









- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
虚拟内存
• 虚拟内存
• 缓冲区
•页表条目
展开查看详情
1 . Goals for Today • Virtual Memory CS194-24 • TLBs Advanced Operating Systems Structures and Implementation Lecture 10 Interactive is important! Ask Questions! Virtual Memory, TLBs February 26th, 2014 Prof. John Kubiatowicz http://inst.eecs.berkeley.edu/~cs194-24 Note: Some slides and/or pictures in the following are adapted from slides ©2013 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.2 Recall: Definition of Monitor Recall: Programming with Monitors • Monitor: a lock and zero or more condition variables • Monitors represent the logic of the program for managing concurrent access to shared data – Wait if necessary – Use of Monitors is a programming paradigm – Signal when change something so any waiting threads • Lock: provides mutual exclusion to shared data: can proceed – Always acquire before accessing shared data structure • Basic structure of monitor-based program: – Always release after finishing with shared data lock while (need to wait) { Check and/or update • Condition Variable: a queue of threads waiting for condvar.wait(); state variables something inside a critical section } Wait if necessary unlock – Key idea: allow sleeping inside critical section by atomically releasing lock at time we go to sleep do something so no need to wait – Contrast to semaphores: Can’t wait inside critical section lock condvar.signal(); Check and/or update state variables unlock 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.3 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.4
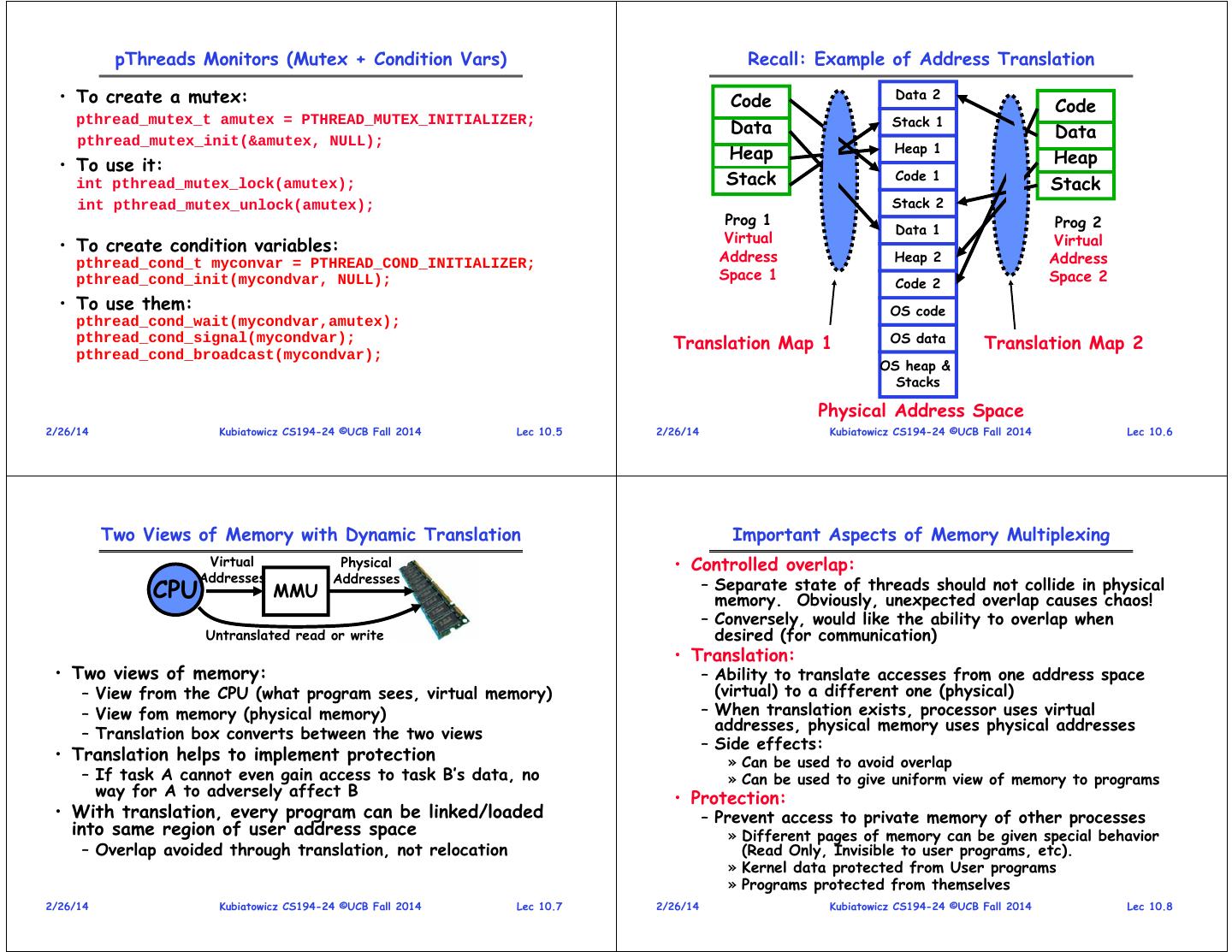
2 . pThreads Monitors (Mutex + Condition Vars) Recall: Example of Address Translation • To create a mutex: Code Data 2 Code Stack 1 Data pthread_mutex_t amutex = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_init(&amutex, NULL); Data Heap Heap 1 • To use it: Heap int pthread_mutex_lock(amutex); Stack Code 1 Stack int pthread_mutex_unlock(amutex); Stack 2 Prog 1 Prog 2 Data 1 Virtual Virtual • To create condition variables: pthread_cond_t myconvar = PTHREAD_COND_INITIALIZER; Address Heap 2 Address Space 1 Space 2 pthread_cond_init(mycondvar, NULL); Code 2 • To use them: OS code pthread_cond_wait(mycondvar,amutex); pthread_cond_signal(mycondvar); Translation Map 1 OS data Translation Map 2 pthread_cond_broadcast(mycondvar); OS heap & Stacks Physical Address Space 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.5 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.6 Two Views of Memory with Dynamic Translation Important Aspects of Memory Multiplexing Virtual Physical • Controlled overlap: Addresses Addresses CPU MMU – Separate state of threads should not collide in physical memory. Obviously, unexpected overlap causes chaos! – Conversely, would like the ability to overlap when Untranslated read or write desired (for communication) • Translation: • Two views of memory: – Ability to translate accesses from one address space – View from the CPU (what program sees, virtual memory) (virtual) to a different one (physical) – View fom memory (physical memory) – When translation exists, processor uses virtual addresses, physical memory uses physical addresses – Translation box converts between the two views – Side effects: • Translation helps to implement protection » Can be used to avoid overlap – If task A cannot even gain access to task B’s data, no » Can be used to give uniform view of memory to programs way for A to adversely affect B • Protection: • With translation, every program can be linked/loaded – Prevent access to private memory of other processes into same region of user address space » Different pages of memory can be given special behavior – Overlap avoided through translation, not relocation (Read Only, Invisible to user programs, etc). » Kernel data protected from User programs » Programs protected from themselves 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.7 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.8
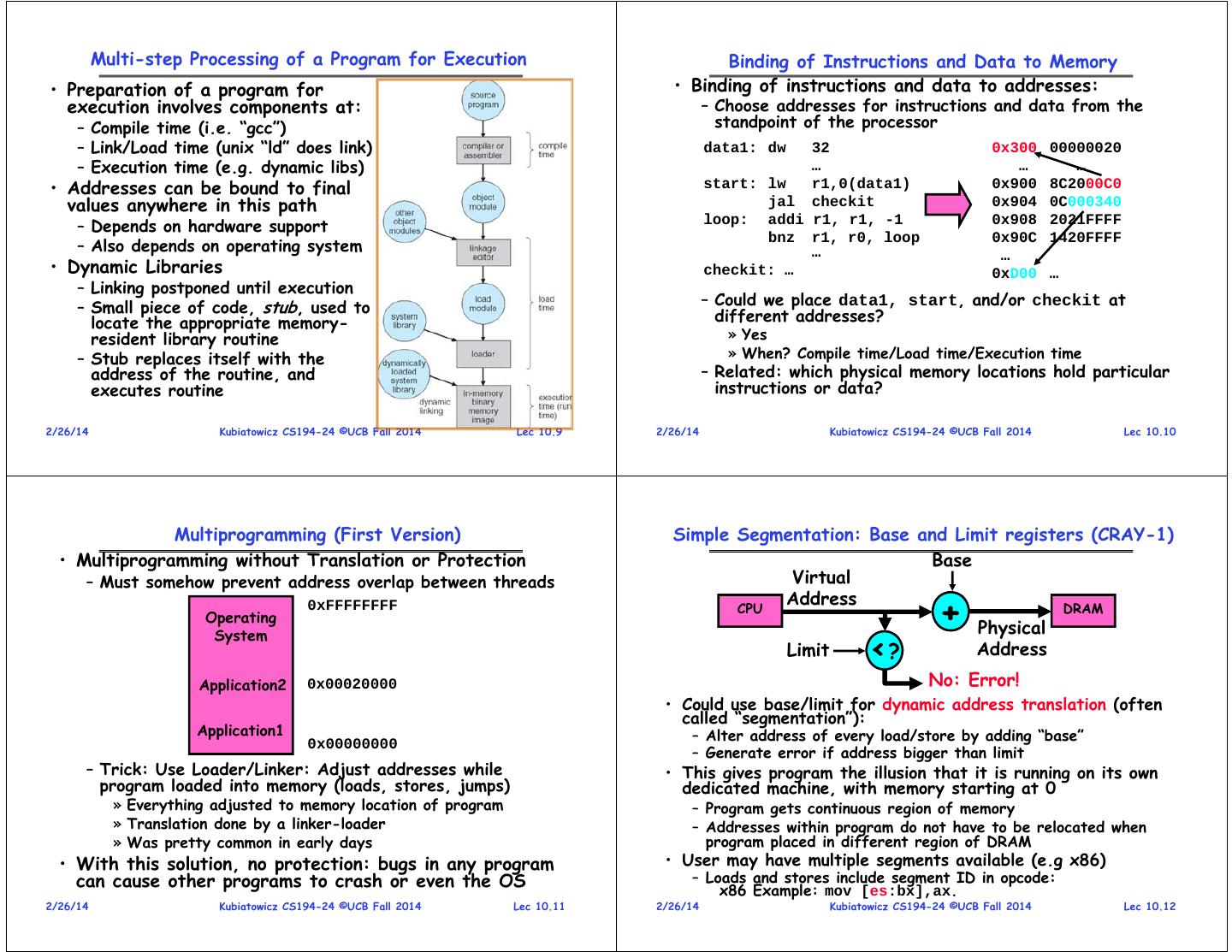
3 . Multi-step Processing of a Program for Execution Binding of Instructions and Data to Memory • Preparation of a program for • Binding of instructions and data to addresses: execution involves components at: – Choose addresses for instructions and data from the – Compile time (i.e. “gcc”) standpoint of the processor – Link/Load time (unix “ld” does link) data1: dw 32 0x300 00000020 – Execution time (e.g. dynamic libs) … … … • Addresses can be bound to final start: lw r1,0(data1) 0x900 8C2000C0 values anywhere in this path jal checkit 0x904 0C000340 – Depends on hardware support loop: addi r1, r1, -1 0x908 2021FFFF bnz r1, r0, loop 0x90C 1420FFFF – Also depends on operating system … … • Dynamic Libraries checkit: … 0xD00 … – Linking postponed until execution – Small piece of code, stub, used to – Could we place data1, start, and/or checkit at locate the appropriate memory- different addresses? resident library routine » Yes – Stub replaces itself with the » When? Compile time/Load time/Execution time address of the routine, and – Related: which physical memory locations hold particular executes routine instructions or data? 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.9 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.10 Multiprogramming (First Version) Simple Segmentation: Base and Limit registers (CRAY-1) • Multiprogramming without Translation or Protection Base – Must somehow prevent address overlap between threads Virtual + 0xFFFFFFFF CPU Address DRAM Operating System Physical Limit <? Address Application2 0x00020000 No: Error! • Could use base/limit for dynamic address translation (often called “segmentation”): Application1 – Alter address of every load/store by adding “base” 0x00000000 – Generate error if address bigger than limit – Trick: Use Loader/Linker: Adjust addresses while • This gives program the illusion that it is running on its own program loaded into memory (loads, stores, jumps) dedicated machine, with memory starting at 0 » Everything adjusted to memory location of program – Program gets continuous region of memory » Translation done by a linker-loader – Addresses within program do not have to be relocated when » Was pretty common in early days program placed in different region of DRAM • With this solution, no protection: bugs in any program • User may have multiple segments available (e.g x86) can cause other programs to crash or even the OS – Loads and stores include segment ID in opcode: x86 Example: mov [es:bx],ax. 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.11 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.12
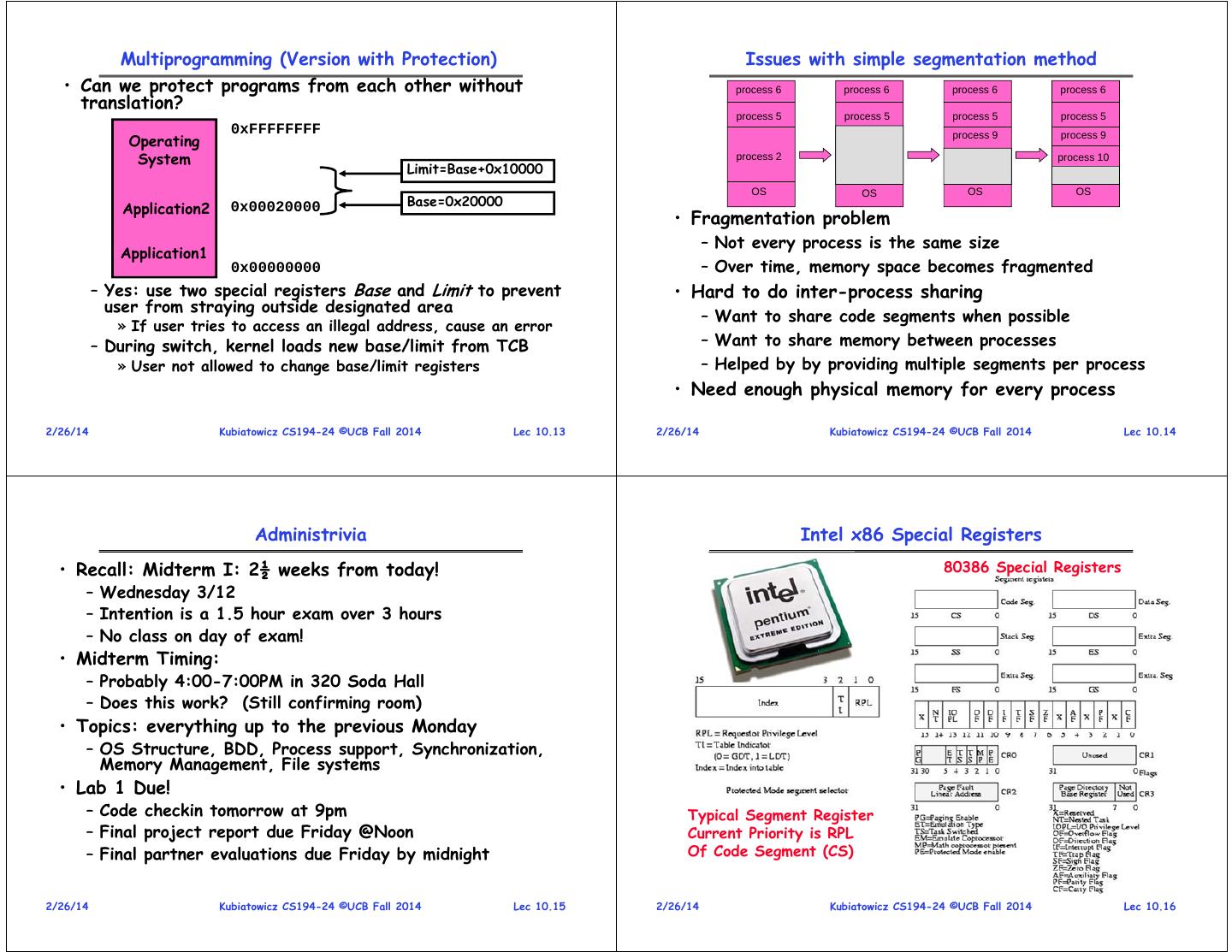
4 . Multiprogramming (Version with Protection) Issues with simple segmentation method • Can we protect programs from each other without process 6 process 6 process 6 process 6 translation? process 5 process 5 process 5 process 5 0xFFFFFFFF Operating process 9 process 9 System process 2 process 10 Limit=Base+0x10000 OS OS OS OS Base=0x20000 Application2 0x00020000 • Fragmentation problem – Not every process is the same size Application1 0x00000000 – Over time, memory space becomes fragmented – Yes: use two special registers Base and Limit to prevent • Hard to do inter-process sharing user from straying outside designated area – Want to share code segments when possible » If user tries to access an illegal address, cause an error – During switch, kernel loads new base/limit from TCB – Want to share memory between processes » User not allowed to change base/limit registers – Helped by by providing multiple segments per process • Need enough physical memory for every process 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.13 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.14 Administrivia Intel x86 Special Registers • Recall: Midterm I: 2½ weeks from today! 80386 Special Registers – Wednesday 3/12 – Intention is a 1.5 hour exam over 3 hours – No class on day of exam! • Midterm Timing: – Probably 4:00-7:00PM in 320 Soda Hall – Does this work? (Still confirming room) • Topics: everything up to the previous Monday – OS Structure, BDD, Process support, Synchronization, Memory Management, File systems • Lab 1 Due! – Code checkin tomorrow at 9pm Typical Segment Register – Final project report due Friday @Noon Current Priority is RPL – Final partner evaluations due Friday by midnight Of Code Segment (CS) 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.15 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.16
5 . Implementation of Multi-Segment Model Example: Four Segments (16 bit addresses) Virtual Seg # Offset Address Base0 Limit0 V > Error Seg Offset Seg ID # 0 (code) Base 0x4000 Limit 0x0800 Base1 Limit1 V 15 14 13 0 1 (data) 0x4800 0x1400 Base2 Limit2 V Virtual Address Format 2 (shared) 0xF000 0x1000 Base3 Base4 Limit3 Limit4 N V + Physical Address 3 (stack) 0x0000 0x3000 Base5 Limit5 N 0x0000 0x0000 Base6 Limit6 N Base7 Limit7 V Might • Segment map resides in processor 0x4000 0x4000 0x4800 be shared – Segment number mapped into base/limit pair 0x5C00 – Base added to offset to generate physical address 0x8000 – Error check catches offset out of range Space for • As many chunks of physical memory as entries Other Apps 0xC000 – Segment addressed by portion of virtual address – However, could be included in instruction instead: 0xF000 Shared with » x86 Example: mov [es:bx],ax. Other Apps • What is “V/N”? Virtual Physical – Can mark segments as invalid; requires check as well Address Space Address Space 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.17 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.18 Example of segment translation Observations about Segmentation 0x240 0x244 main: la $a0, varx jal strlen Seg ID # Base Limit • Virtual address space has holes … … 0 (code) 0x4000 0x0800 – Segmentation efficient for sparse address spaces 0x360 strlen: li $v0, 0 ;count 1 (data) 0x4800 0x1400 – A correct program should never address gaps (except 0x364 loop: lb $t0, ($a0) as mentioned in moment) 0x368 beq $r0,$t1, done 2 (shared) 0xF000 0x1000 » If it does, trap to kernel and dump core … … 3 (stack) 0x0000 0x3000 0x4050 varx dw 0x314159 • When it is OK to address outside valid range: Let’s simulate a bit of this code to see what happens (PC=0x240): – This is how the stack and heap are allowed to grow 1. Fetch 0x240. Virtual segment #? 0; Offset? 0x240 – For instance, stack takes fault, system automatically Physical address? Base=0x4000, so physical addr=0x4240 increases size of stack Fetch instruction at 0x4240. Get “la $a0, varx” Move 0x4050 $a0, Move PC+4PC • Need protection mode in segment table 2. Fetch 0x244. Translated to Physical=0x4244. Get “jal strlen” – For example, code segment would be read-only Move 0x0248 $ra (return address!), Move 0x0360 PC – Data and stack would be read-write (stores allowed) 3. Fetch 0x360. Translated to Physical=0x4360. Get “li $v0,0” Move 0x0000 $v0, Move PC+4PC – Shared segment could be read-only or read-write 4. Fetch 0x364. Translated to Physical=0x4364. Get “lb $t0,($a0)” Since $a0 is 0x4050, try to load byte from 0x4050 • What must be saved/restored on context switch? Translate 0x4050. Virtual segment #? 1; Offset? 0x50 – Segment table stored in CPU, not in memory (small) Physical address? Base=0x4800, Physical addr = 0x4850, Load Byte from 0x4850$t0, Move PC+4PC – Might store all of processes memory onto disk when switched (called “swapping”) 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.19 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.20
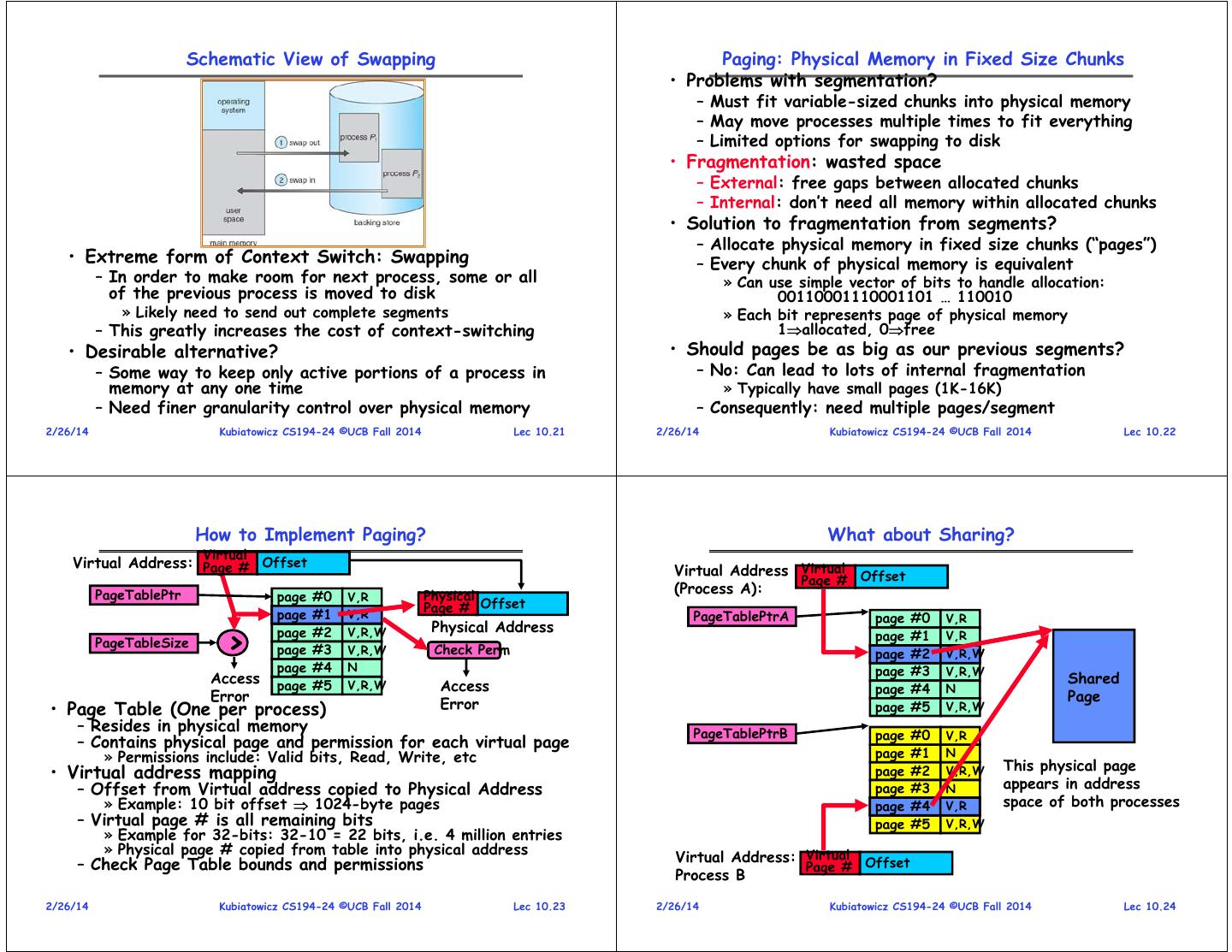
6 . Schematic View of Swapping Paging: Physical Memory in Fixed Size Chunks • Problems with segmentation? – Must fit variable-sized chunks into physical memory – May move processes multiple times to fit everything – Limited options for swapping to disk • Fragmentation: wasted space – External: free gaps between allocated chunks – Internal: don’t need all memory within allocated chunks • Solution to fragmentation from segments? – Allocate physical memory in fixed size chunks (“pages”) • Extreme form of Context Switch: Swapping – Every chunk of physical memory is equivalent – In order to make room for next process, some or all » Can use simple vector of bits to handle allocation: of the previous process is moved to disk 00110001110001101 … 110010 » Likely need to send out complete segments » Each bit represents page of physical memory – This greatly increases the cost of context-switching 1allocated, 0free • Desirable alternative? • Should pages be as big as our previous segments? – Some way to keep only active portions of a process in – No: Can lead to lots of internal fragmentation memory at any one time » Typically have small pages (1K-16K) – Need finer granularity control over physical memory – Consequently: need multiple pages/segment 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.21 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.22 How to Implement Paging? What about Sharing? Virtual Virtual Address: Page # Offset Virtual Address Virtual Offset Page # PageTablePtr Physical (Process A): page #0 V,R page #1 V,R Page # Offset PageTablePtrA page #0 V,R Physical Address > page #2 V,R,W page #1 V,R PageTableSize page #3 V,R,W Check Perm page #2 V,R,W page #4 N page #3 V,R,W Access Shared page #5 V,R,W Access page #4 N Error Page • Page Table (One per process) Error page #5 V,R,W – Resides in physical memory PageTablePtrB page #0 V,R – Contains physical page and permission for each virtual page » Permissions include: Valid bits, Read, Write, etc page #1 N This physical page • Virtual address mapping page #2 V,R,W – Offset from Virtual address copied to Physical Address page #3 N appears in address » Example: 10 bit offset 1024-byte pages page #4 V,R space of both processes – Virtual page # is all remaining bits page #5 V,R,W » Example for 32-bits: 32-10 = 22 bits, i.e. 4 million entries » Physical page # copied from table into physical address – Check Page Table bounds and permissions Virtual Address: Virtual Offset Page # Process B 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.23 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.24
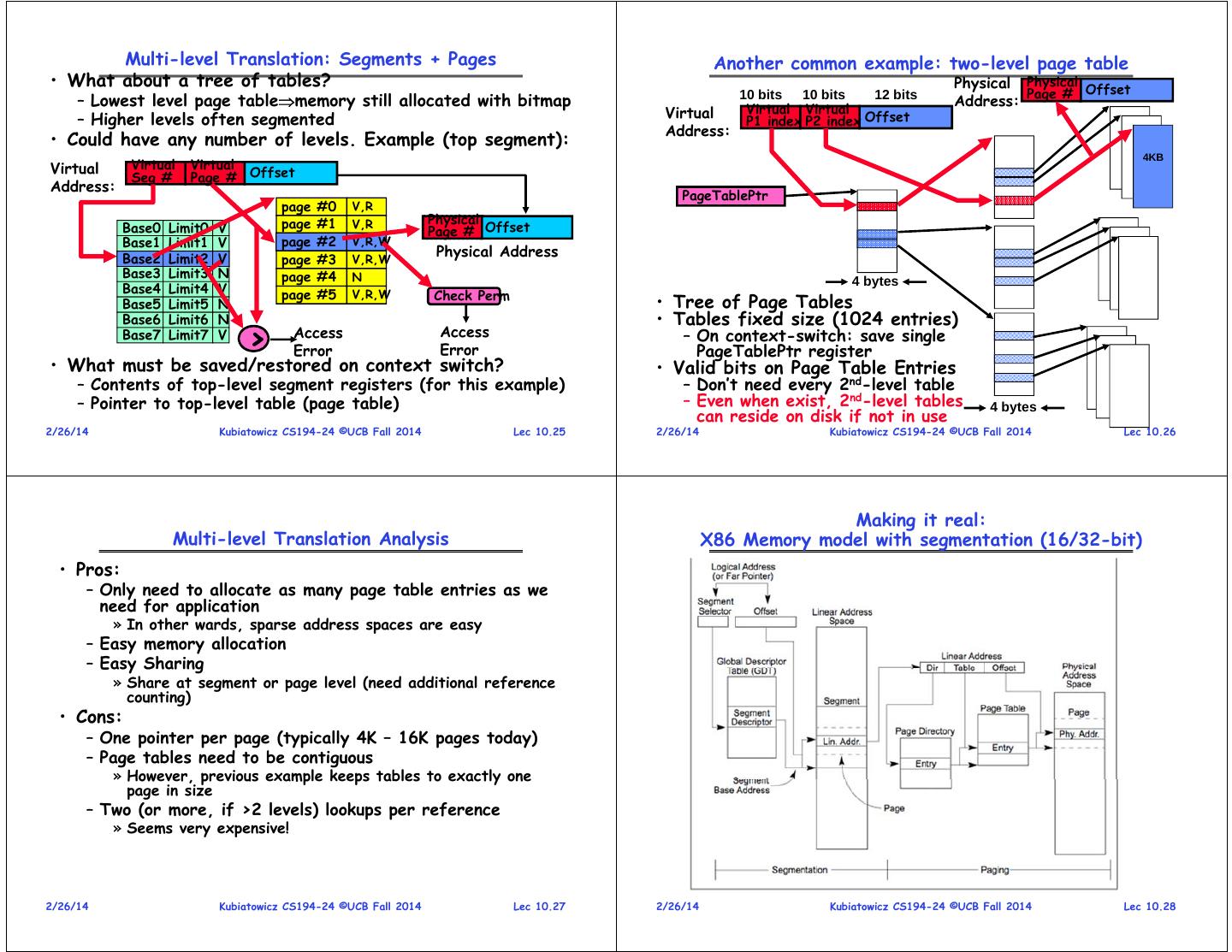
7 . Multi-level Translation: Segments + Pages Another common example: two-level page table • What about a tree of tables? Physical Physical Offset – Lowest level page tablememory still allocated with bitmap 10 bits 10 bits 12 bits Address: Page # Virtual Virtual Virtual – Higher levels often segmented P1 index P2 index Offset Address: • Could have any number of levels. Example (top segment): 4KB Virtual Virtual Virtual Seg # Page # Offset Address: PageTablePtr page #0 V,R page #1 V,R Physical Base0 Limit0 V Page # Offset Base1 Limit1 V page #2 V,R,W Base2 Limit2 V Physical Address page #3 V,R,W Base3 Limit3 N page #4 N 4 bytes Base4 Limit4 V page #5 V,R,W Check Perm Base5 Limit5 N • Tree of Page Tables Base6 Limit6 N • Tables fixed size (1024 entries) Base7 Limit7 V > Access Error Access Error – On context-switch: save single PageTablePtr register • What must be saved/restored on context switch? • Valid bits on Page Table Entries – Contents of top-level segment registers (for this example) – Don’t need every 2nd-level table – Pointer to top-level table (page table) – Even when exist, 2nd-level tables 4 bytes can reside on disk if not in use 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.25 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.26 Making it real: Multi-level Translation Analysis X86 Memory model with segmentation (16/32-bit) • Pros: – Only need to allocate as many page table entries as we need for application » In other wards, sparse address spaces are easy – Easy memory allocation – Easy Sharing » Share at segment or page level (need additional reference counting) • Cons: – One pointer per page (typically 4K – 16K pages today) – Page tables need to be contiguous » However, previous example keeps tables to exactly one page in size – Two (or more, if >2 levels) lookups per reference » Seems very expensive! 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.27 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.28
8 . X86 Segment Descriptors (32-bit Protected Mode) How are segments used? • Segments are either implicit in the instruction (say for code • One set of global segments (GDT) for everyone, different segments) or actually part of the instruction set of local segments (LDT) for every process – There are 6 registers: SS, CS, DS, ES, FS, GS • What is in a segment register? • In legacy applications (16-bit mode): – A pointer to the actual segment description: – Segments provide protection for different components of user programs G/L Segment selector [13 bits] RPL – Separate segments for chunks of code, data, stacks G/L selects between GDT and LDT tables (global vs local – Limited to 64K segments descriptor tables) • Two registers: GDTR and LDTR hold pointers to the global and • Modern use in 32-bit Mode: local descriptor tables in memory – Segments “flattened”, i.e. every segment is 4GB in size – Includes length of table (for < 213) entries – One exception: Use of GS (or FS) as a pointer to “Thread Local • Descriptor format (64 bits): Storage” » A thread can make accesses to TLS like this: mov eax, gs(0x0) G: Granularity of segment (0: 16bit, 1: 4KiB unit) • Modern use in 64-bit (“long”) mode DB: Default operand size (0; 16bit, 1: 32bit) – Most segments (SS, CS, DS, ES) have zero base and no length A: Freely available for use by software limits P: Segment present DPL: Descriptor Privilege Level – Only FS and GS retain their functionality (for use in TLS) S: System Segment (0: System, 1: code or data) Type: Code, Data, Segment 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.29 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.30 What is in a Page Table Entry (PTE)? Examples of how to exploit a PTE • What is in a Page Table Entry (or PTE)? • How do we use the PTE? – Pointer to next-level page table or to actual page – Invalid PTE can imply different things: – Permission bits: valid, read-only, read-write, write-only » Region of address space is actually invalid or » Page/directory is just somewhere else than memory • Example: Intel x86 architecture PTE: – Validity checked first – Address same format previous slide (10, 10, 12-bit offset) » OS can use other (say) 31 bits for location info – Intermediate page tables called “Directories” • Usage Example: Demand Paging Page Frame Number Free – Keep only active pages in memory PCD PWT 0 L D A U WP – Place others on disk and mark their PTEs invalid (Physical Page Number) (OS) 31-12 11-9 8 7 6 5 4 3 2 1 0 • Usage Example: Copy on Write P: Present (same as “valid” bit in other architectures) – UNIX fork gives copy of parent address space to child » Address spaces disconnected after child created W: Writeable – How to do this cheaply? U: User accessible » Make copy of parent’s page tables (point at same memory) PWT: Page write transparent: external cache write-through » Mark entries in both sets of page tables as read-only PCD: Page cache disabled (page cannot be cached) » Page fault on write creates two copies A: Accessed: page has been accessed recently • Usage Example: Zero Fill On Demand D: Dirty (PTE only): page has been modified recently – New data pages must carry no information (say be zeroed) L: L=14MB page (directory only). – Mark PTEs as invalid; page fault on use gets zeroed page Bottom 22 bits of virtual address serve as offset – Often, OS creates zeroed pages in background 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.31 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.32
9 . Slightly More than 4GB RAM: PAE mode on x86 What about 64-bit x86-64 (“long mode”)? • X86 long mode: 64 bit virtual addresses, 40-52 bits of physical memory – Not all 64-bit virtual addresses translated – Virtual Addresses must be “cannonical”: top n bits of must be equal » n here might be 48 PAE with 4K pages PAE with 2MB pages » Non-cannonical addresses • Physical Address Extension (PAE) will cause a protection fault – Poor-man’s large memory extensions • Using PAE scheme with 64-bit PTE can map 48-bits of – More than 4GB physical memory – Every process still can have only 32-bit address space virtual memory (94 + 12 = 48) • 3-Level page table • As mentioned earlier, segments other than FS/GS – 64-bit PTE format disabled in long mode • How do processes use more than 4GB memory? – OS Support for mapping and unmapping physical memory into virtual address space – Application Windowing Extensions (AWE) 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.33 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.34 Inverted Page Table Recall: Caching Concept • With all previous examples (“Forward Page Tables”) – Size of page table is at least as large as amount of virtual memory allocated to processes – Physical memory may be much less » Much of process space may be out on disk or not in use Virtual Page # Offset • Cache: a repository for copies that can be accessed more quickly than the original Physical – Make frequent case fast and infrequent case less dominant Hash Page # Offset • Caching underlies many of the techniques that are used Table today to make computers fast – Can cache: memory locations, address translations, pages, • Answer: use a hash table file blocks, file names, network routes, etc… – Called an “Inverted Page Table” • Only good if: – Size is independent of virtual address space – Frequent case frequent enough and – Directly related to amount of physical memory – Infrequent case not too expensive – Very attractive option for 64-bit address spaces • Important measure: Average Access time = • Cons: Complexity of managing hash changes (Hit Rate x Hit Time) + (Miss Rate x Miss Time) – Often in hardware! 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.35 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.36
10 . Why does caching matter for Virtual Memory? Caching Applied to Address Translation Virtual Virtual Virtual TLB Seg # Page # Offset Virtual Physical Address: Address Cached? page #0 V,R CPU Yes Address Physical page #1 V,R Physical No Memory Base0 Limit0 V Page # Offset Base1 Limit1 V page #2 V,R,W Base2 Limit2 V Physical Address page #3 V,R,W Base3 Limit3 N page #4 N Base4 Limit4 V Translate page #5 V,R,W Check Perm Base5 Limit5 N (MMU) Base6 Limit6 N Base7 Limit7 V > Access Error Access Error Data Read or Write (untranslated) • Cannot afford to translate on every access • Question is one of page locality: does it exist? – At least three DRAM accesses per actual DRAM access – Instruction accesses spend a lot of time on the same – Or: perhaps I/O if page table partially on disk! page (since accesses sequential) • Even worse: What if we are using caching to make – Stack accesses have definite locality of reference memory access faster than DRAM access??? – Data accesses have less page locality, but still some… • Solution? Cache translations! • Can we have a TLB hierarchy? – Translation Cache: TLB (“Translation Lookaside Buffer”) – Sure: multiple levels at different sizes/speeds 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.37 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.38 What Actually Happens on a TLB Miss? What happens on a Context Switch? • Hardware traversed page tables: • Need to do something, since TLBs map virtual – On TLB miss, hardware in MMU looks at current page addresses to physical addresses table to fill TLB (may walk multiple levels) – Address Space just changed, so TLB entries no » If PTE valid, hardware fills TLB and processor never knows longer valid! » If PTE marked as invalid, causes Page Fault, after which kernel decides what to do afterwards • Options? • Software traversed Page tables (like MIPS) – Invalidate TLB: simple but might be expensive – On TLB miss, processor receives TLB fault » What if switching frequently between processes? – Kernel traverses page table to find PTE » If PTE valid, fills TLB and returns from fault – Include ProcessID in TLB » If PTE marked as invalid, internally calls Page Fault handler » This is an architectural solution: needs hardware • Most chip sets provide hardware traversal • What if translation tables change? – Modern operating systems tend to have more TLB faults – For example, to move page from memory to disk or since they use translation for many things vice versa… – Examples: » shared segments – Must invalidate TLB entry! » user-level portions of an operating system » Otherwise, might think that page is still in memory! 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.39 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.40
11 . What TLB organization makes sense? TLB organization: include protection • How big does TLB actually have to be? CPU TLB Cache Memory – Usually small: 128-512 entries – Not very big, can support higher associativity • Needs to be really fast – Critical path of memory access • TLB usually organized as fully-associative cache » In simplest view: before the cache – Lookup is by Virtual Address » Thus, this adds to access time (reducing cache speed) – Returns Physical Address + other info – Seems to argue for Direct Mapped or Low Associativity • What happens when fully-associative is too slow? • However, needs to have very few conflicts! – Put a small (4-16 entry) direct-mapped cache in front – With TLB, the Miss Time extremely high! – Called a “TLB Slice” – This argues that cost of Conflict (Miss Time) is much • Example for MIPS R3000: higher than slightly increased cost of access (Hit Time) Virtual Address Physical Address Dirty Ref Valid Access ASID • Thrashing: continuous conflicts between accesses – What if use low order bits of page as index into TLB? 0xFA00 0x0040 0x0003 0x0010 Y N N Y Y Y R/W R 34 0 » First page of code, data, stack may map to same entry 0x0041 0x0011 N Y Y R 0 » Need 3-way associativity at least? – What if use high order bits as index? » TLB mostly unused for small programs 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.41 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.42 Example: R3000 pipeline includes TLB “stages” Reducing translation time further • As described, TLB lookup is in serial with cache lookup: MIPS R3000 Pipeline Inst Fetch Dcd/ Reg ALU / E.A Memory Write Reg Virtual Address TLB I-Cache RF Operation WB 10 V page no. offset E.A. TLB D-Cache TLB Lookup TLB 64 entry, on-chip, fully associative, software TLB fault handler Access V Rights PA Virtual Address Space ASID V. Page Number Offset 6 12 P page no. offset 20 10 0xx User segment (caching based on PT/TLB entry) Physical Address • Machines with TLBs go one step further: they overlap 100 Kernel physical space, cached 101 Kernel physical space, uncached 11x Kernel virtual space TLB lookup with cache access. Allows context switching among – Works because offset available early 64 user processes without TLB flush 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.43 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.44
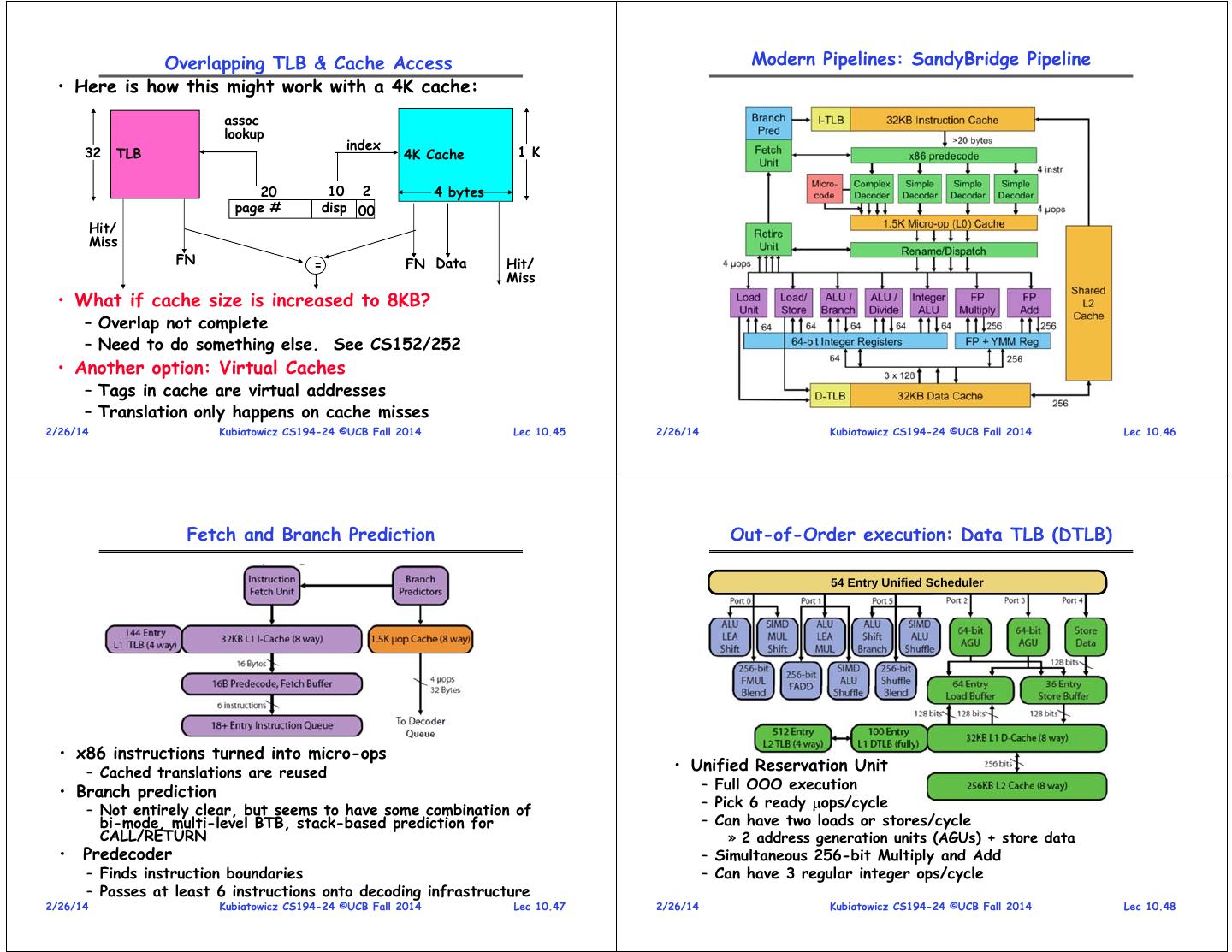
12 . Overlapping TLB & Cache Access Modern Pipelines: SandyBridge Pipeline • Here is how this might work with a 4K cache: assoc lookup index 32 TLB 4K Cache 1 K 20 10 2 4 bytes page # disp 00 Hit/ Miss FN = FN Data Hit/ Miss • What if cache size is increased to 8KB? – Overlap not complete – Need to do something else. See CS152/252 • Another option: Virtual Caches – Tags in cache are virtual addresses – Translation only happens on cache misses 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.45 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.46 Fetch and Branch Prediction Out-of-Order execution: Data TLB (DTLB) 54 Entry Unified Scheduler • x86 instructions turned into micro-ops – Cached translations are reused • Unified Reservation Unit • Branch prediction – Full OOO execution – Pick 6 ready ops/cycle – Not entirely clear, but seems to have some combination of bi-mode, multi-level BTB, stack-based prediction for – Can have two loads or stores/cycle CALL/RETURN » 2 address generation units (AGUs) + store data • Predecoder – Simultaneous 256-bit Multiply and Add – Finds instruction boundaries – Can have 3 regular integer ops/cycle – Passes at least 6 instructions onto decoding infrastructure 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.47 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.48
13 . Summary (1/2) Summary (2/2) • Memory is a resource that must be shared • PTE: Page Table Entries – Controlled Overlap: only shared when appropriate – Includes physical page number – Translation: Change Virtual Addresses into Physical Addresses – Control info (valid bit, writeable, dirty, user, etc) – Protection: Prevent unauthorized Sharing of resources • Segment Mapping • A cache of translations called a “Translation Lookaside – Segment registers within processor Buffer” (TLB) – Segment ID associated with each access » Often comes from portion of virtual address – Relatively small number of entries (< 512) » Can come from bits in instruction instead (x86) – Fully Associative (Since conflict misses expensive) – Each segment contains base and limit information » Offset (rest of address) adjusted by adding base – TLB entries contain PTE and optional process ID • Page Tables – Memory divided into fixed-sized chunks of memory • On TLB miss, page table must be traversed – Virtual page number from virtual address mapped through – If located PTE is invalid, cause Page Fault page table to physical page number – Offset of virtual address same as physical address • On context switch/change in page table – Large page tables can be placed into virtual memory • Multi-Level Tables – TLB entries must be invalidated somehow – Virtual address mapped to series of tables • TLB is logically in front of cache – Permit sparse population of address space • Inverted page table – Thus, needs to be overlapped with cache access to be – Size of page table related to physical memory size really fast 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.49 2/26/14 Kubiatowicz CS194-24 ©UCB Fall 2014 Lec 10.50
3秒后跳转登录页面
去登陆

