involves (depending on system) args – Converting values to a canonical form, serializing objects, copying arguments passed by reference, etc. 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.31 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.32
9 . RPC Details RPC Details (continued) • How does client know which mbox to send to? • Equivalence with regular procedure call – Need to translate name of remote service into network – Parameters Request Message endpoint (Remote machine, port, possibly other info) – Result Reply message – Binding: the process of converting a user-visible name – Name of Procedure: Passed in request message into a network endpoint – Return Address: mbox2 (client return mail box) » This is another word for “naming” at network level • Stub generator: Compiler that generates stubs » Static: fixed at compile time – Input: interface definitions in an “interface definition » Dynamic: performed at runtime language (IDL)” • Dynamic Binding » Contains, among other things, types of arguments/return – Most RPC systems use dynamic binding via name service – Output: stub code in the appropriate source language » Name service provides dynamic translation of servicembox » Code for client to pack message, send it off, wait for – Why dynamic binding? result, unpack result and return to caller » Access control: check who is permitted to access service » Code for server to unpack message, call procedure, pack » Fail-over: If server fails, use a different one results, send them off • What if there are multiple servers? • Cross-platform issues: – Could give flexibility at binding time » Choose unloaded server for each new client – What if client/server machines are different – Could provide same mbox (router level redirect) architectures or in different languages? » Choose unloaded server for each new request » Convert everything to/from some canonical form » Only works if no state carried from one call to next » Tag every item with an indication of how it is encoded • What if multiple clients? (avoids unnecessary conversions). – Pass pointer to client-specific return mbox in request 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.33 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.34 Problems with RPC Andrew File System • Non-Atomic failures • Andrew File System (AFS, late 80’s) DCE DFS – Different failure modes in distributed system than on a (commercial product) single machine – Consider many different types of failures • Callbacks: Server records who has copy of file » User-level bug causes address space to crash – On changes, server immediately tells all with old copy » Machine failure, kernel bug causes all processes on same machine to fail – No polling bandwidth (continuous checking) needed » Some machine is compromised by malicious party – Before RPC: whole system would crash/die • Write through on close – After RPC: One machine crashes/compromised while – Changes not propagated to server until close() others keep working – Session semantics: updates visible to other clients only – Can easily result in inconsistent view of the world after the file is closed » Did my cached data get written back or not? » Did server do what I requested or not? » As a result, do not get partial writes: all or nothing! – Answer? Distributed transactions/Byzantine Commit » Although, for processes on local machine, updates visible • Performance immediately to other programs who have file open – Cost of Procedure call « same-machine RPC « network RPC • In AFS, everyone who has file open sees old version – Means programmers must be aware that RPC is not free » Caching can help, but may make failure handling complex – Don’t get newer versions until reopen file 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.35 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.36
10 . Andrew File System (con’t) More Relaxed Consistency? • Data cached on local disk of client as well as memory • Can we get better performance by relaxing consistency? – On open with a cache miss (file not on local disk): » Get file from server, set up callback with server – More extensive use of caching – On write followed by close: – No need to check frequently to see if data up to date » Send copy to server; tells all clients with copies to fetch – No need to forward changes immediately to readers new version from server on next open (using callbacks) » AFS fixes this problem with “update on close” behavior • What if server crashes? Lose all callback state! – Frequent rewriting of an object does not require all – Reconstruct callback information from client: go ask everyone “who has which files cached?” changes to be sent to readers • AFS Pro: Relative to NFS, less server load: » Consider Write Caching behavior of local file system – is this a relaxed form of consistency? – Disk as cache more files can be cached locally » No, because all requests go through the same cache – Callbacks server not involved if file is read-only • For both AFS and NFS: central server is bottleneck! • Issues with relaxed consistency: – Performance: all writesserver, cache missesserver – When updates propagated to other readers? – Availability: Server is single point of failure – Consistent set of updates make it to readers? – Cost: server machine’s high cost relative to workstation – Updates lost when multiple simultaneous writers? 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.37 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.38 Possible approaches to relaxed consistency Data Deduplication • Usual requirement: Coherence – Writes viewed by everyone in the same serial order Wide Area Network • Free-for-all – Writes happen at whatever granularity the system • How to address performance issues with network file chooses: block size, etc systems over wide area? What about caching? • Update on close – Files are often opened multiple times – As in AFS » Caching works – Makes sure that writes are consistent – Files are often changed incrementally • Conflict resolution: Clean up inconsistencies later » Caching less works less well – Different files often share content or groups of bytes – Often includes versioned data solution » Caching doesn’t work well at all! » Many branches, someone or something merges branches • Why doesn’t file caching work well in many cases? – At server or client – Because it is based on names rather than data – Server side made famous by Coda file system » Name of file, absolute position within file, etc » Every update that goes to server contains predicate to be run on data before commit • Better option? Base caching on contents rather than names » Provide a set of possible data modifications to be chosen – Called “Data de-duplication” based on predicate 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.39 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.40
11 . Data-based Caching (Data “De-Duplication”) Low Bandwidth File System • Use a sliding-window hash function to break files into chunks – Rabin Fingerprint: randomized function of data window • LBFS (Low Bandwidth File System) » Pick sensitivity: e.g. 48 bytes at a time, lower 13 bits = 0 2-13 probability of happening, expected chunk size 8192 – Based on NFS v3 protocol » Need minimum and maximum chunk sizes – Uses AFS consistency, however » Writes made visible on close – Now – if data stays same, chunk stays the same – All messages passed through de-duplication process • Blocks named by cryptographic hashes such as SHA-1 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.41 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.42 How Effective is this technique? Summary (1/2) • Redundancy – RAID: Use of coding and redundancy to protect against failure of disks – Reed-Solomon: Erasure coding for even greater protection • Log Structured File system (LFS) • There is a remarkable amount of overlapping – The Log is the file system content in typical developer file systems – All updates written sequentially in the log – Great for source trees, compilation, etc – Inode map tracks where inodes lie in the log • Less commonality for binary file formats • Journaling File System (JFS, Ext3, …) • However, this technique is in use in network – Use of log to help durability optimization appliances – Primary storage in read-optimized format • Also works really well for archival backup 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.43 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.44
12 . Summary (2/2) • VFS: Virtual File System layer – Provides mechanism which gives same system call interface for different types of file systems • Distributed File System: – Transparent access to files stored on a remote disk – Caching for performance • Data De-Duplication: Caching based on data contents • Peer-to-Peer: – Use of 100s or 1000s of nodes to keep higher performance or greater availability – May need to relax consistency for better performance • Next Time: Application-Specific File Systems (e.g. Dynamo, Haystack): – Optimize system for particular usage pattern 3/17/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.45
3秒后跳转登录页面
去登陆

