












- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
文件系统(续)
-日志结构化文件系统
-日记文件系统
-分布式文件系统
-虚拟文件系统层
展开查看详情
1 . Goals for Today CS194-24 • File Systems (Continued) Advanced Operating Systems • Durability Structures and Implementation – RAID Lecture 13 – Log-structured File System, Journaling • VFS File Systems (Con’t) RAID/Journaling/VFS March 9th, 2014 Interactive is important! Prof. John Kubiatowicz Ask Questions! http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.2 Recall: Implementing LRU Recall: Second-Chance List Algorithm (VAX/VMS) • Perfect: LRU victim – Timestamp page on each reference Directly Second – Keep list of pages ordered by time of reference Mapped Pages Chance List – Too expensive to implement in reality for many reasons • Clock Algorithm: Arrange physical pages in circle with Marked: RW Marked: Invalid single clock hand List: FIFO List: LRU – Approximate LRU (approx to approx to MIN) – Replace an old page, not the oldest page Page-in New New • Details: From disk Active SC – Hardware “use” bit per physical page: Pages Victims » Hardware sets use bit on each reference • Split memory in two: Active list (RW), SC list (Invalid) » If use bit isn’t set, means not referenced in a long time • Access pages in Active list at full speed » Nachos hardware sets use bit in the TLB; you have to copy • Otherwise, Page Fault this back to page table when TLB entry gets replaced – Always move overflow page from end of Active list to – On page fault: front of Second-chance list (SC) and mark invalid » Advance clock hand (not real time) » Check use bit: 1used recently; clear and leave alone – Desired Page On SC List: move to front of Active list, 0selected candidate for replacement mark RW – Will always find a page or loop forever? – Not on SC list: page in to front of Active list, mark RW; » Even if all use bits set, will eventually loop aroundFIFO page out LRU victim at end of SC list 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.3 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.4
2 . Recall: Linked Allocation: File-Allocation Table (FAT) Multilevel Indexed Files (UNIX BSD 4.1) • Multilevel Indexed Files: Like multilevel address translation (from UNIX 4.1 BSD) – Key idea: efficient for small files, but still allow big files – File header contains 13 pointers » Fixed size table, pointers not all equivalent » This header is called an “inode” in UNIX – File Header format: » First 10 pointers are to data blocks » Block 11 points to “indirect block” containing 256 blocks » Block 12 points to “doubly indirect block” containing 256 indirect blocks for total of 64K blocks » Block 13 points to a triply indirect block (16M blocks) • Discussion • MSDOS links pages together to create a file – Basic technique places an upper limit on file size that is – Links not in pages, but in the File Allocation Table (FAT) approximately 16Gbytes » FAT contains an entry for each block on the disk » Designers thought this was bigger than anything anyone » FAT Entries corresponding to blocks of file linked together would need. Much bigger than a disk at the time… – Access properies: » Fallacy: today, EOS producing 2TB of data per day » Sequential access expensive unless FAT cached in memory – Pointers get filled in dynamically: need to allocate » Random access expensive always, but really expensive if indirect block only when file grows > 10 blocks. FAT not cached in memory » On small files, no indirection needed 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.5 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.6 Example of Multilevel Indexed Files Administrivia • Sample file in multilevel indexed format: • Midterm I: Wednesday (3/12)! – How many accesses for – Intention is a 1.5 hour exam over 3 hours block #23? (assume file – No class on day of exam! header accessed on open)? » Two: One for indirect block, • Midterm Timing: one for data – 7:00-10:00PM in 306 Soda Hall (Here!) – How about block #5? » One: One for data • Topics: everything up to Monday – Block #340? – OS Structure, BDD, Process support, Synchronization, » Three: double indirect block, Memory Management, File systems indirect block, and data – Labs/Papers • UNIX 4.1 Pros and cons – Pros: Simple (more or less) • Notes: 1 page both sides, hand written Files can easily expand (up to a point) Small files particularly cheap and easy – Cons: Lots of seeks Very large files must read many indirect block (four I/Os per block!) 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.7 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.8
3 . File Allocation for Cray-1 DEMOS Large File Version of DEMOS basesize disk group base size base size disk group 1,3,2 1,3,2 1,3,3 1,3,3 1,3,4 1,3,4 Basic Segmentation Structure: 1,3,5 1,3,5 1,3,6 Each segment contiguous on disk 1,3,6 1,3,7 1,3,7 1,3,8 1,3,8 file header 1,3,9 file header indirect 1,3,9 block group • DEMOS: File system structure similar to segmentation • What if need much bigger files? – Idea: reduce disk seeks by – If need more than 10 groups, set flag in header: BIGFILE » using contiguous allocation in normal case » Each table entry now points to an indirect block group » but allow flexibility to have non-contiguous allocation – Suppose 1000 blocks in a block group 80GB max file – Cray-1 had 12ns cycle time, so CPU:disk speed ratio about » Assuming 8KB blocks, 8byte entries the same as today (a few million instructions per seek) (10 ptrs1024 groups/ptr1000 blocks/group)*8K =80GB • Header: table of base & size (10 “block group” pointers) • Discussion of DEMOS scheme – Pros: Fast sequential access, Free areas merge simply – Each block chunk is a contiguous group of disk blocks Easy to find free block groups (when disk not full) – Sequential reads within a block chunk can proceed at high – Cons: Disk full No long runs of blocks (fragmentation), speed – similar to continuous allocation so high overhead allocation/access • How do you find an available block group? – Full disk worst of 4.1BSD (lots of seeks) with worst of – Use freelist bitmap to find block of 0’s. continuous allocation (lots of recompaction needed) 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.9 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.10 How to keep DEMOS performing well? UNIX BSD 4.2 • In many systems, disks are always full • Same as BSD 4.1 (same file header and triply indirect blocks), except incorporated ideas from DEMOS: – How to fix? Announce that disk space is getting low, so – Uses bitmap allocation in place of freelist please delete files? – Attempt to allocate files contiguously » Don’t really work: people try to store their data faster – 10% reserved disk space – Sidebar: Perhaps we are getting out of this mode with – Skip-sector positioning (mentioned next slide) new disks… However, let’s assume disks full for now • Fast File System (FFS) • Solution: – Allocation and placement policies for BSD 4.2 – Don’t let disks get completely full: reserve portion • Problem: When create a file, don’t know how big it » Free count = # blocks free in bitmap will become (in UNIX, most writes are by appending) » Scheme: Don’t allocate data if count < reserve – How much contiguous space do you allocate for a file? – How much reserve do you need? – In Demos, power of 2 growth: once it grows past 1MB, allocate 2MB, etc » In practice, 10% seems like enough – In BSD 4.2, just find some range of free blocks – Tradeoff: pay for more disk, get contiguous allocation » Put each new file at the front of different range » Since seeks so expensive for performance, this is a very » To expand a file, you first try successive blocks in good tradeoff bitmap, then choose new range of blocks – Also: store files from same directory near each other • Problem: Block size (512) too small – Increase block size to 4096 or 8192 – Bitmask to allow files to consume partial fragment 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.11 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.12
4 . Attack of the Rotational Delay How do we actually access files? • Problem: Missing blocks due to rotational delay • All information about a file contained in its file header – Issue: Read one block, do processing, and read next – UNIX calls this an “inode” block. In meantime, disk has continued turning: missed » Inodes are global resources identified by index (“inumber”) next block! Need 1 revolution/block! – Once you load the header structure, all the other blocks Skip Sector of the file are locatable • Question: how does the user ask for a particular file? – One option: user specifies an inode by a number (index). Track Buffer » Imagine: open(“14553344”) (Holds complete track) – Better option: specify by textual name – Solution1: Skip sector positioning (“interleaving”) » Have to map nameinumber – Another option: Icon » Place the blocks from one file on every other block of a track: give time for processing to overlap rotation » This is how Apple made its money. Graphical user – Solution2: Read ahead: read next block right after first, interfaces. Point to a file and click. even if application hasn’t asked for it yet. • Naming: The process by which a system translates from » This can be done either by OS (read ahead) user-visible names to system resources » By disk itself (track buffers). Many disk controllers have – In the case of files, need to translate from strings internal RAM that allows them to read a complete track (textual names) or icons to inumbers/inodes • Important Aside: Modern disks+controllers do many – For global file systems, data may be spread over complex things “under the covers” globeneed to translate from strings or icons to some – Track buffers, elevator algorithms, bad block filtering combination of physical server location and inumber 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.13 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.14 Directories Directory Structure • Directory: a relation used for naming – Just a table of (file name, inumber) pairs • How are directories constructed? – Directories often stored in files » Reuse of existing mechanism » Directory named by inode/inumber like other files – Needs to be quickly searchable » Options: Simple list or Hashtable » Can be cached into memory in easier form to search • Not really a hierarchy! • How are directories modified? – Many systems allow directory structure to be organized – Originally, direct read/write of special file as an acyclic graph or even a (potentially) cyclic graph – System calls for manipulation: mkdir, rmdir – Hard Links: different names for the same file – Ties to file creation/destruction » Multiple directory entries point at the same file – Soft Links: “shortcut” pointers to other files • Directories organized into a hierarchical structure » Implemented by storing the logical name of actual file – Entries in directory can be either files or directories • Name Resolution: The process of converting a logical – Files named by “path” through directory structure: name into a physical resource (like a file) e.g. /usr/homes/george/data.txt – Traverse succession of directories until reach target file – Global file system: May be spread across the network 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.15 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.16
5 . Directory Structure (Con’t) Where are inodes stored? • How many disk accesses to resolve “/my/book/count”? • In early UNIX and DOS/Windows’ FAT file – Read in file header for root (fixed spot on disk) system, headers stored in special array in – Read in first data block for root » Table of file name/index pairs. Search linearly – ok since outermost cylinders directories typically very small – Header not stored near the data blocks. To read a – Read in file header for “my” small file, seek to get header, seek back to data. – Read in first data block for “my”; search for “book” – Fixed size, set when disk is formatted. At – Read in file header for “book” formatting time, a fixed number of inodes were – Read in first data block for “book”; search for “count” created (They were each given a unique number, – Read in file header for “count” called an “inumber”) • Current working directory: Per-address-space pointer to a directory (inode) used for resolving file names – Allows user to specify relative filename instead of absolute path (say CWD=“/my/book” can resolve “count”) 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.17 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.18 Where are inodes stored? In-Memory File System Structures • Later versions of UNIX moved the header information to be closer to the data blocks – Often, inode for file stored in same “cylinder group” as parent directory of the file (makes an ls of that directory run fast). – Pros: • Open system call: » UNIX BSD 4.2 puts a portion of the file header – Resolves file name, finds file control block (inode) array on each cylinder. For small directories, can – Makes entries in per-process and system-wide tables fit all data, file headers, etc in same cylinderno seeks! – Returns index (called “file handle”) in open-file table » File headers much smaller than whole block (a few hundred bytes), so multiple headers fetched from disk at same time » Reliability: whatever happens to the disk, you can find many of the files (even if directories disconnected) – Part of the Fast File System (FFS) » General optimization to avoid seeks • Read/write system calls: – Use file handle to locate inode – Perform appropriate reads or writes 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.19 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.20
6 . File System Caching File System Caching (con’t) • Key Idea: Exploit locality by caching data in memory • Cache Size: How much memory should the OS allocate – Name translations: Mapping from pathsinodes to the buffer cache vs virtual memory? – Disk blocks: Mapping from block addressdisk content – Too much memory to the file system cache won’t be • Buffer Cache: Memory used to cache kernel resources, able to run many applications at once including disk blocks and name translations – Too little memory to file system cache many – Can contain “dirty” blocks (blocks yet on disk) applications may run slowly (disk caching not effective) • Replacement policy? LRU – Solution: adjust boundary dynamically so that the disk – Can afford overhead of timestamps for each disk block access rates for paging and file access are balanced – Advantages: • Read Ahead Prefetching: fetch sequential blocks early » Works very well for name translation – Key Idea: exploit fact that most common file access is » Works well in general as long as memory is big enough to sequential by prefetching subsequent disk blocks ahead of accommodate a host’s working set of files. current read request (if they are not already in memory) – Disadvantages: – Elevator algorithm can efficiently interleave groups of » Fails when some application scans through file system, prefetches from concurrent applications thereby flushing the cache with data used only once » Example: find . –exec grep foo {} \; – How much to prefetch? • Other Replacement Policies? » Too many imposes delays on requests by other applications – Some systems allow applications to request other policies » Too few causes many seeks (and rotational delays) among concurrent file requests – Example, ‘Use Once’: » File system can discard blocks as soon as they are used 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.21 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.22 File System Caching (con’t) The Linux Page Cache • Delayed Writes: Writes to files not immediately sent out to disk • Goal: Minimize disk I/O by storing data in memory – Caches any page-based objects, including files and memory – Instead, write() copies data from user space buffer mappings to kernel buffer (in cache) • Cache consists of many address_space objects » Enabled by presence of buffer cache: can leave written file blocks in cache for a while – Really misnamed should be a “page_cache_entity” or “physical_pages_of_a_file” » If some other application tries to read data before – Can hold one or more pages from a file or swapper written to disk, file system will read from cache – Often associated with an inode, but doesn’t have to be – Flushed to disk periodically (e.g. in UNIX, every 30 sec) • Searching an address_space object for given page is done – Advantages: by offset » Disk scheduler can efficiently order lots of requests – Contains a set of address_space operations » Disk allocation algorithm can be run with correct size value » For reading/writing pages from disk for a file – An address_space contains a radix tree of all pages » Some files need never get written to disk! (e..g temporary scratch files written /tmp often don’t exist for 30 sec) • Flusher Threads – Disadvantages – Start pushing dirty blocks back to disk when free memory shrinks below a specified hreshold » What if system crashes before file has been written out? » Worse yet, what if system crashes before a directory file has been written out? (lose pointer to inode!) 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.23 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.24
7 . Important “ilities” How to make file system durable? • Availability: the probability that the system can • Disk blocks contain Reed-Solomon error correcting accept and process requests codes (ECC) to deal with small defects in disk drive – Often measured in “nines” of probability. So, a 99.9% – Can allow recovery of data from small media defects probability is considered “3-nines of availability” • Make sure writes survive in short term – Key idea here is independence of failures – Either abandon delayed writes or • Durability: the ability of a system to recover data – use special, battery-backed RAM (called non-volatile RAM despite faults or NVRAM) for dirty blocks in buffer cache. – This idea is fault tolerance applied to data • Make sure that data survives in long term – Doesn’t necessarily imply availability: information on – Need to replicate! More than one copy of data! pyramids was very durable, but could not be accessed – Important element: independence of failure until discovery of Rosetta Stone » Could put copies on one disk, but if disk head fails… • Reliability: the ability of a system or component to » Could put copies on different disks, but if server fails… » Could put copies on different servers, but if building is perform its required functions under stated conditions struck by lightning…. for a specified period of time (IEEE definition) » Could put copies on servers in different continents… – Usually stronger than simply availability: means that the • RAID: Redundant Arrays of Inexpensive Disks system is not only “up”, but also working correctly – Data stored on multiple disks (redundancy) – Includes availability, security, fault tolerance/durability – Either in software or hardware – Must make sure data survives system crashes, disk » In hardware case, done by disk controller; file system may crashes, other problems not even know that there is more than one disk in use 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.25 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.26 Redundant Arrays of Disks RAID 1: Disk Mirroring/Shadowing Redundant Arrays of Disks RAID 5+: High I/O Rate Parity recovery group Increasing A logical write D0 D1 D2 D3 P Logical becomes four Disk physical I/Os Addresses D4 D5 D6 P D7 Independent writes • Each disk is fully duplicated onto its "shadow" possible because of D8 D9 P D10 D11 Very high availability can be achieved interleaved parity • Bandwidth sacrifice on write: Reed-Solomon D12 P D13 D14 D15 Logical write = two physical writes Codes ("Q") for Stripe protection during • Reads may be optimized P D16 D17 D18 D19 reconstruction Stripe Unit • Most expensive solution: 100% capacity overhead D20 D21 D22 D23 P . . . . . Targeted for high I/O rate , high availability environments . . Disk .Columns . . . . . . . 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.27 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.28
8 . Log Structured and Journaled File Systems Log-Structured File System – Motivation • Better (write) performance through use of log • Radically different file system design – Optimized for writes to disk (log is contiguous) – Assume that reads handled through page cache • Technology motivations: • Better reliability through use of log – CPUs outpacing disks: I/O becoming more-and-more of a – All changes are treated as transactions bottleneck – A transaction is committed once it is written to the log – Large RAM: file caches work well, making most disk » Data forced to disk for reliability traffic writes » Process can be accelerated with NVRAM – Although File system may not be updated immediately, data • Problems with (then) current file systems: preserved in the log – Lots of little writes • Difference between “Log Structured” and “Journaled” – In a Log Structured filesystem, data stays in log form – Synchronous: wait for disk in too many places – makes it – In a Journaled filesystem, Log used for recovery hard to win much from RAIDs, too little concurrency • For Journaled system: – 5 seeks to create a new file: (rough order) – Log used to asynchronously update filesystem 1. file i-node (create) » Log entries removed after used 2. file data – After crash: » Remaining transactions in the log performed (“Redo”) 3. directory entry » Modifications done in way that can survive crashes 4. file i-node (finalize) • Examples of Journaled File Systems: 5. directory i-node (modification time) – Ext3 (Linux), XFS (Unix), etc. 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.29 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.30 LFS Basic Idea Comparison of LFS and FFS • Log all data and metadata with efficient, large, sequential writes • Treat the log as the truth, but keep an index on its contents • Rely on a large memory to provide fast access through caching • Data layout on disk has “temporal locality” (good for writing), rather than “logical locality” (good for reading) • Comparison of LFS (Sprite) with FFS (Unix) – Why is this a better? Because caching helps reads but not writes! – Creation of two single-block files named dir1/file1 and dir2/file2 – Each writes new blocks and inodes for file 1 and file 2 • Two potential problems: – Each writes new data blocks and inodes for directories – Log retrieval on cache misses • FFS Traffic: – Wrap-around: what happens when end of disk is reached? – Ten non-sequential writes for new information » No longer any big, empty runs available – Inodes each written twice to ease recovery from crashes » How to prevent fragmentation? • LFS Traffic: – Single large write • For both when reading back: same number of disk accesses 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.31 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.32
9 . LFS Log Retrieval LFS Disk Wrap-Around • Keep same basic file structure as UNIX (inode, • Compact live info to open up large runs of free space indirect blocks, data) – Problem: long-lived information gets copied over-and-over • Retrieval is just a question of finding a file’s inode • Thread log through free spaces – Problem: disk fragments, causing I/O to become inefficient • UNIX inodes kept in one or a few big arrays, LFS again inodes must float to avoid update-in- place • Solution: an inode map that tells where each inode is • Solution: segmented log (Also keeps other stuff: version number, last access – Divide disk into large, fixed-size segments time, free/allocated) – Do compaction within a segment; thread between segments • inode map gets written to log like everything else – When writing, use only clean segments (i.e. no live data) – Occasionally clean segments: read in several, write out live • Map of inode map gets written in special checkpoint data in compacted form, leaving some fragments free location on disk; used in crash recovery – Try to collect long-lived info into segments that never need to be cleaned – Note there is not free list or bit map (as in FFS), only a list of clean segments 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.33 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.34 LFS Segment Cleaning Analysis and Evolution of Journaling File Systems • Which segments to clean? • Write-ahead logging: commit data by writing it to – Keep estimate of free space in each segment to help log, synchronously and sequentially find segments with lowest utilization • Unlike LFS, then later moved data to its normal – Always start by looking for segment with utilization=0, (FFS-like) location – this write is called since those are trivial to clean… checkpointing and like segment cleaning, it makes – If utilization of segments being cleaned is U: room in the (circular) journal » write cost = • Better for random writes, slightly worse for big (total bytes read & written)/(new data written) = 2/(1-U) sequential writes (unless U is 0) » write cost increases as U increases: U = .9 => cost = 20! • All reads go the the fixed location blocks, not the » Need a cost of less than 4 to 10; => U of less than .75 journal, which is only read for crash recovery and to .45 checkpointing • How to clean a segment? • Much better than FFS (fsck) for crash recovery – Segment summary block contains map of the segment (covered below) because it is much faster – Must list every i-node and file block • Ext3/ReiserFS/Ext4 filesystems are the main ones in Linux – For file blocks you need {i-number, block #} 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.35 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.36
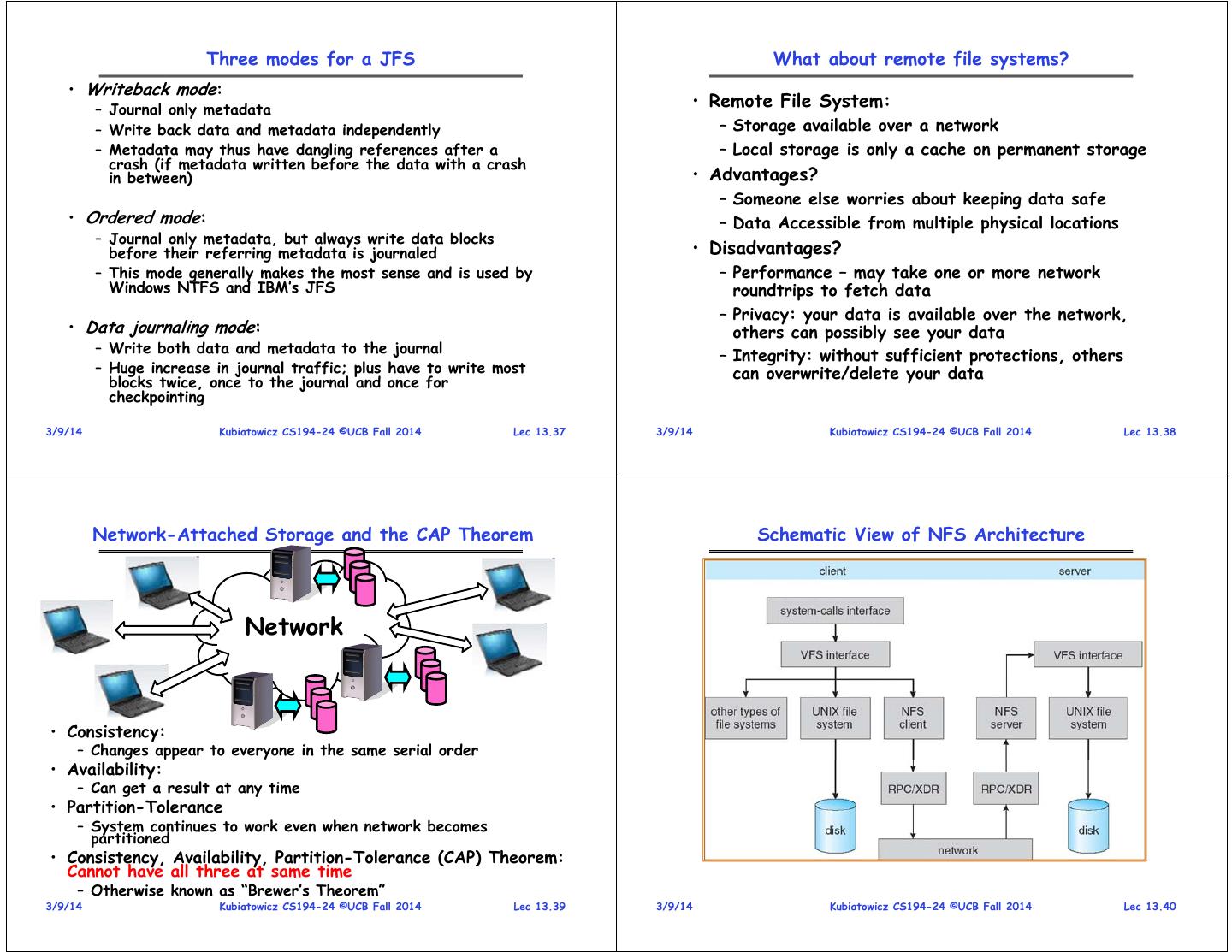
10 . Three modes for a JFS What about remote file systems? • Writeback mode: – Journal only metadata • Remote File System: – Write back data and metadata independently – Storage available over a network – Metadata may thus have dangling references after a – Local storage is only a cache on permanent storage crash (if metadata written before the data with a crash in between) • Advantages? – Someone else worries about keeping data safe • Ordered mode: – Data Accessible from multiple physical locations – Journal only metadata, but always write data blocks before their referring metadata is journaled • Disadvantages? – This mode generally makes the most sense and is used by – Performance – may take one or more network Windows NTFS and IBM’s JFS roundtrips to fetch data – Privacy: your data is available over the network, • Data journaling mode: others can possibly see your data – Write both data and metadata to the journal – Integrity: without sufficient protections, others – Huge increase in journal traffic; plus have to write most can overwrite/delete your data blocks twice, once to the journal and once for checkpointing 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.37 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.38 Network-Attached Storage and the CAP Theorem Schematic View of NFS Architecture Network • Consistency: – Changes appear to everyone in the same serial order • Availability: – Can get a result at any time • Partition-Tolerance – System continues to work even when network becomes partitioned • Consistency, Availability, Partition-Tolerance (CAP) Theorem: Cannot have all three at same time – Otherwise known as “Brewer’s Theorem” 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.39 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.40
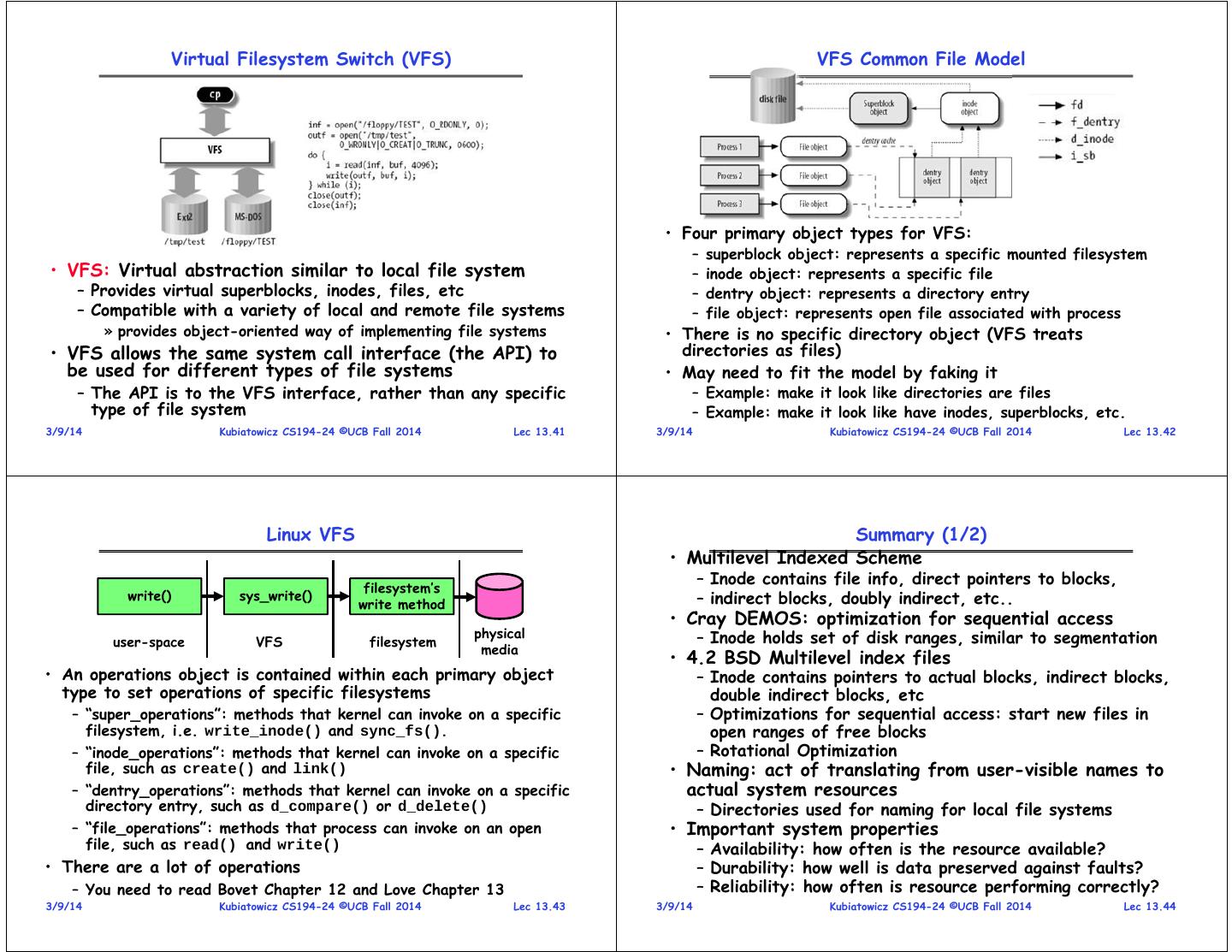
11 . Virtual Filesystem Switch (VFS) VFS Common File Model • Four primary object types for VFS: – superblock object: represents a specific mounted filesystem • VFS: Virtual abstraction similar to local file system – inode object: represents a specific file – Provides virtual superblocks, inodes, files, etc – dentry object: represents a directory entry – Compatible with a variety of local and remote file systems – file object: represents open file associated with process » provides object-oriented way of implementing file systems • There is no specific directory object (VFS treats • VFS allows the same system call interface (the API) to directories as files) be used for different types of file systems • May need to fit the model by faking it – The API is to the VFS interface, rather than any specific – Example: make it look like directories are files type of file system – Example: make it look like have inodes, superblocks, etc. 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.41 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.42 Linux VFS Summary (1/2) • Multilevel Indexed Scheme – Inode contains file info, direct pointers to blocks, filesystem’s write() sys_write() write method – indirect blocks, doubly indirect, etc.. • Cray DEMOS: optimization for sequential access physical – Inode holds set of disk ranges, similar to segmentation user-space VFS filesystem media • 4.2 BSD Multilevel index files • An operations object is contained within each primary object – Inode contains pointers to actual blocks, indirect blocks, type to set operations of specific filesystems double indirect blocks, etc – “super_operations”: methods that kernel can invoke on a specific – Optimizations for sequential access: start new files in filesystem, i.e. write_inode() and sync_fs(). open ranges of free blocks – “inode_operations”: methods that kernel can invoke on a specific – Rotational Optimization file, such as create() and link() • Naming: act of translating from user-visible names to – “dentry_operations”: methods that kernel can invoke on a specific actual system resources directory entry, such as d_compare() or d_delete() – Directories used for naming for local file systems – “file_operations”: methods that process can invoke on an open • Important system properties file, such as read() and write() – Availability: how often is the resource available? • There are a lot of operations – Durability: how well is data preserved against faults? – You need to read Bovet Chapter 12 and Love Chapter 13 – Reliability: how often is resource performing correctly? 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.43 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.44
12 . Summary (2/2) • Log Structured File system (LFS) – The Log is the file system – All updates written sequentially in the log – Inode map tracks where inodes lie in the log • Journaling File System (JFS, Ext3, …) – Use of log to help durability – Primary storage in read-optimized format • Distributed File System: – Transparent access to files stored on a remote disk – Caching for performance • VFS: Virtual File System layer – Provides mechanism which gives same system call interface for different types of file systems – More Next Time! 3/9/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 13.45
3秒后跳转登录页面
去登陆

