













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
页表缓存和对象缓存文件系统
缓存分配机制和使用实例
展开查看详情
1 . Goals for Today CS194-24 • TLBs Advanced Operating Systems • Paging Structures and Implementation • SLAB allocator Lecture 11 Interactive is important! TLBs, SLAB allocator Ask Questions! File Systems March 3st, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.2 Recall: two-level page table Recall: Multi-level Translation: Segments + Pages Physical Physical Offset • What about a tree of tables? 10 bits 10 bits 12 bits Address: Page # Virtual Virtual Virtual Offset – Lowest level page tablememory still allocated with bitmap P1 index P2 index Address: – Higher levels often segmented 4KB • Could have any number of levels. Example (top segment): Virtual Virtual Virtual Seg # Page # Offset PageTablePtr Address: page #0 V,R page #1 V,R Physical Base0 Limit0 V Page # Offset Base1 Limit1 V page #2 V,R,W Base2 Limit2 V Physical Address page #3 V,R,W 4 bytes Base3 Limit3 N page #4 N • Tree of Page Tables Base4 Limit4 V page #5 V,R,W Check Perm Base5 Limit5 N • Tables fixed size (1024 entries) Base6 Limit6 N – On context-switch: save single PageTablePtr register Base7 Limit7 V > Access Error Access Error • Valid bits on Page Table Entries • What must be saved/restored on context switch? – Don’t need every 2nd-level table – Even when exist, 2nd-level tables – Contents of top-level segment registers (for this example) can reside on disk if not in use 4 bytes – Pointer to top-level table (page table) 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.3 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.4
2 . Recall: Recall: X86 Segment Descriptors X86 Memory model with segmentation (16/32-bit) (32-bit Protected Mode) • Segments are either implicit in the instruction (say for code segments) or actually part of the instruction – There are 6 registers: SS, CS, DS, ES, FS, GS • What is in a segment register? – A pointer to the actual segment description: G/L Segment selector [13 bits] RPL G/L selects between GDT and LDT tables (global vs local descriptor tables) • Two registers: GDTR and LDTR hold pointers to the global and local descriptor tables in memory – Includes length of table (for < 213) entries • Descriptor format (64 bits): G: Granularity of segment (0: 16bit, 1: 4KiB unit) DB: Default operand size (0; 16bit, 1: 32bit) A: Freely available for use by software P: Segment present DPL: Descriptor Privilege Level S: System Segment (0: System, 1: code or data) Type: Code, Data, Segment 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.5 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.6 Recall: How are segments used? Slightly More than 4GB RAM: PAE mode on x86 • One set of global segments (GDT) for everyone, different set of local segments (LDT) for every process • In legacy applications (16-bit mode): – Segments provide protection for different components of user programs – Separate segments for chunks of code, data, stacks – Limited to 64K segments • Modern use in 32-bit Mode: – Segments “flattened”, i.e. every segment is 4GB in size PAE with 4K pages PAE with 2MB pages – One exception: Use of GS (or FS) as a pointer to “Thread Local Storage” • Physical Address Extension (PAE) » A thread can make accesses to TLS like this: – Poor-man’s large memory extensions mov eax, gs(0x0) – More than 4GB physical memory • Modern use in 64-bit (“long”) mode – Every process still can have only 32-bit address space – Most segments (SS, CS, DS, ES) have zero base and no length • 3-Level page table limits – 64-bit PTE format • How do processes use more than 4GB memory? – Only FS and GS retain their functionality (for use in TLS) – OS Support for mapping and unmapping physical memory into virtual address space – Application Windowing Extensions (AWE) 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.7 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.8
3 . What about 64-bit x86-64 (“long mode”)? Inverted Page Table • X86 long mode: 64 bit virtual addresses, 40-52 bits of • With all previous examples (“Forward Page Tables”) physical memory – Size of page table is at least as large as amount of virtual memory allocated to processes – Not all 64-bit virtual – Physical memory may be much less addresses translated » Much of process space may be out on disk or not in use – Virtual Addresses must be Virtual “cannonical”: top n bits of Page # Offset must be equal » n here might be 48 Physical Hash Page # Offset » Non-cannonical addresses Table will cause a protection fault • Using PAE scheme with 64-bit PTE can map 48-bits of • Answer: use a hash table virtual memory (94 + 12 = 48) – Called an “Inverted Page Table” • As mentioned earlier, segments other than FS/GS – Size is independent of virtual address space disabled in long mode – Directly related to amount of physical memory – Very attractive option for 64-bit address spaces • Cons: Complexity of managing hash changes – Often in hardware! 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.9 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.10 Recall: Caching Concept Why does caching matter for Virtual Memory? Virtual Virtual Virtual Seg # Page # Offset Address: page #0 V,R page #1 V,R Physical Base0 Limit0 V Page # Offset Base1 Limit1 V page #2 V,R,W Base2 Limit2 V Physical Address page #3 V,R,W • Cache: a repository for copies that can be accessed Base3 Limit3 N page #4 N more quickly than the original Base4 Limit4 V page #5 V,R,W Check Perm – Make frequent case fast and infrequent case less dominant Base5 Limit5 N Base6 Limit6 N • Caching underlies many of the techniques that are used today to make computers fast Base7 Limit7 V > Access Error Access Error – Can cache: memory locations, address translations, pages, • Cannot afford to translate on every access file blocks, file names, network routes, etc… – At least three DRAM accesses per actual DRAM access • Only good if: – Or: perhaps I/O if page table partially on disk! – Frequent case frequent enough and • Even worse: What if we are using caching to make – Infrequent case not too expensive memory access faster than DRAM access??? • Important measure: Average Access time = • Solution? Cache translations! (Hit Rate x Hit Time) + (Miss Rate x Miss Time) – Translation Cache: TLB (“Translation Lookaside Buffer”) 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.11 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.12
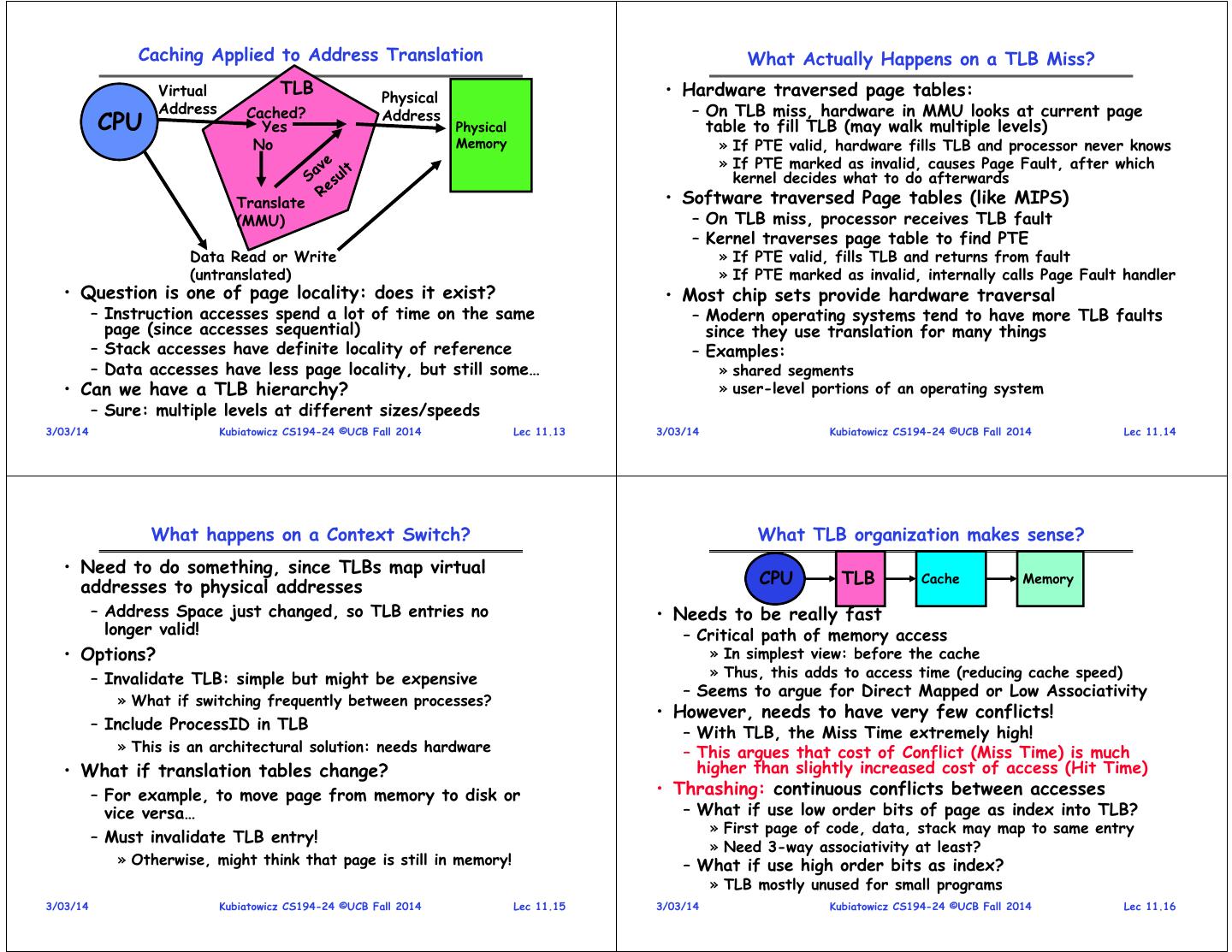
4 . Caching Applied to Address Translation What Actually Happens on a TLB Miss? Virtual TLB Physical • Hardware traversed page tables: Address Cached? – On TLB miss, hardware in MMU looks at current page CPU Yes Address Physical table to fill TLB (may walk multiple levels) No Memory » If PTE valid, hardware fills TLB and processor never knows » If PTE marked as invalid, causes Page Fault, after which kernel decides what to do afterwards Translate • Software traversed Page tables (like MIPS) (MMU) – On TLB miss, processor receives TLB fault – Kernel traverses page table to find PTE Data Read or Write » If PTE valid, fills TLB and returns from fault (untranslated) » If PTE marked as invalid, internally calls Page Fault handler • Question is one of page locality: does it exist? • Most chip sets provide hardware traversal – Instruction accesses spend a lot of time on the same – Modern operating systems tend to have more TLB faults page (since accesses sequential) since they use translation for many things – Stack accesses have definite locality of reference – Examples: – Data accesses have less page locality, but still some… » shared segments • Can we have a TLB hierarchy? » user-level portions of an operating system – Sure: multiple levels at different sizes/speeds 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.13 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.14 What happens on a Context Switch? What TLB organization makes sense? • Need to do something, since TLBs map virtual addresses to physical addresses CPU TLB Cache Memory – Address Space just changed, so TLB entries no • Needs to be really fast longer valid! – Critical path of memory access • Options? » In simplest view: before the cache – Invalidate TLB: simple but might be expensive » Thus, this adds to access time (reducing cache speed) – Seems to argue for Direct Mapped or Low Associativity » What if switching frequently between processes? • However, needs to have very few conflicts! – Include ProcessID in TLB – With TLB, the Miss Time extremely high! » This is an architectural solution: needs hardware – This argues that cost of Conflict (Miss Time) is much • What if translation tables change? higher than slightly increased cost of access (Hit Time) – For example, to move page from memory to disk or • Thrashing: continuous conflicts between accesses vice versa… – What if use low order bits of page as index into TLB? » First page of code, data, stack may map to same entry – Must invalidate TLB entry! » Need 3-way associativity at least? » Otherwise, might think that page is still in memory! – What if use high order bits as index? » TLB mostly unused for small programs 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.15 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.16
5 . TLB organization: include protection Example: R3000 pipeline includes TLB “stages” • How big does TLB actually have to be? – Usually small: 128-512 entries MIPS R3000 Pipeline Dcd/ Reg – Not very big, can support higher associativity Inst Fetch ALU / E.A Memory Write Reg • TLB usually organized as fully-associative cache TLB I-Cache RF Operation WB – Lookup is by Virtual Address E.A. TLB D-Cache – Returns Physical Address + other info TLB • What happens when fully-associative is too slow? 64 entry, on-chip, fully associative, software TLB fault handler – Put a small (4-16 entry) direct-mapped cache in front Virtual Address Space – Called a “TLB Slice” • Example for MIPS R3000: ASID V. Page Number Offset 6 20 12 Virtual Address Physical Address Dirty Ref Valid Access ASID 0xFA00 0x0003 Y N Y R/W 34 0xx User segment (caching based on PT/TLB entry) 0x0040 0x0010 N Y Y R 0 100 Kernel physical space, cached 101 Kernel physical space, uncached 0x0041 0x0011 N Y Y R 0 11x Kernel virtual space Allows context switching among 64 user processes without TLB flush 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.17 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.18 Reducing translation time further Overlapping TLB & Cache Access • As described, TLB lookup is in serial with cache lookup: • Here is how this might work with a 4K cache: Virtual Address assoc 10 lookup index V page no. offset 32 TLB 4K Cache 1 K TLB Lookup 20 10 2 4 bytes page # disp 00 V Access Rights PA Hit/ Miss FN = FN Data Hit/ Miss P page no. offset 10 • What if cache size is increased to 8KB? Physical Address – Overlap not complete • Machines with TLBs go one step further: they overlap – Need to do something else. See CS152/252 TLB lookup with cache access. • Another option: Virtual Caches – Works because offset available early – Tags in cache are virtual addresses – Translation only happens on cache misses 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.19 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.20
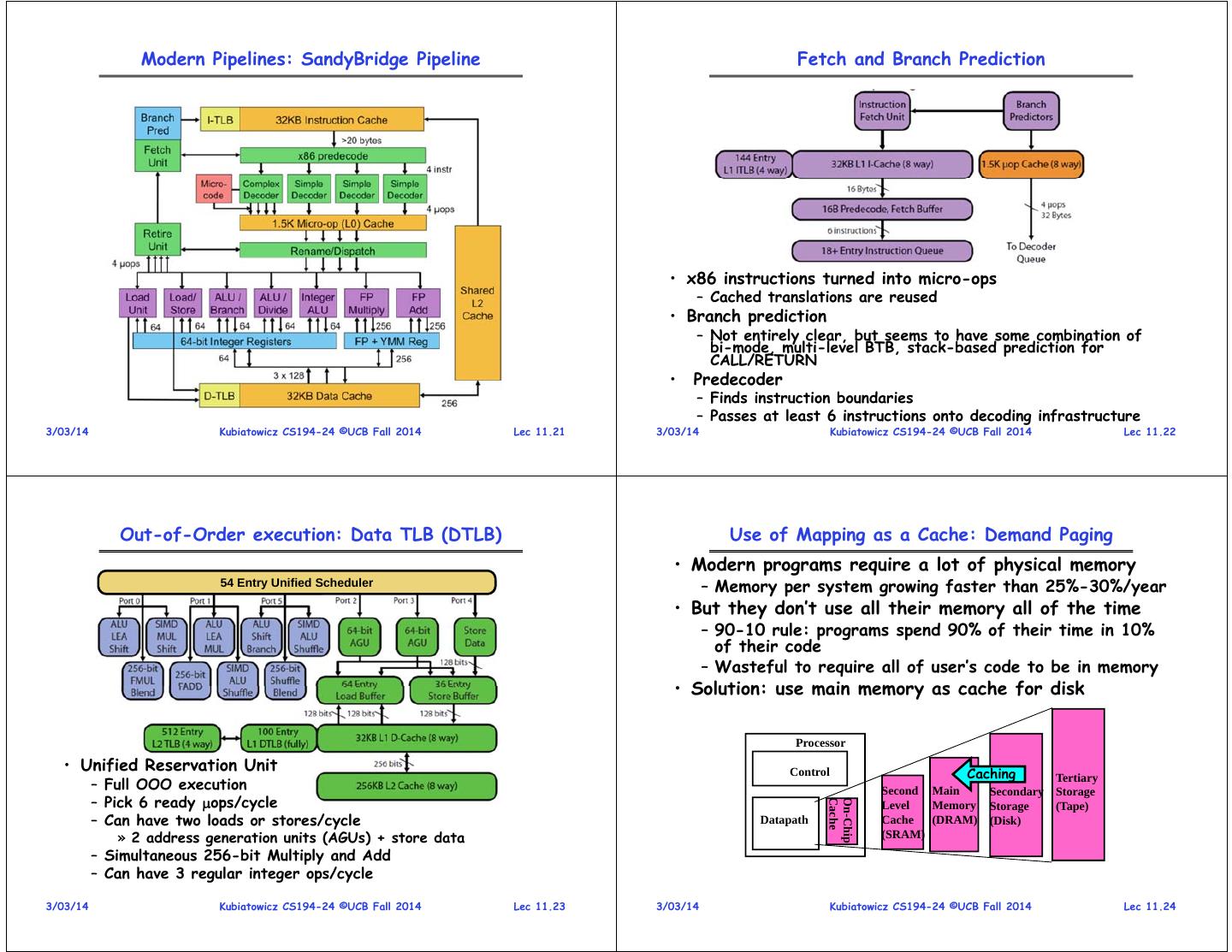
6 . Modern Pipelines: SandyBridge Pipeline Fetch and Branch Prediction • x86 instructions turned into micro-ops – Cached translations are reused • Branch prediction – Not entirely clear, but seems to have some combination of bi-mode, multi-level BTB, stack-based prediction for CALL/RETURN • Predecoder – Finds instruction boundaries – Passes at least 6 instructions onto decoding infrastructure 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.21 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.22 Out-of-Order execution: Data TLB (DTLB) Use of Mapping as a Cache: Demand Paging • Modern programs require a lot of physical memory 54 Entry Unified Scheduler – Memory per system growing faster than 25%-30%/year • But they don’t use all their memory all of the time – 90-10 rule: programs spend 90% of their time in 10% of their code – Wasteful to require all of user’s code to be in memory • Solution: use main memory as cache for disk Processor • Unified Reservation Unit Control Caching – Full OOO execution Tertiary Second Main Secondary Storage – Pick 6 ready ops/cycle Cache On-Chip Level Memory Storage (Tape) – Can have two loads or stores/cycle Datapath Cache (DRAM) (Disk) » 2 address generation units (AGUs) + store data (SRAM) – Simultaneous 256-bit Multiply and Add – Can have 3 regular integer ops/cycle 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.23 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.24
7 . Illusion of Infinite Memory Review: What is in a PTE? • What is in a Page Table Entry (or PTE)? – Pointer to next-level page table or to actual page TLB – Permission bits: valid, read-only, read-write, write-only • Example: Intel x86 architecture PTE: Page – Address same format previous slide (10, 10, 12-bit offset) Table – Intermediate page tables called “Directories” Physical Disk Page Frame Number Free PCD PWT Virtual Memory 500GB 0 L D A U WP Memory (Physical Page Number) (OS) 512 MB 4 GB 31-12 11-9 8 7 6 5 4 3 2 1 0 P: Present (same as “valid” bit in other architectures) • Disk is larger than physical memory W: Writeable – In-use virtual memory can be bigger than physical memory – Combined memory of running processes much larger than U: User accessible physical memory PWT: Page write transparent: external cache write-through » More programs fit into memory, allowing more concurrency PCD: Page cache disabled (page cannot be cached) • Principle: Transparent Level of Indirection (page table) A: Accessed: page has been accessed recently – Supports flexible placement of physical data D: Dirty (PTE only): page has been modified recently » Data could be on disk or somewhere across network L: L=14MB page (directory only). – Variable location of data transparent to user program Bottom 22 bits of virtual address serve as offset » Performance issue, not correctness issue 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.25 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.26 Demand Paging Mechanisms Demand Paging Example • PTE helps us implement demand paging • Since Demand Paging like caching, can compute – Valid Page in memory, PTE points at physical page average access time! (“Effective Access Time”) – Not Valid Page not in memory; use info in PTE to find – EAT = Hit Rate x Hit Time + Miss Rate x Miss Time it on disk when necessary – EAT = Hit Time + Miss Rate x Miss Penalty • Suppose user references page with invalid PTE? • Example: – Memory Management Unit (MMU) traps to OS – Memory access time = 200 nanoseconds » Resulting trap is a “Page Fault” – Average page-fault service time = 8 milliseconds – What does OS do on a Page Fault?: – Suppose p = Probability of miss, 1-p = Probably of hit » Choose an old page to replace – Then, we can compute EAT as follows: » If old page modified (“D=1”), write contents back to disk EAT = 200ns + p x 8 ms » Change its PTE and any cached TLB to be invalid » Load new page into memory from disk = 200ns + p x 8,000,000ns » Update page table entry, invalidate TLB for new entry • If one access out of 1,000 causes a page fault, then » Continue thread from original faulting location EAT = 8.2 μs: – TLB for new page will be loaded when thread continued! – This is a slowdown by a factor of 40! – While pulling pages off disk for one process, OS runs • What if want slowdown by less than 10%? another process from ready queue – 200ns x 1.1 < EAT p < 2.5 x 10-6 » Suspended process sits on wait queue – This is about 1 page fault in 400000! 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.27 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.28
8 . Implementing LRU Clock Algorithm: Not Recently Used • Perfect: Single Clock Hand: – Timestamp page on each reference Advances only on page fault! – Keep list of pages ordered by time of reference Check for pages not used recently – Too expensive to implement in reality for many reasons Mark pages as not used recently • Clock Algorithm: Arrange physical pages in circle with Set of all pages single clock hand in Memory – Approximate LRU (approx to approx to MIN) – Replace an old page, not the oldest page • Details: – Hardware “use” bit per physical page: » Hardware sets use bit on each reference • What if hand moving slowly? » If use bit isn’t set, means not referenced in a long time – Good sign or bad sign? » Nachos hardware sets use bit in the TLB; you have to copy » Not many page faults and/or find page quickly this back to page table when TLB entry gets replaced – On page fault: • What if hand is moving quickly? » Advance clock hand (not real time) – Lots of page faults and/or lots of reference bits set » Check use bit: 1used recently; clear and leave alone • One way to view clock algorithm: 0selected candidate for replacement – Will always find a page or loop forever? – Crude partitioning of pages into two groups: young and old » Even if all use bits set, will eventually loop aroundFIFO – Why not partition into more than 2 groups? 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.29 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.30 Nth Chance version of Clock Algorithm Clock Algorithms: Details • Nth chance algorithm: Give page N chances • Which bits of a PTE entry are useful to us? – OS keeps counter per page: # sweeps – Use: Set when page is referenced; cleared by clock – On page fault, OS checks use bit: algorithm » 1clear use and also clear counter (used in last sweep) – Modified: set when page is modified, cleared when page » 0increment counter; if count=N, replace page written to disk – Means that clock hand has to sweep by N times without page being used before page is replaced – Valid: ok for program to reference this page • How do we pick N? – Read-only: ok for program to read page, but not modify – Why pick large N? Better approx to LRU » For example for catching modifications to code pages! » If N ~ 1K, really good approximation • Do we really need hardware-supported “modified” bit? – Why pick small N? More efficient » Otherwise might have to look a long way to find free page – No. Can emulate it (BSD Unix) using read-only bit • What about dirty pages? » Initially, mark all pages as read-only, even data pages – Takes extra overhead to replace a dirty page, so give » On write, trap to OS. OS sets software “modified” bit, dirty pages an extra chance before replacing? and marks page as read-write. – Common approach: » Whenever page comes back in from disk, mark read-only » Clean pages, use N=1 » Dirty pages, use N=2 (and write back to disk when N=1) 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.31 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.32
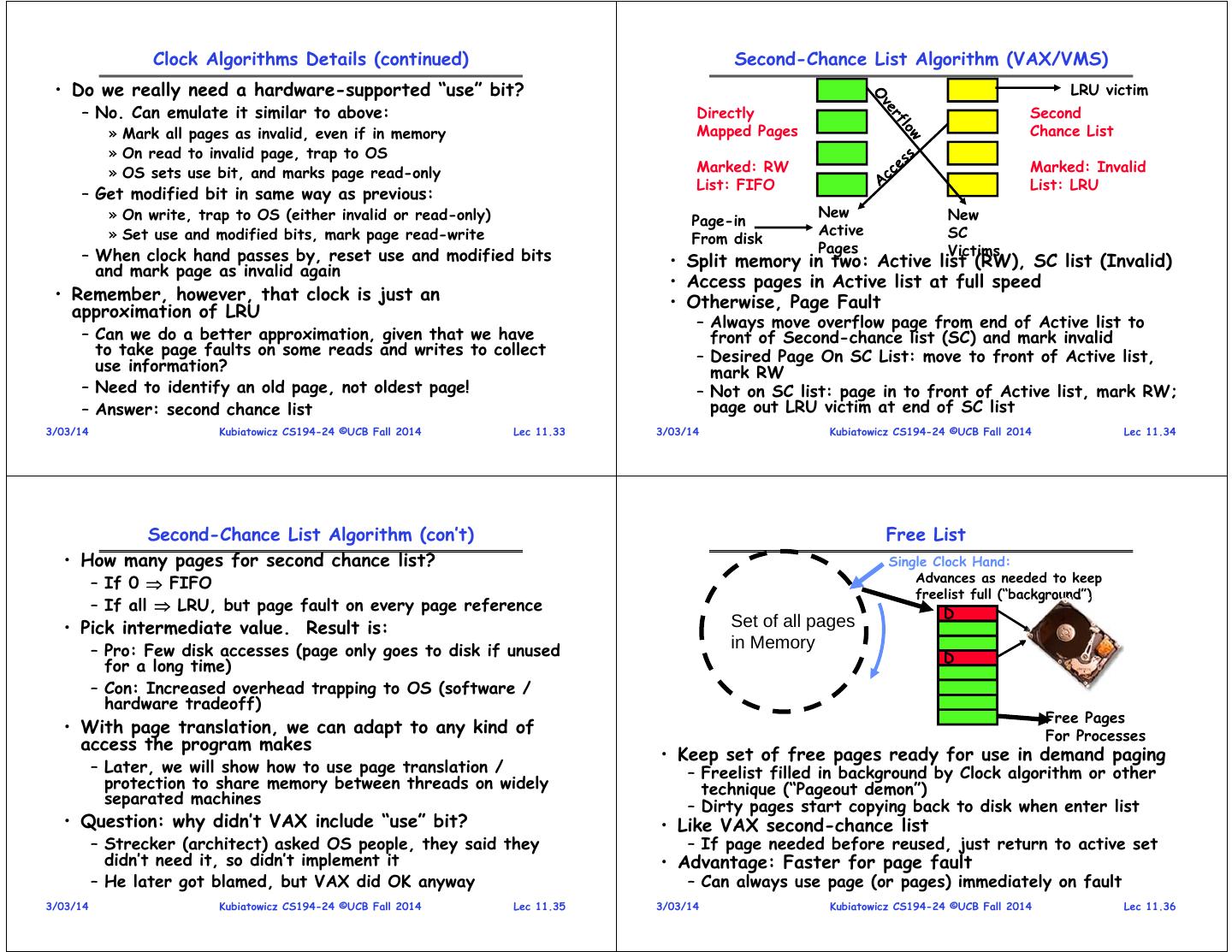
9 . Clock Algorithms Details (continued) Second-Chance List Algorithm (VAX/VMS) • Do we really need a hardware-supported “use” bit? LRU victim – No. Can emulate it similar to above: Directly Second » Mark all pages as invalid, even if in memory Mapped Pages Chance List » On read to invalid page, trap to OS » OS sets use bit, and marks page read-only Marked: RW Marked: Invalid List: FIFO List: LRU – Get modified bit in same way as previous: » On write, trap to OS (either invalid or read-only) New New Page-in » Set use and modified bits, mark page read-write Active SC From disk Pages Victims – When clock hand passes by, reset use and modified bits • Split memory in two: Active list (RW), SC list (Invalid) and mark page as invalid again • Access pages in Active list at full speed • Remember, however, that clock is just an • Otherwise, Page Fault approximation of LRU – Always move overflow page from end of Active list to – Can we do a better approximation, given that we have front of Second-chance list (SC) and mark invalid to take page faults on some reads and writes to collect – Desired Page On SC List: move to front of Active list, use information? mark RW – Need to identify an old page, not oldest page! – Not on SC list: page in to front of Active list, mark RW; – Answer: second chance list page out LRU victim at end of SC list 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.33 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.34 Second-Chance List Algorithm (con’t) Free List • How many pages for second chance list? Single Clock Hand: – If 0 FIFO Advances as needed to keep freelist full (“background”) – If all LRU, but page fault on every page reference D • Pick intermediate value. Result is: Set of all pages – Pro: Few disk accesses (page only goes to disk if unused in Memory D for a long time) – Con: Increased overhead trapping to OS (software / hardware tradeoff) Free Pages • With page translation, we can adapt to any kind of For Processes access the program makes • Keep set of free pages ready for use in demand paging – Later, we will show how to use page translation / – Freelist filled in background by Clock algorithm or other protection to share memory between threads on widely technique (“Pageout demon”) separated machines – Dirty pages start copying back to disk when enter list • Question: why didn’t VAX include “use” bit? • Like VAX second-chance list – Strecker (architect) asked OS people, they said they – If page needed before reused, just return to active set didn’t need it, so didn’t implement it • Advantage: Faster for page fault – He later got blamed, but VAX did OK anyway – Can always use page (or pages) immediately on fault 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.35 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.36
10 . Summary: Examples of how to exploit a PTE Reverse Page Mapping (Sometimes called “Coremap”) • How do we use the PTE? – Invalid PTE can imply different things: • Physical page frames often shared by many different » Region of address space is actually invalid or address spaces/page tables » Page/directory is just somewhere else than memory – All children forked from given process – Validity checked first – Shared memory pages between processes » OS can use other (say) 31 bits for location info • Usage Example: Demand Paging • Whatever reverse mapping mechanism that is in – Keep only active pages in memory place must be very fast – Place others on disk and mark their PTEs invalid – Must hunt down all page tables pointing at given page • Usage Example: Copy on Write frame when freeing a page – UNIX fork gives copy of parent address space to child – Must hunt down all PTEs when seeing if pages “active” » Address spaces disconnected after child created – How to do this cheaply? • Implementation options: » Make copy of parent’s page tables (point at same memory) – For every page descriptor, keep linked list of page » Mark entries in both sets of page tables as read-only table entries that point to it » Page fault on write creates two copies » Management nightmare – expensive • Usage Example: Zero Fill On Demand – New data pages must carry no information (say be zeroed) – Linux 2.6: Object-based reverse mapping – Mark PTEs as invalid; page fault on use gets zeroed page » Link together memory region descriptors instead (much – Often, OS creates zeroed pages in background coarser granularity) 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.37 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.38 Linux Memory Details? Recall: Linux Virtual memory map • Memory management in Linux considerably more complex that the previous indications 0xFFFFFFFF 0xFFFFFFFFFFFFFFFF • Memory Zones: physical memory categories 128TiB 896MB Kernel Kernel 1GB Addresses 64 TiB Addresses – ZONE_DMA: < 16MB memory, DMAable on ISA bus Physical Physical – ZONE_NORMAL: 16MB 896MB (mapped at 0xC0000000) 0xC0000000 0xFFFF800000000000 – ZONE_HIGHMEM: Everything else (> 896MB) • Each zone has 1 freelist, 2 LRU lists (Active/Inactive) “Canonical Hole” Empty Space • Many different types of allocation 3GB Total User – SLAB allocators, per-page allocators, mapped/unmapped Addresses 0x00007FFFFFFFFFFF • Many different types of allocated memory: 128TiB – Anonymous memory (not backed by a file, heap/stack) User Addresses – Mapped memory (backed by a file) • Allocation priorities 0x00000000 0x0000000000000000 – Is blocking allowed/etc 32-Bit Virtual Address Space 64-Bit Virtual Address Space 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.39 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.40
11 . Virtual Map (Details) Internal Interfaces: Allocating Memory • Kernel memory not generally visible to user • One mechanism for requesting pages: everything else – Exception: special VDSO facility that maps kernel code into user on top of this mechanism: space to aid in system calls (and to provide certain actual – Allocate contiguous group of pages of size 2order bytes system calls such as gettimeofday(). given the specified mask: • Every physical page described by a “page” structure struct page * alloc_pages(gfp_t gfp_mask, – Collected together in lower physical memory unsigned int order) – Can be accessed in kernel virtual space – Allocate one page: – Linked together in various “LRU” lists • For 32-bit virtual memory architectures: struct page * alloc_page(gfp_t gfp_mask) – When physical memory < 896MB » All physical memory mapped at 0xC0000000 – Convert page to logical address (assuming mapped): – When physical memory >= 896MB void * page_address(struct page *page) » Not all physical memory mapped in kernel space all the time • Also routines for freeing pages » Can be temporarily mapped with addresses > 0xCC000000 • Zone allocator uses “buddy” allocator that trys to • For 64-bit virtual memory architectures: keep memory unfragmented – All physical memory mapped above 0xFFFF800000000000 • Allocation routines pick from proper zone, given flags 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.41 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.42 Allocation flags Page Frame Reclaiming Algorithm (PFRA) • Possible allocation type flags: • Several entrypoints: – GFP_ATOMIC: Allocation high-priority and must never – Low on Memory Reclaiming: The kernel detects a “low on sleep. Use in interrupt handlers, top memory” condition halves, while holding locks, or other times – Hibernation reclaiming: The kernel must free memory because cannot sleep it is entering in the suspend-to-disk state – GFP_NOWAIT: Like GFP_ATOMIC, except call will – Periodic reclaiming: A kernel thread is activated periodically not fall back on emergency memory to perform memory reclaiming, if necessary pools. Increases likely hood of failure • Low on Memory reclaiming: – GFP_NOIO: Allocation can block but must not – Start flushing out dirty pages to disk initiate disk I/O. – Start looping over all memory nodes in the system – GFP_NOFS: Can block, and can initiate disk I/O, » try_to_free_pages() but will not initiate filesystem ops. » shrink_slab() – GFP_KERNEL: Normal allocation, might block. Use in » pdflush kenel thread writing out dirty pages process context when safe to sleep. • Periodic reclaiming: This should be default choice – Kswapd kernel threads: checks if number of free page – GFP_USER: Normal allocation for processes frames in some zone has fallen below pages_high watermark – GFP_HIGHMEM: Allocation from ZONE_HIGHMEM – Each zone keeps two LRU lists: Active and Inactive – GFP_DMA Allocation from ZONE_DMA. Use in » Each page has a last-chance algorithm with 2 count combination with a previous flag » Active page lists moved to inactive list when they have been idle for two cycles through the list » Pages reclaimed from Inactive list 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.43 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.44
12 . SLAB Allocator SLAB Allocator Details • Replacement for free-lists that are hand-coded by users • Based on algorithm first introduced for SunOS – Consolidation of all of this code under kernel control – Observation: amount of time required to initialize a – Efficient when objects allocated and freed frequently regular object in the kernel exceeds the amount of time Obj 1 required to allocate and deallocate it – Resolves around object caching SLAB Obj 2 » Allocate once, keep reusing objects Obj 3 Cache • Avoids memory fragmentation: – Caching of similarly sized objects, avoid fragmentation Obj 4 – Similar to custom freelist per object SLAB • Reuse of allocation Obj 5 • Objects segregated into “caches” – When new object first allocated, constructor runs – Each cache stores different type of object – On subsequent free/reallocation, constructor does not – Data inside cache divided into “slabs”, which are continuous need to be reexecuted groups of pages (often only 1 page) – Key idea: avoid memory fragmentation 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.45 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.46 SLAB Allocator: Cache Construction SLAB Allocator: Cache Use • Creation of new Caches: • Example: struct kmem_cache * kem_cache_create(const char *name, size_t size, task_struct_cachep = size_t align, kmem_cache_create(“task_struct”, unsigned long flags, sizeof(struct task_struct), void (*ctor)(void *)); ARCH_MIN_TASKALIGN, SLAB_PANIC | SLAB_NOTRACK, – name: name of cache NULL); – size: size of each element in the cache • Use of example: – align: alignment for each object (often 0) struct task_struct *tsk; – flags: possible flags about allocation » SLAB_HWCACHE_ALIGN: Align objects to cache lines tsk = kmem_cache_alloc(task_struct_cachep, GFP_KERNEL); if (!tsk) » SLAB_POISON: Fill slabs to known value (0xa5a5a5a5) in return NULL; order to catch use of uninitialized memory » SLAB_RED_ZONE: Insert empty zones around objects to kmem_free(task_struct_cachep,tsk); help detect buffer overruns » SLAB_PANIC: Allocation layer panics if allocation fails » SLAB_CACHE_DMA: Allocations from DMA-able memory » SLAB_NOTRACK: don’t track uninitialized memory – ctor: called whenever new pages are added to the cache 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.47 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.48
13 . SLAB Allocator Details (Con’t) Recall: Kmalloc/Kfree: The “easy interface” to memory • Caches can be later destroyed with: • Simplest kernel interface to manage memory: int kmem_cache_destroy(struct kmem_cache *cachep); kmalloc()/kfree() – Allocate chunk of memory in kernel’s address space (will – Assuming that all objects freed be physically contiguous and virtually contiguous): – No one ever tries to use cache again void * kmalloc(size_t size, gfp_t flags); • All caches kept in global list – Including global caches set up with objects of powers of – Example usage: 2 from 25 to 217 struct dog *p; – General kernel allocation (kmalloc/kfree) uses least-fit p = kmalloc(sizeof(struct dog), GFP_KERNEL); for requested cache size if (!p) /* Handle error! */ • Reclamation of memory – Caches keep sorted list of empty, partial, and full slabs – Free memory: void kfree(const void *ptr); » Easy to manage – slab metadata contains reference count – Important restrictions! » Must call with memory previously allocated through » Objects within slabs linked together kmalloc() interface!!! – Ask individual caches for full slabs for reclamation » Must not free memory twice! 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.49 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.50 Alternatives for allocation Summary (1/2) • According to Robert Love, “SLAB” has become a name • Memory is a resource that must be shared – Controlled Overlap: only shared when appropriate for any allocator with a similar API – Translation: Change Virtual Addresses into Physical Addresses – Kinda like “Kleenex” has become a generic noun – Protection: Prevent unauthorized Sharing of resources • A number of options in the kernel for object allocation: • Segment Mapping – Segment registers within processor – SLAB: original allocator based on Bonwick’s paper from – Segment ID associated with each access SunOS » Often comes from portion of virtual address » Can come from bits in instruction instead (x86) – SLUB: Newer allocator with same interface but better – Each segment contains base and limit information use of metadata (Default since Linux 2.6.23) » Offset (rest of address) adjusted by adding base » Keeps SLAB metadata in the page data structure (for pages • Page Tables that happen to be in kernel caches) – Memory divided into fixed-sized chunks of memory – Virtual page number from virtual address mapped through » Debugging options compiled in by default, just need to be page table to physical page number enabled – Offset of virtual address same as physical address – Large page tables can be placed into virtual memory – SLOB: low-memory footprint allocator for embedded • Multi-Level Tables systems – Virtual address mapped to series of tables – Permit sparse population of address space • Inverted page table – Size of page table related to physical memory size 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.51 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.52
14 . Summary (2/2) • PTE: Page Table Entries – Includes physical page number – Control info (valid bit, writeable, dirty, user, etc) • A cache of translations called a “Translation Lookaside Buffer” (TLB) – Relatively small number of entries (< 512) – Fully Associative (Since conflict misses expensive) – TLB entries contain PTE and optional process ID • On TLB miss, page table must be traversed – If located PTE is invalid, cause Page Fault • On context switch/change in page table – TLB entries must be invalidated somehow • TLB is logically in front of cache – Thus, needs to be overlapped with cache access to be really fast 3/03/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 11.53
3秒后跳转登录页面
去登陆

